多项NLP任务新SOTA,Facebook提出预训练模型BART
2019-11-04 13:38:14
论文选自arXiv
作者:Mike Lewis等机器之心编译参与:魔王、一鸣
FaceBook 近日提出了一个名为BART的预训练语言模型。该模型结合双向和自回归 Transformer 进行模型预训练,在一些自然语言处理任务上取得了SOTA性能表现。
近日,Facebook 发表论文,提出一种为预训练序列到序列模型而设计的去噪自编码器 BART。BART 通过以下步骤训练得到:1)使用任意噪声函数破坏文本;2)学习模型来重建原始文本。BART 使用基于 Transformer 的标准神经机器翻译架构,可泛化 BERT(具备双向编码器)、GPT(具备从左至右的解码器)等近期出现的预训练模型,尽管它非常简洁。Facebook 研究人员评估了多种噪声方法,最终通过随机打乱原始句子的顺序,再使用新型文本填充方法(即用单个 mask token 替换文本段)找出最优性能。
BART 尤其擅长处理文本生成任务,不过它在理解任务中的性能也不错。在提供同等的训练资源时,BART 可在 GLUE 和 SQuAD 数据集上实现与 RoBERTa 相当的性能,并在抽象对话、问答和文本摘要等任务中获得新的当前最优结果,在 XSum 数据集上的性能比之前研究提升了 6 ROUGE。在机器翻译任务中,BART 在仅使用目标语言预训练的情况下,获得了比回译系统高出 1.1 个 BLEU 值的结果。研究人员还使用控制变量实验复制了 BART 框架内的其他预训练机制,从而更好地评估影响终端任务性能的最大因素。
论文链接:https://arxiv.org/pdf/1910.13461.pdf
引言
自监督方法在大量 NLP 任务中取得了卓越的成绩。近期研究通过改进 masked token 的分布(即 masked token 被预测的顺序)和替换 masked token 的可用语境,性能获得提升。然而,这些方法通常聚焦于特定类型和任务(如 span prediction、生成等),应用较为有限。
Facebook 的这项研究提出了新架构 BART,它结合双向和自回归 Transformer 对模型进行预训练。BART 是一个适用于序列到序列模型的去噪自编码器,可应用于大量终端任务。预训练包括两个阶段:1)使用任意噪声函数破坏文本;2)学得序列到序列模型来重建原始文本。BART 使用基于 Tranformer 的标准神经机器翻译架构,可泛化 BERT、GPT 等近期提出的预训练模型。
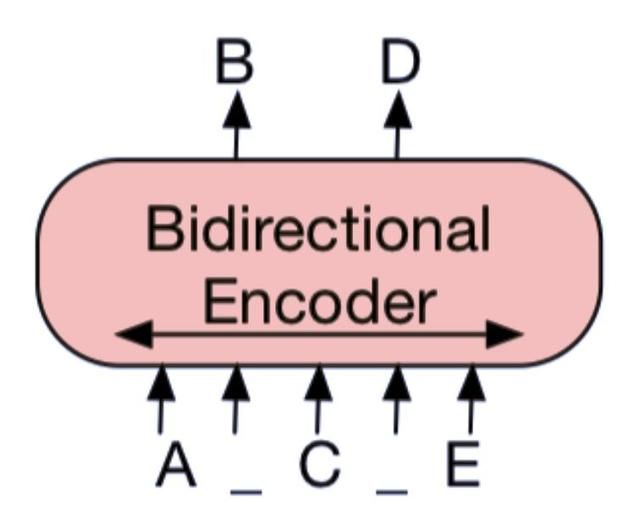
图 1a:BERT:用掩码替换随机 token,双向编码文档。由于缺失 token 被单独预测,因此 BERT 较难用于生成任务。
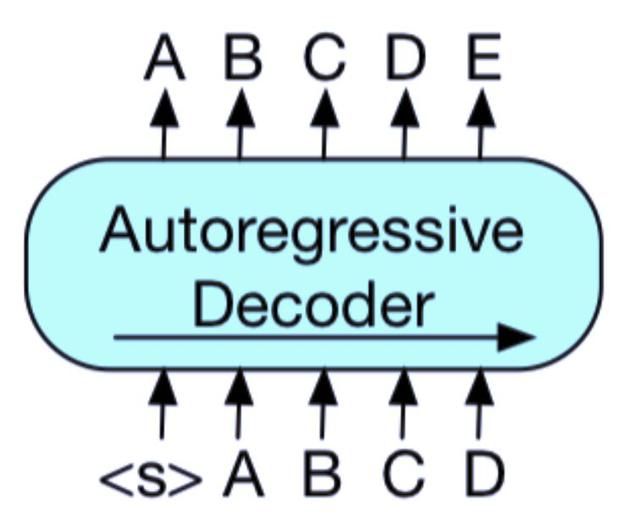
图 1b:GPT:使用自回归方式预测 token,这意味着 GPT 可用于生成任务。但是,该模型仅基于左侧上下文预测单词,无法学习双向交互。

图 1c:BART:编码器输入与解码器输出无需对齐,即允许任意噪声变换。使用掩码符号替换文本段,从而破坏文本。使用双向模型编码被破坏的文本(左),然后使用自回归解码器计算原始文档的似然(右)。至于微调,未被破坏的文档是编码器和解码器的输入,研究者使用来自解码器最终隐藏状态的表征。
模型
去噪自编码器 BART 可将被破坏文档映射至原始文档。它是一个具备双向编码器(对被破坏文本使用)和从左至右自回归解码器的序列到序列模型。至于预训练,研究人员优化了原始文档的负 log 似然。
架构
BART 使用 (Vaswani et al., 2017) 提出的标准序列到序列 Transformer 架构,不过做了少许改动:按照 GPT 模型,将 ReLU 激活函数更改为 GeLU,从 N (0, 0.02) 初始化参数。BART base 模型的编码器和解码器各有 6 层,large 模型中层数各增加到了 12。BART 架构与 BERT 所用架构类似,区别如下:1)解码器的每个层对编码器最终隐藏层额外执行 cross-attention(和 Transformer 序列到序列模型一样);2)BERT 在词预测之前使用了额外的前馈网络,而 BART 没有。总之,BART 相比同等规模的 BERT 模型大约多出 10% 的参数。
预训练 BART
BART 是通过破坏文档再优化重建损失(即解码器输出和原始文档之间的交叉熵)训练得到的。与目前仅适合特定噪声机制的去噪自编码器不同,BART 可应用于任意类型的文档破坏。极端情况下,当源文本信息全部缺失时,BART 也等同于语言模型。
- token 掩码:按照 BERT 模型,BART 采样随机 token,并用掩码替换它们。
- token 删除:从输入中随机删除 token。与 token 掩码不同,模型必须确定缺失输入的位置。

图 2:向输入添加不同的噪声变换。这些变换是可组合的。
- 文本填充:采样多个文本段,文本段长度取决于泊松分布 (λ = 3)。用单个掩码 token 替换每个文本段。长度为 0 的文本段对应掩码 token 的插入。
- 句子排列变换:按句号将文档分割成多个句子,然后以随机顺序打乱这些句子。
- 文档旋转:随机均匀地选择 token,旋转文档使文档从该 token 开始。该任务的目的是训练模型识别文档开头。
BART 模型微调
序列分类任务
序列分类任务中,编码器和解码器的输入相同,最终解码器 token 的最终隐藏状态被输入到新的多类别线性分类器中。该方法与 BERT 中的 CLS token 类似,不过 BART 在解码器最后额外添加了一个 token,这样该 token 的表征可以处理来自完整输入的解码器状态(见图 3a)。
token 分类任务
对于 token 分类任务,研究人员将完整文档输入到编码器和解码器中,使用解码器最上方的隐藏状态作为每个单词的表征。该表征的用途是分类 token。
序列生成任务
由于 BART 具备自回归解码器,因此它可以针对序列生成任务进行直接微调,如抽象问答和摘要。在这两项任务中,信息复制自输入但是经过了处理,这与去噪预训练目标紧密相关。这里,编码器的输入是输入序列,解码器以自回归的方式生成输出。
机器翻译
研究人员用新的随机初始化编码器替换 BART 的编码器嵌入层。该模型以端到端的方式接受训练,即训练一个新的编码器将外来词映射到输入(BART 可将其去噪为英文)。新的编码器可以使用不同于原始 BART 模型的词汇。
源编码器的训练分两步,均需要将来自 BART 模型输出的交叉熵损失进行反向传播。第一步中,研究人员冻结 BART 的大部分参数,仅更新随机初始化的源编码器、BART 位置嵌入和 BART 编码器第一层的自注意力输入投影矩阵。第二步中,研究人员将所有模型参数进行少量迭代训练。
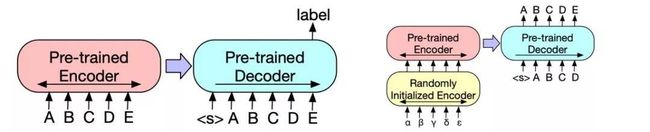
图 3:a:要想使用 BART 解决分类问题,编码器和解码器的输入要相同,使用最终输出的表征。b:对于机器翻译任务,研究人员训练一个额外的小型编码器来替换 BART 中的词嵌入。新编码器可使用不同的词汇。
结果

表 1:预训练目标对比。所有模型的训练数据都是书籍和维基百科数据。

表 2:大模型在 SQuAD 和 GLUE 任务上的结果。BART 的性能堪比 RoBERTa 和 XLNet,这表明 BART 的单向解码器层不会降低模型在判别任务上的性能。

表 3:在两个标准摘要数据集上的结果。在这两个摘要任务上,BART 在所有度量指标上的性能均优于之前的研究,在更抽象的 XSum 数据集上的性能较之前模型提升了 6 个百分点。

表 4:BART 在对话回答生成任务上的性能优于之前研究。困惑度基于 ConvAI2 官方 tokenizer 进行了重新归一化。

表 5:BART 在难度较高的 ELI5 抽象问答数据集上取得了当前最优结果。
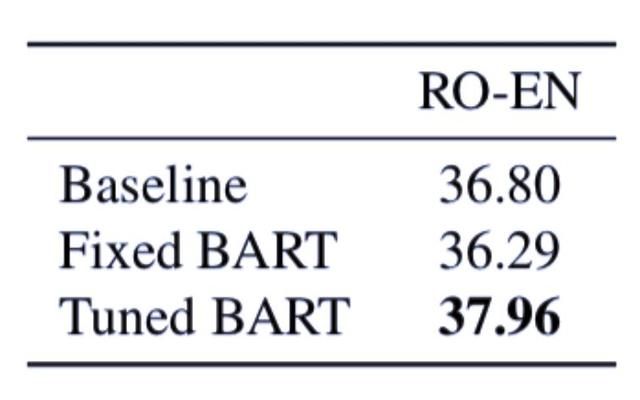
表 6:BART 和基线模型在机器翻译任务上(使用数据集包括 WMT‘16 RO-EN 和回译数据)的性能对比情况。BART 使用单语英文预训练,性能优于强大的回译基线模型。