Kubeflow调研
文章目录
- Kubeflow基本概念
- 创建Kubeflow的Component
-
- 通过Yaml定义
- 在代码中创建
- 在Jupyter中创建
- Kubeflow的架构
-
- TensorFlow Training 的支持 (TFJob)
- 与 Jupyter Notebook 的整合
- KFServing
- 以解决一个分子属性预测问题为例,阐述如何用kubeflow实现
- Kubeflow 的总结
Kubeflow基本概念
Kubeflow 是一个 Google 主导的 Kubernetes 与机器学习工作流集成框架,帮助机器学习任务更好的运行在云环境中,进行分布式的处理,扩展到大量的机器,可以移植到不同平台,观察模型的运行效果等等。
Kubeflow 可以做的事情包括:
- data preparation
- model training
- prediction serving
- service management
机器学习工作流分为开发流程和生产流程两个阶段

Kubeflow 有以下的概念:
-
Pipeline - 一个机器学习工作流管线,执行一系列的计算步骤,有多个 component 组成
-
Component - 工作流中的一个计算任务,相当于一个 python 函数,有固定的输入和输出,并且相互依赖
-
Experiment - 工作流的一个配置环境,一套执行的参数
-
Run - 表示 Pipeline 在一个 Experiment 环境下的一次执行
-
Recurring Run - 是一种会定时重复执行的 Run,也称为 Job
-
Step - 对应 Run 中一个 Component 的执行
-
Artifact - 一个输入或输出得到数据集
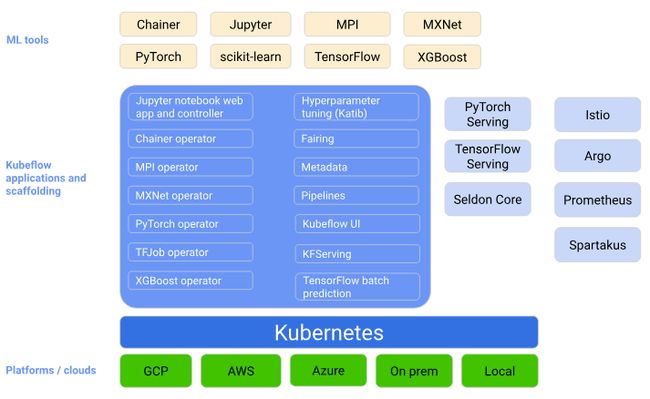
创建Kubeflow的Component
Kubeflow 的设计中,每个 Component 就是一个 python 函数,被打包成 Docker 容器,多个 Component 组成一个 Pipeline,提交到 Kubernetes 进行执行,并按要求分配指定的计算资源需求, Kubeflow Pipeline 的 Server 进行管理。指定输入和输出数据的 s3 路径,由系统进行加载。Run 的记录,Pipeline 的配置,以及运行的结果可以在 Kubeflow UI 中查看,以及创建新的 Run。
每个 Component 是一个具体的计算任务,支持多种机器学习框架,如 Tensorflow,PyTorch,MXNet,MPI。Pipeline 除了可以通过 YAML 文件定义之外还可以用 Python 脚本或者在 Jupyter Notebook 中动态创建。除了单次执行的 Pipeline,**还支持以 Serving 的方式将计算模型部署成一个服务,并监控 Serving 的状态。**任务依赖是由 Argo 来进行管理的。每一种计算任务有相应的 Operator 调度,控制底层 Kubernetes 的调度和资源分配。整个系统可以运行在不同的云平台上。
相关文档:
- sdk-overview
- build-component
通过Yaml定义
代码1 一个 Component 的定义:
name: xgboost4j - Train classifier
description: Trains a boosted tree ensemble classifier using xgboost4j
inputs:
- {name: Training data}
- {name: Rounds, type: Integer, default: '30', help: Number of training rounds}
outputs:
- {name: Trained model, type: XGBoost model, help: Trained XGBoost model}
implementation:
container:
image: gcr.io/ml-pipeline/xgboost-classifier-train@sha256:b3a64d57
command: [
/ml/train.py,
--train-set, {inputPath: Training data},
--rounds, {inputValue: Rounds},
--out-model, {outputPath: Trained model},
]
-
name - Component 的名称
-
description - 任务描述
-
inputs - 输入参数列表,可以定义 name,类型,默认值等
-
outputs - 输出参数列表
-
implementation - 计算任务的描述,在这里指定一个 Docker 镜像,以及启动参数,并且指定了模板参数
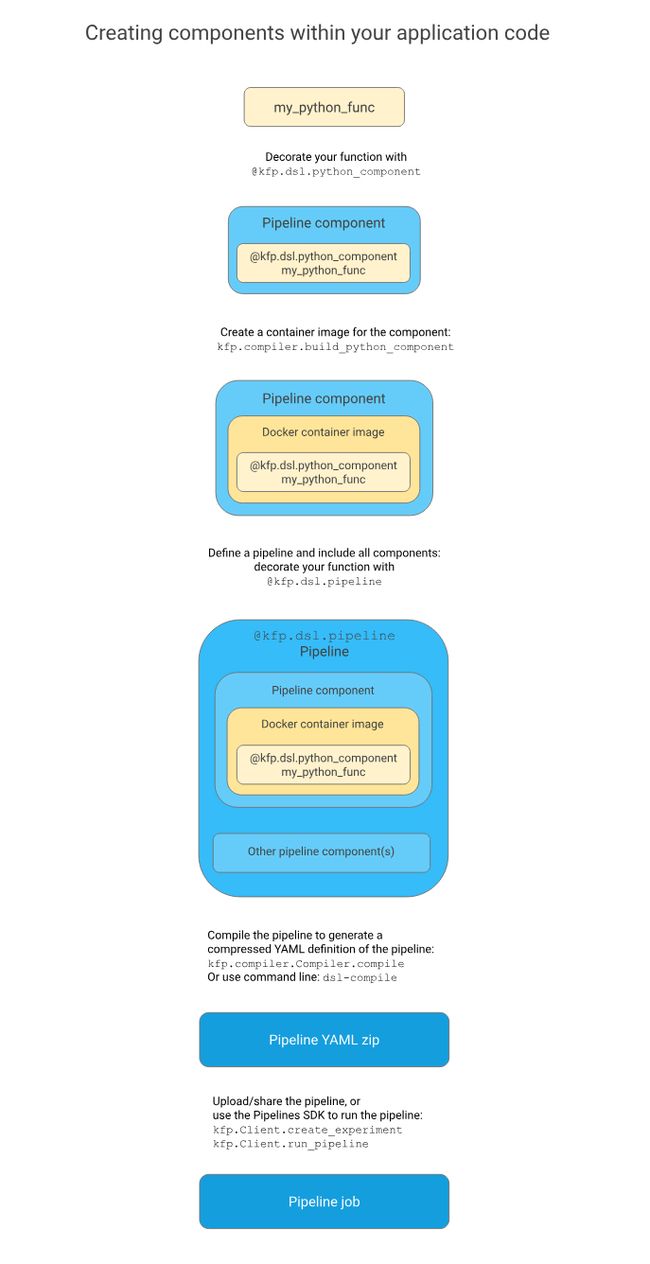
可以通过 python 代码创建 Pipeline,使用 decorator 来标识,函数的参数就是整个 Pipeline 的参数。中间的步骤不会直接被执行,而是创建一个计算图,每一个步骤是一个 Component,交给 Kubernetes 进行分布式处理。
在代码中创建
代码2 一个 Pipeline 的结构:
from kfp import dsl
from kubernetes.client.models import V1EnvVar, V1SecretKeySelector
@dsl.pipeline(
name='foo',
description='hello world')
def foo_pipeline(tag: str, pull_image_policy: str):
# any attributes can be parameterized (both serialized string or actual PipelineParam)
op = dsl.ContainerOp(name='foo',
image='busybox:%s' % tag,
# pass in init_container list
init_containers=[dsl.InitContainer('print', 'busybox:latest', command='echo "hello"')],
# pass in sidecars list
sidecars=[dsl.Sidecar('print', 'busybox:latest', command='echo "hello"')],
# pass in k8s container kwargs
container_kwargs={'env': [V1EnvVar('foo', 'bar')]},
)
# set `imagePullPolicy` property for `container` with `PipelineParam`
op.container.set_pull_image_policy(pull_image_policy)
# add sidecar with parameterized image tag
# sidecar follows the argo sidecar swagger spec
op.add_sidecar(dsl.Sidecar('redis', 'redis:%s' % tag).set_image_pull_policy('Always'))
在Jupyter中创建

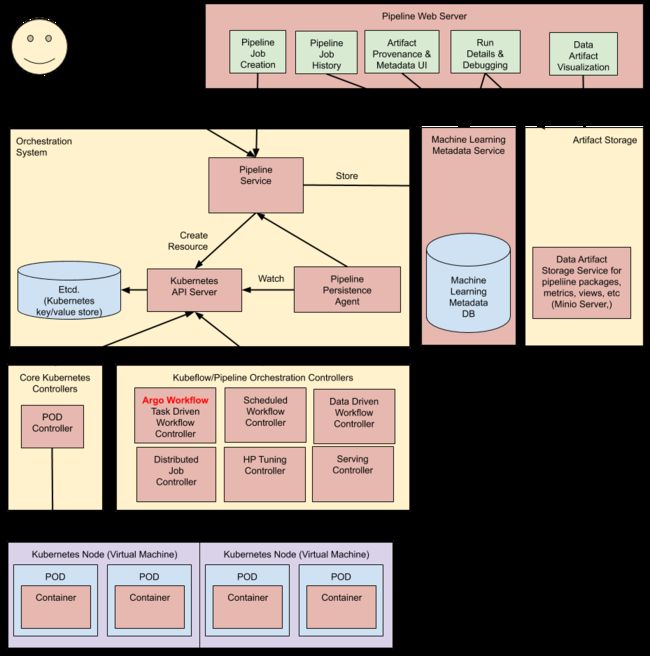
Kubeflow的架构
在 Kubeflow 之下,真正负责 Pipeline 执行的是 Argo Workflow Controller,把计算任务提交给 Kubernetes。
TensorFlow Training 的支持 (TFJob)
特定于 Tensorflow 任务,进行分布式计算资源管理的功能,实现在 TFJob 组件中,这是一个基于 tf-operator 的 Kubernetes CRD。
对于 PyTorch,MXNet,Chainer,MPI 任务也有对应的组件
与 Jupyter Notebook 的整合
以上面的方式可以通过 YAML 和 Python 脚本创建 Component 和 Pipeline,另外也可以通过 Notebook 创建,适合交互式开发的场景,动态地部署一个 Python 函数,持续创建和部署新任务,并且查看数据,验证计算结果。
这种方式的好处的用户不需要本地创建开发环境,只需要浏览器中操作,并且可以进行访问控制,Notebook 也可以保存起来,把整个环境分享给同事。
KFServing
Kubeflow 提供了自己的 Serving 组件,对于需要部署到生产环境的机器学习模型,进行服务化,常驻在内存,不需要每次进行预测重新加载模型。KFServing 底层基于 Knative 和 Istio,实现了一个 Serverless 的弹性扩展服务。

以解决一个分子属性预测问题为例,阐述如何用kubeflow实现
- 定义环境,将分子属性预测问题依赖的环境整理为docker镜像
- 定义数据,将分子属性预测问题依赖的数据存放到指定地点,如S3
- 定义多个Component,并启动Pipeline
name: mol_attr_pred - Train classifier
description: Trains a Molecular attribute prediction
inputs:
- {name: Training data}
- {name: Rounds, type: Integer, default: '30', help: Number of training rounds}
outputs:
- {name: Trained model, type: Tensorflow model, help: Trained Tensorflow model}
implementation:
container:
image: gcr.io/ml-pipeline/mol_attr_pred-classifier-train@sha256:b3a64d57
command: [
/ml/train.py,
--train-set, {inputPath: Training data},
--rounds, {inputValue: Rounds},
--out-model, {outputPath: Trained model},
]
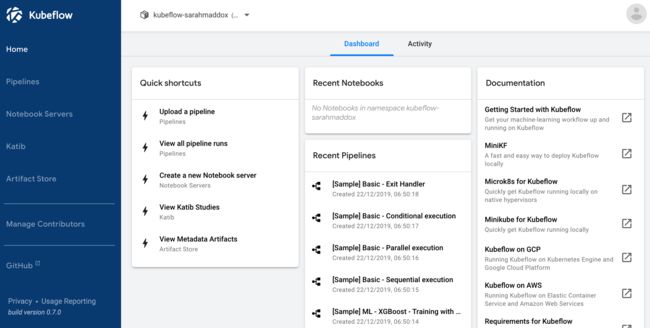
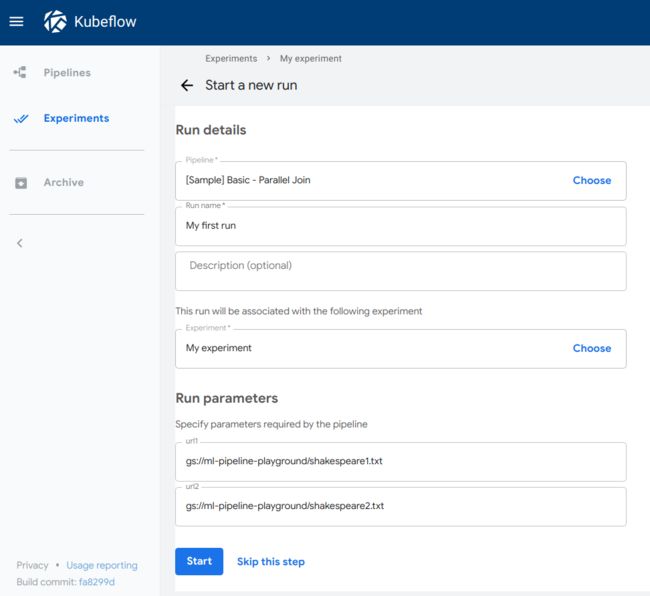
可以在dashboard中查看任务
Kubeflow 的总结
支持很多的机器学习框架,包括 Tensorflow,PyTorch,MXNet,TensorRT,ONNX,MPI 等等
高度集成 Kubernetes,Google Cloud,AWS,Azure 等云平台
核心基于 Component 和 Pipeline 等概念
提供的任务管理,历史任务,任务提交,计算调度等功能
有 Serving 的框架
支持 Jupyter Notebook 中交互式创建任务
有多个松散、独立的组件构成
部署比较复杂,运维成本很高,跟云平台过度耦合
API 复杂,组件多,概念多,过度工程化
文档混乱(极其混乱。。。)