论文阅读《What is Normal, What is Strange, and What is Missing in aKnowledge Graph》
论文链接:https://arxiv.org/abs/2003.10412
知识图谱质量控制算法-KGIST
模型简介
KGIST通过归纳总结统一表征在KGs中什么是正常的、什么是奇怪的、什么是缺失的。
关于处理知识图谱错误和缺失信息的标准方法是“知识图谱细化”,这涉及针对每种类型的错误或缺失信息定制技术,但这有很多限制,首先是针对每种错误类型和缺失类型定制技术所涉及的开发时间和成本,第二是不可能针对未知类型的错误定制方法,我们不可能为未知的错误类型开发一种方法,第三是如果我们想在知识上运行一套不同的定制技术,图有可能是非常密集的(知识图谱非常大,新的事实添加到KG中时,图谱会变得更大,使这个问题变得更糟糕)。
我们换一个角度来看待问题,我们想知道这些不同类型的奇怪和缺失的共同特征是什么,它们都是异常事实的实例,与正常事实形成对比。
梳理一下我们的问题,图谱中存在错误和缺失,当前的解决方案是针对每种类型的错误或缺失信息定制方法,首先在开发成本上不可能,其次针对我们不知道的领域无法定制方法,最后在大型知识图谱上运行这些不同的方法会占用大量资源。在本文工作中,我们不会将这些问题视为不同的问题,而是将他们视为一个问题(即,发现异常),将问题转化为归纳总结,“总结”允许我们识别什么是正常的,然后所有不正常的都是异常,我们不太关心为什么它是异常的,尽管我们能够推理,因为它是我们所有“丢失”和“错误”信息的共同特征。
我们的模型简称为KGist, 它指出如果给定知识图谱G,我们希望找到该图G的简明摘要,并且我们希望摘要包含归纳,软规则。这些规则将作为我们对什么是正常的描述或总结,这将允许我们识别什么是异常的(规则的例外)。我们通过对问题的转换将不同的细化任务统一为一个任务,使用富有表现力的图形结构规则,使用简洁的基于最小描述长度(MDL) 的方法。
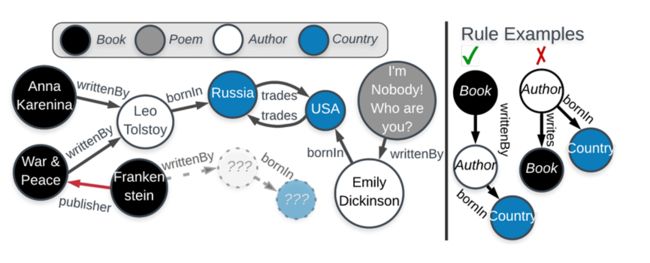 KGIST的检测过程
KGIST的检测过程
1.2 模型结构
知识图谱被视为带标记的有向图,图谱的边就是三元组(由主语、关系、宾语)组成,我们可以在数学上将它表示为邻接张量,其中张量的每个切片对应特定的关系类型,除此之外我们还有一个二元标签矩阵,它指定每个实体的标签。
首先,该论文引入一个新的规则图论公式,将规则递归定义为有根的、有向、有标记的图。
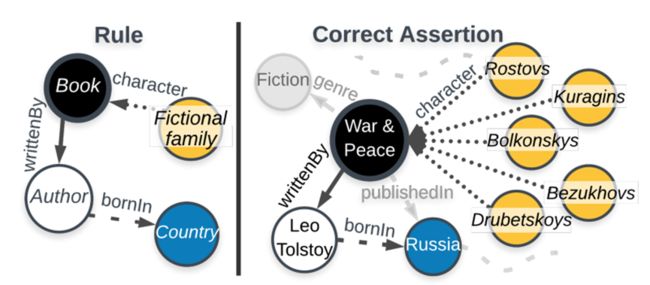 KGIST的规则图论公式
KGIST的规则图论公式
如图10左边的规则适用于书籍,它特别断言关于它们的两件事,它断言它们具有虚构的家庭角色,并且它们是由出生在某些国家的作者写的。断言关于特定节点的事情时,它会在该节点周围引发一个子图,例如图10右边所示,书规则描述的内容适用于《战争与和平》,它断言一本书应该有一些虚拟的家庭角色,它拥有五个角色,它还断言书应该由一位作者写成,列夫托尔斯泰,作者出生于俄罗斯。所以针对一个节点,会导出一个子图,通过遵循规则隐含的引导遍历来实现的,所有这些遍历的集合被称为规则正确断言。
断言的总集合是正确的断言加上规则的例外情况:
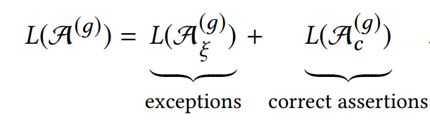
根据最小描述距离,如果我们得到一些称之为G的数据,我们想找到一个描述该数据的模型M,我们希望最小化描述。描述长度分为两部分,第一是我们需要描述的模型M的位数,第二个是给定模型M描述的位数数据,我们需要多少位来描述数据,这具有一个关键优势,因为我们正在尝试最小化它,从而形成一个更小的模型,可以更容易地使用我们的模型来改进大型知识图谱。这涉及四个步骤,第一步是定义模型是什么/定义模型空间,第二步是推导或定义描述的长度以及第三步模型下数据的描述长度,第四步是从模型空间中选择一个模型,即最小化描述长度的模型。
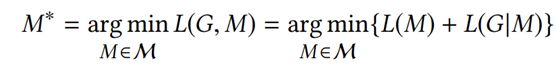
因此我们现在可以重新表述我们的问题,给定知识图谱的最小描述链接原则,我们希望找到简洁的归纳规则集M,使描述长度最小化,如果这里的M是我们的规则集,那么这些规则用于描述什么使正常的,然后描述链接的那部分昂贵的部分将揭示什么是异常的。
接下来我们将以信息论的方式展示如何根据最小描述长度原则更详细地表述我们的问题。
第一步再次是定义模型是什么,我们将非常简单的将其定义为一组规则,每个规则都有正确的断言,这些正确的断言首先用于描述图的结构,再次是引导遍历,所以其导出的子图的边缘已经由规则描述,它还描述了一些语义,因为它揭示了诱导子图中的标签。
第二步是推导描述长度,我们得到的信息有独立信息(图中结点数、边数)、图谱摘要模型(一组规则)以及规则的例外,我们使用它们来完善标签矩阵和张量矩阵。
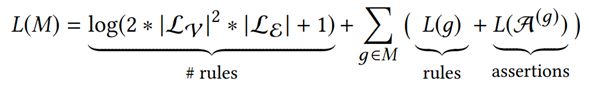
我们通过对独立信息中的规则与例外,来填充标签矩阵和张量矩阵。
![]()
下一步是驱动找到这样一个模型的方法,模型是一组规则,所以我们可以想象所有可能规则的集合或者代替候选规则和任何子集候选规则是一个有效模型,问题是这些规则呈指数增长,因此为了避免枚举或搜索的指数空间,我们将从简单的候选规则开始,简单的意思是它们只断言一件事并将它们组合成更复杂和更具表现力的东西。
所以第一步是生成这些候选规则,我们将通过迭代图来做到这一点,每次遇到边时,我们解释它的规则,例如如果我们遇到一个演奏音乐的人,那么我们将生成描述该示意图结构的规则,因此我们也有可能生成作者写的书、城市制造的车和山脉属于地方。
下一步是对模型中考虑的规则进行排名,并将通过测量它们压缩图的程度来实现,当我们计算出这个压缩值,我们将根据它们实现的压缩量对它们进行排名,并考虑按照这个顺序来建模。描述长度通过添加规则而获得减少那么我们将保留,如果描述长度增加了,那么我们会把它扔掉。

所以此时我们找到一些简单规则,我们想让这些规则更具表现力,所以我们将介绍两个细化步骤,第一个是合并细化,如果我们有作者写的书和出版商出版的书,那么我们可以将它们合并为一个规则。第二个规则是嵌套,如果我们有“山脉位于地方”的规则,和“轨迹包含地方”的规则时(第二条规则不是很准确,因为有很多地方它们不包含在轨迹中),我们可以通过嵌套使其更准确,嵌套后它只适用于山区、自然地区这些更有可能具备轨迹特征的地方。
最后进行异常检测,首先是违反很多规则的节点很可能是异常的,我们可以通过将结点花费的比特数相加来捕获这一点。
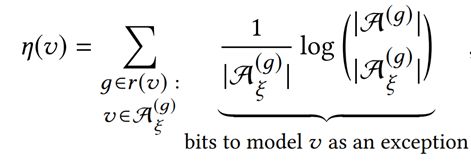
另外对于边来说,它的异常由两部分组成,第一是模型未解释的边可能是异常的,第二具有异常端点更多的边可能是异常的。
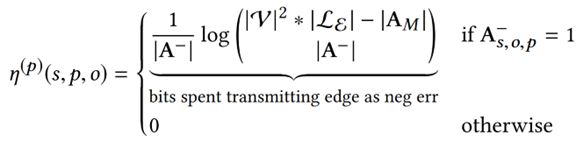
我们将二者相加,可以保证异常边不会获得相同的分数。
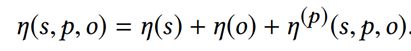
1.3 实验结果
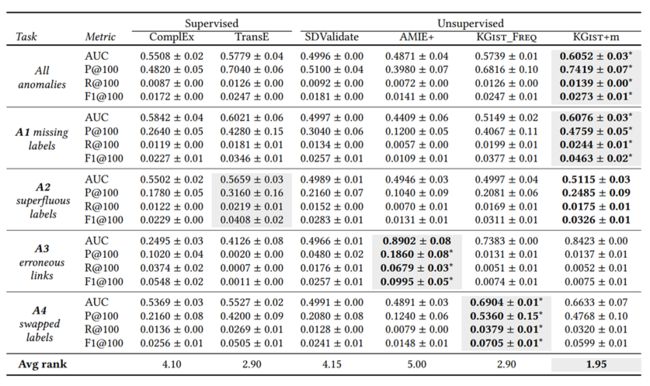 KGIST的实验结果
KGIST的实验结果
1.4.实验分析
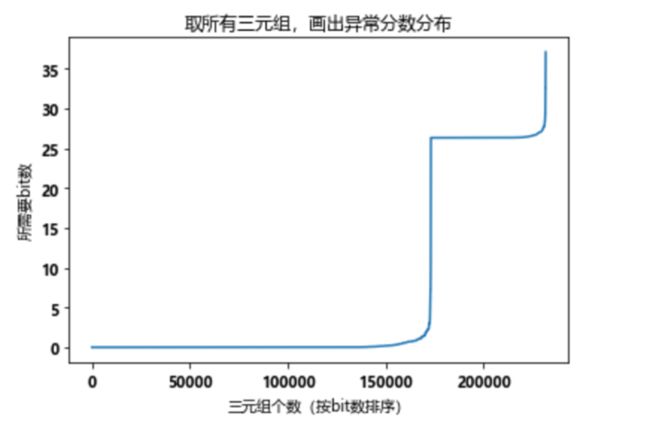
NELL数据集中三元组的得分排名
虽然KGIST是一个非常漂亮的工作,但我在对异常得分高的三元组进行查看时,发现异常得分高的三元组中很多它们的实体属于没有被压缩的实体类别,并且KGIST只能解决图谱结构方面的异常。
github链接:https://github.com/GemsLab/KGist