ElasticSearch系列——文档操作
文章目录
- Elasticsearch的增删查改(CURD)
-
- 一 CURD之Create
- 二 CURD之Update
- 三 CURD之Delete
- 四 CURD之Retrieve
- Elasticsearch之查询的两种方式
-
- 一 前言
- 二 准备数据
- 三 查询字符串
- 四 结构化查询
- term与match查询
-
- 一 match查询
-
- 1.1 准备数据
- 1.2 match系列之match(按条件查询)
- 1.3 match系列之match_all(查询全部)
- 1.4 match系列之match_phrase(短语查询)
- 1.4 match系列之match_phrase_prefix(最左前缀查询)
- 1.5 match系列之multi_match(多字段查询)
- 二 term查询
- 4 Elasticsearch之排序查询
-
- 一 准备数据
- 二 排序查询:sort
-
- 2.1 降序:desc
- 2.2 升序:asc
- 三 不是什么数据类型都能排序
- 4 Elasticsearch之排序查询
-
- 一 准备数据
- 二 排序查询:sort
-
- 2.1 降序:desc
- 2.2 升序:asc
- 三 不是什么数据类型都能排序
- 5-Elasticsearch之分页查询
-
- 一 准备数据
- 二 分页查询:from/size
- 6-Elasticsearch之布尔查询
-
- 一 前言
- 二 准备数据
- 三 must
- 四 should
- 五 must_not
- 6 filter
- 7-Elasticsearch之查询结果过滤
-
- 一 前言
- 二 准备数据
- 三 结果过滤:_source
- 7-Elasticsearch之高亮查询
-
- 一 前言
- 二 准备数据
- 三 默认高亮显示
- 四 自定义高亮显示
- 8-Elasticsearch之聚合函数
-
- 一 前言
- 二 准备数据
- 三 avg
- 四 max
- 五 min
- 六 sum
- 七 分组查询
- 9-Elasticsearch之mappings
-
- 一 前言
- 二 映射是什么?
- 三 映射类型
- 四 字段的数据类型
- 五 映射约束
- 六 一个简单的映射示例
- 10-Elasticsearch mappings之dynamic的三种状态
-
- 一 前言
- 二 动态映射(dynamic:true)
- 三 静态映射(dynamic:false)
- 四 严格模式(dynamic:strict)
- 一 前言
- 二 index
- 三 copy_to
- 四 对象属性
- 五 settings设置
-
- 5.1 设置主、复制分片
- 12-Elasticsearch之mappings parameters
-
- 一 ignore_above
- 13-Elasticsearch - 分析过程
-
- 一 前言
- 二分析过程
- 三分析器
-
- 3.1 标准分析器:standard analyzer
- 3.2 简单分析器:simple analyzer
- 3.3 空白分析器:whitespace analyzer
- 3.4 停用词分析器:stop analyzer
- 3.5 关键词分析器:keyword analyzer
- 3.6 模式分析器:pattern analyzer
- 3.7 语言和多语言分析器:chinese
- 3.8 雪球分析器:snowball analyzer
- 四 字符过滤器
-
- 4.1 HTML字符过滤器
- 4.2 映射字符过滤器
- 4.3 模式替换过滤器
- 五 分词器
-
- 5.1 标准分词器:standard tokenizer
- 5.2 关键词分词器:keyword tokenizer
- 5.3 字母分词器:letter tokenizer
- 5.4 小写分词器:lowercase tokenizer
- 5.5 空白分词器:whitespace tokenizer
- 5.6 模式分词器:pattern tokenizer
- 5.7 UAX URL电子邮件分词器:UAX RUL email tokenizer
- 5.8 路径层次分词器:path hierarchy tokenizer
- 六 分词过滤器
-
- 6.1 自定义分词过滤器
- 6.2 自定义小写分词过滤器
- 6.3 多个分词过滤器
- 14-Elasticsearch - ik分词器
-
- 一 前言
- 二 ik分词器的由来
- 三 IK分词器插件的安装
-
- 3.1 安装
- 3.2 测试
- 3.3 ik目录简介
- 四 ik分词器的使用
-
- 4.1 第一个ik示例
- 4.2 ik_max_word
- 4.3 ik_smart
- 4.4 ik之短语查询
- 4.5 ik之短语前缀查询
- 15-Elasticsearch for Python之连接
-
- 一 前言
- 二 依赖下载
- 三 Python连接elasticsearch
- 四 配置忽略响应状态码
- 五 一个简单的示例
- 16-Elasticsearch for Python之操作
-
- 一 前言
- 二 结果过滤
- 三 Elasticsearch(es对象)
- 四 Indices(es.indices)
- 五 Cluster(集群相关)
- 六 Node(节点相关)
- 七 Cat(一种查询方式)
- 八 Snapshot(快照相关)
- 九 Task(任务相关)
Elasticsearch的增删查改(CURD)
一 CURD之Create
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
他明处貌似还有俩老婆:
PUT lqz/doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
家里红旗不倒,家外彩旗飘摇:
PUT lqz/doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
注意:当执行PUT命令时,如果数据不存在,则新增该条数据,如果数据存在则修改该条数据。
咱们通过GET命令查询一下:
GET lqz/doc/1
结果如下:
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
}
查询也没啥问题,但是你可能说了,人家老二是黄种人,怎么是黑的呢?好吧咱改改desc和tags:
PUT lqz/doc/1
{
"desc":"皮肤很黄,武器很长,性格很直",
"tags":["很黄","很长", "很直"]
}
上例,我们仅修改了desc和tags两处,而name、age和from三个属性没有变化,我们可以忽略不写吗?查查看:
GET lqz/doc/1
结果如下:
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"desc" : "皮肤很黄,武器很长,性格很直",
"tags" : [
"很黄",
"很长",
"很直"
]
}
}
哎呀,出事故了!修改是修改了,但结果不太理想啊,因为name、age和from属性都没啦!
注意:**PUT命令,在做修改操作时,如果未指定其他的属性,则按照指定的属性进行修改操作。**也就是如上例所示的那样,我们修改时只修改了desc和tags两个属性,其他的属性并没有一起添加进去。
很明显,这是病!dai治!怎么治?上车,咱们继续往下走!
二 CURD之Update
让我们首先恢复一下事故现场:
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
我们要将黑修改成黄:
POST lqz/doc/1/_update
{
"doc": {
"desc": "皮肤很黄,武器很长,性格很直",
"tags": ["很黄","很长", "很直"]
}
}
上例中,我们使用POST命令,在id后面跟_update,要修改的内容放到doc文档(属性)中即可。
我们再来查询一次:
GET lqz/doc/1
结果如下:
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_version" : 5,
"found" : true,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤很黄,武器很长,性格很直",
"tags" : [
"很黄",
"很长",
"很直"
]
}
}
结果如上例所示,现在其他的属性没有变化,只有desc和tags属性被修改。
注意:POST命令,这里可用来执行修改操作(还有其他的功能),POST命令配合_update完成修改操作,指定修改的内容放到doc中。
写了这么多,我也发现我上面有讲的不对的地方——石头不是跟顾老二不清不楚,石头是跟小桃不清不楚!好吧,刚才那个数据是一个错误示范!我们这就把它干掉!
三 CURD之Delete
DELETE lqz/doc/4
很简单,通过DELETE命令,就可以删除掉那个错误示范了!
删除效果如下:
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_version" : 4,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}
我们再来查询一遍:
GET lqz/doc/4
结果如下:
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"found" : false
}
上例中,found:false表示查询数据不存在。
四 CURD之Retrieve
我们上面已经不知不觉的使用熟悉这种简单查询方式,通过 GET命令查询指定文档:
GET lqz/doc/1
结果如下:
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_version" : 5,
"found" : true,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤很黄,武器很长,性格很直",
"tags" : [
"很黄",
"很长",
"很直"
]
}
}
Elasticsearch之查询的两种方式
一 前言
简单的没挑战,来点复杂的,elasticsearch提供两种查询方式:
- 查询字符串(query string),简单查询,就像是像传递URL参数一样去传递查询语句,被称为简单搜索或查询字符串(query string)搜索。
- 另外一种是通过DSL语句来进行查询,被称为DSL查询(Query DSL),DSL是Elasticsearch提供的一种丰富且灵活的查询语言,该语言以json请求体的形式出现,通过restful请求与Elasticsearch进行交互。
二 准备数据
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
PUT lqz/doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
PUT lqz/doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
三 查询字符串
GET lqz/doc/_search?q=from:gu
还是使用GET命令,通过_serarch查询,查询条件是什么呢?条件是from属性是gu家的人都有哪些。最后,别忘了_search和from属性中间的英文分隔符?
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
我们来重点说下hits,hits是返回的结果集——所有from属性为gu的结果集。重点中的重点是_score得分,得分是什么呢?根据算法算出跟查询条件的匹配度,匹配度高得分就高。后面再说这个算法是怎么回事。
四 结构化查询
我们现在使用DSL方式,来完成刚才的查询,查看来自顾家的都有哪些人。
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
}
}
上例,查询条件是一步步构建出来的,将查询条件添加到match中即可,而match则是查询所有from字段的值中含有gu的结果就会返回。
当然结果没啥变化:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
term与match查询
一 match查询
1.1 准备数据
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
PUT lqz/doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
PUT lqz/doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
1.2 match系列之match(按条件查询)
我们查看来自顾家的都有哪些人。
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
}
}
上例,查询条件是一步步构建出来的,将查询条件添加到match中即可,而match则是查询所有from字段的值中含有gu的结果就会返回。
结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
1.3 match系列之match_all(查询全部)
除了按条件查询之外,我们还可以查询lqz索引下的doc类型中的所有文档,那就是查询全部:
GET lqz/doc/_search
{
"query": {
"match_all": {}
}
}
match_all的值为空,表示没有查询条件,那就是查询全部。就像select * from table_name一样。
查询结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 1.0,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "魏行首",
"age" : 25,
"from" : "广云台",
"desc" : "仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags" : [
"闭月",
"羞花"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "大娘子",
"age" : 18,
"from" : "sheng",
"desc" : "肤白貌美,娇憨可爱",
"tags" : [
"白",
"富",
"美"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
返回的是lqz索引下doc类型的所有文档!
1.4 match系列之match_phrase(短语查询)
我们现在已经对match有了基本的了解,match查询的是散列映射,包含了我们希望搜索的字段和字符串。也就说,只要文档中只要有我们希望的那个关键字,但也因此带来了一些问题。
首先来创建一些示例:
PUT t1/doc/1
{
"title": "中国是世界上人口最多的国家"
}
PUT t1/doc/2
{
"title": "美国是世界上军事实力最强大的国家"
}
PUT t1/doc/3
{
"title": "北京是中国的首都"
}
现在,当我们以中国作为搜索条件,我们希望只返回和中国相关的文档。我们首先来使用match查询:
GET t1/doc/_search
{
"query": {
"match": {
"title": "中国"
}
}
}
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.68324494,
"hits" : [
{
"_index" : "t1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.68324494,
"_source" : {
"title" : "中国是世界上人口最多的国家"
}
},
{
"_index" : "t1",
"_type" : "doc",
"_id" : "3",
"_score" : 0.5753642,
"_source" : {
"title" : "北京是中国的首都"
}
},
{
"_index" : "t1",
"_type" : "doc",
"_id" : "2",
"_score" : 0.39556286,
"_source" : {
"title" : "美国是世界上军事实力最强大的国家"
}
}
]
}
}
虽然如期的返回了中国的文档。但是却把和美国的文档也返回了,这并不是我们想要的。是怎么回事呢?因为这是elasticsearch在内部对文档做分词的时候,对于中文来说,就是一个字一个字分的,所以,我们搜中国,中和国都符合条件,返回,而美国的国也符合。
而我们认为中国是个短语,是一个有具体含义的词。所以elasticsearch在处理中文分词方面比较弱势。后面会讲针对中文的插件。
但目前我们还有办法解决,那就是使用短语查询:
GET t1/doc/_search
{
"query": {
"match_phrase": {
"title": {
"query": "中国"
}
}
}
}
这里match_phrase是在文档中搜索指定的词组,而中国则正是一个词组,所以愉快的返回了。
那么,现在我们要想搜索中国和世界相关的文档,但又忘记其余部分了,怎么做呢?用match也不行,那就继续用match_phrase试试:
GET t1/doc/_search
{
"query": {
"match_phrase": {
"title": "中国世界"
}
}
}
返回结果也是空的,因为没有中国世界这个短语。
我们搜索中国和世界这两个指定词组时,但又不清楚两个词组之间有多少别的词间隔。那么在搜的时候就要留有一些余地。这时就要用到了slop了。相当于正则中的中国.*?世界。这个间隔默认为0,导致我们刚才没有搜到,现在我们指定一个间隔。
GET t1/doc/_search
{
"query": {
"match_phrase": {
"title": {
"query": "中国世界",
"slop": 2
}
}
}
}
现在,两个词组之间有了2个词的间隔,这个时候,就可以查询到结果了:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.7445889,
"hits" : [
{
"_index" : "t1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.7445889,
"_source" : {
"title" : "中国是世界上人口最多的国家"
}
}
]
}
}
slop间隔你可以根据需要适当改动。
短语查询, 比如要查询:python系统
会把查询条件python和系统分词,放到列表中,再去搜索的时候,必须满足python和系统同时存在的才能搜出来
“slop”:6 :python和系统这两个词之间最小的距离
1.4 match系列之match_phrase_prefix(最左前缀查询)
现在凌晨2点半,单身狗小黑为了缓解寂寞,就准备搜索几个beautiful girl来陪伴自己。但是由于英语没过2级,但单词beautiful拼到bea就不知道往下怎么拼了。这个时候,我们的智能搜索要帮他啊,elasticsearch就看自己的词库有啥事bea开头的词,结果还真发现了两个:
PUT t3/doc/1
{
"title": "maggie",
"desc": "beautiful girl you are beautiful so"
}
PUT t3/doc/2
{
"title": "sun and beach",
"desc": "I like basking on the beach"
}
但这里用match和match_phrase都不太合适,因为小黑输入的不是完整的词。那怎么办呢?我们用match_phrase_prefix来搞:
GET t3/doc/_search
{
"query": {
"match_phrase_prefix": {
"desc": "bea"
}
}
}
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.39556286,
"hits" : [
{
"_index" : "t3",
"_type" : "doc",
"_id" : "1",
"_score" : 0.39556286,
"_source" : {
"title" : "maggie",
"desc" : "beautiful girl,you are beautiful so"
}
},
{
"_index" : "t3",
"_type" : "doc",
"_id" : "2",
"_score" : 0.2876821,
"_source" : {
"title" : "sun and beach",
"desc" : "I like basking on the beach"
}
}
]
}
}
前缀查询是短语查询类似,但前缀查询可以更进一步的搜索词组,只不过它是和词组中最后一个词条进行前缀匹配(如搜这样的you are bea)。应用也非常的广泛,比如搜索框的提示信息,当使用这种行为进行搜索时,最好通过max_expansions来设置最大的前缀扩展数量,因为产生的结果会是一个很大的集合,不加限制的话,影响查询性能。
GET t3/doc/_search
{
"query": {
"match_phrase_prefix": {
"desc": {
"query": "bea",
"max_expansions": 1
}
}
}
}
但是,如果此时你去尝试加上max_expansions测试后,你会发现并没有如你想想的一样,仅返回一条数据,而是返回了多条数据。
max_expansions执行的是搜索的编辑(Levenshtein)距离。那什么是编辑距离呢?编辑距离是一种计算两个字符串间的差异程度的字符串度量(string metric)。我们可以认为编辑距离就是从一个字符串修改到另一个字符串时,其中编辑单个字符(比如修改、插入、删除)所需要的最少次数。俄罗斯科学家Vladimir Levenshtein于1965年提出了这一概念。
我们再引用elasticsearch官网的一段话:该max_expansions设置定义了在停止搜索之前模糊查询将匹配的最大术语数,也可以对模糊查询的性能产生显着影响。但是,减少查询字词会产生负面影响,因为查询提前终止可能无法找到某些有效结果。重要的是要理解max_expansions查询限制在分片级别工作,这意味着即使设置为1,多个术语可能匹配,所有术语都来自不同的分片。此行为可能使其看起来好像max_expansions没有生效,因此请注意,计算返回的唯一术语不是确定是否有效的有效方法max_expansions。。
我想你也没看懂这句话是啥意思,但我们只需知道该参数工作于分片层,也就是Lucene部分,超出我们的研究范围了。
我们快刀斩乱麻的记住,使用前缀查询会非常的影响性能,要对结果集进行限制,就加上这个参数。
1.5 match系列之multi_match(多字段查询)
现在,我们有一个50个字段的索引,我们要在多个字段中查询同一个关键字,该怎么做呢?
PUT t3/doc/1
{
"title": "maggie is beautiful girl",
"desc": "beautiful girl you are beautiful so"
}
PUT t3/doc/2
{
"title": "beautiful beach",
"desc": "I like basking on the beach,and you? beautiful girl"
}
我们先用原来的方法查询:
GET t3/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "beautiful"
}
},
{
"match": {
"desc": "beautiful"
}
}
]
}
}
}
使用must来限制两个字段(值)中必须同时含有关键字。这样虽然能达到目的,但是当有很多的字段呢,我们可以用multi_match来做:
GET t3/doc/_search
{
"query": {
"multi_match": {
"query": "beautiful",
"fields": ["title", "desc"]
}
}
}
我们将多个字段放到fields列表中即可。以达到匹配多个字段的目的。
除此之外,multi_match甚至可以当做match_phrase和match_phrase_prefix使用,只需要指定type类型即可:
GET t3/doc/_search
{
"query": {
"multi_match": {
"query": "gi",
"fields": ["title"],
"type": "phrase_prefix"
}
}
}
GET t3/doc/_search
{
"query": {
"multi_match": {
"query": "girl",
"fields": ["title"],
"type": "phrase"
}
}
}
小结:
- match:返回所有匹配的分词。
- match_all:查询全部。
- match_phrase:短语查询,在match的基础上进一步查询词组,可以指定
slop分词间隔。 - match_phrase_prefix:前缀查询,根据短语中最后一个词组做前缀匹配,可以应用于搜索提示,但注意和
max_expanions搭配。其实默认是50… - multi_match:多字段查询,使用相当的灵活,可以完成
match_phrase和match_phrase_prefix的工作。
二 term查询
默认情况下,elasticsearch在对文档分析期间(将文档分词后保存到倒排索引中),会对文档进行分词,比如默认的标准分析器会对文档进行:
- 删除大多数的标点符号。
- 将文档分解为单个词条,我们称为token。
- 将token转为小写。
完事再保存到倒排索引上,当然,原文件还是要保存一分的,而倒排索引使用来查询的。
例如Beautiful girl!,在经过分析后是这样的了:
POST _analyze
{
"analyzer": "standard",
"text": "Beautiful girl!"
}
# 结果
["beautiful", "girl"]
而当在使用match查询时,elasticsearch同样会对查询关键字进行分析:
PUT w10
{
"mappings": {
"doc":{
"properties":{
"t1":{
"type": "text"
}
}
}
}
}
PUT w10/doc/1
{
"t1": "Beautiful girl!"
}
PUT w10/doc/2
{
"t1": "sexy girl!"
}
GET w10/doc/_search
{
"query": {
"match": {
"t1": "Beautiful girl!"
}
}
}
也就是对查询关键字Beautiful girl!进行分析,得到["beautiful", "girl"],然后分别将这两个单独的token去索引w10中进行查询,结果就是将两篇文档都返回。
这在有些情况下是非常好用的,但是,如果我们想查询确切的词怎么办?也就是精确查询,将Beautiful girl!当成一个token而不是分词后的两个token。
这就要用到了term查询了,term查询的是没有经过分析的查询关键字。
但是,这同样需要限制,如果你要查询的字段类型(如上例中的字段t1类型是text)是text(因为elasticsearch会对文档进行分析,上面说过),那么你得到的可能是不尽如人意的结果或者压根没有结果:
GET w10/doc/_search
{
"query": {
"term": {
"t1": "Beautiful girl!"
}
}
}
如上面的查询,将不会有结果返回,因为索引w10中的两篇文档在经过elasticsearch分析后没有一个分词是Beautiful girl!,那此次查询结果为空也就好理解了。
所以,我们这里得到一个论证结果:不要使用term对类型是text的字段进行查询,要查询text类型的字段,请改用match查询。
学会了吗?那再来一个示例,你说一下结果是什么:
GET w10/doc/_search
{
"query": {
"term": {
"t1": "Beautiful"
}
}
}
答案是,没有结果返回!因为elasticsearch在对文档进行分析时,会经过小写!人家倒排索引上存的是小写的beautiful,而我们查询的是大写的Beautiful。
所以,要想有结果你这样:
GET w10/doc/_search
{
"query": {
"term": {
"t1": "beautiful"
}
}
}
那,term查询可以查询哪些类型的字段呢,例如elasticsearch会将keyword类型的字段当成一个token保存到倒排索引上,你可以将term和keyword结合使用。
最后,要想使用term查询多个精确的值怎么办?我只能说:亲,这里推荐卸载es呢!低调又不失尴尬的玩笑!
这里推荐使用terms查询:
GET w10/doc/_search
{
"query": {
"terms": {
"t1": ["beautiful", "sexy"]
}
}
}
4 Elasticsearch之排序查询
一 准备数据
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
PUT lqz/doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
PUT lqz/doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
二 排序查询:sort
2.1 降序:desc
想到排序,出现在脑海中的无非就是升(正)序和降(倒)序。比如我们查询顾府都有哪些人,并根据age字段按照降序,并且,我只想看nmae和age字段:
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
上例,在条件查询的基础上,我们又通过sort来做排序,根据age字段排序,是降序呢还是升序,由order字段控制,desc是降序。
结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : null,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : null,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
},
"sort" : [
30
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : null,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
},
"sort" : [
29
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : null,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
},
"sort" : [
22
]
}
]
}
}
上例中,结果是以降序排列方式返回的。
2.2 升序:asc
那么想要升序怎么搞呢?
GET lqz/doc/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
上例,想要以升序的方式排列,只需要将order值换为asc就可以了。
结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : null,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "大娘子",
"age" : 18,
"from" : "sheng",
"desc" : "肤白貌美,娇憨可爱",
"tags" : [
"白",
"富",
"美"
]
},
"sort" : [
18
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : null,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
},
"sort" : [
22
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "5",
"_score" : null,
"_source" : {
"name" : "魏行首",
"age" : 25,
"from" : "广云台",
"desc" : "仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags" : [
"闭月",
"羞花"
]
},
"sort" : [
25
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : null,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
},
"sort" : [
29
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : null,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
},
"sort" : [
30
]
}
]
}
}
上例,可以看到结果是以age从小到大的顺序返回结果。
三 不是什么数据类型都能排序
那么,你可能会问,除了age,能不能以别的属性作为排序条件啊?来试试:
GET lqz/chengyuan/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"name": {
"order": "asc"
}
}
]
}
上例,我们以name属性来排序,来看结果:
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "lqz",
"node": "wrtr435jSgi7_naKq2Y_zQ",
"reason": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
],
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
},
"status": 400
}
结果跟我们想象的不一样,报错了!
注意:在排序的过程中,只能使用可排序的属性进行排序。那么可以排序的属性有哪些呢?
- 数字
- 日期
其他的都不行!
4 Elasticsearch之排序查询
一 准备数据
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
PUT lqz/doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
PUT lqz/doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
二 排序查询:sort
2.1 降序:desc
想到排序,出现在脑海中的无非就是升(正)序和降(倒)序。比如我们查询顾府都有哪些人,并根据age字段按照降序,并且,我只想看nmae和age字段:
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
上例,在条件查询的基础上,我们又通过sort来做排序,根据age字段排序,是降序呢还是升序,由order字段控制,desc是降序。
结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : null,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : null,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
},
"sort" : [
30
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : null,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
},
"sort" : [
29
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : null,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
},
"sort" : [
22
]
}
]
}
}
上例中,结果是以降序排列方式返回的。
2.2 升序:asc
那么想要升序怎么搞呢?
GET lqz/doc/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
上例,想要以升序的方式排列,只需要将order值换为asc就可以了。
结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : null,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "大娘子",
"age" : 18,
"from" : "sheng",
"desc" : "肤白貌美,娇憨可爱",
"tags" : [
"白",
"富",
"美"
]
},
"sort" : [
18
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : null,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
},
"sort" : [
22
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "5",
"_score" : null,
"_source" : {
"name" : "魏行首",
"age" : 25,
"from" : "广云台",
"desc" : "仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags" : [
"闭月",
"羞花"
]
},
"sort" : [
25
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : null,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
},
"sort" : [
29
]
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : null,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
},
"sort" : [
30
]
}
]
}
}
上例,可以看到结果是以age从小到大的顺序返回结果。
三 不是什么数据类型都能排序
那么,你可能会问,除了age,能不能以别的属性作为排序条件啊?来试试:
GET lqz/chengyuan/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"name": {
"order": "asc"
}
}
]
}
上例,我们以name属性来排序,来看结果:
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "lqz",
"node": "wrtr435jSgi7_naKq2Y_zQ",
"reason": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
],
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
},
"status": 400
}
结果跟我们想象的不一样,报错了!
注意:在排序的过程中,只能使用可排序的属性进行排序。那么可以排序的属性有哪些呢?
- 数字
- 日期
其他的都不行!
5-Elasticsearch之分页查询
一 准备数据
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
PUT lqz/doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
PUT lqz/doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
二 分页查询:from/size
我们来看看elasticsearch是怎么将结果分页的:
GET lqz/doc/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 2,
"size": 1
}
上例,首先以age降序排序,查询所有。并且在查询的时候,添加两个属性from和size来控制查询结果集的数据条数。
- from:从哪开始查
- size:返回几条结果
如上例的结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : null,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "5",
"_score" : null,
"_source" : {
"name" : "魏行首",
"age" : 25,
"from" : "广云台",
"desc" : "仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags" : [
"闭月",
"羞花"
]
},
"sort" : [
25
]
}
]
}
}
上例中,在返回的结果集中,从第2条开始,返回1条数据。
那如果想要从第2条开始,返回2条结果怎么做呢?
GET lqz/doc/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 2,
"size": 2
}
上例中,我们指定from为2,意为从第2条开始返回,返回多少呢?size意为2条。
还可以这样:
GET lqz/doc/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 4,
"size": 2
}
上例中,从第4条开始返回2条数据。
结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : null,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "2",
"_score" : null,
"_source" : {
"name" : "大娘子",
"age" : 18,
"from" : "sheng",
"desc" : "肤白貌美,娇憨可爱",
"tags" : [
"白",
"富",
"美"
]
},
"sort" : [
18
]
}
]
}
}
上例中仅有一条数据,那是为啥呢?因为我们现在只有5条数据,从第4条开始查询,就只有1条符合条件,所以,就返回了1条数据。
学到这里,我们也可以看到,我们的查询条件越来越多,开始仅是简单查询,慢慢增加条件查询,增加排序,对返回结果进行限制。所以,我们可以说:对于elasticsearch来说,所有的条件都是可插拔的,彼此之间用,分割。比如说,我们在查询中,仅对返回结果进行限制:
GET lqz/doc/_search
{
"query": {
"match_all": {}
},
"from": 4,
"size": 2
}
上例中,在所有的返回结果中,结果从4开始返回2条数据。
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 1.0,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
但我们只有1条符合条件的数据。
6-Elasticsearch之布尔查询
一 前言
布尔查询是最常用的组合查询,根据子查询的规则,只有当文档满足所有子查询条件时,elasticsearch引擎才将结果返回。布尔查询支持的子查询条件共4中:
- must(and)
- should(or)
- must_not(not)
- filter
下面我们来看看每个子查询条件都是怎么玩的。
二 准备数据
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
PUT lqz/doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
PUT lqz/doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
三 must
现在,我们用布尔查询所有from属性为gu的数据:
GET lqz/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "gu"
}
}
]
}
}
}
上例中,我们通过在bool属性(字段)内使用must来作为查询条件,那么条件是什么呢?条件同样被match包围,就是from为gu的所有数据。
这里需要注意的是must字段对应的是个列表,也就是说可以有多个并列的查询条件,一个文档满足各个子条件后才最终返回。
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
上例中,可以看到,所有from属性为gu的数据查询出来了。
那么,我们想要查询from为gu,并且age为30的数据怎么搞呢?
GET lqz/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "gu"
}
},
{
"match": {
"age": 30
}
}
]
}
}
}
上例中,在must列表中,在增加一个age为30的条件。
结果如下:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.287682,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 1.287682,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
}
]
}
}
上例,符合条件的数据被成功查询出来了。
注意:现在你可能慢慢发现一个现象,所有属性值为列表的,都可以实现多个条件并列存在
四 should
那么,如果要查询只要是from为gu或者tags为闭月的数据怎么搞?
GET lqz/doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"from": "gu"
}
},
{
"match": {
"tags": "闭月"
}
}
]
}
}
}
上例中,或关系的不能用must的了,而是要用should,只要符合其中一个条件就返回。
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 4,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "5",
"_score" : 0.5753642,
"_source" : {
"name" : "魏行首",
"age" : 25,
"from" : "广云台",
"desc" : "仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags" : [
"闭月",
"羞花"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
返回了所有符合条件的结果。
五 must_not
那么,如果我想要查询from既不是gu并且tags也不是可爱,还有age不是18的数据怎么办?
GET lqz/doc/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"from": "gu"
}
},
{
"match": {
"tags": "可爱"
}
},
{
"match": {
"age": 18
}
}
]
}
}
}
上例中,must和should都不能使用,而是使用must_not,又在内增加了一个age为18的条件。
结果如下:
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "魏行首",
"age" : 25,
"from" : "广云台",
"desc" : "仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags" : [
"闭月",
"羞花"
]
}
}
]
}
}
上例中,只有魏行首这一条数据,因为只有魏行首既不是顾家的人,标签没有可爱那一项,年龄也不等于18!
这里有点需要补充,条件中age对应的18你写成整形还是字符串都没啥……
6 filter
那么,如果要查询from为gu,age大于25的数据怎么查?
GET lqz/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "gu"
}
}
],
"filter": {
"range": {
"age": {
"gt": 25
}
}
}
}
}
}
这里就用到了filter条件过滤查询,过滤条件的范围用range表示,gt表示大于,大于多少呢?是25。
结果如下:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
}
]
}
}
上例中,age大于25的条件都已经筛选出来了。
那么要查询from是gu,age大于等于30的数据呢?
GET lqz/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "gu"
}
}
],
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
}
}
上例中,大于等于用gte表示。
结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
}
]
}
}
那么,要查询age小于25的呢?
GET lqz/doc/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"lt": 25
}
}
}
}
}
}
上例中,小于用lt表示,结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.0,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "2",
"_score" : 0.0,
"_source" : {
"name" : "大娘子",
"age" : 18,
"from" : "sheng",
"desc" : "肤白貌美,娇憨可爱",
"tags" : [
"白",
"富",
"美"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 0.0,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
在查询一个age小于等于18的怎么办呢?
GET lqz/doc/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"lte": 18
}
}
}
}
}
}
上例中,小于等于用lte表示。结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.0,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "2",
"_score" : 0.0,
"_source" : {
"name" : "大娘子",
"age" : 18,
"from" : "sheng",
"desc" : "肤白貌美,娇憨可爱",
"tags" : [
"白",
"富",
"美"
]
}
}
]
}
}
要查询from是gu,age在25~30之间的怎么查?
GET lqz/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "gu"
}
}
],
"filter": {
"range": {
"age": {
"gte": 25,
"lte": 30
}
}
}
}
}
}
上例中,使用lte和gte来限定范围。结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30,
"from" : "gu",
"desc" : "皮肤黑、武器长、性格直",
"tags" : [
"黑",
"长",
"直"
]
}
}
]
}
}
那么,要查询from是sheng,age小于等于25的怎么查呢?其实结果,我们可能已经想到了,只有一条,因为只有盛家小六符合结果。
GET lqz/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "sheng"
}
}
],
"filter": {
"range": {
"age": {
"lte": 25
}
}
}
}
}
}
结果果然不出洒家所料!
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "2",
"_score" : 0.6931472,
"_source" : {
"name" : "大娘子",
"age" : 18,
"from" : "sheng",
"desc" : "肤白貌美,娇憨可爱",
"tags" : [
"白",
"富",
"美"
]
}
}
]
}
}
但是,洒家手一抖,将must换为should看看会发生什么?
GET lqz/doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"from": "sheng"
}
}
],
"filter": {
"range": {
"age": {
"lte": 25
}
}
}
}
}
}
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "2",
"_score" : 0.6931472,
"_source" : {
"name" : "大娘子",
"age" : 18,
"from" : "sheng",
"desc" : "肤白貌美,娇憨可爱",
"tags" : [
"白",
"富",
"美"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "5",
"_score" : 0.0,
"_source" : {
"name" : "魏行首",
"age" : 25,
"from" : "广云台",
"desc" : "仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags" : [
"闭月",
"羞花"
]
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 0.0,
"_source" : {
"name" : "龙套偏房",
"age" : 22,
"from" : "gu",
"desc" : "mmp,没怎么看,不知道怎么形容",
"tags" : [
"造数据",
"真",
"难"
]
}
}
]
}
}
结果有点出乎意料,因为龙套偏房和魏行首不属于盛家,但也被查询出来了。那你要问了,怎么肥四?小老弟!这是因为在查询过程中,优先经过filter过滤,因为should是或关系,龙套偏房和魏行首的年龄符合了filter过滤条件,也就被放行了!所以,如果在filter过滤条件中使用should的话,结果可能不会尽如人意!建议使用must代替。
注意:filter工作于bool查询内。比如我们将刚才的查询条件改一下,把filter从bool中挪出来。
GET lqz/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "sheng"
}
}
]
},
"filter": {
"range": {
"age": {
"lte": 25
}
}
}
}
}
如上例所示,我们将filter与bool平级,看查询结果:
{
"error": {
"root_cause": [
{
"type": "parsing_exception",
"reason": "[bool] malformed query, expected [END_OBJECT] but found [FIELD_NAME]",
"line": 12,
"col": 5
}
],
"type": "parsing_exception",
"reason": "[bool] malformed query, expected [END_OBJECT] but found [FIELD_NAME]",
"line": 12,
"col": 5
},
"status": 400
}
结果报错了!所以,filter工作位置很重要。
小结:
must:与关系,相当于关系型数据库中的and。should:或关系,相当于关系型数据库中的or。must_not:非关系,相当于关系型数据库中的not。filter:过滤条件。range:条件筛选范围。gt:大于,相当于关系型数据库中的>。gte:大于等于,相当于关系型数据库中的>=。lt:小于,相当于关系型数据库中的<。lte:小于等于,相当于关系型数据库中的<=。
7-Elasticsearch之查询结果过滤
一 前言
在未来,一篇文档可能有很多的字段,每次查询都默认给我们返回全部,在数据量很大的时候,是的,比如我只想查姑娘的手机号,你一并给我个喜好啊、三围什么的算什么?
所以,我们对结果做一些过滤,清清白白的告诉elasticsearch
二 准备数据
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
三 结果过滤:_source
现在,在所有的结果中,我只需要查看name和age两个属性,其他的不要怎么办?
GET lqz/doc/_search
{
"query": {
"match": {
"name": "顾老二"
}
},
"_source": ["name", "age"]
}
如上例所示,在查询中,通过_source来控制仅返回name和age属性。
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.8630463,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.8630463,
"_source" : {
"name" : "顾老二",
"age" : 30
}
}
]
}
}
在数据量很大的时候,我们需要什么字段,就返回什么字段就好了,提高查询效率
7-Elasticsearch之高亮查询
一 前言
如果返回的结果集中很多符合条件的结果,那怎么能一眼就能看到我们想要的那个结果呢?比如下面网站所示的那样,我们搜索elasticsearch,在结果集中,将所有elasticsearch高亮显示?
 如上图我们搜索百度一样。
如上图我们搜索百度一样。
我们该怎么做呢?
二 准备数据
PUT lqz/doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
三 默认高亮显示
我们来查询:
GET lqz/doc/_search
{
"query": {
"match": {
"name": "石头"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
上例中,我们使用highlight属性来实现结果高亮显示,需要的字段名称添加到fields内即可,elasticsearch会自动帮我们实现高亮。
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.5098256,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 1.5098256,
"_source" : {
"name" : "石头",
"age" : 29,
"from" : "gu",
"desc" : "粗中有细,狐假虎威",
"tags" : [
"粗",
"大",
"猛"
]
},
"highlight" : {
"name" : [
"石头"
]
}
}
]
}
}
上例中,elasticsearch会自动将检索结果用标签包裹起来,用于在页面中渲染。
四 自定义高亮显示
但是,你可能会问,我不想用em标签, 我这么牛逼,应该用个b标签啊!好的,elasticsearch同样考虑到你很牛逼,所以,我们可以自定义标签。
GET lqz/chengyuan/_search
{
"query": {
"match": {
"from": "gu"
}
},
"highlight": {
"pre_tags": "",
"post_tags": "",
"fields": {
"from": {}
}
}
}
上例中,在highlight中,pre_tags用来实现我们的自定义标签的前半部分,在这里,我们也可以为自定义的标签添加属性和样式。post_tags实现标签的后半部分,组成一个完整的标签。至于标签中的内容,则还是交给fields来完成。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "lqz",
"_type" : "chengyuan",
"_id" : "1",
"_score" : 0.5753642,
"_source" : {
"name" : "老二",
"age" : 30,
"sex" : "male",
"birth" : "1070-10-11",
"from" : "gu",
"desc" : "皮肤黑,武器长,性格直",
"tags" : [
"黑",
"长",
"直"
]
},
"highlight" : {
"name" : [
"老二"
]
}
}
]
}
}
需要注意的是:自定义标签中属性或样式中的逗号一律用英文状态的单引号表示,应该与外部elasticsearch语法的双引号区分开。
8-Elasticsearch之聚合函数
一 前言
聚合函数大家都不陌生,elasticsearch中也没玩出新花样,所以,这一章相对简单,只需要记得:
- avg
- max
- min
- sum
以及各自的用法即可。先来看求平均。
二 准备数据
PUT lqz/doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
PUT lqz/doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
PUT lqz/doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
三 avg
现在的需求是查询from是gu的人的平均年龄。
select max(age) as my_avg
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
},
"_source": ["name", "age"]
}
上例中,首先匹配查询from是gu的数据。在此基础上做查询平均值的操作,这里就用到了聚合函数,其语法被封装在aggs中,而my_avg则是为查询结果起个别名,封装了计算出的平均值。那么,要以什么属性作为条件呢?是age年龄,查年龄的什么呢?是avg,查平均年龄。
返回结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "4",
"_score" : 0.6931472,
"_source" : {
"name" : "石头",
"age" : 29
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "顾老二",
"age" : 30
}
},
{
"_index" : "lqz",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"name" : "龙套偏房",
"age" : 22
}
}
]
},
"aggregations" : {
"my_avg" : {
"value" : 27.0
}
}
}
上例中,在查询结果的最后是平均值信息,可以看到是27岁。
虽然我们已经使用_source对字段做了过滤,但是还不够。我不想看都有哪些数据,只想看平均值怎么办?别忘了size!
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
},
"size": 0,
"_source": ["name", "age"]
}
上例中,只需要在原来的查询基础上,增加一个size就可以了,输出几条结果,我们写上0,就是输出0条查询结果。
查询结果如下:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"my_avg" : {
"value" : 27.0
}
}
}
查询结果中,我们看hits下的total值是3,说明有三条符合结果的数据。最后面返回平均值是27。
四 max
那怎么查最大值呢?
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_max": {
"max": {
"field": "age"
}
}
},
"size": 0
}
上例中,只需要在查询条件中将avg替换成max即可。
返回结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"my_max" : {
"value" : 30.0
}
}
}
在返回的结果中,可以看到年龄最大的是30岁。
五 min
那怎么查最小值呢?
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_min": {
"min": {
"field": "age"
}
}
},
"size": 0
}
最小值则用min表示。
返回结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"my_min" : {
"value" : 22.0
}
}
}
返回结果中,年龄最小的是22岁。
六 sum
那么,要是想知道它们的年龄总和是多少怎么办呢?
GET lqz/doc/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_sum": {
"sum": {
"field": "age"
}
}
},
"size": 0
}
上例中,求和用sum表示。
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"my_sum" : {
"value" : 81.0
}
}
}
从返回的结果可以发现,年龄总和是81岁。
七 分组查询
现在我想要查询所有人的年龄段,并且按照15~20,20~25,25~30分组,并且算出每组的平均年龄。
分析需求,首先我们应该先把分组做出来。
GET lqz/doc/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"age_group": {
"range": {
"field": "age",
"ranges": [
{
"from": 15,
"to": 20
},
{
"from": 20,
"to": 25
},
{
"from": 25,
"to": 30
}
]
}
}
}
}
上例中,在aggs的自定义别名age_group中,使用range来做分组,field是以age为分组,分组使用ranges来做,from和to是范围,我们根据需求做出三组。
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"age_group" : {
"buckets" : [
{
"key" : "15.0-20.0",
"from" : 15.0,
"to" : 20.0,
"doc_count" : 1
},
{
"key" : "20.0-25.0",
"from" : 20.0,
"to" : 25.0,
"doc_count" : 1
},
{
"key" : "25.0-30.0",
"from" : 25.0,
"to" : 30.0,
"doc_count" : 2
}
]
}
}
}
返回的结果中可以看到,已经拿到了三个分组。doc_count为该组内有几条数据,此次共分为三组,查询出4条内容。还有一条数据的age属性值是30,不在分组的范围内!
那么接下来,我们就要对每个小组内的数据做平均年龄处理。
GET lqz/doc/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"age_group": {
"range": {
"field": "age",
"ranges": [
{
"from": 15,
"to": 20
},
{
"from": 20,
"to": 25
},
{
"from": 25,
"to": 30
}
]
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
}
}
}
}
上例中,在分组下面,我们使用aggs对age做平均数处理,这样就可以了。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"age_group" : {
"buckets" : [
{
"key" : "15.0-20.0",
"from" : 15.0,
"to" : 20.0,
"doc_count" : 1,
"my_avg" : {
"value" : 18.0
}
},
{
"key" : "20.0-25.0",
"from" : 20.0,
"to" : 25.0,
"doc_count" : 1,
"my_avg" : {
"value" : 22.0
}
},
{
"key" : "25.0-30.0",
"from" : 25.0,
"to" : 30.0,
"doc_count" : 2,
"my_avg" : {
"value" : 27.0
}
}
]
}
}
}
在结果中,我们可以清晰的看到每组的平均年龄(my_avg的value中)。
注意:聚合函数的使用,一定是先查出结果,然后对结果使用聚合函数做处理
小结:
- avg:求平均
- max:最大值
- min:最小值
- sum:求和
欢迎斧正,that’s all
9-Elasticsearch之mappings
一 前言
我们应该知道,在关系型数据库中,必须先定义表结构,才能插入数据,并且,表结构不会轻易改变。而我们呢,我们怎么玩elasticsearch的呢:
PUT t1/doc/1
{
"name": "小黑"
}
PUT t1/doc/2
{
"name": "小白",
"age": 18
}
文档的字段可以是任意的,原本都是name字段,突然来个age。还要elasticsearch自动去猜,哦,可能是个long类型,然后加个映射!之后发什么什么?肯定是:猜猜猜,猜你妹!
难道你不想知道elasticsearch内部是怎么玩的吗?
当我们执行上述第一条PUT命令后,elasticsearch到底是怎么做的:
GET t1
结果:
{
"t1" : {
"aliases" : { },
"mappings" : {
"doc" : {
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1553334893136",
"number_of_shards" : "5",
"number_of_replicas" : "1",
"uuid" : "lHfujZBbRA2K7QDdsX4_wA",
"version" : {
"created" : "6050499"
},
"provided_name" : "t1"
}
}
}
}
由返回结果可以看到,分为两大部分,第一部分关于t1索引类型相关的,包括该索引是否有别名aliases,然后就是mappings信息,包括索引类型doc,各字段的详细映射关系都收集在properties中。
另一部分是关于索引t1的settings设置。包括该索引的创建时间,主副分片的信息,UUID等等。
我们再执行第二条PUT命令,再查看该索引是否有什么变化,返回结果如下:
{
"t1" : {
"aliases" : { },
"mappings" : {
"doc" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1553334893136",
"number_of_shards" : "5",
"number_of_replicas" : "1",
"uuid" : "lHfujZBbRA2K7QDdsX4_wA",
"version" : {
"created" : "6050499"
},
"provided_name" : "t1"
}
}
}
}
由返回结果可以看到,settings没有变化,只是mappings中多了一条关于age的映射关系,这一切都是elasticsearch自动的,但特定的场景下,需要我们更多的设置。
所以,接下来,我们研究一下mappings到底是怎么回事!
二 映射是什么?
其实,映射mappings没那么神秘!说白了,就相当于原来由elasticsearch自动帮我们定义表结构。现在,我们要自己来了,旨在创建索引的时候,有更多定制的内容,更加的贴合业务场景。OK,坐好了,开车!
elasticsearch中的映射用来定义一个文档及其包含的字段如何存储和索引的过程。例如,我们可以使用映射来定义:
- 哪些字符串应该被视为全文字段。
- 哪些字段包含数字、日期或者地理位置。
- 定义日期的格式。
- 自定义的规则,用来控制动态添加字段的的映射。
三 映射类型
每个索引都有一个映射类型(这话必须放在elasticsearch6.x版本后才能说,之前版本一个索引下有多个类型),它决定了文档将如何被索引。
映射类型有:
- 元字段(meta-fields):元字段用于自定义如何处理文档关联的元数据,例如包括文档的
_index、_type、_id和_source字段。 - 字段或属性(field or properties):映射类型包含与文档相关的字段或者属性的列表。
继续往下走!
四 字段的数据类型
- 简单类型,如文本(
text)、关键字(keyword)、日期(date)、整形(long)、双精度(double)、布尔(boolean)或ip。 - 可以是支持
JSON的层次结构性质的类型,如对象或嵌套。 - 或者一种特殊类型,如
geo_point、geo_shape或completion。
为了不同的目的,以不同的方式索引相同的字段通常是有用的。例如,字符串字段可以作为全文搜索的文本字段进行索引,也可以作为排序或聚合的关键字字段进行索引。或者,可以使用标准分析器、英语分析器和法语分析器索引字符串字段。
这就是多字段的目的。大多数数据类型通过fields参数支持多字段。
五 映射约束
在索引中定义太多的字段有可能导致映射爆炸!因为这可能会导致内存不足以及难以恢复的情况,为此。我们可以手动或动态的创建字段映射的数量:
- index.mapping.total_fields.limit:索引中的最大字段数。字段和对象映射以及字段别名都计入此限制。默认值为1000。
- index.mapping.depth.limit:字段的最大深度,以内部对象的数量来衡量。例如,如果所有字段都在根对象级别定义,则深度为1.如果有一个子对象映射,则深度为2,等等。默认值为20。
- index.mapping.nested_fields.limit:索引中嵌套字段的最大数量,默认为50.索引1个包含100个嵌套字段的文档实际上索引101个文档,因为每个嵌套文档都被索引为单独的隐藏文档。
六 一个简单的映射示例
PUT mapping_test1
{
"mappings": {
"test1":{
"properties":{
"name":{"type": "text"},
"age":{"type":"long"}
}
}
}
}
上例中,我们在创建索引PUT mapping_test1的过程中,为该索引定制化类型(设计表结构),添加一个映射类型test1;指定字段或者属性都在properties内完成。
GET mapping_test1
通过GET来查看。
{
"mapping_test1" : {
"aliases" : { },
"mappings" : {
"test1" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text"
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1550469220778",
"number_of_shards" : "5",
"number_of_replicas" : "1",
"uuid" : "7I_m_ULRRXGzWcvhIZoxnQ",
"version" : {
"created" : "6050499"
},
"provided_name" : "mapping_test1"
}
}
}
}
返回的结果中你肯定很熟悉!映射类型是test1,具体的属性都被封装在properties中。而关于settings的配置,我们暂时不管它。
我们为这个索引添加一些数据:
put mapping_test1/test1/1
{
"name":"张开嘴",
"age":16
}
上例中,mapping_test1是之前创建的索引,test1为之前自定义的mappings类型。字段是之前创建好的name和age。
GET mapping_test1/test1/_search
{
"query": {
"match": {
"age": 16
}
}
}
上例中,我们通过age条件查询。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "mapping_test1",
"_type" : "test1",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "张开嘴",
"age" : 16
}
}
]
}
}
返回了预期的结果信息。
10-Elasticsearch mappings之dynamic的三种状态
一 前言
一般的,mapping则又可以分为动态映射(dynamic mapping)和静态(显式)映射(explicit mapping)和精确(严格)映射(strict mappings),具体由dynamic属性控制。
二 动态映射(dynamic:true)
现在有这样的一个索引:
PUT m1
{
"mappings": {
"doc":{
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
}
}
}
}
}
通过GET m1/_mapping看一下mappings信息:
{
"m1" : {
"mappings" : {
"doc" : {
"dynamic" : "true",
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text"
}
}
}
}
}
}
添加一些数据,并且新增一个sex字段:
PUT m1/doc/1
{
"name": "小黑",
"age": 18,
"sex": "不详"
}
当然,新的字段查询也没问题:
GET m1/doc/_search
{
"query": {
"match": {
"sex": "不详"
}
}
}
返回结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "m1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.5753642,
"_source" : {
"name" : "小黑",
"age" : 18,
"sex" : "不详"
}
}
]
}
}
现在,一切都很正常,跟elasticsearch自动创建时一样。那是因为,当 Elasticsearch 遇到文档中以前未遇到的字段,它用动态映射来确定字段的数据类型并自动把新的字段添加到类型映射。我们再来看mappings你就明白了:
{
"m1" : {
"mappings" : {
"doc" : {
"dynamic" : "true",
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text"
},
"sex" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}
通过上例可以发下,elasticsearch帮我们新增了一个sex的映射。所以。这一切看起来如此自然。这一切的功劳都要归功于dynamic属性。我们知道在关系型数据库中,字段创建后除非手动修改,则永远不会更改。但是,elasticsearch默认是允许添加新的字段的,也就是dynamic:true。
其实创建索引的时候,是这样的:
PUT m1
{
"mappings": {
"doc":{
"dynamic":true,
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
}
}
}
}
}
上例中,当dynamic设置为true的时候,elasticsearch就会帮我们动态的添加映射属性。也就是等于啥都没做!
这里有一点需要注意的是:mappings一旦创建,则无法修改。因为Lucene生成倒排索引后就不能改了。
三 静态映射(dynamic:false)
现在,我们将dynamic值设置为false:
PUT m2
{
"mappings": {
"doc":{
"dynamic":false,
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
}
}
}
}
}
现在再来测试一下false和true有什么区别:
PUT m2/doc/1
{
"name": "小黑",
"age":18
}
PUT m2/doc/2
{
"name": "小白",
"age": 16,
"sex": "不详"
}
第二条数据相对于第一条数据来说,多了一个sex属性,我们以sex为条件来查询一下:
GET m2/doc/_search
{
"query": {
"match": {
"sex": "不详"
}
}
}
结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : null,
"hits" : [ ]
}
}
结果是空的,也就是什么都没查询到,那是为什呢?来GET m2/_mapping一下此时m2的mappings信息:
``{ “m2” : { “mappings” : { “doc” : { “dynamic” : “false”, “properties” : { “age” : { “type” : “long” }, “name” : { “type” : “text” } } } } } } 可以看到elasticsearch并没有为新增的sex建立映射关系。所以查询不到。 当elasticsearch察觉到有新增字段时,因为dynamic:false的关系,会忽略该字段,但是仍会存储该字段。 在有些情况下,dynamic:false`依然不够,所以还需要更严谨的策略来进一步做限制。
四 严格模式(dynamic:strict)
让我们再创建一个mappings,并且将dynamic的状态改为strict:
PUT m3
{
"mappings": {
"doc": {
"dynamic": "strict",
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
}
}
}
}
}
现在,添加两篇文档:
PUT m3/doc/1
{
"name": "小黑",
"age": 18
}
PUT m3/doc/2
{
"name": "小白",
"age": 18,
"sex": "不详"
}
第一篇文档添加和查询都没问题。但是,当添加第二篇文档的时候,你会发现报错了:
{
"error": {
"root_cause": [
{
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [sex] within [doc] is not allowed"
}
],
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [sex] within [doc] is not allowed"
},
"status": 400
}
错误提示,严格动态映射异常!说人话就是,当dynamic:strict的时候,elasticsearch如果遇到新字段,会抛出异常。
上述这种严谨的作风洒家称为——严格模式!
小结:
- 动态映射(dynamic:true):动态添加新的字段(或缺省)。
- 静态映射(dynamic:false):忽略新的字段。在原有的映射基础上,当有新的字段时,不会主动的添加新的映射关系,只作为查询结果出现在查询中。
- 严格模式(dynamic: strict):如果遇到新的字段,就抛出异常。
一般静态映射用的较多。就像HTML的img标签一样,src为自带的属性,你可以在需要的时候添加id或者class属性。
当然,如果你非常非常了解你的数据,并且未来很长一段时间不会改变,strict不失为一个好选择。
一 前言
上一小节中,根据dynamic的状态不同,我们对字段有了更多可自定义的操作。现在再来补充一个参数,使自定义的属性更加的灵活。
二 index
首先来创建一个mappings:
PUT m4
{
"mappings": {
"doc": {
"dynamic": false,
"properties": {
"name": {
"type": "text",
"index": true
},
"age": {
"type": "long",
"index": false
}
}
}
}
}
可以看到,我们在创建索引的时候,为每个属性添加一个index参数。那会有什么效果呢?
先来添加一篇文档:
PUT m4/doc/1
{
"name": "小黑",
"age": 18
}
再来查询看效果:
GET m4/doc/_search
{
"query": {
"match": {
"name": "小黑"
}
}
}
GET m4/doc/_search
{
"query": {
"match": {
"age": 18
}
}
}
以name查询没问题,但是,以age作为查询条件就有问题了:
{
"error": {
"root_cause": [
{
"type": "query_shard_exception",
"reason": "failed to create query: {\n \"match\" : {\n \"age\" : {\n \"query\" : 18,\n \"operator\" : \"OR\",\n \"prefix_length\" : 0,\n \"max_expansions\" : 50,\n \"fuzzy_transpositions\" : true,\n \"lenient\" : false,\n \"zero_terms_query\" : \"NONE\",\n \"auto_generate_synonyms_phrase_query\" : true,\n \"boost\" : 1.0\n }\n }\n}",
"index_uuid": "GHBPeT5pRnSi3g6DkpIkow",
"index": "m4"
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "m4",
"node": "dhkqLLTsRemm7qEgRdpvTg",
"reason": {
"type": "query_shard_exception",
"reason": "failed to create query: {\n \"match\" : {\n \"age\" : {\n \"query\" : 18,\n \"operator\" : \"OR\",\n \"prefix_length\" : 0,\n \"max_expansions\" : 50,\n \"fuzzy_transpositions\" : true,\n \"lenient\" : false,\n \"zero_terms_query\" : \"NONE\",\n \"auto_generate_synonyms_phrase_query\" : true,\n \"boost\" : 1.0\n }\n }\n}",
"index_uuid": "GHBPeT5pRnSi3g6DkpIkow",
"index": "m4",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Cannot search on field [age] since it is not indexed."
}
}
}
]
},
"status": 400
}
返回的是报错结果,这其中就是index参数在起作用。
小结:index属性默认为true,如果该属性设置为false,那么,elasticsearch不会为该属性创建索引,也就是说无法当做主查询条件。
三 copy_to
现在,再来学习一个copy_to属性,该属性允许我们将多个字段的值复制到组字段中,然后将组字段作为单个字段进行查询。
PUT m5
{
"mappings": {
"doc": {
"dynamic":false,
"properties": {
"first_name":{
"type": "text",
"copy_to": "full_name"
},
"last_name": {
"type": "text",
"copy_to": "full_name"
},
"full_name": {
"type": "text"
}
}
}
}
}
PUT m5/doc/1
{
"first_name":"tom",
"last_name":"ben"
}
PUT m5/doc/2
{
"first_name":"john",
"last_name":"smith"
}
GET m5/doc/_search
{
"query": {
"match": {
"first_name": "tom"
}
}
}
GET m5/doc/_search
{
"query": {
"match": {
"full_name": "tom"
}
}
}
上例中,我们将first_name和last_name都复制到full_name中。并且使用full_name查询也返回了结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "m5",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"first_name" : "tom",
"last_name" : "ben"
}
}
]
}
}
返回结果表示查询成功。那么想要查询tom或者smith该怎么办?
GET m5/doc/_search
{
"query": {
"match": {
"full_name": {
"query": "tom smith",
"operator": "or"
}
}
}
}
将查询条件以空格隔开并封装在query内,operator参数为多个条件的查询关系也可以是and,也有简写方式:
GET m5/doc/_search
{
"query": {
"match": {
"full_name": "tom smith"
}
}
}
copy_to还支持将相同的属性值复制给不同的字段。
PUT m6
{
"mappings": {
"doc": {
"dynamic":false,
"properties": {
"first_name":{
"type": "text",
"copy_to": "full_name"
},
"last_name": {
"type": "text",
"copy_to": ["field1", "field2"]
},
"field1": {
"type": "text"
},
"field2": {
"type": "text"
}
}
}
}
}
PUT m6/doc/1
{
"first_name":"tom",
"last_name":"ben"
}
PUT m6/doc/2
{
"first_name":"john",
"last_name":"smith"
}
上例中,只需要将copy_to的字段以数组的形式封装即可。无论是通过field1还是field2都可以查询。
小结:
copy_to复制的是属性值而不是属性copy_to如果要应用于聚合请将filddata设置为true- 如果要将属性值复制给多个字段,请用数组,比如
copy_to:["field1", "field2"]
四 对象属性
现在,有一个个人信息文档如下:
PUT m7/doc/1
{
"name":"tom",
"age":18,
"info":{
"addr":"北京",
"tel":"10010"
}
}
首先,这样嵌套多层的mappings该如何设计呢?
PUT m7
{
"mappings": {
"doc": {
"dynamic": false,
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "text"
},
"info": {
"properties": {
"addr": {
"type": "text"
},
"tel": {
"type" : "text"
}
}
}
}
}
}
}
那么,如果要以name或者age属性作为查询条件查询难不倒我们。
现在如果要以info中的tel为条件怎么写查询语句呢?
GET mapping_test9/doc/_search
{
"query": {
"match": {
"info.tel": "10086"
}
}
}
上例中,info既是一个属性,也是一个对象,我们称为info这类字段为对象型字段。该对象内又包含addr和tel两个字段,如上例这种以嵌套内的字段为查询条件的话,查询语句可以以字段点子字段的方式来写即可。
五 settings设置
5.1 设置主、复制分片
在创建一个索引的时候,我们可以在settings中指定分片信息:
PUT s1
{
"mappings": {
"doc": {
"properties": {
"name": {
"type": "text"
}
}
}
},
"settings": {
"number_of_replicas": 1,
"number_of_shards": 5
}
}
number_of_shards是主分片数量(每个索引默认5个主分片),而number_of_replicas是复制分片,默认一个主分片搭配一个复制分片。
12-Elasticsearch之mappings parameters
一 ignore_above
长度超过ignore_above设置的字符串将不会被索引或存储(个人认为会存储,但不会为该字段建立索引,也就是该字段不能被检索)。 对于字符串数组,ignore_above将分别应用于每个数组元素,并且不会索引或存储比ignore_above更长的字符串元素。
PUT w1
{
"mappings": {
"doc":{
"properties":{
"t1":{
"type":"keyword",
"ignore_above": 5
},
"t2":{
"type":"keyword",
"ignore_above": 10 ①
}
}
}
}
}
PUT w1/doc/1
{
"t1":"elk", ②
"t2":"elasticsearch" ③
}
GET w1/doc/_search ④
{
"query":{
"term": {
"t1": "elk"
}
}
}
GET w1/doc/_search ⑤
{
"query": {
"term": {
"t2": "elasticsearch"
}
}
}
①,该字段将忽略任何超过10个字符的字符串。
②,此文档已成功建立索引,也就是说能被查询,并且有结果返回。
③,该字段将不会建立索引,也就是说,以该字段作为查询条件,将不会有结果返回。
④,有结果返回。
⑤,则将不会有结果返回,因为t2字段对应的值长度超过了ignove_above设置的值。
该参数对于防止Lucene的术语字节长度限制也很有用,限制长度是32766。
注意,该ignore_above设置可以利用现有的领域进行更新PUT地图API。
对于值ignore_above是字符数,但Lucene的字节数为单位。如果您使用带有许多非ASCII字符的UTF-8文本,您可能需要设置限制,32766 / 4 = 8191因为UTF-8字符最多可占用4个字节。
如果我们观察上述示例中,我们可以看到在设置映射类型时,字段的类型是keyword,也就是说ignore_above参数仅针对于keyword类型有用。
那么如果字符串的类型是text时能用ignore_above吗,答案是能,但要特殊设置:
PUT w2
{
"mappings": {
"doc":{
"properties":{
"t1":{
"type":"keyword",
"ignore_above":5
},
"t2":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above": 10
}
}
}
}
}
}
}
PUT w2/doc/1
{
"t1":"beautiful",
"t2":"beautiful girl"
}
GET w2/doc/_search ①
{
"query": {
"term": {
"t1": {
"value": "beautiful"
}
}
}
}
GET w2/doc/_search ②
{
"query": {
"term": {
"t2": "beautiful"
}
}
}
①,不会有返回结果。
②,有返回结果,因为该字段的类型是text。
但是,当字段类型设置为text之后,ignore_above参数的限制就失效了。
13-Elasticsearch - 分析过程
一 前言
现在,我们已经了解了如何建立索引和搜索数据了。
那么,是时候来探索背后的故事了!当数据传递到elasticsearch后,到底发生了什么?
二分析过程
当数据被发送到elasticsearch后并加入到倒排索引之前,elasticsearch会对该文档的进行一系列的处理步骤:
- 字符过滤:使用字符过滤器转变字符。
- 文本切分为分词:将文本(档)分为单个或多个分词。
- 分词过滤:使用分词过滤器转变每个分词。
- 分词索引:最终将分词存储在Lucene倒排索引中。
整体流程如下图所示:
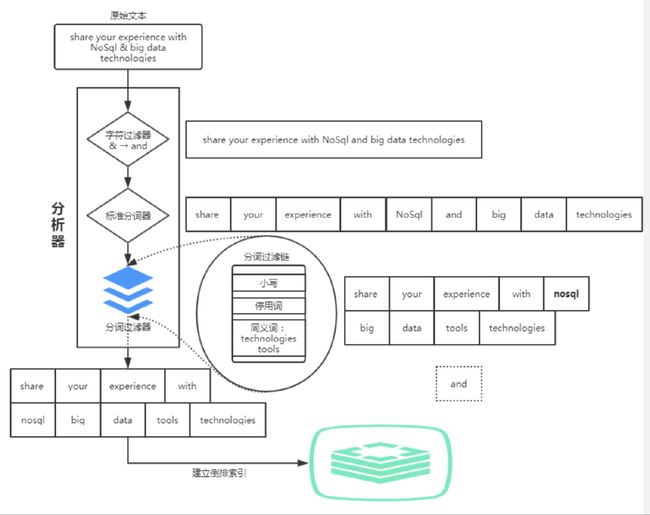
接下来,我们简要的介绍elasticsearch中的分析器、分词器和分词过滤器。它们配置简单,灵活好用,我们可以通过不同的组合来获取我们想要的分词!
是的,无论多么复杂的分析过程,都是为了获取更加人性化的分词!
接下来,我们来看看其中,在整个分析过程的各个组件吧。
三分析器
在elasticsearch中,一个分析器可以包括:
- 可选的字符过滤器
- 一个分词器
- 0个或多个分词过滤器
接下来简要的介绍各内置分词的大致情况。在介绍之前,为了方便演示。如果你已经按照之前的教程安装了ik analysis,现在请暂时将该插件移出plugins目录。
3.1 标准分析器:standard analyzer
标准分析器(standard analyzer):是elasticsearch的默认分析器,该分析器综合了大多数欧洲语言来说合理的默认模块,包括标准分词器、标准分词过滤器、小写转换分词过滤器和停用词分词过滤器。
POST _analyze
{
"analyzer": "standard",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
分词结果如下:
{
"tokens" : [
{
"token" : "to",
"start_offset" : 0,
"end_offset" : 2,
"type" : "",
"position" : 0
},
{
"token" : "be",
"start_offset" : 3,
"end_offset" : 5,
"type" : "",
"position" : 1
},
{
"token" : "or",
"start_offset" : 6,
"end_offset" : 8,
"type" : "",
"position" : 2
},
{
"token" : "not",
"start_offset" : 9,
"end_offset" : 12,
"type" : "",
"position" : 3
},
{
"token" : "to",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 4
},
{
"token" : "be",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 5
},
{
"token" : "that",
"start_offset" : 21,
"end_offset" : 25,
"type" : "",
"position" : 6
},
{
"token" : "is",
"start_offset" : 26,
"end_offset" : 28,
"type" : "",
"position" : 7
},
{
"token" : "a",
"start_offset" : 29,
"end_offset" : 30,
"type" : "",
"position" : 8
},
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "",
"position" : 9
},
{
"token" : "莎",
"start_offset" : 45,
"end_offset" : 46,
"type" : "",
"position" : 10
},
{
"token" : "士",
"start_offset" : 46,
"end_offset" : 47,
"type" : "",
"position" : 11
},
{
"token" : "比",
"start_offset" : 47,
"end_offset" : 48,
"type" : "",
"position" : 12
},
{
"token" : "亚",
"start_offset" : 48,
"end_offset" : 49,
"type" : "",
"position" : 13
}
]
}
3.2 简单分析器:simple analyzer
简单分析器(simple analyzer):简单分析器仅使用了小写转换分词,这意味着在非字母处进行分词,并将分词自动转换为小写。这个分词器对于亚种语言来说效果不佳,因为亚洲语言不是根据空白来分词的,所以一般用于欧洲言中。
POST _analyze
{
"analyzer": "simple",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
分词结果如下:
{
"tokens" : [
{
"token" : "to",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "be",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "or",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "not",
"start_offset" : 9,
"end_offset" : 12,
"type" : "word",
"position" : 3
},
{
"token" : "to",
"start_offset" : 13,
"end_offset" : 15,
"type" : "word",
"position" : 4
},
{
"token" : "be",
"start_offset" : 16,
"end_offset" : 18,
"type" : "word",
"position" : 5
},
{
"token" : "that",
"start_offset" : 21,
"end_offset" : 25,
"type" : "word",
"position" : 6
},
{
"token" : "is",
"start_offset" : 26,
"end_offset" : 28,
"type" : "word",
"position" : 7
},
{
"token" : "a",
"start_offset" : 29,
"end_offset" : 30,
"type" : "word",
"position" : 8
},
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "word",
"position" : 9
},
{
"token" : "莎士比亚",
"start_offset" : 45,
"end_offset" : 49,
"type" : "word",
"position" : 10
}
]
}
3.3 空白分析器:whitespace analyzer
空白(格)分析器(whitespace analyzer):这玩意儿只是根据空白将文本切分为若干分词,真是有够偷懒!
POST _analyze
{
"analyzer": "whitespace",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
分词结果如下:
{
"tokens" : [
{
"token" : "To",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "be",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "or",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "not",
"start_offset" : 9,
"end_offset" : 12,
"type" : "word",
"position" : 3
},
{
"token" : "to",
"start_offset" : 13,
"end_offset" : 15,
"type" : "word",
"position" : 4
},
{
"token" : "be,",
"start_offset" : 16,
"end_offset" : 19,
"type" : "word",
"position" : 5
},
{
"token" : "That",
"start_offset" : 21,
"end_offset" : 25,
"type" : "word",
"position" : 6
},
{
"token" : "is",
"start_offset" : 26,
"end_offset" : 28,
"type" : "word",
"position" : 7
},
{
"token" : "a",
"start_offset" : 29,
"end_offset" : 30,
"type" : "word",
"position" : 8
},
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "word",
"position" : 9
},
{
"token" : "————",
"start_offset" : 40,
"end_offset" : 44,
"type" : "word",
"position" : 10
},
{
"token" : "莎士比亚",
"start_offset" : 45,
"end_offset" : 49,
"type" : "word",
"position" : 11
}
]
}
3.4 停用词分析器:stop analyzer
停用词分析(stop analyzer)和简单分析器的行为很像,只是在分词流中额外的过滤了停用词。
POST _analyze
{
"analyzer": "stop",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果也很简单:
{
"tokens" : [
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "word",
"position" : 9
},
{
"token" : "莎士比亚",
"start_offset" : 45,
"end_offset" : 49,
"type" : "word",
"position" : 10
}
]
}
3.5 关键词分析器:keyword analyzer
关键词分析器(keyword analyzer)将整个字段当做单独的分词,如无必要,我们不在映射中使用关键词分析器。
POST _analyze
{
"analyzer": "keyword",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "To be or not to be, That is a question ———— 莎士比亚",
"start_offset" : 0,
"end_offset" : 49,
"type" : "word",
"position" : 0
}
]
}
说的一点没错,分析结果是将整段当做单独的分词。
3.6 模式分析器:pattern analyzer
模式分析器(pattern analyzer)允许我们指定一个分词切分模式。但是通常更佳的方案是使用定制的分析器,组合现有的模式分词器和所需要的分词过滤器更加合适。
POST _analyze
{
"analyzer": "pattern",
"explain": false,
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "to",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "be",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "or",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "not",
"start_offset" : 9,
"end_offset" : 12,
"type" : "word",
"position" : 3
},
{
"token" : "to",
"start_offset" : 13,
"end_offset" : 15,
"type" : "word",
"position" : 4
},
{
"token" : "be",
"start_offset" : 16,
"end_offset" : 18,
"type" : "word",
"position" : 5
},
{
"token" : "that",
"start_offset" : 21,
"end_offset" : 25,
"type" : "word",
"position" : 6
},
{
"token" : "is",
"start_offset" : 26,
"end_offset" : 28,
"type" : "word",
"position" : 7
},
{
"token" : "a",
"start_offset" : 29,
"end_offset" : 30,
"type" : "word",
"position" : 8
},
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "word",
"position" : 9
}
]
}
我们来自定制一个模式分析器,比如我们写匹配邮箱的正则。
PUT pattern_test
{
"settings": {
"analysis": {
"analyzer": {
"my_email_analyzer":{
"type":"pattern",
"pattern":"\\W|_",
"lowercase":true
}
}
}
}
}
上例中,我们在创建一条索引的时候,配置分析器为自定义的分析器。
需要注意的是,在json字符串中,正则的斜杠需要转义。
我们使用自定义的分析器来查询。
POST pattern_test/_analyze
{
"analyzer": "my_email_analyzer",
"text": "[email protected]"
}
结果如下:
{
"tokens" : [
{
"token" : "john",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 0
},
{
"token" : "smith",
"start_offset" : 5,
"end_offset" : 10,
"type" : "word",
"position" : 1
},
{
"token" : "foo",
"start_offset" : 11,
"end_offset" : 14,
"type" : "word",
"position" : 2
},
{
"token" : "bar",
"start_offset" : 15,
"end_offset" : 18,
"type" : "word",
"position" : 3
},
{
"token" : "com",
"start_offset" : 19,
"end_offset" : 22,
"type" : "word",
"position" : 4
}
]
}
3.7 语言和多语言分析器:chinese
elasticsearch为很多世界流行语言提供良好的、简单的、开箱即用的语言分析器集合:阿拉伯语、亚美尼亚语、巴斯克语、巴西语、保加利亚语、加泰罗尼亚语、中文、捷克语、丹麦、荷兰语、英语、芬兰语、法语、加里西亚语、德语、希腊语、北印度语、匈牙利语、印度尼西亚、爱尔兰语、意大利语、日语、韩国语、库尔德语、挪威语、波斯语、葡萄牙语、罗马尼亚语、俄语、西班牙语、瑞典语、土耳其语和泰语。
我们可以指定其中之一的语言来指定特定的语言分析器,但必须是小写的名字!如果你要分析的语言不在上述集合中,可能还需要搭配相应的插件支持。
POST _analyze
{
"analyzer": "chinese",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "",
"position" : 9
},
{
"token" : "莎",
"start_offset" : 45,
"end_offset" : 46,
"type" : "",
"position" : 10
},
{
"token" : "士",
"start_offset" : 46,
"end_offset" : 47,
"type" : "",
"position" : 11
},
{
"token" : "比",
"start_offset" : 47,
"end_offset" : 48,
"type" : "",
"position" : 12
},
{
"token" : "亚",
"start_offset" : 48,
"end_offset" : 49,
"type" : "",
"position" : 13
}
]
}
也可以是别语言:
POST _analyze
{
"analyzer": "french",
"text":"Je suis ton père"
}
POST _analyze
{
"analyzer": "german",
"text":"Ich bin dein vater"
}
3.8 雪球分析器:snowball analyzer
雪球分析器(snowball analyzer)除了使用标准的分词和分词过滤器(和标准分析器一样)也是用了小写分词过滤器和停用词过滤器,除此之外,它还是用了雪球词干器对文本进行词干提取。
POST _analyze
{
"analyzer": "snowball",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "",
"position" : 9
},
{
"token" : "莎",
"start_offset" : 45,
"end_offset" : 46,
"type" : "",
"position" : 10
},
{
"token" : "士",
"start_offset" : 46,
"end_offset" : 47,
"type" : "",
"position" : 11
},
{
"token" : "比",
"start_offset" : 47,
"end_offset" : 48,
"type" : "",
"position" : 12
},
{
"token" : "亚",
"start_offset" : 48,
"end_offset" : 49,
"type" : "",
"position" : 13
}
]
}
四 字符过滤器
字符过滤器在``属性中定义,它是对字符流进行处理。字符过滤器种类不多。elasticearch只提供了三种字符过滤器:
- HTML字符过滤器(HTML Strip Char Filter)
- 映射字符过滤器(Mapping Char Filter)
- 模式替换过滤器(Pattern Replace Char Filter)
我们来分别看看都是怎么玩的吧!
4.1 HTML字符过滤器
HTML字符过滤器(HTML Strip Char Filter)从文本中去除HTML元素。
POST _analyze
{
"tokenizer": "keyword",
"char_filter": ["html_strip"],
"text":"I'm so happy!
"
}
结果如下:
{
"tokens" : [
{
"token" : """
I'm so happy!
""",
"start_offset" : 0,
"end_offset" : 32,
"type" : "word",
"position" : 0
}
]
}
4.2 映射字符过滤器
映射字符过滤器(Mapping Char Filter)接收键值的映射,每当遇到与键相同的字符串时,它就用该键关联的值替换它们。
PUT pattern_test4
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer":"keyword",
"char_filter":["my_char_filter"]
}
},
"char_filter":{
"my_char_filter":{
"type":"mapping",
"mappings":["苍井空 => 666","武藤兰 => 888"]
}
}
}
}
}
上例中,我们自定义了一个分析器,其内的分词器使用关键字分词器,字符过滤器则是自定制的,将字符中的苍井空替换为666,武藤兰替换为888。
POST pattern_test4/_analyze
{
"analyzer": "my_analyzer",
"text": "苍井空热爱武藤兰,可惜后来苍井空结婚了"
}
结果如下:
{
"tokens" : [
{
"token" : "666热爱888,可惜后来666结婚了",
"start_offset" : 0,
"end_offset" : 19,
"type" : "word",
"position" : 0
}
]
}
4.3 模式替换过滤器
模式替换过滤器(Pattern Replace Char Filter)使用正则表达式匹配并替换字符串中的字符。但要小心你写的抠脚的正则表达式。因为这可能导致性能变慢!
PUT pattern_test5
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}
}
}
}
上例中,我们自定义了一个正则规则。
POST pattern_test5/_analyze
{
"analyzer": "my_analyzer",
"text": "My credit card is 123-456-789"
}
结果如下:
{
"tokens" : [
{
"token" : "My",
"start_offset" : 0,
"end_offset" : 2,
"type" : "",
"position" : 0
},
{
"token" : "credit",
"start_offset" : 3,
"end_offset" : 9,
"type" : "",
"position" : 1
},
{
"token" : "card",
"start_offset" : 10,
"end_offset" : 14,
"type" : "",
"position" : 2
},
{
"token" : "is",
"start_offset" : 15,
"end_offset" : 17,
"type" : "",
"position" : 3
},
{
"token" : "123_456_789",
"start_offset" : 18,
"end_offset" : 29,
"type" : "",
"position" : 4
}
]
}
我们大致的了解elasticsearch分析处理数据的流程。但可以看到的是,我们极少地在例子中演示中文处理。因为elasticsearch内置的分析器处理起来中文不是很好。所以,后续会介绍一个重量级的插件就是elasticsearch analysis ik(一般习惯称呼为ik分词器)。
五 分词器
由于elasticsearch内置了分析器,它同样也包含了分词器。分词器,顾名思义,主要的操作是将文本字符串分解为小块,而这些小块这被称为分词token。
5.1 标准分词器:standard tokenizer
标准分词器(standard tokenizer)是一个基于语法的分词器,对于大多数欧洲语言来说还是不错的,它同时还处理了Unicode文本的分词,但分词默认的最大长度是255字节,它也移除了逗号和句号这样的标点符号。
POST _analyze
{
"tokenizer": "standard",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "To",
"start_offset" : 0,
"end_offset" : 2,
"type" : "",
"position" : 0
},
{
"token" : "be",
"start_offset" : 3,
"end_offset" : 5,
"type" : "",
"position" : 1
},
{
"token" : "or",
"start_offset" : 6,
"end_offset" : 8,
"type" : "",
"position" : 2
},
{
"token" : "not",
"start_offset" : 9,
"end_offset" : 12,
"type" : "",
"position" : 3
},
{
"token" : "to",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 4
},
{
"token" : "be",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 5
},
{
"token" : "That",
"start_offset" : 21,
"end_offset" : 25,
"type" : "",
"position" : 6
},
{
"token" : "is",
"start_offset" : 26,
"end_offset" : 28,
"type" : "",
"position" : 7
},
{
"token" : "a",
"start_offset" : 29,
"end_offset" : 30,
"type" : "",
"position" : 8
},
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "",
"position" : 9
},
{
"token" : "莎",
"start_offset" : 45,
"end_offset" : 46,
"type" : "",
"position" : 10
},
{
"token" : "士",
"start_offset" : 46,
"end_offset" : 47,
"type" : "",
"position" : 11
},
{
"token" : "比",
"start_offset" : 47,
"end_offset" : 48,
"type" : "",
"position" : 12
},
{
"token" : "亚",
"start_offset" : 48,
"end_offset" : 49,
"type" : "",
"position" : 13
}
]
}
5.2 关键词分词器:keyword tokenizer
关键词分词器(keyword tokenizer)是一种简单的分词器,将整个文本作为单个的分词,提供给分词过滤器,当你只想用分词过滤器,而不做分词操作时,它是不错的选择。
POST _analyze
{
"tokenizer": "keyword",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "To be or not to be, That is a question ———— 莎士比亚",
"start_offset" : 0,
"end_offset" : 49,
"type" : "word",
"position" : 0
}
]
}
5.3 字母分词器:letter tokenizer
字母分词器(letter tokenizer)根据非字母的符号,将文本切分成分词。
POST _analyze
{
"tokenizer": "letter",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "To",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "be",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "or",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "not",
"start_offset" : 9,
"end_offset" : 12,
"type" : "word",
"position" : 3
},
{
"token" : "to",
"start_offset" : 13,
"end_offset" : 15,
"type" : "word",
"position" : 4
},
{
"token" : "be",
"start_offset" : 16,
"end_offset" : 18,
"type" : "word",
"position" : 5
},
{
"token" : "That",
"start_offset" : 21,
"end_offset" : 25,
"type" : "word",
"position" : 6
},
{
"token" : "is",
"start_offset" : 26,
"end_offset" : 28,
"type" : "word",
"position" : 7
},
{
"token" : "a",
"start_offset" : 29,
"end_offset" : 30,
"type" : "word",
"position" : 8
},
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "word",
"position" : 9
},
{
"token" : "莎士比亚",
"start_offset" : 45,
"end_offset" : 49,
"type" : "word",
"position" : 10
}
]
}
5.4 小写分词器:lowercase tokenizer
小写分词器(lowercase tokenizer)结合了常规的字母分词器和小写分词过滤器(跟你想的一样,就是将所有的分词转化为小写)的行为。通过一个单独的分词器来实现的主要原因是,一次进行两项操作会获得更好的性能。
POST _analyze
{
"tokenizer": "lowercase",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "to",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "be",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "or",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "not",
"start_offset" : 9,
"end_offset" : 12,
"type" : "word",
"position" : 3
},
{
"token" : "to",
"start_offset" : 13,
"end_offset" : 15,
"type" : "word",
"position" : 4
},
{
"token" : "be",
"start_offset" : 16,
"end_offset" : 18,
"type" : "word",
"position" : 5
},
{
"token" : "that",
"start_offset" : 21,
"end_offset" : 25,
"type" : "word",
"position" : 6
},
{
"token" : "is",
"start_offset" : 26,
"end_offset" : 28,
"type" : "word",
"position" : 7
},
{
"token" : "a",
"start_offset" : 29,
"end_offset" : 30,
"type" : "word",
"position" : 8
},
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "word",
"position" : 9
},
{
"token" : "莎士比亚",
"start_offset" : 45,
"end_offset" : 49,
"type" : "word",
"position" : 10
}
]
}
5.5 空白分词器:whitespace tokenizer
空白分词器(whitespace tokenizer)通过空白来分隔不同的分词,空白包括空格、制表符、换行等。但是,我们需要注意的是,空白分词器不会删除任何标点符号。
POST _analyze
{
"tokenizer": "whitespace",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "To",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "be",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 1
},
{
"token" : "or",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "not",
"start_offset" : 9,
"end_offset" : 12,
"type" : "word",
"position" : 3
},
{
"token" : "to",
"start_offset" : 13,
"end_offset" : 15,
"type" : "word",
"position" : 4
},
{
"token" : "be,",
"start_offset" : 16,
"end_offset" : 19,
"type" : "word",
"position" : 5
},
{
"token" : "That",
"start_offset" : 21,
"end_offset" : 25,
"type" : "word",
"position" : 6
},
{
"token" : "is",
"start_offset" : 26,
"end_offset" : 28,
"type" : "word",
"position" : 7
},
{
"token" : "a",
"start_offset" : 29,
"end_offset" : 30,
"type" : "word",
"position" : 8
},
{
"token" : "question",
"start_offset" : 31,
"end_offset" : 39,
"type" : "word",
"position" : 9
},
{
"token" : "————",
"start_offset" : 40,
"end_offset" : 44,
"type" : "word",
"position" : 10
},
{
"token" : "莎士比亚",
"start_offset" : 45,
"end_offset" : 49,
"type" : "word",
"position" : 11
}
]
}
5.6 模式分词器:pattern tokenizer
模式分词器(pattern tokenizer)允许指定一个任意的模式,将文本切分为分词。
POST _analyze
{
"tokenizer": "pattern",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
现在让我们手动定制一个以逗号分隔的分词器。
PUT pattern_test2
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"tokenizer":"my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer":{
"type":"pattern",
"pattern":","
}
}
}
}
}
上例中,在settings下的自定义分析器my_analyzer中,自定义的模式分词器名叫my_tokenizer;在与自定义分析器同级,为新建的自定义模式分词器设置一些属性,比如以逗号分隔。
POST pattern_test2/_analyze
{
"tokenizer": "my_tokenizer",
"text":"To be or not to be, That is a question ———— 莎士比亚"
}
结果如下:
{
"tokens" : [
{
"token" : "To be or not to be",
"start_offset" : 0,
"end_offset" : 18,
"type" : "word",
"position" : 0
},
{
"token" : " That is a question ———— 莎士比亚",
"start_offset" : 19,
"end_offset" : 49,
"type" : "word",
"position" : 1
}
]
}
根据结果可以看到,文档被逗号分割为两部分。
5.7 UAX URL电子邮件分词器:UAX RUL email tokenizer
在处理单个的英文单词的情况下,标准分词器是个非常好的选择,但是现在很多的网站以网址或电子邮件作为结尾,比如我们现在有这样的一个文本:
作者:张开
来源:未知
原文:https://www.cnblogs.com/Neeo/articles/10402742.html
邮箱:[email protected]
版权声明:本文为博主原创文章,转载请附上博文链接!
现在让我们使用标准分词器查看一下:
POST _analyze
{
"tokenizer": "standard",
"text":"作者:张开来源:未知原文:https://www.cnblogs.com/Neeo/articles/10402742.html邮箱:[email protected]版权声明:本文为博主原创文章,转载请附上博文链接!"
}
结果很长:
{
"tokens" : [
{
"token" : "作",
"start_offset" : 0,
"end_offset" : 1,
"type" : "",
"position" : 0
},
{
"token" : "者",
"start_offset" : 1,
"end_offset" : 2,
"type" : "",
"position" : 1
},
{
"token" : "张",
"start_offset" : 3,
"end_offset" : 4,
"type" : "",
"position" : 2
},
{
"token" : "开",
"start_offset" : 4,
"end_offset" : 5,
"type" : "",
"position" : 3
},
{
"token" : "来",
"start_offset" : 5,
"end_offset" : 6,
"type" : "",
"position" : 4
},
{
"token" : "源",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 5
},
{
"token" : "未",
"start_offset" : 8,
"end_offset" : 9,
"type" : "",
"position" : 6
},
{
"token" : "知",
"start_offset" : 9,
"end_offset" : 10,
"type" : "",
"position" : 7
},
{
"token" : "原",
"start_offset" : 10,
"end_offset" : 11,
"type" : "",
"position" : 8
},
{
"token" : "文",
"start_offset" : 11,
"end_offset" : 12,
"type" : "",
"position" : 9
},
{
"token" : "https",
"start_offset" : 13,
"end_offset" : 18,
"type" : "",
"position" : 10
},
{
"token" : "www.cnblogs.com",
"start_offset" : 21,
"end_offset" : 36,
"type" : "",
"position" : 11
},
{
"token" : "Neeo",
"start_offset" : 37,
"end_offset" : 41,
"type" : "",
"position" : 12
},
{
"token" : "articles",
"start_offset" : 42,
"end_offset" : 50,
"type" : "",
"position" : 13
},
{
"token" : "10402742",
"start_offset" : 51,
"end_offset" : 59,
"type" : "",
"position" : 14
},
{
"token" : "html",
"start_offset" : 60,
"end_offset" : 64,
"type" : "",
"position" : 15
},
{
"token" : "邮",
"start_offset" : 64,
"end_offset" : 65,
"type" : "",
"position" : 16
},
{
"token" : "箱",
"start_offset" : 65,
"end_offset" : 66,
"type" : "",
"position" : 17
},
{
"token" : "xxxxxxx",
"start_offset" : 67,
"end_offset" : 74,
"type" : "",
"position" : 18
},
{
"token" : "xx.com",
"start_offset" : 75,
"end_offset" : 81,
"type" : "",
"position" : 19
},
{
"token" : "版",
"start_offset" : 81,
"end_offset" : 82,
"type" : "",
"position" : 20
},
{
"token" : "权",
"start_offset" : 82,
"end_offset" : 83,
"type" : "",
"position" : 21
},
{
"token" : "声",
"start_offset" : 83,
"end_offset" : 84,
"type" : "",
"position" : 22
},
{
"token" : "明",
"start_offset" : 84,
"end_offset" : 85,
"type" : "",
"position" : 23
},
{
"token" : "本",
"start_offset" : 86,
"end_offset" : 87,
"type" : "",
"position" : 24
},
{
"token" : "文",
"start_offset" : 87,
"end_offset" : 88,
"type" : "",
"position" : 25
},
{
"token" : "为",
"start_offset" : 88,
"end_offset" : 89,
"type" : "",
"position" : 26
},
{
"token" : "博",
"start_offset" : 89,
"end_offset" : 90,
"type" : "",
"position" : 27
},
{
"token" : "主",
"start_offset" : 90,
"end_offset" : 91,
"type" : "",
"position" : 28
},
{
"token" : "原",
"start_offset" : 91,
"end_offset" : 92,
"type" : "",
"position" : 29
},
{
"token" : "创",
"start_offset" : 92,
"end_offset" : 93,
"type" : "",
"position" : 30
},
{
"token" : "文",
"start_offset" : 93,
"end_offset" : 94,
"type" : "",
"position" : 31
},
{
"token" : "章",
"start_offset" : 94,
"end_offset" : 95,
"type" : "",
"position" : 32
},
{
"token" : "转",
"start_offset" : 96,
"end_offset" : 97,
"type" : "",
"position" : 33
},
{
"token" : "载",
"start_offset" : 97,
"end_offset" : 98,
"type" : "",
"position" : 34
},
{
"token" : "请",
"start_offset" : 98,
"end_offset" : 99,
"type" : "",
"position" : 35
},
{
"token" : "附",
"start_offset" : 99,
"end_offset" : 100,
"type" : "",
"position" : 36
},
{
"token" : "上",
"start_offset" : 100,
"end_offset" : 101,
"type" : "",
"position" : 37
},
{
"token" : "博",
"start_offset" : 101,
"end_offset" : 102,
"type" : "",
"position" : 38
},
{
"token" : "文",
"start_offset" : 102,
"end_offset" : 103,
"type" : "",
"position" : 39
},
{
"token" : "链",
"start_offset" : 103,
"end_offset" : 104,
"type" : "",
"position" : 40
},
{
"token" : "接",
"start_offset" : 104,
"end_offset" : 105,
"type" : "",
"position" : 41
}
]
}
无论如何,这个结果不符合我们的预期,因为把我们的邮箱和网址分的乱七八糟!那么针对这种情况,我们应该使用UAX URL电子邮件分词器(UAX RUL email tokenizer),该分词器将电子邮件和URL都作为单独的分词进行保留。
POST _analyze
{
"tokenizer": "uax_url_email",
"text":"作者:张开来源:未知原文:https://www.cnblogs.com/Neeo/articles/10402742.html邮箱:[email protected]版权声明:本文为博主原创文章,转载请附上博文链接!"
}
结果如下:
{
"tokens" : [
{
"token" : "作",
"start_offset" : 0,
"end_offset" : 1,
"type" : "",
"position" : 0
},
{
"token" : "者",
"start_offset" : 1,
"end_offset" : 2,
"type" : "",
"position" : 1
},
{
"token" : "张",
"start_offset" : 3,
"end_offset" : 4,
"type" : "",
"position" : 2
},
{
"token" : "开",
"start_offset" : 4,
"end_offset" : 5,
"type" : "",
"position" : 3
},
{
"token" : "来",
"start_offset" : 5,
"end_offset" : 6,
"type" : "",
"position" : 4
},
{
"token" : "源",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 5
},
{
"token" : "未",
"start_offset" : 8,
"end_offset" : 9,
"type" : "",
"position" : 6
},
{
"token" : "知",
"start_offset" : 9,
"end_offset" : 10,
"type" : "",
"position" : 7
},
{
"token" : "原",
"start_offset" : 10,
"end_offset" : 11,
"type" : "",
"position" : 8
},
{
"token" : "文",
"start_offset" : 11,
"end_offset" : 12,
"type" : "",
"position" : 9
},
{
"token" : "https://www.cnblogs.com/Neeo/articles/10402742.html",
"start_offset" : 13,
"end_offset" : 64,
"type" : "",
"position" : 10
},
{
"token" : "邮",
"start_offset" : 64,
"end_offset" : 65,
"type" : "",
"position" : 11
},
{
"token" : "箱",
"start_offset" : 65,
"end_offset" : 66,
"type" : "",
"position" : 12
},
{
"token" : "[email protected]",
"start_offset" : 67,
"end_offset" : 81,
"type" : "",
"position" : 13
},
{
"token" : "版",
"start_offset" : 81,
"end_offset" : 82,
"type" : "",
"position" : 14
},
{
"token" : "权",
"start_offset" : 82,
"end_offset" : 83,
"type" : "",
"position" : 15
},
{
"token" : "声",
"start_offset" : 83,
"end_offset" : 84,
"type" : "",
"position" : 16
},
{
"token" : "明",
"start_offset" : 84,
"end_offset" : 85,
"type" : "",
"position" : 17
},
{
"token" : "本",
"start_offset" : 86,
"end_offset" : 87,
"type" : "",
"position" : 18
},
{
"token" : "文",
"start_offset" : 87,
"end_offset" : 88,
"type" : "",
"position" : 19
},
{
"token" : "为",
"start_offset" : 88,
"end_offset" : 89,
"type" : "",
"position" : 20
},
{
"token" : "博",
"start_offset" : 89,
"end_offset" : 90,
"type" : "",
"position" : 21
},
{
"token" : "主",
"start_offset" : 90,
"end_offset" : 91,
"type" : "",
"position" : 22
},
{
"token" : "原",
"start_offset" : 91,
"end_offset" : 92,
"type" : "",
"position" : 23
},
{
"token" : "创",
"start_offset" : 92,
"end_offset" : 93,
"type" : "",
"position" : 24
},
{
"token" : "文",
"start_offset" : 93,
"end_offset" : 94,
"type" : "",
"position" : 25
},
{
"token" : "章",
"start_offset" : 94,
"end_offset" : 95,
"type" : "",
"position" : 26
},
{
"token" : "转",
"start_offset" : 96,
"end_offset" : 97,
"type" : "",
"position" : 27
},
{
"token" : "载",
"start_offset" : 97,
"end_offset" : 98,
"type" : "",
"position" : 28
},
{
"token" : "请",
"start_offset" : 98,
"end_offset" : 99,
"type" : "",
"position" : 29
},
{
"token" : "附",
"start_offset" : 99,
"end_offset" : 100,
"type" : "",
"position" : 30
},
{
"token" : "上",
"start_offset" : 100,
"end_offset" : 101,
"type" : "",
"position" : 31
},
{
"token" : "博",
"start_offset" : 101,
"end_offset" : 102,
"type" : "",
"position" : 32
},
{
"token" : "文",
"start_offset" : 102,
"end_offset" : 103,
"type" : "",
"position" : 33
},
{
"token" : "链",
"start_offset" : 103,
"end_offset" : 104,
"type" : "",
"position" : 34
},
{
"token" : "接",
"start_offset" : 104,
"end_offset" : 105,
"type" : "",
"position" : 35
}
]
}
5.8 路径层次分词器:path hierarchy tokenizer
路径层次分词器(path hierarchy tokenizer)允许以特定的方式索引文件系统的路径,这样在搜索时,共享同样路径的文件将被作为结果返回。
POST _analyze
{
"tokenizer": "path_hierarchy",
"text":"/usr/local/python/python2.7"
}
返回结果如下:
{
"tokens" : [
{
"token" : "/usr",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 0
},
{
"token" : "/usr/local",
"start_offset" : 0,
"end_offset" : 10,
"type" : "word",
"position" : 0
},
{
"token" : "/usr/local/python",
"start_offset" : 0,
"end_offset" : 17,
"type" : "word",
"position" : 0
},
{
"token" : "/usr/local/python/python2.7",
"start_offset" : 0,
"end_offset" : 27,
"type" : "word",
"position" : 0
}
]
}
六 分词过滤器
asticsearch内置很多(真是变态多啊!但一般用不到,美滋滋!!!)的分词过滤器。其中包含分词过滤器和字符过滤器。
常见分词过滤器
这里仅列举几个常见的分词过滤器(token filter)包括:
- 标准分词过滤器(Standard Token Filter)在6.5.0版本弃用。此筛选器已被弃用,将在下一个主要版本中删除。在之前的版本中其实也没干啥,甚至在更老版本的
Lucene中,它用于去除单词结尾的s字符,还有不必要的句点字符,但是现在, 连这些小功能都被其他的分词器和分词过滤器顺手干了,真可怜! - ASCII折叠分词过滤器(ASCII Folding Token Filter)将前127个ASCII字符(基本拉丁语的Unicode块)中不包含的字母、数字和符号Unicode字符转换为对应的ASCII字符(如果存在的话)。
- 扁平图形分词过滤器(Flatten Graph Token Filter)接受任意图形标记流。例如由同义词图形标记过滤器生成的标记流,并将其展平为适合索引的单个线性标记链。这是一个有损的过程,因为单独的侧路径被压扁在彼此之上,但是如果在索引期间使用图形令牌流是必要的,因为Lucene索引当前不能表示图形。 出于这个原因,最好只在搜索时应用图形分析器,因为这样可以保留完整的图形结构,并为邻近查询提供正确的匹配。该功能在Lucene中为实验性功能。
- 长度标记过滤器(Length Token Filter)会移除分词流中太长或者太短的标记,它是可配置的,我们可以在settings中设置。
- 小写分词过滤器(Lowercase Token Filter)将分词规范化为小写,它通过
language参数支持希腊语、爱尔兰语和土耳其语小写标记过滤器。 - 大写分词过滤器(Uppercase Token Filter)将分词规范为大写。
其余分词过滤器不一一列举。详情参见官网。
6.1 自定义分词过滤器
接下来我们简单的来学习自定义两个分词过滤器。首先是长度分词过滤器。
PUT pattern_test3
{
"settings": {
"analysis": {
"filter": {
"my_test_length":{
"type":"length",
"max":8,
"min":2
}
}
}
}
}
上例中,我们自定义了一个长度过滤器,过滤掉长度大于8和小于2的分词。
需要补充的是,max参数表示最大分词长度。默认为Integer.MAX_VALUE,就是2147483647(231−1
),而min则表示最小长度,默认为0。
POST pattern_test3/_analyze
{
"tokenizer": "standard",
"filter": ["my_test_length"],
"text":"a Small word and a longerword"
}
结果如下:
{
"tokens" : [
{
"token" : "Small",
"start_offset" : 2,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "word",
"start_offset" : 8,
"end_offset" : 12,
"type" : "",
"position" : 2
},
{
"token" : "and",
"start_offset" : 13,
"end_offset" : 16,
"type" : "",
"position" : 3
}
]
}
6.2 自定义小写分词过滤器
自定义一个小写分词过滤器,过滤希腊文:
PUT lowercase_example
{
"settings": {
"analysis": {
"analyzer": {
"standard_lowercase_example": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase"]
},
"greek_lowercase_example": {
"type": "custom",
"tokenizer": "standard",
"filter": ["greek_lowercase"]
}
},
"filter": {
"greek_lowercase": {
"type": "lowercase",
"language": "greek"
}
}
}
}
}
过滤内容是:
POST lowercase_example/_analyze
{
"tokenizer": "standard",
"filter": ["greek_lowercase"],
"text":"Ένα φίλτρο διακριτικού τύπου πεζά s ομαλοποιεί το κείμενο διακριτικού σε χαμηλότερη θήκη"
}
结果如下:
{
"tokens" : [
{
"token" : "ενα",
"start_offset" : 0,
"end_offset" : 3,
"type" : "",
"position" : 0
},
{
"token" : "φιλτρο",
"start_offset" : 4,
"end_offset" : 10,
"type" : "",
"position" : 1
},
{
"token" : "διακριτικου",
"start_offset" : 11,
"end_offset" : 22,
"type" : "",
"position" : 2
},
{
"token" : "τυπου",
"start_offset" : 23,
"end_offset" : 28,
"type" : "",
"position" : 3
},
{
"token" : "πεζα",
"start_offset" : 29,
"end_offset" : 33,
"type" : "",
"position" : 4
},
{
"token" : "s",
"start_offset" : 34,
"end_offset" : 35,
"type" : "",
"position" : 5
},
{
"token" : "ομαλοποιει",
"start_offset" : 36,
"end_offset" : 46,
"type" : "",
"position" : 6
},
{
"token" : "το",
"start_offset" : 47,
"end_offset" : 49,
"type" : "",
"position" : 7
},
{
"token" : "κειμενο",
"start_offset" : 50,
"end_offset" : 57,
"type" : "",
"position" : 8
},
{
"token" : "διακριτικου",
"start_offset" : 58,
"end_offset" : 69,
"type" : "",
"position" : 9
},
{
"token" : "σε",
"start_offset" : 70,
"end_offset" : 72,
"type" : "",
"position" : 10
},
{
"token" : "χαμηλοτερη",
"start_offset" : 73,
"end_offset" : 83,
"type" : "",
"position" : 11
},
{
"token" : "θηκη",
"start_offset" : 84,
"end_offset" : 88,
"type" : "",
"position" : 12
}
]
}
6.3 多个分词过滤器
除此之外,我们可以使用多个分词过滤器。例如我们在使用长度过滤器时,可以同时使用小写分词过滤器或者更多。
POST _analyze
{
"tokenizer": "standard",
"filter": ["length","lowercase"],
"text":"a Small word and a longerword"
}
上例中,我们用列表来管理多个分词过滤器。
结果如下:
{
"tokens" : [
{
"token" : "a",
"start_offset" : 0,
"end_offset" : 1,
"type" : "",
"position" : 0
},
{
"token" : "small",
"start_offset" : 2,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "word",
"start_offset" : 8,
"end_offset" : 12,
"type" : "",
"position" : 2
},
{
"token" : "and",
"start_offset" : 13,
"end_offset" : 16,
"type" : "",
"position" : 3
},
{
"token" : "a",
"start_offset" : 17,
"end_offset" : 18,
"type" : "",
"position" : 4
},
{
"token" : "longerword",
"start_offset" : 19,
"end_offset" : 29,
"type" : "",
"position" : 5
}
]
}
14-Elasticsearch - ik分词器
一 前言
在知名的中分分词器中,ik中文分词器的大名可以说是无人不知,elasticsearch有了ik分词器的加持,就像男人有了神油…要了解ik中文分词器,就首先要了解一下它的由来。
二 ik分词器的由来
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IK Analyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
IK Analyzer 2012特性:
- 采用了特有的
正向迭代最细粒度切分算法,支持细粒度和智能分词两种切分模式。在系统环境:Core2 i7 3.4G双核,4G内存,window 7 64位, Sun JDK 1.6_29 64位 普通pc环境测试,IK2012具有160万字/秒(3000KB/S)的高速处理能力。 - 2012版本的智能分词模式支持简单的分词排歧义处理和数量词合并输出。
- 采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符
- 优化的词典存储,更小的内存占用。支持用户词典扩展定义。特别的,在2012版本,词典支持中文,英文,数字混合词语。
后来,被一个叫medcl(曾勇 elastic开发工程师与布道师,elasticsearch开源社区负责人,2015年加入elastic)的人集成到了elasticsearch中, 并支持自定义字典…
ps:elasticsearch的ik中文分词器插件由medcl的github上下载,而 IK Analyzer 这个分词器,如果百度搜索的,在开源中国中的提交者是林良益,由此推断之下,才有了上面的一番由来…
才有了接下来一系列的扯淡…
三 IK分词器插件的安装
- 打开
Github官网,搜索elasticsearch-analysis-ik,单击medcl/elasticsearch-analysis-ik。或者直接点击
- 在
readme.md文件中,下拉选择历史版本连接。
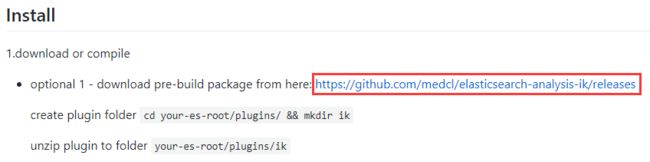
- 由于
ik与elasticsearch存在兼容问题。所以在下载ik时要选择和elasticsearch版本一致的,也就是选择v6.5.4版本,单击elasticsearch-analysis-ik-6.5.4.zip包,自动进入下载到本地。
- 本地下载成功后,是个
zip包。
![]()
3.1 安装
- 首先打开
C:\Program Files\elasticseach-6.5.4\plugins目录,新建一个名为ik的子目录,并将elasticsearch-analysis-ik-6.5.4.zip包解压到该ik目录内也就是C:\Program Files\elasticseach-6.5.4\plugins\ik目录。
3.2 测试
- 首先将
elascticsearch和kibana服务重启。 - 然后地址栏输入
http://localhost:5601,在Dev Tools中的Console界面的左侧输入命令,再点击绿色的执行按钮执行。
GET _analyze
{
"analyzer": "ik_max_word",
"text": "上海自来水来自海上"
}
右侧就显示出结果了如下所示:
{
"tokens" : [
{
"token" : "上海",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "自来水",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "自来",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "水",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "来自",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "海上",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 5
}
]
}
OK,安装完毕,非常的简单。
3.3 ik目录简介
我们简要的介绍一下ik分词配置文件:
- IKAnalyzer.cfg.xml,用来配置自定义的词库
- main.dic,ik原生内置的中文词库,大约有27万多条,只要是这些单词,都会被分在一起。
- surname.dic,中国的姓氏。
- suffix.dic,特殊(后缀)名词,例如
乡、江、所、省等等。 - preposition.dic,中文介词,例如
不、也、了、仍等等。 - stopword.dic,英文停用词库,例如
a、an、and、the等。 - quantifier.dic,单位名词,如
厘米、件、倍、像素等。
四 ik分词器的使用
before
- 首先将
elascticsearch和kibana服务重启,让插件生效。 - 然后地址栏输入
http://localhost:5601,在Dev Tools中的Console界面的左侧输入命令,再点击绿色的执行按钮执行。
4.1 第一个ik示例
来个简单的示例。
GET _analyze
{
"analyzer": "ik_max_word",
"text": "上海自来水来自海上"
}
右侧就显示出结果了如下所示:
{
"tokens" : [
{
"token" : "上海",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "自来水",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "自来",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "水",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "来自",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "海上",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 5
}
]
}
那么你可能对开始的analyzer:ik_max_word有一丝的疑惑,这个家伙是干嘛的呀?我们就来看看这个家伙到底是什么鬼!
4.2 ik_max_word
现在有这样的一个索引:
PUT ik1
{
"mappings": {
"doc": {
"dynamic": false,
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
上例中,ik_max_word参数会将文档做最细粒度的拆分,以穷尽尽可能的组合。
接下来为该索引添加几条数据:
PUT ik1/doc/1
{
"content":"今天是个好日子"
}
PUT ik1/doc/2
{
"content":"心想的事儿都能成"
}
PUT ik1/doc/3
{
"content":"我今天不活了"
}
现在让我们开始查询,随便查!
GET ik1/_search
{
"query": {
"match": {
"content": "心想"
}
}
}
查询结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "2",
"_score" : 0.2876821,
"_source" : {
"content" : "心想的事儿都能成"
}
}
]
}
}
成功的返回了一条数据。我们再来以今天为条件来查询。
GET ik1/_search
{
"query": {
"match": {
"content": "今天"
}
}
}
结果如下:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"content" : "今天是个好日子"
}
},
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"content" : "我今天不活了"
}
}
]
}
}
上例的返回中,成功的查询到了两条结果。
与ik_max_word对应还有另一个参数。让我们一起来看下。
4.3 ik_smart
与ik_max_word对应的是ik_smart参数,该参数将文档作最粗粒度的拆分。
GET _analyze
{
"analyzer": "ik_smart",
"text": "今天是个好日子"
}
上例中,我们以最粗粒度的拆分文档。
结果如下:
{
"tokens" : [
{
"token" : "今天是",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "个",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "好日子",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 2
}
]
}
再来看看以最细粒度的拆分文档。
GET _analyze
{
"analyzer": "ik_max_word",
"text": "今天是个好日子"
}
结果如下:
{
"tokens" : [
{
"token" : "今天是",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "今天",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "是",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "个",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "好日子",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "日子",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 5
}
]
}
由上面的对比可以发现,两个参数的不同,所以查询结果也肯定不一样,视情况而定用什么粒度。
在基本操作方面,除了粗细粒度,别的按照之前的操作即可,就像下面两个短语查询和短语前缀查询一样。
4.4 ik之短语查询
ik中的短语查询参照之前的短语查询即可。
GET ik1/_search
{
"query": {
"match_phrase": {
"content": "今天"
}
}
}
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"content" : "今天是个好日子"
}
},
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"content" : "我今天不活了"
}
}
]
}
}
4.5 ik之短语前缀查询
同样的,我们第2部分的快速上手部分的操作在ik中同样适用。
GET ik1/_search
{
"query": {
"match_phrase_prefix": {
"content": {
"query": "今天好日子",
"slop": 2
}
}
}
}
结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"content" : "今天是个好日子"
}
},
{
"_index" : "ik1",
"_type" : "doc",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"content" : "我今天不活了"
}
}
]
}
}
15-Elasticsearch for Python之连接
一 前言
现在,我们来学习Python如何操作elasticsearch。
二 依赖下载
首先,我们必须拥有Python的环境,如何搭建Python环境,请参阅。
要用Python来操作elasticsearch,首先安装Python的elasticsearch包:
pip install elasticsearch
pip install elasticsearch==6.3.1
# 豆瓣源
pip install -i https://pypi.doubanio.com/simple/ elasticsearch
三 Python连接elasticsearch
Python连接elasticsearch有以下几种连接方式:
from elasticsearch import Elasticsearch
# es = Elasticsearch() # 默认连接本地elasticsearch
# es = Elasticsearch(['127.0.0.1:9200']) # 连接本地9200端口
es = Elasticsearch(
["192.168.1.10", "192.168.1.11", "192.168.1.12"], # 连接集群,以列表的形式存放各节点的IP地址
sniff_on_start=True, # 连接前测试
sniff_on_connection_fail=True, # 节点无响应时刷新节点
sniff_timeout=60 # 设置超时时间
)
四 配置忽略响应状态码
es = Elasticsearch(['127.0.0.1:9200'],ignore=400) # 忽略返回的400状态码
es = Elasticsearch(['127.0.0.1:9200'],ignore=[400, 405, 502]) # 以列表的形式忽略多个状态码
五 一个简单的示例
from elasticsearch import Elasticsearch
es = Elasticsearch() # 默认连接本地elasticsearch
print(es.index(index='py2', doc_type='doc', id=1, body={'name': "张开", "age": 18}))
print(es.get(index='py2', doc_type='doc', id=1))
第1个print为创建py2索引,并插入一条数据,第2个print查询指定文档。
查询结果如下:
{'_index': 'py2', '_type': 'doc', '_id': '1', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 0, '_primary_term': 1}
{'_index': 'py2', '_type': 'doc', '_id': '1', '_version': 1, 'found': True, '_source': {'name': '张开', 'age': 18}}
16-Elasticsearch for Python之操作
一 前言
Python中关于elasticsearch的操作,主要集中一下几个方面:
- 结果过滤,对于返回结果做过滤,主要是优化返回内容。
- Elasticsearch(简称es),直接操作elasticsearch对象,处理一些简单的索引信息。一下几个方面都是建立在es对象的基础上。
- Indices,关于索引的细节操作,比如创建自定义的
mappings。 - Cluster,关于集群的相关操作。
- Nodes,关于节点的相关操作。
- Cat API,换一种查询方式,一般的返回都是json类型的,cat提供了简洁的返回结果。
- Snapshot,快照相关,快照是从正在运行的Elasticsearch集群中获取的备份。我们可以拍摄单个索引或整个群集的快照,并将其存储在共享文件系统的存储库中,并且有一些插件支持S3,HDFS,Azure,Google云存储等上的远程存储库。
- Task Management API,任务管理API是新的,仍应被视为测试版功能。API可能以不向后兼容的方式更改。
二 结果过滤
print(es.search(index='py2', filter_path=['hits.total', 'hits.hits._source'])) # 可以省略type类型
print(es.search(index='w2', doc_type='doc')) # 可以指定type类型
print(es.search(index='w2', doc_type='doc', filter_path=['hits.total']))
filter_path参数用于减少elasticsearch返回的响应,比如仅返回hits.total和hits.hits._source内容。
除此之外,filter_path参数还支持*通配符以匹配字段名称、任何字段或者字段部分:
print(es.search(index='py2', filter_path=['hits.*']))
print(es.search(index='py2', filter_path=['hits.hits._*']))
print(es.search(index='py2', filter_path=['hits.to*'])) # 仅返回响应数据的total
print(es.search(index='w2', doc_type='doc', filter_path=['hits.hits._*'])) # 可以加上可选的type类型
三 Elasticsearch(es对象)
- es.index,向指定索引添加或更新文档,如果索引不存在,首先会创建该索引,然后再执行添加或者更新操作。
# print(es.index(index='w2', doc_type='doc', id='4', body={"name":"可可", "age": 18})) # 正常
# print(es.index(index='w2', doc_type='doc', id=5, body={"name":"卡卡西", "age":22})) # 正常
# print(es.index(index='w2', id=6, body={"name": "鸣人", "age": 22})) # 会报错,TypeError: index() missing 1 required positional argument: 'doc_type'
print(es.index(index='w2', doc_type='doc', body={"name": "鸣人", "age": 22})) # 可以不指定id,默认生成一个id
- es.get,查询索引中指定文档。
print(es.get(index='w2', doc_type='doc', id=5)) # 正常
print(es.get(index='w2', doc_type='doc')) # TypeError: get() missing 1 required positional argument: 'id'
print(es.get(index='w2', id=5)) # TypeError: get() missing 1 required positional argument: 'doc_type'
- es.search,执行搜索查询并获取与查询匹配的搜索匹配。这个用的最多,可以跟复杂的查询条件。
index要搜索的以逗号分隔的索引名称列表; 使用_all 或空字符串对所有索引执行操作。doc_type要搜索的以逗号分隔的文档类型列表; 留空以对所有类型执行操作。body使用Query DSL(QueryDomain Specific Language查询表达式)的搜索定义。_source返回_source字段的true或false,或返回的字段列表,返回指定字段。_source_exclude要从返回的_source字段中排除的字段列表,返回的所有字段中,排除哪些字段。_source_include从_source字段中提取和返回的字段列表,跟_source差不多。
print(es.search(index='py3', doc_type='doc', body={"query": {"match":{"age": 20}}})) # 一般查询
print(es.search(index='py3', doc_type='doc', body={"query": {"match":{"age": 19}}},_source=['name', 'age'])) # 结果字段过滤
print(es.search(index='py3', doc_type='doc', body={"query": {"match":{"age": 19}}},_source_exclude =[ 'age']))
print(es.search(index='py3', doc_type='doc', body={"query": {"match":{"age": 19}}},_source_include =[ 'age']))
- es.get_source,通过索引、类型和ID获取文档的来源,其实,直接返回想要的字典。
print(es.get_source(index='py3', doc_type='doc', id='1')) # {'name': '王五', 'age': 19}
- es.count,执行查询并获取该查询的匹配数。比如查询年龄是18的文档。
body = {
"query": {
"match": {
"age": 18
}
}
}
print(es.count(index='py2', doc_type='doc', body=body)) # {'count': 1, '_shards': {'total': 5, 'successful': 5, 'skipped': 0, 'failed': 0}}
print(es.count(index='py2', doc_type='doc', body=body)['count']) # 1
print(es.count(index='w2')) # {'count': 6, '_shards': {'total': 5, 'successful': 5, 'skipped': 0, 'failed': 0}}
print(es.count(index='w2', doc_type='doc')) # {'count': 6, '_shards': {'total': 5, 'successful': 5, 'skipped': 0, 'failed': 0}}
- es.create,创建索引(索引不存在的话)并新增一条数据,索引存在仅新增(只能新增,重复执行会报错)。
print(es.create(index='py3', doc_type='doc', id='1', body={"name": '王五', "age": 20}))
print(es.get(index='py3', doc_type='doc', id='3'))
在内部,调用了index,等价于:
print(es.index(index='py3', doc_type='doc', id='4', body={"name": "麻子", "age": 21}))
但个人觉得没有index好用!
- es.delete,删除指定的文档。比如删除文章id为
4的文档,但不能删除索引,如果想要删除索引,还需要es.indices.delete来处理
print(es.delete(index='py3', doc_type='doc', id='4'))
- es.delete_by_query,删除与查询匹配的所有文档。
index要搜索的以逗号分隔的索引名称列表; 使用_all 或空字符串对所有索引执行操作。doc_type要搜索的以逗号分隔的文档类型列表; 留空以对所有类型执行操作。body使用Query DSL的搜索定义。
print(es.delete_by_query(index='py3', doc_type='doc', body={"query": {"match":{"age": 20}}}))
- es.exists,查询elasticsearch中是否存在指定的文档,返回一个布尔值。
print(es.exists(index='py3', doc_type='doc', id='1'))
- es.info,获取当前集群的基本信息。
print(es.info())
- es.ping,如果群集已启动,则返回True,否则返回False。
print(es.ping())
四 Indices(es.indices)
- **es.indices.create,在Elasticsearch中创建索引,用的最多。**比如创建一个严格模式、有4个字段、并为
title字段指定ik_max_word查询粒度的mappings。并应用到py4索引中。这也是常用的创建自定义索引的方式。
body = {
"mappings": {
"doc": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"url": {
"type": "text"
},
"action_type": {
"type": "text"
},
"content": {
"type": "text"
}
}
}
}
}
es.indices.create('py4', body=body)
- es.indices.analyze,返回分词结果。
es.indices.analyze(body={'analyzer': "ik_max_word", "text": "皮特和茱丽当选“年度模范情侣”Brad Pitt and Angelina Jolie"})
- es.indices.delete,在Elasticsearch中删除索引。
print(es.indices.delete(index='py4'))
print(es.indices.delete(index='w3')) # {'acknowledged': True}
- es.indices.put_alias,为一个或多个索引创建别名,查询多个索引的时候,可以使用这个别名。
index别名应指向的逗号分隔的索引名称列表(支持通配符),使用_all对所有索引执行操作。name要创建或更新的别名的名称。body别名的设置,例如路由或过滤器。
print(es.indices.put_alias(index='py4', name='py4_alias')) # 为单个索引创建别名
print(es.indices.put_alias(index=['py3', 'py2'], name='py23_alias')) # 为多个索引创建同一个别名,联查用
- es.indices.delete_alias,删除一个或多个别名。
print(es.indices.delete_alias(index='alias1'))
print(es.indices.delete_alias(index=['alias1, alias2']))
- es.indices.get_mapping,检索索引或索引/类型的映射定义。
print(es.indices.get_mapping(index='py4'))
- es.indices.get_settings,检索一个或多个(或所有)索引的设置。
print(es.indices.get_settings(index='py4'))
- es.indices.get,允许检索有关一个或多个索引的信息。
print(es.indices.get(index='py2')) # 查询指定索引是否存在
print(es.indices.get(index=['py2', 'py3']))
- es.indices.get_alias,检索一个或多个别名。
print(es.indices.get_alias(index='py2'))
print(es.indices.get_alias(index=['py2', 'py3']))
- es.indices.get_field_mapping,检索特定字段的映射信息。
print(es.indices.get_field_mapping(fields='url', index='py4', doc_type='doc'))
print(es.indices.get_field_mapping(fields=['url', 'title'], index='py4', doc_type='doc'))
- es.indices.delete_alias,删除特定别名。
- es.indices.exists,返回一个布尔值,指示给定的索引是否存在。
- es.indices.exists_type,检查索引/索引中是否存在类型/类型。
- es.indices.flus,明确的刷新一个或多个索引。
- es.indices.get_field_mapping,检索特定字段的映射。
- es.indices.get_template,按名称检索索引模板。
- es.indices.open,打开一个封闭的索引以使其可用于搜索。
- es.indices.close,关闭索引以从群集中删除它的开销。封闭索引被阻止进行读/写操作。
- es.indices.clear_cache,清除与一个或多个索引关联的所有缓存或特定缓存。
- es.indices.put_alias,为特定索引/索引创建别名。
- es.indices.get_uprade,监控一个或多个索引的升级程度。
- es.indices.put_mapping,注册特定类型的特定映射定义。
- es.indices.put_settings,实时更改特定索引级别设置。
- es.indices.put_template,创建一个索引模板,该模板将自动应用于创建的新索引。
- es.indices.rollove,当现有索引被认为太大或太旧时,翻转索引API将别名转移到新索引。API接受单个别名和条件列表。别名必须仅指向单个索引。如果索引满足指定条件,则创建新索引并切换别名以指向新别名。
- es.indices.segments,提供构建Lucene索引(分片级别)的低级别段信息。
五 Cluster(集群相关)
- es.cluster.get_settigns,获取集群设置。
print(es.cluster.get_settings())
- es.cluster.health,获取有关群集运行状况的非常简单的状态。
print(es.cluster.health())
- es.cluster.state,获取整个集群的综合状态信息。
print(es.cluster.state())
- es.cluster.stats,返回群集的当前节点的信息。
print(es.cluster.stats())
六 Node(节点相关)
- es.nodes.info,返回集群中节点的信息。
print(es.nodes.info()) # 返回所节点
print(es.nodes.info(node_id='node1')) # 指定一个节点
print(es.nodes.info(node_id=['node1', 'node2'])) # 指定多个节点列表
- es.nodes.stats,获取集群中节点统计信息。
print(es.nodes.stats())
print(es.nodes.stats(node_id='node1'))
print(es.nodes.stats(node_id=['node1', 'node2']))
- es.nodes.hot_threads,获取指定节点的线程信息。
print(es.nodes.hot_threads(node_id='node1'))
print(es.nodes.hot_threads(node_id=['node1', 'node2']))
- es.nodes.usage,获取集群中节点的功能使用信息。
print(es.nodes.usage())
print(es.nodes.usage(node_id='node1'))
print(es.nodes.usage(node_id=['node1', 'node2']))
七 Cat(一种查询方式)
- es.cat.aliases,返回别名信息。
name要返回的以逗号分隔的别名列表。formatAccept标头的简短版本,例如json,yaml
print(es.cat.aliases(name='py23_alias'))
print(es.cat.aliases(name='py23_alias', format='json'))
- es.cat.allocation,返回分片使用情况。
print(es.cat.allocation())
print(es.cat.allocation(node_id=['node1']))
print(es.cat.allocation(node_id=['node1', 'node2'], format='json'))
- es.cat.count,Count提供对整个群集或单个索引的文档计数的快速访问。
print(es.cat.count()) # 集群内的文档总数
print(es.cat.count(index='py3')) # 指定索引文档总数
print(es.cat.count(index=['py3', 'py2'], format='json')) # 返回两个索引文档和
- es.cat.fielddata,基于每个节点显示有关当前加载的fielddata的信息。有些数据为了查询效率,会放在内存中,fielddata用来控制哪些数据应该被放在内存中,而这个
es.cat.fielddata则查询现在哪些数据在内存中,数据大小等信息。
print(es.cat.fielddata())
print(es.cat.fielddata(format='json', bytes='b'))
bytes显示字节值的单位,有效选项为:'b','k','kb','m','mb','g','gb','t','tb' ,'p','pb'
formatAccept标头的简短版本,例如json,yaml
- es.cat.health,从集群中
health里面过滤出简洁的集群健康信息。
print(es.cat.health())
print(es.cat.health(format='json'))
- es.cat.help,返回
es.cat的帮助信息。
print(es.cat.help())
- es.cat.indices,返回索引的信息;也可以使用此命令进行查询集群中有多少索引。
print(es.cat.indices())
print(es.cat.indices(index='py3'))
print(es.cat.indices(index='py3', format='json'))
print(len(es.cat.indices(format='json'))) # 查询集群中有多少索引
- es.cat.master,返回集群中主节点的IP,绑定IP和节点名称。
print(es.cat.master())
print(es.cat.master(format='json'))
- es.cat.nodeattrs,返回节点的自定义属性。
print(es.cat.nodeattrs())
print(es.cat.nodeattrs(format='json'))
- es.cat.nodes,返回节点的拓扑,这些信息在查看整个集群时通常很有用,特别是大型集群。我有多少符合条件的节点?
print(es.cat.nodes())
print(es.cat.nodes(format='json'))
- es.cat.plugins,返回节点的插件信息。
print(es.cat.plugins())
print(es.cat.plugins(format='json'))
- es.cat.segments,返回每个索引的Lucene有关的信息。
print(es.cat.segments())
print(es.cat.segments(index='py3'))
print(es.cat.segments(index='py3', format='json'))
- es.cat.shards,返回哪个节点包含哪些分片的信息。
print(es.cat.shards())
print(es.cat.shards(index='py3'))
print(es.cat.shards(index='py3', format='json'))
- es.cat.thread_pool,获取有关线程池的信息。
print(es.cat.thread_pool())
八 Snapshot(快照相关)
- es.snapshot.create,在存储库中创建快照。
repository存储库名称。snapshot快照名称。body快照定义。
- es.snapshot.delete,从存储库中删除快照。
- es.snapshot.create_repository。注册共享文件系统存储库。
- es.snapshot.delete_repository,删除共享文件系统存储库。
- es.snapshot.get,检索有关快照的信息。
- es.snapshot.get_repository,返回有关已注册存储库的信息。
- es.snapshot.restore,恢复快照。
- es.snapshot.status,返回有关所有当前运行快照的信息。通过指定存储库名称,可以将结果限制为特定存储库。
- es.snapshot.verify_repository,返回成功验证存储库的节点列表,如果验证过程失败,则返回错误消息。
九 Task(任务相关)
- es.tasks.get,检索特定任务的信息。
- es.tasks.cancel,取消任务。
- es.tasks.list,任务列表。