ob运维相关
一、oracle和mysql租户
1、查看当前资源剩余
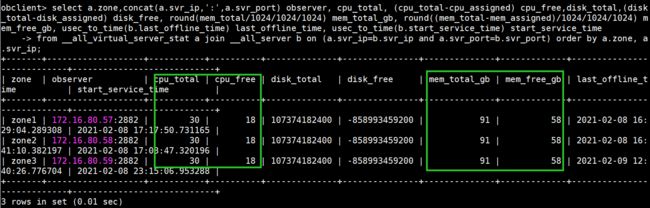
select a.zone,concat(a.svr_ip,':',a.svr_port) observer, cpu_total, (cpu_total-cpu_assigned) cpu_free,disk_total,(disk_total-disk_assigned) disk_free, round(mem_total/1024/1024/1024) mem_total_gb, round((mem_total-mem_assigned)/1024/1024/1024) mem_free_gb, usec_to_time(b.last_offline_time) last_offline_time, usec_to_time(b.start_service_time) start_service_time
from __all_virtual_server_stat a join __all_server b on (a.svr_ip=b.svr_ip and a.svr_port=b.svr_port) order by a.zone, a.svr_ip;
select t1.name resource_pool_name, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb, t2.max_disk_size/1024/1024/1024 ,t2.max_session_num,t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,t4.tenant_id, t4.tenant_name
from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id) join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;

2、创建资源规格模板
资源模板不会占用资源空间
CREATE resource unit mysql_unit_config max_cpu=10, min_cpu=8, max_memory='20G', min_memory='10G', max_iops=10000, min_iops=1000, max_session_num=1000000, max_disk_size='200G';
CREATE resource unit oracle_unit_config max_cpu=10, min_cpu=8, max_memory='20G', min_memory='15G', max_iops=10000, min_iops=1000, max_session_num=1000000, max_disk_size='300G';
select * from __all_unit_config;
3、创建资源池
资源池分配之后,资源才配占用
CREATE resource pool oracle_pool unit = 'oracle_unit_config', unit_num = 1;
CREATE resource pool mysql_pool unit = 'mysql_unit_config', unit_num = 1;
可以修改resource pool的unit
alter resource pool mysql_pool unit='config_mysql_test_restore_zone2_S1_aam';
select * from __all_resource_pool;
4、指定资源池、创建租户
create tenant oracle_test resource_pool_list=('oracle_pool'), primary_zone='RANDOM',comment 'oracle tenant/instance', charset='utf8mb4' set ob_tcp_invited_nodes='%', ob_compatibility_mode='oracle';
oracle租户autocommit是off
create tenant mysql_test resource_pool_list=('mysql_pool'), primary_zone='RANDOM',comment 'mysql tenant/instance', charset='utf8mb4' set ob_tcp_invited_nodes='%', ob_compatibility_mode='mysql';
mysql租户autocommit是on
select * from __all_tenant;
5、再次检查资源占用
select a.zone,concat(a.svr_ip,':',a.svr_port) observer, cpu_total, (cpu_total-cpu_assigned) cpu_free,disk_total,(disk_total-disk_assigned) disk_free, round(mem_total/1024/1024/1024) mem_total_gb, round((mem_total-mem_assigned)/1024/1024/1024) mem_free_gb, usec_to_time(b.last_offline_time) last_offline_time, usec_to_time(b.start_service_time) start_service_time
from __all_virtual_server_stat a join __all_server b on (a.svr_ip=b.svr_ip and a.svr_port=b.svr_port) order by a.zone, a.svr_ip;
select t1.name resource_pool_name, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb, t2.max_disk_size/1024/1024/1024 ,t2.max_session_num,t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,t4.tenant_id, t4.tenant_name
from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id) join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;
SELECT t.tenant_id, a.tenant_name, t.table_name, d.database_name, tg.tablegroup_name , t.part_num , t2.partition_id, t2.ZONE, concat(t2.svr_ip,':',t2.svr_port)
, a.primary_zone , IF(t.locality = '' OR t.locality IS NULL, a.locality, t.locality) AS locality
FROM oceanbase.__all_tenant AS a
JOIN oceanbase.__all_virtual_database AS d ON ( a.tenant_id = d.tenant_id )
JOIN oceanbase.__all_virtual_table AS t ON (t.tenant_id = d.tenant_id AND t.database_id = d.database_id)
JOIN oceanbase.__all_virtual_meta_table t2 ON (t.tenant_id = t2.tenant_id AND (t.table_id=t2.table_id OR t.tablegroup_id=t2.table_id) AND t2.ROLE IN (1) )
LEFT JOIN oceanbase.__all_virtual_tablegroup AS tg ON (t.tenant_id = tg.tenant_id and t.tablegroup_id = tg.tablegroup_id)
WHERE t.table_type IN (3)
ORDER BY t.tenant_id, tg.tablegroup_name, d.database_name, t.table_name, t2.partition_id
;
SELECT zone,svr_ip,COUNT(1) cnt FROM __all_meta_table WHERE tenant_id = 1001 AND role =1 GROUP BY svr_ip ORDER BY zone,cnt desc;
SELECT zone,svr_ip,COUNT(1) cnt FROM __all_virtual_meta_table WHERE tenant_id = 1001 AND role =1 GROUP BY svr_ip;
select table_name,database_name,table_id from gv$table where table_name='PROD_ATTR_VALUE';
select data_size/1024 from __all_virtual_meta_table where table_id='1100611139461642';
6、分别验证mysql租户和oracle租户的登陆
无密码登陆,需要设置密码
mysql -h127.1 -uroot@mysql_test -P2883 -p
alter user root identified by *****;
obclient -h127.1 -usys@oracle_test -P2883 -p
alter user sys identified by *****;
7、删除租户
TENANT 参数代表延迟删除租户,后台线程会进行 GC 动作,租户的信息仍然可以通过内部表查询。
force 参数可以立刻删除租户。
obclient> drop tenant mysql_test;---延迟删除租户
ERROR 1235 (0A000): should drop tenant force, delay drop tenant not supported
obclient> drop tenant mysql_test force; --立即删除租户
Query OK, 0 rows affected (0.02 sec)
drop租户之后需要drop对应的resource pool和unit,否则占用的pool不释放
8、数据库调优
set global ob_sql_work_area_percentage=30; (默认:5)
alter system set merge_thread_count=45; (默认:0)
alter system set minor_freeze_times=500; (默认:10)
二、ob物理备份恢复
ocp管控平台可以备份恢复ob集群,这里不再赘述,也可以用命令行实现备份
目前 OceanBase 数据库支持 OSS 和 NFS 两种备份介质,提供了备份、恢复、管理三大功能。
OceanBase 数据库从 V2.2.52 版本开始支持集群级别的物理备份。物理备份由基线数据、日志归档数据两种数据组成,因此物理备份由日志归档和数据备份两个功能组合而成:
日志归档是指日志数据的自动归档功能,OBServer 会定期将日志数据归档到指定的备份路径。这个动作是全自动的,不需要外部定期触发。
数据备份指的是备份基线数据的功能,该功能分为全量备份和增量备份两种:
全量备份是指备份所有的需要基线的宏块。
增量备份是指备份上一次备份以后新增和修改过的宏块。
OceanBase 数据库支持租户级别的恢复,恢复是基于已有数据的备份重建新租户的过程。用户只需要一个 alter system restore tenant 命令,就可以完成整个恢复过程。恢复过程包括租户系统表和用户表的Restore 和 Recover 过程。
Restore 是将恢复需要的基线数据恢复到目标租户的 OBServer;
Recover 是将基线对应的日志恢复到对应 OBServer;
OceanBase 数据库目前支持手动删除指定的备份和自动过期备份的功能
1、创建nfs服务器,使得ob集群中的所有机器共享备份目录
(1)安装nfs包
yum install nfs-utils
(2)创建nfs文件系统
lvcreate -L 1.5T -n lvobbackup vggfs2
mkfs.xfs /dev/vggfs2/lvobbackup
vi /etc/fstab
/dev/vggfs2/lvobbackup /obbackup xfs defaults 0 0
mount /obbackup
(3)配置/etc/export
root@mgr0[/root]$ cat /etc/exports
/obbackup *(rw,all_squash,anonuid=500,anongid=500)
(4)为nfsnobody 赋权,确保 nfsnobody 有权限访问 exports 中指定的目录
chown nfsnobody:nfsnobody -R /obbackup/
(5)配置 /etc/sysconfig/nfs
root@mgr0[/root]$ grep -v '^#' /etc/sysconfig/nfs
RPCNFSDARGS="-N 2 -N 3 -U"
RPCNFSDCOUNT=8
NFSD_V4_GRACE=90
NFSD_V4_LEASE=90
RPCMOUNTDOPTS=""
STATDARG=""
SMNOTIFYARGS=""
RPCIDMAPDARGS=""
RPCGSSDARGS=""
GSS_USE_PROXY="yes"
BLKMAPDARGS=""
(6)重启nfs服务
systemctl restart nfs-config
systemctl restart nfs-server
2、配置nfs客户端(所有ob服务器)
yum install nfs-utils
mount -o soft 172.16.80.56:/obbackup /obbackup
3、配置backup_dest
alter system set backup_dest='file:///obbackup';
4、日志备份
备份恢复:sys租户才行,oracle租户不能执行
obclient -uroot@sys -p -h172.16.80.57 -P2883
开始日志备份:
ALTER SYSTEM ARCHIVELOG;
停止日志备份:
ALTER SYSTEM NOARCHIVELOG;
查看备份
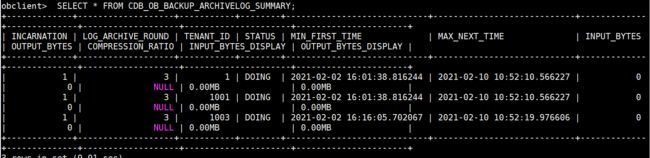
SELECT * FROM CDB_OB_BACKUP_ARCHIVELOG_SUMMARY;
5、全量备份
全量备份前要进行合并
合并:ALTER SYSTEM MAJOR FREEZE;
查看合并进程:
SELECT * FROM __all_zone WHERE name='merge_status';
全量备份:ALTER SYSTEM BACKUP DATABASE;
查看备份进程:
SELECT * FROM CDB_OB_BACKUP_PROGRESS;
增备:SELECT * FROM BACKUP INCREMENTAL DATABASE;
SELECT * FROM CDB_OB_BACKUP_SET_EXPIRED;
6、查看备份策略
备份策略: SHOW PARAMETERS LIKE '%recovery_window%';
auto_delete_expired_backup 或者 ALTER SYSTEM SET DELETE OBSOLETE;
查看全部备份:
SELECT * FROM CDB_OB_BACKUP_SET_DETAILS order by START_TIME,TENANT_ID;
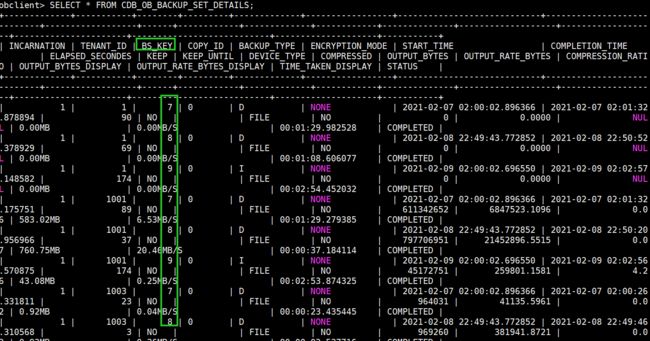
手动执行的备份,ocp可以识别
7、删除备份(根据bs_key)
ALTER SYSTEM DELETE BACKUPSET backup_set_id;
此命令会一起删除全备和下一次全备前的增备,如果没有存在的全备和增备,delete无法执行成功(即要保留一份全量数据)
8、备份目录结构解析
以下是备份功能在备份目的地创建的目录结构以及每个目录下保存的文件类型

9、恢复(只能租户级别的恢复)
备份恢复不可以就地选择tenant恢复(恢复需要指定不一样的tenant名)
新建的tenant会对应的创建一个resource pool和resource unit
CREATE resource unit mysql_unit_config max_cpu=2, min_cpu=1, max_memory='10G', min_memory='5G', max_iops=10000, min_iops=1000, max_session_num=1000000, max_disk_size='200G';
CREATE RESOURCE POOL mysql_pool unit = 'mysql_unit_config', unit_num = 1, zone_list = ('zone1','zone2','zone3');
ALTER SYSTEM RESTORE mysql_1 FROM mysql_test_restore at 'file:///obbackup' UNTIL '2021-02-02 18:00:16' WITH 'backup_cluster_name=obdemo&backup_cluster_id=20210127&pool_list=mysql_pool';
查看资源:
SELECT svr_ip,role, is_restore, COUNT(*) FROM __all_root_table as a, (SELECT value FROM __all_restore_info WHERE name='mysql_1') AS b WHERE a.tenant_id=b.value GROUP BY role, is_restore, svr_ip ORDER BY svr_ip, is_restore;
SELECT svr_ip,role, is_restore, COUNT(*) FROM __all_virtual_meta_table AS a, (SELECT value FROM __all_restore_info WHERE name='mysql_1') AS b WHERE a.tenant_id=b.value GROUP BY role, is_restore, svr_ip ORDER BY svr_ip, is_restore;
SELECT * FROM __all_restore_info;
select a.zone,concat(a.svr_ip,':',a.svr_port) observer, cpu_total, (cpu_total-cpu_assigned) cpu_free,disk_total,(disk_total-disk_assigned) disk_free, round(mem_total/1024/1024/1024) mem_total_gb, round((mem_total-mem_assigned)/1024/1024/1024) mem_free_gb, usec_to_time(b.last_offline_time) last_offline_time, usec_to_time(b.start_service_time) start_service_time
from __all_virtual_server_stat a join __all_server b on (a.svr_ip=b.svr_ip and a.svr_port=b.svr_port) order by a.zone, a.svr_ip;
select t1.name resource_pool_name, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb, t2.max_disk_size/1024/1024/1024 ,t2.max_session_num,t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,t4.tenant_id, t4.tenant_name
from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id) join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;
三、ob回收站机制(oracle租户)
ob的oracle租户回收站默认关闭,需要开启回收站机制,才能实现oracle租户的回收站功能
1、开启回收站
obclient> show variables like 'recyclebin';
+---------------+-------+
| VARIABLE_NAME | VALUE |
+---------------+-------+
| recyclebin | OFF |
+---------------+-------+
1 row in set (0.00 sec)
obclient> set global recyclebin=on;
Query OK, 0 rows affected (0.03 sec)
obclient> exit
Bye
root@mgr1[/root]#obclient -ucc@oracle_test -p -h172.16.80.57 -P2883 -DCC
obclient> show variables like 'recyclebin';
+---------------+-------+
| VARIABLE_NAME | VALUE |
+---------------+-------+
| recyclebin | ON |
+---------------+-------+
1 row in set (0.00 sec)
2、测试drop表之后恢复
obclient> drop table TEST_PARTITION2;
obclient> show recyclebin;
+-------------------------------------+-----------------+-------+------------------------------+
| OBJECT_NAME | ORIGINAL_NAME | TYPE | CREATETIME |
+-------------------------------------+-----------------+-------+------------------------------+
| RECYCLE_$_20210127_1612510989948352 | TEST_PARTITION2 | TABLE | 05-FEB-21 03.43.09.948832 PM |
+-------------------------------------+-----------------+-------+------------------------------+
1 row in set (0.00 sec)
obclient> flashback table TEST_PARTITION2 to before drop;
Query OK, 0 rows affected (0.01 sec)
3、测试truncate表之后恢复
ob中truncate表可以进回收站(将变量ob_enable_truncate_flashback设为on,默认是off)truncate分为create as select、drop两步,所以truncate表会导致table_id改变,从而导致执行计划无效,同样的sql会产生硬解析,这是与oracle不同的地方
show variables like '%truncate%';
set ob_enable_truncate_flashback=on;
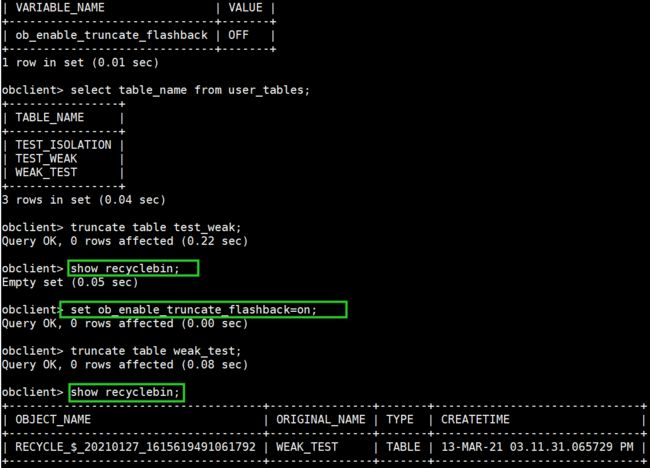
flashback truncate的表
需要将当前已存在的表rename,flashback table WEAK_TEST to before drop;
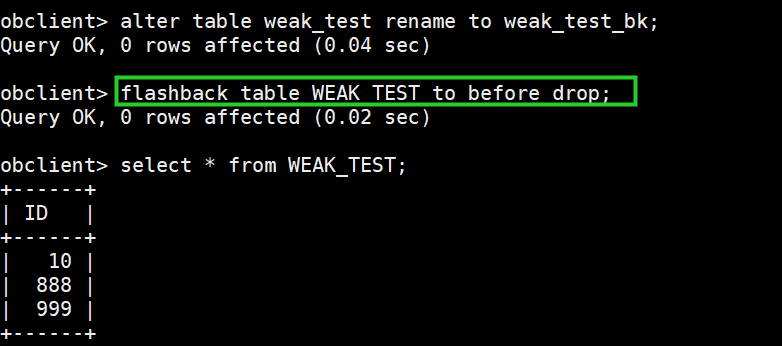
4、回收站清理机制
目前回收站不会自动清理,也就是会越来越大(到3.x版本可能会出参数,设置保留多长时间的回收站数据),不会释放磁盘,可以通过purge recyclebin的方式释放空间(sys用户和普通用户看到的回收站信息一样,可以使用普通用户清空)
sys用户drop一张表,到回收站

同样用cc用户去查也能看到并清理

四、闪回查询
undo_retention=0(默认)的情况下:
undo_retention为0的话,只能保留最新的版本,此时闪回查询的机制是取memtable中的数据,可以查到上次转储后的所有变更,但如果一旦发生转储或者合并,闪回查询就无法查到
undo_retention不为0
则会保留undo_retention内的多版本数据,从而实现闪回(注:ob的undo是逻辑概念,并不存在物理undo表空间)
但是undo_retention设置很大的话,会保留很多历史版本(减少转储的频率),从而导致性能问题
obclient> show variables like '%undo%';
+----------------+-------+
| VARIABLE_NAME | VALUE |
+----------------+-------+
| undo_retention | 0 |
+----------------+-------+
1 row in set (0.00 sec)
(1)插入1000条数据
begin
for i in 60001..61000 loop
insert into test_partition2 values(i);
end loop;
commit;
end;
/
(2)查询当前记录数
obclient> select count(*) from test_partition2;
+----------+
| COUNT(*) |
+----------+
| 4000 |
+----------+
1 row in set (0.01 sec)
(3)闪回查询(基于timestamp usec_to_time())
obclient> select count(*) from test_partition2 as of timestamp to_timestamp('2021-02-05 16:00:00','yyyy-mm-dd hh24:mi:ss');
+----------+
| COUNT(*) |
+----------+
| 3000 |
+----------+
1 row in set (0.01 sec)
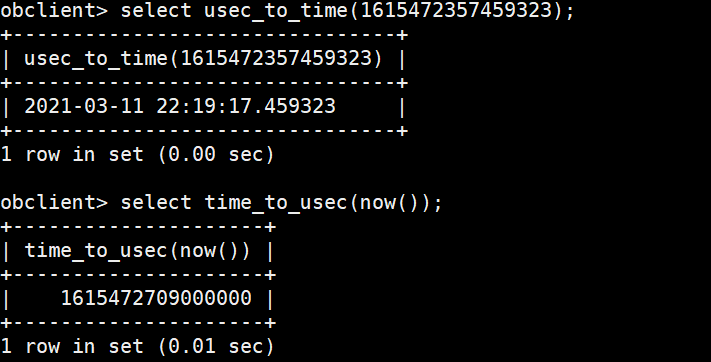
(4)闪回查询(基于scn,ob中的scn号其实就是time_to_usec(),是unix时间戳)
select usec_to_time(1615472357459323);

select time_to_usec(now()); --得到当前scn
select count(*) from test1 as of scn 1615472709000000;
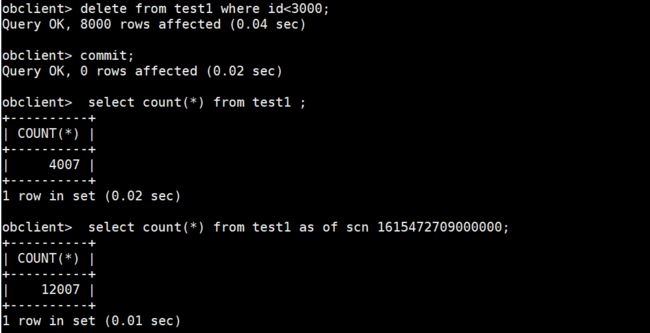
(5)回滚表
obclient> create table test_partition3 as select * from test_partition2 as of timestamp to_timestamp('2021-02-05 16:00:00','yyyy-mm-dd hh24:mi:ss');
Query OK, 3000 rows affected (0.35 sec)
obclient> drop table test_partition2 purge;
Query OK, 0 rows affected (0.02 sec)
obclient> alter table test_partition3 rename to test_partition2;
Query OK, 0 rows affected (0.03 sec)
四、ob分区表、表组、索引、复制表
1、不可见列和约束
CREATE TABLE test_check (prod_id number(4),
Prod_name varchar2(20),
Category_id number(30),
Quantity_on_hand number(3) INVISIBLE ,
CONSTRAINT check_in CHECK (Quantity_on_hand BETWEEN 100 and 9999));
2、hash表组和hash分区表
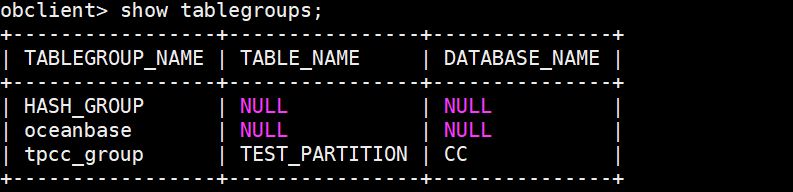
create tablegroup hash_group binding true partition by hash partitions 10;
show tablegroups;
![]()
create table hash_partition (id number(10) not null, name varchar2(10) default '123', partition_key number(10) not null) TABLEGROUP = hash_group partition by hash(partition_key) partitions 10;
3、range表组和range分区表
create tablegroup range_group partition by range columns 1
(
partition P1 values less than (10000),
partition P2 values less than (20000),
partition P3 values less than (30000),
partition P4 values less than (MAXVALUE)
);
create table range_partition(id number) tablegroup=range_group
partition by range(id)
(
partition P1 values less than (10000),
partition P2 values less than (20000),
partition P3 values less than (30000),
partition P4 values less than (MAXVALUE)
);
4、list表组和list分区表
create tablegroup list_group partition by list columns 1
(
partition P1 values (1),
partition P2 values (1000),
partition P3 values (10000)
);
create table list_partition(id number primary key) tablegroup=list_group
partition by list(id)
(
partition p1 values (1),
partition p2 values (1000),
partition p3 values (10000)
);
5、相关数据字典
select table_name,PARTITIONING_TYPE from dba_part_tables;
6、ob复制表
非分区表跟分区表的远程 SQL 优化,可以使用复制表的功能
上面的表分组要么针对非分区表,要么针对分区表。一个表分组没有办法同时包含非分区表和分区表。
OB 针对这种场景提供了一个方案就是复制表方案。非分区表创建为复制表时,则可以在租户的每个资源单元中都有一个副本。也就是在一个 2-2-2 的租户里,复制表不一定是 3 副本,而可以是 6 副本(1 主 5 备,全同步策略,强一致)
查看复制表的分布情况(3个zone,每个zone 2个observer,会有6副本)
create table test_dup (id int primary key,name varchar2(10)) duplicate_scope='cluster';
SELECT t.tenant_id, a.tenant_name, d.database_name, t.table_name, tg.tablegroup_name , t.part_num , t2.partition_id,
t2.ZONE, t2.svr_ip, case when t2.ROLE=1 then '主副本' when t2.ROLE=2 then '备副本' END AS role, t2.data_size
, a.primary_zone , IF(t.locality = '' OR t.locality IS NULL, a.locality, t.locality) AS locality
FROM oceanbase.__all_tenant AS a
JOIN oceanbase.__all_virtual_database AS d ON ( a.tenant_id = d.tenant_id )
JOIN oceanbase.__all_virtual_table AS t ON (t.tenant_id = d.tenant_id AND t.database_id = d.database_id)
JOIN oceanbase.__all_virtual_meta_table t2 ON (t.tenant_id = t2.tenant_id AND (t.table_id=t2.table_id OR t.tablegroup_id=t2.table_id) AND t2.ROLE IN (1,2) )
LEFT JOIN oceanbase.__all_virtual_tablegroup AS tg ON (t.tenant_id = tg.tenant_id and t.tablegroup_id = tg.tablegroup_id)
WHERE a.tenant_id IN (1001 ) AND t.table_type IN (3) AND d.database_name LIKE '%TPCC%'
AND t.table_name IN ('TEST_DUP') order by partition_id,role,ZONE;

普通表的分布情况:(3个zone,每个zone 2个observer,会有3副本)
create table bmsql_config ( cfg_name varchar2(30) primary key,cfg_value varchar2(50));
SELECT t.tenant_id, a.tenant_name, d.database_name, t.table_name, tg.tablegroup_name , t.part_num , t2.partition_id,
t2.ZONE, t2.svr_ip, case when t2.ROLE=1 then '主副本' when t2.ROLE=2 then '备副本' END AS role, t2.data_size
, a.primary_zone , IF(t.locality = '' OR t.locality IS NULL, a.locality, t.locality) AS locality
FROM oceanbase.__all_tenant AS a
JOIN oceanbase.__all_virtual_database AS d ON ( a.tenant_id = d.tenant_id )
JOIN oceanbase.__all_virtual_table AS t ON (t.tenant_id = d.tenant_id AND t.database_id = d.database_id)
JOIN oceanbase.__all_virtual_meta_table t2 ON (t.tenant_id = t2.tenant_id AND (t.table_id=t2.table_id OR t.tablegroup_id=t2.table_id) AND t2.ROLE IN (1,2) )
LEFT JOIN oceanbase.__all_virtual_tablegroup AS tg ON (t.tenant_id = tg.tenant_id and t.tablegroup_id = tg.tablegroup_id)
WHERE a.tenant_id IN (1001 ) AND t.table_type IN (3) AND d.database_name LIKE '%TPCC%'
AND t.table_name IN ('BMSQL_CONFIG') order by partition_id,role,ZONE;

分区表各分区的分布情况:(3个zone,每个zone 2个observer,每个分区会有3副本)
create table bmsql_warehouse (w_id integer not null,w_ytd decimal(12,2) primary key(w_id)) tablegroup='tpcc_group' partition by hash(w_id) partitions 12;
SELECT t.tenant_id, a.tenant_name, d.database_name, t.table_name, tg.tablegroup_name , t.part_num , t2.partition_id,
t2.ZONE, t2.svr_ip, case when t2.ROLE=1 then '主副本' when t2.ROLE=2 then '备副本' END AS role, t2.data_size
, a.primary_zone , IF(t.locality = '' OR t.locality IS NULL, a.locality, t.locality) AS locality
FROM oceanbase.__all_tenant AS a
JOIN oceanbase.__all_virtual_database AS d ON ( a.tenant_id = d.tenant_id )
JOIN oceanbase.__all_virtual_table AS t ON (t.tenant_id = d.tenant_id AND t.database_id = d.database_id)
JOIN oceanbase.__all_virtual_meta_table t2 ON (t.tenant_id = t2.tenant_id AND (t.table_id=t2.table_id OR t.tablegroup_id=t2.table_id) AND t2.ROLE IN (1,2) )
LEFT JOIN oceanbase.__all_virtual_tablegroup AS tg ON (t.tenant_id = tg.tenant_id and t.tablegroup_id = tg.tablegroup_id)
WHERE a.tenant_id IN (1001 ) AND t.table_type IN (3) AND d.database_name LIKE '%TPCC%'
AND t.table_name IN ('BMSQL_WAREHOUSE') order by partition_id,role,ZONE;
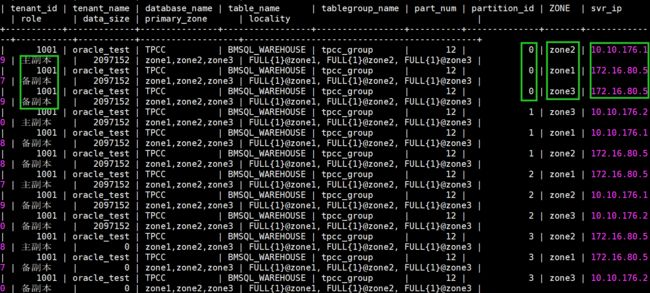
7、ob表组作用
TableGroup对经常会被同时访问的一组表,为了优化性能,需要将它们相同类型的副本存储在同一个OceanBase服务器中。通过定义一个Table group,并且将这一组表放在这个Table group中来达到这个目的。
此外,同一个Table group的多个分区表具有相同的分区数和分区规则。假设一个Table group里的表都有N个分区,所有这些表的第i个分区的集合组成一个Partition group。同一个Partition group里的分区,主副本总是位于同一个server上
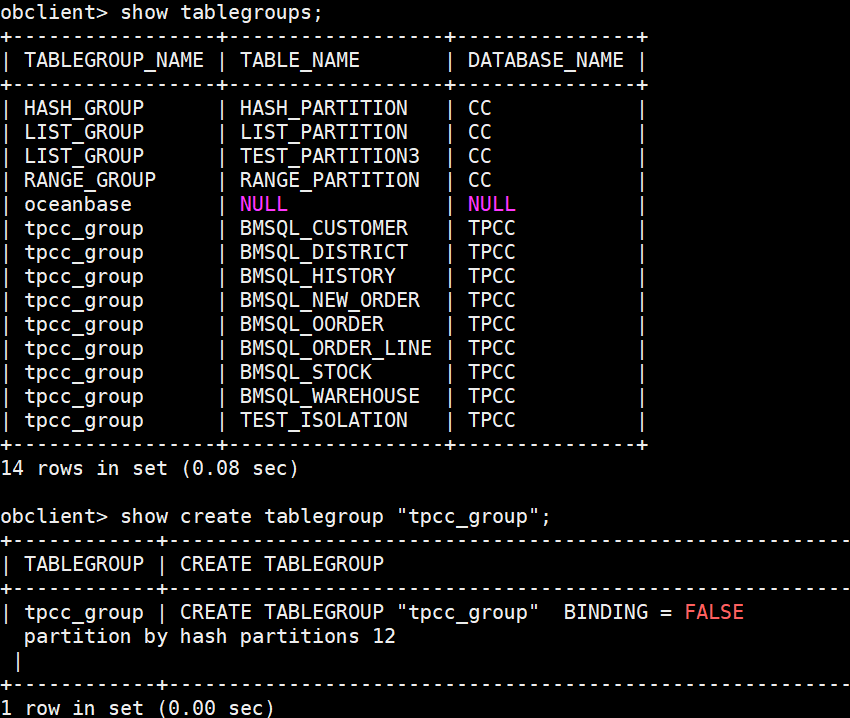
show tablegroups列出所有表组及其下的表,show create tablegroup "tpcc_group";
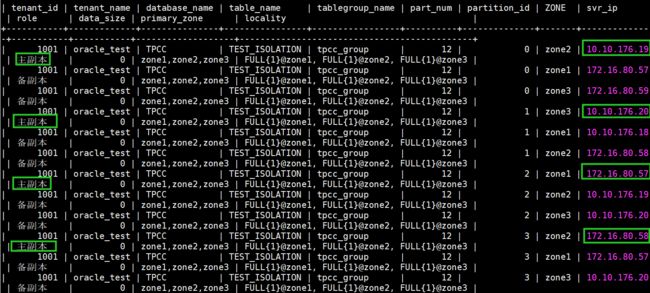
比如BMSQL_STOCK和TEST_ISOLATION同属于tpcc表组(partitions 12),查看TEST_ISOLATION的分区分布
SELECT t.tenant_id, a.tenant_name, d.database_name, t.table_name, tg.tablegroup_name , t.part_num , t2.partition_id,
t2.ZONE, t2.svr_ip, case when t2.ROLE=1 then '主副本' when t2.ROLE=2 then '备副本' END AS role, t2.data_size
, a.primary_zone , IF(t.locality = '' OR t.locality IS NULL, a.locality, t.locality) AS locality
FROM oceanbase.__all_tenant AS a
JOIN oceanbase.__all_virtual_database AS d ON ( a.tenant_id = d.tenant_id )
JOIN oceanbase.__all_virtual_table AS t ON (t.tenant_id = d.tenant_id AND t.database_id = d.database_id)
JOIN oceanbase.__all_virtual_meta_table t2 ON (t.tenant_id = t2.tenant_id AND (t.table_id=t2.table_id OR t.tablegroup_id=t2.table_id) AND t2.ROLE IN (1,2) )
LEFT JOIN oceanbase.__all_virtual_tablegroup AS tg ON (t.tenant_id = tg.tenant_id and t.tablegroup_id = tg.tablegroup_id)
WHERE a.tenant_id IN (1001 ) AND t.table_type IN (3) AND d.database_name LIKE '%TPCC%'
AND t.table_name IN ('****') order by partition_id,role,ZONE;
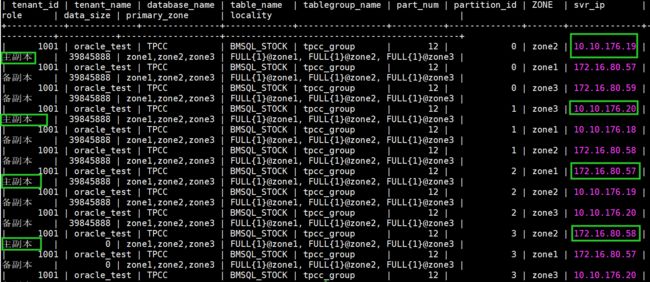
创建一个partitions 12的表,不将其加入tpcc_group表组,查看分区分布:
create table TEST_12 (d_w_id number primary key,name varchar2(10)) partition by hash(d_w_id) partitions 12;

可以看出,即使分区数相同,不在同一个表组,主副本的分布也不同
五、ob函数、触发器、视图、dblink等
(1)触发器
CREATE OR REPLACE TRIGGER "CC"."PCRF_SUBS_CHANGE"
AFTER INSERT OR UPDATE ON SUBS
FOR EACH ROW
BEGIN
if updating then
INSERT INTO PCRF_CHANGE_NOTIF(CHANGE_NOTIF_ID,TABLE_NAME,KEY_VALUE,CREATED_DATE,
ROUTING_ID)
VALUES(PCRF_CHANGE_NOTIF_ID_SEQ.NEXTVAL,'SUBS',to_char(:new.SUBS_ID),SYSDATE,:new.ROUTING_ID);
end if;
END;
/
ALTER TRIGGER "CC"."PCRF_SUBS_CHANGE" DISABLE;
(2)视图
obclient> CREATE OR REPLACE FORCE VIEW "CC"."BPM_PROCESS" ("PROCESS_NO", "PROCESS_NAME", "FLAG") AS select ID as process_no,NAME as process_name,'0' FLAG from bfm_process_temp where state='A';
ORA-00900: You have an error in your SQL syntax; check the manual that corresponds to your OceanBase version for the right syntax to use near 'FORCE VIEW "CC"."BPM_PROCESS" ("PROCESS_NO", "PROCESS_NAME", "FLAG") AS select I' at line 1
obclient> CREATE OR REPLACE VIEW "CC"."BPM_PROCESS" ("PROCESS_NO", "PROCESS_NAME", "FLAG") AS select ID as process_no,NAME as process_name,'0' FLAG from bfm_process_temp where state='A';
Query OK, 0 rows affected (0.02 sec)
(3)dblink
ob oracle租户的dblink功能还有缺陷报错,且限制如下:
1. 只能执行只读语句。
2. 只能访问表对象,不支持访问其它对象,如视图、序列等。
3. 访问表对象时必须显式指定数据库名,如: test.t1@my_link 。
4. 不支持部分计划和算子:
不能在远程数据库执行 RESCAN 操作。
不能在远程数据库执行 NESTED LOOP JOIN 、 SEMI JOIN 、 ANTI JOIN 、 SUBPLAN FILTER 等算子。
如遇以上问题请尝试运行 EXPLAIN PLAN 语句查看原始计划和发送到远端集群执行的 SQL 语句,并通过使用 Hint 调整计划。
CREATE resource unit oracle_dblink_unit max_cpu=5, min_cpu=3, max_memory='10G', min_memory='5G', max_iops=10000, min_iops=1000, max_session_num=1000000, max_disk_size='200G';
CREATE resource pool oracle_dblink unit = 'oracle_dblink_unit', unit_num = 1;
create tenant oracle_dblink resource_pool_list=('oracle_dblink'), primary_zone='RANDOM',comment 'oracle tenant/instance', charset='utf8mb4' set ob_tcp_invited_nodes='%', ob_compatibility_mode='oracle';
obclient -usys@oracle_dblink#obcluster -h172.16.80.56 -P2883 -p
obclient> alter user sys identified by ******;
Query OK, 0 rows affected (0.02 sec)
obclient> create user dblink_test identified by ******;
Query OK, 0 rows affected (0.02 sec)
obclient> grant dba to dblink_test;
obclient> CREATE DATABASE LINK mylink CONNECT TO dblink_test@oracle_dblink IDENTIFIED BY **** HOST '172.16.80.56:2883';
Query OK, 1 row affected (0.01 sec)
obclient> select * from DBLIBK_TEST.t1@mylink;
ERROR:
Unknown Error
obclient> CREATE DATABASE LINK mylink CONNECT TO TEST@oracle_test IDENTIFIED BY ****** HOST '172.16.80.57:2883';
Query OK, 1 row affected (0.02 sec)
obclient> select * from TEST.t1@mylink;
ORA-01861: literal does not match format string
(4)序列
CREATE SEQUENCE seq_account START WITH 1 INCREMENT BY 1 nocycle;
select seq_account.nextval from dual;
select seq_account.currval from dual;
select * from dba_sequences;
六、故障恢复ob集群
1、observer起停测试(命令行模式)
停observer:
ps -ef|grep observer
su - admin
kill -9 `pidof observer`
obclient -uroot@sys -p****** -h172.16.80.57 -P2883 -D oceanbase -A
select * from __all_server; --可以看到停止observer的处于inactive状态
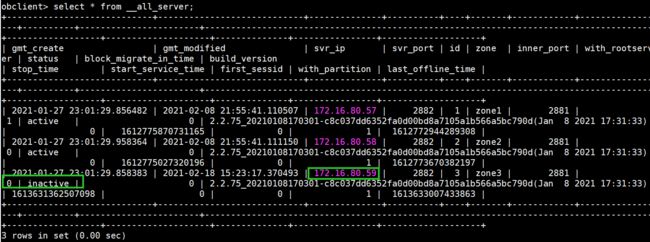
如果连接的会话正好在故障节点,会有一时的连接报错
obclient> select * from test where id=4000;
ERROR-02013: Lost connection to MySQL server during query
obclient> select * from test where id=4000;
ERROR-02006: OceanBase server has gone away
No connection. Trying to reconnect...
Connection id: 55229
Current database: CC
+------+
| ID |
+------+
| 4000 |
| 4000 |
| 4000 |
| 4000 |
| 4000 |
| 4000 |
+------+
6 rows in set (0.03 sec)
手动起observer:
su - admin
cd /home/admin/oceanbase/
/home/admin/oceanbase/bin/observer
起来后observer恢复为active
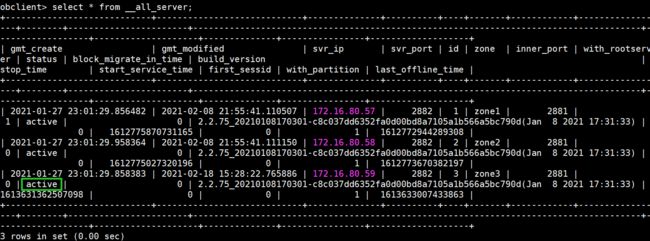
如果停一个角色为rootservice的ob server(with_rootserver为1),集群会重新选举一个root server
2、两个zone故障,会导致集群无法访问
由于ob使用paxos协议,只允许一个zone故障,若两个zone故障,会导致集群无法访问,报错如下:
(1)原有的会话报错如下:
obclient> select * from __all_server;
ERROR 4012 (25000): Statement is timeout
(2)新会话无法连接:
root@mgr0[/soft/obpoc_x86/oms/ob-loader-dumper-2.1.11-SNAPSHOT/bin]$ obclient -ucc@oracle_test#obdemo -p****** -h172.16.80.57 -P2883
obclient: [Warning] Using a password on the command line interface can be insecure.
ERROR 6002 (25000): transaction needs rollback
(3)ocp告警如下:
ob_cluster=obdemo-20210127 OB集群状态检测失败,检查项 cluster connect check, 失败原因
注:ocp只能停止一个zone,禁止停两个zone,报错:
com.alipay.ocp.core.obsdk.exception.OceanBaseException: not enough member or quorum mismatch, stop zone not allowed
任务失败,在任务界面回滚任务,使得observer的错误状态由停止中改为运行中
所以只能通过命令行停止两个或以上的zone
(4)恢复:
只能黑屏手动起observer:
su - admin
cd /home/admin/oceanbase/(此步骤必须要跑,否则会导致文件目录不对)
/home/admin/oceanbase/bin/observer(要写绝对路径)
黑屏将另一台机器observer拉起来后,ocp可能无法识别,可以在ocp上再次启动(没有影响)
等10分钟之后集群才能恢复:
obclient> select * from __all_server;
+----------------------------+----------------------------+--------------+----------+----+-------+------------+-----------------+----------+-----------------------+--------------------------------------------------------------------------------------+-----------+--------------------+--------------+----------------+-------------------+
| gmt_create | gmt_modified | svr_ip | svr_port | id | zone | inner_port | with_rootserver | status | block_migrate_in_time | build_version | stop_time | start_service_time | first_sessid | with_partition | last_offline_time |
+----------------------------+----------------------------+--------------+----------+----+-------+------------+-----------------+----------+-----------------------+--------------------------------------------------------------------------------------+-----------+--------------------+--------------+----------------+-------------------+
| 2021-01-27 23:01:29.856482 | 2021-02-08 16:28:54.289268 | 172.16.80.57 | 2882 | 1 | zone1 | 2881 | 0 | inactive | 0 | 2.2.75_20210108170301-c8c037dd6352fa0d00bd8a7105a1b566a5bc790d(Jan 8 2021 17:31:33) | 0 | 0 | 0 | 1 | 1612772944289308 |
| 2021-01-27 23:01:29.958364 | 2021-02-08 16:41:00.365732 | 172.16.80.58 | 2882 | 2 | zone2 | 2881 | 0 | inactive | 0 | 2.2.75_20210108170301-c8c037dd6352fa0d00bd8a7105a1b566a5bc790d(Jan 8 2021 17:31:33) | 0 | 0 | 0 | 1 | 1612773670382197 |
| 2021-01-27 23:01:29.858383 | 2021-02-08 16:28:51.300328 | 172.16.80.59 | 2882 | 3 | zone3 | 2881 | 1 | active | 0 | 2.2.75_20210108170301-c8c037dd6352fa0d00bd8a7105a1b566a5bc790d(Jan 8 2021 17:31:33) | 0 | 1611911142068305 | 0 | 1 | 1611910928198024 |
3、磁盘故障导致数据丢失,恢复observer
磁盘异常验证(格式化数据盘):
mkfs.ext4 /dev/vgflash/lv1
此时observer自动down,处于不可用状态
恢复此observer:
(1)清理ob:
su - admin
kill -9 `pidof observer`
sleep 3
/bin/rm -rf /data/1/obdemo
/bin/rm -rf /data/log1/obdemo
/bin/rm -rf /home/admin/oceanbase/store/obdemo /home/admin/oceanbase/log/* /home/admin/oceanbase/etc/*config*
ps -ef|grep observer
df -h |egrep home\|data
(2)重建目录:
mkdir -p /data/1/obdemo/{etc3,sort_dir,sstable}
mkdir -p /data/log1/obdemo/{clog,etc2,ilog,slog,oob_clog}
mkdir -p /home/admin/oceanbase/store/obdemo
for t in {etc3,sort_dir,sstable};do ln -s /data/1/obdemo/$t /home/admin/oceanbase/store/obdemo/$t; done
for t in {clog,etc2,ilog,slog,oob_clog};do ln -s /data/log1/obdemo/$t /home/admin/oceanbase/store/obdemo/$t; done
(3)执行初始化此zone的脚本:
cd /home/admin/oceanbase && /home/admin/oceanbase/bin/observer -i ens5f0 -P 2882 -p 2881 -z zone3 -d /home/admin/oceanbase/store/obdemo -r '172.16.80.57:2882:2881;172.16.80.58:2882:2881;172.16.80.59:2882:2881' -c 20210127 -n obdemo -o "system_memory=10G,datafile_size=100G,config_additional_dir=/data/1/obdemo/etc3;/data/log1/obdemo/etc2"
可能恢复过之后ocp无法识别,需要手动在ocp上启动识别(不会影响当前observer)
4、网卡问题导致集群异常
ifdown网卡或者主机shutdown :ocp显示主机下线,为inactive状态
obclient> select * from __all_server;
+----------------------------+----------------------------+--------------+----------+----+-------+------------+-----------------+----------+-----------------------+--------------------------------------------------------------------------------------+------------------+--------------------+--------------+----------------+-------------------+
| gmt_create | gmt_modified | svr_ip | svr_port | id | zone | inner_port | with_rootserver | status | block_migrate_in_time | build_version | stop_time | start_service_time | first_sessid | with_partition | last_offline_time |
+----------------------------+----------------------------+--------------+----------+----+-------+------------+-----------------+----------+-----------------------+--------------------------------------------------------------------------------------+------------------+--------------------+--------------+----------------+-------------------+
| 2021-01-27 23:01:29.856482 | 2021-02-08 21:55:41.110507 | 172.16.80.57 | 2882 | 1 | zone1 | 2881 | 1 | active | 0 | 2.2.75_20210108170301-c8c037dd6352fa0d00bd8a7105a1b566a5bc790d(Jan 8 2021 17:31:33) | 0 | 1612775870731165 | 0 | 1 | 1612772944289308 |
| 2021-01-27 23:01:29.958364 | 2021-02-08 21:55:41.111150 | 172.16.80.58 | 2882 | 2 | zone2 | 2881 | 0 | active | 0 | 2.2.75_20210108170301-c8c037dd6352fa0d00bd8a7105a1b566a5bc790d(Jan 8 2021 17:31:33) | 0 | 1612775027320196 | 0 | 1 | 1612773670382197 |
| 2021-01-27 23:01:29.858383 | 2021-02-09 12:31:51.335899 | 172.16.80.59 | 2882 | 3 | zone3 | 2881 | 0 | inactive | 0 | 2.2.75_20210108170301-c8c037dd6352fa0d00bd8a7105a1b566a5bc790d(Jan 8 2021 17:31:33) | 1612793767436243 | 0 | 0 | 1 | 1612845121404528 |
+----------------------------+----------------------------+--------------+----------+----+-------+------------+-----------------+----------+-----------------------+--------------------------------------------------------------------------------------+------------------+--------------------+--------------+----------------+-------------------+
3 rows in set (0.00 sec)
七、ob系统参数、变量管理
OceanBase 的集群参数分为集群级别和租户级别,同时参数分为动态生效和重启生效两类。
通过集群参数的设置可以控制集群的负载均衡、合并时间、合并方式、资源分配和模块开关等功能。
如果同时存在集群级别参数和租户级别参数,则集群级别参数将覆盖租户级别参数
系统租户可以查看和设置所有其他租户的参数 (包括 sys 租户),普通租户只能设置自己租户的参数

进入sys租户:
obclient -uroot@sys -p -h172.16.80.57 -P2883
SHOW PARAMETERS WHERE edit_level='static_effective' AND name='sql_work_area';

show parameters like 'major_freeze_duty_time' tenant=oracle_test;
show parameters like 'major_freeze_duty_time';

alter system set major_freeze_duty_time='04:00' ;

alter system set major_freeze_duty_time='06:00' zone='zone1';
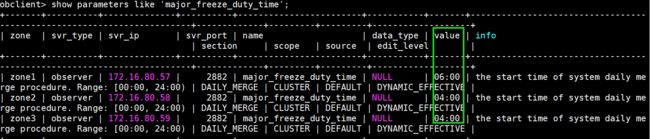
alter system set major_freeze_duty_time='08:00' server='172.16.80.59:2882';
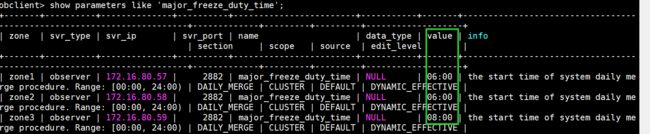
ob系统参数相关表:

参数的改变会记录到__all_sys_parameter和参数文件observer.config.bin中
如_ob_enable_prepared_statement,alter system set _ob_enable_prepared_statement=true;
select * from __all_sys_parameter where name like '%_ob_enable_prepared_statement%';

strings observer.config.bin|grep _ob_enable_prepared_statement
![]()
变量的修改会记录到__all_virtual_sys_variable,set global autocommit=off;
select * from __all_virtual_sys_variable where name like '%commit%';
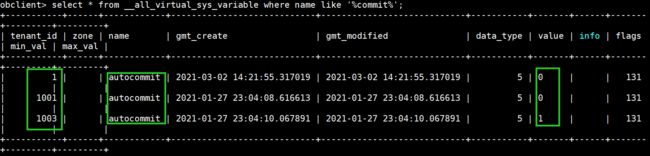
某个observer重启后,修改的值仍然生效
八、ob的各种日志
1、关于clog
OBServer服务器的“~/datadir/clog”目录下,Commit Log,所有Partition共用,日志可能是乱序的,记录事务、PartitionService提供的原始日志内容。此目录下的日志基于Paxos协议在多个副本之间同步。
事务的日志包括:redo log, prepare log, commit log, abort log, clear log等
• redo log记录了事务的具体操作,比如某一行数据的某个字段从A修改为B
• prepare log记录了事务的prepare状态
• commit log表示这个事务成功commit,并记录commit信息,比如事务的全局版本号
• clear log用于通知事务清理事务上下文
• abort log表示这个事务被回滚
2、关于ilog
OBServer服务器的“~/datadir/ilog”目录下,Index Log,所有Partition共用,单Partition内部日志有序,记录Partition内部log_id>clog(file_id, offset)的索引信息。每个副本自行记录。
3、关于slog
OBServer服务器的“~/datadir/slog”目录下,记录Storage log,指SSTable操作日志信息
九、ob逻辑备份恢复
ob的oracle租户支持source .sql文件
ob的逻辑备份恢复是由obdumper和obloader实现,解压ob-loader-dumper的tar包
tar -xvf ob-loader-dumper-2.1.10.tar.gz
cd ob-loader-dumper-2.1.10/bin/
chmod +x obdumper
chmod +x obloader
obdumper以sql形式(insert into)备份表数据
./obdumper -u cc -t oracle_test -c obdemo -p ****** -h 172.16.80.57 -P 2883 -D CC --table 'TEST_PARTITION,TEST' --sql -f /soft --sys-password ******
会自动在/soft/data/CC/TABLE下生成sql文件(注意:分区表会生成多个sql文件)
obdumper以csv形式(数据行)备份表数据
./obdumper -u cc -t oracle_test -c obdemo -p ****** -h 172.16.80.57 -P 2883 -D CC --table 'TEST_PARTITION2,TEST' --csv -f /soft --sys-password ******
会自动在/soft/data/CC/TABLE下生成csv文件(注意:分区表会生成多个csv文件)
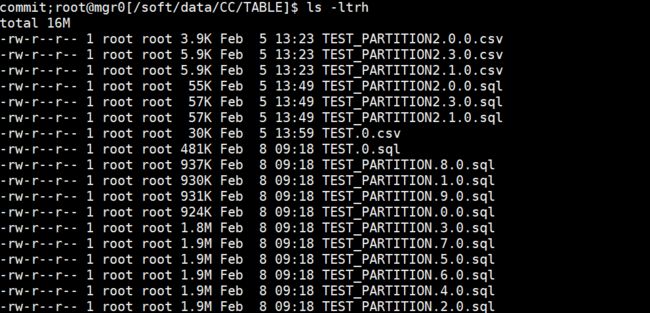
obdumper备份表结构(oracle租户),生成sql文件
./obdumper -u cc -t oracle_test -c obdemo -p ****** -h 172.16.80.57 -P 2883 -D CC --table 'TEST_PARTITION2,TEST' --ddl -f /soft --sys-password ******
obdumper备份表结构(mysql租户),生成sql文件
./obdumper -u test -t mysql_test_restore -c obdemo -p****** -h 172.16.80.57 -P 2883 -D test --table 't1' --ddl -f /soft --sys-password ******

obdumper备份表结构和数据,生成sql文件
./obdumper -u cc -t oracle_test -c obdemo -p ****** -h 172.16.80.57 -P 2883 -D CC --table 'TEST_PARTITION2,TEST' --mix -f /soft --sys-password ******
obloader默认加载的格式为:逗号分隔列,并默认以单引号''围起来列值,且要带header

obloader导入数据(默认为append)
./obloader -u cc -t oracle_test -c obdemo -p ****** -h 172.16.80.57 -P 2883 -D CC --table 'TEST_PARTITION,TEST' --sql -f /soft --sys-password ******
obloader导入数据(先truncate再导入)
./obloader -u cc -t oracle_test -c obdemo -p ****** -h 172.16.80.57 -P 2883 -D CC --table 'TEST_PARTITION2' --truncate-table --csv -f /soft --sys-password ******
./obloader -u postcc -t oracle_test -c obdemo -p **** -h 172.16.80.57 -P 2883 -D POSTCC --table 'DEBIT_ACTION_TYPE' --truncate-table --csv -f /soft --sys-password **** --skip-header
./obloader -u postcc -t oracle_test -c obdemo -p **** -h 172.16.80.57 -P 2883 -D POSTCC --table 'DEBIT_ACTION_TYPE' --truncate-table --sql -f /soft --sys-password ****
或者
source /soft/data/DEBIT_ACTION_TYPE.sql
十、其他
1、会话管理
不管是oracle租户还是mysql租户,都可以使用SHOW PROCESSLIST;来查看当前进程

通过KILL session_id;来杀掉会话

ocp也可以查看会话和kill会话
打开相应的租户-【会话管理】选中会话--【关闭会话】

2、sql审计
sql审计默认打开,show parameters like '%enable_sql_audit%'; sql审计记录在gv$sql_audit视图里
ob开启审计不会影响性能,甚至在做性能压测时都可以打开(蚂蚁内部是打开的),是因为sql信息不做持久化,都保留在内存中,受参数sql_audit_memory_limit的影响

sql_audit 相关设置
设置 sql_audit 使用开关。
alter system set enable_sql_audit = true/false;
设置 sql_audit 内存上限。默认内存上限为 3G,可设置范围为 [64M,+∞]。
alter system set sql_audit_memory_limit = '3G';
sql_audit 淘汰机制
机制启动间隔:
后台任务每隔 1s 会检测是否需要淘汰。
触发淘汰的标准:
当内存或记录数达到淘汰上限时触发淘汰。
sql_audit 内存最大可使用上限:avail_mem_limit = min( OBServer 可使用内存*10%, sql_audit_memory_limit)。
淘汰内存上限:
当 avail_mem_limit 在[64M, 100M]时, 内存使用达到 avail_mem_limit-20M 时触发淘汰。
当 avail_mem_limit 在[100M, 5G]时, 内存使用达到 availmem_limit*0.8 时触发淘汰。
当 avail_mem_limit 在 [5G, +∞]时, 内存使用达到 availmem_limit-1G 时触发淘汰。
淘汰记录数上限:当 sql_audit 记录数超过 900w 条记录时,触发淘汰。
停止淘汰的标准:
如果是达到内存上限触发淘汰则:
当 avail_mem_limit 在 [64M, 100M] 时, 内存使用淘汰到 avail_mem_limit-40M 时停止淘汰。
当 avail_mem_limit 在 [100M, 5G] 时, 内存使用淘汰到 availmem_limit*0.6 时停止淘汰。
当 avail_mem_limit 在 [5G, +∞] 时, 内存使用淘汰到 availmem_limit-2G 时停止淘汰。
如果是达到记录数上限触发的淘汰则淘汰到 800w 行记录时停止淘汰
查询记录
查询某个租户某个用户执行的sql
SELECT /*+ read_consistency(weak) ob_querytimeout(100000000) */ substr(usec_to_time(request_time),1,19) request_time_, s.svr_ip, s.client_Ip, s.sid, s.plan_type, s.query_sql, s.affected_rows, s.return_rows, s.ret_code
FROM gv$sql_audit s WHERE s.tenant_id=1001 AND user_name LIKE '%TPCC%';
查询当前最旧的时间
select substr(usec_to_time(request_time),1,19) from gv$sql_audit order by 1 limit 10;

ocp上每个租户下有TopSQL,记录慢查询
慢sql参数:trace_log_slow_query_watermark 默认100ms

sql_audit 字段解释
| 字段名称 |
类型 |
描述 |
| SVR_IP |
varchar(32) |
IP 地址 |
| SVR_PORT |
bigint(20) |
端口号 |
| REQUEST_ID |
bigint(20) |
请求的 ID 号 |
| TRACE_ID |
varchar(128) |
这条语句的 trace ID |
| CLIENT_IP |
varchar(32) |
发送请求的 client IP |
| CLIENT_PORT |
bigint(20) |
发送请求的 client 端口 |
| TENANT_ID |
bigint(20) |
发送请求的租户 ID |
| TENANT_NAME |
varchar(64) |
发送请求的租户名称 |
| USER_ID |
bigint(20) |
发送请求的用户 ID |
| USER_NAME |
varchar(64) |
发送请求的用户名称 |
| SQL_ID |
varchar(32) |
这条 SQL 的 ID |
| QUERY_SQL |
varchar(32768) |
实际的 SQL 语句 |
| PLAN_ID |
bigint(20) |
执行计划 ID |
| AFFECTED_ROWS |
bigint(20) |
影响行数 |
| RETURN_ROWS |
bigint(20) |
返回行数 |
| PARTITION_CNT |
bigint(20) |
该请求涉及的分区数 |
| RET_CODE |
bigint(20) |
执行结果返回码 |
| EVENT |
varchar(64) |
最长等待事件名称 |
| P1TEXT |
varchar(64) |
等待事件参数 1 |
| P1 |
bigint(20) unsigned |
等待事件参数 1 的值 |
| P2TEXT |
varchar(64) |
等待事件参数 2 |
| P2 |
bigint(20) unsigned |
等待事件参数 2 的值 |
| P3TEXT |
varchar(64) |
等待事件参数 3 |
| P3 |
bigint(20) unsigned |
等待事件参数 3 的值 |
| LEVEL |
bigint(20) |
等待事件的 level 级别 |
| WAIT_CLASS_ID |
bigint(20) |
等待事件所属的 class ID |
| WAIT_CLASS# |
bigint(20) |
等待事件所属的 class 的下标 |
| WAIT_CLASS |
varchar(64) |
等待事件所属的 class 名称 |
| STATE |
varchar(19) |
等待事件的状态 |
| WAIT_TIME_MICRO |
bigint(20) |
该等待事件所等待的时间(微秒) |
| TOTAL_WAIT_TIME_MICRO |
bigint(20) |
执行过程所有等待的总时间(微秒) |
| TOTAL_WAITS |
bigint(20) |
执行过程总等待的次数 |
| RPC_COUNT |
bigint(20) |
发送 RPC 个数 |
| PLAN_TYPE |
bigint(20) |
执行计划类型(local/remote/distribute) |
| IS_INNER_SQL |
tinyint(4) |
是否内部 SQL 请求 |
| IS_EXECUTOR_RPC |
tinyint(4) |
当前请求是否 RPC 请求 |
| IS_HIT_PLAN |
tinyint(4) |
是否命中 plan cache |
| REQUEST_TIME |
bigint(20) |
开始执行时间点 |
| ELAPSED_TIME |
bigint(20) |
接收到请求到执行结束消耗总时间 |
| NET_TIME |
bigint(20) |
发送 rpc 到接收到请求时间 |
| NET_WAIT_TIME |
bigint(20) |
接收到请求到进入队列时间 |
| QUEUE_TIME |
bigint(20) |
请求在队列等待事件 |
| DECODE_TIME |
bigint(20) |
出队列后 decode 时间 |
| GET_PLAN_TIME |
bigint(20) |
开始 process 到获得 plan 时间 |
| EXECUTE_TIME |
bigint(20) |
plan 执行消耗时间 |
| APPLICATION_WAIT_TIME |
bigint(20) unsigned |
所有 application 类事件的总时间 |
| CONCURRENCY_WAIT_TIME |
bigint(20) unsigned |
所有 concurrency 类事件的总时间 |
| USER_IO_WAIT_TIME |
bigint(20) unsigned |
所有 user IO 类事件的总时间 |
| SCHEDULE_TIME |
bigint(20) unsigned |
所有 schedule 类事件的时间 |
| ROW_CACHE_HIT |
bigint(20) |
行缓存命中次数 |
| BLOOM_FILTER_CACHE_HIT |
bigint(20) |
bloom filter 缓存命中次数 |
| BLOCK_CACHE_HIT |
bigint(20) |
块缓存命中次数 |
| BLOCK_INDEX_CACHE_HIT |
bigint(20) |
块索引缓存命中次数 |
| DISK_READS |
bigint(20) |
物理读次数 |
| EXECUTION_ID |
bigint(20) |
执行 ID |
| SESSION_ID |
bigint(20) |
session ID |
| RETRY_CNT |
bigint(20) |
重试次数 |
| TABLE_SCAN |
tinyint(4) |
判断该请求是否含全表扫描 |
| CONSISTENCY_LEVEL |
bigint(20) |
一致性级别 |
| MEMSTORE_READ_ROW_COUNT |
bigint(20) |
MEMSTORE 中的读行数 |
| SSSTORE_READ_ROW_COUNT' |
bigint(20) |
SSSTORE 中国年读的行数 |
| REQUEST_MEMORY_USED |
bigint(20) |
该请求消耗的内存 |
3、ob错误码

4、常用sql
--查看集群剩余cpu,memory
select b.zone, a.svr_ip, a.cpu_total, a.cpu_assigned , a.cpu_assigned_percent,round(a.mem_total/1024/1024/1024, 2) as mem_total,
round(a.mem_assigned/1024/1024/1024,2) mem_assigned,round((a.mem_total-a.mem_assigned)/1024/1024/1024, 2) as mem_free,
a.mem_assigned_percent mem_assigned_percent from __all_virtual_server_stat a,__all_server b where a.svr_ip = b.svr_ip order by zone,cpu_assigned_percent desc;
----查看集群剩余磁盘
select svr_ip, total_size/1024/1024/1024 total_G,free_size/1024/1024/1024 free_G, (total_size - free_size)/1024/1024/1024 used_G from __all_virtual_disk_stat order by svr_ip;
--查看超过500m的分区(表)
select tenant_id, svr_ip, unit_id, table_id, sum(data_size)/1024/1024/1024 size_G from __all_virtual_meta_table group by 1, 2, 3, 4 having size_G>0.5;
select table_name,tenant_id,database_id from __all_virtual_table where table_id=1100611139467138;
--查看sql的执行计划类型 type(1,2,3):local,remote 或 distribute
select SQL_TEXT,type from gv$sql where sql_text like '%EVENT_ACM_INST%';
--检查特定租户下Top 10的sql执行时间
select sql_id, query_sql,count(*), avg(elapsed_time), avg(execute_time), avg(queue_time),avg(user_io_wait_time) from gv$sql_audit where tenant_id=1001 group by sql_id having count(*)>1 order by 5 desc limit 10\G;
--检查特定租户下消耗cpu最多的top sql
select sql_id, avg(execute_time) avg_exec_time, count(*) cnt, avg(execute_time-TOTAL_WAIT_TIME_MICRO) cpu_time,PLAN_ID from gv$sql_audit where tenant_id=1001 group by 1 order by avg_exec_time * cnt desc limit 5;
select sql_text from gv$sql where sql_id='4CF20640FB3D08FD3CA456E9FD6536EC';
--查看合并事件等
__all_rootservice_event_history:记录集群级事件,如major freeze, 合并,server 上下线,负载均衡任务执行等,保留最近7天历史
select * from __all_rootservice_event_history order by gmt_create desc limit 10;
如发现一台server宕机,要确认OceanBase探测到此server宕机时间点,可执以下SQL:
select * from __all_rootservice_event_history where module = 'server';
--__all_server_event_history:记录server级事件,如转储,合并完成,切主,执行用户命令等,保留最近3天历史
查看转储次数:select * from __all_server_event_history where module like '%minor%' order by gmt_create desc limit 10;
-- v$sql_audit 存储本机的sql执行历史, gv$sql_audit 存储整个集群的sql执行历史
-- 查询 v$sql_audit 表,如查询某租户执行时间大于1s (1000000微秒)的SQL:
select * from v$sql_audit where tenant_id = 1001 and elapsed_time > 1000000 limit 10 ;
--oracle租户查看系统时间:
select sysdate from dual;
select systimestamp from dual;
--mysql租户查看系统时间
select sysdate() from dual;
select now() from dual;
5、缩容(zone内删除observer)
如果一个集群是2-2-2的架构(且存在某个租户unit_num=2),则只能stop一个zone中的一个或两个observer
select t1.name resource_pool_name, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb, t2.max_disk_size/1024/1024/1024 ,t2.max_session_num,t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,t4.tenant_id, t4.tenant_name
from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id) join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;
(1)将租户的resource pool的unit数改为1
alter resource pool oracle_pool unit_num=1; --此操作会导致很多分区迁移(运行时间较久)
select count(*) from __all_virtual_partition_migration_status;

--内部表:
• __all_virtual_rebalance_task_stat:迁移复制任务(zone内observer之间副本的迁移)
• __all_virtual_partition_migration_status:observer端正在执行的对象迁移任务(unit减少之后,租户从一个unit移动到另一个unit)
(2)下线observer
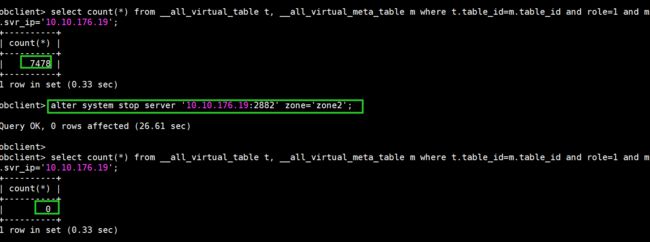
--查看某个要下线的机器上是否还有主副本
select count(*) from __all_virtual_table t, __all_virtual_meta_table m where t.table_id=m.table_id and role=1 and m.svr_ip='10.10.176.19';
alter system stop server '10.10.176.19:2882' zone='zone2'; --stop server的作用是将主副本移动
select t1.name resource_pool_name, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb, t2.max_disk_size/1024/1024/1024 ,t2.max_session_num,t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,t4.tenant_id, t4.tenant_name from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id) join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`) left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id) order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;
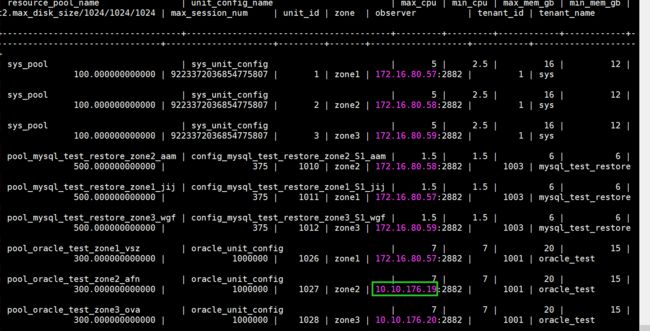
(3)删除observer
alter system delete server '10.10.176.19:2882' zone='zone2'; --此操作会导致在此observer上的备副本迁移到同zone内的其他observer上(运行时间较久,直到__all_virtual_rebalance_task_stat中的记录清空)
select count(*) from __all_virtual_rebalance_task_stat;

同一个zone内的其他unit取代了删除的observer
select t1.name resource_pool_name, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb, t2.max_disk_size/1024/1024/1024 ,t2.max_session_num,t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,t4.tenant_id, t4.tenant_name from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id) join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`) left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id) order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;

等observer从deleting消失,即可进行下面的步骤
select * from __all_server;

(4)停止主机上observer进程
su - admin
kill -9 `pidof observer`
(5)清空目录数据
/bin/rm -rf /data/1/obdemo
/bin/rm -rf /data/log1/obdemo
/bin/rm -rf /home/admin/oceanbase/store/obdemo /home/admin/oceanbase/log/* /home/admin/oceanbase/etc/*config*
ps -ef|grep observer
df -h |egrep home\|data
6、替换observer

7、查看sql执行计划
explain select * from test;
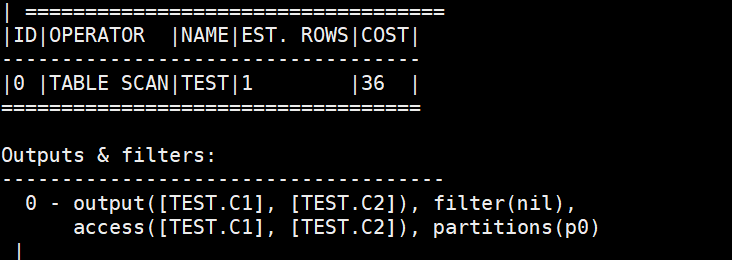
index_scan:索引扫描,一般是二级索引
indec_get:索引读取,一般是主键索引
explain extended select * from test; --得到更为具体的执行计划
