图像分割技术及经典实例分割网络Mask R-CNN(含基于Keras Python源码定义)
图像分割技术及经典实例分割网络Mask R-CNN(含Python源码定义)
文章目录
- 图像分割技术及经典实例分割网络Mask R-CNN(含Python源码定义)
-
- 1. 图像分割技术概述
- 2. FCN与语义分割
-
- 2.1 FCN简介
- 2.2 反卷积
- 2.2 FCN与语义分割的关系
- 3. Mask R-CNN
-
- 3.1 实例分割的难点
- 3.2 FPN(特征金字塔)
- 3.2 Mask R-CNN
- 3.3 RoiAlign
- 3.4 分割掩膜
- 4. 工程实践
1. 图像分割技术概述
图像分割技术是可以浅显的理解为精细化的目标检测过程,由于之前的目标检测算法只能使用标定框框定规则区域,从而进行分类,标出目标的大题区域,但是,在譬如自动驾驶领域,仅仅只有一个规则的区域去框定目标还是不够的,比如碰到车道线,那么仅仅用一个矩形区域框定车道线并不能准确地指导车辆的下一步动向,所以我们需要一个能够追溯细节的新应用领域,来将检测到的目标精细化。
图像分割即为图片的每个对象创建一个像素级的掩膜,这样可以追溯到目标轮廓的更多细节。下图为细菌的图像分割例子,为每个细菌做了图像分割。

图像分类有两类:
-
语义分割:语义分割关注类别,忽略个体实例。

-
实例分割:实力分割关注个体实例。

为了使得概念更加直观,下图说明了分类、目标检测、语义分割、实例分割的不同任务直观示意图。

2. FCN与语义分割
2.1 FCN简介
FCN即Fully Convolutional Networks,全卷积网络,FCN将传统卷积网络后面的全连接层换成了卷积层,这样网络输出不再是类别而是heatmap;同时为了解决因为卷积和池化对图像尺寸的影响,提出使用上采样的方式恢复尺寸。
传统分类使用的网络结构一般通过在最后连接全连接层,它会将原来二维的图像信息“压扁”成一维的(分类),从而丢失了空间信息,最后训练输出一个标量,这就是我们的分类标签。FCN网络和一般的网络的最大不同是,FCN产生的输出和输入的维度保持一致,即改变原本的CNN网络末端的全连接层,将其调整为卷积层,这样原本的分类网络最终输出一个热度图类型的图像。

其实在笔者的上一篇博文就提过全卷积,全卷积网络最大的特点是可以适应任意尺寸的输入,因为其不受最终分类数量的限制。
2.2 反卷积
反卷积又称转置卷积,它并不是正向卷积的完全逆过程。反卷积是一种特殊的正向卷积,先按照一
定的比例通过补0来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。
详细参考此文章《反卷积(Transposed Convolution)详细推导》
反卷积的处理步骤概括:
- 将上一层的卷积核反转(上下左右方向进行反转)。
- 将上一层卷积的结果作为输入,做补0扩充操作,即往每一个元素后面补0。这一步是根据步长来的,对于每个元素沿着步长方向补(步长减一)个0。例如,步长为1就不用补0了
- 在扩充后的输入基础上再对整体补0。以原始输入的shape作为输出shape,按照卷积padding规则,计算pading的补0的位置及个数,得到补0的位置及个数。
- 将补0后的卷积结果作为真正的输入,反转后的卷积核为filter,进行步长为1的卷积操作。
计算padding按规则补0时,统一按照padding=‘SAME’、步长为 1 × 1 1\times 1 1×1的方式来计算


卷积输出通道公式:
o = i − k + 2 × p s + 1 o=\frac{i-k+2\times p}{s}+1 o=si−k+2×p+1
反卷积输入输出通道关系计算公式:
i = ( o − 1 ) × s + k − 2 × p i=(o-1)\times s+k-2\times p i=(o−1)×s+k−2×p
注意
通过反卷积操作并不能还原出卷积之前的图片,只能还原出卷积之前图片的尺寸。卷积和反卷积,并没有什么关系,操作的过程也都是不可逆的。
反卷积的应用场景:
- 反卷积/转置卷积在语义分割领域应用很广,如果说pooling层用于特征降维,那么在多个pooling
层后,就需要用转置卷积来进行分辨率的恢复。 - 如果up-sampling采用双线性插值进行分辨率的提升,这种提升是非学习的。采用反卷积来完成上采样的工作,就可以通过学习的方式得到更高的精度

反卷积的局限性:
矩阵稀疏,有大量的0元素,因此大量的信息是无用的,反卷积所用的转置矩阵计算是非常消耗计算资源的。
2.2 FCN与语义分割的关系
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。
对全卷积网络的末端再进行upsampling(上采样),即可得到和原图大小一样的输出,这就是
热度图了。这里上采样采用了deconvolutional(反卷积)的方法。
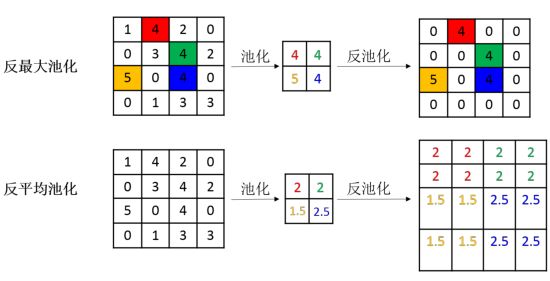
反最大池化、反平均池化
池化操作中最常见的最大池化和平均池化,因此最常见的反池化操作有反最大池化和反平均池化。
反最大池化需要记录池化时最大值的位置,反平均池化不需要此过程。
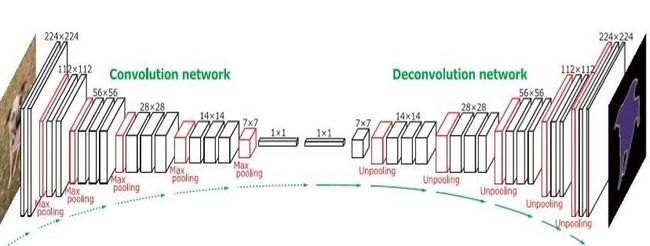
语义分割的一种实现-DeconvNet
3. Mask R-CNN
3.1 实例分割的难点
实例分割(instance segmentation)的难点在于:需要同时检测出目标的位置并且对目标进行分割,所以这就需要融合目标检测(框出目标的位置)以及语义分割(对像素进行分类,分割出目标)方法。

3.2 FPN(特征金字塔)
FPN即Feature Pyramid Networks,特征金字塔,其提出的背景为目标检测任务和语义分割任务里面常常需要检测小目标。但是当小目标比较小时,可能在原图里面只有几十个像素点。对于深度卷积网络,从一个特征层卷积到另一个特征层,无论步长是1还是2还是更多,卷积核都要遍布整个图片进行卷积,大的目标所占的像素点比小目标多,所以大的目标被经过卷积核的次数远比小的目标多,所以在下一个特征层里,会更多的反应大目标的特点。特别是在步长大于等于2的情况下,大目标的特点更容易得到保留,小目标的特征点容易被跳过。因此,经过很多层的卷积之后,小目标的特点会越来越少。
例如此图中的猫,对于周边的落叶来说,明显差距很大。

特征图(feature map)用蓝色轮廓表示,较粗的轮廓表示语义上更强的特征图。
- 对于(a),使用图像金字塔构建特征金字塔。特征是根据每个不同大小比例的图像独立计算的,每计算一次特征都需要resize一下图片大小,耗时,速度很慢。
- 对于(b),检测系统都在采用的为了更快地检测而使用的单尺度特征检测。
- 对于©,由卷积计算的金字塔特征层次来进行目标位置预测,但底层feature map特征表达能力不足。
- 对于(d),特征金字塔网络(FPN)和b,c一样快,但更准确。

FPN的提出是为了实现更好的feature maps融合,一般的网络都是直接使用最后一层的feature maps,虽然最后一层的feature maps 语义强,但是位置和分辨率都比较低,容易检测不到比较小的物体。FPN的功能就是融合了底层到高层的feature maps ,从而充分的利用了提取到的各个阶段的特征(ResNet中的C2-C5)。

3.2 Mask R-CNN
Mask R-CNN可算作是Faster R-CNN的升级版。Faster R-CNN广泛用于目标检测。对于给定图像,它会给图中每个对象加上类别标签与边界框坐标。Mask R-CNN框架是以Faster R-CNN为基础而架的。因此,针对给定图像, Mask R-CNN不仅会给每个对象添加类标签与边界框坐标,还会返回其对象掩膜。

Mask R-CNN的网络结构


在Mask R-CNN的设计中网络在进行目标检测的同时进行了实例分割。
Mask R-CNN的大体框架与Faster-RCNN框架相似,可以说在基础特征网络之后又加入了全连接的分割子网,由原来的两个任务(分类+回归)变为了三个任务(分类+回归+分割)。Mask R-CNN 是一个两阶段的框架,第一个阶段扫描图像并生成候选区域(proposals,即有可能包含一个目标的区域),第二阶段分类候选区域并生成边界框和掩码。
Faster R-CNN请参考笔者的上一篇博文《CV学习笔记-Faster-RCNN》

Mask R-CNN的不同
- 使用ResNet网络作为backbone
- 将 Roi Pooling 层替换成了 RoiAlign
- 添加并列的 Mask 层
- 引入FPN 和 FCN

Mask R-CNN的处理流程:
- 输入图像,进行预处理
- 将预处理后的图像信息输入到预训练好的神经网络中(例如ResNet)获得feature map
- 对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI
- 将这些候选的ROI送入RPN网络进行二值分类(positive或negative)和BB回归,过滤掉一部分候选的ROI(截止到目前,Mask和Faster完全相同);
- 对这些剩下的ROI进行ROIAlign操作(ROIAlign为Mask R-CNN创新点1,比ROIPooling有长足进步);
- 最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)(引入FCN生成Mask是创新点2,使得此网络可以进行分割型任务)。
Mask R-CNN使用Resnet101作为backbone对应为CNN提取主干特征网络部分
ResNet的相关内容请参照笔者之前的博客《CV学习笔记-ResNet》
特征金字塔FPN的构建是为了实现特征多尺度的融合,在Mask R-CNN当中,我们取出在主干特征提取网络中长宽压缩了两次C2、三次C3、四次C4、五次C5的结果来进行特征金字塔结构的构造。
具体构造过程如下:

P2-P5是将来用于预测物体的bbox,box-regression,mask的。P2-P6是用于训练RPN的,即P6只用于RPN网络中。
3.3 RoiAlign
Mask-RCNN中提出了一个新的思想就是RoIAlign,其实RoIAlign就是在RoI pooling上稍微改动过来的,但是为什么在模型中不继续使用RoI pooling呢?
Roi pooling请参考笔者博客CV学习笔记-Faster-RCNN 3.3节

在RoI pooling中出现了两次的取整,虽然在feature maps上取整看起来只是小数级别的数,但是当
把feature map还原到原图上时就会出现很大的偏差,比如第一次的取整是舍去了0.78
(665/32=20.78),还原到原图时是20*32=640,第一次取整就存在了25个像素点的偏差,在第二
次的取整后的偏差更加的大。对于分类和物体检测来说可能这不是一个很大的误差,但是对于实
例分割而言,这是一个非常大的偏差,因为mask出现没对齐的话在视觉上是很明显的。而RoIAlign
的提出就是为了解决这个不对齐问题。

简单概括就是RoiAlign取消了取整的简单取舍,使用双线性插值的做法得到固定四个点坐标的像素值,从而使得不连续的操作变得连续起来返回到原图的时候误差将会更小。
它充分的利用了原图中虚拟点(比如20.56这个浮点数。像素位置都是整数值,没有浮点值)四周
的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对
应的像素值估计出来。
示例:
蓝色的虚线框表示卷积后获得的feature map,黑色实线框表示ROI feature。
最后需要输出的大小是2x2,那么我们就利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,最后得到相应的输出。
然后在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。我们的整个过程中没有用到量化操作,没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。
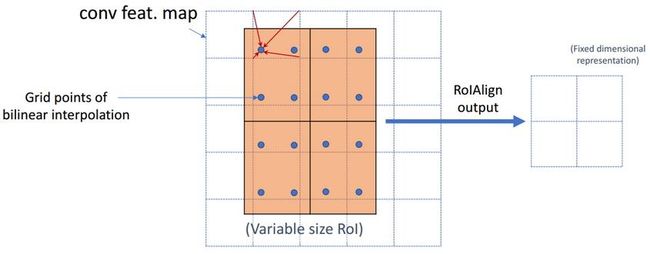
RoiAlign的输出将作为分割掩膜的依据。
3.4 分割掩膜
获得感兴趣区域(ROI)后,给已有框架加上一个掩膜分支,每个囊括特定对象的区域都会被赋予一个掩膜。每个区域都会被赋予一个 m × m m\times m m×m掩膜,并按比例放大以便推断。


mask语义分割信息的获取
在之前的步骤中,我们获得了预测框,我们把这个预测框作为mask模型的区域截取部分,利用这个预测框对mask模型中用到的公用特征层进行截取。截取后,利用mask模型再对像素点进行分类,获得语义分割结果。
mask分支采用FCN对每个RoI产生一个 K × m × m K\times m \times m K×m×m的输出,即K个分辨率为 m × m m\times m m×m的二值的掩膜,K为分类物体的种类数目。
K × m × m K\times m \times m K×m×m二值mask结构解释:最终的FCN输出一个K层的mask,每一层为一类。用0.5作为阈值进
行二值化,产生背景和前景的分割Mask。
对于预测的二值掩膜输出,我们对每个像素点应用sigmoid函数(或softmax等),整体损失定义
为交叉熵。引入预测K个输出的机制,允许每个类都生成独立的掩膜,避免类间竞争。这样做解
耦了掩膜和种类预测。

Mask R-CNN的损失函数为:
L = L c l s + L b o x + L m a s k L=L_{cls}+L_{box}+L_{mask} L=Lcls+Lbox+Lmask
Lmask 使得网络能够输出每一类的 mask,且不会有不同类别 mask 间的竞争:
- 分类网络分支预测 object 类别标签,以选择输出 mask。对每一个ROI,如果检测得到的ROI属于哪一个分类,就只使用哪一个分支的交叉熵误差作为误差值进行计算。
- 举例说明:分类有3类(猫,狗,人),检测得到当前ROI属于“人”这一类,那么所使用的Lmask为“人”这一分支的mask,即每个class类别对应一个mask可以有效避免类间竞争(其他class不贡献Loss)
- 对每一个像素应用sigmoid,然后取RoI上所有像素的交叉熵的平均值作为Lmask。
网络输出如何将 14 × 14 14\times 14 14×14或者 28 × 28 28\times 28 28×28大小的mask映射到原图是个问题
其实一个后处理,将模型预测的mask通过resize得到与proposal中目标相同大小的mask即可。
4. 工程实践
代码工程代码稍大,所以摘取网络定义的核心源码环节展示:
from keras.layers import Input,ZeroPadding2D,Conv2D,MaxPooling2D,BatchNormalization,Activation,UpSampling2D,Add,Lambda,Concatenate
from keras.layers import Reshape,TimeDistributed,Dense,Conv2DTranspose
from keras.models import Model
import keras.backend as K
from nets.resnet import get_resnet
from nets.layers import ProposalLayer,PyramidROIAlign,DetectionLayer,DetectionTargetLayer
from nets.mrcnn_training import *
from utils.anchors import get_anchors
from utils.utils import norm_boxes_graph,parse_image_meta_graph
import tensorflow as tf
import numpy as np
'''
TimeDistributed:
对FPN网络输出的多层卷积特征进行共享参数。
TimeDistributed的意义在于使不同层的特征图共享权重。
'''
#------------------------------------#
# 五个不同大小的特征层会传入到
# RPN当中,获得建议框
#------------------------------------#
def rpn_graph(feature_map, anchors_per_location):
shared = Conv2D(512, (3, 3), padding='same', activation='relu',
name='rpn_conv_shared')(feature_map)
x = Conv2D(2 * anchors_per_location, (1, 1), padding='valid',
activation='linear', name='rpn_class_raw')(shared)
# batch_size,num_anchors,2
# 代表这个先验框对应的类
rpn_class_logits = Reshape([-1,2])(x)
rpn_probs = Activation(
"softmax", name="rpn_class_xxx")(rpn_class_logits)
x = Conv2D(anchors_per_location * 4, (1, 1), padding="valid",
activation='linear', name='rpn_bbox_pred')(shared)
# batch_size,num_anchors,4
# 这个先验框的调整参数
rpn_bbox = Reshape([-1,4])(x)
return [rpn_class_logits, rpn_probs, rpn_bbox]
#------------------------------------#
# 建立建议框网络模型
# RPN模型
#------------------------------------#
def build_rpn_model(anchors_per_location, depth):
input_feature_map = Input(shape=[None, None, depth],
name="input_rpn_feature_map")
outputs = rpn_graph(input_feature_map, anchors_per_location)
return Model([input_feature_map], outputs, name="rpn_model")
#------------------------------------#
# 建立classifier模型
# 这个模型的预测结果会调整建议框
# 获得最终的预测框
#------------------------------------#
def fpn_classifier_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True,
fc_layers_size=1024):
# ROI Pooling,利用建议框在特征层上进行截取
# Shape: [batch, num_rois, POOL_SIZE, POOL_SIZE, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_classifier")([rois, image_meta] + feature_maps)
# Shape: [batch, num_rois, 1, 1, fc_layers_size],相当于两次全连接
x = TimeDistributed(Conv2D(fc_layers_size, (pool_size, pool_size), padding="valid"),
name="mrcnn_class_conv1")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_class_bn1')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, 1, 1, fc_layers_size]
x = TimeDistributed(Conv2D(fc_layers_size, (1, 1)),
name="mrcnn_class_conv2")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_class_bn2')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, fc_layers_size]
shared = Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2),
name="pool_squeeze")(x)
# Classifier head
# 这个的预测结果代表这个先验框内部的物体的种类
mrcnn_class_logits = TimeDistributed(Dense(num_classes),
name='mrcnn_class_logits')(shared)
mrcnn_probs = TimeDistributed(Activation("softmax"),
name="mrcnn_class")(mrcnn_class_logits)
# BBox head
# 这个的预测结果会对先验框进行调整
# [batch, num_rois, NUM_CLASSES * (dy, dx, log(dh), log(dw))]
x = TimeDistributed(Dense(num_classes * 4, activation='linear'),
name='mrcnn_bbox_fc')(shared)
# Reshape to [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
mrcnn_bbox = Reshape((-1, num_classes, 4), name="mrcnn_bbox")(x)
return mrcnn_class_logits, mrcnn_probs, mrcnn_bbox
def build_fpn_mask_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True):
# ROI Align,利用建议框在特征层上进行截取
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_mask")([rois, image_meta] + feature_maps)
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv1")(x)
x = TimeDistributed(BatchNormalization(),
name='mrcnn_mask_bn1')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv2")(x)
x = TimeDistributed(BatchNormalization(),
name='mrcnn_mask_bn2')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv3")(x)
x = TimeDistributed(BatchNormalization(),
name='mrcnn_mask_bn3')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv4")(x)
x = TimeDistributed(BatchNormalization(),
name='mrcnn_mask_bn4')(x, training=train_bn)
x = Activation('relu')(x)
# Shape: [batch, num_rois, 2xMASK_POOL_SIZE, 2xMASK_POOL_SIZE, channels]
x = TimeDistributed(Conv2DTranspose(256, (2, 2), strides=2, activation="relu"),
name="mrcnn_mask_deconv")(x)
# 反卷积后再次进行一个1x1卷积调整通道,使其最终数量为numclasses,代表分的类
x = TimeDistributed(Conv2D(num_classes, (1, 1), strides=1, activation="sigmoid"),
name="mrcnn_mask")(x)
return x
def get_predict_model(config):
h, w = config.IMAGE_SHAPE[:2]
if h / 2**6 != int(h / 2**6) or w / 2**6 != int(w / 2**6):
raise Exception("Image size must be dividable by 2 at least 6 times "
"to avoid fractions when downscaling and upscaling."
"For example, use 256, 320, 384, 448, 512, ... etc. ")
# 输入进来的图片必须是2的6次方以上的倍数
input_image = Input(shape=[None, None, config.IMAGE_SHAPE[2]], name="input_image")
# meta包含了一些必要信息
input_image_meta = Input(shape=[config.IMAGE_META_SIZE],name="input_image_meta")
# 输入进来的先验框
input_anchors = Input(shape=[None, 4], name="input_anchors")
# 获得Resnet里的压缩程度不同的一些层
_, C2, C3, C4, C5 = get_resnet(input_image, stage5=True, train_bn=config.TRAIN_BN)
# 组合成特征金字塔的结构
# P5长宽共压缩了5次
# Height/32,Width/32,256
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
# P4长宽共压缩了4次
# Height/16,Width/16,256
P4 = Add(name="fpn_p4add")([
UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
# P4长宽共压缩了3次
# Height/8,Width/8,256
P3 = Add(name="fpn_p3add")([
UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
# P4长宽共压缩了2次
# Height/4,Width/4,256
P2 = Add(name="fpn_p2add")([
UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
# 各自进行一次256通道的卷积,此时P2、P3、P4、P5通道数相同
# Height/4,Width/4,256
P2 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
# Height/8,Width/8,256
P3 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
# Height/16,Width/16,256
P4 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
# Height/32,Width/32,256
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
# 在建议框网络里面还有一个P6用于获取建议框
# Height/64,Width/64,256
P6 = MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# P2, P3, P4, P5, P6可以用于获取建议框
rpn_feature_maps = [P2, P3, P4, P5, P6]
# P2, P3, P4, P5用于获取mask信息
mrcnn_feature_maps = [P2, P3, P4, P5]
anchors = input_anchors
# 建立RPN模型
rpn = build_rpn_model(len(config.RPN_ANCHOR_RATIOS), config.TOP_DOWN_PYRAMID_SIZE)
rpn_class_logits, rpn_class, rpn_bbox = [],[],[]
# 获得RPN网络的预测结果,进行格式调整,把五个特征层的结果进行堆叠
for p in rpn_feature_maps:
logits,classes,bbox = rpn([p])
rpn_class_logits.append(logits)
rpn_class.append(classes)
rpn_bbox.append(bbox)
rpn_class_logits = Concatenate(axis=1,name="rpn_class_logits")(rpn_class_logits)
rpn_class = Concatenate(axis=1,name="rpn_class")(rpn_class)
rpn_bbox = Concatenate(axis=1,name="rpn_bbox")(rpn_bbox)
# 此时获得的rpn_class_logits、rpn_class、rpn_bbox的维度是
# rpn_class_logits : Batch_size, num_anchors, 2
# rpn_class : Batch_size, num_anchors, 2
# rpn_bbox : Batch_size, num_anchors, 4
proposal_count = config.POST_NMS_ROIS_INFERENCE
# Batch_size, proposal_count, 4
# 对先验框进行解码
rpn_rois = ProposalLayer(
proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD,
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])
# 获得classifier的结果
mrcnn_class_logits, mrcnn_class, mrcnn_bbox =\
fpn_classifier_graph(rpn_rois, mrcnn_feature_maps, input_image_meta,
config.POOL_SIZE, config.NUM_CLASSES,
train_bn=config.TRAIN_BN,
fc_layers_size=config.FPN_CLASSIF_FC_LAYERS_SIZE)
detections = DetectionLayer(config, name="mrcnn_detection")(
[rpn_rois, mrcnn_class, mrcnn_bbox, input_image_meta])
detection_boxes = Lambda(lambda x: x[..., :4])(detections)
# 获得mask的结果
mrcnn_mask = build_fpn_mask_graph(detection_boxes, mrcnn_feature_maps,
input_image_meta,
config.MASK_POOL_SIZE,
config.NUM_CLASSES,
train_bn=config.TRAIN_BN)
# 作为输出
model = Model([input_image, input_image_meta, input_anchors],
[detections, mrcnn_class, mrcnn_bbox,
mrcnn_mask, rpn_rois, rpn_class, rpn_bbox],
name='mask_rcnn')
return model
def get_train_model(config):
h, w = config.IMAGE_SHAPE[:2]
if h / 2**6 != int(h / 2**6) or w / 2**6 != int(w / 2**6):
raise Exception("Image size must be dividable by 2 at least 6 times "
"to avoid fractions when downscaling and upscaling."
"For example, use 256, 320, 384, 448, 512, ... etc. ")
# 输入进来的图片必须是2的6次方以上的倍数
input_image = Input(shape=[None, None, config.IMAGE_SHAPE[2]], name="input_image")
# meta包含了一些必要信息
input_image_meta = Input(shape=[config.IMAGE_META_SIZE],name="input_image_meta")
# RPN建议框网络的真实框信息
input_rpn_match = Input(
shape=[None, 1], name="input_rpn_match", dtype=tf.int32)
input_rpn_bbox = Input(
shape=[None, 4], name="input_rpn_bbox", dtype=tf.float32)
# 种类信息
input_gt_class_ids = Input(shape=[None], name="input_gt_class_ids", dtype=tf.int32)
# 框的位置信息
input_gt_boxes = Input(shape=[None, 4], name="input_gt_boxes", dtype=tf.float32)
# 标准化到0-1之间
gt_boxes = Lambda(lambda x: norm_boxes_graph(x, K.shape(input_image)[1:3]))(input_gt_boxes)
# mask语义分析信息
# [batch, height, width, MAX_GT_INSTANCES]
if config.USE_MINI_MASK:
input_gt_masks = Input(shape=[config.MINI_MASK_SHAPE[0],config.MINI_MASK_SHAPE[1], None],name="input_gt_masks", dtype=bool)
else:
input_gt_masks = Input(shape=[config.IMAGE_SHAPE[0], config.IMAGE_SHAPE[1], None],name="input_gt_masks", dtype=bool)
# 获得Resnet里的压缩程度不同的一些层
_, C2, C3, C4, C5 = get_resnet(input_image, stage5=True, train_bn=config.TRAIN_BN)
# 组合成特征金字塔的结构
# P5长宽共压缩了5次
# Height/32,Width/32,256
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
# P4长宽共压缩了4次
# Height/16,Width/16,256
P4 = Add(name="fpn_p4add")([
UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
# P4长宽共压缩了3次
# Height/8,Width/8,256
P3 = Add(name="fpn_p3add")([
UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
# P4长宽共压缩了2次
# Height/4,Width/4,256
P2 = Add(name="fpn_p2add")([
UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
# 各自进行一次256通道的卷积,此时P2、P3、P4、P5通道数相同
# Height/4,Width/4,256
P2 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
# Height/8,Width/8,256
P3 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
# Height/16,Width/16,256
P4 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
# Height/32,Width/32,256
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
# 在建议框网络里面还有一个P6用于获取建议框
# Height/64,Width/64,256
P6 = MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# P2, P3, P4, P5, P6可以用于获取建议框
rpn_feature_maps = [P2, P3, P4, P5, P6]
# P2, P3, P4, P5用于获取mask信息
mrcnn_feature_maps = [P2, P3, P4, P5]
anchors = get_anchors(config,config.IMAGE_SHAPE)
# 拓展anchors的shape,第一个维度拓展为batch_size
anchors = np.broadcast_to(anchors, (config.BATCH_SIZE,) + anchors.shape)
# 将anchors转化成tensor的形式
anchors = Lambda(lambda x: tf.Variable(anchors), name="anchors")(input_image)
# 建立RPN模型
rpn = build_rpn_model(len(config.RPN_ANCHOR_RATIOS), config.TOP_DOWN_PYRAMID_SIZE)
rpn_class_logits, rpn_class, rpn_bbox = [],[],[]
# 获得RPN网络的预测结果,进行格式调整,把五个特征层的结果进行堆叠
for p in rpn_feature_maps:
logits,classes,bbox = rpn([p])
rpn_class_logits.append(logits)
rpn_class.append(classes)
rpn_bbox.append(bbox)
rpn_class_logits = Concatenate(axis=1,name="rpn_class_logits")(rpn_class_logits)
rpn_class = Concatenate(axis=1,name="rpn_class")(rpn_class)
rpn_bbox = Concatenate(axis=1,name="rpn_bbox")(rpn_bbox)
# 此时获得的rpn_class_logits、rpn_class、rpn_bbox的维度是
# rpn_class_logits : Batch_size, num_anchors, 2
# rpn_class : Batch_size, num_anchors, 2
# rpn_bbox : Batch_size, num_anchors, 4
proposal_count = config.POST_NMS_ROIS_TRAINING
# Batch_size, proposal_count, 4
rpn_rois = ProposalLayer(
proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD,
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])
active_class_ids = Lambda(
lambda x: parse_image_meta_graph(x)["active_class_ids"]
)(input_image_meta)
if not config.USE_RPN_ROIS:
# 使用外部输入的建议框
input_rois = Input(shape=[config.POST_NMS_ROIS_TRAINING, 4],
name="input_roi", dtype=np.int32)
# Normalize coordinates
target_rois = Lambda(lambda x: norm_boxes_graph(
x, K.shape(input_image)[1:3]))(input_rois)
else:
# 利用预测到的建议框进行下一步的操作
target_rois = rpn_rois
"""找到建议框的ground_truth
Inputs:
proposals: [batch, N, (y1, x1, y2, x2)]建议框
gt_class_ids: [batch, MAX_GT_INSTANCES]每个真实框对应的类
gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)]真实框的位置
gt_masks: [batch, height, width, MAX_GT_INSTANCES]真实框的语义分割情况
Returns:
rois: [batch, TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)]内部真实存在目标的建议框
target_class_ids: [batch, TRAIN_ROIS_PER_IMAGE]每个建议框对应的类
target_deltas: [batch, TRAIN_ROIS_PER_IMAGE, (dy, dx, log(dh), log(dw)]每个建议框应该有的调整参数
target_mask: [batch, TRAIN_ROIS_PER_IMAGE, height, width]每个建议框语义分割情况
"""
rois, target_class_ids, target_bbox, target_mask =\
DetectionTargetLayer(config, name="proposal_targets")([
target_rois, input_gt_class_ids, gt_boxes, input_gt_masks])
# 找到合适的建议框的classifier预测结果
mrcnn_class_logits, mrcnn_class, mrcnn_bbox =\
fpn_classifier_graph(rois, mrcnn_feature_maps, input_image_meta,
config.POOL_SIZE, config.NUM_CLASSES,
train_bn=config.TRAIN_BN,
fc_layers_size=config.FPN_CLASSIF_FC_LAYERS_SIZE)
# 找到合适的建议框的mask预测结果
mrcnn_mask = build_fpn_mask_graph(rois, mrcnn_feature_maps,
input_image_meta,
config.MASK_POOL_SIZE,
config.NUM_CLASSES,
train_bn=config.TRAIN_BN)
output_rois = Lambda(lambda x: x * 1, name="output_rois")(rois)
# Losses
rpn_class_loss = Lambda(lambda x: rpn_class_loss_graph(*x), name="rpn_class_loss")(
[input_rpn_match, rpn_class_logits])
rpn_bbox_loss = Lambda(lambda x: rpn_bbox_loss_graph(config, *x), name="rpn_bbox_loss")(
[input_rpn_bbox, input_rpn_match, rpn_bbox])
class_loss = Lambda(lambda x: mrcnn_class_loss_graph(*x), name="mrcnn_class_loss")(
[target_class_ids, mrcnn_class_logits, active_class_ids])
bbox_loss = Lambda(lambda x: mrcnn_bbox_loss_graph(*x), name="mrcnn_bbox_loss")(
[target_bbox, target_class_ids, mrcnn_bbox])
mask_loss = Lambda(lambda x: mrcnn_mask_loss_graph(*x), name="mrcnn_mask_loss")(
[target_mask, target_class_ids, mrcnn_mask])
# Model
inputs = [input_image, input_image_meta,
input_rpn_match, input_rpn_bbox, input_gt_class_ids, input_gt_boxes, input_gt_masks]
if not config.USE_RPN_ROIS:
inputs.append(input_rois)
outputs = [rpn_class_logits, rpn_class, rpn_bbox,
mrcnn_class_logits, mrcnn_class, mrcnn_bbox, mrcnn_mask,
rpn_rois, output_rois,
rpn_class_loss, rpn_bbox_loss, class_loss, bbox_loss, mask_loss]
model = Model(inputs, outputs, name='mask_rcnn')
return model