Mask R-CNN 论文阅读
为了以后的学习方便,把几篇计算机视觉的论文放上来,仅为自己的学习方便。期间有参考了很多博客和文献,但是我写的仍然很粗糙,存在很多的疑问。排版对手机端不友好,欢迎指正。
原文地址:Mask R-CNN
样例代码:Mask R-CNN代码(文末附踩坑纪录)
一位高手的翻译:Mask R-CNN完整翻译
一位大佬的详解:Mask R-CNN详解
研究问题的背景
实例分割需要做到较好的完成检测任务的同时,并能够很好的分割实例,是物体检测和语义分割的集成。
Mask R-CNN在Faster R-CNN的基础上,对每个RoI增加一个掩膜预测分支。这个分支用的是简单的FCN,可以实现像素到像素产生分割掩膜。
为了解决像素不对称问题(实际就是因为截断造成的),提出RoIAlign,效果优于RoIPooling和RoIWarp,可以提高10%-50%的性能。解耦掩膜和类别预测,并对每个感兴趣区域生成 个二值掩膜,为类别的个数,每个掩膜dui。这相当于做了多个二分类,机器学习中,用多个二分类处理比一个多分类效果要好。
个二值掩膜,为类别的个数,每个掩膜dui。这相当于做了多个二分类,机器学习中,用多个二分类处理比一个多分类效果要好。
论文的研究内容
先来概述一下 Mask-RCNN 的几个特点:
⑴ 训练收敛速度快,分割效果优;
⑵ 不外加任何trick,多个技术的融合,例如RoIAlign、Faster R-CNN、FPN;
⑶ 同时完成检测、分割和人体关键点检测任务,并取得start-of-art效果;
⑷ 基础网络强势:ResNeXt-101+FPN;
A、与Faster R-CNN的区别和联系
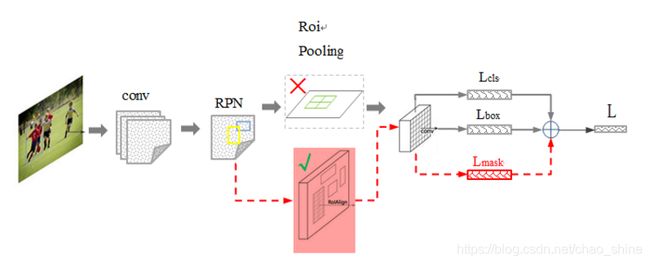
对于固定尺寸为![]() 的全连接层输入,将有截断的RoIPooling改成RoIAlign。
的全连接层输入,将有截断的RoIPooling改成RoIAlign。
B、区域推荐网络(RPN,region proposal network)
目标:输入任意图像,输出物体候选框集,每个框有对应的置信度,替换基于特征的方法Selective Search(~2k)。
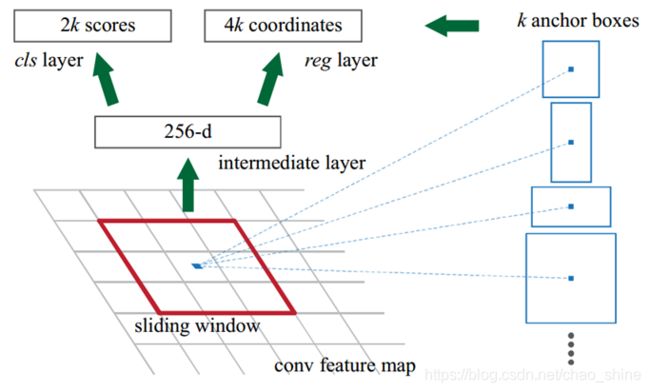
在特征提取后得到的特征图上,进行逐个特征映射的计算,设置不同尺度的锚框。
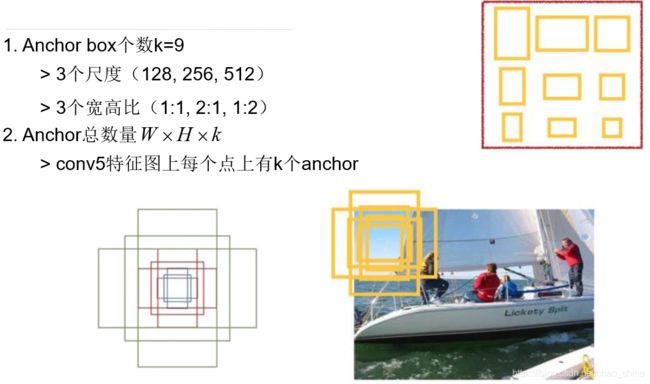
这里的尺度对应的是原图中的尺寸,Mask R-CNN采用了5个尺度。在Faster R-CNN中,RPN需要先训练,然后再训练Fast R-CNN的部分,最后将两者结合起来一起训练。Mask R-CNN将两者区分,不进行共享操作。结合FPN后,这个过程需要产生1000个候选框。然后经过非极大值抑制抑制,在分值最高的100个(这里是不是决定了一个图像中最多检测100个实例?)上进行特征提取,供下面的操作。
C、RoIAlign
目标:解决RoIPooling层产生的量化误差,并能够产生固定大小为![]() 特征图,用于分类、回归和分割。
特征图,用于分类、回归和分割。

按照图中来看,![]() 的原图下采样后可以得到
的原图下采样后可以得到![]() 的特征图,但是图中的狗
的特征图,但是图中的狗![]() 经过下采样不是整数。同样的在映射
经过下采样不是整数。同样的在映射![]() 模块时,也不是整数,所以也有截断误差。直观上20.78和20差不多,但是反向看一下
模块时,也不是整数,所以也有截断误差。直观上20.78和20差不多,但是反向看一下![]() ,再加上后面一步的截断,叠加起来,将是一个很大的区域。
,再加上后面一步的截断,叠加起来,将是一个很大的区域。
上述的误差对于预测掩膜位置是不利的,对物体框的预测也是不利的,但是物体有回归这一步,所以检测效果还是可以提升的。
RoIAlign将直接保存浮点数,最终计算的时候根据双线性插值来计算。

以上图为例子,上图设置的bin个数为![]() ,即未截断计算得到的尺寸(图中黑色线)等分成四份。在bin中选取4个点,这四个点的值根据围成它的网格(实际的特征)四个值,利用双线性插值完成赋值,最终每个bin按照最大值或者平均值作为代表。完成
,即未截断计算得到的尺寸(图中黑色线)等分成四份。在bin中选取4个点,这四个点的值根据围成它的网格(实际的特征)四个值,利用双线性插值完成赋值,最终每个bin按照最大值或者平均值作为代表。完成![]() 固定尺寸。
固定尺寸。
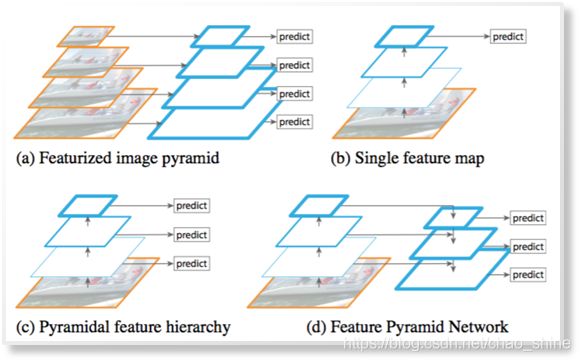
D、FPN(Feature Pyramid Networks)
目标:结合不同层的信息,低层位置信息,高层语义信息,提高检测精度。
F、Mask branch
目标:生成掩膜,解耦物体框和掩膜掩膜的关系。
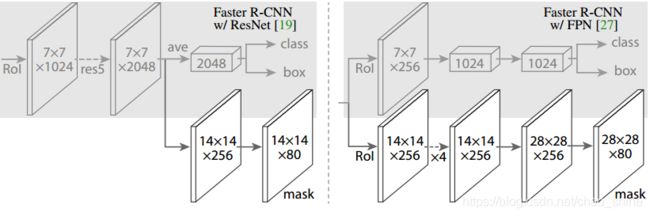
因为COCO提供80类分割的实例,所以最后的输出的通道数为80。
因为完全基于检测的分割,受限于检测的精度。对于未能检测到的小部分,分割效果自然不好。Mask R-CNN让网络自己选择,选择最好尺度的框用于分割,大尺度下的区域可以的分割操作肯定比紧凑的不完整信息要好。直观的影响便是,出现检测重叠部位,出现“块效应”。

G、损失函数
在训练中,Mask R-CNN将每个RoI上的多任务损失函数定义为:
其中, 和
和 和在Fast R-CNN中提出的一样,为分类误差和物体框误差。仅对分类分支得到的类进行计算损失,即只关注某个类别的分割效果,对其他的类也没法求啊,实际位置都没有,求了也应该是0。
和在Fast R-CNN中提出的一样,为分类误差和物体框误差。仅对分类分支得到的类进行计算损失,即只关注某个类别的分割效果,对其他的类也没法求啊,实际位置都没有,求了也应该是0。
论文的效果

(a-e)表分别说明了网络深度、二/多分类、ROIAlign加不加双线性插值和Max及Ave的关系、RoIAlign和RoIPool以及FCN对Mask R-CNN结果的影响。
训练COCO数据集
1、环境说明
| 系统 |
Ubuntu 16.04 |
| 内存 |
32G |
| 显卡 |
GeForce RTX 2080 Ti*1 |
| 语言选择 |
Python=3.6.8 |
| 代码环境 |
tensorflow-gpu=1.9.0、keras=2.0.8、h5py=2.9.0、imgaug=0.3.0、opencv-python=4.1.0、pycocotools=2.0.0、numpy=1.16.3 |
2、开始训练
因为代码对COCO已经做好了完备的封装,只需要进行执行就可以完成训练
python Mask_RCNN-master/samples/coco/coco.py train --dataset=path/to/your/data --year=2017/2014 --model=coco3、出现的问题



4、实现效果


实现demo出现的问题纪录(Windows端)
根据上面的连接下载得到源码数据,开始用Anaconda跑程序。因为之前安装了opencv-python和Tensorflow(pip install tensorflow),所以这次该方面没有出错。
出现的问题1:
No module named keras解决方法:直接pip install
pip install keras出现的问题2:
No module named imgaug尝试使用pip install imgaug,但是提示没有Sharply模块。于是参考imgaug学习笔记,未解决。
解决方法:
pip install imgaug==0.2.5出现的问题3:
No module named pycocotools尝试windows10编译 Pycocotools出错解决方案,没看懂。根据安装pycocotools,看懂了。需要先安装git,然后出现以下错误:
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual根据Scrapy安装错误:Microsoft Visual C++ 14.0 is required...和Microsoft visual c++ 14.0 is required问题解决办法得到了解决。然后根据安装pycocotools安装好pycocotools。
运行结果:
根据上述配置完成后,在anaconda下运行demo.ipynb文件,把图片路径改成自己的图片,测试结果如下:
