设计模式-01-C-2020-08-11
因为CSDN博客的特性,对于已经发布的博客再进行编辑的过程里,没有提供保存草稿这样的功能。因此有时候在做更新的时候,新的设计模式没有讲解完我就发布了。那可能是因为电脑太卡,不保存的话,怕东西就没了。但是一保存他会自动发布,因此大家可能会看到最下面的设计模式写了一半的情况,在此向大家道歉。
如果出现了写了一半的情况,我一般都会在当天把新的内容继续进行编写,然后进行发布。
文章目录
- 更新日志
- 前言
- 设计模式
-
- 单例模式
- 工厂方法模式
- 抽象工厂模式
- 模板方法模式
- 建造者模式
- 代理模式
- 原型模式
- 中介者模式
- 命令模式
- 责任链模式
- 装饰模式
- 策略模式
- 适配器模式
- 迭代器模式
- 组合模式
- 设计原则
- 参考文献
更新日志
| 日志编号 | 说明 |
|---|---|
| C-2020-08-11 | 第一次创建,内容偏多,持续更新 |
| U-2020-08-12 | 增加单例模式的讲解 |
| U-2020-08-13 | 增加工厂方法模式的讲解 |
| U-2020-08-14 | 增加抽象工厂模式的讲解 |
| U-2020-08-15 | 增加模板方法模式的讲解 |
| U-2020-08-16 | 增加建造者模式的讲解 |
| U-2020-08-17 | 增加代理模式的讲解,留个坑。对于动态代理和AOP的讲解会在spring相关内容中体现,而不是在这里体现。因此动态代理只是做了一个很简单的概述。随后写完spring的内容,会把spring的内容贴在动态代理的末尾 |
| U-2020-08-18 | 增加原型模式的讲解 |
| U-2020-08-19 | 增加中介者模式的讲解 |
| U-2020-08-20 | 增加命令模式的讲解 |
| U-2020-08-21 | 增加责任链模式的讲解 |
| U-2020-08-24 | 增加装饰模式的讲解 |
| U-2020-08-25 | 增加策略模式的讲解 |
| U-2020-08-26 | 增加适配器模式的讲解 |
| U-2020-08-27 | 增加迭代器模式的讲解 |
| U-2020-08-27 | 增加组合模式的讲解 |
前言
设计模式贯穿程序开发,面试等诸多环节,日常中有三个问题是程序员经常被问到的。第一个,有没有读过Java源码?第二个,会多少种设计模式?第三个,对JVM有多了解?
借着这篇博客,基于《设计模式之禅(第2版)》1 的内容和学习体会,将个人经验进行总结。
本文内容中出现任何错误,描述不清之处,欢迎各位大佬指出。
本博客在编写时只是细分到了不同设计模式,设计原则进行了次级标题的设置,对于每个模式中的细小分节没有加标题。这样做的原因是标题太多,增加了目录的长度。并且层次过深的目录会极大的增大阅读的心理压力。反而这种适当的层级深度,能带来更轻松的阅读心情。
设计模式
设计模式是摒弃语言之差,专注于程序设计本身的经验总结。通过大牛们不断锤炼,不断对设计原则的钻研,最终形成了23种设计模式。今天会陆陆续续补充这个博客,讲解23种设计模式和6种设计原则。出于方便实际使用的目标,本文会先介绍设计模式,后介绍设计原则。但在实际学习的过程中,更推荐先学习设计原则,后学习设计模式。
单例模式
单例模式是一个比较简单的设计模式,单例模式的定义如下:
Ensure a class has only one instance, and provide a global point of access to it.(确保某一个类 只有一个实例,而且自行实例化并向整个系统提供这个实例。) 1
借由书中的例子,单例模式更类似于古代的皇帝,或者现在的主席,总统。一个时间内,一个国家中能当皇帝或者主席,总统的人只能有一个。(此处不考虑各种特殊情况)。这样类比之后,国家等同于当前的项目。而单例模式是指,整个项目内这个类的实例有且仅有一个。
对象实例化的过程,于Java语言而言,就是调用构造方法的过程。一般情况下,构造方法都是public修饰的,那此时为了能够进行单例,需要将构造方法的访问修饰符设置成private,并且通过一个公开方法进行对象的返回。
单例模式基础代码如下:
package com.phl.design.singleTon;
public class DemoOne {
private static DemoOne demo = new DemoOne();
private DemoOne() {
}
public static DemoOne getInstance(){
return demo;
}
}
上面的是最基本的单例模式示例。其实在单例模式中,需要无时无刻保证两个事情。第一个,这个类的构造方法不能通过其他类调用,另一个,这个类只会返回这一个固定的实例。
但是在实际使用中,往往都会出现各种各样的问题。因为不同使用场景中,应对问题的整合处理,单例模式又逐步演变出更多形式,其中最好用,最能符合多种场景需求的就是线程安全的懒汉模式。
线程安全的懒汉模式,代码如下:
package com.phl.design.singleTon;
public class DemoOne {
private final static DemoOne demo = null;
private DemoOne() {
}
public static synchronized DemoOne getInstance(){
if(demo == null){
demo = new DemoOne();
}
return demo;
}
}
这种写法主要的好处在于延时加载和线程安全。
首先说延时加载。这种写法在第一次调用时才加载,避免内存浪费。
线程安全。第一种直接new的写法也是线程安全的,但是这种在程序初始化过程中就直接实例化的行为会造成内存浪费。因此改成了延时加载。但是由于延时加载,当使用B/S架构时,每当收到一个请求,就会开辟一个线程。此时如果两个请求同时访问了其中的demo == null这样的判断时,有一定几率(虽然很小)会最终生成两个实例对象,并且一旦发生这种两个实例的情况很难复现,而且代码上不容易看出问题出现在哪里,这并不是我们想看到的。因此对于这种情况,做成了静态同步方法的形式,这样就避免出现同一时间两个实例的情况。
因此,在写单例模式的时候更推荐按照线程安全的懒汉模式进行编写。
单例模式在什么时候使用?
基于单例模式的特性永远有且只有一个实例,单例模式更适合用于如下情况:
- 生成唯一序列号
- 整个项目中需要提供一个共享访问点或共享数据,例如web页面中的计数器。可以不用每次都把数据刷到数据库中,使用单例模式保持计数器的值,并且能保证线程安全。
- 创建的对象会消耗很多资源,比如访问IO或者数据库连接等资源的时候,可以使用单例模式。
- 需要定义大量的静态常量和静态方法(如工具类)的情况,可以选择使用单例模式。(当然,也可以直接将工具类中的方法声明成static)
单例模式的缺点
单例模式的好处显而易见,实现了线程同步,不会重复创建销毁对象等。但是,它并不是完美的,常见的缺点如下:
- 单例模式一般没有接口,拓展性差。注意,这里说的没有接口,是指无法把一个要做单例模式的类声明称接口或者抽象类,因为接口和抽象类无法进行实例化。当然,本质上单例模式可以实现借口接口或者被继承,从而实现拓展。只是这种用法在实际中很少见,具体问题还是需要具体分析。
- 单例模式不利于测试。这里是说在并行开发情况下,如果单例模式的类并没有开发好,就无法测试。而且因为没有接口,单例模式也无法通过mock的方式虚拟出一个对象。
- 单例模式一般情况都与“单一职责原则”(后面会讲解的设计原则)冲突。说句闲话,那些设计原则,如果大家对设计原则不熟悉,那至少对数据库范式熟悉。这两者是类似的东西,同理,在实际使用中,大多数情况都会出现一种现象,就是范式(原则)向现实低头。
单例模式使用过程中注意的地方
首先要注意的就是在多线程的时候,做到线程安全,解决方案就是线程安全的懒汉模式。
其次,除过通过构造方法实例化之外,在Java中还有两种方式可以实现。一种是通过反射,一种是类实现cloneable接口之后,通过clone方法进行复制。这两种方式都可以生成新的实例。因此在做单例模式的时候,不要通过这两种方式进行实例化。
单例模式拓展
这中拓展很少,但是可能是有必要的。
如果是需要一个实例,我们可以用单例模式。如果需要多个实例,我们就普通的通过new的形式就能实现。但是如果需要固定个数的实例,并且这个固定个数>1的情况下。该怎么解决?
其实,还是用单例模式,但是在单例模式里,多了两个变量就能实现。一个变量用于定义最多可以有多少个实例。另一个变量是用于接收所有实例的集合。
这种设计是单例模式的拓展,被称为有上限的多例模式。
这种有上限的多例模式,是对单例模式可能存在的性能不足进行了补充。比如在进行文件读取的过程里会出现IO性能不足。但是可以通过有上限的多例模式,提前准备好多个IO对象,这样在需要读取多个文件时就能做到快速响应。
工厂方法模式
于工厂模式而言,大面上可以分为工厂方法模式和抽象工厂模式。这里先讲解工厂方法模式,下一个章节讲解抽象工厂模式。
在日常开发过程中,我们总是在强调高内聚低耦合。对于没怎么接触过设计模式的同志来讲,做到前半句似乎不难,但是后半句怎么保证呢?即便在使用Spring框架的时候,我们定义了各种各样的Bean,并且设置了prototype或者singleton,但是有多少是通过ApplicationContext里面实现的实例化呢?
比如在Service层中,前端传入了一组查询参数(此处的假设条件是这些入参并没有通过Spring的类型转换组装成了一个对象)。假设这里要用一个自定义对象去接收,此时大多数同志的做法都是new一个对象出来,之后进行各种set。或者直接调用有参构造方法。亦或者在Dao层里进行对象传参的时候,大多都习惯于new一个出来。对于这种写法,就没有做到低耦合。这样的写法让Service和Dao依赖于Bean对象的构造方法,加大了模块的耦合度。
工厂方法模式定义
Define an interface for creating an object,but let subclasses decide which class to instantiate.Factory Method lets a class defer instantiation to subclasses.(定义一个用于创建对象的 接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。)1
《设计模式之禅(第2版)》中采用的例子很恰当,这也是我能不会觉得无聊的读完这本书的主要原因。
针对工厂方法模式,书中举例是女娲造人。以防有同志不知道女娲造人的故事,这里放上了链接:女娲造人——百度百科。
现在将女娲造人的故事抽象成一个类图。首先请大家原谅我这个夹生的类图,我不怎么会画。
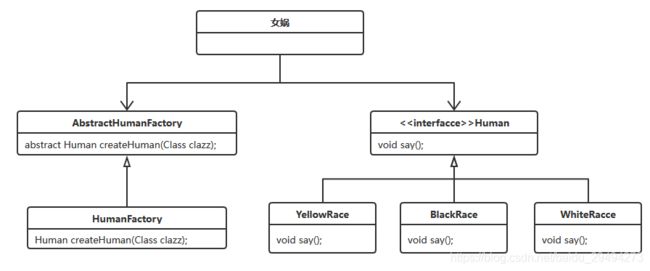 这里对故事稍作变形。故事里人是女娲娘娘自己捏出来的。这里的变形是假设女娲娘娘在造人的时候借助了某项工具,这个工具具备了造人的能力。从而出现了上面这个图。
这里对故事稍作变形。故事里人是女娲娘娘自己捏出来的。这里的变形是假设女娲娘娘在造人的时候借助了某项工具,这个工具具备了造人的能力。从而出现了上面这个图。
女娲作为神仙具有很多种能力,其中一个能力就是造人。于是便把这种能力抽象成一个抽象类AbstractHumanFactory,具体进行造人的是HumanFactory。人类则被定义成了一个接口Human,他有三个实现类,分别是黄种人,黑种人,白种人。这样从逻辑上就完成了划分。
首先展示代码结构:
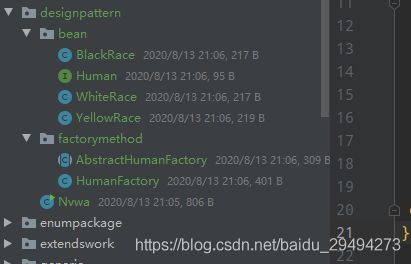 上图中,bean包里面定义了Human这个接口,并且提供了YellowRace,BlackRace和WhiteRace三个实现类。factorymethod包下提供了抽象类AbstractHumanFactory,同时还有继承了这个抽象类的真实工厂HumanFactory。
上图中,bean包里面定义了Human这个接口,并且提供了YellowRace,BlackRace和WhiteRace三个实现类。factorymethod包下提供了抽象类AbstractHumanFactory,同时还有继承了这个抽象类的真实工厂HumanFactory。
Human接口如下:
package com.phl.demoone.designpattern.bean;
public interface Human {
void say();
}
抽象工厂类如下,抽象工厂中定义了抽象方法CreateHuman:
package com.phl.demoone.designpattern.factorymethod;
import com.phl.demoone.designpattern.bean.Human;
public abstract class AbstractHumanFactory {
abstract <T extends Human> T createHuman(Class<T> t) throws ClassNotFoundException, IllegalAccessException,
InstantiationException;
}
实际的工厂类代码如下。在实际进行实例化的时候,使用了Java的反射机制。:
package com.phl.demoone.designpattern.factorymethod;
import com.phl.demoone.designpattern.bean.Human;
public class HumanFactory extends AbstractHumanFactory {
@Override
public <T extends Human> T createHuman(Class<T> t) throws ClassNotFoundException, IllegalAccessException,
InstantiationException {
return (T)Class.forName(t.getName()).newInstance();
}
}
最后,创建一个女娲类进行调用上述过程:
package com.phl.demoone.designpattern;
import com.phl.demoone.designpattern.bean.BlackRace;
import com.phl.demoone.designpattern.bean.WhiteRace;
import com.phl.demoone.designpattern.bean.YellowRace;
import com.phl.demoone.designpattern.factorymethod.HumanFactory;
public class Nvwa {
public static void main(String[] args) throws IllegalAccessException, InstantiationException,
ClassNotFoundException {
HumanFactory humanFactory = new HumanFactory();
YellowRace yellowRace = humanFactory.createHuman(YellowRace.class);
yellowRace.say();
WhiteRace whiteRace = humanFactory.createHuman(WhiteRace.class);
whiteRace.say();
BlackRace blackRace = humanFactory.createHuman(BlackRace.class);
blackRace.say();
}
}
看到这里相信大家对工厂方法模式很定有很多问题,比如,为什么工厂方法要先做了一层抽象类,而不是直接使用工厂方法类?又比如这样写的好处有哪些?
下面将会对工厂模式进行展开讲解。
工厂方法模式的万金油写法
这里说的万金油写法,除过可能会增加一些代码量(比如在工厂方法上抽出来的抽象类),其他方面都很优秀。先上图,这个图出自《设计模式之禅(第2版)》。1
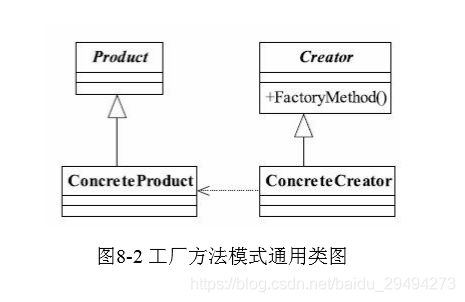
在工厂方法模式中,抽象产品类Product负责定义产品的共性,实现对事物最抽象的定 义;Creator为抽象创建类,也就是抽象工厂,具体如何创建产品类是由具体的实现工厂 ConcreteCreator完成的。1
类似在单例模式讲解时,提出了基本能完美的响应各种需要线程安全的懒汉模式一样,往往这种万金油写法对于编码经验不足的同志而言,是一个非常好的指导方案。
按照这些万金油写法,能解决工作中近99%的需求。同时根据自己的经验增长,逐步琢磨出这些万金油写法的变形从而更贴近自己的实际需求。
参照这个类图,以及上面写的女娲例子,整理之后就会有如下代码。
抽象产品类,就是之前例子里的Human接口,只不过这里写成了抽象类。
package com.phl.demoone.designpattern.base;
public abstract class AbstractProduct {
abstract void doSomething();
}
抽象工厂方法类
package com.phl.demoone.designpattern.base;
public abstract class AbstractCreateFactory {
abstract <T extends AbstractProduct> T createProduct(Class<T> clazz) throws ClassNotFoundException,
IllegalAccessException, InstantiationException;
}
真实产品类
package com.phl.demoone.designpattern.base;
public class RealProduct extends AbstractProduct{
@Override
void doSomething() {
}
}
真实工厂方法类
package com.phl.demoone.designpattern.base;
public class RealFactory extends AbstractCreateFactory {
@Override
<T extends AbstractProduct> T createProduct(Class<T> clazz) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
return (T) (Class.forName(clazz.getName()).newInstance());
}
}
上面这些代码就是根据那个类图转换出来的,这是工厂方法模式的万金油写法。这个万金油写法方便同志们根据实际项目进行扩展。
工厂方法模式优点
首先,工厂方法模式提供了良好的封装性。代码结构清晰,易于理解、修改、扩展。出现任何多的工厂、产品都可以套用上述万金油写法进行全部或者部分扩展。
其次,屏蔽了产品本身。还记得工厂方法模式一开篇提到的,在Service,Dao中的各种new吗?仔细看看整个工厂方法模式中,有没有任何一个地方用到了产品的构造方法呢?并没有!这使得所有的业务逻辑与数据对象解耦合。不论对象数据的构造方法怎么改变,怎么的颠三倒四都不会影响到任何一个地方。
最后,细想一下我们在日常中new对象的过程,其实我们更多是使用无参的构造方法,原因在于我们本身并不关注要new出来的对象需要是什么,这个是什么的过程,往往是new出来之后进行各种set操作。这一点也很符合工厂方法模式。在通过工厂方法去实例化的时候,我们只需要指定我要的对象是什么类型的,之后就交给工厂方法,其他都不用我们去操心。
工厂方法模式的使用场景
首先请注意,工厂方法模式,本质上讲,他是new对象的替代方式。因此在实际使用中,需要衡量是否需要引入工厂方法模式,因为这么做会直接增加代码的复杂度。
其次,如果项目中需要灵活的、可扩展对象的框架时,可以考虑工厂方法模式。比方说,短信,邮件都能实现对人的通知。那么此时就可以将这两种方式定义成一个抽象产品,之后通过上述万金油写法进行实例化。这样的好处在于,一旦出现新的通知方式,比如微信,QQ或者其他什么的时候,对于业务代码而言,他们不会出现改变。(因为都实现了同样的抽象类,并且通知人的方法就类似与抽象类中的doSomeThing方法,是一个共性的方法)。此时需要修改的代码只是在用工厂类实例化时传入一个微信,或者QQ的类型即可。
当然了,其他原本该增加的还是得新增,比如微信或者QQ这个类,以及他们是怎么实现通知人的这个方法。
相信通过这样的类比,会使得我们真实的体会到工厂方法模式的好处,易于扩展、维护、模块之间解耦合。
工厂方法模式的变形
工厂方法模式的万金油写法很好,很强大,但是有时候会显得有一些麻烦,或者不够切合自身项目特点。因此,根据这种情况大佬们提出了如下几种变形供我们参考。
简单工厂模式
简单工厂模式是对上述万金油写法的一种缩小。我们考虑一个问题。一个类只需要一个工厂类就能实现该类对象的实例化,因此没有必要非要把这个工厂类进行实例化,使用静态方法足矣。因此那个万金油的类图就变成了如下结果
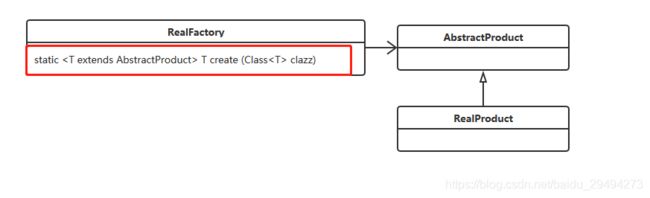 从上图可以看出来,工厂类并没有再做抽象类,而是省略成了一个类,并且这个类不用被实例化,因为里面的create方法设置成了static。
从上图可以看出来,工厂类并没有再做抽象类,而是省略成了一个类,并且这个类不用被实例化,因为里面的create方法设置成了static。
多个工厂模式
所谓多个工厂是这么理解。用女娲造人的例子来看,我们实例化一个工厂之后,给工厂里传入不同的参数(各种Class)得到不同的返回(各个类的实例)。在这个过程里,可以应对每个需要实例化的类(黄种人,黑种人,白种人)创建出他们对应的工厂类(原本只有一个工厂类实现了抽象工厂,现在按照人种,做了三个抽象工厂的实现类)。这样做了之后,都不用传递参数。创建黄种人的时候就调用黄种人工厂。创建白种人就调用白种人工厂。以此类推。
工厂方法模式替代单例模式
这里唯一需要注意的地方,之前单例模式都是单例这个类自身创建自己,不存在其他类去创建的过程。使用工厂方法模式时,却是由工厂类进行实例化。这里并不影响单例类把自己的构造方法写成前它修饰,它的构造方法还是private。之后在工厂类里通过反射拿到构造方法,然后将Accessible设置成true,就可以实现对象实例化的过程了。剩余前它内容,仿制单例模式是如何控制单例的即可。
延迟初始化
所谓延迟初始化,乍一看这个概念有些陌生。我们换一个说法。
之前讲过数据库连接池,里面在讲到newCachedThreadPoolExecutor的时候提到了,通过这个方法返回的ThreadPoolExecutor线程池中的线程有一个keepAlive时长,默认是1分钟。意思是,如果线程池里的一个线程执行完当次任务,不会直接被GC回收,而是会待在缓存里,如果1分钟之内有新的任务进来,它还能被再次使用。
这就是延迟初始化想表达的事情。
在工厂类中提供一个Map变量,每次通过这个工厂类实例化一个对象的时候,先在Map中看一下,是否包含了当前要实例化类型的对象,如果有,则返回。如果没有,则进行实例化,并且把实例化对象放在Map中,然后将新实例化的对象进行返回。
综述
工厂方法模式在项目中使用的很频繁,基本上是人尽皆知。学习好这个模式,并且与其他模式灵活搭配会有更好更灵活的效果。
抽象工厂模式
从名字可以看出来,抽象工厂模式与工厂方法模式肯定有有着千丝万缕的联系的。在解释抽象工厂模式之前,先回顾一下工厂方法模式。
在工厂方法模式中,根据推崇的万金油写法。我们首先会需要两个抽象类,分别是抽象工厂类,里面定义了用于实例化的抽象方法,入参是要被实例化的Class对象。其次,我们会需要一个产品抽象类,这个抽象类中定义了这一类型产品的共性,并且提供了各式各样的抽象方法,用于让实际产品类在继承了抽象产品类之后进行特性化实现。最后,我们还需要有一个真实工厂类,这个类继承自抽象工厂类,里面实现了实例化的具体操作。
使用时,在场景类(调用类)中实例化出真实工厂类的对象,然后在调用实例化方法时传入指定待实例化类的Class对象,交由真实工厂类实例化后,返回实例化结果供调用者使用。
抽象工厂模式大致上符合这样的流程,或者说这样的思想,或者说这样的类图。但是抽象工厂模式中所谓的抽象是对抽象产品,抽象工厂进行了更细致的抽象过程。
思考
作为自然界中的一员,不论是根据进化论,还是上面提到的女娲造人的神话。我们应该已经意识到了,在上述介绍工厂方法模式的时候,出现了一个巨大的BUG。我们虽然实例化出了三个人种,分别是黄种人,黑种人和白种人。但是,这些人没有进行性别的区分,这与现实世界的差距太大了。
解决和变形
这三种人种中,都有两种性别(这个例子暂不考虑特殊情况,特殊情况会在下面进行讲解)。同样,这三种人中每一种都有两个性别。此处,先按照性别->人种这样的分类方法往下进行,具体的原因会在后面讲解。
基于这样的考量,我们可以将原本的工厂方法模式类图抽象成如下的一个类图。
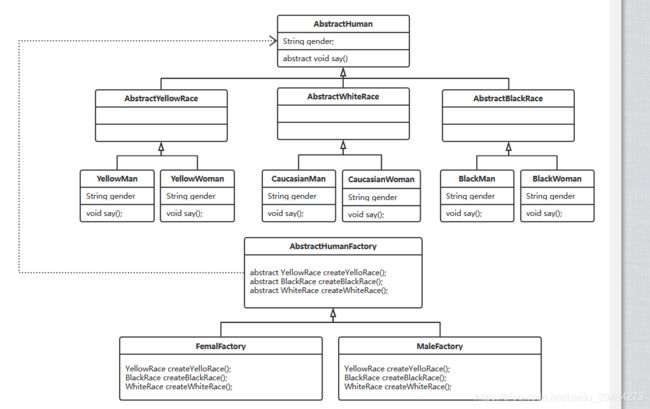 首先强调一点,针对人类这个抽象类以及中间的黄种人,白种人,黑种人这些抽象类中的属性和方法,仅仅进行讲解用。大家自己练习的时候,可以做更多种。
首先强调一点,针对人类这个抽象类以及中间的黄种人,白种人,黑种人这些抽象类中的属性和方法,仅仅进行讲解用。大家自己练习的时候,可以做更多种。
变形的过程中进行了如下改变。首先就是产品(Human)类。原先是一层抽象类,之后直接有三个真实的产品类,代表了三个人种。现在是人种也做成了抽象类,每个人种下面有了男性和女性两个具体的类。
之后是工厂。原先只有一个抽象工厂,抽象工厂里定义了创建人的抽象方法,然后通过一个真实工厂继承并实现了抽象的造人方法。并且在造人的过程里需要传入要创造的人的类型。
现在在抽象工厂里有了三个抽象方法,分别用于创建三种人。然后有两个工厂实现类,按照性别创建这三种人。并且因为方法最终都能指定到真实的对象上,因此不需要传入各种各样的参数。
注意这里为什么这么分,会在后续进行解释。这里这段描述只是对类图进行解读。
说了这么多,具体的代码如下所示。首先是抽象工厂与工厂实现类的代码。
抽象工厂代码:
package com.phl.design.abstractfactorypattern.abstractfactory;
import com.phl.design.abstractfactorypattern.bean.AbstractBlackRace;
import com.phl.design.abstractfactorypattern.bean.AbstractWhiteRace;
import com.phl.design.abstractfactorypattern.bean.AbstractYellowRace;
public abstract class AbstractHumanFactory {
abstract AbstractWhiteRace createWhiteRace();
abstract AbstractBlackRace createBlackRace();
abstract AbstractYellowRace createYellowRace();
}
真实工厂的代码,男人工厂:
package com.phl.design.abstractfactorypattern.abstractfactory;
import com.phl.design.abstractfactorypattern.bean.*;
public class MaleFactory extends AbstractHumanFactory {
@Override
AbstractWhiteRace createWhiteRace() {
return new CaucasianMale();
}
@Override
AbstractBlackRace createBlackRace() {
return new BlackMale();
}
@Override
AbstractYellowRace createYellowRace() {
return new YellowMale();
}
}
女人工厂:
package com.phl.design.abstractfactorypattern.abstractfactory;
import com.phl.design.abstractfactorypattern.bean.*;
public class FemaleFactory extends AbstractHumanFactory {
@Override
AbstractWhiteRace createWhiteRace() {
return new CaucasianFemale();
}
@Override
AbstractBlackRace createBlackRace() {
return new BlackFemale();
}
@Override
AbstractYellowRace createYellowRace() {
return new YellowFemale();
}
}
工厂的代码都在上面了。
接着是人的代码。首先是最上层的人类抽象类:
package com.phl.design.abstractfactorypattern.bean;
public abstract class AbstractHuman {
String gender;
//之后会在不同实现类中进行特性实现
abstract void say();
}
第二层抽象,抽象出不同人种。因为有很多相似的地方,因此人类这边的例子只通过黄种人记性展示。
黄种人抽象类,只是做了最简单的继承,并没有任何特性的地方:
package com.phl.design.abstractfactorypattern.bean;
public abstract class AbstractYellowRace extends AbstractHuman{
}
真实的黄种人类,分为黄种男人和黄种女人。
黄种男人类:
package com.phl.design.abstractfactorypattern.bean;
public class YellowMale extends AbstractYellowRace {
void setGender(){
this.gender = "male";
}
@Override
void say() {
System.out.println("一个黄种男人");
}
}
黄种女人类:
package com.phl.design.abstractfactorypattern.bean;
public class YellowFemale extends AbstractYellowRace{
void setGender(){
this.gender = "female";
}
@Override
void say() {
System.out.println("一个黄种女人");
}
}
剩余没有展示的白种人,黑种人都是同样的形式。
这样,就把讲工厂方法模式的时候出现的人类没有性别的BUG进行了更改。这个更改过程里用到的,就叫做抽象工厂模式。
抽象工厂模式定义
Provide an interface for creating families of related or dependent objects without specifying their concrete classes.(为创建一组相关或相互依赖的对象提供一个接口,而且无须指定它们的具体类。)1
上面给出了抽象工厂模式的官方定义。仔细剖析这段话。这里有两个值得我们注意的内容。
- an interface for creating families…
这句话需要对比着去进行解读。在工厂方法模式中,抽象工厂类里只有一个用于构建对象的抽象方法,然后在具体的工厂类中进行方法的继承和实现。核心点在于那里面只有一个。但是在抽象工厂模式中,会有多个抽象方法用于对象的实例化。这是第一个区别。仔细想这次的例子中,抽象工厂中有三个抽象方法,跟别用于创建黄种人,白种人,黑种人。 - without specifying their concrete classes
无需指定他们的具体类。这个也是需要对比去理解。在工厂方法模式中,那个用于实例化的抽象方法中是需要传入具体类的Class对象。而在抽象工厂模式中,不需要传入具体的类,而是在方法实现时直接进行了实例化操作。
经过上面的定义和解读,让我们发现了在工厂方法模式与抽象方法模式中最大的区别。具体的类图如下:
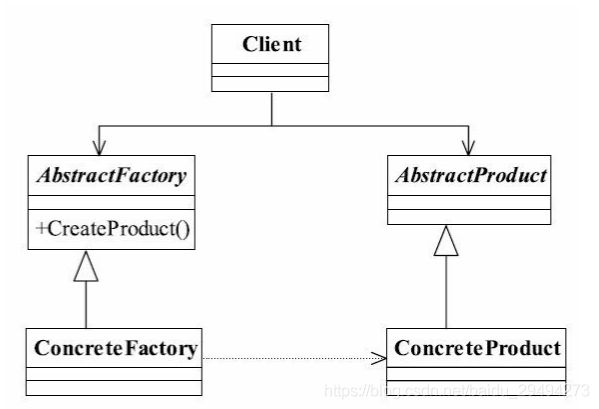 乍一看与工厂方法模式的通用类图一样,但是实际上这里的实例化方法中没有存在入参,并且因为这个图中只列举了一种产品的情况,因此抽象工厂里用于实例化对象的方法只有一个。如果有多种产品,就会有多个抽象方法与之对应。
乍一看与工厂方法模式的通用类图一样,但是实际上这里的实例化方法中没有存在入参,并且因为这个图中只列举了一种产品的情况,因此抽象工厂里用于实例化对象的方法只有一个。如果有多种产品,就会有多个抽象方法与之对应。
抽象工厂模式是工厂方法模式的升级版本,在有多个业务品种、业务分类时,通过抽象工厂模式产生需要的对象是一种非常好的解决方式。
现在根据给人类添加性别的这个例子讲解抽象工厂模式中涉及到的核心点。
产品族
在上面的定义中,出现了一个描述“创建一组。。。”,那么,什么是一组?
还是沿用女娲造人的例子,类比成实际的工厂。在实际的工厂里,每个工厂分为了多个车间,每个车间又包含了多个生产线。在女娲造人的例子中去看,FemaleFactory,专门生产女性,这个专门生产女性的车间里,提供了三个生产线,生产黄种人,白种人,黑种人。同样MaleFactory,专门生产男性的车间,里面同样也提供了三个生产线,生产黄种人,白种人,黑种人。
例子中类比成生产线的生产白种人,黄种人,黑种人的抽象方法因为他们都是用来造人的,因此称为产品族。
重点,对象族里,每多一种,就需要在抽象方法模式中多定义一个抽象方法用于这个产品族的实例化。
产品级
例子中有两个车间,FemaleFactory和MaleFactory,对应实际代码的两个具体的工厂类。在设计中,这样的车间成为产品级。
重点,每多一个产品级,就需要多一个具体的工厂类。
现在来回答一开始就抛出来的问题:为什么在设计的时候用性别当产品级(具体的工厂类)而不用人种当做产品级?
根据上面的定义可知,如果现在多了一个产品级,我只需要多一个工厂类即可。
但是如果现在多了一个产品族,那么需要做的就会跟多。首先,需要在抽象工厂中多一个抽象创造方法, 并在所有的工厂类中实现它,并且我需要创造新的具体产品类。
举个例子,在不考虑人类变异的前提下,我估计白种人,黄种人,黑种人已经囊括了世界上所有人的肤色大类。不容易出现更多颜色分类,因此这种稳定的因素更适合去当产品族。
但是性别,正常情况下人出生是男或者女。但是特殊情况下,有双性,或者一开始以为是女性,后来才发现自己是男性的。这种不太确定的因素,就适合当做产品级。因为比起产品族的增加,产品级的增加更轻便,更灵活。
抽象工厂模式的优点
- 封装性。每个产品的具体类不是高层模块关心的。高层模块在使用的时候连他的Class都不用关心。高层模块只需要关心接口(抽象类)。通过方法调用就能得到想要的内容,省事省力省心。
- 产品级内的约束是非公开状态。比如这三个产品族之间需要满足什么约定,比如创建任意一个女性,就需要多创建一个男性。那么这种约束完全可以通过工厂类进行实现,对于高层调用模块而言,他不需要进行直接的管控。
抽象工厂模式的缺点
抽象工厂模式最大的缺点就是对产品族的扩展。在扩展产品族的时候需要更改,新增很多地方。因此在最初设计的时候,就应该让那些实在是没什么变化的项当做产品族,容易变动的项成为产品级。
抽闲工厂模式的应用
它的使用场景定义非常简单:当存在了对象族,对象级的这种分类后,就可以使用抽象工厂模式。
抽象工厂模式的注意事项
重要的事情说三遍:更稳定的项当做对象族,容易变化的当做对象级。更稳定的项当做对象族,容易变化的当做对象级。更稳定的项当做对象族,容易变化的当做对象级。
模板方法模式
终于讲到了模板方法模式。为什么这么期待,因为这设计模式在我们日常工作中总是会用到,但是我们却不自知。这个设计模式的难度极低,应用极广,任何一个程序员都写过这样的代码,但是很少有人会知道这种写法居然是模板方法模式。通过这设计模式,能够让我们深刻的体会到设计模式本就不是什么阳春白雪,不神秘,不高不可攀。
我们用一个讲解继承时都会用到的例子进行讲解。设计两个汽车,让他们实现汽车应有的基本功能,不考虑任何其他复杂或者独特的汽车功能,只做到最基础实现。
现在假定这两个车分别是宝马3系和奥迪A4。那我们可以得出最简单的一个类图。
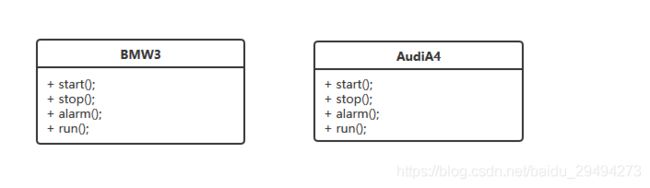
从上图里可以看出,不论是宝马还是奥迪,都包括了启动,停止,鸣笛,运行这四个基础方法。因为考虑到可能存在的扩展性,把这个类图抽象成如下类图:
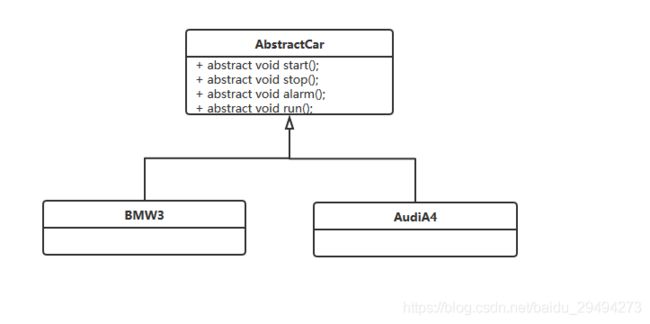
在上图中,考虑到系统的可扩展性,我们将宝马3系和奥迪A4的共同特性抽象成了一个AbstractCar这个抽象类。有了这一层抽象之后,以后要是在只考虑基础功能的情况下,进行拓展的时候只用多一个子类即可。
此时,各个类中的代码如下:
抽象汽车类:
package com.phl.demoone.designpattern.templatemethod;
public abstract class AbstractCar {
protected abstract void start();
protected abstract void stop();
protected abstract void alarm();
protected abstract void run();
}
宝马3系
package com.phl.demoone.designpattern.templatemethod;
public class BMW3 extends AbstractCar{
@Override
void start() {
System.out.println("宝马3启动");
}
@Override
void stop() {
System.out.println("宝马3停止");
}
@Override
void alarm() {
System.out.println("宝马3鸣笛");
}
@Override
void run() {
this.start();
this.alarm();
this.stop();
}
}
奥迪A4:
package com.phl.demoone.designpattern.templatemethod;
public class AudiA4 extends AbstractCar {
@Override
void start() {
System.out.println("奥迪A4启动");
}
@Override
void stop() {
System.out.println("奥迪A4停止");
}
@Override
void alarm() {
System.out.println("奥迪A4鸣笛");
}
@Override
void run() {
this.start();
this.alarm();
this.stop();
}
}
从上面的例子可以看出来,同样的run代码出现了两个相同的实现。针对这个情况,我们对类图进行了如下修改:
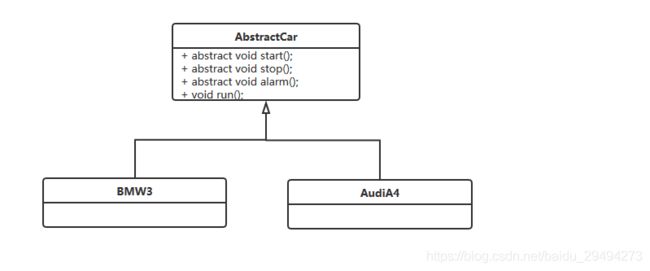 根据类图的修改,抽象类中的run方法不再是抽象方法,而是一个具体的方法了。此时,抽象类AbstractCar的代码如下:
根据类图的修改,抽象类中的run方法不再是抽象方法,而是一个具体的方法了。此时,抽象类AbstractCar的代码如下:
package com.phl.demoone.designpattern.templatemethod;
public abstract class AbstractCar {
protected abstract void start();
protected abstract void stop();
protected abstract void alarm();
final void run() {
this.start();
this.alarm();
this.stop();
}
}
在BWM3和AudiA4的类中不再重写和实现run方法。
截止现在,这个例子讲解完了。
难吗?一点都不难,对吧。这个例子的写法叫做什么呢?这个就是模板方法模式。
模板方法模式定义
Define the skeleton of an algorithm in an operation,deferring some steps to subclasses.Template Method lets subclasses redefine certain steps of an algorithm without changing the algorithm’s structure.(定义一个操作中的算法的框架,而将一些步骤延迟到子类中。使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。)1
从定义中,我们就可以高度抽象出模板方法模式的精髓:将一些步骤延迟到子类中(通过abstract)。使得子类可以不改变一个算法的结构(例子中的run方法)就可以重新定义该算法的某些特定步骤。
模板方法模式的共用类图如下:
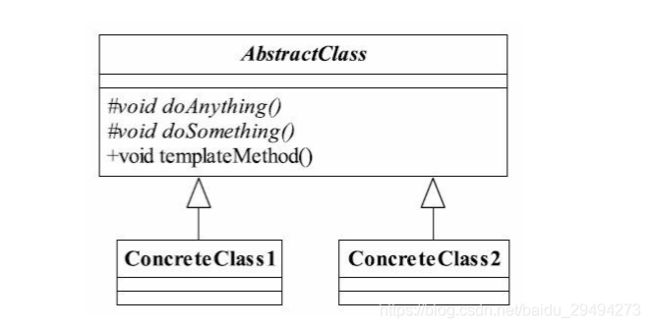 模板方法模式非常简单,内里只使用了Java的继承机制,但它是一个应用非常广泛的模式。其中AbstractClass成为抽象模板。在抽象模板里的方法可以分为两类:
模板方法模式非常简单,内里只使用了Java的继承机制,但它是一个应用非常广泛的模式。其中AbstractClass成为抽象模板。在抽象模板里的方法可以分为两类:
- 基本方法
基本方法也就叫做基本操作,就是在抽象模板中定义的抽象方法。这些方法最终会被子类实现,就是定义中说的,推迟到子类中的特殊操作。 - 模板方法
模板方法可以有一到多个,一般是一个具体的方法,但是也可以是一个框架,实现了对于基本方法的调用,完成一套固定的逻辑。
注意为了避免恶意的更改或者其他不小心的更改,一般模板方法上都加上 final关键字,不允许被重写。
图中还有两个ConcreteClass,叫做具体模板。在具体模板中,实现了父类中定义的基本方法(也就是抽象方法),体现了固定逻辑中的特殊性。
注意抽象模板中的基本方法应该尽量设计为protected类型,符合迪米特法则。不需要暴露的属性或方法尽量不要设置为protected类型。实现类若非必要,尽量不要扩大父类中的访问权限。
模板方法的优点
- 封装不变的部分,拓展可变部分。
- 提供公共部分代码,便于维护。
- 具体执行逻辑由父类控制,子类提供具体实现。
模板方法模式的缺点
- 这种写法对于纯入门的人来说,比较复杂。因为一般我们在抽象类里不出现这种具体的方法。
模板方法模式的使用场景
- 多个子类有公共方法,并且逻辑基本相同。
- 重复,复杂的代码设计成模板方法,周边的相关细节由各个子类实现。
- 重构时,相同的代码提取到父类中,然后通过钩子方法(下面的扩展里讲)约束其行为。
模板方法模式的扩展
在介绍模板方法模式的过程里,我们用了车的例子,现在继续用这个例子继续讲解。
在这个例子中,汽车是启动,鸣笛,停止。这样三步走进行执行的。但是现在客户说,不希望宝马3系的车鸣笛,要把宝马三系的逻辑变成启动,停止。
那么现在的类图就有了如下改变:
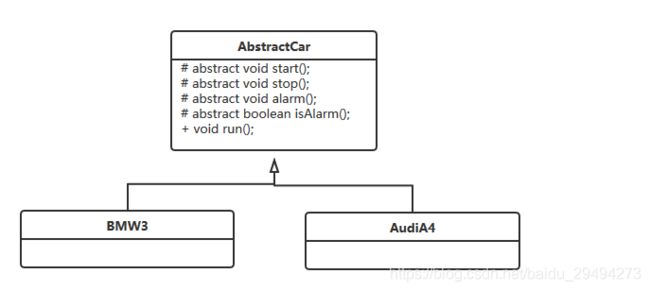
经过变形,我们会发现基本方法中多了一个返回boolean的方法isAlarm。此时的抽象模板类代码变成了下面的情况:
package com.phl.demoone.designpattern.templatemethod;
public abstract class AbstractCar {
protected abstract void start();
protected abstract void stop();
protected abstract void alarm();
protected abstract boolean isAlarm();
protected final void run() {
this.start();
if (this.isAlarm())
this.alarm();
this.stop();
}
}
在我们的抽象类中isAlarm的返回值就是影响了模板方法的执行结 果,该方法就叫做钩子方法(Hook Method)。通过这样的钩子方法,实现了固定逻辑的多样化。
建造者模式
序模板方法模式的例子进行讲解。在模板方法模式中,我们创建宝马3系和奥迪A4这两款车。并且在通用父类中定义了统一的模板方法。虽然在模板方法中使用了钩子方法对模板方法内的执行顺序进行了自定义,但是存在一个很显著的问题。这个问题就是模板方法中的执行顺序无法自定义。所谓的无法自定义是指,不够灵活,无法按照不同的需求进行不同的订制。这个过程里的顺序一旦发生更改,那么对于模板方法模式而言,就需要修改模板方法的源代码。因此针对这个问题,提出了如下解决方法。
既然要模板方法能够按照需求的定义顺序来执行,那至少需要一个变量来存储需求中提出的执行顺序。
package com.phl.demoone.designpattern.builder;
import java.util.ArrayList;
public abstract class AbstractCar {
//存储操作顺序名称的list
private ArrayList<String> list = null;
protected abstract void start();
protected abstract void stop();
protected abstract void alarm();
public final void run(){
this.list.stream().forEach(x->{
if (x.equalsIgnoreCase("start")){
this.start();
}
if (x.equalsIgnoreCase("stop")){
this.stop();
}
if (x.equalsIgnoreCase("alarm")){
this.alarm();
}
});
}
//给 this.list赋上定义好操作顺序的list
public final void setSequence(ArrayList<String> list){
this.list = list;
}
}
上述代码中,与模板方法模式而言,存在两处明显变化。
-
run()方法
在run方法中,没有固定的执行逻辑,也没有通过钩子方法进行流向控制。这个新的run方法中,是对list进行循环,之后按照list中定义好的操作名称去调用名称对应的方法。 -
Arraylist
这个抽象类中多了一个私有属性list,用于保留自定义的操作序列。 -
setSequence()方法
定义好操作序列之后,通过这个方法赋值给list变量。
通过上述变形,抽象类AbstractCar已经具备了按照需求的执行顺序执行的能力。此时的类图就变成了:
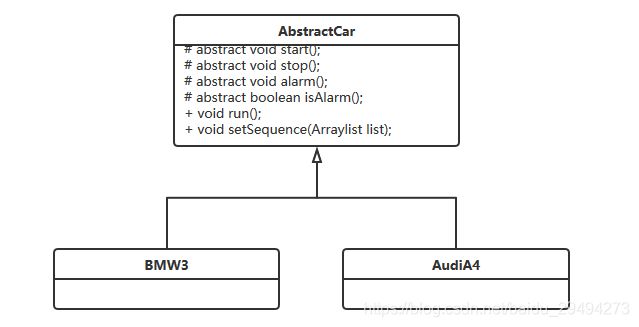 此时与模板方法模式比较,没有太过明显的变化。下面是调用的测试代码:
此时与模板方法模式比较,没有太过明显的变化。下面是调用的测试代码:
package com.phl.demoone.designpattern.builder;
import java.util.ArrayList;
public class CarTest {
public static void main(String[] args) {
BMW3 bmw3 = new BMW3();
ArrayList<String> opList = new ArrayList<>();
opList.add("start");
opList.add("stop");
opList.add("alarm");
bmw3.setSequence(opList);
bmw3.run();
}
}
这么写之后,我已经可以让车子按照需求定义的顺序进行执行。可是这么写了之后有出现了新的问题。现在的宝马车是按照启动,停止,鸣笛的顺序执行。如果第二个变成了鸣笛,启动。第三个是鸣笛,第四个是启动,停止。这种情况下,应对每个情况都需要定义序列,生成对象,对象与序列绑定。总是这么做太过麻烦。并且,假设上面说的四种型号的宝马车需要批量生产,那上面说到的三个步骤就需要进行批量执行,越想这样的代码设计就越糟糕。
应对这种情况,就引出了建造者模式。建造者模式落在这个例子里的体现就是,我们生成一个建造者,然后告诉建造者我们现在的执行顺序,之后由建造者给我们生成对象,对象与序列绑定,并最终把这个对象返回给我们。经过建造者的封装,整个过程就变得更简洁了。
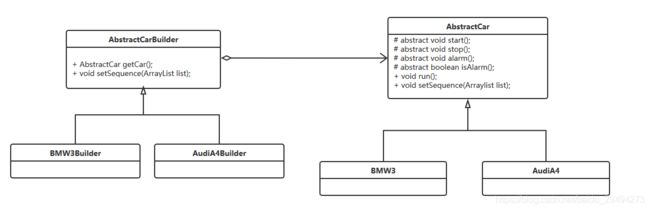
上面就是引入了建造者类的类图。抽象建造者类里提供了获取对象的getCar方法,也提供了绑定序列的方法。在实际使用中,根据不同的建造者类进行对象的初始化和对象与执行顺序绑定。这里使用BMW3Builder代码进行具体演示:
package com.phl.demoone.designpattern.builder;
import java.util.ArrayList;
public class BMW3Builder extends AbstractBuilder {
private BMW3 bmw3 = new BMW3();
@Override
protected AbstractCar getCar() {
return this.bmw3;
}
@Override
protected void setSequence(ArrayList<String> list) {
this.bmw3.setSequence(list);
}
}
这样在调用的时候,只需要实例化一个BMW3Builder出来,定义好操作序列,然后把操作序列通过Builder提供的setSequence进行对象与序列绑定。正确创建了BMW3实例会通过getCar方法进行返回。
代码如下:
package com.phl.demoone.designpattern.builder;
import java.util.ArrayList;
public class CarTest {
public static void main(String[] args) {
ArrayList<String> opList = new ArrayList<>();
opList.add("start");
opList.add("stop");
opList.add("alarm");
BMW3Builder bmw3Builder = new BMW3Builder();
bmw3Builder.setSequence(opList);
AbstractCar car = bmw3Builder.getCar();
car.run();
}
}
通过这种写法,每次进行新实例化的时候只是实例化建造者。写成这样之后,其实从代码简洁性而言,多出来的这个Builder并没有直接去实例化BMW3来的更简单直接。并且目前写成这样,对于已经存在的问题并不算完美解决。因为这个过程里对新来的需求只能通过更改代码进行解决,无法预设好很多种有可能存在的执行顺序。那么,再往下深挖一下。假设有一个更高层的对象,这层对象是用来控制建造者的,起到指挥的作用。通过这个更高层次的介入,可以进行多种执行模式的预设,对外展现出来的效果就好像是顾客提出什么要求,我们都能立马生成好对应的产品。
有了高层介入之后的类图:
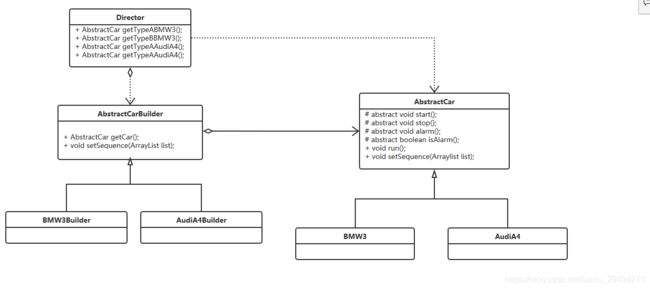
新引入的类称为导演类,这个类中预设了4个方法,两两成对,分别用来实例化BMW3和AudiA4。
代码如下所示,注意代码中仅写了BMW3的实现,AudiA4的是一样的,所以没有重复写:
package com.phl.demoone.designpattern.builder;
import java.util.ArrayList;
public class Director {
private ArrayList<String> opList = new ArrayList<>();
public AbstractCar getTypeABMW3(){
this.opList.clear();
BMW3Builder bmw3Builder = new BMW3Builder();
this.opList.add("start");
this.opList.add("stop");
this.opList.add("alarm");
bmw3Builder.setSequence(this.opList);
return bmw3Builder.getCar();
}
public AbstractCar getTypeBBMW3(){
this.opList.clear();
BMW3Builder bmw3Builder = new BMW3Builder();
this.opList.add("start");
this.opList.add("alarm");
this.opList.add("stop");
bmw3Builder.setSequence(this.opList);
return bmw3Builder.getCar();
}
}
定义好Director导演类之后,在调用的时候进行这样操作即可。
package com.phl.demoone.designpattern.builder;
public class CarTest {
public static void main(String[] args) {
Director director = new Director();
director.getTypeABMW3().run();
}
}
这样最终暴露出来的结果是不是非常简洁了?
仔细想想这个过程。
上述变形过程文字描述
首先是需求提出,要求我们的产品可以根据用户提出的运行顺序进行运行。
因此对于模板方法模式的写法中,更改了run的逻辑,并且定义了一个List用来接收运行顺序的信息。除过这个之外,还增加了一个setSequence的模板方法。
经过这个更改之后,就可以每次创建一个实例(以BMW3系为例),定义执行list,然后setSequence,最后将绑定好执行信息的BMW3执行run()方法。
然后为了能把整个实例化BMW3实例的过程进一步封装,提出了Builder这样的抽象类。抽象类中提供了两个方法,分别是返回AbstractCar类型的汽车实例,另一个方法是setSequence绑定操作序列到对象实例上。有了这样的抽象Builder之后,再根据产品类型配上相应的实现类。就可以在实例化的过程里不直接调用产品本身(BMW3)的构造器。这么做已经算是降低耦合度,因为在实际调用的业务代码中已经不会出现调用产品本身的地方。
但是现在还是有不足,就是没有办法预存各种各样可能的执行循序,继而无法做到客户一旦提出新的功能顺序,我们就能直接提供给客户,只能在客户提出之后,进行代码的修改,然后才能提供给客户。因此我们现在又在Builder的上面抽象出了一层新的对象,Director。
有个Director之后,在Director中有了很多预存的方法,这些方法中预设了各式各样可能的执行顺序,有了这样的预设,就可能实现客户一提出要求,我们就直接把产品提供给他们。
这样的最终的类图,就是本节要讲解的建造者模式,通过这个造车的例子,一步一步把我们从模板方法模式变形到了建造者模式。
建造者模式的定义
建造者模式(Builder Pattern)也叫做生成器模式,其定义如下:
Separate the construction of a complex object from its representation so that the same construction process can create different representations.(将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。)1
建造者模式的万金油写法
通过对上述定义的解读,以及对刚才例子的体会,我们得到了如下通用类图:
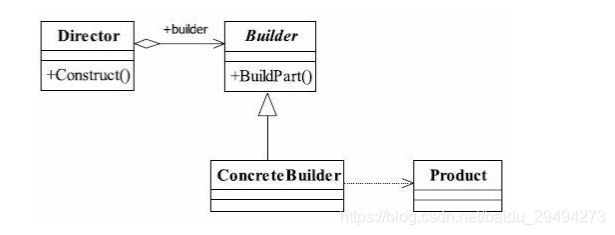 上述类图中出现了四个对象。
上述类图中出现了四个对象。
-
Product,产品类。
通常是实现了模板方法模式,也就是有模板方法和基本方法。注意,对于建造者模式而言,从定义中可以看出来它做的事情是对复杂事物的实例化,并且实例化之后还要给他提供各种各样的表示(representation),所谓的表示就类似于我们例子中提到的自定义的操作顺序。强调这个过程是为了说明,一般情况下建造者模式都是与模板方法模式连用的。而这里说的产品类,正式模板方法模式中的抽象父类的子类实现。 -
Builder,抽象建造者类
规范产品的组建,一般是由子类实现。 -
ConcreteBuilder,建造者实现类。
就好比例子中的BMW3Builder类,他就是继承了AbstractBuilder类,并对getCar和setSequence方法做了具体实现。 -
Director导演类
导演类中要做的事情就是对可能被客户提出的多种运行情况进行预设。所谓的预设,就是把这些可能的结果定义在不同的方法中。通过不同的方法调用,最终返回了各式各样的运行情况的实例。
建造者模式的优点
- 封装性
- 产品,建造者之间独立,易于扩展
- 便于控制细节风险
因为建造者之间都是独立的,因此各个建造者可以独自逐步优化,不会影响到其他地方。
建造者模式的使用场景
- 类似例子中,相同的方法,相同的对象,但是想要实现不同的顺序,不同的结果,可以采用建造者模式
- 多个零部件都可以装配到一个对象中,但是产生的运行结果又不相同,可以采用建造者模式
- 产品类本身非常复杂, 或者产品类中的调用顺序不同产生了不同的效能,这时更适合用建造者模式
建造者模式的注意事项
建造者模式关注的是零件类型和装配工艺(顺序),这是它与工厂方法模式最大不同的地方,虽然同为创建类模式,但是注重点不同。
代理模式
代理模式是一个非常常见,非常有知名度的设计模式。其实,说到代理模式,或者说代理,并不是一个复杂的词汇,作为一个网民,最常见的代理就是游戏代练。我把自己的账号交给游戏工作室,由他们来帮我冲级,并且在这个过程里我支付相应金额。
现在借由这个过程我们抽象并讲解代理模式。
首先,在不找代练的情况下,我们玩游戏需要自己登陆,练级。这个过程可以抽象成下面这样的类图。
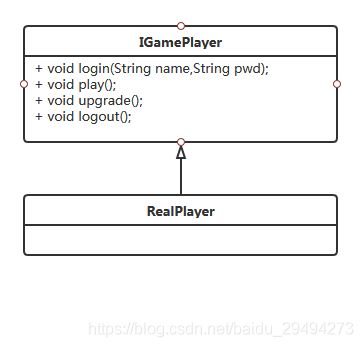 上述类图是描述了我作为一个真实的玩家,实现了游戏提供的多个接口,包括登录,玩游戏,升级,登出这四个基本方法。通过这四个方法,就能模拟出最基本的游戏玩法。
上述类图是描述了我作为一个真实的玩家,实现了游戏提供的多个接口,包括登录,玩游戏,升级,登出这四个基本方法。通过这四个方法,就能模拟出最基本的游戏玩法。
此时,我接入了游戏代练,上面的类图就发生了新的变化。
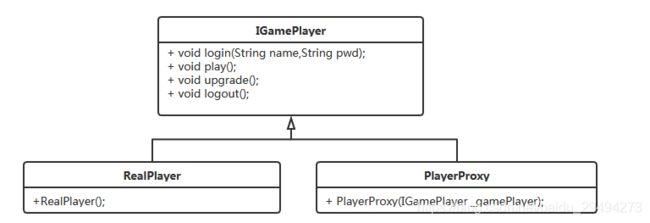
此时,我们多了一个游戏代练的类PlayerProxy,和真实玩法一样,游戏代练也需要实现IGamePlayer接口。
在代理类中,通过公开的构造方法传入一个IGamePlayer对象,表示游戏工作室要对哪个真实玩家进行代练。现在把接口和代理类的代码贴出来。
接口:
package com.phl.design.proxy;
public interface IGamePlayer {
void login(String name,String pwd);
void play();
void upgrade();
void logout();
}
代理类:
package com.phl.design.proxy;
public class PlayerProxy implements IGamePlayer {
private IGamePlayer _gamePlayer;
public PlayerProxy(IGamePlayer _gamePlayer) {
this._gamePlayer = _gamePlayer;
}
@Override
public void login(String name, String pwd) {
this._gamePlayer.login(name,pwd);
}
@Override
public void play() {
this._gamePlayer.play();
}
@Override
public void upgrade() {
this._gamePlayer.upgrade();
}
@Override
public void logout() {
this._gamePlayer.logout();
}
}
在代理类里,提供了一个有参构造方法。根据这个方法实例化出来的代理类就实现了代理与真实对象的关联。并且在代理类的方法实现中可以看到,真正操作的是传入的真实玩家。这样就实现了最初的设想,通过游戏代练给自己练级。
代理模式的定义
代理模式的定义很直白,下方就是代理类的定义。
Provide a surrogate or placeholder for another object to control access to it.(为其他对象提供 一种代理以控制对这个对象的访问。)1
代理模式的通用类图:
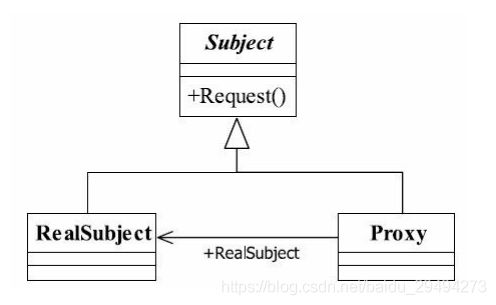
代理模式也叫做委托模式,它是一项基本设计技巧。许多其他的模式,如状态模式、策略模式、访问者模式本质上是在更特殊的场合采用了委托模式,而且在日常的应用中,代理模式可以提供非常好的访问控制。1上面类图中包含了三个主体,下面对这三个主体进行介绍。
-
Subject,抽象主题
抽象主题类可以是抽象类也可以是接口。它代表了一组抽象的业务方法,并且这些方法要被具体的主题进行实现。 -
RealSubject,真实主题
RealSubject,实现Subject中定义的多个业务抽象业务方法。RealSubject也称为被代理者,是业务逻辑的具体执行这。 -
Proxy,代理
代理类也实现了抽象主题中的所有方法。并且在代理类中需要传入一个真实主题,通过传入的真是主题把代理类和真实主题结合在一起。注意, 在代理类中,可以在真实主题执行前,执行后增加预处理和善后处理。
代理模式万金油写法
万金油的代码写法如下。
抽象主题:
package com.phl.design.proxy;
public interface AbstractSubject {
void request();
}
具体主题:
package com.phl.design.proxy;
public class RealSubject implements AbstractSubject {
@Override
public void request() {
System.out.println("RealSubject request");
}
}
代理类,这个代理类中也出现了预处理和善后操作:
package com.phl.design.proxy;
public class Proxy implements AbstractSubject {
private AbstractSubject _realSubject;
public Proxy(AbstractSubject _realSubject) {
this._realSubject = _realSubject;
}
public void before(){
System.out.println("before-----");
}
@Override
public void request() {
this.before();
this._realSubject.request();
this.after();
}
public void after(){
System.out.println("after-----");
}
}
上述就是代理模式的万金油写法。
代理模式的优点
- 职责清晰
- 扩展性高
- 智能化,这个特性暂时没有体现出来,会在后续的动态代理部分体现出来。
代理模式的使用场景
代理模式的应用场景很宽泛。因为预处理和善后处理的存在,代理模式使的我们对于业务方法只需要关注在业务本身,其他内容都可以在代理中实现,而不用杂糅在真实业务方法中。
代理模式的扩展
在使用网络代理服务器的时候,可以分为普通代理和透明代理。其中普通代理需要用户知道代理服务器的地址,进行配置。透明代理则不需要配置代理服务器地址,也就是说代理服务器对用户来说是透明的,不用知道它存在的。
在设计模式中,普通代理和强制代理也是这样的关系。
普通代理下,需要客户端(也就是调用的类)需要知道哪个是代理类,类似于知道PlayerProxy,才能进行剩下的操作,比如实例化,调用代理去执行业务方法等。
强制代理则不一样,强制代理在调用的时候是直接调用真实对象,不是调用代理对象。并且不用关心代理是否存在,其代理的产生是由真实对象决定的。
现在我们先从普通代理进行讲解。
普通代理
当我们站在调用方的角度去看问题时,我作为调用方,先实例化真实对象,然后把真实对象作为入参来实例了代理对象。最后再使用代理对象去执行相应业务方法。这个过程本质上是反复的,因为作为调用方,我已经都有了真实对象了,为什么必须要通过代理对象呢?
因此为了解决这种疑问,普通代理应运而生。
对于普通代理而言,有一个要求就是客户端只能调用代理对象,不能调用真实对象。确切说来,客户端并不清楚代理对象具体代理的是什么对象。在普通代理的情况下,代理模式的类图变成了如下样式:
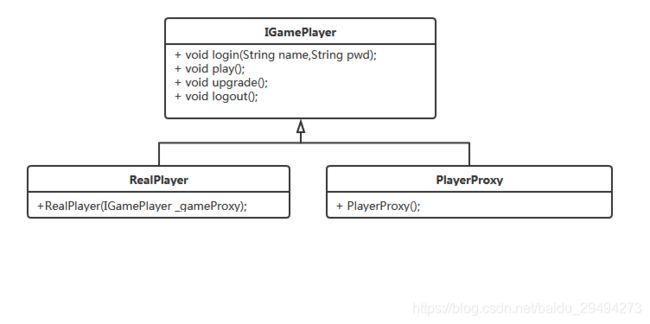
仔细看上面的类图,其中存在两处明显差异。
- PlayerProxy提供的构造方法变了。
普通代理的构造方法写成这个样子,想体现的意思就在于,对于调用者而言,你无法通过这个调用方法直观的了解到去代理哪个类。代理类在进行实例化的时候没有对应的真实对象参数。因此就不会再出现先实例化真实对象,后把真实对象传递给代理对象这种舍近求远的情况。 - RealPlayer构造方法变了。
在真实对象中,他的构造方法内部需要传入一个IGamePlayer类型的对象,这里其实是传入了接口对象。
代理类和真实对象代码如下:
真实对象:
package com.phl.design.proxy;
public class RealPlayer implements IGamePlayer {
public RealPlayer() {
}
public RealPlayer(IGamePlayer PlayerProxy) {
if (PlayerProxy != null){
new RealPlayer();
}
}
@Override
public void login(String name, String pwd) {
}
@Override
public void play() {
}
@Override
public void upgrade() {
}
@Override
public void logout() {
}
}
代理类:
package com.phl.design.proxy;
public class PlayerProxy implements IGamePlayer {
private IGamePlayer _gamePlayer;
public PlayerProxy() {
this._gamePlayer = new RealPlayer(this);
}
@Override
public void login(String name, String pwd) {
this._gamePlayer.login(name,pwd);
}
@Override
public void play() {
this._gamePlayer.play();
}
@Override
public void upgrade() {
this._gamePlayer.upgrade();
}
@Override
public void logout() {
this._gamePlayer.logout();
}
}
这样写了之后,在初始化代理类的时候,不会再有先实例化具体对象的这一步。这就是普通代理模式。
在该模式下,调用者只知代理而不用知道真实的角色是谁,屏蔽了真实角色的变更对高层模块的影响,真实的主题角色想怎么修改就怎么修改,对高层次的模块没有任何的影响,只要你实现了接口所对应的方法,该模式非常适合对扩展性要求较高的场合。
强制代理模式
强制代理模式在设计模式中比较另类。一般的思维都是通过代理类去操作真实对象,但是强制代理却是要 “强制”,必须通过真实对象找到代理对象,否则不能访问。不论是通过代理类,或者是直接new了一个真实对象,都不能访问。只能通过真实对象指定的代理类才能访问。
在普通代理模式中,当new了一个代理类的时候,实际内里是new了一个真实对象。
在强制代理模式中,高层模块new了一个真实对象,返回的却是一个代理角色。套用书上的例子,我和某个明星很熟悉,然后我想托他帮个忙。就给他打电话了,电话那头他说,行,这事儿我知道了,你找我经纪人吧。是不是很郁闷,本身我是想绕过代理,直接让真实对象帮我忙,结果真实对象给我强制指定了一个代理对象。从这个场景就表述出来,不论是我直接找代理对象(此时他不知道真实对象已经同意了),或者我找真实对象(他虽然同意,但是他不亲自帮我做事儿),都没法执行我想要执行的内容。唯一是通过真实对象,他会给我指定一个代理对象,然后才能让事情正常执行下去。
强制代理模式的类图如下所示:
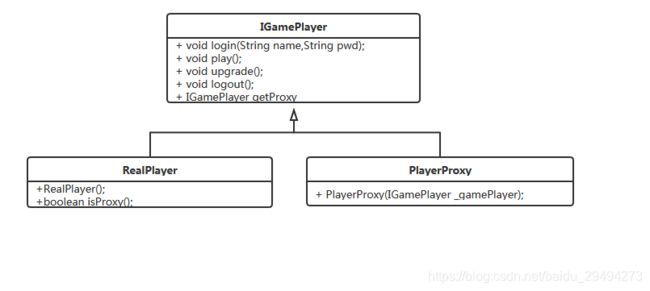
值得注意的是,在强制代理模式中,抽象接口中多了一个方法getProxy,真实对象通过这个方法返回指定的代理类。同时,在真实对象和代理对象里提供的构造方法也不再是普通代理模式里面的写法,反而变成了万金油写法的样式。即在创建代理对象的时候需要传入真实对象进行绑定。
抽象接口代码如下:
package com.phl.design.proxy;
public interface IGamePlayer {
void login(String name,String pwd);
void play();
void upgrade();
void logout();
IGamePlayer getProxy();
}
真实对象类的代码如下,注意里面的isProxy():
package com.phl.design.proxy;
public class RealPlayer implements IGamePlayer {
private IGamePlayer proxy = null;
public RealPlayer() {
}
@Override
public void login(String name, String pwd) {
if(!isProxy()){
System.out.println("请使用代理");
}else {
System.out.println("do something");
}
}
@Override
public void play() {
if(!isProxy()){
System.out.println("请使用代理");
}else {
System.out.println("do something");
}
}
@Override
public void upgrade() {
if(!isProxy()){
System.out.println("请使用代理");
}else {
System.out.println("do something");
}
}
@Override
public void logout() {
if(!isProxy()){
System.out.println("请使用代理");
}else {
System.out.println("do something");
}
}
@Override
public IGamePlayer getProxy() {
this.proxy = new PlayerProxy(this);
return this.proxy;
}
public boolean isProxy(){
if (this.proxy != null)
return true;
return false;
}
}
代理类的代码如下:
package com.phl.design.proxy;
public class PlayerProxy implements IGamePlayer {
private IGamePlayer _gamePlayer;
public PlayerProxy(IGamePlayer _gamePlayer) {
this._gamePlayer = _gamePlayer;
}
@Override
public void login(String name, String pwd) {
this._gamePlayer.login(name,pwd);
}
@Override
public void play() {
this._gamePlayer.play();
}
@Override
public void upgrade() {
this._gamePlayer.upgrade();
}
@Override
public void logout() {
this._gamePlayer.logout();
}
@Override
public IGamePlayer getProxy() {
return this;
}
}
通过代码的对比
在普通代理模式里面,是将新建的真实对象返回给代理对象,这样在初始化代理对象的时候就不需要暴露出真实对象,而是凭借代理对象就能进行各种操作。
在强制代理模式下,每一个真实对象无法通过自身,或者通过代理对象直接进行操作。因为在真实对象的每个操作中都执行了isProxy()的判断。
public boolean isProxy(){
if (this.proxy != null)
return true;
return false;
}
这个判断很简单,就是看真实对象中有没有指定自己的代理。如果没有,则不允许执行。如果有,则可以执行。
也就是说不论是new一个RealPlayer,或者new一个PlayerProxy都无法直接执行。只能在new了RealPlayer之后,通过它里面的getProxy()方法返回了指定的代理才可以进行操作。
多样性代理
在上面所说的不论是万金油写法,还是普通代理模式,强制代理模式,我们一开始都在模拟网游代练的场景。现在通过这三种方式工作室已经可以帮我们升级了,但是有一个大BUG一直没有解决。工作室帮我们做了这么多,我们与工作室之间怎么结算呢?
在Java中,一个类可以实现多个接口。接口的多样性在这里就可以体现出代理的多样性。
首先,我们把整个过程回退到万金油写法,万金油类图如下:
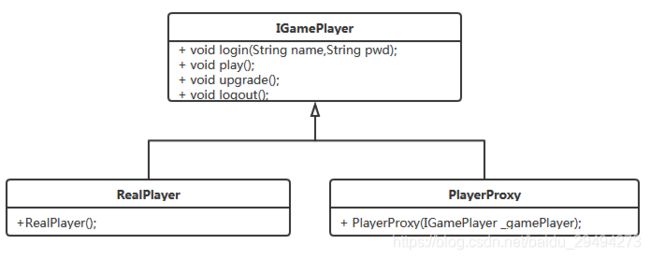 现在就只是有了代练,然后我们要在玩家和代练之间添加支付的方法。
现在就只是有了代练,然后我们要在玩家和代练之间添加支付的方法。
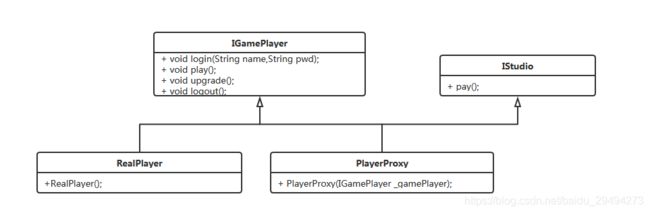 什么叫代理的多样性?通过这个图希望有有个直观的解答。在这个过程里,代理类除了实现了真实的游戏业务接口,同时也实现了自己的工作室接口,工作室接口中有了一个pay的方法。通过这个方法,我们可以在代理类中执行到某个地方(比如到了约定的级别)支付给工作室相应的金额。
什么叫代理的多样性?通过这个图希望有有个直观的解答。在这个过程里,代理类除了实现了真实的游戏业务接口,同时也实现了自己的工作室接口,工作室接口中有了一个pay的方法。通过这个方法,我们可以在代理类中执行到某个地方(比如到了约定的级别)支付给工作室相应的金额。
动态代理
终于写到了动态代理。对于动态代理而言,我们在日常工作中经常使用,比如Spring框架中实现AOP就是通过动态代理实现的。那,什么是动态代理呢?
在之前提到的代理模式的例子中,不论是代理模式的万金油写法,或者是后面扩展出来的普通代理模式,强制代理模式,我们在使用他们的时候都是自己编写代理类。这样的实现形式称之为静态代理。反之,动态代理在实现阶段不关心代理谁,而是在运行阶段才制定代理哪一个对象。
还是以网游代练为例,看看动态代理中的网游代练是怎么实现的。
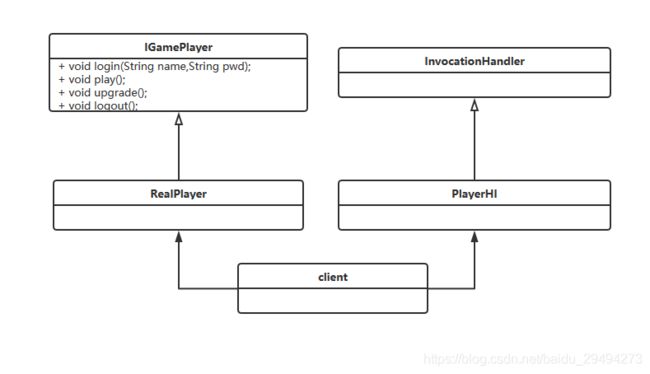 在类图里增加了一个InvocationHandler的接口和PlayerHI类,作用是产生一个对象的代理对象,其中InvocationHandler就是JDK提供的动态代理接口(这里使用JDK动态代理为例,也可以用CGLIB)。PlayerHI代码如下:
在类图里增加了一个InvocationHandler的接口和PlayerHI类,作用是产生一个对象的代理对象,其中InvocationHandler就是JDK提供的动态代理接口(这里使用JDK动态代理为例,也可以用CGLIB)。PlayerHI代码如下:
package com.phl.demoone.designpattern.dynamicproxy;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class PlayerHI implements InvocationHandler {
//被代理的类
Class clazz = null;
//被代理的实例
private Object obj;
//构造方法
public PlayerHI(Object _obj) {
this.obj = _obj;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = method.invoke(this.obj, args);
return result;
}
}
在上面的代码例子中,代理类实现了InvocationHandler接口,并且实现了invoke方法。在PlayHI类中,通过构造方法传入了要被代理的对象。
整个invoke方法是通过Java的反射机制,使用了method.invoke(obj,args)。第一个参数是被发射的对象,第二个参数是当前方法的入参,result是method的执行结果,进行返回。
关于整个method,其实吧,这个method并不是特指某个方法,而是通过反射机制拿到的,所有要被代理的接口里的方法。然后会根据调用情况,在这里进行invoke操作。
如何调用基于JDK提供的动态代理,代码如下:
package com.phl.demoone.designpattern.dynamicproxy;
import java.lang.reflect.Proxy;
public class Client {
//在main方法里实现动态代理的调用
public static void main(String[] args) {
//创建一个玩家
RealPlayer player = new RealPlayer("张三","pwd123");
//创建一个Handler。注意一点,虽然PlayerHI实现了InvocationHandler,但是它不是代理类,它是一个处理器(Handler)
PlayerHI playerHI = new PlayerHI(player);
//获取类加载器
ClassLoader loader = player.getClass().getClassLoader();
//这一步是真正生成代理对象的。方法中有三个参数。
/*
* loader:类加载器;
* new Class[]{IGamePlayer.class}:要引入的代理类的接口列表。其实这个参数也有多种写法。
* 比如,这里要代理的实际上是player对象,那么就可以用player.getClass().getInterfaces(),同样可以起到上述作用。
* 不过,当player中实现了多个接口时,我更习惯这种手动指定的形式。
* playerHI:针对Player这个要被代理的对象所定义的处理器。
* */
IGamePlayer proxyInstance = (IGamePlayer)Proxy.newProxyInstance(loader,new Class[]{IGamePlayer.class}, playerHI);
//proxyInstance,这个才是正儿八经的代理对象。
proxyInstance.login(player.getName(),player.getPwd());
proxyInstance.play();
proxyInstance.upgrade();
proxyInstance.logout();
}
}
运行结果如下图:
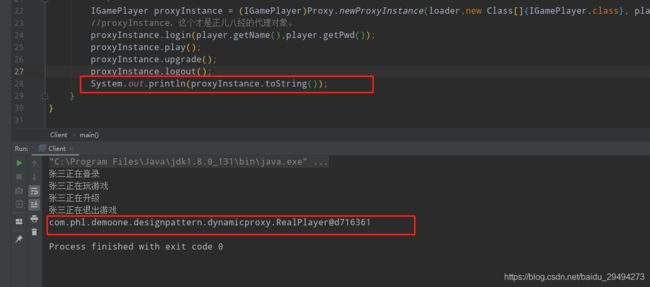
细看上面所有东西,不论是之前的万金油写法,普通代理模式还是强制代理模式,都要求代理类需要实现业务接口IGamePlayer。但是在动态代理中,并不存在这种情况。
之前那些写法中,通过在实例化代理类或者实例化真实对象的时候,建立代理类与这是对象的关联,最终代理类里操作的总是真实对象。
动态代理中,是通过Proxy类里的newProxyInstance()生成了代理对象,被代理的接口是通过一个Class[] 数组对象进行传递。最后被代理的方法在执行时也是通过反射机制,传入的待执行方法的实例,和待执行方法的入参。
**注意**由于我个人博客编写顺序问题,针对这AOP和更常见,更棒的动态代理不在这里讲解。而是会写到大家最熟悉的Spring中去。因此对于动态代理的解释,在这里就停止了。后续写到Spring的时候,会把博文地址扔过来。
原型模式
也许我们对原型模式这个名词有些陌生,但是我们都接触过原型模式的产物。仔细想一想我们平时生活里收到的各类广告邮件,广告短信,他们都是通过统一的模板(应对不同场景,会有不同的模板进行选用)和个性化信息(从数据库中抓出来,用于替换类似于XX先生,XX女士这样的地方)拼接成了我们最终收到的邮件或者短信。而在生成邮件,短信的过程就成为原型模型。
现在用生成广告邮件的整体过程为例,逐步迫近去讲解原型模式。
为了实现邮件的创建,我们定义了Mail类和MailTemplate类。类图关系如下:
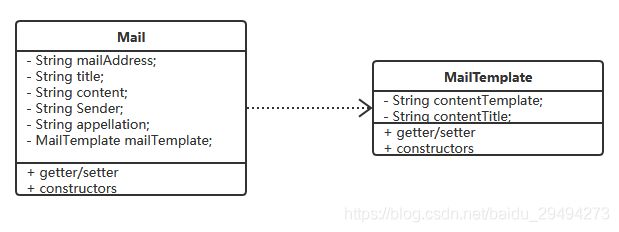 类中只是定义了基础的属性,getter/setter,各式各样的构造函数。
类中只是定义了基础的属性,getter/setter,各式各样的构造函数。
Mail类代码
package com.phl.design.prototypepattern;
public class Mail {
private String mailAddress;
private String title;
private String content;
private String Sender;
private String appellation;
private MailTemplate mailTemplate;
public Mail() {
}
public Mail(MailTemplate mailTemplate) {
this.mailTemplate = mailTemplate;
this.content = this.mailTemplate.getContentTemplate();
this.title = this.mailTemplate.getContentTitle();
}
public Mail(String mailAddress, String title, String content, String sender, String appellation, MailTemplate mailTemplate) {
this.mailAddress = mailAddress;
this.title = title;
this.content = content;
Sender = sender;
this.appellation = appellation;
this.mailTemplate = mailTemplate;
}
public MailTemplate getMailTemplate() {
return mailTemplate;
}
public void setMailTemplate(MailTemplate mailTemplate) {
this.mailTemplate = mailTemplate;
}
public String getMailAddress() {
return mailAddress;
}
public void setMailAddress(String mailAddress) {
this.mailAddress = mailAddress;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getSender() {
return Sender;
}
public void setSender(String sender) {
Sender = sender;
}
public String getAppellation() {
return appellation;
}
public void setAppellation(String appellation) {
this.appellation = appellation;
}
}
MailTemplate类代码:
package com.phl.design.prototypepattern;
public class MailTemplate {
private String contentTemplate;
private String contentTitle;
public MailTemplate(String contentTemplate, String contentTitle) {
this.contentTemplate = contentTemplate;
this.contentTitle = contentTitle;
}
public MailTemplate() {
}
public String getContentTemplate() {
return contentTemplate;
}
public void setContentTemplate(String contentTemplate) {
this.contentTemplate = contentTemplate;
}
public String getContentTitle() {
return contentTitle;
}
public void setContentTitle(String contentTitle) {
this.contentTitle = contentTitle;
}
}
有了这两个类之后,我们在定义一个client,在client中实现具体生成邮件和发送邮件的过程。
此时,类图就会变成下面这个样子:
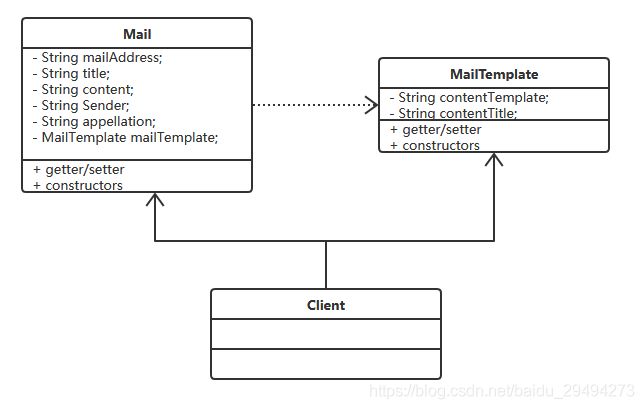 client代码如下:
client代码如下:
package com.phl.design.prototypepattern;
public class Client {
//定义一个属性,表示要发送多少份
public static Integer MAX_COUNT = 10;
public static void main(String[] args) {
//生成邮件模板
MailTemplate template = new MailTemplate("XXXXX","XX银行 国庆黄金周抽奖(AD)");
//生成邮件
for (Integer i = 0; i < MAX_COUNT; i++) {
Mail mail = new Mail(template);
mail.setSender("[email protected]");
//这里并没有通过随机字符串的生成来模拟不同的收件地址,比较懒。
mail.setMailAddress(i+ "@xx.com");
//这里并没有随机选择先生/女士,比较懒。
mail.setAppellation("xx"+i+"先生");
sendMail(mail);
}
}
private static void sendMail(Mail mail) {
System.out.println("发送邮件 :: " + mail.getAppellation() + ",地址是 " + mail.getMailAddress());
}
}
通过这样的操作,我们就算是实现了邮件的生成和发送。
但是这里存在一个明显的问题。假设,这个银行里能收到这个邮件的人有500万人,需求要求是在国庆前一天统一进行发送。那此时就会出现性能问题。因为在这个过程里需要从库中查询出500万人的信息,假设查库的开销是固定的,假设整个过程耗时0.02秒(包括查库,写入数据,发送)出现的情况是,24小时内,无法发送完所有的邮件。
因为我们现在是单线程在进行操作,那我们可以把整个过程做成多线程。这样就压缩了IO阻塞的时间,提升了整体的效率。可以在进行多线程开发的时候,假设线程1启动并运行,但是还没发送,然后线程2开始执行,并且把mail对象的收件人和称谓进行了覆盖。此时就出现了我们说的线程不安全情况。当然,我们可以有很多种方法做到线程安全,比如同步方法,同步代码块,volatile关键字,JUC中的阻塞队列,或者通过ThreadLocal创建线程本地变量等。
下面,我们使用原型模式来解决上述线程不安全的情况。要用原型模式,需要把上述类图再次进行修改,修改之后的结果如下:
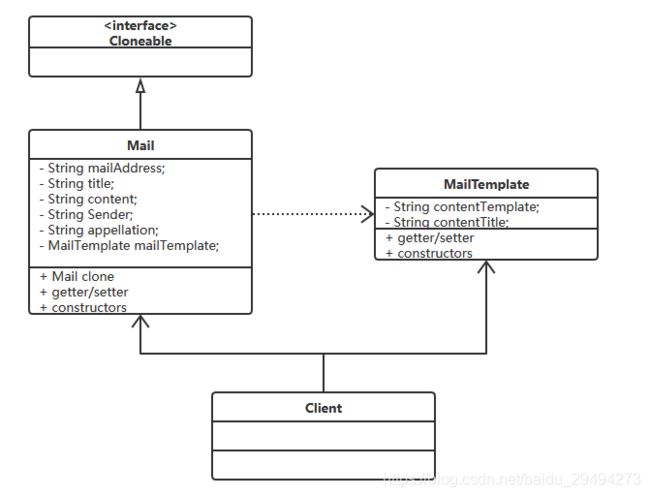 上图中,Mail类实现了Cloneable接口。Cloneable接口是java.lang包下提供的接口。这个接口中并没有任何方法。官方给出的解释是,一个类实现了cloneable接口,就指明他可以使用Object类中的clone方法。如果不实现这个接口,是无法使用clone方法的。
上图中,Mail类实现了Cloneable接口。Cloneable接口是java.lang包下提供的接口。这个接口中并没有任何方法。官方给出的解释是,一个类实现了cloneable接口,就指明他可以使用Object类中的clone方法。如果不实现这个接口,是无法使用clone方法的。
当实现了Cloneable接口之后,需要在实现类中重写clone方法,这样才能正常使用clone方法。
Mail类代码如下:
package com.phl.design.prototypepattern;
public class Mail implements Cloneable{
private String mailAddress;
private String title;
private String content;
private String Sender;
private String appellation;
private MailTemplate mailTemplate;
public Mail() {
}
@Override
public Mail clone() {
Mail mail = null;
try {
mail = (Mail) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return mail;
}
public Mail(MailTemplate mailTemplate) {
this.mailTemplate = mailTemplate;
this.content = this.mailTemplate.getContentTemplate();
this.title = this.mailTemplate.getContentTitle();
}
public Mail(String mailAddress, String title, String content, String sender, String appellation, MailTemplate mailTemplate) {
this.mailAddress = mailAddress;
this.title = title;
this.content = content;
Sender = sender;
this.appellation = appellation;
this.mailTemplate = mailTemplate;
}
public MailTemplate getMailTemplate() {
return mailTemplate;
}
public void setMailTemplate(MailTemplate mailTemplate) {
this.mailTemplate = mailTemplate;
}
public String getMailAddress() {
return mailAddress;
}
public void setMailAddress(String mailAddress) {
this.mailAddress = mailAddress;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getSender() {
return Sender;
}
public void setSender(String sender) {
Sender = sender;
}
public String getAppellation() {
return appellation;
}
public void setAppellation(String appellation) {
this.appellation = appellation;
}
}
注意上面的类实现了Cloneable接口,并且重写了clone方法。这样写了之后,client中的代码就做出如下调整。
Client:
package com.phl.design.prototypepattern;
public class Client {
//定义一个属性,表示要发送多少份
public static Integer MAX_COUNT = 10;
public static void main(String[] args) {
//生成邮件模板
MailTemplate template = new MailTemplate("XXXXX","XX银行 国庆黄金周抽奖(AD)");
//生成邮件
Mail mail = new Mail(template);
for (Integer i = 0; i < MAX_COUNT; i++) {
Mail clone = mail.clone();
clone.setSender("[email protected]");
//这里并没有通过随机字符串的生成来模拟不同的收件地址,比较懒。
clone.setMailAddress(i+ "@xx.com");
//这里并没有随机选择先生/女士,比较懒。
clone.setAppellation("xx"+i+"先生");
sendMail(clone);
}
}
private static void sendMail(Mail mail) {
System.out.println("发送邮件 :: " + mail.getAppellation() + ",地址是 " + mail.getMailAddress());
}
}
注意到上方的差异了吗,之前是在循环里new 出来Mail对象。现在是通过mail.clone方法返回了mail的实例。在之后,就算把sendMail方法改成多线程的也不会出现那种对象属性错乱的情况。把对象复制一份,产生一个新的对象,和原有对象一样,然后再修改细节的数据,如设置称谓、设置收件人地址等。这种不通过new关键字来产生一个对象,而是通过对象复制来实现的模式就叫做原型模式。
原型模式定义
Specify the kinds of objects to create using a prototypical instance,and create new objects by copying this prototype.(用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。)1
原型模式的定义就是这么简单,不同过构造函数,而是通过拷贝得到一个新的实例。于java 而言,原型模式的通用类图如下:
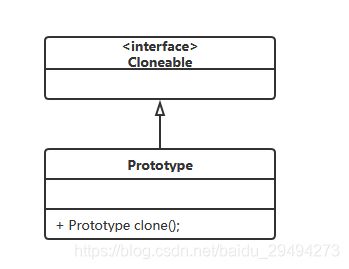 如上图所示,原型类实现了Cloneable接口,并在原型类中重写了clone方法。
如上图所示,原型类实现了Cloneable接口,并在原型类中重写了clone方法。
原型模式的优点
- 性能优良
原型模式是在内存二进制流的拷贝,要比直接new一个对象性能好很多,特别是要在一个循环体内产生大量的对象时,原型模式可以更好地体现其优点。 - 逃避构造函数的约束
这个既是它的优点又是它的缺点。所谓逃避构造函数的约束,是因为在执行clone的时候,构造方法不会被执行。
原型模式的使用场景
- 资源优化场景
类初始化需要消耗非常多的资源,这个资源包括数据,硬件资源等。 - 性能和安全要求的场景
通过new产生一个对象需要非常繁琐的数据准备或者访问权限时,可以通过原型模式解决。 - 一个对象多个修改者的场景
一个对象需要提供给多个调用者,并且每个调用者可能都需要更改其值时,可以考虑使用原型模式拷贝对个对象共调用者使用。
实际项目中,原型模式很少会单一出现。一般都是和工厂模式一起出现,通过clone方法返回新的实例给调用者。同时,Cloneable接口是Java本身提供,用起来也很方便,所以他是单独使用也方便,集成使用也方便。
原型模式的注意事项
构造方法不执行
这个很好理解。在执行clone的时候,其实是从堆内存中通过二进制流进行了数据拷贝,并重新分配了一个内存地址,因此就不会出现构造方法被执行的情况。
浅拷贝和深拷贝
浅拷贝和深拷贝,从字面意思上就能看出端倪。浅拷贝是拷贝了数据对象和部分属性,还有部分属性是新老对象共用的。深拷贝则是把对象和对象下所以属性都进行了拷贝。
下面具体说明其中存在的异同。
浅拷贝,在Java中我们都听过值传递和引用传递这样的名称。其实,对于拷贝的过程,与这个类似。所谓拷贝,实则是在进行拷贝的时候,clone()方法只是对于基础数据类型和String采用了值传递,对于数组,集合,引用对象都是采用了引用传递。继而如果一个类的成员变量是数组,集合或者引用对象的时候,在clone操作之后,克隆对象中的这个成员变量与原对象中指向了同一个引用。
深拷贝,深拷贝是指在重写clone方法中,除了执行clone操作之外,还对数组,集合,引用对象等进行了手动的clone操作。注意,这里的手动clone操作,其实是使用了数组,集合,或者引用对象的clone方法。
现在我们用一个MailBox类进行说明。
MailBox类:
package com.phl.design.prototypepattern;
import java.util.ArrayList;
public class MailBox implements Cloneable{
private int boxNo;
private String boxName;
private ArrayList<Mail> mails;
@Override
public MailBox clone() throws CloneNotSupportedException {
MailBox box = null;
box = (MailBox)super.clone();
return box;
}
public MailBox(int boxNo, String boxName, ArrayList<Mail> mails) {
this.boxNo = boxNo;
this.boxName = boxName;
this.mails = mails;
}
public MailBox() {
}
public int getBoxNo() {
return boxNo;
}
public void setBoxNo(int boxNo) {
this.boxNo = boxNo;
}
public String getBoxName() {
return boxName;
}
public void setBoxName(String boxName) {
this.boxName = boxName;
}
public ArrayList<Mail> getMails() {
return mails;
}
public void setMails(ArrayList<Mail> mails) {
this.mails = mails;
}
}
此时的MailBox重写的clone方法里,只是执行的super.clone,这样的情况就是浅拷贝,他只是会对基础数据类型和String类型进行值传递,其他情况都是引用传递。
测试类如下:
package com.phl.design.prototypepattern;
import java.util.ArrayList;
public class BoxClient {
public static void main(String[] args) throws CloneNotSupportedException {
ArrayList<Mail> mails = new ArrayList<>();
MailTemplate template = new MailTemplate("XXXXX","XX银行 国庆黄金周抽奖(AD)");
Mail mail = new Mail(template);
mails.add(mail);
MailBox box = new MailBox(1,"test_box",mails);
MailBox clone = box.clone();
clone.getMails().get(0).setTitle("clone_title");
System.out.println(box.getMails().get(0).getTitle());
}
}
运行结果如图:
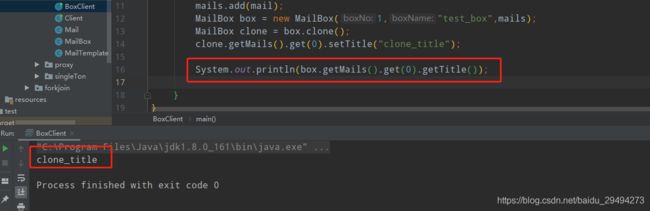 那么为了能够让数组,集合(这个例子是集合),引用对象(这个例子也是)也进行值传递,而非只是引用传递,就需要更改MailBox中重写的clone,写成深拷贝的形式。
那么为了能够让数组,集合(这个例子是集合),引用对象(这个例子也是)也进行值传递,而非只是引用传递,就需要更改MailBox中重写的clone,写成深拷贝的形式。
深拷贝MailBox如下,着重看更改之后的clone方法:
package com.phl.design.prototypepattern;
import java.util.ArrayList;
import java.util.Arrays;
public class MailBox implements Cloneable{
private int boxNo;
private String boxName;
private ArrayList<Mail> mails;
@Override
public MailBox clone() throws CloneNotSupportedException {
MailBox box = null;
box = (MailBox)super.clone();
//clone出一个list,但是这么做还不够。因为list内部的元素是引用对象
//对于这种结果,只是做出两个list,但是list内部指向是相同元素
box.mails = (ArrayList<Mail>)this.mails.clone();
box.mails.clear();
for (int i = 0; i < this.mails.size(); i++) {
//循环内部元素,对内部元素进行clone
Mail clone = this.mails.get(i).clone();
//把内部clone结果赋给clone出来的box
box.mails.add(clone);
}
return box;
}
public MailBox(int boxNo, String boxName, ArrayList<Mail> mails) {
this.boxNo = boxNo;
this.boxName = boxName;
this.mails = mails;
}
public MailBox() {
}
public int getBoxNo() {
return boxNo;
}
public void setBoxNo(int boxNo) {
this.boxNo = boxNo;
}
public String getBoxName() {
return boxName;
}
public void setBoxName(String boxName) {
this.boxName = boxName;
}
public ArrayList<Mail> getMails() {
return mails;
}
public void setMails(ArrayList<Mail> mails) {
this.mails = mails;
}
}
进行上述调整之后,通过编码对list和list内部的元素都进行了拷贝,这个就成为深拷贝。改成深拷贝之后的执行结果如下图:
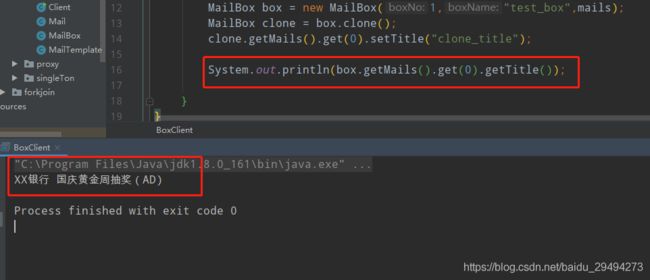
注意,不论是浅拷贝,或者是深拷贝,都不建议混用。所谓的混用就是一个类中,对部分属性进行了深拷贝,但是还留有部分属性是浅拷贝。不推荐这种写法。
中介者模式
中介者模式,也叫做调停者模式。很好理解,从名字上看,这个就是在模块之间设立一个中介的形式,进行模块与模块之间的解耦合。
空口无凭,我们用一个现实的例子进行详解。
现在有一个商店,商店里面卖面包,假设是桃李的切片面包。围绕着这个切片面包就会存在进销存的问题。三者之间的关系可以转化成如下这个图:
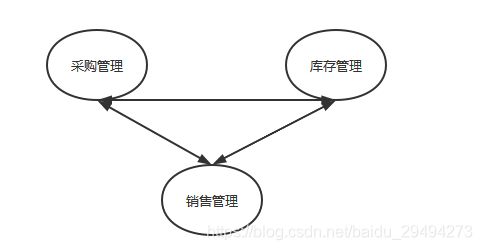 如图中所示,采购,销售,库存三者之间相互影响。在不同的情况,三者之间还需要协同实现某些动作,比如冲销,囤货。如果觉得上述这三者之间的关系还算简单,那么可以看看下面这个图:
如图中所示,采购,销售,库存三者之间相互影响。在不同的情况,三者之间还需要协同实现某些动作,比如冲销,囤货。如果觉得上述这三者之间的关系还算简单,那么可以看看下面这个图:
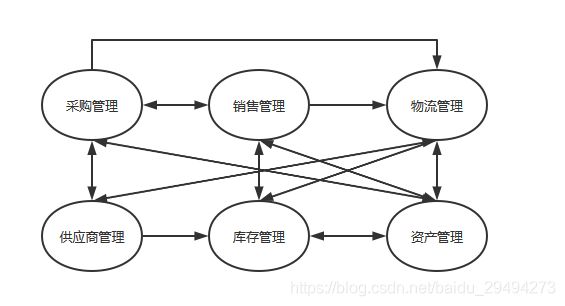 随着场景的增加,别说用程序,就是让我用文字描述出上述过程,我都做不到。为了解决这个问题就出现了中介者模式。
随着场景的增加,别说用程序,就是让我用文字描述出上述过程,我都做不到。为了解决这个问题就出现了中介者模式。
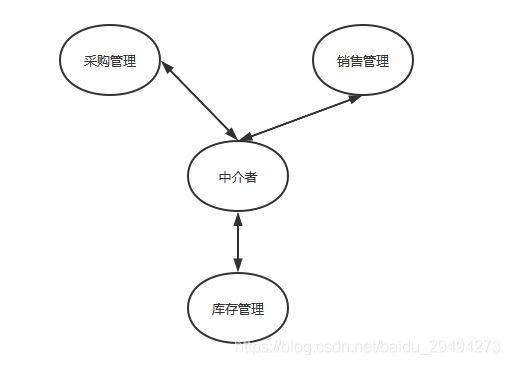 毕竟我们是为了解释中介者模式,因此把问题回到初始状态。此时给这三者之间引入了中介者这个角色。有了中介者之后,上面的场景里业务模块之间不再两两打交道。他们之间的沟通统一通过中介者完成。这样最大程度的降低了系统的耦合度。
毕竟我们是为了解释中介者模式,因此把问题回到初始状态。此时给这三者之间引入了中介者这个角色。有了中介者之后,上面的场景里业务模块之间不再两两打交道。他们之间的沟通统一通过中介者完成。这样最大程度的降低了系统的耦合度。
回归到最基本的代码上,这样的模式下,代码应该设计成什么样子。
首先,还是上类图。
 对于一开始就说过的,销售管理(sale),采购管理(Purchase)和库存管理(Stock),分别在内部定义了sale销售,in/decrease增加,减少库存,以及buy采购这三个基础方法。注意,这个例子中没有涉及冲销,清库存这些由库存信息发起的场景。这是故意设计的,这么做的目的是在于实际编码中,让大家能体会出来即便用了中介者模式,也没有必要非得通过中介者进行操作。对于本质上不会引起其他模块交互的功能,可以通过当前模块自己控制。需要中介者的地方,当且仅当模块A会引起其他模块变化时,才需要引入中介者。
对于一开始就说过的,销售管理(sale),采购管理(Purchase)和库存管理(Stock),分别在内部定义了sale销售,in/decrease增加,减少库存,以及buy采购这三个基础方法。注意,这个例子中没有涉及冲销,清库存这些由库存信息发起的场景。这是故意设计的,这么做的目的是在于实际编码中,让大家能体会出来即便用了中介者模式,也没有必要非得通过中介者进行操作。对于本质上不会引起其他模块交互的功能,可以通过当前模块自己控制。需要中介者的地方,当且仅当模块A会引起其他模块变化时,才需要引入中介者。
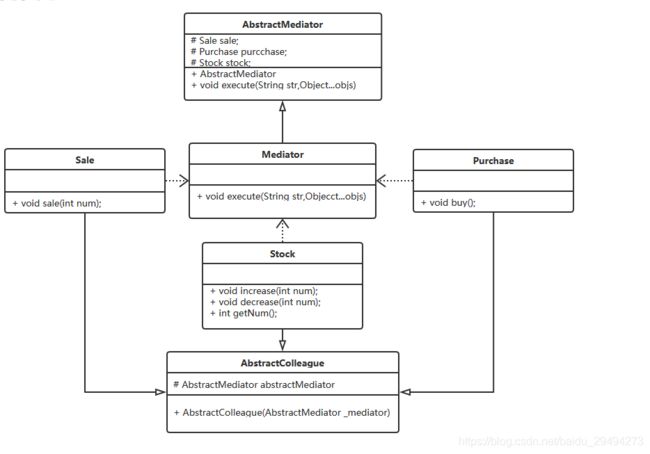
在上述类图中出现了两个抽象类,这两个抽象类很重要。
AbstractMediator,中介者抽象类。中介者抽象类是定义了当前业务场景下,中介者需要引入哪些业务模块,定义了抽象类本身的构造方法,以及核心方法execute。execute方法中传递两个参数。第一个参数是操作特征符号command,这个符号指代业务场景中的某一系列操作的总称,之后的Object…objs是不定长参数,这个不定长参数的目的是给这一系列操作进行传值。
Mediator是真实的中介者类,Mediator类中会根据当前要处理的业务场景,重写来自父类的execute方法。
AbstractColleague,抽象同事命名成同事只是因为这个场景下是多部门合作,部门和部门之间关系就是同事,所以叫了这个名字。抽象同事类中定义了一个属性,代理类。并且提供了一个传入中介类的构造方法。
提出这个抽象类的目的是为了在销售管理,采购管理,库存管理的上层能抽象出一个统一的层级。换句话说就是这三个业务类需要继承这个抽象同事类。
继承了抽象同事类类之后,会被要求在子类中同样提供一个入参是抽象中介类的构造方法,这个构造方法很关键,在这里实现了业务模块(Sale,Purchase,Stock)与中介对象(Mediator对象)的赋值绑定。
在绑定了之后,如果Sale,Purchase,Stock业务模块中的某些方法,比如(sale销售,buy采购)都会引起库存信息变化,针对这种会引起其他模块变化的方法,就需要通过中介者的execute方法去执行。
上述文字描述比较长,但还是希望可以仔细阅读,慢慢品。接下来,我会粘贴整个例子的代码。
首先是抽象中介类,AbstractMediator:
package com.phl.design.mediator;
/**
* 抽象中介类,类中定义了需要被中介的业务类和构造方法,以及最终的抽象执行方法
*/
public abstract class AbstractMediator {
protected Sale sale;
protected Stock stock;
protected Purchase purchase;
//子类实现中会进行实现的执行方法
protected abstract void execute(String command,Object... objs);
public AbstractMediator() {
//这里一开始先是分别调用了各个模块自己的构造方法。
/*
* 其实,AbstractMediator可以写成有参构造函数,然后把核心模块对象set到自己的值上去。
* 之所以没有这么设计的原因在于,如果写成那样,我需要在先准备好所有的核心对象,才能创建中介者。
* 其实对于中介者而言,我并不需要每一个业务模块,我只需要交由我进行处理的模块。我这里通过这种形式去做,
* 以及后续通过属性赋值的形式赋值,或者可以对这三个写成getset形式赋值都可以。
* 但是对于Colleague而言,他们都是需要中介的,作为业务覆盖内的一环,他们都需要交给中介者。只不过,
* 他们自身不会引起其他别的模块变化的方法,可以由他们自己执行。
* */
this.sale = new Sale(this);
this.stock = new Stock(this);
this.purchase = new Purchase(this);
}
}
接着是Mediator,中介类:
package com.phl.design.mediator;
/**
* 真实的中介
*/
public class Mediator extends AbstractMediator {
@Override
protected void execute(String command, Object... objs) {
if(command.equalsIgnoreCase("buy")){
//这个输出是表示采购方法的执行
System.out.println("采购了"+ (int)objs[0] +"个面包");
//下面这个方法是因为采购,引起了库存的变化
super.stock.increase((int)objs[0]);
System.out.println("当前库存是:"+super.stock.getNum());
}
if(command.equalsIgnoreCase("sale")){
//这个输出是表示销售方法的执行
System.out.println("卖了"+ (int)objs[0] +"个面包");
//下面这个方法是因为销售,引起了库存的变化
super.stock.decrease((int)objs[0]);
System.out.println("当前库存是:"+super.stock.getNum());
}
if(command.equalsIgnoreCase("getNum")){
System.out.println("当前库存是:"+super.stock.getNum());
}
}
}
Mediator类中,只是重写了父类的抽象方法execute。
execute方法的入参有两个,第一个command是一个行为的描述,后面的可变长参数是对于当前的“行为”需要的入参列表,是一个数组。
用buy(Command的值是buy)作为例子讲解。buy表示的一次是采购。因此进入判断之后,先进行了采购的操作(就是那句输出),采购成功之后紧接着执行了增加库存的操作。
通过这种设计,使得原本在采购过程里需要先调动purchase,再调用stock的情况变成了只需要通过mediator进行操作。降低了核心模块之间的耦合度。这三个核心模块只需要与中介进行耦合。
接着是AbstractColleague抽象类:
package com.phl.design.mediator;
public abstract class AbstractColleague {
protected AbstractMediator abstractMediator;
public AbstractColleague(AbstractMediator _mediator){
this.abstractMediator = _mediator;
}
}
这个抽象类的代码是又简单,又短。在抽象类里面定义了一个抽象接口对象,然后提供了这样的有参构造方法。这个有参构造方法很重要。通过这个有参构造方法,可以让它的子类实现中得到这个对象,从而可以通过子类的构造方法把核心模块对象赋予中介对象。
接着是Sale模块代码。:
package com.phl.design.mediator;
public class Sale extends AbstractColleague{
public Sale(AbstractMediator _mediator) {
super(_mediator);
super.abstractMediator.sale = this;
}
public void sale(int num){
super.abstractMediator.execute("sale",num);
}
}
这里面有两个地方需要注意。第一个,因为实现了AbstractColleague抽象类,因此需要对它的有参构造方法进行重写。在重写的过程里,把sale这个当前类对象赋值给了AbstractColleague中的AbstractMediator的sale引用。这样,就实现了核心模块与中介的关联。
在Sale模块中有一个业务方法,叫做sale(销售)。因为方法会引起库存信息的变化,因此对于这种会引发其它模块变化的方法就通过了中介进行执行,执行的方法是execute,传入的command是sale(在这个command是可以随意定义的,只要两边能对应上就行)。
注意,在不用中介者模式时,A执行A的,然后调用B执行B的。但是在中介者模式中,模块A的动作只是告诉中介者,我要做一个什么样的事情,此时,并没有任何真实的操作产生。注意sale方法内部,并没有任何销售的动作,只是告诉了中介者我要销售多少个面包。
总结,在中介者模式中,业务模块内需要使用中介者时,那他本身的方法内部不会去执行相应的逻辑,只是告诉中介者,我要做什么事情了。有了中介之后,模块A的这个方法,就可以当做是一个唤醒?甩手掌柜?类似这样的感觉。
同理,在采购模块中也是这样,代码如下:
package com.phl.design.mediator;
public class Purchase extends AbstractColleague{
public Purchase(AbstractMediator _mediator) {
super(_mediator);
super.abstractMediator.purchase = this;
}
public void buy(int num){
super.abstractMediator.execute("buy",num);
}
}
还记得一开始说过,这个例子中没有设计冲销,清仓这样的场景,因此库存的动作,本质上不会引起其他模块的变化。(如果说库存为0不让卖东西了,那不是模块的变化,那是逻辑上的校验,那种情况下,销售不会有任何动作)。这个场景是我故意设计的。目的是为了展示如下代码:
package com.phl.design.mediator;
public class Stock extends AbstractColleague{
private int STOCK_NUM = 100;
public Stock(AbstractMediator _mediator) {
super(_mediator);
//因为其他模块动作会引起库存的变化,因此还是需要把库存交由中介,让中介去配合其他操作的进行。
super.abstractMediator.stock = this;
}
/*
* 注意,因为设计的场景中并不会有因为库存的变化而让销售和采购有相应动作产生。
* 所以,在下面的增减库存的操作中,并不是通过中介完成的。
* 也就是说,在中介者模式里,如果某个模块的动作不会引起其他模块也有动作时,那么他自己的动作,可以自己执行,
* 不必去调用中介者,让中介者去代由完成。
* */
//增加库存
public void increase(int num){
this.STOCK_NUM = this.STOCK_NUM + num;
}
//减少库存
public void decrease(int num){
this.STOCK_NUM = this.STOCK_NUM - num;
}
//返回当前库存
public int getNum(){
return this.STOCK_NUM;
}
}
这个类的代码很简单,主要是凸显出即便在中介者模式中,也不是每个都需要用中介去代由完成。
最后就是测试类,测试类倒是没什么特别需要备注的。
package com.phl.design.mediator;
public class Client {
public static void main(String[] args) {
//新建一个中介类
Mediator mediator = new Mediator();
//下面这三个new的过程,只是想模拟我们从数据库中获取到了库存信息,之后把库存信息,以及相关的业务对象添加到中介类中。
//之所以说是添加到中介类中,因为在下面三个对象的构造方法中,都对父类对象的属性进行了相应赋值。
Sale sale = new Sale(mediator);
Purchase purchase = new Purchase(mediator);
Stock stock = new Stock(mediator);
// 场景里并没有涉及冲销这样的清库存,因此库存不会反作用于其他两个模块
// 这也就是为什么在库存模块里的代码是它本身,而其他模块中的功能是通过mediator对象进行操作。
// 这是故意设计的,其目的在于告诉大家,使用mediator的时候,并不是说每一个都必须做成通过中介执行
// 按照实际需求去设计和简化代码。
// 场景模拟
// 获取当前库存
System.out.println("初始库存是:" +stock.getNum());
// 采购100个面包
purchase.buy(100);
// 销售50个面包
sale.sale(50);
// 当前库存
System.out.println("最终库存是:" +stock.getNum());
}
}
通过文字讲解,代码粘贴,解读,就已经实现了一个通过中介者模式实现简易进销存的模型。这个就是中介者模式。
真正执行的时候,由于中介者的接入,各个模块之间不在直接调用,通过中介者实现了解耦合。
中介者模式的定义
Define an object that encapsulates how a set of objects interact.Mediator promotes loose coupling by keeping objects from referring to each other explicitly,and it lets you vary their interaction independently.(用一个中介对象封装一系列的对象交互,中介者使各对象不需要显示地相互作用,从而使其耦合松散,而且可以独立地改变它们之间的交互。)1
根据定义和上面的例子,我们可以得出,中介者模式是在中介者内(AbstractMediator)中封装了一系列对象(都继承了AbstractColleague),然后让这些AbstractColleague的子类之间不显示调用,实现解耦合,通过AbstractMediator的子类Mediator实现他们之间的交互。
中介者模式的万金油类图:
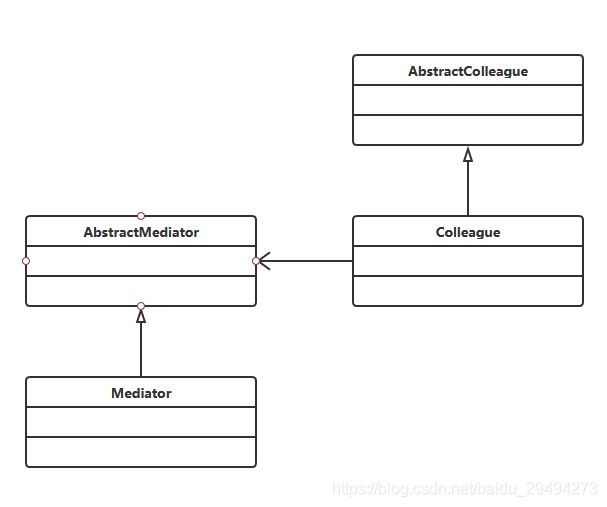 在Colleague中,方法分为两类。一类是自身方法,这类方法不会影响到其他模块,可以Colleague本身进行执行。另一类方法是依赖方法,这种方法会对其他模块产生影响,其他模块需要根据这个动作进行其他的动作。这种依赖方法就要由Mediator来执行。
在Colleague中,方法分为两类。一类是自身方法,这类方法不会影响到其他模块,可以Colleague本身进行执行。另一类方法是依赖方法,这种方法会对其他模块产生影响,其他模块需要根据这个动作进行其他的动作。这种依赖方法就要由Mediator来执行。
中介者模式的优缺点
优点
使用中介者模式,可以降低系统内耦合,减少系统内依赖。把一对多依赖转化成Colleague与Mediator之间的一对一依赖。
缺点
中介者模式的缺点很明显,中介者类会变得很大。Colleague越多,Mediator就会越大。并且,把原本多个对象的直接联系变成了间接连接使的代码难度变大逻辑复杂。
中介者模式的使用场景
中介者模式道理简单,写起来却不简单。在日常开发中,作为面向对象的语言,类和类之间肯定存在联系,如果一个人与任何一个类都没联系,那就出问题了。对于中介者模式而言,类与类之间,如果存在的联系已经复杂到蜘蛛网状的情况了,那么就可以引入中介者模式,这样设计之后可以把蜘蛛网状的关系变成星状联系,优化类与类之间的关联关系。
命令模式
命令模式是一个高内聚的设计模式。通过命令模式,可以将重复繁杂的处理逻辑变得更简单。现在引用一个时下很流行的敏捷开发进行说明。
我们公司里根据不同的项目,或者领导者在项目之初的设想,成立了敏捷工作室。这个工作室是一个人员流动性强的办公室,谁要是做敏捷开发,谁就搬进去。谁的项目结束了,谁再搬出来。
提一嘴,所谓的敏捷开发,并不见得会比传统的瀑布式耗时短,说他敏捷,是因为项目进度是不断的迭代,极大程度降低了复工的风险,并且在非常多的迭代过程里,项目可以随时按照需求者的需求变动进行灵活的调整。
在做敏捷的项目时,我们公司采用了教科书上的那一套,拆分故事点,每天和需求讨论今天要做的事情。每天对昨天的问题进行复盘。这样的过程涉及到的人员可以用下面这个类图进行描述:
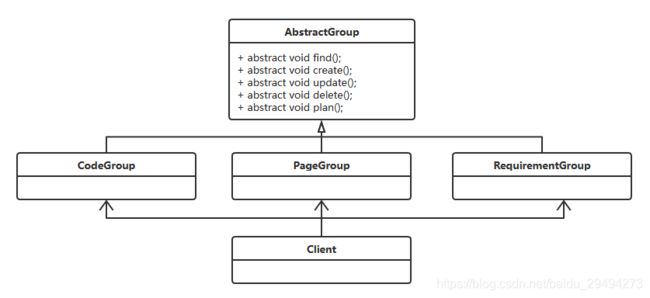 如上图所示,在后端人员(CodeGroup)、前端人员(PageGroup)和需求人员(RequirementGroup)的上面,定义了一个抽象父类(AbstractGroup)。抽象父类中提供了这些子组别的公共方法。图中的Client是需求人员。在上图中出现了5个方法,对于各个组会有不同的实现。以CodeGroup为例,代码如下:
如上图所示,在后端人员(CodeGroup)、前端人员(PageGroup)和需求人员(RequirementGroup)的上面,定义了一个抽象父类(AbstractGroup)。抽象父类中提供了这些子组别的公共方法。图中的Client是需求人员。在上图中出现了5个方法,对于各个组会有不同的实现。以CodeGroup为例,代码如下:
package com.phl.design.command;
public class CodeGroup extends AbstractGroup {
@Override
public void find() {
System.out.println("找来后台组开会");
}
@Override
public void create() {
System.out.println("客户增加一项功能");
}
@Override
public void modify() {
System.out.println("客户修改一项功能");
}
@Override
public void delete() {
System.out.println("客户删除一项功能");
}
@Override
public void plan() {
System.out.println("客户要求出具功能的详细设计方案");
}
}
在PageGroup和RequirementGroup中的各种实现都是类似的,此处不再赘述。
有了这些实现之后,每天开会的时候,都会进行如下类似的过程,这个过程在Client类中体现。
package com.phl.design.command;
public class Client {
public static void main(String[] args) {
CodeGroup codeGroup = new CodeGroup();
codeGroup.find();
codeGroup.create();
codeGroup.plan();
}
}
上面的过程模拟了在早会的时候,甲方(client)在会上给后端组提出了一个新功能,并要求后端组出具一个针对这个新功能的详细设计文档。同样,这个早会上会有更多场景,更多人。由于敏捷开发中刻板的规定,每次开会的时候都会涉及客户,后端组,前端组,需求组的所哟人员,并且会议的时间尚不确定。尤其是和顾客一起开会,在逐步明确需求,设计等内容的过程里,这个会议会变得时长不可控。
周而复始之后,出现了如下问题。
1,每次开会都需要把所有涉及的项目组成员拉到一起,影响到了开发效率。虽然这样做会让组内的每个人都清楚要做什么,怎么做,但是这个过程太过了,并非一定好用。恰巧,我们的敏捷工作室,敏捷项目的同事总会因为冗长的会议和讨论侵占了他们的开发时间,使的总会加班。
2,敏捷的会议上总会讨论到很细致的实现,目的是为了及时找出各种可能的坑。但是这个过程里,对于客户而言,大多数时间是浪费了。
3,客户在面对这么多人的时候,脑子也容易乱,容易说出来颠三倒四的话。
基于上述客观存在的问题,客户与项目组协商之后,提出了如下的开发模式。每天的会议保留,但是限制会议人数。项目组提供一个对接人。这个人专门负责与客户在会议上进行需求沟通,进度说明,问题复盘。会后,再由这个人把今天的工作任务分解给刚才提到的三组人。这个情况下会议过程的类图就变成了这个样子:
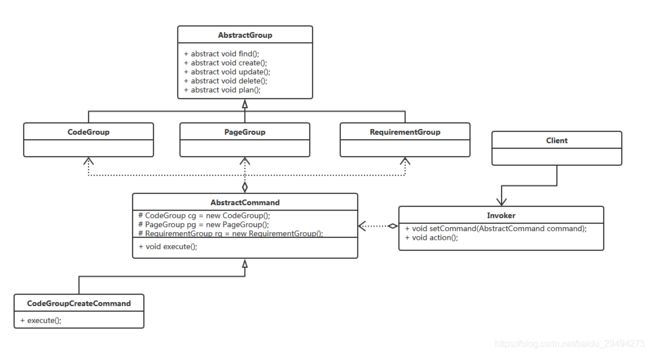 这个类图与初始的类图有很大的差异。
这个类图与初始的类图有很大的差异。
首先,提出了Invoker类。这个类就是上面说的对接人。这个类中有两个方法。setCommand和action。
setCommand的作用是把客户提出的需求转换成一个AbstractCommand的子类对象。action方法是执行客户的命令。
AbstractCommand抽象类是客户命令的抽象类。在类中初始化了需要执行命令的各个组,并且提供了execute抽象方法。
AbstractCommand会有很多个子类实现,每一个子类实现都应对一个不同的客户命令。这次还是用了让后端增加一个功能这个场景为例,因此多了一个CodeGroupCreateCommand这样的子类。在这个子类中重写了父类的execute方法,而这个execute发方法中就是完成这项命令具体要做的事情。这个execute方法会被Invoker中的action方法调用。
详细的代码如下,首先是AbstractCommand类:
package com.phl.design.command;
public abstract class AbstractCommand {
//初始化会涉及到的组
protected CodeGroup cg = new CodeGroup();
protected PageGroup pg = new PageGroup();
protected RequirementGroup rg = new RequirementGroup();
public abstract void execute();
}
有了抽象类之后,就要写出具体的命令,比如类图中出具的后端新增需求命令,CodeGroupCreateCommand:
package com.phl.design.command;
public class CodeGroupCreateCommand extends AbstractCommand {
@Override
public void execute() {
super.cg.find();
super.cg.create();
super.cg.plan();
}
}
这个类中只是重写了父类的execute方法。并且方法内部与第一个例子中的调用顺序一致,还是找来后端组开会,后端组被告知客户要新增一个需求,最后后端组给出了详细设计方案。虽然在这个过程里都是一样的,但是假设今天的会议中没有后端组任何的相关信息,那他们就可以不用参会,不必像之前那样旁听。
接下来是对接人,Invoker类:
package com.phl.design.command;
public class Invoker {
private AbstractCommand command;
public void setCommand(AbstractCommand _command){
this.command = _command;
}
public void action(){
if (null != this.command)
this.command.execute();
}
}
对接人的代码很简单。对接人内部有一个AbstractCommand,用于接收各种各样的子类Command,通过setCommand方法设置到自己私有的AbstractCommand对象上。然后在action方法中,当command不是null的时候,执行command的execute方法。
最终,现在的Client类中的调用过程就变成了如下样子:
package com.phl.design.command;
public class Client {
public static void main(String[] args) {
//找来对接人开会
Invoker invoker = new Invoker();
//告诉对接人今天的任务,之后对接人把任务转化成一个AbstractCommand对象。
CodeGroupCreateCommand codeGroupCreateCommand = new CodeGroupCreateCommand();
//添加命令
invoker.setCommand(codeGroupCreateCommand);
//执行顾客的命令
invoker.action();
}
}
执行结果:
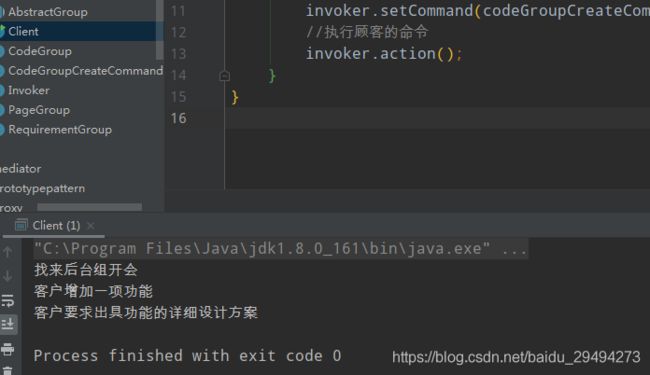
从最终的运行结果来看,使用了对接人,命令之后,执行结果正常,并且整个过程里没有消耗掉不涉及的资源。
虽然敏捷开发的模式很美好,让项目中的每个人都能知道项目具体的情况,我们到底在做什么东西,前台是什么样,后端是什么样。但是在这个过程里,很大的侵占了单日的开发时长,会让组内同事经常加班。这里只是使用这个场景进行描述了命令模式,至于是否敏捷开发,或者敏捷开发的执行程度,不做讨论。
命令模式的定义
命令模式是一个高内聚的模式,其定义为:Encapsulate a request as an object,thereby letting you parameterize clients with different requests,queue or log requests,and support undoable operations.(将一个请求封装成一个对象,从而让你使用不同的请求把客户端参数化,对请求排队或者记录请求日志,可以提供命令的撤销和恢复功能。)1
基于上述给出的定义,下面给出命令模式的通用类图。
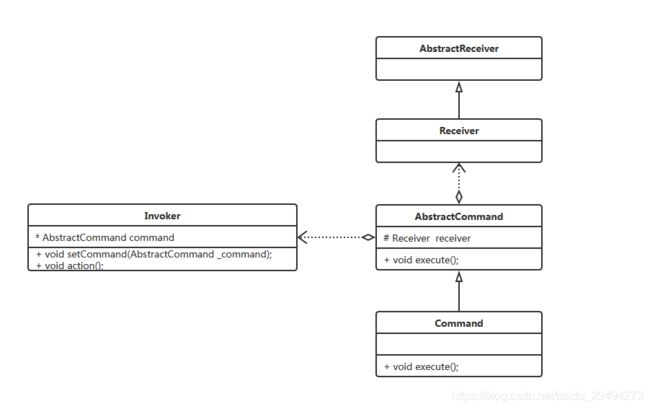
在上图中,总共出现了5个类。
-
Invoker
Invoker是用于接收顾客的调用,并把顾客的要求转换成对应的命令。然后通过action方法执行对应的命令。 -
AbstractReceiver & Receiver
这两个类分别是抽象类和真实子类。他们实际干活的人,有自己去做这个事儿的方法。类似于例子中的AbstractGroup和各个Group。 -
AbstractCommand & Command
这个就是抽象指令和真实指令类。在抽象类中,引入了各个执行者,然后按照不同的指令,生成指令子类。在子类中,通过执行者去执行对应的逻辑。
命令模式比较简单,而且在日常项目里可以经常用到。因为它的封装性非常好,把调用者Invoker与干活的Receiver进行了分离,拓展性也有所保证。
命令模式的优点和缺点
命令模式的优点
- Invoker与Receiver之间解耦合
- 命令模式结合其他模式会更优秀
命令模式合一结合责任链模式,实现命令族解析任务;结合模板方法模式,则可以减少Command子类的膨胀问题。 - 可扩展性。
这个特性主要体现在Command上。当有新的命令出现时,只需要新生成一个Command类就能完成扩展。不仅如此,在各个Command中,还可以引用各个Receiver的功能,让Command内部变得更丰富。
命令模式的缺点
他的缺点就和优点一样显而易见。如果有N个命令,就会有N个Command产生。会让整个Command变得特别膨胀。
责任链模式
责任链模式是一个生活里常见的模型,所谓责任链模式,说的笼统点,他适用的场景就是有多个对象可以处理同一个请求的时候。举个书上用的例子。在古代,女定地位不高,古代社会中对女性提出了诸多规范,其中就包括三从四德。现在使用三从来讲解责任链模式。所谓三从,就是妇女未嫁从父、出嫁从夫、夫死从子。解释起来就是如果女性要做什么事情,那么在她没出嫁的时候,需要听从父亲的决断;结婚后需要听从丈夫的决断;婚后丈夫故去,需要听从儿子的决断。实际情况中,如果儿子也故去,那肯定会有需要被她听从的其他男性亲属。
上述过程,可以简单抽象成下面这样的类图。
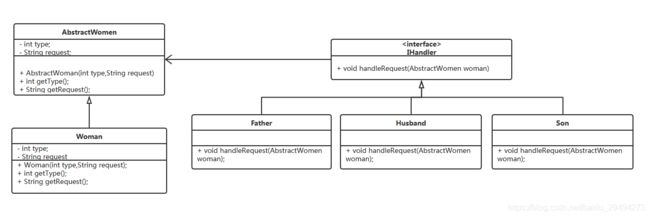
在上面类图中,我们定义的一个抽象类AbstractWomen,用来表示女性。它的子类实现就是具体的某一个女人。
Woman类中有两个属性,一个是type,int类型,用于表示未婚(0),已婚(1),婚后有子且丧偶(2)。另一个String类型的,表示女性的某个诉求。
之后定义了一个IHandler接口。接口提供了一个方法,用于处理女性的request(入参中的属性)。
有三个类实现了这个接口,分别是女性的父亲,丈夫和儿子。
这里提一下,什么时候使用抽象类,什么时候使用接口。
抽象类是一个上层对象,由真实对象抽象出来的,并且单独的上层对象是没有实际意义的。比如宠物是上层对象,猫,狗都是他的子类实现。上层对象无意义就是说,我们不能养一个宠物当宠物,我们只能养猫,狗之类的实物当做动物(抽象父类)。
接口表明的是一组能力,这一组能力就是接口中的抽象方法。举一个不算太恰当的例子,人和狗都需要睡觉,那人和狗之间有共有的能力,睡觉。此时可以把睡觉抽象成一个专门的接口。当然不论是这个例子,还是类图里的接口,通过抽象类 都可以进行转换实现,只是类似于人和狗需要抽象成脊椎动物,这种抽象本质上会更远离,或者方法我们本身想解决的问题。
以往针对这种情况,我们最终执行的时候会这么做。此处给出Client的代码:
package com.phl.design.chain;
public class Client {
public static void main(String[] args) {
//type的值,0未婚;1已婚;2有儿子且丧偶
Woman woman = new Woman(1,"request...");
if(woman.getType() == 0){
new Father().handleRequest(woman);
} else if (woman.getType() == 1){
new Husband().handleRequest(woman);
}else if (woman.getType() == 2){
new Son().handleRequest(woman);
}
}
}
上面的代码已经实现了我们想象的内容,这种写法也是我们日常经常在写的一种方式。现在指出这里的不足。这里的不足也是我们日常写代码中经常出现的问题。
-
职责界定不清晰
从需求看出来。如果是女儿提出的请求,就应该让父亲做出决断。如果是妻子,就应该是丈夫,或者丈夫故去就应该是儿子。因此作为IHandler的实现类,他们应该应对Woman不同的Type知道该由谁来处理,而不是在Client(调用)中进行组装。 -
代码臃肿
现在是通过if…else…进行判断的,可想而知,如果请求可能通过的人员越多,if…else…就越多,臃肿的条件判断,会增加出错的可能性,降低代码的可读性。 -
耦合过重
这个意思是说,我们通过Type作为依据,判断是由IHandler哪个实现类进行处理,但是一旦Type增加该怎么办?就需要修改Client了。这个违背了开闭原则。 -
异常情况欠考虑
妻子只能向丈夫请示吗?如果妻子向自己的父亲请示了,父亲应该做出什么反应?现在实现的判断只是未婚的女儿对父亲请示时,父亲有反应。但是其他情况下,都没有体现在程序中。这就是对异常情况的欠考虑。
基于上述4点问题,我们再仔细思考一下需要解决的问题。当女性提出请求时,会出现两种情况。第一种情况是,如果这个请求该我响应,那我会给出一个明确的答案 yes/no。第二种情况是,这个请求不该我响应,我会给你指派一个人,这个人可能会满足第一种情况。如果这个人还不满足,他会继续指派出一个人来处理请求。这样处理之后,就可以避免前面提到的妻子给她的父亲提出请求,父亲却不会有响应的情况。现在针对女性的请求,都会有一个响应在产生。
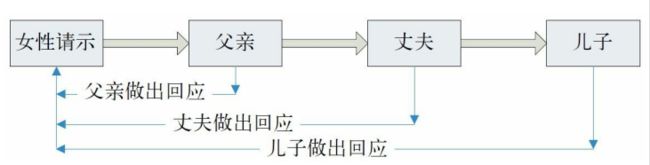
基于上面的图例,过程中涉及的类会出现这样的更改。
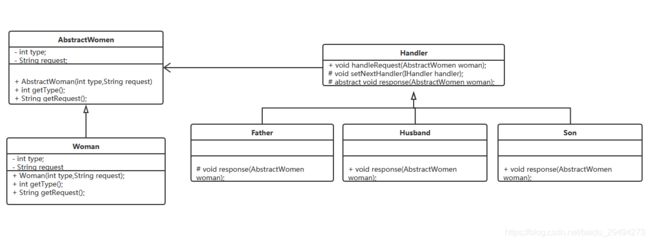
更改之后,把IHandler接口转换成了Handler抽象类。Handler中提供了三个方法。
handleRequest方法,用来处理女性的请求。
setNextHandler方法,用来设置下一个处理人。
response,给女性的请求进行反馈。这个方法是一个抽象方法,需要在各个子类实现中进行实现。
package com.phl.design.chain;
public abstract class Handler {
protected final static int FATHER_TYPE = 0;
protected final static int HUSBAND_TYPE = 1;
protected final static int SON_TYPE = 2;
private Handler nextHandler;
protected int currentType = 0;
public Handler(int _currentLevel) {
this.currentType = _currentLevel;
}
public final void handleRequest(AbstractWomen woman){
if(this.currentType == woman.getType()){
this.response(woman);
}else{
this.nextHandler.handleRequest(woman);
}
}
protected void setNextHandler(Handler _handler){
this.nextHandler = _handler;
}
protected abstract void response(AbstractWomen woman);
}
这个是更改之后的Handler抽象类。阅读代码之后会发现,这里使用了模板方法模式。Handler中的基本方法是handleRequest(AbstractWomen woman)和setNextHandler(Handler _handler),模板方法是abstract void response(AbstractWomen woman)。经过变形之后,Handler的核心基本方法是handleRequest(AbstractWomen woman)。这个方法中判断当前子类的type与woman中的type是否一致。如果一致,就处理woman的请求。如果不一致,就让下一个handler进行处理。
Handler中定义了三个int常量,这三个值是应对现在女性的三种type。具体作用是在子类实现中写父类构造方法时,作为参数进行传递。
注意,在通过模板方法模式去执行的时候,有一个要求。针对这种有明显的传递顺序的类,每次在处理请求的时候都需要从最优先的handler作为起始,这样才能保证逻辑的完整性。
对于Handler的三个子类实现,这里用Father类作为例子,进行代码展示:
package com.phl.design.chain;
public class Father extends Handler{
public Father() {
super(Handler.FATHER_TYPE);
}
@Override
protected void response(AbstractWomen woman) {
System.out.println("请求是: " + woman.getRequest());
System.out.println("父亲的回复是 yes");
}
}
我们看到,在Father类中重写了父类的抽象方法(模板方法)response方法。除此之外还要注意一个地方。
我们都知道,如果父类中包含有参构造函数,那么在子类中,需要在子类的构造方法中对齐进行调用。在Father中,我们也是这么做的。并且在调用父类的构造方法时,传入了之前定义好了的属性。
下面给出AbstractWomen和Woman的代码示例。
AbstractWomen:
package com.phl.design.chain;
public abstract class AbstractWomen {
public AbstractWomen(int type, String request) {
this.type = type;
this.request = request;
}
private int type;
private String request;
public int getType() {
return type;
}
public void setType(int type) {
this.type = type;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
}
Woman:
package com.phl.design.chain;
public class Woman extends AbstractWomen {
public Woman(int type, String request) {
super(type, request);
}
}
经过上面的更改,Client(调用)中的代码也变成了如下的样子:
package com.phl.design.chain;
import java.util.ArrayList;
import java.util.Random;
public class Client {
public static void main(String[] args) {
//随机生成几个女性
Random random = new Random();
ArrayList<AbstractWomen> women = new ArrayList<>();
for (int i = 0; i < 5; i++) {
Woman woman = new Woman(random.nextInt(3),"request..." + i);
women.add(woman);
}
// 初始化父亲,丈夫,儿子
Father father = new Father();
Husband husband = new Husband();
Son son = new Son();
// 设置nextHandler
father.setNextHandler(husband);
husband.setNextHandler(son);
// 循环执行请求
women.forEach(father :: handleRequest);
}
}
用了方法引用,这个例子需要在Java8及以上执行。
上面在调用的时候体现了一个思想,该我处理的,就我来处理。不该我处理的,就往下传递。
责任链模式的定义
Avoid coupling the sender of a request to its receiver by giving more than one object a chance to handle the request.Chain the receiving objects and pass the request along the chain until an object handles it.(使多个对象都有机会处理请求,从而避免了请求的发送者和接受者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有对象处理它止。)1
责任链模式的重点在“链”上,由一条链去处理相似的请求。在链中决定谁来处理这个请求,并返回相应的结果。
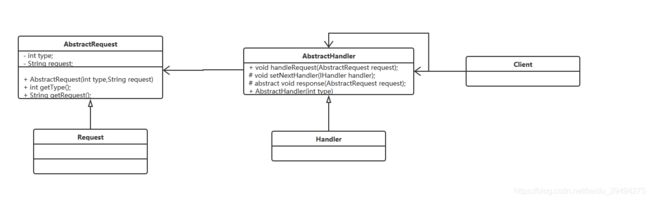
上方是通用的责任链模式类图。
在实际应用中,一般会有一个封装类对责任模式进行封装,也就是替代Client类,直接返回链中的第一个处理者,具体链的设置不需要高层次模块关系,这样,更简化了高层次模块的调用,减少模块间的耦合,提高系统的灵活性。
责任链模式的优点
责任链模式非常显著的优点就是将请求和处理分开。请求者可以不用知道是谁处理的,两者解耦。
责任链模式的缺点
责任链模式的缺点也非常显著。首先是性能问题。每一个请求都从链头开始遍历,特别是在链较长的时候,会产生性能问题。除去性能,链式模式的另一个缺点就是调试不方便,特别是链比较长,调试的时候会在多个类中进行追踪。
链式模式的注意事项
链中节点数量需要控制。避免出现超级链的情况。一般的做法会在Handler中定义一个最大节点数量,并在setNext的方法中判断是否超过阈值,超过了则不允许建立该链。
装饰模式
装饰模式在程序设计中很常见,并且也是一个简单的设计模式。这里先摆出装饰模式的基础定义。装饰模式用来给一个类增加额外的方法,这种设计模式做起来一般比子类更灵活。
核心点就是给一种给一个类提供额外方法的更灵活的方式。在日常生活里,这种情况我们经常遇到,学生时代中最常见的例子就是期末考试的成绩单需要让家长签字。
成绩单的类图如下:
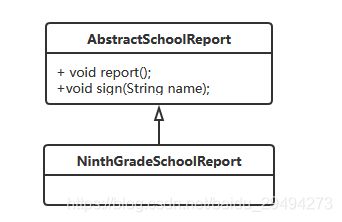
成绩单的类图如上所示。抽象成绩单提供了两个方法,一个是report,展示我们成绩信息,另一个是sign,家长签字。这两个方法是抽象方法。然后初三成绩单是抽象成绩单的一个子类,用以表示真实的成绩单。
对于这种设计,还是遵循了不能养个宠物当宠物,但是可以养只狗狗当宠物的原则。
学习成绩好的同志们可能不清楚接下来我要做的。但是我成绩中等偏下,在这种情况下,成绩单签字就类似于上刑。这个时候,我需要想办法美化自己的成绩单。因此出现了如下的类图。
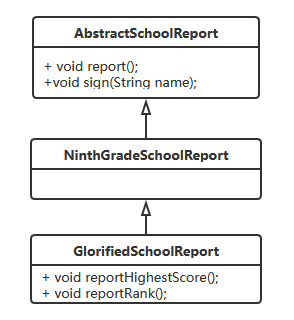
这里说的美化,并没有作假,而是希望对自己最有利的信息,用以逃避即将发生的毒打。比如说,某一科的成绩我考了60多分,但是这门课我们班最高分只有70多,这样看60多分就不会觉得很低。虽然大家普遍都在70分以上,我这个60多分还是中下游,但是我只需要技巧性地忽略大家,只突出我的分数和最高分,就能满足我的目的。再比如,这次考试一个班50多个学生,我排名快到40名。但是相较原来40多名的情况,略有进步。这也算是一个有利条件,虽然实际上是因为有两个同学转学了,才造成的位次提升,可是这同样是一个会被我忽略的情况。通过这样的美化,我就做到了在数据真实的情况下,凸显出于自己有利的情况。而这种对自己的情况,也就是定义中提到过的,额外的方法。
现在在给家人展示成绩单的时候,我会先指出班里各门课程的最高分,然后给出自己的分数,最后凸显我在名次上的进步,家长一看,觉得我有进步,也就不至于特别上火的给我签字了。因此在美化成绩单中,除了提供两个新的方法之外,还会重写父类的report方法。在report方法中,先调用reportHighestScore,然后说明自己的成绩,最后调用reportRank方法。
可是,实际情况呢?
重新考量一下我的需求。我的需求不是家长有多么了解,从各个维度去了解我的成绩,而是家长能在这个成绩单上签字。如果我光说了自己与最高分的差异,家人就要签字,我肯定不会固执的去介绍自己的排名。
亦或者一开始家人就留意到我的排名上升了,虽然成绩总体还是不行,不过也是有进步的。家长也会签字,这种情况下, 我也不会固执的要再去介绍自己与最高分的差距。
应对这种实际情况
我们通过代码模拟的话,一般情况下,我们会创建多个子类,子类重写父类report方法中,调用美化方法的顺序不同,也就是我们会产生多个用于应对不同情况的美化子类。
但是通过这种方式,首先应对每一个潜在的情况,我们都需要创建出新的子类来进行美化。这样会造成类爆炸,并且有很多相同,重复的代码产生。
怎么做更合理?
现在用这样的类图去描述一种更合理的处理方式。
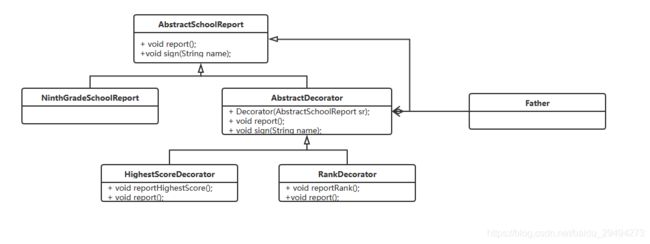 改进之后,给出了整体的类图。其中,Father就是上述所有例子中的调用者。
改进之后,给出了整体的类图。其中,Father就是上述所有例子中的调用者。
新的类图里面多了一个抽象类和两个子类实现。
抽象类AbstractDecorator提供了有参构造方法,这个构造方法的入参是AbstractSchoolReport(成绩单)类。抽象类中的重写了父类中report和sign的方法。
针对AbstractDecorator,有两个子类实现,分别用于汇报最高成绩和名次。下面给出详细的代码。
AbstractSchoolReport:
package com.phl.design.decorator;
public abstract class AbstractSchoolReport {
public abstract void report();
public abstract void sign(String name);
}
NinthGradeSchoolReport:
package com.phl.design.decorator;
public class NinthGradeSchoolReport extends AbstractSchoolReport {
@Override
public void report() {
System.out.println("各科成绩是。。。。");
}
@Override
public void sign(String name) {
System.out.println("家长进行签字" + name);
}
}
AbstractDecorator:
package com.phl.design.decorator;
public abstract class AbstractDecorator extends AbstractSchoolReport {
private AbstractSchoolReport sr;
public AbstractDecorator(AbstractSchoolReport sr) {
this.sr = sr;
}
@Override
public void report() {
this.sr.report();
}
@Override
public void sign(String name) {
this.sr.sign(name);
}
}
HighestScoreReport:
package com.phl.design.decorator;
public class HighestScoreReport extends AbstractDecorator {
public HighestScoreReport(AbstractSchoolReport sr) {
super(sr);
}
public void reportHighestScore(){
System.out.println("各科最高成绩。。。。");
}
@Override
public void report() {
this.reportHighestScore();
super.report();
}
}
RankReport:
package com.phl.design.decorator;
public class RankReport extends AbstractDecorator {
public RankReport(AbstractSchoolReport sr) {
super(sr);
}
public void reportRank(){
System.out.println("本次考试的班级名次是。。。");
}
@Override
public void report() {
this.reportRank();
super.report();
}
}
Father:
package com.phl.design.decorator;
public class Father {
public static void main(String[] args) {
AbstractSchoolReport sr;
//原装成绩单
sr = new NinthGradeSchoolReport();
//最高分成绩单
sr = new HighestScoreReport(sr);
sr.report();
System.out.println("===================================");
//继续装载了排名的成绩单
sr = new RankReport(sr);
sr.report();
}
}
装饰模式的代码示例已经粘贴完毕,这个例子的执行结果是:
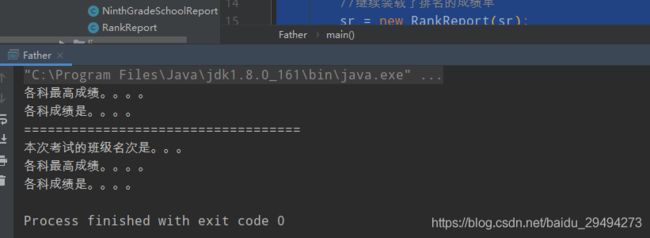
根据这个例子,首先,我们能发现,装饰模式与代理模式中的静态代理很像。在代理模式中,代理类中会传入被代理对象。在装饰模式中,会给装饰类里传入被装饰对象。
通过这样的演示,希望大家可以体会到,在装饰模式中,虽然类似于多子类的形式,我们定义了很多装饰子类,但是这些装饰子类每个里面只提供了一个单一的额外方法。最终在调用的时候,需要哪个,就new出来哪个。并在最终执行的过程里,装饰子类会按照构造器调用的顺序,加载出我们希望的执行顺序。这样的写法,代码条理性更强,理解起来更简单,并且非常方便应对不同的情况,进行各式各样的扩展。
装饰模式的定义
装饰模式(Decorator Pattern)是一种比较常见的模式,其定义如下:Attach additional responsibilities to an object dynamically keeping the same interface.Decorators provide a flexible alternative to subclassing for extending functionality.(动态地给一个对象添加一些额外的职责。 就增加功能来说,装饰模式相比生成子类更为灵活。)1
上方给出了装饰模式的定义,动态地,给一个对象,添加一些额外的职责。就增加功能来说,装饰模式相比生成子类更加灵活。
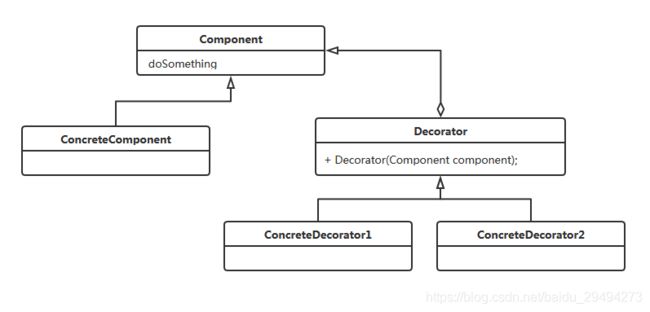 上图是通用的装饰模式类图,图片上出现了四个对象。
上图是通用的装饰模式类图,图片上出现了四个对象。
- Component
Component可以是接口,也可以是抽象类。这个对应例子中的AbstractSchoolReport抽象类,用于定义要被装饰对象的抽象类型。注意,在装饰模式里,必然有一个最基础,最原始的接口或者抽象类来扮演Component的角色。 - ConcreteComponent
ConcreteComponent,是Component的子类实现,表示一个具体的被装饰的对象。也就是例子中的NinthGradeSchoolReport。 - Decorator
一般是一个抽象类。Decorator的作用是所有装饰子类的父类,在Decorator里,必然会把Component当做入参的有参构造方法,同时他的属性里一定有一个private Component指向Component。在Decorator中,可以根据实际需要声明具体的方法和抽象方法。 - ConcreteDecorator
一个真实的装饰子类。在装饰子类中,需要按照业务需求,对最原始,最核心的被装饰对象提供额外方法。类似例子中的HighestScoreReport和RankReport。
装饰模式的优点
- 装饰类和被修饰类可以独立发展,不会相互耦合。换句话讲,Component类无须知道Decorator类,Decorator是从外部扩展Component类的功能。而Decorator也无须知道Component的具体构件。
- 装饰模式是继承关系的一种替代方案。通过例子和通用类的解释,我们发现不管Decorator被修饰了多少层,返回的都是Component对象。因此它实现的还是is-a的关系。
- 装饰模式可以动态的扩展一个实现类的功能。
装饰模式的缺点
对于装饰模式的缺点,记住一个就足够了。多层的装饰模式比较复杂,因为程序调试之后可能会发现是最里层的装饰出了问题,这样更改起来就很麻烦。因此,尽量减少装饰类的数量,这样可以降低整体的工作量。
策略模式
随着设计模式学习的深入,现在在讲解设计模式的时候,总会发现一些特别类似的设计模式。比如今天要讲解的策略模式。策略模式与之前讲到的代理模式就很相似。讲解策略模式的时候,引用三国里面赵云陪刘备去江东娶亲,诸葛亮提供了三个锦囊妙计的故事。
故事中,诸葛亮给赵云了三个锦囊妙计。第一个是,到达东吴,先去拜会乔国老。第二个,刘备贪念美色不思离开,就对他谎称曹操大军压境。第三个,如果被东吴军队追赶,求孙夫人解围。这三个锦囊妙计都有一个相同的方法,就是执行。上述三个,只是执行这个方法中的不同实现。并且,这三个锦囊妙计是装在锦囊里面的。最终被赵云调用。整个过程,就可以通过如下的类图形容其中的关系。
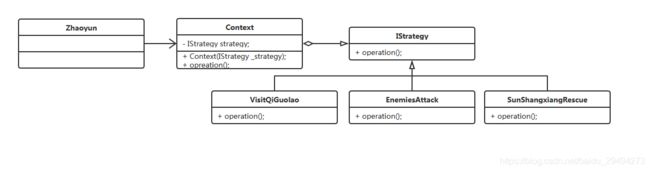
对应的代码如下,首先是IStrategy:
package com.phl.design.strategy;
public interface IStrategy {
void operation();
}
接着是三个锦囊妙计。
VisitQiGuolao:
package com.phl.design.strategy;
public class VisitQiGuolao implements IStrategy {
@Override
public void operation() {
System.out.println("一到东吴,就去拜访齐国老");
}
}
EnemiesAttack:
package com.phl.design.strategy;
public class EnemiesAttack implements IStrategy {
@Override
public void operation() {
System.out.println("刘备乐不思蜀,谎称曹军大军压境");
}
}
SunShangxiangRescue:
package com.phl.design.strategy;
public class SunShangxiangRescue implements IStrategy {
@Override
public void operation() {
System.out.println("被人围困,孙尚香来解围");
}
}
妙计接口和三个实现子类已经写好了,下面是装妙计的锦囊。Context:
package com.phl.design.strategy;
public class Context {
private IStrategy strategy;
public Context(IStrategy _strategy) {
this.strategy = _strategy;
}
public void operation(){
this.strategy.operation();
}
}
最后就是使用锦囊的人,赵云。Zhaoyun:
package com.phl.design.strategy;
public class Zhaoyun {
public static void main(String[] args) {
Context context = new Context(new VisitQiGuolao());
context.operation();
context = new Context(new EnemiesAttack());
context.operation();
context = new Context(new SunShangxiangRescue());
context.operation();
}
}
上面就是整个过程的代码示例。代码没有难度,很好理解。
策略模式的定义
策略模式(Strategy Pattern)是一种比较简单的模式,也叫做政策模式(Policy Pattern)。
Define a family of algorithms,encapsulate each one,and make them interchangeable.(定义一组算法,将每个算法都封装起来,并且使它们之间可以互换。)1
基于定义给出的类图如下:
 上图就是根据定义给出的类图。定义一组算法,就是图中的IStrategy和ConcreteStrategy构成,也就是我们例子里的妙计接口和三个实现类。所谓的封装起来,就是我们例子里的锦囊,也是这个类图中的Context。定义中的可以相互转换,其实就是说Context中的有参构造方法里,因为传入的是IStrategy类型的,因此各个子类都可以当做入参,这也就实现了互换。
上图就是根据定义给出的类图。定义一组算法,就是图中的IStrategy和ConcreteStrategy构成,也就是我们例子里的妙计接口和三个实现类。所谓的封装起来,就是我们例子里的锦囊,也是这个类图中的Context。定义中的可以相互转换,其实就是说Context中的有参构造方法里,因为传入的是IStrategy类型的,因此各个子类都可以当做入参,这也就实现了互换。
策略模式的重点就是封装角色,它是借用了代理模式的思路,大家可以想想,它和代理模式有什么差别,差别就是策略模式的封装角色和被封装的策略类不用是同一个接口,如果是同一个接口那就成为了代理模式。
策略模式的优点
- 算法可以自由切换
这是策略模式本身定义的,只要实现了抽象策略,就成为了策略家族的一个成员。通过封装角色(Context)对它进行封装,保证对外提供“可以自由切换”的策略。 - 避免使用多重条件判断
假设没有策略模式,用刚才的例子来看,我们想要使用这些方法,一会儿访问齐国老,一会儿又是诈有敌军,这怎么设计呢,多重条件判断吗?但是多重条件判断不易维护。使用策略模式之后,可以由其他模块决定该使用何种策略,策略家族对外提供的访问接口就是封装类,简化了操作,同时避免了条件语句判断。 - 扩展性良好
这个优点非常明显。不多进行赘述。
策略模式的缺点
- 策略类数量增多
一个策略都是一个类,复用的可能性小,类数量增多。 - 所有的策略类都需要对外暴露
上层模块必须知道有哪些策略,然后才能决定使用哪一个策略。这样与迪米特法则是相违背的。我只是想使用一个策略,凭什么必须要了解这个策略。所幸,这个缺点可以通过配合其他设计模式来解决,比如工厂方法模式、代理模式或者享元模式。
策略模式的使用场景
- 多个类只有在算法上稍有不同的场景
- 算法需要自由切换的场景
- 需要屏蔽算法规则的场景
策略模式的注意事项
如果系统中的一个策略家族的具体策略数量超过4个,则需要考虑使用混合模式,解决策略类膨胀对外暴露的问题,否则日后的系统维护就会成为一个烫手山芋。
策略模式的扩展
引用一个例子,来讲解策略模式的扩展。
假设,现在需要做两个数的加减法。数字是int,运算符是String,只有+,-可以选择。这个过程里不考虑任何可能存在的漏洞和需要校验的地方,只是单纯的实现这个功能。该怎么做?
首先给出最常想到的方式:
package com.phl.design.strategy;
public class CalculateDemo {
public static void main(String[] args) {
int a = Integer.parseInt(args[0]);
int b = Integer.parseInt(args[1]);
String symbol = args[2];
System.out.println(symbol.equals("+") ? a + b : a - b);
}
}
上面代码足够简单,并且也能实现这个需求。下面,使用今天介绍的策略模式的变形体来解决这个问题。这种变形称为策略枚举。
package com.phl.design.strategy;
public enum EnumCalculate {
ADD("+"){
@Override
public void calculate(int a, int b) {
System.out.println(a + b);
}
},SUB("-"){
@Override
public void calculate(int a, int b) {
System.out.println(a - b);
}
};
private String symbol;
EnumCalculate(String _symbol) {
this.symbol = _symbol;
}
public abstract void calculate(int a ,int b);
public static void main(String[] args) {
EnumCalculate.ADD.calculate(1,2);
EnumCalculate.SUB.calculate(1,2);
}
}
什么是策略枚举?
首先,他是一个枚举类。
然后,他浓缩了策略模式的精华。把原有定义在抽象策略中的方法移植到了枚举类中,每个枚举成员都成为了一个具体实现。
策略枚举是一个非常易于理解和维护的模式。但是他受到枚举类的限制。枚举类中的枚举项都是public static final的,扩展性受到了一定限制。因此在系统开发过程中,策略枚举一般都担当了不经常发生变化的角色。
最佳实践
策略模式是一个非常简单的模式,在项目中也有很多应用。但是他有一个致命缺陷:所有的策略都需要暴露出去。这样才方便客户端决定调用哪个策略。
例子中的赵云,实际上不知道使用哪个策略,他只知道拆开第一个锦囊,但是不知道对应的是VisitQiGuolao这个妙计。
诸葛亮已经规定了在适当的场景下拆开指定的锦囊,而策略模式只是实现了锦囊的管理,但我们在例子中并没有严格规定“适当场景”拆开指定锦囊。
在实际项目中,我们一般通过工厂方法模式来实现策略类的声明。
适配器模式
适配器模式叫做变压器模式,也叫做包装模式。但是,包装模式不只这一种,前面讲到的装饰模式也是包装模式。
适配器模式在日常使用中,经常会遇到。它存在的意义就是让我们能从突发的需求变动中灵活的应对。
举一个例子,我们现在要做一个人员管理系统,用于管理自己公司里面的自聘人员信息。离职和退休的人员不考虑。核心业务类图如下:
在上面的类图中,有一个接口IUserInterface,里面定义了人员管理中的各种方法,用以提供人员信息的查询操作。
UserInfo类实现了IUserInterface接口,把数据库里查询出来的数据转义成对应的业务接口。做到这一步,我们对库中的数据就完成了查询操作。
现在我们公司出于成本考虑,又通过外包的形式招了一批同事。领导说,这些同事的信息也需要录入到系统中。但是这些人员信息是他们本身的公司进行管理,因此我们只能通过其他形式进行数据同步。但是对方提供数据的接口类似这样的结构:
 上面出现的IOutUserInterface是传递外部数据的接口形式。在这个接口里,他们将个人信息封装成了三部分,分别是基础信息,家庭信息和办公信息,返回的内容都是在Map中。从接口提供的方法可以看出,我们需要在拿到数据之后进行一次转换,然后才能供给我们的系统使用。最终的类图如下:
上面出现的IOutUserInterface是传递外部数据的接口形式。在这个接口里,他们将个人信息封装成了三部分,分别是基础信息,家庭信息和办公信息,返回的内容都是在Map中。从接口提供的方法可以看出,我们需要在拿到数据之后进行一次转换,然后才能供给我们的系统使用。最终的类图如下:
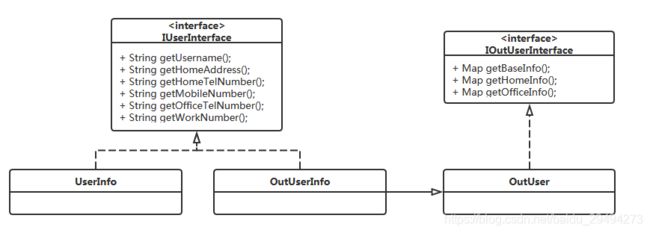
上图是最终的类图。与中间过程相比,多了两个类。OutUser类实现了IOutUserInterface接口,实现数据接收。OutUserInfo类继承了OutUser类,并且实现了IUserInterface接口,实现了外部人员数据转换,并且提供给我们自己的系统。
因为这个例子很简单,代码上也不存在什么写不了的地方,因此就不提供代码示例。
适配器模式定义
Convert the interface of a class into another interface clients expect.Adapter lets classes work together that couldn’t otherwise because of incompatible interfaces.(将一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。)1
适配器模式在我们日常生活中很常见,比如各种各样的变压器。这个模式就是这么浅显易懂。
适配器模式的通用类图:
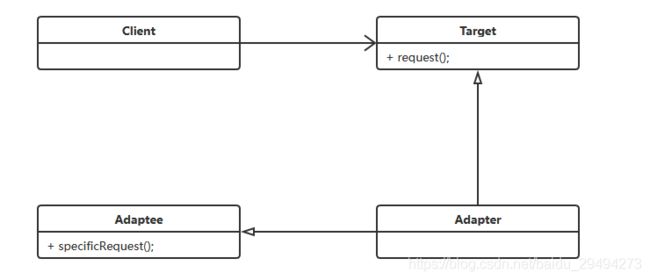 上述类图中存在四个角色。
上述类图中存在四个角色。
- Client
程序的调用者。 - Target
该角色定义把其他类转换为何种接口,也就是我们的期望接口,例子中的IUserInfo接口就是目标角色。 - Adaptee
你想把谁转换成目标角色,这个“谁”就是源角色,它是已经存在的、运行良好的类或对象,经过适配器角色的包装,它会成为一个崭新、靓丽的角色。 - Adapter
适配器模式的核心角色,其他两个角色都是已经存在的角色,而适配器角色是需要新建立的,它的职责非常简单:把源角色转换为目标角色,怎么转换?通过继承或是类关联的方式。
适配器模式的优点
- 适配器模式可以让两个没有任何联系的类在一起运行。
- 增加了类的透明性。
- 提高了类的复用度。
- 灵活性非常好。适配器模式对原有的功能没有任何侵入性。当不需要适配器时,只需要移除Adapter与Target之间的关联就行。
适配器模式的使用场景
适配器模式的使用场景,只需要记住一点就足够了。当需要修改一个已经已经投产的接口时,适配器模式可能是最适合的模式。
适配器模式的注意事项
适配器模式最好在详细设计阶段不要考虑他,它不是为了解决还处在开发阶段的问题,而是解决正在服役的项目问题,没有一个系统分析师会在设计阶段考虑使用适配器模式,这个模式使用的场景就是扩展应用。再次提醒一点,项目一定要遵守依赖倒置原则和里氏替换原则,否则即使在适合使用适配器的场合下,也会带来非常大的改造。
另一个注意事项。例子中我们是幸运的,Target只是一个类,我们可以通过集成就实现了需要的效果。但是如果是多个类呢?在这种情况下,需要进行类关联和类适配。
类关联,说白了就是通过私有属性和构造方法建立类与类之间的关系,类适配则是对所有的Target进行适配。然后将适配的结果作为入参,通过构造方法传入到一个Adapter中。
迭代器模式
首先,迭代器模式时一个过时的模式,在日常开发中不推荐使用,取而代之的是Java提供的Iterator。
也就是说,只要公司里的JDK版本高于1.2,就不会出现需要使用迭代器模式的场景。因为从JDK1.2开始,java提供了Iterator这个接口。
组合模式
在讲解组合模式之前,先进行一个铺垫。组合模式适用于部分-整体这样的情况,适合于现实生活里的各种树型结构。比如一个单位里面的人事架构,这种人事架构就是树形结构。
剩余内容,明天完成。
设计原则
参考文献
设计模式之禅(第2版) 作者: 秦小波 出版社:机械工业出版社 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎