论文翻译:搜索人脸活体检测的中心差异卷积网络及实现代码
搜索人脸活体检测的中心差异卷积网络
- 摘要
- 1. 绪论
- 2. 相关工作
-
- 人脸活体检测
- 卷积运算符
- 神经架构搜索
- 3. 方法论
-
- 3.1 中心差分卷积
-
- 基本卷积
- 基本卷积结合中心差分操作
- 中心差分卷积的实现
- 与先前工作的关系
- 3.2 CDCN
- 3.3 CNDC++
-
- 面部反欺诈任务的骨干网络搜索
- MAFM
- 4. 实验
-
- 4.1 数据集和指标
-
- 数据库
- 性能指标
- 4.2 实现细节
-
- 深度生成
- 训练和测试设置
- 搜索设置
- 4.3 消融实验
-
- θ θ θ对CDCN的影响
- CDC vs 其他卷积
- NAS配置的影响
- 基于NAS的主干和MAFM的有效性
- 4.4 内部测试
-
- 在OULU-NPU上的结果
- 在SiW上的结果
- 4.5 交叉测试
-
- 跨类型测试
- 跨数据集测试
- 4.6 分析和可视化
-
- 对领域漂移的鲁棒性。
- 特征可视化
- 5. 总结和未来的工作
- 6. 致谢
- 引用
- 附录
-
- A. CDC的推导和代码
- B. CDC的自适应θ
- C.在SiW-M数据集上进行交叉类型测试
- D. 特征可视化
- 代码实现
文章原文和模型源码:https://github.com/ZitongYu/CDCN
摘要
人脸活体检测(FAS)在人脸识别系统中起着至关重要的作用。大部分最先进的FAS技术。1)依赖于堆叠卷积层和专业设计的网络,这些网络在描述详细的细粒度信息方面较弱,并且当环境变化时容易失效(例如,在不同的照明条件下)。2)更倾向使用长序列作为输出来提取动态特征,这使得它们难以部署到需要快速响应的场景中。本文提出一种基于中心差分卷积(CDC)的帧级FAS方法,该方法可以通过聚合强度和梯度信息来捕获内在的详细模型。使用CDC构建的网络称为中心差分卷积网络(CDCN),能够提供比其使用普通卷积构建的对应网络更强大的建模能力。此外,在特定设计的CDC搜索空间上,利用神经结构搜索(NAS)发现了一个更强大的网络结构(CDCN ++),可以与多尺度注意力融合模块(MAFM)组合以进一步提高性能。在六个基准数据集上进行了全面的实验,结果显示:1)所提出的方法不仅在内部数据集测试中取得了优越的性能(尤其是在OULU-NPU数据集的Protocol-1中的0.2% ACER);2)在跨数据集测试中也具有很好的泛化性能(特别是从CASIA-MFSD到Replay-Attack数据集的6.5% HTER)。代码可在https://github.com/ZitongYu/CDCN上获取。
1. 绪论
人脸识别因其便利性已经被广泛应用在许多交互式的人工智能系统中。然而,易受攻击展示攻击(PA)的漏洞限制了它的可靠部署。仅仅向生物识别传感器呈现打印出的照片或者视频就可以欺骗人脸识别系统。展示攻击的典型例子时打印照片,视频回放和3D面具。为了保证人脸识别系统的可靠性,人脸活体检测(FAS)方法是检测这类展示攻击的重要方法。

注释:
VanillaConv是一种基本的卷积神经网络,它只包含卷积层和池化层,没有任何正则化或其他技巧。
图一:普通卷积(VanillaConv)和中心差分卷积(CDC)对于在不同偏移域(照明和输入相机)中欺骗面部的特征响应。普通卷积未能捕捉到一致的欺骗模式,而CDC能够提取不变的详细欺骗特征,例如晶格伪影。
近年来,一些基于[7,8,15,29,45,44]和基于深度学习的[49,64,36,26,62,4,19,20]方法被提出用于表示攻击检测(PAD)。一方面,经典的手工描述符(例如,局部二元模式(LBP)[7])利用邻居之间的局部关系作为鉴别特征,这对于描述生命面孔和欺骗面孔之间的详细不变信息(例如,颜色纹理、莫尔模式和噪声伪影)具有鲁棒性。另一方面,由于具有非线性激活的堆叠卷积操作,卷积神经网络(CNN)具有很强的表示能力来区分真实的和PA。“然而,基于CNN的方法专注于更深层次的语义特征,这些特征在描述生活和欺骗面部之间的详细细粒度信息方面较弱,并且在环境变化(例如,不同的光照)时很容易失效。如何将局部描述符与卷积运算相结合以实现鲁棒的特征表示是一个值得研究的问题。
最近的基于深度学习的FAS方法通常建立在基于图像分类任务的骨干 ·[61,62,20]上,如VGG [54]、ResNet [22]和DenseNet [23]。网络通常由二进制交叉熵损失监督,这很容易学习不重要的信息,如屏幕边框,而不是欺骗模式的本质。为了解决这一问题,我们开发了几种利用伪深度图标签作为辅助监督信号的深度监督FAS方法[4,36]。因此,应考虑通过辅助深度监督来自动发现最适合FAS任务的网络。
“大多数现有的最先进的FAS方法[36、56、62、32]需要多个帧作为输入,以提取动态的时空特征(例如,motion[36、56]和rPPG[62、32])用于PAD。然而,长视频序列可能不适用于需要快速做出决策的特定部署条件。因此,尽管与视频级方法相比性能较差,但基于帧级别的PAD方法从可用性角度来看具有优势。设计高性能的帧级方法对于实际FAS应用至关重要。”
基于上述讨论,我们提出了一种新的卷积算子,称为中心差分卷积(CDC),它很擅长描述细粒度不变信息。如图1所示,在不同的环境中,CDC比普通的卷积更有可能提取内在的欺骗模式(例如,晶格伪影)。此外,在一个专门设计的CDC搜索空间上,利用神经结构搜索(NAS)来发现优秀的帧级网络,用于深度监督的人脸反欺骗任务。我们的贡献包括:
- 我们设计了一种新的卷积算子,称为中心差分卷积(CDC),由于其在不同环境中对不变细粒度特征的显著表示能力,适用于FAS任务。在不引入任何额外参数的情况下,CDC可以取代现有神经网络中普通的普通卷积和即插即用,形成具有更鲁棒建模能力的中心差分卷积网络(CDCN)。
- 我们提出了CDCN++,CDCN的一个扩展版本,由搜索的主干网络和多尺度注意融合模块(MAFM)组成,可以有效地聚合多级CDC特征。
- 据我们所知,这是第一个搜索FAS任务的神经结构的方法。与之前基于softmax损失监督的NAS分类任务不同,我们在一个专门设计的CDC搜索空间上搜索非常适合的帧级网络的深度监督FAS任务。
- 我们提出的方法在所有6个基准数据集上通过内部和跨数据集测试实现了最先进的性能。
2. 相关工作
人脸活体检测
传统的人脸反欺骗方法通常从面部图像中提取手工制作的特征来捕捉欺骗模式。一些经典的局部描述符,如LBP [7,15]、SIFT [44]、SURF [9]、HOG [29]和DoG [45]被用来提取帧级特征,而视频级方法通常捕获动态线索,如动态纹理[28]、微运动[53]和眼睛闪烁[41]。最近,人们提出了一些基于深度学习的帧级和视频级人脸反欺骗的方法。相比之下,引入辅助深度监督FAS方法[4,36]来有效地学习更详细的信息。另一方面,提出了几种视频级CNN方法来利用PAD的动态时空[56,62,33]或rPPG [31,36,32]特征。尽管实现了最先进的性能,基于视频级深度学习的方法需要长序列作为输入。此外,与传统的描述符相比,CNN容易过度拟合,很难在看不见的场景上很好地概括。
卷积运算符
卷积算子是在深度学习框架中提取基本视觉特征的常用方法。最近,有人提出了对普通卷积算子的扩展。在一个方向上,经典的局部描述符(例如,LBP [2]和Gabor滤波器[25])被考虑到卷积设计中。具有代表性的工作包括局部二元卷积[27]和Gabor卷积[38],这分别是为了节省计算成本和提高抗空间变化的能力而提出的。另一个方向是修改聚合的空间范围。两个相关的工作是拨号卷积[63]和可变形卷积[14]。然而,由于对不变细粒度特征的表示能力有限,这些卷积算符可能不适用于FAS任务。
神经架构搜索
我们的工作是受最近对NAS [11,17,35,47,68,69,60]的研究的激励,同时我们专注于寻找一个高性能的深度监督模型,而不是一个人脸反欺骗任务的二元分类模型。现有的NAS方法主要有三类: 1)基于强化学习的[68,69],2)基于[51,52]的进化算法,3)基于梯度的[35,60,12]。大多数NAS方法在一个小的代理任务上搜索网络,并将找到的架构转移到另一个大型目标任务上。从计算机视觉应用的角度来看,NAS已经被开发用于人脸识别[67]、动作识别[46]、人ReID [50]、目标检测[21]和分割[65]任务。据我们所知,目前还没有基于NAS的方法用于人脸反欺骗任务。为了克服上述缺陷,填补空白,我们在一个专门设计的卷积算子上搜索深度监督FAS任务。
3. 方法论
在本节中,我们将首先在3.1节中介绍中心差分卷积,然后在3.2节中介绍用于面反欺骗的中心差分卷积网络(CDCN),最后在3.3节中介绍具有注意机制的搜索网络(CDCN++)。
3.1 中心差分卷积
在现代深度学习框架中,特征映射和卷积以三维形状(二维空间域和额外通道维度)表示。由于卷积操作在整个通道维度上保持相同,为了简单起见,在本小节中,卷积在二维中描述,而扩展到3D是直接的。
基本卷积
由于二维空间卷积是CNN中用于视觉任务的基本操作,这里我们将其表示为普通卷积,并首先对其进行回顾。二维卷积有两个主要步骤:
1)在输入特征图x上采样局部感受域区域R;
2)通过加权求和对采样值进行聚合。因此,输出特征映射y可以表示为
y ( p 0 ) = ∑ p n ∈ R w ( p n ) x ( p 0 + p n ) ( 1 ) y(p_0)=\sum_{p_n\in R}w(p_n) x(p_0+p_n)\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1) y(p0)=pn∈R∑w(pn)x(p0+pn) (1)
其中p0表示输入和输出特征图上的当前位置,而pn枚举R中的位置。例如,3×3核的局部接受域区域1是R={(−1、−1),(−1、0)、···、(0、1)、(1、1)}。
基本卷积结合中心差分操作
受著名的局部二元模式(LBP)[7]的启发,它以二元中心差的方式描述局部关系,我们也在基本卷积中引入中心差分操作,以增强其表示和泛化能力。
同样,中心差分卷积也包括两个步骤,即采样和聚合。采样步长与基本卷积相似,但聚合步骤不同:如图2所示,中心差分卷积更倾向于聚合采样值的中心向梯度。(1)式变为:
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ( x ( p 0 + p n ) − x ( p 0 ) ) ( 2 ) y(p_0)=\sum_{p_n\in R}w(p_n)(x(p_0+p_n)-x(p_0))\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (2) y(p0)=pn∈R∑w(pn)(x(p0+pn)−x(p0)) (2)
当 p n = ( 0 , 0 ) p_n =(0,0) pn=(0,0)时,相对于中心位置 p 0 p_0 p0本身,梯度值始终等于零。
图二如下:
中心差分
在卷积神经网络中,中心差分操作可以通过在卷积核中引入差分核来实现。具体来说,可以在卷积核的中心位置添加一个差分核,用它来计算中心像素点与相邻像素点之间的差分值,然后将这个值加入到原始卷积核的权重中,以达到更好地捕捉图像像素点变化趋势的效果。
以一阶差分为例,假设卷积核的大小为 3 × 3 3\times 3 3×3,则差分核的大小也为 3 × 3 3\times 3 3×3,中心像素的权重为 0 0 0,其余像素的权重为 − 1 -1 −1 或 1 1 1,具体如下所示:
[ − 1 0 1 − 1 0 1 − 1 0 1 ] \begin{bmatrix} -1 & 0 & 1 \\ -1 & 0 & 1 \\ -1 & 0 & 1 \end{bmatrix} −1−1−1000111
在进行卷积运算时,可以将差分核与卷积核按照一定的方式进行叠加,然后再对图像进行卷积运算。具体来说,假设卷积核权重矩阵为 W W W,则卷积运算的输出可以表示为:
y ( p 0 ) = ∑ p n ∈ R ( ∑ i , j W ( i , j ) K ( p n + i , p n + j ) ) x ( p 0 + p n ) y(p_0)=\sum_{p_n\in R}\left(\sum_{i,j}W(i,j)K(p_n+i,p_n+j)\right)x(p_0+p_n) y(p0)=pn∈R∑(i,j∑W(i,j)K(pn+i,pn+j))x(p0+pn)
其中 K K K 表示差分核, W ( i , j ) W(i,j) W(i,j) 表示卷积核的权重值, x ( p 0 + p n ) x(p_0+p_n) x(p0+pn) 表示输入图像中坐标为 p 0 + p n p_0+p_n p0+pn 的像素值, y ( p 0 ) y(p_0) y(p0) 表示卷积运算的输出。
对于人脸活体检测任务而言,无论是强度级别的语义信息还是梯度级别的细节信息,都对区分真实人脸和欺诈人脸具有关键作用,这表明将普通卷积和中心差分卷积相结合可能是提供更强建模能力的可行方式。因此,我们将中心差分卷积推广为:
y ( p 0 ) = θ ∑ p n ∈ R w ( p n ) ( x ( p 0 + p n ) − x ( p 0 ) ) + ( 1 − θ ) ∑ p n ∈ R w ( p n ) x ( p 0 + p n ) ( 3 ) y(p_0)=\theta \sum_{p_n\in R}w(p_n)(x(p_0+p_n)-x(p_0))\\+(1-\theta)\sum_{p_n\in R}w(p_n)x(p_0+p_n) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (3) y(p0)=θpn∈R∑w(pn)(x(p0+pn)−x(p0))+(1−θ)pn∈R∑w(pn)x(p0+pn) (3)
前半部分为中心差分卷积,后半部分为基本卷积,分别捕获梯度级别的细节信息和语义信息
其中,超参数θ∈[0,1]权衡了强度水平和梯度水平信息之间的贡献。θ值越高,说明中心差分梯度信息的重要性越大。今后,我们将把这种广义的中心差分卷积称为CDC,它应该根据其上下文很容易识别。
中心差分卷积的实现
为了在现代深度学习框架中有效地实现CDC,我们对等式进行了分解和合并(3)加入了附加的中心差分项的基本卷积:
y ( p 0 ) = ∑ p n ∈ R w ( p n ) x ( p 0 + p n ) + θ ( − x ( p 0 ) ∑ p n ∈ R w ( p n ) ) ( 4 ) y(p_0)= \sum_{p_n\in R}w(p_n)x(p_0+p_n)+\theta(-x(p_0)\sum_{p_n\in R}w(p_n)) \ \ \ \ \ (4) y(p0)=pn∈R∑w(pn)x(p0+pn)+θ(−x(p0)pn∈R∑w(pn)) (4)
根据等式的说法(4),CDC可以通过PyTorch[42]和TensorFlow[1]中的几行代码轻松实现。等式的推导(4)基于Pytorch的代码如下:

import torch . nn as nn
import torch . nn. functional as F
class CDC (nn.Module):
def __init__ (self,IC,OC,K=3,P=1,theta =0.7):
# IC, OC: in channels , out channels
# K, P: kernel size , padding
# theta : hyperparameter in CDC
super(CDC, self).init ()
self.vani = nn.Conv2d(IC,OC,kernel_size=K, padding=P)
self.theta = theta
def forward(self,x):
# x: input features with shape [N,C,H,W]
out vanilla = self.vani (x)
kernel diff = self.conv.weight.sum(2).sum(2)
kernel diff = kernel diff [:, :, None, None]
out CD = F.conv2d(input=x, weight= kernel_diff , padding=0)
return out vanilla − self.theta ∗ out CD
这段代码定义了一个中心差分卷积(CDC)的 PyTorch 模型类。其主要包括以下组成部分:
init 方法:定义了 CDC 类的初始化函数,输入参数包括输入通道数 IC、输出通道数 OC、卷积核大小 K、填充 P、CDC 超参数 theta 等。在该函数中,首先调用 nn.Module 的初始化函数,然后定义了一个普通卷积 vani,并保存了超参数 theta。
forward 方法:定义了 CDC 模型的前向传播函数,输入参数 x 为输入的特征张量,其形状为 [N,C,H,W],其中 N 为批次大小,C 为输入通道数,H 和 W 分别为输入特征图的高度和宽度。在前向传播过程中,先对输入特征进行普通卷积操作 vani(x) 得到 out_vanilla,然后通过 self.conv.weight 计算出差分核 kernel_diff,并将其应用于输入特征 x 上,得到中心差分卷积的结果 out_CD。最后,将 out_vanilla 减去 theta * out_CD 得到最终输出。
其中,F.conv2d 是 PyTorch 中的卷积函数,self.conv.weight 表示 CDC 模型中的卷积核,None 表示在该位置插入新的维度。super(CDC, self).init() 调用了父类 nn.Module 的 init 函数,nn.Conv2d 定义了普通卷积的操作。
self.conv.weight 表示 CDC 模型中普通卷积操作的卷积核,sum(2).sum(2) 表示在第三个和第四个维度(即高度和宽度维度)上分别做求和操作,得到的 kernel_diff 即为差分核。其中,第三个维度上的求和使得差分核在宽度方向上只有一列,而第四个维度上的求和则使得差分核在高度方向上只有一行,即变成了一个形状为 [OC, IC, 1, 1] 的张量。
接着,kernel_diff[:, :, None, None] 用于在 kernel_diff 张量的第三个和第四个维度上添加新的维度,即将形状变成 [OC, IC, 1, 1],这样就与输入特征的形状相同,可以应用于中心差分卷积操作。
与先前工作的关系
本文讨论了CDC与基本卷积、局部二元卷积[27]和Gabor卷积[38]之间的关系,它们有相似的设计理念,但重点不同。消融研究在第4.3节中显示了CDC在面部抗欺骗任务中的优越性能。
与基本卷积的关系。CDC更通用。从等式(3)上就可以看到当θ = 0时,即聚合没有梯度信息的局部强度信息时,基本卷积是CDC的一种特殊情况。
与Gabor卷积[38]的关系。Gabor卷积(GaborConv)致力于增强空间转换(即方向和尺度变化)的表示能力,而CDC则更专注于在不同环境中表示细粒度的鲁棒特征。
3.2 CDCN
深度监督人脸活体检测方法[36,4]利用基于三维形状的欺骗与活人脸的区分,为FAS模型捕获欺骗线索提供了像素级的详细信息。在此基础上,本文建立了一个类似的深度监督网络深度“[36]”作为基线。为了提取更细粒度和鲁棒的特征来估计人脸深度图,引入CDC形成中心差分卷积网络(CDCN)。注意,当所有CDC操作符使用θ = 0时,DepthNet是提议的CDCN的特殊情况。
CDCN的细节如表1所示。给定一个大小为3×256×256的单一RGB面部图像,提取多层次(低、中、高级)融合特征来预测大小为32×32的灰度面部深度。我们使用θ = 0.7作为默认设置,关于θ的消融研究将在第4.3节中显示。

表1。深度网和CDCN的架构。在方括号内是过滤器的大小和特征维度。所有的卷积层都是步幅=1,然后是一个BN-ReLU层,而最大池化层的步幅=2。
对于损失函数,利用均方误差损失 L M S E L_{MSE} LMSE进行像素级监督。此外,为了FAS任务中的细粒度监督需求,考虑对比深度损失 L C D L L_{CDL} LCDL [56]可以帮助网络学习更详细的特征。因此,整体损失可以表述为 L o v e r a l l = L M S E + L C D L 。 L_{overall}= L_{MSE} + L_{CDL}。 Loverall=LMSE+LCDL。
L C D L L_{CDL} LCDL
CDL损失函数是一种用于深度学习图像分类任务的损失函数。它的全称是"Central Difference Loss",中文翻译为中心差分损失。
CDL损失函数的目标是提高分类模型对于不同类别之间的相似性刻画能力,使得模型在分类时能够更好地区分不同的类别。具体来说,CDL损失函数通过引入一个超参数(即中心差分系数),通过对模型预测结果和真实标签之间的差异进行度量,来衡量不同类别之间的相似度。在CDL损失函数中,如果两个类别在特征空间中距离较近,则它们的相似性会被更强烈地惩罚,从而提高了模型的分类准确性。
具体地,CDL损失函数的计算过程如下:首先计算模型对于输入样本的预测结果,然后根据真实标签和预测结果之间的差异计算一个分类损失。然后,通过对模型中间层的特征图进行中心差分操作,计算出不同类别之间的相似度,最终将相似度加入到分类损失中,得到最终的CDL损失函数。
L C D L = − 1 N ∑ i = 1 N ∑ j = 1 K y i , j log ( exp ( s i , j / τ ) ∑ k = 1 K exp ( s i , k / τ ) ) \mathcal{L_{CDL}}=-\frac{1}{N} \sum{i=1}^{N} \sum_{j=1}^{K} y_{i, j} \log \left(\frac{\exp \left(s_{i, j} / \tau\right)}{\sum_{k=1}^{K} \exp \left(s_{i, k} / \tau\right)}\right) LCDL=−N1∑i=1Nj=1∑Kyi,jlog(∑k=1Kexp(si,k/τ)exp(si,j/τ))
其中, L C D L \mathcal{L_{CDL}} LCDL表示CDL的损失函数, N N N表示样本数量, K K K表示类别数量, y i , j y{i,j} yi,j表示第 i i i个样本的第 j j j个类别的真实标签(取值为0或1), s i , j s_{i,j} si,j表示第 i i i个样本的第 j j j个类别的输出结果, τ \tau τ表示温度参数, exp \exp exp表示指数函数, ∑ \sum ∑表示求和运算, log \log log表示自然对数。
3.3 CNDC++
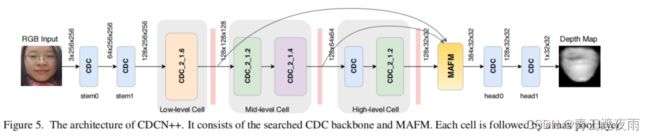
从表1可以看出,CDCN的架构设计粗糙(例如,简单地对不同级别重复相同的块结构),这可能对面部反欺骗任务进行了次优化。受经典的视觉对象理解模型 [40] 的启发,我们提出了一个扩展版本的 CDCN++(见图5),它由一个基于 NAS 的骨干网络和具有选择性注意力容量的多尺度注意力融合模块(MAFM)组成。
面部反欺诈任务的骨干网络搜索
我们的搜索算法是基于两种基于梯度的NAS方法[35,60],更多的技术细节可以参考原始论文。这里我们主要介绍了关于FAS任务搜索骨干的新贡献。
NAS 是 Neural Architecture Search 的缩写,中文翻译为神经网络架构搜索。它是一种自动化的深度学习方法,通过搜索最优的神经网络架构来提高深度学习模型的性能。在 NAS 中,利用启发式算法、进化算法、强化学习等方法来探索大量的神经网络结构空间,并从中挑选出表现最佳的网络结构。通过 NAS,可以加速深度学习模型的设计和优化,使其更适合特定的任务和数据集。
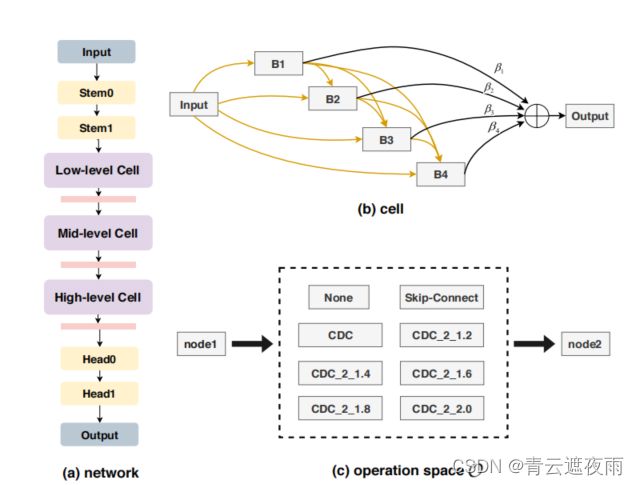
图3. 使用CDC的架构搜索空间。(a)一个由三个堆叠的cell组成的网络,其中stem和head层采用了具有3x3核和θ = 0.7的CDC。(b) 一个cell包含6个节点,包括一个输入节点,四个中间节点B1,B2,B3,B4和一个输出节点。
(c ) 两个节点之间的边表示可能的操作。操作空间包括八个候选项,其中CDC_2_r表示首先使用两个堆叠的CDC以比例r增加通道数量,然后再降回原始通道大小。总搜索空间的大小为3×8×10 = 240。
如图3(a)所示,其目标是搜索三个层次(低、中、高层次)的细胞,形成FAS任务的网络主干。受人类视觉系统[40]中专用的分层组织神经元的启发,我们更倾向于自由地搜索这些多层次的细胞(即,结构不同的细胞),这更灵活和广义。我们将这种配置命名为“可变单元格”,并将在Sec中研究它的影响。4.3(请参见表2).与之前的工作[35,60]不同,我们只采用最新入入单元的一个输出作为当前单元的输入。
对于单元级结构,图3(b)显示,每个单元被表示为N个节点 { X } i = 0 N − 1 {\{X\}}^{N-1}_{i=0} {X}i=0N−1的有向无环图(DAG),其中每个节点代表一个网络层。我们将操作空间表示为 O O O,图3©显示了8个设计好的候选操作(无、跳过连接和CDC连接)特别地,每条边 ( i , j ) (i,j) (i,j)都可以用一个函数 o ˜ ( i , j ) o˜^{(i,j)} o˜(i,j)来表示,其中 o ˜ ( i , j ) ( x i ) = ∑ o ∈ O η o ( i , j ) ⋅ o ( x i ) o˜^{(i,j)}(xi)=\sum_{o∈O}η^{(i,j)}_o·o(x_i) o˜(i,j)(xi)=∑o∈Oηo(i,j)⋅o(xi)。Softmax函数被用来将架构参数 α ( i , j ) \alpha^{(i,j)} α(i,j)映射为操作权重 o ∈ O o∈O o∈O,即 η o ( i , j ) = e x p ( α ( i , j ) ) ∑ o ′ ∈ O e x p ( α o ′ ( i , j ) ) η^{(i,j)}_o=\frac{exp(\alpha^{(i,j)})}{\sum{o'\in O}exp(\alpha^{(i,j)}_{o'})} ηo(i,j)=∑o′∈Oexp(αo′(i,j))exp(α(i,j))。中间节点可以表示为 x j = ∑ i < j o ˜ ( i , j ) ( x i ) x_j=\sum_{i
在搜索阶段, L t r a i n L_{train} Ltrain和 L v a l L_{val} Lval分别表示训练损失和验证损失,它们都基于第3.2节中描述的深度监督损失函数 L o v e r a l l L_{overall} Loverall。网络参数w和架构参数α通过以下双层优化问题进行学习:
m i n α L v a l ( w ∗ ( α ) , α ) s . t . w ∗ ( α ) = a r g m i n w L t r a i n ( w , α ) ( 5 ) min_\alpha \ \ \ \ \ \ \ \ L_{val}(w^*(\alpha),\alpha)\\ s.t. \ \ \ w^*(\alpha)=argmin_w \ L_{train}(w,\alpha)\ \ \ \ \ \ \ (5) minα Lval(w∗(α),α)s.t. w∗(α)=argminw Ltrain(w,α) (5)
这个公式描述了一个双层优化问题,其中外层问题最小化验证损失 L v a l ( w ∗ ( α ) , α ) L_{val}(w^*(\alpha),\alpha) Lval(w∗(α),α),其中 w ∗ ( α ) w^*(\alpha) w∗(α)表示通过内层问题解决方案来优化的网络参数,也就是通过最小化训练损失 L t r a i n ( w , α ) L_{train}(w,\alpha) Ltrain(w,α)找到的参数,即 w ∗ ( α ) = a r g m i n w L t r a i n ( w , α ) w^*(\alpha)=argmin_w L_{train}(w,\alpha) w∗(α)=argminwLtrain(w,α)。内层问题的解决方法通常是通过梯度下降等优化算法来实现。因此,通过解决内层问题来学习网络参数 w w w,再将其用于解决外层问题,以最小化验证损失 L v a l L_{val} Lval。这种优化方式被称为“学习如何学习”。
在收敛后,最终的离散架构是通过以下步骤得出的:1)设置 o ( i , j ) = a r g m a x o ∈ O , o ≠ n o n e p o ( i , j ) o^{(i,j)}=argmax_{o\in O,o\neq none} p_o^{(i,j)} o(i,j)=argmaxo∈O,o=nonepo(i,j);2)对于每个中间节点,选择具有最大值 m a x o ∈ O , o ≠ n o n e p o ( i , j ) max_{o \in O,o\neq none}p_o^{(i,j)} maxo∈O,o=nonepo(i,j)的一个入边,3)对于每个输出节点,选择具有最大值 m a x 0 < i < N − 1 β i max_{0
MAFM
虽然简单地融合低-中-高级别的特征可以提高搜索的CDC架构的性能,但仍然很难找到重要的重要区域,这不利于学习更多的区别特征。受人类视觉系统中的选择性注意力[40, 55]的启发,不同层级的神经元可能在其感受野内具有各种注意力的刺激。因此,我们提出了一个多尺度注意力融合模块(MAFM),它能够通过空间注意力对低-中-高级别CDC特征进行细化和融合。
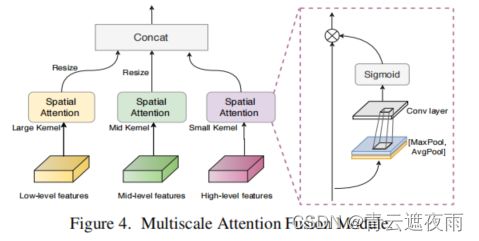
如图4所示,不同层次的特征F通过与感受野相关的核大小(即,在我们的情况下,高/语义级别应该具有较小的注意力核大小,而低级别则具有较大的注意力核大小)进行空间注意力[58]的细化,然后拼接在一起。经过细化的特征 F ′ F' F′可以表示为:
F i ′ = F i ⊙ ( σ ( C i ( [ A ( F i ) , M ( F i ) ] ) ) ) , i ∈ { l o w , m i d , h i g h } ( 6 ) F'_i=F_i\odot (σ(C_i([A(F_i),M(F_i)]))),i\in\{low,mid,high\} \ \ \ \ \ \ \ (6) Fi′=Fi⊙(σ(Ci([A(Fi),M(Fi)]))),i∈{low,mid,high} (6)
其中, ⊙ \odot ⊙表示Hadamard积。A和M分别表示平均池化和最大池化层。σ表示sigmoid函数,而C表示卷积层。对于Clow,使用7×7的普通卷积核;对于 C m i d C_{mid} Cmid,使用5×5的普通卷积核;对于 C h i g h C_{high} Chigh,则使用3×3的普通卷积核。CDC在这里没有被选择,因为其全局语义认知能力有限,在空间注意力中非常重要。相应的消融研究将在第4.3节中进行。
4. 实验
在本节中,我们进行了广泛的实验,以展示我们方法的有效性。接下来,我们将按顺序描述所使用的数据集和指标(第4.1节),实现细节(第4.2节),结果(第4.3-4.5节)和分析(第4.6节)。
4.1 数据集和指标
数据库
我们的实验使用了六个数据库,分别是OULU-NPU [10],SiW [36],CASIA-MFSD [66],Replay-Attack [13],MSU-MFSD [57]和SiW-M [37]。OULU-NPU和SiW是高分辨率数据库,分别包含四个和三个协议以验证模型的泛化性(例如,未见过的照明和攻击媒介),用于内部测试。CASIA-MFSD、Replay-Attack和MSU-MFSD是包含低分辨率视频的数据库,用于交叉测试。SiW-M旨在进行跨类型测试,以验证对未知攻击的鲁棒性,其中包含多达13种攻击类型。
性能指标
在OULU-NPU和SiW数据集中,我们遵循原始的协议和指标,即攻击呈现分类错误率(APCER)、真实呈现分类错误率(BPCER)和ACER[24]进行公平的比较。案例与重复攻击的交叉测试采用半总错误率(HTER)。利用曲线下面积(AUC)对CASIA-MFSD、重放-攻击和MSU-MFSD进行数据库内跨型测试。对于SiW-M的跨型测试,采用了APCER、BPCER、宏碁和等错误率(EER)。
4.2 实现细节
深度生成
采用密集的面部对齐PRNet [18]来估计活体脸部的三维形状并生成大小为32×32的面部深度图。更多细节和示例可以在[56]中找到。为了区分真实的面部和欺骗的面部,在训练阶段,我们将真实的深度图归一化到[0,1]范围内,而将欺骗的深度图设置为0,这与[36]类似。
训练和测试设置
我们提出的方法使用Pytorch实现。在训练阶段,使用Adam优化器训练模型,初始学习率(lr)和权重衰减(wd)分别为1e-4和5e-5。我们最多训练1300个epoch,每500个epoch学习率减半。批量大小为56,使用八个1080Ti GPU。在测试阶段,我们计算预测深度图的平均值作为最终得分。
搜索设置
与[60]类似,采用了部分通道连接和边缘归一化。网络的初始通道数为{32、64、128、128、128、64、1},在搜索后加倍(参见图3(a))。训练模型权重时使用lr=1e-4和wd=5e-5的Adam优化器。使用lr=6e-4和wd=1e-3的Adam优化器训练体系结构参数。在OULU-NPU的Protocol-1上使用批量大小为12进行60个epoch的搜索,前10个epoch不更新架构参数。整个过程在三个1080Ti上花费了一天时间。
4.3 消融实验
在本小节中,我们对我们提出的CDC、CDCN和CDCN++进行了所有消融实验,以探索它们的细节,所有实验均在OULU-NPU [10]的Protocol-1上进行,该协议在训练集和测试集之间具有不同的照明条件和位置。
θ θ θ对CDCN的影响
根据等式(3),θ控制了基于梯度的细节的贡献,即θ越高,所包含的局部详细信息就越多。如图6(a)所示,当θ > 0.3时,CDC总是比普通卷积(θ = 0,ACER=3.8%)获得更好的性能,这表明基于细粒度信息的中心差异对FAS任务很有帮助。由于在θ=为0.7时获得了最佳性能(ACER=1.0%),因此我们使用此设置进行以下实验。除了保持所有层的θ不变外,我们还探索了一种自适应CDC方法来学习每个层的θ,如附录B所示。
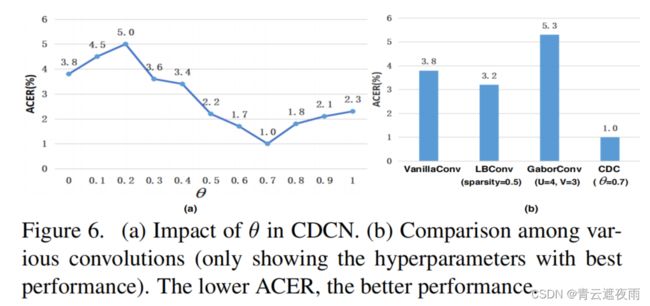
图6。(a)在CDCN中对θ的影响。(b)不同卷积之间的比较(仅显示性能最好的超参数)。ACER性能越低,性能越好。
CDC vs 其他卷积
在第3.1节中讨论了CDC与之前的卷积之间的关系,我们认为针对面部反欺诈任务,CDC更适合,因为在不同环境中详细的欺诈伪影应该由基于梯度的不变特征来表示。图6(b)显示,CDC的性能优于其他卷积,优势超过2%的ACER。有趣的是发现,LBConv的表现优于普通卷积,这表明对于FAS任务来说,局部梯度信息很重要。GaborConv表现最差,因为它是设计用来捕捉空间不变特征的,而在面部反欺诈任务中并没有帮助。
NAS配置的影响

表2展示了关于第3.3节中描述的两种NAS配置的消融研究,即不同的细胞和节点注意力。与基线设置(共享细胞和最后一个中间节点作为输出节点)相比,这两种配置都可以提高搜索性能。原因有两个:1)使用更灵活的搜索约束,NAS能够找到不同级别的专用细胞,更接近人类视觉系统[40],2)将最后一个中间节点作为输出可能不是最优选择,而选择最重要的一个更合理。
基于NAS的主干和MAFM的有效性
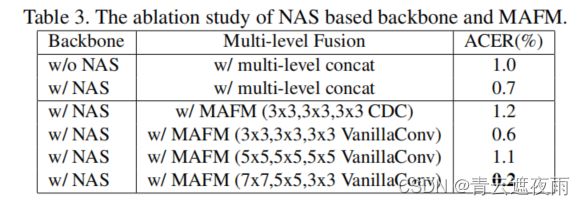
所提出的CDCN++包括基于NAS的骨干网络和MAFM,如图5所示。显然,来自多个层级的细胞非常不同,中间层细胞具有更深的(四个CDC)层。表3显示了关于基于NAS的骨干网络和MAFM的消融研究。从前两行可以看出,具有直接多级融合的NAS基础网络比没有NAS的基础网络表现更好(0.3%的ACER),表明我们搜索到的架构的有效性。同时,具有MAFM的骨干网络比具有直接多级融合的骨干网络ACER低0.5%,这表明MAFM的有效性。我们还分析了MAFM中的卷积类型和卷积核大小,发现普通卷积更适合捕捉语义空间注意力。此外,注意力卷积核的大小对于低级特征应该足够大(7x7),对于高级特征应该足够小(3x3)。
4.4 内部测试
在OULU-NPU和SiW数据集上都进行了内部测试。我们严格遵循OULU-NPU的四种协议和SiW的三个协议进行评估。包括STASN [62]在内的所有比较方法都在没有额外数据集的情况下进行训练,以进行公平的比较。
在OULU-NPU上的结果
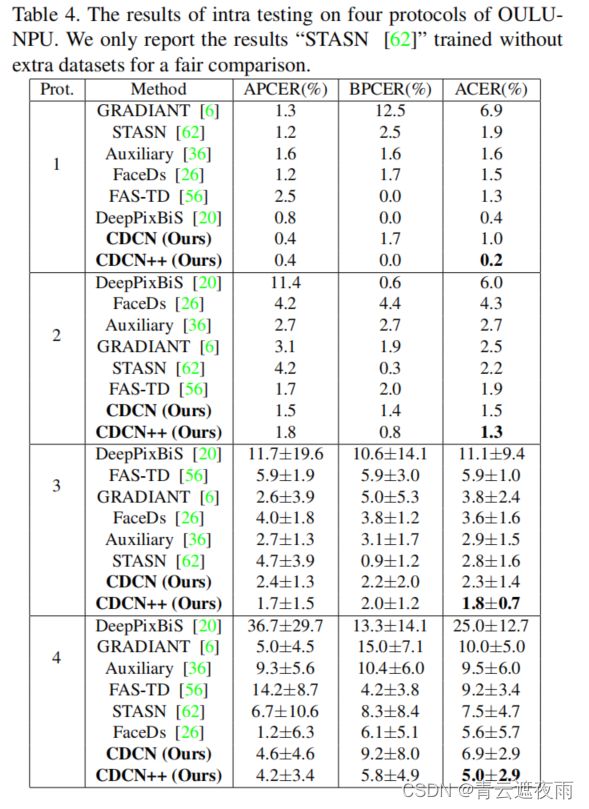
在表4中,我们提出的CDCN ++在所有4个协议(分别为0.2%,1.3%,1.8%和5.0%ACER)上排名第一,这表明该方法在外部环境、攻击媒介和输入相机变化的泛化方面表现良好。与其他提取多帧动态特征的先进方法(Auxiliary [36],STASN [62],GRADIANT [6]和FAS-TD [56])不同,我们的方法只需要帧级输入,非常适合实际部署。值得注意的是,尽管NAS基础架构是在Protocol-1上搜索的,但它对于所有协议都是可转移的,并具有良好的普适性。
在SiW上的结果。表5将我们的方法与三种最先进的方法Auxiliary [36],STASN [62]和FAS-TD [56]在SiW数据集上的表现进行了比较。从表5可以看出,我们的方法在所有三个协议上表现最好,揭示了CDC在(1)面部姿势和表情变化,(2)不同欺骗媒介的变化,以及(3)交叉/未知表示攻击方面的出色泛化能力。
在SiW上的结果
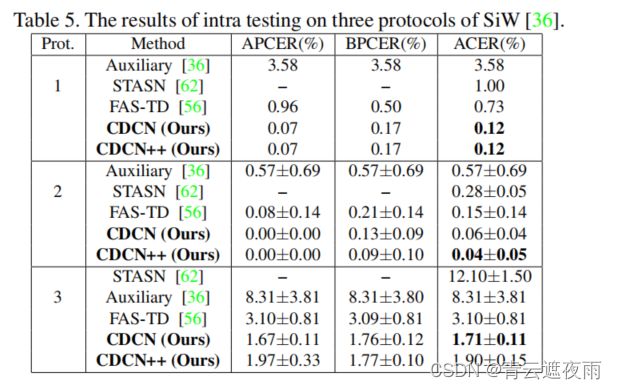
表5将我们的方法与三种最先进的方法Auxiliary [36],STASN [62]和FAS-TD [56]在SiW数据集上的性能进行了比较。从表5可以看出,我们的方法在所有三个协议中表现最好,揭示了CDC的出色的泛化能力,适用于(1)面部姿势和表情的变化,(2)不同的欺骗媒介的变化,(3)交叉/未知的攻击呈现。
4.5 交叉测试
为了进一步证明我们的模型的泛化能力,我们分别进行了跨类型和跨数据集测试,以验证其对未知表示攻击和看不见环境的泛化能力。
跨类型测试

根据[3]中提出的协议,我们使用CASIA-MFSD [66]、Replay-Attack [13]和MSU-MFSD [57]在重放攻击和印刷攻击之间执行数据集内跨类型测试。如表6所示,我们提出的基于CDC的方法在整体性能上表现最佳(甚至超过了基于零样本学习的方法DTN [37]),表明我们具有一致的对未知攻击的良好泛化能力。此外,我们还在最新的SiW-M [37]数据集上进行了跨类型测试,并在13种攻击中实现了最佳的平均ACER(12.7%)和EER(11.9%)。详细结果请参见附录C。
跨数据集测试
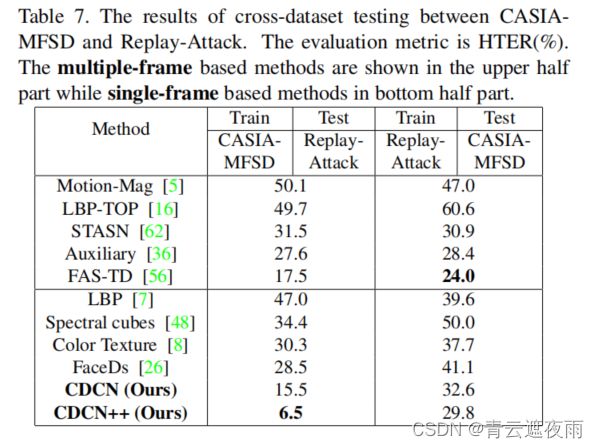
在这个实验中,有两个跨数据集测试协议。一个是在CASIA-MFSD上进行训练,然后在Replay-Attack上进行测试,被命名为协议CR;第二个是交换训练数据集和测试数据集,被命名为协议RC。如表7所示,我们提出的CDCN++在协议CR上的HTER为6.5%,比之前的最先进方法高出了11%的巨大优势。对于协议RC,我们也超过了最先进的帧级方法(见表7的后半部分)。通过引入Auxiliary[36]和FAS-TD[56]中的类似时间动态特征,性能可能进一步提高。
4.6 分析和可视化
在本小节中,我们提供了两个观点来演示为什么CDC表现良好的分析。
对领域漂移的鲁棒性。

OULU-NPU的协议1用于验证CDC在遇到领域漂移(即训练/开发集和测试集之间存在巨大的照明差异)时的鲁棒性。图7显示,使用普通卷积的网络在开发集上具有低的ACER(蓝色曲线),而在测试集上具有高的ACER(灰色曲线),这表明普通卷积很容易在已知领域中过拟合,但在照明发生变化时泛化能力差。相比之下,具有CDC的模型能够在开发集(红色曲线)和测试集(黄色曲线)上实现更一致的性能,表明CDC对领域漂移具有鲁棒性。
特征可视化
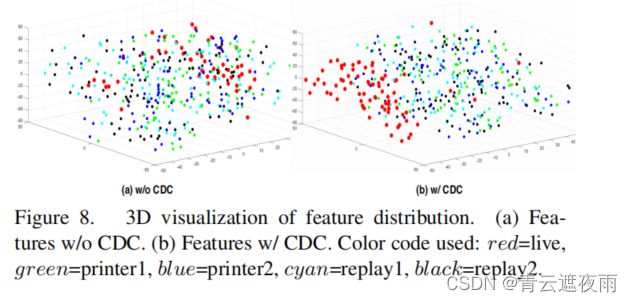
图8展示了在OULU-NPU协议1上使用t-SNE [39]对测试视频的多级融合特征分布的情况。从图8(a)可以看出,使用CDC的特征呈现出比使用普通卷积更好的聚类行为,而图8(b)则相反。这说明了CDC的区分真实人脸和假人脸的能力。有关MAFM的特征图(带/不带CDC)和注意力图的可视化可以在附录D中找到。
5. 总结和未来的工作
本文提出了一种用于人脸反欺诈任务的新型算子,称为中心差分卷积(Central Difference Convolution,CDC)。基于CDC,设计了一种中央差分卷积网络(CDCN)。我们还提出了CDCN++,包括一个经过搜索的CDC主干和多尺度注意力融合模块(Multiscale Attention Fusion Module,MAFM)。通过大量实验证明了所提出方法的有效性。我们指出,CDC的研究仍处于早期阶段。未来的方向包括:1)为每个层/通道设计上下文感知的自适应CDC;2)探索其他属性(例如域泛化)以及在其他视觉任务(例如图像质量评估[34]和面部疑似检测)中的适用性。
6. 致谢
本研究得到了芬兰学院的MiGA项目(授权号316765)、ICT 2023项目(授权号328115)和Infotech Oulu的支持。此外,作者们还要感谢芬兰CSC IT Center提供的计算资源。
引用
引用过多这里不进行展示,详情见**文章原文和模型源码:https://github.com/ZitongYu/CDCN**
附录
A. CDC的推导和代码
在这里,我们展示CDC在公式(7)中的详细推导(见草稿中的公式(4)),以及CDC在Pytorch中的代码(见图9)。

可复制代码见上文

B. CDC的自适应θ
虽然对于人脸反欺诈任务,最佳超参数θ = 0.7可以手动测量,但是当将中心差分卷积(CDC)应用于其他数据集/任务时,找到最适合的θ仍然是麻烦的。在这里,我们将θ视为每个层的数据驱动可学习权重。一种简单的实现方法是利用Sigmoid(θ)来确保输出范围在[0,1]之内。
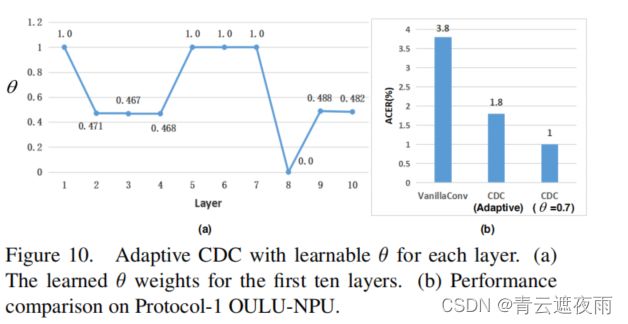
如图10(a)所示,有趣的是,低(第2至第4层)和高(第8至第10层)级别的学习权重相对较小,而中(第5至第7层)级别的学习权重较大。这表明,对于中等级别的特征,中心差分梯度信息可能更加重要。在性能比较方面,从图10(b)可以看出,自适应CDC具有可比性的结果(1.8%对1.0% ACER),而CDC使用恒定的θ = 0.7。
C.在SiW-M数据集上进行交叉类型测试

在SiW-M数据集[37]上,我们按照相同的跨类型测试协议(13种攻击分别测试)将我们的提出的方法与三种最新的人脸反欺诈方法[10, 36, 37]进行比较,以验证对未见过的攻击的泛化能力。如表8所示,我们的CDCN++取得了更好的ACER和EER,相对于先前最先进的方法[37],分别提高了24%和26%。具体来说,我们几乎检测到所有的“身份冒充”和“部分纸张”攻击(EER = 0%),而之前的方法在“身份冒充”攻击上表现很差。显然,我们显着降低了面具攻击(“HalfMask”,“SiliconeMask”,“TransparentMask”和“MannequinHead”)的EER和ACER,这表明我们基于CDC的方法在3D非平面攻击上具有很好的泛化性。
D. 特征可视化
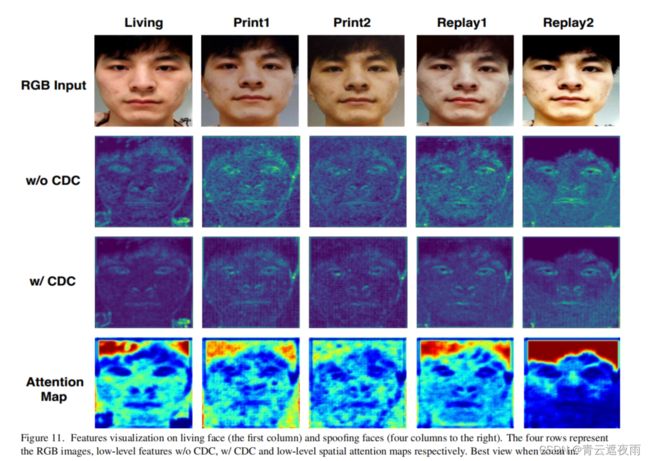
图11展示了MAFM的低级特征和对应的空间注意力图。很明显,活体和欺诈面孔之间的特征和注意力图有很大不同。1)对于低级特征(见图11的第二行和第三行),来自欺诈面孔的神经激活在面部和背景区域之间似乎更加均匀,而来自活体面孔的神经激活更集中在面部区域。值得注意的是,使用CDC的特征更容易捕捉到详细的欺诈模式(例如“Print1”中的网格伪影和“Replay2”中的反射伪影)。2)对于MAFM的空间注意力图(见图11的第四行),活体面孔的所有区域(头发、面部和背景)都有相对强的激活,而欺诈面孔的面部区域对激活的贡献较弱。