Dlink On Yarn 三种 Flink 执行方式的实践
原文:Dlink On Yarn 三种 Flink 执行方式的实践 - 腾讯云开发者社区-腾讯云
一、简介
Dlink 为 Apache Flink 而生,让 Flink SQL 更加丝滑。它是一个 交互式的 FlinkSQL Studio,可以在线开发、预览、校验 、执行、提交 FlinkSQL,支持 Flink 官方所有语法及其增强语法,并且可以同时对多 Flink 实例集群进行提交、停止、SavePoint 等运维操作,如同您的 IntelliJ IDEA For Flink SQL。
需要注意的是,Dlink 它更专注于 FlinkSQL 的应用,而不是 DataStream。在开发过程中您不会看到任何一句 java、scala 或者 python。所以,它的目标是基于 100% FlinkSQL 来实现批流一体的实时计算平台。
二、原理
原理图

JobManager
JobManager 并非 Flink 的 JM,而是作为 Dlink 的作业管理入口,负责 Flink 的各种作业执行方式及其他功能的调度。
Executor
Executor 是 Dlink 定制的 FlinkSQL 执行器,来模拟真实的 Flink 执行环境,负责 FlinkSQL 的 Catalog 管理、UDF管理、片段管理、配置管理、语句集管理、语法校验、逻辑验证、计划优化、生成 JobGraph、本地执行、远程提交、SELECT 及 SHOW 预览等核心功能。
Interceptor
Interceptor 是 Dlink 的 Flink 执行拦截器,负责对其进行片段解析、UDF注册、SET 和 AGGTABLE 等增强语法解析。
Gateway
Gateway 并非是开源项目 flink-sql-gateway,而是 Dlink 自己定制的 Gateway,负责进行基于 Yarn 环境的任务提交与管理,主要有 Yarn-Per-Job 和 Yarn-Application 的 FlinkSQL 提交、停止、SavePoint 以及配置测试,而 User Jar 目前只开放了 Yarn-Application 的提交。
Flink SDK
Dlink 主要通过调用 flink-client 和 flink-table 模块进行二次开发,打包主要位于 dlink-client.jar ,所以切换 Flink 版本只需要更换对应版本的 dlink-client.jar 。
Yarn SDK
Dlink 通过调用 flink-yarn 模块进行二次开发,打包也位于 dlink-client.jar ,所以切换 Flink 版本只需要更换对应版本的 dlink-client.jar 。此外也使用到了 flink-shaded-hadoop-3-uber.jar。
Flink API
Dlink 也支持通过调用 Flink 集群的 JobManager 的 RestAPI 对任务进行管理等操作,系统配置可以控制开启和停用。
Yarn-Session
Dlink 通过已注册的 Flink Session 集群实例可以对 Standalone 和 Yarn-Session 两种集群进行 FlinkSQL 的提交、Catalog 的交互式管理、会话管理以及对 SELECT 和 SHOW 等语句的执行结果预览。
Yarn-Per-Job
Dlink 通过已注册的集群配置来获取对应的 YarnClient 实例,然后将本地解析生成的 JobGraph 与 Configuration 提交至 Yarn 来创建 Flink-Per-Job 应用。
Yarn-Application
Dlink 通过已注册的集群配置来获取对应的 YarnClient 实例。对于 User Jar,将 Jar 相关配置与 Configuration 提交至 Yarn 来创建 Flink-Application 应用;对于 Flink SQL,Dlink 则将作业 ID 及数据库连接配置作为 Main 入参和 dlink-app.jar 以及 Configuration 提交至 Yarn 来创建 Flink-Application 应用。
三、部署
获取安装包
百度网盘链接:https://pan.baidu.com/s/1HNAmpiZMu8IUrUKQgR55qQ
提取码:0400
安装
将安装包上传至服务器并解压。
得到以下项目结构:
config/ -- 配置文件
|- application.yml
extends/ -- 扩展文件
html/ -- 前端文件
jar/ -- 扩展 Flink Jar 文件
lib/ -- 外部依赖及Connector
|- dlink-client-1.13.jar
|- dlink-connector-jdbc.jar
|- dlink-function.jar
|- dlink-metadata-clickhouse.jar
|- dlink-metadata-mysql.jar
|- dlink-metadata-oracle.jar
|- dlink-metadata-postgresql.jar
plugins/ -- Flink 相关扩展
|- flink-shaded-hadoop-3-uber.jar
|- flink-connector-jdbc_2.11-1.13.3.jar
|- flink-csv-1.13.3.jar
|- flink-json-1.13.3.jar
|- mysql-connector-java-8.0.21.jar
sql/
|- dlink.sql -- Mysql初始化脚本
auto.sh -- 启动停止脚本
dlink-admin.jar -- 程序包复制
修改配置文件
修改数据源连接配置:
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/dlink?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: dlink
password: dlink
driver-class-name: com.mysql.cj.jdbc.Driver
application:
name: dlink复制
注:数据库实例名为 dlink,url 后缀参数可以根据实际数据库连接参数进行修改配置。
初始化数据库
在对应数据库下执行 sql 目录下的 dlink.sql 脚本。
执行成功后,可见以下数据表:
dlink_catalogue
dlink_cluster
dlink_cluster_configuration
dlink_database
dlink_flink_document
dlink_history
dlink_jar
dlink_savepoints
dlink_sys_config
dlink_task
dlink_task_statement
dlink_user复制
启动程序
启动 dlink 应用进程:
sh auto.sh start复制
其他命令:
# 停止
sh auto.sh stop
# 重启
sh auto.sh restart
# 状态
sh auto.sh status复制
运行日志
控制台输出:项目根目录下的 dlink.log 文件。
日志归档输出:项目根目录下的 logs 目录下。
前端部署
将 html 目录下文件上传至 Nginx 的 html 文件夹。
修改 nginx 配置文件并重启。添加内容如下:
server {
listen 9999;
server_name localhost;
# gzip config
gzip on;
gzip_min_length 1k;
gzip_comp_level 9;
gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
gzip_vary on;
gzip_disable "MSIE [1-6]\.";
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
try_files $uri $uri/ /index.html;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
location ^~ /api {
proxy_pass http://127.0.0.1:8888;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
}
}复制
1.server.listen 填写前端访问端口
2.proxy_pass 填写后端地址如 http://127.0.0.1:8888
3.重启 Nginx。
4.后续只更新前端资源时,不需要重启 Nginx。
打开主页
访问 Nginx 代理的端口号 9999。
默认超级管理员账号:admin / admin
新增用户默认密码:123456
四、Yarn-Session 实践
注册 Session 集群

进入集群中心进行远程集群的注册。点击新建按钮配置远程集群的参数。图中示例配置了一个 Flink on Yarn 的高可用集群,其中 JobManager HA 地址需要填写集群中所有可能被作为 JobManager 的 RestAPI 地址,多个地址间使用英文逗号分隔。表单提交时可能需要较长时间的等待,因为 dlink 正在努力的计算当前活跃的 JobManager 地址。
保存成功后,页面将展示出当前的 JobManager 地址以及被注册集群的版本号,状态为正常时表示可用。
注意:只有具备 JobManager 实例的 Flink 集群才可以被成功注册到 dlink 中。( Yarn-Per-Job 和 Yarn-Application 也具有 JobManager,当然也可以手动注册,但无法提交任务)
如状态异常时,请检查被注册的 Flink 集群地址是否能正常访问,默认端口号为8081,可能更改配置后发生了变化,查看位置为 Flink Web 的 JobManager 的 Configuration 中的 rest 相关属性。
执行 Hello World
万物都具有 Hello World 的第一步,当然 dlink 也是具有的。我们选取了基于 datagen 的流查询作为第一行 Flink Sql。具体如下:
CREATE TABLE Orders (
order_number BIGINT,
price DECIMAL(32,2),
buyer ROW,
order_time TIMESTAMP(3)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1'
);
select order_number,price,order_time from Orders 复制
该例子使用到了 datagen,需要在 dlink 的 plugins 目录下添加 flink-table.jar。
点击 Flink Sql Studio 进入开发页面:
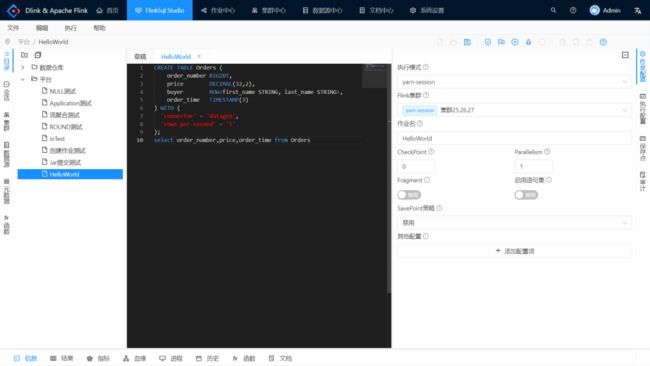
在中央的编辑器中编辑 Flink Sql。
右边作业配置:
- 执行模式:选中 yarn-session;
- Flink 集群:选中上文注册的测试集群;
- SavePoint 策略:选中禁用;
- 按需进行其他配置。
右边执行配置:
- 预览结果:启用;
- 远程执行:启用。
点击快捷操作栏的三角号按钮同步执行该 FlinkSQL 任务。
预览数据

切换到历史选项卡点击刷新可以查看提交进度。切换到结果选项卡,等待片刻点击获取最新数据即可预览 SELECT。
停止任务

切换到进程选项卡,选则对应的集群实例,查询当前任务,可执行停止操作。
五、Yarn-Per-Job 实践
注册集群配置
进入集群中心——集群配置,注册配置。
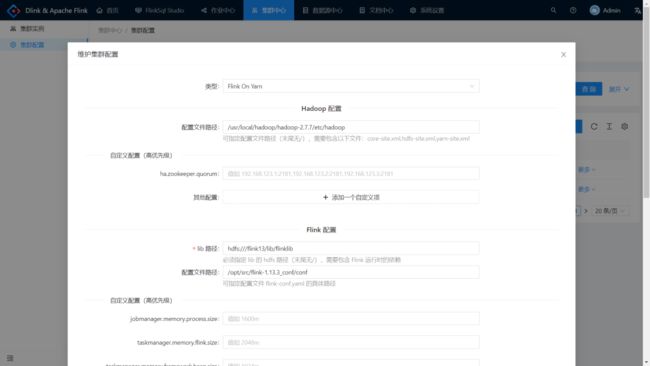
- Hadoop 配置文件路径:指定配置文件路径(末尾无/),需要包含以下文件:
core-site.xml,hdfs-site.xml,yarn-site.xml; - Flink 配置 lib 路径:指定 lib 的 hdfs 路径(末尾无/),需要包含 Flink 运行时的所有依赖,即 flink 的 lib 目录下的所有 jar;
- Flink 配置文件路径:指定配置文件
flink-conf.yaml的具体路径(末尾无/); - 按需配置其他参数(重写效果);
- 配置基本信息(标识、名称等);
- 点击测试或者保存。
执行升级版 Hello World
之前的 hello world 是个 SELECT 任务,改良下变为 INSERT 任务:
CREATE TABLE Orders (
order_number INT,
price DECIMAL(32,2),
order_time TIMESTAMP(3)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.order_number.kind' = 'sequence',
'fields.order_number.start' = '1',
'fields.order_number.end' = '1000'
);
CREATE TABLE pt (
ordertotal INT,
numtotal INT
) WITH (
'connector' = 'print'
);
insert into pt select 1 as ordertotal ,sum(order_number)*2 as numtotal from Orders复制
此外,该功能使用到了 Hadoop 相关依赖,所以需要在 plugins 下添加 flink-shaded-hadoop-3-uber.jar。
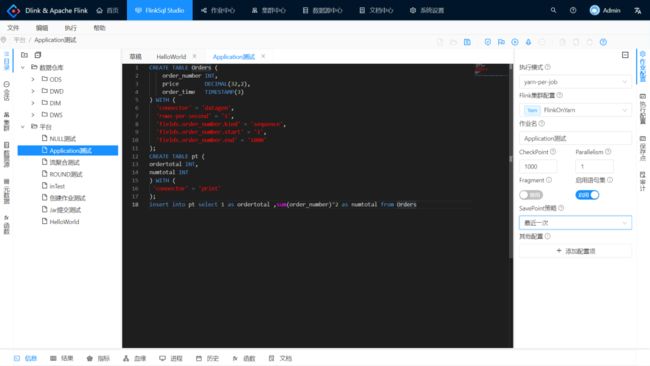
编写 Flink SQL;
作业配置:
- 执行模式:选中 yarn-per-job ;
- Flink 集群配置:选中刚刚注册的配置;
- SavePoint 策略:选中最近一次。
快捷操作栏:
- 点击保存按钮保存当前所有配置;
- 点击小火箭异步提交作业。
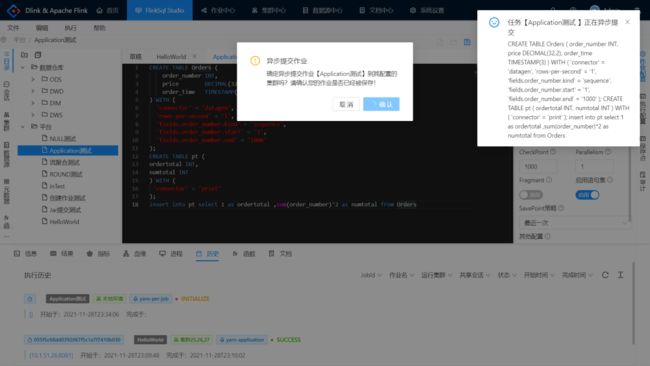
注意,执行历史需要手动刷新。
自动注册集群
点击集群中心——集群实例,即可发现自动注册的 Per-Job 集群。

查看 Flink Web UI
提交成功后,点击历史的蓝色地址即可快速打开 Flink Web UI地址。

从 Savepoint 处停止
在进程选项卡中选择自动注册的 Per-Job 集群,查看任务并 SavePoint-Cancel。
在右侧保存点选项卡可以查看该任务的所有 SavePoint 记录。

从 SavePoint 处启动
再次点击小火箭提交任务。
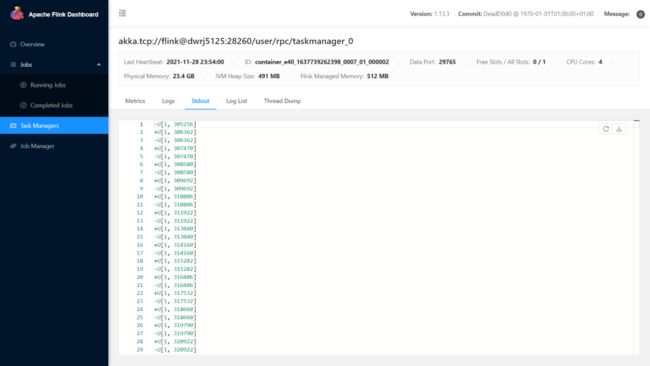
查看对应 Flink Web UI,从 Stdout 输出中证实 SavePoint 恢复成功。
六、Yarn-Application 实践
注册集群配置
使用之前注册的集群配置即可。
上传 dlink-app.jar
第一次使用时,需要将 dlink-app.jar 上传到 hdfs 指定目录,目录可修改如下:
50070 端口 浏览文件系统如下:

执行升级版 Hello World
作业配置:
- 执行模式:选中 yarn-application ;
快捷操作栏:
- 点击保存按钮保存当前所有配置;
- 点击小火箭异步提交作业。
其他同 Per-Job
其他操作同 yarn-per-job ,本文不再做描述。
提交 User Jar
作业中心—— Jar 管理,注册 User Jar 配置。

右边作业配置的可执行 Jar 选择刚刚注册的 Jar 配置,保存后点击小火箭提交作业。
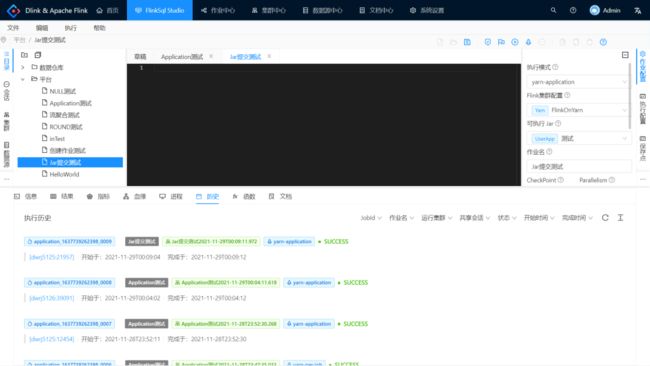
由于提交了个批作业,Yarn 可以发现已经执行完成并销毁集群了。

七、总结
综上所述,Dlink 的部署及搭建相关执行模式的步骤虽繁锁,但确实为一个一劳永逸的工作。目前 Dlink 已支持作为 FlinkSQL 交互式开发平台对多种执行模式下的 SQL 任务提交与基本运维管理,欢迎试用。此外 K8S 的支持将后续开放。
八、未来
Dlink 将紧跟 Flink 官方社区发展,为推广及发展 Flink 的应用而奋斗,打造 FlinkSQL 的最佳搭档的形象。