Pytorch框架学习路径(九:transforms图像增强(一))
文章目录
- Pytorch专栏
- 录制的相应的视频
- 本文code下载
- transform_invert()函数
-
- 1.1、isinstance()函数的介绍
- 1.2、lambda匿名函数
-
- 1.2.1、一个语法
- 1.2.2、三个特性
- 1.2.3、四个用法
- 1.3、filter()函数
- 1.4、Image.fromarray的用法
- 数据增强
- transforms——Crop
-
- 1、transforms.CenterCrop
- 2、transforms.RandomCrop
- 3、FiveCrop和TenCrop
- transforms——翻转、旋转(Flip and Rotation)
-
- transforms_Flip
- RandomRotation
Pytorch专栏
Pytorch框架学习路径(一:张量简介与创建)
Pytorch框架学习路径(二:张量操作)
Pytorch框架学习路径(三:线性回归)
Pytorch框架学习路径(四:计算图与动态图机制)
Pytorch框架学习路径(五:autograd与逻辑回归)
Pytorch框架学习路径(七:数据读取机制DataLoader与Dataset)
Pytorch框架学习路径(八:图像预处理——transforms)
录制的相应的视频
1、transform_invert()函数的视频讲解:
链接:https://pan.baidu.com/s/1VUZvbN71DlYaJ9Q6sj5ixQ
提取码:gd0o
transforms.CenterCrop以及transforms.RandomCrop的视频讲解:
链接:https://pan.baidu.com/s/1ZOeRuJZju6Cyz6-FNJDUqg
提取码:1ops
Fivecrop以及TenCrop的讲解视频
链接:https://pan.baidu.com/s/1V9oo-TGnSpiS-Olt6GKAaw
提取码:ejiz
图片旋转的视频讲解:
链接:https://pan.baidu.com/s/1HBI7SQdHYSVXjEi8_G3qtg
提取码:4d6k
本文code下载
本篇博客下载链接https://download.csdn.net/download/weixin_54546190/85558906`
transform_invert()函数
在介绍数据增强之前我们看一下
transform_invert()函数的源码,下面每个小节是对transform_invert函数中一些不常见的函数进行介绍,方便大家看懂transform_invert()函数的源码。
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train) or img_.max() < 1:
img_ = img_.detach().numpy() * 255
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
| 1、norm_transform得到的是什么? |
如果大家不太懂isinstance()函数、lambda函数、filter()函数的情况下,可以通过下述1.1、1.2、1.3小节相应函数的介绍,我们就能看懂这行代码了。
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
由下图,我们可以清楚的看到norm_transform是什么。
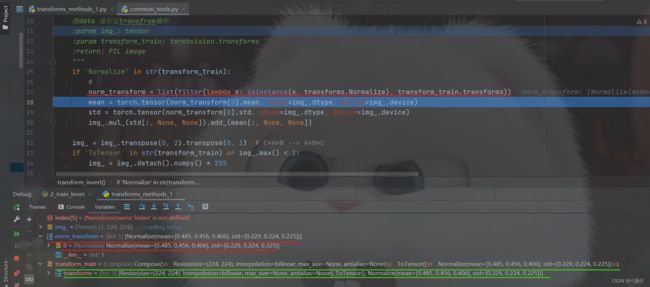
| 2、img_.detach().numpy() * 255 |

| 3、Image.fromarray |
# 如img_.shape=(W,H,C),所以shape[2]=C通道数,
# Image.fromarray:实现`array`到`Image`的转换
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
详细请看下图Debug的结果。

1.1、isinstance()函数的介绍
函数
isinstance()可以判断一个变量的类型,既可以用在Python内置的数据类型如str、list、dict,也可以用在我们自定义的类,它们本质上都是数据类型。
假设有如下的 Person、Student 和 Teacher 的定义及继承关系如下:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
class Teacher(Person):
def __init__(self, name, gender, course):
super(Teacher, self).__init__(name, gender)
self.course = course
p = Person('Tim', 'Male')
s = Student('Bob', 'Male', 88)
t = Teacher('Alice', 'Female', 'English')
当我们拿到变量
p、s、t时,可以使用isinstance判断类型:
>>> isinstance(p, Person)
True # p是Person类型
>>> isinstance(p, Student)
False # p不是Student类型
>>> isinstance(p, Teacher)
False # p不是Teacher类型
这说明在继承链上,一个父类的实例不能是子类类型,因为子类比父类少了一些属性和方法。
我们再考察 s :
>>> isinstance(s, Person)
True # s是Person类型
>>> isinstance(s, Student)
True # s是Student类型
>>> isinstance(s, Teacher)
False # s不是Teacher类型
s是Student类型,不是Teacher类型,这很容易理解。但是,s也是Person类型,因为Student继承自Person,虽然它比Person多了一些属性和方法,但是,把s看成Person的实例也是可以的。
这说明在一条继承链上,一个实例可以看成它本身的类型,也可以看成它父类的类型。
任务
请根据继承链的类型转换,依次思考t是否是Person,Student,eacher,object类型,并使用isinstance()判断来验证您的答案。
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
class Teacher(Person):
def __init__(self, name, gender, course):
super(Teacher, self).__init__(name, gender)
self.course = course
t = Teacher('Alice', 'Female', 'English')
print (isinstance(t,Person))
print (isinstance(t, Student))
print (isinstance(t, Teacher))
print (isinstance(t, object ))
#运行结果
#True
#False
#True
#True
1.2、lambda匿名函数
1.2.1、一个语法
在Python中,lambda的语法是唯一的。其形式如下:
lambda argument_list: expression
其中,lambda是Python预留的关键字,argument_list和expression由用户自定义。具体介绍如下。
- 这里的
argument_list是参数列表,它的结构与Python中函数(function)的参数列表是一样的。具体来说,argument_list可以有非常多的形式。例如:
- a, b
- a=1, b=2
- *args
- **kwargs
- a, b=1, *args
- 空
- …
- 这里的
expression是一个关于参数的表达式。表达式中出现的参数需要在argument_list中有定义,并且表达式只能是单行的。以下都是合法的表达式:
- 1
- None
- a + b
- sum(a)
- 1 if a >10 else 0
- …
- 这里的
lambda argument_list: expression表示的是一个函数。这个函数叫做lambda函数。
1.2.2、三个特性
lambda函数有如下特性:
-
lambda函数是匿名的:所谓匿名函数,通俗地说就是没有名字的函数。lambda函数没有名字。 -
lambda函数有输入和输出:输入是传入到参数列表argument_list的值,输出是根据表达式expression计算得到的值。 -
lambda函数一般功能简单:单行expression决定了lambda函数不可能完成复杂的逻辑,只能完成非常简单的功能。由于其实现的功能一目了然,甚至不需要专门的名字来说明。
下面是一些lambda函数示例:
lambda x, y: x*y;函数输入是x和y,输出是它们的积x*y
lambda:None;函数没有输入参数,输出是None
lambda *args: sum(args); 输入是任意个数的参数,输出是它们的和(隐性要求是输入参数必须能够进行加法运算)
lambda **kwargs: 1;输入是任意键值对参数,输出是1
1.2.3、四个用法
由于lambda语法是固定的,其本质上只有一种用法,那就是定义一个lambda函数。在实际中,根据这个lambda函数应用场景的不同,可以将lambda函数的用法扩展为以下几种:
- 1、 将lambda函数赋值给一个变量,通过这个变量间接调用该lambda函数。
例如,执行语句add=lambda x, y: x+y,定义了加法函数lambda x, y: x+y,并将其赋值给变量add,这样变量add便成为具有加法功能的函数。例如,执行add(1,2),输出为3。
- 2、将lambda函数赋值给其他函数,从而将其他函数用该lambda函数替换。
例如,为了把标准库time中的函数sleep的功能屏蔽(Mock),我们可以在程序初始化时调用:time.sleep=lambda x:None。这样,在后续代码中调用time库的sleep函数将不会执行原有的功能。例如,执行time.sleep(3)时,程序不会休眠3秒钟,而是什么都不做。
- 3、 将lambda函数作为其他函数的返回值,返回给调用者。
函数的返回值也可以是函数。例如return lambda x, y: x+y返回一个加法函数。这时,lambda函数实际上是定义在某个函数内部的函数,称之为嵌套函数,或者内部函数。对应的,将包含嵌套函数的函数称之为外部函数。内部函数能够访问外部函数的局部变量,这个特性是闭包(Closure)编程的基础,在这里我们不展开。
- 4、将lambda函数作为参数传递给其他函数。
部分Python内置函数接收函数作为参数。典型的此类内置函数有这些。
-
filter函数。此时lambda函数用于指定过滤列表元素的条件。例如filter(lambda x: x % 3 == 0, [1, 2, 3])指定将列表[1,2,3]中能够被3整除的元素过滤出来,其结果是[3]。 -
sorted函数。此时lambda函数用于指定对列表中所有元素进行排序的准则。例如sorted([1, 2, 3, 4, 5, 6, 7, 8, 9], key=lambda x: abs(5-x))将列表[1, 2, 3, 4, 5, 6, 7, 8, 9]按照元素与5距离从小到大进行排序,其结果是[5, 4, 6, 3, 7, 2, 8, 1, 9]。 -
map函数。此时lambda函数用于指定对列表中每一个元素的共同操作。例如map(lambda x: x+1, [1, 2,3])将列表[1, 2, 3]中的元素分别加1,其结果[2, 3, 4]。 -
reduce函数。此时lambda函数用于指定列表中两两相邻元素的结合条件。例如reduce(lambda a, b: '{}, {}'.format(a, b), [1, 2, 3, 4, 5, 6, 7, 8, 9])将列表 [1, 2, 3, 4, 5, 6, 7, 8, 9]中的元素从左往右两两以逗号分隔的字符的形式依次结合起来,其结果是’1, 2, 3, 4, 5, 6, 7, 8, 9’。
1.3、filter()函数
filter(function, iterable)
参数
- function – 判断函数。
- filter会遍历iterable中的每一个数据,用function判断,符合条件,才会被留下。
- iterable – 可迭代对象。
如列表,元组,甚至集合都可以。 - 返回值
返回一个迭代器对象
实例:
#过滤出列表中的所有奇数:
def is_odd(n):
return n % 2 == 1
tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
newlist = list(tmplist)
print(newlist)
# 输出[1, 3, 5, 7, 9]
#过滤出1~100中平方根是整数的数:
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0
tmplist = filter(is_sqr, range(1, 101))
newlist = list(tmplist)
print(newlist)
#输出结果 :
#[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
filter:过滤
filter(function or None, iterable)
fuction or None:第一个参数可以是一个函数或者是None
iterable:可迭代对象
如果给了
function,则将可迭代对象中的每一个元素,传递给function作为参数,筛选出所有结果为真的值。
如果function没有给出,必须要给None,直接返回
iterable中所有为真的值真值:任何非零的值(包括负数)
假值:零,所有的空(空列表等) None
0,False,所有的空
1.4、Image.fromarray的用法
Image.fromarray的作用:简而言之,就是实现array到image的转换。
PIL中的Image和numpy中的数组array相互转换:
- 1、PIL image转换成array
img = np.asarray(image)
需要注意的是,如果出现read-only错误,并不是转换的错误,一般是你读取的图片的时候,默认选择的是"r","rb"模式有关。
修正的办法: 手动修改图片的读取状态如下:
img.flags.writeable = True # 将数组改为读写模式
- 2、array转换成image
Image.fromarray(np.uint8(img))
数据增强
什么是数据增强?
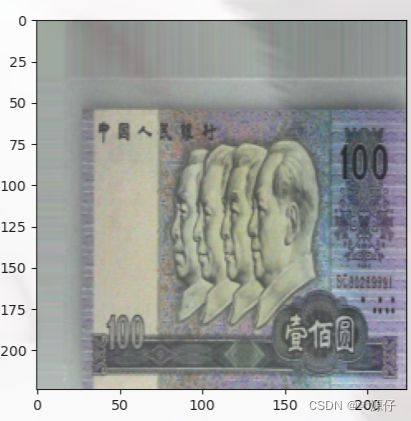
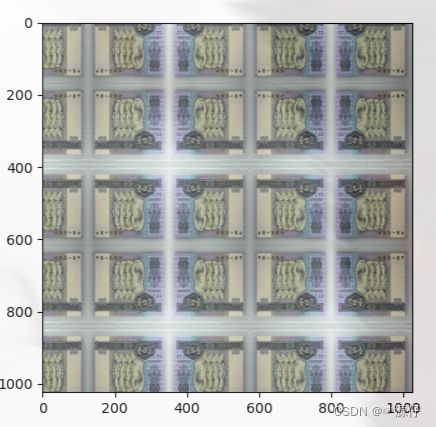
答:数据增强又称为数据增广,数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力。(下图是一个很形象的比喻)

下图右边的64张图片是由左边的这一张图片生成的,比如采用了图像的旋转、颜色扰动、随机裁剪等。

transforms——Crop
transforms.Resize(224,224)后的图片:

1、transforms.CenterCrop
| transforms.CenterCrop |

train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 CenterCrop
transforms.CenterCrop(194), # 194
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
CenterCrop(194)后的图片。

2、transforms.RandomCrop
| transforms.CenterCrop |


| 1、transforms.RandomCrop(224, padding=16) |
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 2 RandomCrop
transforms.RandomCrop(224, padding=16),
# transforms.RandomCrop(224, padding=(16, 64)),
# transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)),
# transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True
# transforms.RandomCrop(224, padding=64, padding_mode='edge'),
# transforms.RandomCrop(224, padding=64, padding_mode='reflect'),
# transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])

疑问1:
上面的padding:设置填充大小的定义不是说,当为a时,上下左右均填充a个像素,为啥我们上面的输出的图片好像只对左和下做了填充。答:因为我们首先对
Resize到(224,224)图片进行padding=16上下左右的填充得到新的图片大小为(256,256),然后再执行RandomCrop(224)随机裁剪,那为啥叫随机裁剪呢,因为对图片进行裁剪的位置是不固定的,这里正好是从左下方对(256,256)的图片裁剪到(224,224),所以上面和右边的填充部分被裁剪掉了。
疑问2:
为啥填充的是黑色呢?因为默认填充为(0,0,0),也就是黑色。这里的颜色可参考RGB。
| 2、transforms.RandomCrop(224, padding=(16, 64)) |
当为
(16, 64)时,上下填充64个像素,左右填充16个像素

| 3、transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)) |
fill:constant时,设置填充的像素值(255,0,0)为红色。

| 4、transforms.RandomCrop(512, pad_if_needed=True) |
pad_if_need:若图像小于设定size,则需要填充,这时pad_if_need应该设置为True,默认情况为False。比如这里要把
(224,224)大小的图片裁剪为(512,512).

| 5、transforms.RandomCrop(224, padding=64, padding_mode='edge') |
padding_mode=‘edge’
edge:像素值由图像边缘像素决定。
通俗的来说就是填充的像素时,图片边缘的颜色。
| 6、transforms.RandomCrop(224, padding=64, padding_mode='reflect') |
padding_mode='reflect'
reflect:镜像填充,并对边缘像素不镜像(比如这里的1和4),eg:[1,2,3,4] → [3,2,1,2,3, 4,3,2]
这里可以看我说的视频进行理解。

| 7、RandomCrop(1024, padding=1024, padding_mode='symmetric') |
padding_mode='symmetric'
symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4] → [2,1,1,2,3,4,4,3]
当裁剪的size大于原本resize图片的大小时,镜像效果如下。
3、FiveCrop和TenCrop

transforms——翻转、旋转(Flip and Rotation)
transforms_Flip

原图如下:

# 水平旋转 p=1指(旋转概率百分百)
transforms.RandomHorizontalFlip(p=1)

# 2 Vertical Flip
transforms.RandomVerticalFlip(p=1)

RandomRotation

本节旋转内容在第四个旋转视频中详细的讲解。其实也没啥好说的。
transforms.RandomRotation(90),

transforms.RandomRotation((90), expand=True),
# transforms.RandomRotation(30, center=(0, 0)),
# transforms.RandomRotation(30, center=(0, 0), expand=True), # expand only for center rotation

transforms.RandomRotation(30, center=(0, 0)),
# transforms.RandomRotation(30, center=(0, 0), expand=True), # expand only for center rotation

transforms.RandomRotation(30, center=(0, 0), expand=True), # expand only for center rotation
