Monitor 监控指标
Monitor 监控指标
- 指标格式
-
- 全局唯一字符串
- 标签集组合
- Influx 指标格式
- 指标类型
-
- Gauge
- Counter
- Histogram
- Summary
- 告警
监控指标: 数值类型的监控数据
- 如: 某个机器的内存利用率,某个 MySQL 实例的当前连接数,某个 Redis 的最大内存上限
指标格式
| 指标标识 | 优点 | 缺点 |
|---|---|---|
| 全局唯一字符串 | 简单 | 缺少维度,不利于聚合计算,灵活筛选 |
| 标签集组合 | 灵活 | 较重复 |
| Influx 指标格式 | 灵活,精巧,语义丰富 | 理解成本较高 |
全局唯一字符串
监控指标:一般是全局唯一的字符串
- 如: 某机器的内存利用率
host.10.2.3.4.mem_used_percent, 包含: 机器的信息,指标名
设监控数据采集的频率: 30 秒
- 2 分钟内采集 4 个数据点
- 每个数据点有时间戳和值
指标内容:
{
"name": "host.10.2.3.4.mem_used_percent",
"points": [
{
"clock": 1662449136,
"value": 45.4
},
{
"clock": 1662449166,
"value": 43.2
},
{
"clock": 1662449196,
"value": 44.9
},
{
"clock": 1662449226,
"value": 44.8
}
]
}
HTTP 请求状态码的指标 :
- myhost 机器上部署了两个服务: service1 和 service2
- 请求状态码是 200 或 500
- HTTP method 是 get 或 post
分类维度都要拼到指标标识中。处理弊端:较混乱,不方便聚合统计
myhost.service1.http_request.200.get
myhost.service1.http_request.200.post
myhost.service1.http_request.500.get
myhost.service1.http_request.500.post
myhost.service2.http_request.200.get
myhost.service2.http_request.500.post
标签集组合
OpenTSDB 描述指标的方式
指标通过空格分开
- 第一段:指标名
- 第二段: 时间戳(单位是秒)
- 第三段: 指标值
- 其他部分:多个标签 (tags/labels),每个标签以 key=value 格式,多个标签之间用空格分隔
mysql.bytes_received 1287333217 327810227706 schema=foo host=db1
mysql.bytes_sent 1287333217 6604859181710 schema=foo host=db1
mysql.bytes_received 1287333232 327812421706 schema=foo host=db1
mysql.bytes_sent 1287333232 6604901075387 schema=foo host=db1
mysql.bytes_received 1287333321 340899533915 schema=foo host=db2
mysql.bytes_sent 1287333321 5506469130707 schema=foo host=db2
Influx 指标格式
Influx 指标格式分 4 个部分: measurement,tag_set field_set timestamp
- tag_set:可选 , tag_set 与 measurement 之间用逗号分开
- 其他各个部分用空格分开
mesurement,labelkey1=labelval1,labelkey2=labelval2 field1=1.2,field2=2.3 timestamp
例子:
weather,location=us-midwest temperature=82 1465839830100400200
| -------------------- -------------- |
| | | |
| | | |
+-----------+--------+-+---------+-+---------+
|measurement|,tag_set| |field_set| |timestamp|
+-----------+--------+-+---------+-+---------+
将 OpenTSDB 的指标数据改成 Influx 格式
- 时间戳的单位:纳秒,标签重复度低,field 越多,越能节省更多带宽
mysql,schema=foo,host=db1 bytes_received=327810227706,bytes_sent=6604859181710 1287333217000000000
mysql,schema=foo,host=db1 bytes_received=327812421706,bytes_sent=6604901075387 1287333232000000000
mysql,schema=foo,host=db2 bytes_received=340899533915,bytes_sent=5506469130707 1287333321000000000
指标类型
Prometheus 生态支持的 4 种数据类型 : Gauge、Counter、Histogram、Summary
Gauge
测量值类型: 可大可小,可正可负,一般是当前值
- 如:房间里的人数、队列积压的消息数、今年公司的收入和净利润
Counter
单调递增的值
- 如:网卡接收到的所有流量包的数量。每收到一个包,就加 1
- 当操作系统重启, Prometheus 当感知到重置时,会将新采集的值 + 原来值进行计算
Histogram
直方图类型 (Histogram):用于描述数据分布
- 根据数据的 value 范围,规划多个桶(bucket),把数据值放入不同的桶来统计
典型场景: 监控延迟数据,计算 90 分位、99 分位的值
- 分位值: 把一批数据从小到大排序,然后取 X% 位置的数据,90 分位: 数据第 90% 位置的值
例子:服务 service1,它的接口延迟最小在一两百毫秒,最大在 1 秒,当超过 3 秒,就认为该系统不正常
- 规划 4 个桶,设有 1000 个请求
- 延迟 < 200 毫秒,有 600 个请求落到该区间
- 延迟 < 1 秒,有 850 个请求落到该区间,说明 > 200 毫秒的有 250 个请求
- 延迟 < 3 秒,有 1000 个请求落到该区间,说明 > 1 秒的有 150 个请求
- 延迟 < 正无穷,也就是总量,有 1000 个请求落到该区间,说明没有 > 3 秒的请求
当90 分位值 (第 900 个请求)落在第 3 个桶 (延迟小于 3 秒)
- 结论: 90 分位的延迟大小是 1~3 秒之间

histogram_quantile 计算逻辑:
- 认为各个桶里的样本数据是均匀分布的
- 当第三个桶的总请求 150 ,延迟区间在 [1 秒,3 秒]
- 当总量的第 900 个请求,是该桶里的第 50 个请求
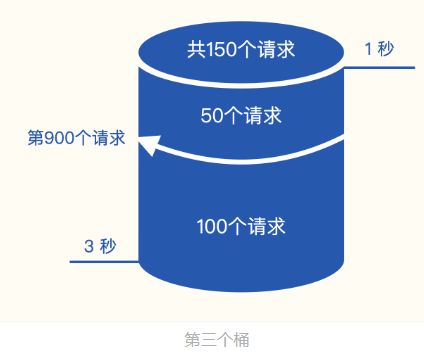
最终 90 分位的延迟数据计算方法:
(3−1)×(50÷150) + 1 = 1.67秒
Summary
Summary 解决痛点:Histogram 计算成千上万个接口的分位值延迟数据,还是很耗资源
Summary: 在客户端计算分位值,再把计算结果推给服务端存储,展示时,直接查询,不用再计算,性能大幅提升
告警
告警收敛 : 当出现故障,可能会瞬间产生很多告警事件 (告警风暴),就要想办法让告警事件变少
告警闭环 : 告警要认领,期间可能会升级通知