Cache的基本知识
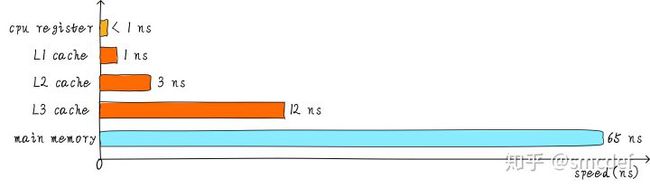
1. 不同等级cache速度之间关系:
2. Cache和CPU的关系:每个CPU上的HT(Hyper-Threading)共享L1 cache和L2 Cache,其中L1 Cache又分为单独的instruction cache(ICache)和data cache(DCache);不同物理CPU有自己的L1、L2 cache独立,每个socket有自己的L3 cache(也叫LLC),即同socket上的所有CPU共享LLC。如下图
Cache映射关系
直接映射缓存
考虑一个问题,CPU从0x0654地址读取一个字节,cache控制器是如何判断数据是否在cache中命中呢?cache大小相对于主存来说,可谓是小巫见大巫。所以cache肯定是只能缓存主存中极小一部分数据。我们如何根据地址在有限大小的cache中查找数据呢?现在硬件采取的做法是对地址进行散列(可以理解成地址取模操作)。我们接下来看看是如何做到的?
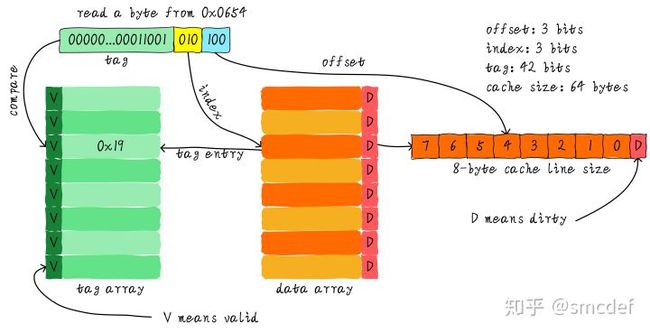
我们一共有8行cache line,cache line大小是8 Bytes。所以我们可以利用地址低3 bits(如上图地址蓝色部分)用来寻址8 bytes中某一字节,我们称这部分bit组合为offset。同理,8行cache line,为了覆盖所有行。我们需要3 bits(如上图地址黄色部分)查找某一行,这部分地址部分称之为index。现在我们知道,如果两个不同的地址,其地址的bit3-bit5如果完全一样的话,那么这两个地址经过硬件散列之后都会找到同一个cache line。所以,当我们找到cache line之后,只代表我们访问的地址对应的数据可能存在这个cache line中,但是也有可能是其他地址对应的数据。所以,我们又引入tag array区域,tag array和data array一一对应。每一个cache line都对应唯一一个tag,tag中保存的是整个地址位宽去除index和offset使用的bit剩余部分(如上图地址绿色部分)。tag、index和offset三者组合就可以唯一确定一个地址了。因此,当我们根据地址中index位找到cache line后,取出当前cache line对应的tag,然后和地址中的tag进行比较,如果相等,这说明cache命中。如果不相等,说明当前cache line存储的是其他地址的数据,这就是cache缺失。在上述图中,我们看到tag的值是0x19,和地址中的tag部分相等,因此在本次访问会命中。由于tag的引入,因此解答了我们之前的一个疑问“为什么硬件cache line不做成一个字节?”。这样会导致硬件成本的上升,因为原本8个字节对应一个tag,现在需要8个tag,占用了很多内存。
我们可以从图中看到tag旁边还有一个valid bit,这个bit用来表示cache line中数据是否有效(例如:1代表有效;0代表无效)。当系统刚启动时,cache中的数据都应该是无效的,因为还没有缓存任何数据。cache控制器可以根据valid bit确认当前cache line数据是否有效。所以,上述比较tag确认cache line是否命中之前还会检查valid bit是否有效。只有在有效的情况下,比较tag才有意义。如果无效,直接判定cache缺失。
直接映射缓存的优缺点
直接映射缓存在硬件设计上会更加简单,因此成本上也会较低。根据直接映射缓存的工作方式,我们可以画出主存地址0x00-0x88地址对应的cache分布图。

我们可以看到,地址0x00-0x3f地址处对应的数据可以覆盖整个cache。0x40-0x7f地址的数据也同样是覆盖整个cache。我们现在思考一个问题,如果一个程序试图依次访问地址0x00、0x40、0x80,cache中的数据会发生什么呢?首先我们应该明白0x00、0x40、0x80地址中index部分是一样的。因此,这3个地址对应的cache line是同一个。所以,当我们访问0x00地址时,cache会缺失,然后数据会从主存中加载到cache中第0行cache line。当我们访问0x40地址时,依然索引到cache中第0行cache line,由于此时cache line中存储的是地址0x00地址对应的数据,所以此时依然会cache缺失。然后从主存中加载0x40地址数据到第一行cache line中。同理,继续访问0x80地址,依然会cache缺失。这就相当于每次访问数据都要从主存中读取,所以cache的存在并没有对性能有什么提升。访问0x40地址时,就会把0x00地址缓存的数据替换。这种现象叫做cache颠簸(cache thrashing)。针对这个问题,我们引入多路组相连缓存。我们首先研究下最简单的两路组相连缓存的工作原理。
两路组相连缓存(Two-way set associative cache)
我们依然假设64 Bytes cache size,cache line size是8 Bytes。什么是路(way)的概念。我们将cache平均分成多份,每一份就是一路。因此,两路组相连缓存就是将cache平均分成2份,每份32 Bytes。如下图所示。

cache被分成2路,每路包含4行cache line。我们将所有索引一样的cache line组合在一起称之为组。例如,上图中一个组有两个cache line,总共4个组。我们依然假设从地址0x0654地址读取一个字节数据。由于cache line size是8 Bytes,因此offset需要3 bits,这和之前直接映射缓存一样。不一样的地方是index,在两路组相连缓存中,index只需要2 bits,因为一路只有4行cache line。上面的例子根据index找到第2行cache line(从0开始计算),第2行对应2个cache line,分别对应way 0和way 1。因此index也可以称作set index(组索引)。先根据index找到set,然后将组内的所有cache line对应的tag取出来和地址中的tag部分对比,如果其中一个相等就意味着命中。
因此,两路组相连缓存较直接映射缓存最大的差异就是:一个地址对应的数据可以对应2个cache line,而直接映射缓存一个地址只对应一个cache line。那么这究竟有什么好处呢?
两路组相连缓存优缺点
两路组相连缓存的硬件成本相对于直接映射缓存更高。因为其每次比较tag的时候需要比较多个cache line对应的tag(某些硬件可能还会做并行比较,增加比较速度,这就增加了硬件设计复杂度)。为什么我们还需要两路组相连缓存呢?因为其可以有助于降低cache颠簸可能性。那么是如何降低的呢?根据两路组相连缓存的工作方式,我们可以画出主存地址0x00-0x4f地址对应的cache分布图。
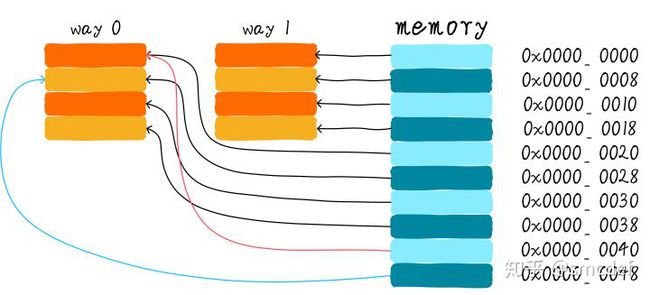
我们依然考虑直接映射缓存一节的问题“如果一个程序试图依次访问地址0x00、0x40、0x80,cache中的数据会发生什么呢?”。现在0x00地址的数据可以被加载到way 1,0x40可以被加载到way 0。这样是不是就在一定程度上避免了直接映射缓存的尴尬境地呢?在两路组相连缓存的情况下,0x00和0x40地址的数据都缓存在cache中。试想一下,如果我们是4路组相连缓存,后面继续访问0x80,也可能被被缓存。
因此,当cache size一定的情况下,组相连缓存对性能的提升最差情况下也和直接映射缓存一样,在大部分情况下组相连缓存效果比直接映射缓存好。同时,其降低了cache颠簸的频率。从某种程度上来说,直接映射缓存是组相连缓存的一种特殊情况,每个组只有一个cache line而已。因此,直接映射缓存也可以称作单路组相连缓存。
全相连缓存(Full associative cache)
既然组相连缓存那么好,如果所有的cache line都在一个组内。岂不是性能更好。是的,这种缓存就是全相连缓存。我们依然以64 Byts大小cache为例说明。
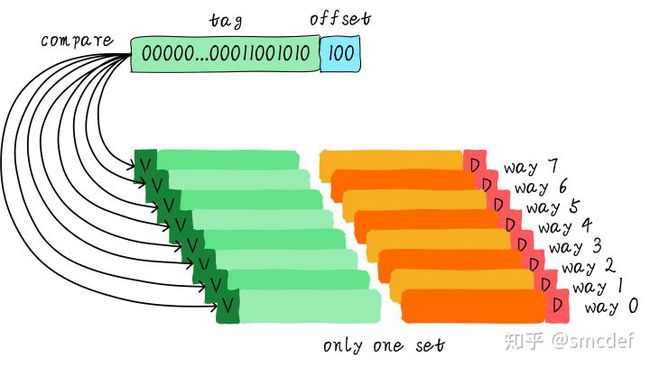
由于所有的cache line都在一个组内,因此地址中不需要set index部分。因为,只有一个组让你选择,间接来说就是你没得选。我们根据地址中的tag部分和所有的cache line对应的tag进行比较(硬件上可能并行比较也可能串行比较)。哪个tag比较相等,就意味着命中某个cache line。因此,在全相连缓存中,任意地址的数据可以缓存在任意的cache line中。所以,这可以最大程度的降低cache颠簸的频率。但是硬件成本上也是更高。
为什么以cache line为传输单位?
为什么cache line大小是cache控制器和主存之间数据传输的最小单位呢?这也是因为每个cache line只有一个dirty bit。这一个dirty bit代表着整个cache line是否被修改的状态。
Cache组织方式
我们都知道cache控制器根据地址查找判断是否命中,这里的地址究竟是虚拟地址(virtual address,VA)还是物理地址(physical address,PA)?我们应该清楚CPU发出对某个地址的数据访问,这个地址其实是虚拟地址,虚拟地址经过MMU转换成物理地址,最终从这个物理地址读取数据。因此cache的硬件设计既可以采用虚拟地址也可以采用物理地址甚至是取两者地址部分组合作为查找cache的依据。
虚拟高速缓存(VIVT)
我们首先介绍的是虚拟高速缓存,这种cache硬件设计简单。在cache诞生之初,大部分的处理器都使用这种方式。虚拟高速缓存以虚拟地址作为查找对象。如下图所示。
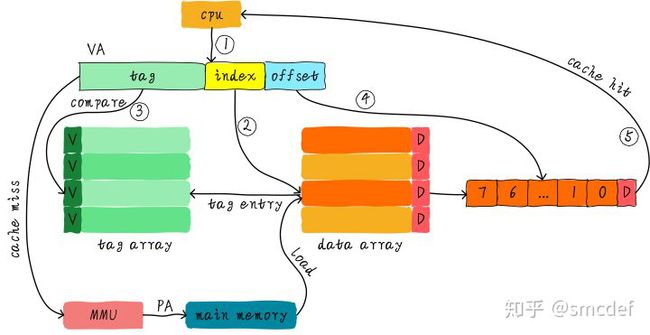
虚拟地址直接送到cache控制器,如果cache hit。直接从cache中返回数据给CPU。如果cache miss,则把虚拟地址发往MMU,经过MMU转换成物理地址,根据物理地址从主存(main memory)读取数据。由于我们根据虚拟地址查找高速缓存,所以我们是用虚拟地址中部分位域作为索引(index),找到对应的的cacheline。然后根据虚拟地址中部分位域作为标记(tag)来判断cache是否命中。因此,我们针对这种index和tag都取自虚拟地址的高速缓存称为虚拟高速缓存,简称VIVT(Virtually Indexed Virtually Tagged)。 虚拟高速缓存的优点是不需要每次读取或者写入操作的时候把虚拟地址经过MMU转换为物理地址,这在一定的程度上提升了访问cache的速度,毕竟MMU转换虚拟地址需要时间。同时硬件设计也更加简单。但是,正是使用了虚拟地址作为tag,所以引入很多软件使用上的问题。 操作系统在管理高速缓存正确工作的过程中,主要会面临两个问题。歧义(ambiguity)和别名(alias)。为了保证系统的正确工作,操作系统负责避免出现歧义和别名。
歧义(ambiguity)
歧义是指不同的数据在cache中具有相同的tag和index。cache控制器判断是否命中cache的依据就是tag和index,因此这种情况下,cache控制器根本没办法区分不同的数据。这就产生了歧义。什么情况下发生歧义呢?我们知道不同的物理地址存储不同的数据,只要相同的虚拟地址映射不同的物理地址就会出现歧义。例如两个互不相干的进程,就可能出现相同的虚拟地址映射不同的物理地址。假设A进程虚拟地址0x4000映射物理地址0x2000。B进程虚拟地址0x4000映射物理地址0x3000。当A进程运行时,访问0x4000地址会将物理地址0x2000的数据加载到cacheline中。当A进程切换到B进程的时候,B进程访问0x4000会怎样?当然是会cache hit,此时B进程就访问了错误的数据,B进程本来想得到物理地址0x3000对应的数据,但是却由于cache hit得到了物理地址0x2000的数据。操作系统如何避免歧义的发生呢?当我们切换进程的时候,可以选择flush所有的cache。flush cache操作有两种: - 使主存储器有效。针对write back高速缓存,首先应该使主存储器有效,保证已经修改数据的cacheline写回主存储器,避免修改的数据丢失。 - 使高速缓存无效。保证切换后的进程不会错误的命中上一个进程的缓存数据。
因此,切换后的进程刚开始执行的时候,将会由于大量的cache miss导致性能损失。所以,VIVT高速缓存明显的缺点之一就是经常需要flush cache以保证歧义不会发生,最终导致性能的损失。VIVT高速缓存除了面对歧义问题外,还面临另一个问题:别名(alias)。
别名(alias)
当不同的虚拟地址映射相同的物理地址,而这些虚拟地址的index不同,此时就发生了别名现象(多个虚拟地址被称为别名)。通俗点来说就是指同一个物理地址的数据被加载到不同的cacheline中就会出现别名现象。 考虑这样的一个例子。虚拟地址0x2000和0x4000都映射到相同的物理地址0x8000。这意味着进程既可以从0x2000读取数据,也能从地址0x4000读取数据。假设系统使用的是直接映射VIVT高速缓存,cache更新策略采用写回机制,并且使用虚拟地址的位<15...4>作为index。那么虚拟地址0x2000和虚拟地址0x4000的index分别是0x200和0x400。这意味同一个物理地址的数据会加载到不同的cacheline。假设物理地址0x8000存储的数据是0x1234。程序先访问0x2000把数据0x1234加载到第0x200(index)行cacheline中。接着访问0x4000,会将0x1234再一次的加载到第0x400(index)行cacheline中。现在程序将0x2000地址数据修改成0x5678。由于采用的是写回策略,因此修改的数据依然躺在cacheline中。当程序访问0x4000的时候由于cache hit导致读取到旧的数据0x1234。这就造成了数据不一致现象,这不是我们想要的结果。可以选择下面的方法避免这个问题。
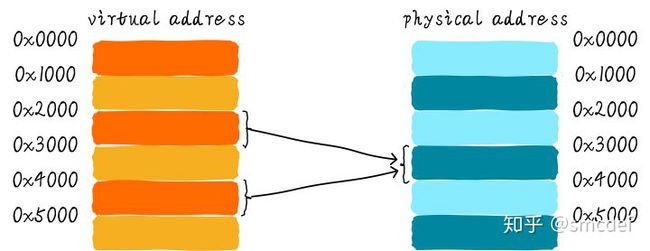
针对共享数据所在页的映射方式采用nocache映射。例如上面的例子中,0x2000和0x4000映射物理地址0x8000的时候都采用nocache的方式,这样不通过cache的访问,肯定可以避免这种问题。但是这样就损失了cache带来的性能好处。这种方法既适用于不同进程共享数据,也适用于同一个进程共享数据。 如果是不同进程之间共享数据,还可以在进程切换时主动flush cache(使主存储器有效和使高速缓存无效)的方式避免别名现象。但是,如果是同一个进程共享数据该怎么办?除了nocache映射之外,还可以有另一种解决方案。这种方法只针对直接映射高速缓存,并且使用了写分配机制有效。在建立共享数据映射时,保证每次分配的虚拟地址都索引到相同的cacheline。这种方式,后面还会重点说。
物理高速缓存(PIPT)
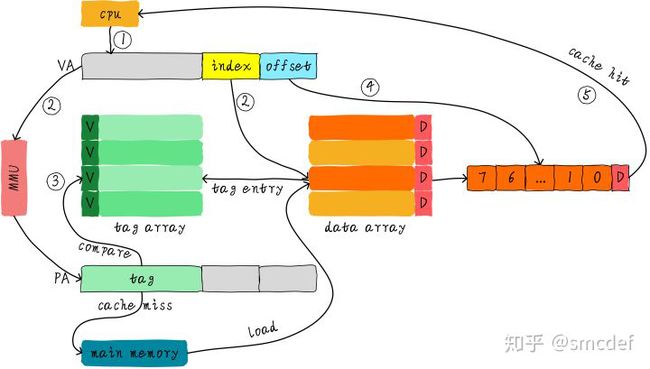
基于对VIVT高速缓存的认识,我们知道VIVT高速缓存存在歧义和名别两大问题。主要问题原因是:tag取自虚拟地址导致歧义,index取自虚拟地址导致别名。所以,如果想让操作系统少操心,最简单的方法是tag和index都取自物理地址。物理的地址tag部分是独一无二的,因此肯定不会导致歧义。而针对同一个物理地址,index也是唯一的,因此加载到cache中也是唯一的cacheline,所以也不会存在别名。我们称这种cache为物理高速缓存,简称PIPT(Physically Indexed Physically Tagged)。PIPT工作原理如下图所示。

CPU发出的虚拟地址经过MMU转换成物理地址,物理地址发往cache控制器查找确认是否命中cache。虽然PIPT方式在软件层面基本不需要维护,但是硬件设计上比VIVT复杂很多。因此硬件成本也更高。同时,由于虚拟地址每次都要翻译成物理地址,因此在查找性能上没有VIVT方式简洁高效,毕竟PIPT方式需要等待虚拟地址转换物理地址完成后才能去查找cache。顺便提一下,为了加快MMU翻译虚拟地址的速度,硬件上也会加入一块cache,作用是缓存虚拟地址和物理地址的映射关系,这块cache称之为TLB(Translation Lookaside Buffer)。当MMU需要转换虚拟地址时,首先从TLB中查找,如果cache hit,则直接返回物理地址。如果cache miss则需要MMU查找页表。这样就加快了虚拟地址转换物理地址的速度。如果系统采用的PIPT的cache,那么软件层面基本不需要任何的维护就可以避免歧义和别名问题。这是PIPT最大的优点。现在的CPU很多都是采用PIPT高速缓存设计。在Linux内核中,可以看到针对PIPT高速缓存的管理函数都是空函数,无需任何的管理。
物理标记的虚拟高速缓存(VIPT)
为了提升cache查找性能,我们不想等到虚拟地址转换物理地址完成后才能查找cache。因此,我们可以使用虚拟地址对应的index位查找cache,与此同时(硬件上同时进行)将虚拟地址发到MMU转换成物理地址。当MMU转换完成,同时cache控制器也查找完成,此时比较cacheline对应的tag和物理地址tag域,以此判断是否命中cache。我们称这种高速缓存为VIPT(Virtually Indexed Physically Tagged)。
VIPT以物理地址部分位作为tag,因此我们不会存在歧义问题。但是,采用虚拟地址作为index,所以可能依然存在别名问题。是否存在别名问题,需要考虑cache的结构,我们需要分情况考虑。
VIPT Cache什么情况不存在别名
我们知道VIPT的优点是查找cache和MMU转换虚拟地址同时进行,所以性能上有所提升。歧义问题虽然不存在了,但是别名问题依旧可能存在,那么什么情况下别名问题不会存在呢?Linux系统中映射最小的单位是页,一页大小是4KB。那么意味着虚拟地址和其映射的物理地址的位<11...0>是一样的。针对直接映射高速缓存,如果cache的size小于等于4KB,是否就意味着无论使用虚拟地址还是物理地址的低位查找cache结果都是一样呢?是的,因为虚拟地址和物理地址对应的index是一样的。这种情况,VIPT实际上相当于PIPT,软件维护上和PIPT一样。如果示例是一个四路组相连高速缓存呢?只要满足一路的cache的大小小于等于4KB,那么PIPT方式的cache也不会出现别名问题。
VIPT Cache的别名问题
假设系统使用的是直接映射高速缓存,cache大小是8KB,cacheline大小是256字节。这种情况下的VIPT就存在别名问题。因为index来自虚拟地址位<12...8>,虚拟地址和物理地址的位<11...8>是一样的,但是bit12却不一定相等。 假设虚拟地址0x0000和虚拟地址0x1000都映射相同的物理地址0x4000。那么程序读取0x0000时,系统将会从物理地址0x4000的数据加载到第0x00行cacheline。然后程序读取0x1000数据,再次把物理地址0x4000的数据加载到第0x10行cacheline。这不,别名出现了。相同物理地址的数据被加载到不同cacheline中。
如何解决VIPT Cache别名问题
我们接着上面的例子说明。首先出现问题的场景是共享映射,也就是多个虚拟地址映射同一个物理地址才可能出现问题。我们需要想办法避免相同的物理地址数据加载到不同的cacheline中。如何做到呢?那我们就避免上个例子中0x1000映射0x4000的情况发生。我们可以将虚拟地址0x2000映射到物理地址0x4000,而不是用虚拟地址0x1000。0x2000对应第0x00行cacheline,这样就避免了别名现象出现。因此,在建立共享映射的时候,返回的虚拟地址都是按照cache大小对齐的地址,这样就没问题了。如果是多路组相连高速缓存的话,返回的虚拟地址必须是满足一路cache大小对齐。在Linux的实现中,就是通过这种方法解决别名问题。
总结
VIVT Cache问题太多,软件维护成本过高,是最难管理的高速缓存。所以现在基本只存在历史的文章中。现在我们基本看不到硬件还在使用这种方式的cache。现在使用的方式是PIPT或者VIPT。如果多路组相连高速缓存的一路的大小小于等于4KB,一般硬件采用VIPT方式,因为这样相当于PIPT,岂不美哉。当然,如果一路大小大于4KB,一般采用PIPT方式,也不排除VIPT方式,这就需要操作系统多操点心了。
linux查看Cache信息的方式
Linux下查看CPU Cache级数,每级大小
1. 第一种方法:
dmesg | grep cache
2. 第二种方法:
[root@gc15 ~]# ls /sys/devices/system/cpu/cpu0/cache/index
index0/ index1/ index2/ index3/
其中index0和index1分别是L1 Cache的DCache和ICache。
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index0/level
1
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index0/type
Data
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index0/size
32K
一级cache, Instruction cache
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/level
1
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/type
Instruction
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/size
32K
index2为L2cache的信息,同物理CPU共享的
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index2/level
2
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/type
Unified
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index2/size
256K
Index3为L3 cache,同socket共享的
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/level
3
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/type
Unified
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/size
12288K
查看Cache的关联方式
在 /sys/devices/system/cpu/中查看相应的文件夹
如查看cpu0的一级缓存中有多少路(Cache被平均分成了几份)
$cat /sys/devices/system/cpu/cpu0/cache/index0/ways_of_associativity
$8
如查看cpu0 的一级缓存中的有多少组(每一份中有多少个cacheline),
$ cat /sys/devices/system/cpu/cpu0/cache/index0/number_of_sets
$64
查看cache_line的大小
上面以本人电脑的cpu一级缓存为例知道了cpu0的一级缓存的大小:32k,其包含64个(sets)组,每组有8(ways),则可以算出每一个way(cache_line)的大小 cache_line = 32*1024/(64*8)=64 bytes。当然我们也可以通过以下命令查出cache_line的大小(单位是字节)
$ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
或者
$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R) Core(TM) i7-4770K CPU @ 3.50GHz
stepping : 3
cpu MHz : 3497.664
cache size : 8192 KB
physical id : 0
siblings : 8
core id : 0
cpu cores : 4
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology tsc_reliable nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 fma cx16 xtpr pdcm sse4_1 sse4_2 movbe popcnt aes xsave avx lahf_lm abm ida arat tpr_shadow vnmi flexpriority ept vpid
bogomips : 6995.32
clflush size : 64
cache_alignment : 64
address sizes : 39 bits physical, 48 bits virtual