Python 字符串类型 - 详细
Python 字符串类型
Python 不支持单字符类型,一个字符在 Python 中,也是作为一个字符串使用。
一. 访问字符串的值
可以通过索引和切片来访问字符串的值
mystr = 'hello world!'
print(mystr[3]) # 通过下标来访问
print(mystr[2:6:2]) # 通过切片来访问
运行效果:
![]()
二. python 转义字符
Python 转义字符:
| 转义字符 | 描述 |
|---|---|
| \ | (在行尾时) 续行符 |
| \ \ | 反斜杠符号 |
| \’ | 单引号 |
| ‘’ | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行LF (line feed),另起一新行,光标在新行的开头。 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车CR (carriage return),光标回到一当前行的开头。(光标目前所在的行为当前行) |
| \f | 换页 |
| \yyy | 八进制数,y 代表 0~7 的字符,其实yyy就是字符对应的ASCII码,具体可以参考"ASCII码表"。例如:\012 代表换行。 |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,具体数值可以参考"ASCII码表"例如:\x0a 代表换行 |
| \other | 其它的字符以普通格式输出 |
注意:网上关于八进制数\yyy,有些表述是有问题的。他们写的内容是【"\oyy" 代表八进制数,其中yy代表的字符,例如:\o12代表换行】。这样的写法,在Python 2.7,Python3目前现有的版本中都是错的。
var1 = 'abcdeffghijklmn'
print(var1[:6]+'qwer') # 获取字符串的值
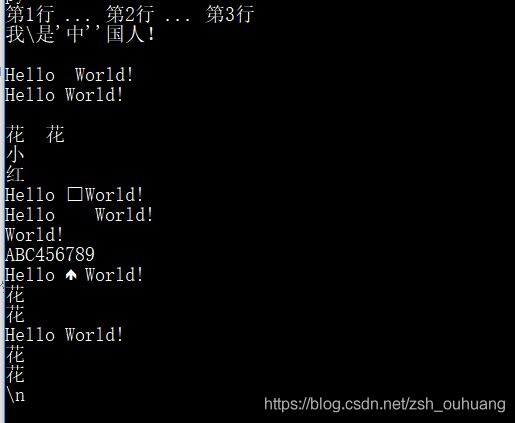
print("第1行 \
... 第2行 \
... 第3行") # \为续行符
print("我\\是\'中\''国人!") # 反斜杠、单引号、双引号
print("\a") #响铃, 执行后电脑有响声。
print("Hello World!") # 单词间空了两格 Hello World!
print("Hello \b World!")# 加上退格符后,只会显示一格
print("\000") # \000 为空
print("花\000\000花")
print("小\n红") # 换行
print("Hello \v World!") #纵向制表符
#由于很多控制台没法显示纵向制表符,只能显示 '口' 这样的字符。
print("Hello \t World!") #横向制表符,相当于一格tab键
print("Hello\rWorld!") #回车 World!
print("123456789\rABC") # 回车:光标回到一当前行的开头。(光标目前所在的行为当前行)
print("Hello \f World!") # 换页
#由于很多控制台没法显示纵向制表符,只能显示 '向上的箭头' 这样的字符。
print("花\012花") # \yyy 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。
print("\110\145\154\154\157\40\127\157\162\154\144\41") #八进制数 Hello World!
print("花\x0a花") # \xyy 十六进制数,yy代表的字符,例如:\x0a 代表换行
print('\\n') # 其他字符
运行效果:
三. Python 字符串格式化
Python的字符串格式化有两种方式:%格式符方式,format方式
方式1:%格式符方式
%格式符方式: %[(name)][flags][width].[precision]typecode
参数:
- (name) 可选,用于选择指定的key
- flags 可选,可供选择的值有:
| 符号 | 含义 |
|---|---|
| + | 右对齐;正数前加正号,负数前加负号; |
| - | 左对齐;正数前无符号,负数前加负号; |
| 0 | 右对齐;正数前无符号,负数前加负号;用0填充空白处 |
| 空格 | 右对齐;正数前加空格,负数前加负号; |
-
width 可选,占有宽度,小数点算一位;
-
precision 可选,小数点后保留的位数
-
typecode 必选:
s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置,字符串没有引号 r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置,字符串有引号 c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置 o,将整数转换成八进制表示,并将其格式化到指定位置 x,将整数转换成十六进制表示,并将其格式化到指定位置(小写) X,将整数转换成十六进制表示,并将其格式化到指定位置(大写) d,将整数、浮点数转换成十进制表示,并将其格式化到指定位置 e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e) E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E) f,将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位) F,同上 g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;) G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;) %,当字符串中存在格式化标志时,需要用 %%表示一个百分号 %u, 格式化无符号整型 %p, 用十六进制数格式化变量的地址 注:Python中百分号格式化,是不存在自动将整数转换成二进制表示的方式
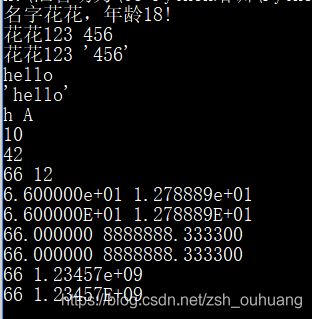
print("名字%(name)s,年龄%(age)d!" %{'name':'花花','age':18})
print('花花%s' %123, '%s' %'456')
print('花花%r' %123, '%r' %'456')
print('%s' %'hello')
print('%r' %'hello')
print('%c' %'h','%c' %65)
print('%o' %8)
print('%x' %66)
print('%d' %66,'%d' %12.7)
print('%e' %66,'%e' %12.7888888666)
print('%E' %66,'%E' %12.78888888888)
print('%f' %66,'%f' %8888888.3333)
print('%F' %66,'%10F' %8888888.3333)
print('%g' %66,'%10g' %1234567889)
print('%G' %66,'%10G' %1234567890)
运行效果:
方法2:format方式
format方式:
数字格式的定义以 ‘:’ 号开始。碰到了’:'字符,就知道要定义一个数字的显示格式了。
格式的定义顺序为::[fill][align][sign][#][0][width][,][.precision][type]
-
fill 【可选】空白处填充的字符(只能取一个字符)
-
align 【可选】对齐方式(需配合width使用)
<,内容左对齐
>,内容右对齐(默认)
=,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
^,内容居中 -
sign 【可选】有无符号数字
+,正号加正,负号加负;
-,正号不变,负号加负;
空格 ,正号空格,负号加负; -
‘#’ 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
-
‘,’ 【可选】为数字添加分隔符,如:1,000,000
-
width 【可选】格式化位所占宽度
-
.precision【可选】小数位保留精度
-
type 【可选】格式化类型
<1> 传入” 字符串类型 “的参数 s,格式化字符串类型数据 空白,未指定类型,则默认是None,同s <2> 传入“ 整数类型 ”的参数 b,将10进制整数自动转换成2进制表示,然后格式化; c,将10进制整数自动转换为其对应的unicode字符; d,十进制整数; o,将10进制整数自动转换成8进制表示,然后格式化; x,将10进制整数自动转换成16进制表示,然后格式化(加上#,显示小写x); X,将10进制整数自动转换成16进制表示,然后格式化(加上#,显示大写X); <3> 传入“ 浮点型或小数类型 ”的参数; e, 转换为科学计数法(小写e)表示,然后格式化; E, 转换为科学计数法(大写E)表示,然后格式化; f ,转换为浮点型(默认小数点后保留6位)表示,然后格式化; F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化; g, 自动在e和f中切换; G, 自动在E和F中切换; %, 显示百分比(把数乘以100,显示百分比,默认显示小数点后6位);
代码1:
print('{},你好!'.format('花花'))
print('{:s},今年{:}岁!'.format('花花','12'))
print('{:s},今年{:c}岁!'.format('花花',65))
运行效果:
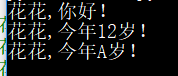
代码2:
print('{:s},今年{:b}岁!'.format('花花',65)) #b,将10进制整数,转换成2进制
print('{:s},今年{:o}岁!'.format('花花',65)) #o,将10进制整数,转换成8进制表示
print('{:s},今年{:d}岁!'.format('花花',65)) #d,十进制整数;
print('{:s},今年{:x}岁!'.format('花花',65)) #x,将10进制整数,转换成16进制表示
print('{:s},今年{:X}岁!'.format('花花',65)) #X,将10进制整数,转换成16进制表示
运行效果:

代码3:
print("15的 二进制{:b},八进制{:o},十进制{:d},十六进制{:x},十六进制{:X}".format(15, 15, 15, 15, 15))
print("65的 二进制{:#b},八进制{:#o},十进制{:#d},十六进制{:#x},十六进制{:#X}".format(65, 65, 65, 65, 65)) # 对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
运行效果:
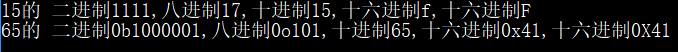
代码4:
print("{3:b},{2:o},{0:d},{1:x},{0:X}".format(66,77,88,3)) # :前面是索引
print("{num1:b},{num2:o},{num2:d},{num2:x},{num1:X}".format(num1=66,num2=88)) # :前面是变量名
运行效果:

代码5:
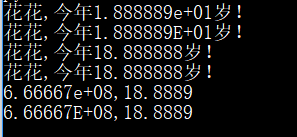
print('{:s},今年{:e}岁!'.format('花花',18.888888))
print('{:s},今年{:E}岁!'.format('花花',18.888888))
print('{:s},今年{:f}岁!'.format('花花',18.888888))
print('{:s},今年{:F}岁!'.format('花花',18.888888))
print('{:g},{:g}'.format(666666666,18.888888))
print('{:G},{:G}'.format(666666666,18.888888))
运行效果:
代码6:
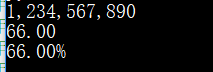
print('{:,}'.format(1234567890)) #,号为数字添加分隔符,如:1,234,567,890
print('{:.2f}'.format(66))
print('{:.2%}'.format(0.66)) #% 显示百分比(默认显示小数点后6位)
运行效果:
代码7:
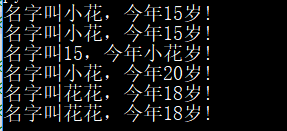
print('名字叫{2},今年{1}岁!'.format('花花',15,'小花',18,'红红',20))
print('名字叫{2},今年{1}岁!'.format(*['花花',15,'小花',18,'红红',20])) # * 解包列表
print('名字叫{0[1]},今年{0[2]}岁!'.format(['花花',15,'小花',18,'红红',20]))
print('名字叫{1[1]},今年{0[2]}岁!'.format([15,18,20],['花花','小花','红红']))
print('名字叫{name},今年{age}岁!'.format(name='花花',age=18))
print('名字叫{name},今年{age}岁!'.format(**{'name':'花花','age':18})) # **解包字典
运行效果:
代码8:
print('{:15f}'.format(66))
print('{:015f}'.format(66))
print('{:#015o}'.format(66))
运行效果:

代码9:
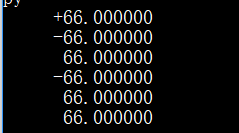
print('{:+15f}'.format(66))
print('{:+15f}'.format(-66))
print('{:-15f}'.format(66))
print('{:-15f}'.format(-66))
print('{:15f}'.format(66))
print('{: 15f}'.format(66))
运行效果:
代码10:
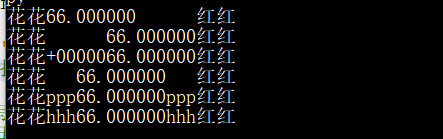
print('花花{:<15f}红红'.format(66)) #<,内容左对齐
print('花花{:>15f}红红'.format(66)) #>,内容右对齐(默认)
print('花花{:=+015f}红红'.format(66)) #=,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
print('花花{:^15f}红红'.format(66)) #^,内容居中
print('花花{:p^15f}红红'.format(66)) #fill的值取z,【可选】空白处用字符p来填充
print('花花{:h^015f}红红'.format(66)) #花花 hhh66.000000hhh 红红,0不在起作用了
运行效果:
四. Python 字符串的内建函数
- string.capitalize() 把字符串的第一个字符大写,返回一个首字母大写的字符串。
注意:
1、首字符会转换成大写,其余字符会转换成小写。
2、首字符如果是非字母,首字母不会转换成大写,其余字符会转换成小写。
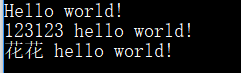
mystr = 'hELLo world!'
print(mystr.capitalize())
print('123123 hELLo WORLD!'.capitalize())
print('花花 hELLo WORLD!'.capitalize())
运行效果:
2. string.center(width[, fillchar]) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
参数
width – 字符串的总宽度。
fillchar – 填充字符。默认是空格,只能是单个字符;如果 width 小于字符串宽度直接返回字符串,不会截断:
返回值:返回一个指定的宽度 width 居中的字符串,如果 width 小于字符串宽度直接返回字符串,否则使用 fillchar 去填充。
print('huahua'.center(4))
print('huahua'.center(10,'@'))
运行效果:

- string.count(str, start=0, end=len(string)) 返回 str 在 string 里面出现的次数,如果指定 start 或者 end ,则返回指定范围内 str 出现的次数。
参数:
str – 搜索的子字符串
start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
返回值:该方法返回子字符串在字符串中出现的次数。
print('huahua uu qq uu'.count('u')) # 返回u在前面字符串中的次数为6次。
print('huahua uu qq uu'.count('uu')) # 返回uu在前面字符串中的次数为2次。
print('huahua uu qq uu'.count('u',3,30))
print('huahua uu qq uu'.count('u',3,-30))
运行效果:
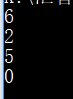
- encode 编码;decode 解码
str.encode(encoding=‘UTF-8’,errors=‘strict’) 用指定的编码格式编码字符串。
参数:
encoding – 要使用的编码,如: UTF-8。
errors – 设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个UnicodeError。 其他可能得值有 ‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。
返回值:该方法返回编码后的字符串,它是一个 bytes 对象。
bytes.decode(encoding=“utf-8”, errors=“strict”) 以指定的编码格式解码 bytes 对象。默认编码为 ‘utf-8’。
Python3 的字符串中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。
参数:
encoding – 要使用的编码,如"UTF-8"。
errors – 设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个UnicodeError。 其他可能得值有 ‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。
返回值:该方法返回解码后的字符串。
str1 = '123 huahua 花花'.encode('GBK')
str2 = '123 huahua 花花'.encode('UTF-8')
print("GBK 编码:",str1)
print("UTF-8 编码:",str2)
str3 = str1.decode('GBK','strict')
print("GBK 解码:",str3)
str4 = str2.decode('UTF-8','strict')
print("UTF-8 解码:",str4)
运行结果:

- startswith & endswith 字符串以指定字符开头/结尾
str.startswith(substr, beg=0,end=len(string)); 检查字符串是否是以指定子字符串 substr 开头,如果是则返回 True,否则返回 False。参数 beg 和 end 指定范围内检查。
参数:
str – 检测的字符串。
substr – 指定的子字符串。
beg – 检测的起始位置,包含。
end – 检测的结束位置,不包含。
返回值:如果检测到字符串则返回True,否则返回False。
str1 = 'hua uhello hua world hua'
str2 = 'hua'
print(str1.startswith(str2))
print(str1.startswith('u',4,8))
运行结果:
![]()
str.endswith(suffix[, start[, end]]) 检查字符串是否以 suffix 结束
参数
suffix – 该参数可以是一个字符串或者是一个元素。
start – 字符串中的开始位置,包含。
end – 字符中结束位置,不包含。
返回值:如果字符串含有指定的后缀返回 True,否则返回 False。
str1 = 'hello hua world hua'
str2 = 'hua'
print(str1.endswith(str2))
print(str1.endswith('u',4,8))
运行结果:
![]()
- string.expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。
expandtabs() 方法把字符串中的 tab 符号 \t 转为空格,tab 符号 \t 默认的空格数是 8,
在第 0、8、16…等处给出制表符位置,如果当前位置到开始位置或上一个制表符位置的字符数不足 8 的倍数则以空格代替。
参数
tabsize – 指定转换字符串中的 tab 符号 \t 转为空格的字符数。
返回值:该方法返回字符串中的 tab 符号 \t 转为空格后生成的新字符串。
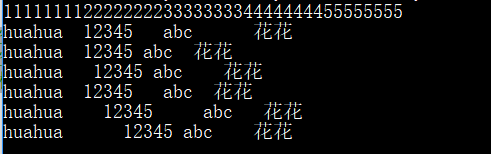
str1 = "huahua\t12345\tabc\t"
print('1111111122222222333333334444444455555555')
print(str1.expandtabs(),'花花') # 默认8个空格
# huahua 有 6 个字符,后面的 \t 填充 2 个空格
# 12345 有 5 个字符,后面的 \t 填充 3 个空格
# abc 有 3 个字符,后面的 \t 填充 5 个空格
print(str1.expandtabs(2),'花花') # \t代表 2 个空格
# huahua 有 6 个字符,刚好是 2 的 3 倍,后面的 \t 填充 2 个空格
# 12345 有 5 个字符,不是 2 的倍数,后面的 \t 填充 1 个空格
# abc 有 3 个字符,不是 2 的倍数,后面的 \t 填充 1 个空格
print(str1.expandtabs(3),'花花') # \t代表 3 个空格
# huahua 有 6 个字符,刚好是 3 的 2 倍,后面的 \t 填充 3 个空格
# 12345 有 5 个字符,不是 3 的倍数,后面的 \t 填充 1 个空格
# abc 有 3 个字符,是 3 的倍数,后面的 \t 填充 3 个空格
print(str1.expandtabs(4),'花花') # \t代表 4 个空格
# huahua 有 6 个字符,不是 4 的倍数,后面的 \t 填充 2 个空格
# 12345 有 5 个字符,不是 4 的倍数,后面的 \t 填充 3 个空格
# abc 有 3 个字符,不是 4 的倍数,后面的 \t 填充 1 个空格
print(str1.expandtabs(5),'花花')
print(str1.expandtabs(6),'花花')
运行结果:
- find & rfind 查找子字符串的下标,找不到返回-1
string.find(str, beg=0, end=len(string)) 检测字符串 string 中第一次出现的子字符串 str
参数:
str – 指定检索的字符串
beg – 开始索引,默认为0。 包含
end – 结束索引,默认为字符串的长度。不包含
返回值:如果包含子字符串返回第一个出现的索引值,不包含则返回-1。
相似的函数还有:
string.rfind(str, beg=0,end=len(string)) 返回字符串最后一次出现的位置,如果没有匹配项则返回-1。
print('bcadefaghijk'.find('a')) # 查找开头
print('bcadefaghijk'.find('a',3,7))
print('bcadefaghijk'.find('zz'))
print('bcadefaghijak'.rfind('a',3,7)) #查找结尾
运行结果:
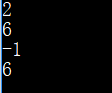
- index & rindex 查找子字符串的下标,找不到报错。
tring.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果 str 不在 string中会报一个异常.
参数
str – 指定检索的字符串
beg – 开始索引,默认为0。 包含
end – 结束索引,默认为字符串的长度。不包含
返回值:如果包含子字符串返回开始的索引值,不包含则抛出异常。
相似的函数还有:
str.rindex(str, beg=0 end=len(string)) 返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常。
print('bcadefaghijk'.index('a'))
print('bcadefaghijk'.index('a',3,7))
#print('bcadefaghijk'.index('zz')) # 没找到则抛出异常
print('bcadefaaghaaijk'.rindex('aa',3,90))
运行结果:
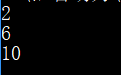
- string.isalnum() 检测字符串是否由字母和数字组成。如果 string 至少有一个字符并且所有字符都是字母或数字,则返回 True,否则返回 False
无参数,返回值:如果字符串都是由字母和数字组成,则返回 True,否则返回 False
print ("huahua123".isalnum())
print ("huahua_123".isalnum())
print ("huahua123花花".isalnum()) # 字符串里面有汉字的话,也返回 True
运行结果:
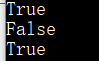
- string.isalpha() 检测字符串是否只由字母或文字组成。如果 string 至少有一个字符并且所有字符都是字母,则返回 True,否则返回 False
无参数,返回值:如果字符串都是由字母和文字组成,则返回 True,否则返回 False.
print ("huahua花花".isalpha()) # 汉字也会返回 True
print ("huahua_123".isalpha())
print ("1234huahua".isalpha())
运行结果:
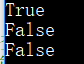
- string.isdecimal() 检测字符串是否只由数字组成。检查字符串是否只包含十进制字符。这种方法只存在于unicode对象。
注意:定义一个十进制字符串,只需要在字符串前添加 ‘u’ 前缀即可。
无参数,返回值:如果字符串只包含十进制数字,则返回 True ,否则返回 False。
print ("1234".isdecimal())
print ("huahua123".isdecimal())
print ("123.4".isdecimal())
运行结果:
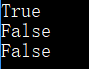
- string.isdigit() 检测字符串是否只由数字组成。无参数,如果 string 只包含数字,则返回 True 否则返回 False.
注意:isdigit() 检测字符串是否只包含数字(即不接受其他一切非 [0-9] 元素)。
print('1234'.isdigit())
print('huahua1234'.isdigit())
print("123.4".isdigit())
运行结果:
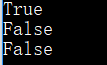
- string.isnumeric() 如果 string 中只包含数字字符,则返回True,否则返回 False
注意:isnumeric() 方法检测字符串是否只由数字组成,数字可以是: Unicode 数字,全角数字(双字节),罗马数字,汉字数字。指数类似 ² 与分数类似 ½ 也属于数字。
print('10'.isnumeric())
print('10.1'.isnumeric())
print('½'.isnumeric())
print('²3455'.isnumeric())
print('\u00B23455'.isnumeric())
print("\u0030".isnumeric()) #unicode for 0
print("\u00B2".isnumeric()) #unicode for ²
运行结果:
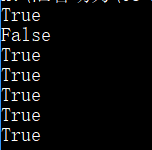
- string.isspace() 检测字符串是否只由空白字符组成。如果 string 中只包含空格,则返回 True,否则返回 False.
空白符包含:空格、制表符(\t)、换行(\n)、回车(\r)等。 空串不算空白符。
print(' '.isspace())
print('hua hua '.isspace())
print('\t'.isspace())
print(''.isspace())
运行结果:

- istitle 判断字符串首字母是否大写 && title 把字符串首字母大写。
string.istitle() 检测字符串中,所有的单词拼写首字母是否为大写,且其他字母为小写。
如果 string 是标题化的(见 title())则返回 True,否则返回 False
str.title(); 返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写
无参数,返回值:返回"标题化"的字符串
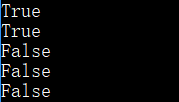
print('Hello World'.istitle())
print('Hello World 123'.istitle())
print('hello World'.istitle())
print('HELLO World'.istitle())
print('HRllo World'.istitle())
运行结果:
print('my name is honghong!'.title())
print('my 3na3me !i!s 红hong红hong!'.title()) #非字母后的第一个字母将转换为大写字母
运行结果:

- string.join(sequence) 将序列中的元素以指定的字符连接生成一个新的字符串。
以 string 作为分隔符,将 sequence 中所有的元素(的字符串表示)合并为一个新的字符串
语法:‘连接符’.join(序列)
参数:sequence – 要连接的元素序列。
返回值:返回生成的新字符串。
print('@'.join('hello'))
print('!'.join(['1','2','3','4']))
print('*'.join({'hello':12,'age':1})) # 针对字典,只能取对应的值
运行结果:
- str.split(str="", num=string.count(str)) 将字符串按照指定的字符进行分割,分割num次。返回列表。
参数:
str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num – 分割次数。默认为 -1, 即分隔所有。
返回值:返回分割后的字符串列表。
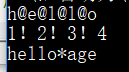
print(mystr.split()) #以空白字符为分隔符
print(mystr.split('*')) #以'*'为分隔符
print(mystr.split('*',1)) #以'*'为分隔符,分割1次
运行结果;
- str.splitlines([keepends]) 按照行(’\r’, ‘\r\n’, ‘\n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends = False,不包含换行符,如果为 True,则保留换行符。
参数:
keepends – 在输出结果里是否去掉换行符(’\r’, ‘\r\n’, \n’),默认为 False,不包含换行符,如果为 True,则保留换行符。
返回值:返回一个包含各行作为元素的列表。
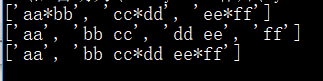
print('ab c\n\nde fg\rkl\r\nhuahua\trr'.splitlines()) #['ab c', '', 'de fg', 'kl', 'huahua\trr']
print('ab c\n\nde fg\rkl\r\nhuahua\trr'.splitlines(True)) #['ab c\n', '\n', 'de fg\r', 'kl\r\n', 'huahua\trr']
运行结果:

- ljust & rjust 填充新字符
string.ljust(width[, fillchar]) 返回一个原字符串左对齐,并使用空格填充至指定长度 width 的新字符串。
如果指定的长度小于原字符串的长度,则返回原字符串。
参数:
width – 指定字符串长度。
fillchar – 填充字符,默认为空格。
返回值:返回一个新字符串。如果指定的长度小于原字符串的长度,则返回原字符串。
print('huahua'.ljust(10))
print('huahua'.ljust(10,'*'))
运行结果:
![]()
rjust(width,[, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串
参数:
width – 指定填充指定字符后中字符串的总长度.
fillchar – 填充的字符,默认为空格。
返回值:返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串
print ("huahua123!!!".rjust(20, '*')) #********huahua123!!!
print ("huahua".rjust(10, '*'),'18'.rjust(6,'!'))
运行结果:
![]()
- str.zfill(width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0。
参数:width – 指定字符串的长度。原字符串右对齐,前面填充0。
返回值:返回指定长度的字符串。
注:zfill(width) 作用同 rjust(width,“0”)
print('huahua'.zfill(3)) # 原样显示
print('huahua'.zfill(10))
print('huahua'.rjust(10,"0")) # 作用相当于:'huahua'.zfill(10)
运行结果:

- islower & isupper 检查字符串是否全是小写/大写
string.islower() 检测字符串是否由小写字母组成。
无参数,如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
注意:str.islower() 检测字符串是否不包含大写字母。
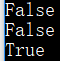
print('huahua123'.islower())
print('huahua123花花#!'.islower())# True
print('HUAHUA123'.islower())
print('hua 123 HUA'.islower())
print('\t'.islower()) #False
运行结果:

string.isupper() 检测字符串中所有的字母是否都为大写。如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
print('huahua123'.isupper())
print('Huahua123'.isupper())
print('HUAHUA123花花#!'.isupper())
运行结果:
- lower & upper 把字符串全部转换为小写/大写
string.lower() 把 string 中所有大写字符转换为小写. 返回转换后的新字符串。
print('HELLO World !123'.lower())
运行结果:
hello world !123
string.upper() 把 string 中所有大写字符转换为大写. 返回转换后的新字符串。
print('HELLO World !123'.upper())
运行结果:
HELLO WORLD !123
- str.swapcase(); 用于对字符串的大小写字母进行转换。
无参数,返回值:返回大小写字母转换后生成的新字符串。
print('HELLO World !123'.swapcase())
运行结果:
hello wORLD !123
- lstrip && rstrip && strip 去掉字符串左边、右边、两边的空白或指定字符
str.lstrip([chars]) 去掉字符串左边的空格或指定字符。 参数:chars – 指定去掉的字符。返回值:返回截掉字符串左边的空格或指定字符后生成的新字符串
注意:从左到右移除字符串的指定字符:
无字符集参数或为 None 时,移除空格,
str 移除所有属于字符集子串的字符,一旦不属于则停止移除,并返回字符串副本。
相似的函数还有:
str.rstrip([chars]) 去掉字符串右边的空格或指定字符。
str.strip([chars]) 去掉字符串两边的空格或指定字符。该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
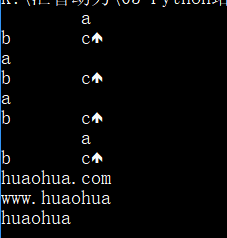
mystr = '\ta\nb\tc\f'
print(mystr)
print(mystr.lstrip())
print(mystr.lstrip(None))
print('\ta\nb\tc\fqq'.rstrip('qq'))
print('www.huaohua.com'.lstrip('cmowz.'))
print('www.huaohua.com'.rstrip('cmowz.'))
print('www.huaohua.com'.strip('cmowz.'))
运行结果:
- maketrans 创建字符映射的转换表
string.maketrans(intab, outtab]) 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串,表示转换的目标。
两个字符串的长度必须相同,为一一对应的关系。
注:Python3.4 以后已经没有 string.maketrans() 了,取而代之的是内建函数: bytearray.maketrans()、bytes.maketrans()、str.maketrans() 。
参数:
intab – 字符串中要替代的字符组成的字符串。
outtab – 相应的映射字符的字符串。
返回值:返回字符串转换后生成的新字符串。
str1 = "abcedf"
str2 = "123456"
result = str.maketrans(str1, str2)
print(result)
str = "aaeehhcc!"
print (str.translate(result)) # translate的用法下一个函数介绍。
运行结果:

- translate 转换字符
语法:根据参数table给出的表(包含 256 个字符)转换字符串的字符,要过滤掉的字符放到 deletechars 参数中。
str.translate(table)
bytes.translate(table[, delete])
bytearray.translate(table[, delete])
参数:
table – 翻译表,翻译表是通过 maketrans() 方法转换而来。
deletechars – 字符串中要过滤的字符列表。
返回值:返回翻译后的字符串,若给出了 delete 参数,则将原来的bytes中的属于delete的字符删除,剩下的字符要按照table中给出的映射来进行映射 。
1> 一个参数,该参数必须为字典
d = {'a':'1','b':'2','c':'3','d':'4','e':'5','s':'6'}
result = str.maketrans(d) # 制作翻译表
print('i like you aa'.translate(result)) # 翻译
运行结果:
i lik5 you 11
2> 两个参数 x 和 y,x、y 必须是长度相等的字符串,并且 x 中每个字符映射到 y 中相同位置的字符.
str1 = 'abcdefs'
str2 = '1234567'
result = str.maketrans(str1,str2)
print('loveyou,haha'.translate(result))
运行结果:
lov5you,h1h1
3> 三个参数 x、y、z,第三个参数 z 必须是字符串,其字符将被映射为 None,即删除该字符;
如果 z 中字符与 x 中字符重复,该重复的字符在最终结果中还是会被删除。
也就是无论是否重复,只要有第三个参数 z,z 中的字符都会被删除。
str1 = 'abcdefs'
str2 ='1234567'
str3 ='ot'
result = str.maketrans(str1,str2,str3)
print('she love you! t a'.translate(result)) # 在字符串中'she love you! t a',带有str3 变量中的字符,全部被去掉。
运行结果:
7h5 lv5 yu! 1
4> 过滤掉的字符 o
制作翻译表:把小写字母转为大写字母
bytes_tabtrans = bytes.maketrans(b'abcdefghijklmnopqrstuvwxyz', b'ABCDEFGHIJKLMNOPQRSTUVWXYZ')
转换为大写,并删除字母o
print(b'hello ou mygod maita'.translate(bytes_tabtrans, b'o'))
运行结果:
b’HELL U MYGD MAITA’
maketrans 的扩展:
str 类型的 translate() 函数只接受一个参数,没有原文中的第二个 deletechars 参数。bytearray, bytes 和 str 三种对象的 translate() 函数原型抄写如下:
bytearray.translate(table, delete=b’’)
bytes.translate(table, delete=b’’)
str.translate(table)
- max && min 求字符串的最大、最小字母
max(str) 返回字符串 str 中最大的字母。
min(str) 返回字符串 str 中最小的字母。
注意:在有大小写的字符串中,返回的是 小写字母的最大值/大写字母的最小值。
print(max('andzbfhZsiS'))
print(min('andbfhsiA'))
运行结果:

- replace 替换字符
string.replace(oldstr1, newstr2, num=string.count(str1)) 将字符串中的 oldstr1 替换成 newstr2 ,替换次数不超过 max 次。
oldstr1 – 将被替换的子字符串。
newstr2 – 新字符串,用于替换old子字符串。
max – 可选字符串, 替换不超过 max 次
返回值:返回替换后的新字符串。
mystr = 'she is huahua,he is huahua'
print(mystr.replace('huahua','honghong'))
print(mystr.replace('huahua','honghong',1))
运行结果:

- string.partition(str) 根据指定的分隔符将字符串进行分割。有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把字符串 string 分成一个3元素的元组
(string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string.
如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。
参数:str 指定的分隔符。
返回值:返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。
print('aa*bb*cc'.partition("*"))# 第2个'*'不会被分割,结果是:('aa', '*', 'bb*cc')
运行结果:
(‘aa’, ‘’, 'bbcc’)
30. str.len(obj) 方法返回对象(字符、列表、元组等)长度或项目个数。
注意:len()是内置函数,返回对象的长度(元素个数)。len()不是字符串类的方法。
实参:可以是序列(如 string、bytes、tuple、list 或 range 等)或集合(如 dictionary、set 或 frozen set 等)。
print(len('hello'))
运行结果: 5