【读后感】Java Concurrency in Practice:8.避免活跃性危险
0. 是无人知的欢喜~
在安全性与活跃性之间存在某种制衡,例如过度的使用加锁,可能导致锁顺序死锁。
当我们想通过线程池以及信号量来限制对资源的使用时,又可能导致资源死锁。
Java应用程序无法从死锁中恢复过来,因此程序设计时需要考虑避免死锁出现的条件。
1.死锁
数据库系统的设计中考虑了检测死锁以及从死锁中恢复。
当数据库服务器检测到一组事务发生死锁时(通过在表示等待关系的有向图中搜索循环),将选择一个牺牲者并放弃这个事务。
JVM在解决死锁问题方面并没有数据库服务那么强大。
死锁问题可能导致服务停止,或者性能降低。
恢复应用程序的唯一方式只能中止并重启它。
与其他的并发危险一样,死锁造成的影响很少很立即显现出来,往往是在最糟糕的时候——高负载。
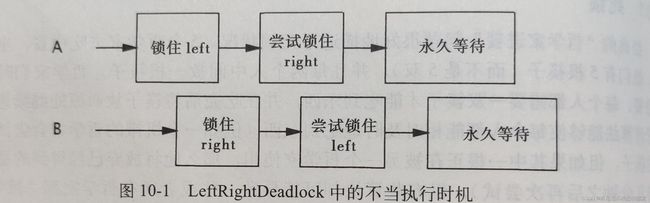
1.1 锁顺序死锁
书中用例LeftRightDeadLock的示例图:
代码片段:

1.2 动态的锁顺序死锁
书中用例"资金从一个账户转账到另一个账户"
代码片段:

解决顺序死锁的思路——在整个应用程序中定义锁的获取顺序
一种简单的方式是借助System.identityHashCode(返回Object.hashCode)
代码片段:


在极少数情况下,两个对象可能拥有相同的散列值,此时必须通过某种任意的方法来决定锁的顺序,
而这可能又会重新引入死锁。为了避免这种情况,可以使用"加时赛"锁。
该锁只允许一个线程以未知的顺序获得这两个锁,从而消除死锁的可能。
但是在散列冲突经常出现的情况下,这个技术可能将成为并发性的一个瓶颈。
另一种改进的方法是借助对象中的一个 唯一的、不可变的、可比的 字段来定制锁的获取顺序
此时就不需要"加时赛"锁
1.3 在协作对象之间发生的死锁
在协作对象之间的锁顺序死锁的代码:


有时候,获取多个锁的操作可能并不那么明显(加锁操作被封装到一个被调的方法中)。
这警示我们:
如果在持有锁的情况下调用某个外部方法,那么将出现活跃性问题。
在这个外部方法中可能会获取其他锁(这可能造成死锁),或者阻塞时间过长。
1.4 开放调用
将1.3的代码重新编写成开放调用的形式:

如果在调用某个方法时不需要持有锁,那么这种调用就被称为开放调用。
在程序中应尽量使用开放调用。与那些在持有锁时调用外部方法的程序相比:
更易于对依赖与开放调用的程序进行死锁分析(因为更容易的找到获取多个锁的代码路径)。
还可以进一步的缩小同步代码块的保护范围,提高可伸缩性
有时候,在重新编写同步代码块以使用开放调用时会产生意想不到结果
因为这会使得某个原子操作变为非原子操作
在很多情况下,使某个操作失去原子性是可以接受的,比如:
在关闭某个服务时,你希望所有正在运行的操作执行完成以后,再释放这些服务占用的资源。
如果在等待操作完成的同时持有该服务的锁,那么将很容易导致死锁;
如果在服务关闭之前就释放服务的锁,则可能导致其他线程开始一些新的操作;
解决方案——通过定制协议来替代加锁机制来防止其他线程进入代码临界区:
当开始关闭服务的时候,在服务中维护一个"关闭"状态来告知其他线程该服务目前不可被操作,已经持有锁
等到关闭操作结束&开放调用完成后,此时,仅有关闭服务的线程才能访问服务的状态
1.5 资源死锁
当多个线程在相同的资源上等待的时候,也会发生死锁(资源死锁)。
另一种资源死锁的形式就是线程饥饿死锁(例如第7章所提及的"在一个任务中提交另一个任务")。
容易发生线程饥饿死锁的往往是有界线程池/资源池+互相依赖的任务。
2. 死锁的避免与诊断
在使用细粒度锁的程序中,可以通过使用一种两阶段策略来检查代码中的死锁:
找出在什么地方将获取多个锁(这也是为啥建议使用开放调用)
对这些地方的代码进行全局分析(可以通过代码审查或者自动化源代码分析工具),从而确保它们获取多个锁的顺序保持一致
2.1 支持定时的锁
还有一项技术可以检测死锁和从死锁中恢复过来——显式使用Lock类中的定时tryLock功能
超时之后,tryLock会返回一个失败信息;
如果超时时限比获取锁的时间要长很多,那么就可以在发生某个意外情况后重新获得控制权;
当定时锁失败的时候,虽然你不能马上知道失败的原因,但是至少可以记录发生的失败以及这次操作的其他信息,并通过一种更平缓的方式来重新启动计算,而不是关闭整个进程;
使用定时一个锁来获取多个锁也能有效地应对死锁问题:如果在获取锁时超时了,那么可以释放锁,然后过一段时间后再次尝试,从而消除了死锁发生的条件,使程序恢复过来。(这项技术只有在同时获取两个锁的时候才有效,如果在嵌套的方法调用中请求多个锁,那么即使你知道已经持有了外层的锁,也无法释放它。)
2.2 通过线程转储信息来分析死锁
虽然防止死锁的主要责任在于你自己,但JVM仍然通过线程转储(Thread Dump)来帮助识别死锁的发生。
线程转储包括各个运行中的线程的:
栈追踪信息
加锁信息
哪些线程持有了锁
哪些栈帧获得了锁
被阻塞的线程正在等待哪一个锁
在生成线程转储之前,JVM将在等待关系图中通过搜索循环来找出死锁
即使没有死锁,通过定期的触发线程转储,可以观察程序的加锁行为
虽然Java6中包含了对显式Lock的线程转储和死锁检测等,但在这些锁上获取的信息要比内置锁的精度低
内置锁与获得它们所在的线程栈帧是相关联的,而显式Lock只与获得它们的线程关联。
3.其他活跃性危险
尽管死锁是最常见的活跃性危险,但是在并发程序中还存在一些其他的活跃性危险
包括:饥饿、丢失信号和活锁等。
活跃性故障是一个非常严重的问题,除了中止应用程序之外没有任何机制可以从中恢复过来。
3.1 饥饿
当线程由于无法访问它所需要的资源而不能继续执行时,就发生了"饥饿"引发饥饿的最常见的资源就是CPU时钟周期。
JVM将Thread API定义的线程优先级映射到操作系统的调度优先级
这种映射是与特定平台相关的
某个操作系统中两个相同/不同的Java优先级可能被映射到不同/相同的优先级
当提高线程优先级时,可能不会引起到任何作用,或者也可能导致饥饿。
通常,我们尽量不要改变线程的优先级,因为会增加平台依赖性并容易导致线程活跃性问题
在大多数并发应用程序中,都可以使用默认的线程优先级
有时候,你能发现某个程序会在一些奇怪的地方调用Thread.sleep/yield
这是因为该程序试图克服线程优先级调整问题或响应性问题
并试图让低优先级的线程执行更多的时间
Thread.yield或者Thread.sleep(0)的语义均未定义
JVM即可以实现为空操作,
也可以视作线程调度的参考:
UNIX系统中,没有要求Thread.yield必须拥有sleep(0)的语义(将当前线程放在其对应优先级队列末尾,并将执行权交给同优先级的其他线程)
尽管,有些JVM是这么实现yield的
3.2 糟糕的响应性
CPU密集型的后台任务:
举一个GUI应用程序的栗子——
把执行时间较长的任务放到后台线程中运行,可以使得应用界面不会失去响应
但是,如果是CPU密集型的后台任务的话,则会对响应性造成影响
因为它们会与事件线程争夺CPU的时钟周期
在这种情况下,可以发挥出线程优先级的作用
除此之外,还有 不良的锁管理:
栗如——
一个线程长时间的占有一个锁
用于迭代一个大容器
并且每个元素都进行计算密集的处理
3.3 活锁
该问题并不会阻塞线程,但是也不能继续执行
因为线程会不断重复相同的操作
并且总会失败
活锁通常发生在处理事务的应用程序中:
一个消息到达一个存在错误的处理器,随后发生事务回滚
当这个消息又被放回到队列开头,如此反复调用…
这种形式的活锁通常是由过度的错误恢复代码造成的,
因为它错误的将不可修复的错误视作可修复的错误
除此之外,多个相互的协作线程也容易出现活锁:
协作线程彼此响应从而修改自己的状态的情况,
并使得任何一个线程都无法继续执行时
(
书上有个好栗子:
两个过于礼貌的人,在一顿礼让之后,都选择走另一条路
当他们的"另一条路"恰好又相同的时候,他们又相遇了…
)
解决方案:
在重试机制中引入随机性
例如:以太协议定义了当两台机器用相同的载波发送数据包并且冲突的时候,
会各自在等待一段随机的时间后重试