ElasticSearch索引文档写入和近实时搜索
一、基本概念
1.Segments In Lucene
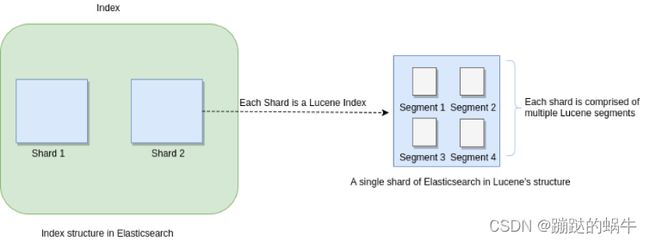
众所周知,ElasticSearch存储的基本单元Shard,ES中一个Index可能分为多个Shard,事实上每个Shard都是一个Lucence的Index,并且每个Lucene Index由多个Segment组成,每个Segment事实上是一些倒排索引的集合,每次创建一个新的Document,都会归属于一个新的Segment,而不是去修改原来的Segment。每次的文档删除操作,只是标记Segment中该文档为删除状态,并不会立马物理删除,所以说ES的Index是一个抽象的概念,如下图所示:
2.Commits In Lucene
Commit 操作意味着将 Segment 合并,并写入磁盘。保证内存数据尽量不丢失。但刷盘是很重的 IO 操作, 所以为了机器性能和近实时搜索, 并不会刷盘那么及时。
3.Translog
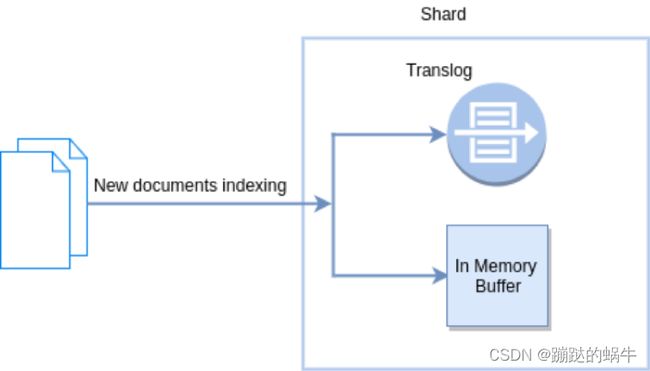
新文档被索引意味着文档会被首先写入内存 buffer 和 translog 文件。每个 shard 都对应一个 translog文件。
4.Refresh In ElasticSearch
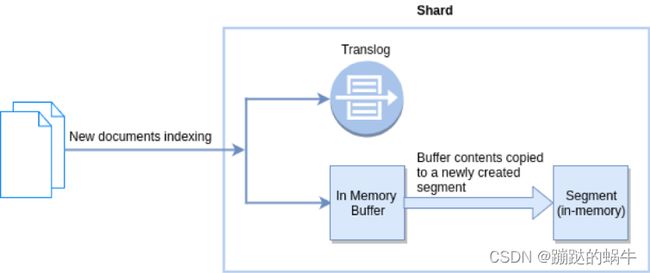
在 Elasticsearch 中, _refresh 操作默认每秒执行一次, 意味着将内存 buffer 的数据写入到一个新的 Segment 中,这个时候索引变成了可被检索的。写入新Segment后 会清空内存buffer。
5.Flush In ElasticSearch
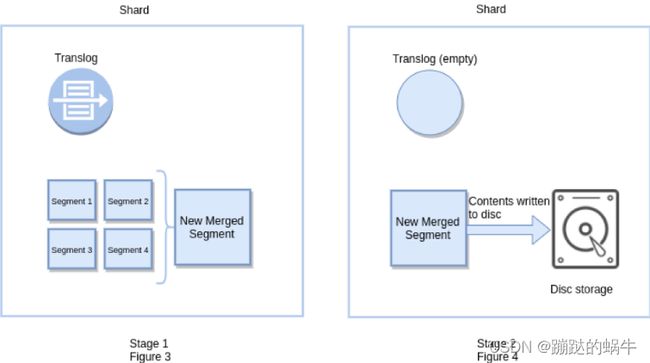
Flush操作意味着将内存Buffer的数据全部写入新的Segment中,并将内存中所有的Segment全部刷盘,并且清空Translog日志的过程。
二、近实时搜索
提交(Commiting)一个新的段到磁盘需要一个fsync来确保被物理性地写入磁盘,这样在断电的时候就不会丢失数据。但是fsync操作代价很多,如果每次索引一个稳定都去执行一次的话就会造成很大的性能问题。
在ElasticSearch和磁盘之间是文件系统缓存。像之前描述的一样,在内存索引缓冲区中的文档会被写入到一个新的段中。但是这里新段会被先写入到文件系统缓存–这一步代价比较低,稍后会被刷新到磁盘–这一步代价比较高。不过只要文件已经在系统缓存中,就可以像其他文件一样被打开和读取了。如下图:表示在内存缓存区中包含了新文档的索引

Lucene 允许新段被写入和打开–使其包含的文档在未进行一次完整提交时便对搜索可见。 这种方式比进行一次提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
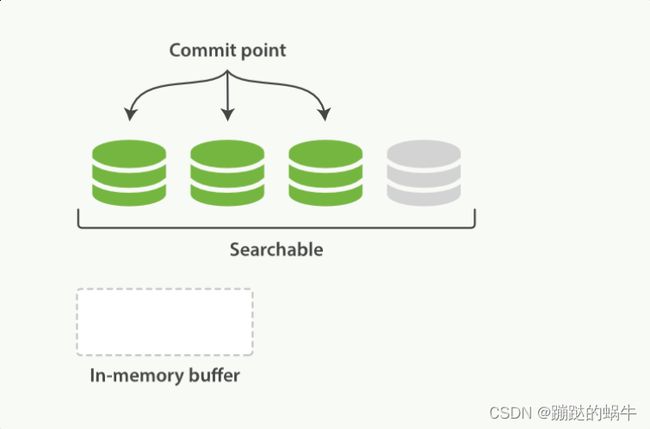
上图表示,缓存区的内容已经被写入一个可被搜索的段中,但是还没有提交。
2.1 原理

上图表示的是ES的写操作流程,当一个写请求发送到ES后,ES将数据写入Memory Buffer中,并添加事务日志(Translog)。如果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操作也就是随机写入了。磁盘随机写入的效率相当低,会严重降低ES的性能。因此ES在设计时在Memory Buffer和磁盘间加入了Linux的高速缓存(File System Cache)来提高ES的写效率。
当写请求发送到ES后,ES将数据暂时写入Memory Buffer中,此时写入的数据还不能被查询到。默认设置下,ES每1秒将Memory Buffer中的数据refresh到Linux的File System Cache,并清空Memory Buffer,此时写入的数据就可以被查询到了。
2.2 Refresh API
在ElasticSearch中,写入和打开一个新段的轻量的过程叫refresh。默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说ElasticSearch是近实时搜索:文档的变化并不是立即对搜索可见,但是会在一秒内变为可见。
这些默认的机制会造成在索引了一个文档后尝试搜索它,但是没有搜索到,这个问题就可以通过refresh api 执行一次手动刷新:
POST /_refresh // 刷新所有索引
POST /my_blogs/_refresh // 只刷新blogs索引
PUT /my_blogs/_doc/1?refresh // 只刷新文档
并不是所有的情况都需要每秒刷新。在日志系统中,ElasticSearch被用来索引大量的日志文件,此时更应该优化索引速度而不是近实时搜索,可以通过设置refresh_interval,降低每个索引的刷新频率。
PUT /my_logs
{
"settings": { "refresh_interval": "30s" }
}
refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来:
PUT /my_logs/_settings
{ "refresh_interval": -1 }
PUT /my_logs/_settings
{ "refresh_interval": "1s" }
三、持久化变更
3.1 原理
如果没有用fsync把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证ElasticSearch的可靠性,需要确保数据变化被持久到磁盘。
在动态更新索引时,我们说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。ElasticSearch在重启或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
即使通过每秒刷新(refresh)实现了近实时的搜索,我们仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办? 当然是不能丢失掉这些数据。
ElasticSearch增加了一个TransLog,或者叫事务日志,在每一次对ElasticSearch进行操作时均进行了日志记录。通过TransLog,这个流程看起来是下面这样:
1、一个文档被索引之后,就会添加到内存缓存区,并且追加到了TransLog;
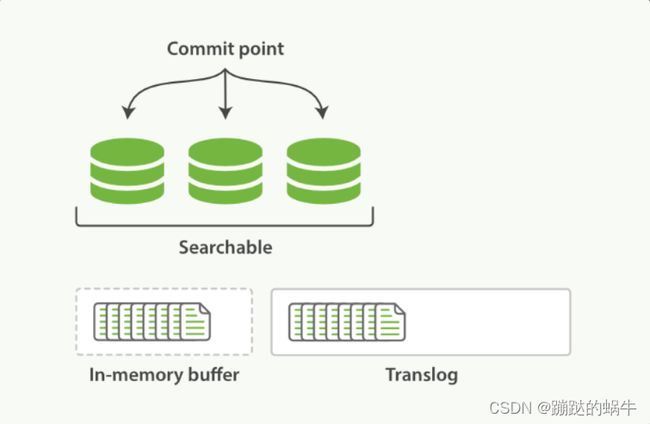
2、刷新(refresh)使分片处于Searchable状态,分片每秒被刷新一次
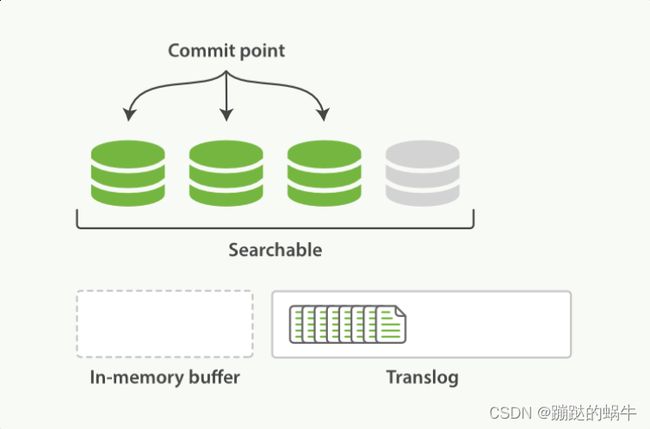
●这些在内存缓冲区的文档被写入一个新的段中,且没有进行fsync操作
●这个段被打开,使其可被搜索
●内存缓存区被清空
3、这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志

4、每个一段时间–例如translog变得越来越大–索引被刷新(flush);一个新的translog被创建,并且一个全量提交被执行。
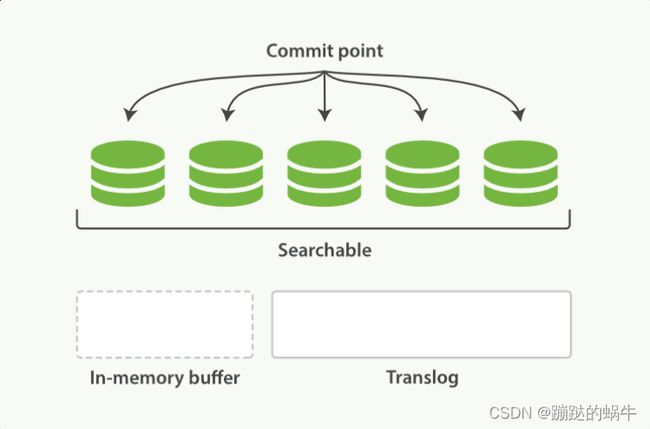
●所有在内存缓冲区的文档都被写入一个新的段;
●缓冲区被清空;
●一个提交点被写入硬盘;
●文件系统缓存通过fsync被刷新(flush);
●老的translog被删除
translog提供所有还没有被刷到磁盘的操作的一个持久化记录。当ElasticSearch启动的时候,它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放translog中所有在最后一次提交后发生的变更操作。
translog也被用来提供实时的CRUD。当试着通过ID查询、更新、删除一个文档,会在尝试从相应的段中检索之前,首先检查translog任何最近的变更,这意味着它总是能够实时地获取到文档的最新版本。
3.2 flush API
这个执行一个提交并且截断translog的行为在ElasticSearch被称作一次flush。分片每30分钟被自动刷新(flush),或者再translog太大的时候也会被刷新。
flush API可以被用来执行一个手动的刷新:
POST /blogs/_flush
POST /_flush?wait_for_ongoin
●刷新blogs索引
●刷新所有的索引并且等待所有刷新在返回前完成
3.3 Translog有多安全
Translog的目的是保证操作不会丢失。这引出了一个问题:Translog有多安全?
在文件被fsync到磁盘之前,被写入的文件在重启之后就会丢失。默认translog是每5秒被fsync刷新到磁盘,或者再每次写请求完成之后执行(e.g. index, delete, update, bulk)。这个过程在主分片和复制分片都会发生。这就意味着在整个请求被fsync到主分片和复制分片的translog之前,客户端不会得到一个200 OK的响应。
在每次写请求后都执行一个fsync会带来一些性能损失,尽管实践表明这种损失相对较小(特别是 bulk 导入,它在一次请求中平摊了大量文档的开销)。但是对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的fsync还是比较有益的。