【计组】CPU并行方案--《深入浅出计算机组成原理》(四)
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间
一、Superscalar和VLIW
程序的 CPU 执行时间 = 指令数 × CPI × Clock Cycle Time
CPI 的倒数,又叫作 IPC(Instruction Per Clock),也就是一个时钟周期里面能够执行的指令数,代表了 CPU 的吞吐率。
(一)多发射和超标量
指令的执行阶段,是由很多个功能单元(FU)并行(Parallel)进行的。取指令(IF)和指令译码(ID)部分,也一样能通过增加硬件的方式,并行进行。
一次性从内存里面取出多条指令,然后分发给多个并行的指令译码器,进行译码,然后对应交给不同的功能单元去处理。这样,在一个时钟周期里,能够完成的指令就不只一条了。IPC 也就能做到大于 1 了。这种 CPU 设计,叫作多发射(Mulitple Issue)和超标量(Superscalar)
多发射就是同一个时间,可能会同时把多条指令发射(Issue)到不同的译码器或者后续处理的流水线中去。
超标量是说在一个时钟周期里面,只能执行一个标量(Scalar)的运算。多发射的情况下,能够超越这个限制,同时进行多次计算。
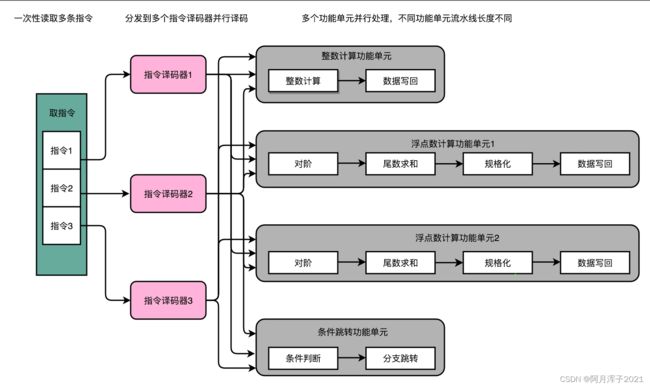
实现多发射和超标量需要CPU 在指令执行之前,去判断指令之间是否有依赖关系。如果有对应的依赖关系,指令就不能分发到执行阶段。因此超标量 CPU 的多发射功能,又被称为动态多发射处理器。这些对于依赖关系的检测,都会使得 CPU 电路变得更加复杂。
(二)VLIW超长指令字设计
超长指令字设计(Very Long Instruction Word,VLIW)是一个非常大胆的CPU设计想法,这个设计,不仅想让编译器来优化指令数,还想直接通过编译器,来优化 CPI。
在乱序执行和超标量的 CPU 架构里,指令的前后依赖关系,是由 CPU 内部的硬件电路来检测的。而到了超长指令字的架构里面,这个工作交给了编译器这个软件。
编译器在高级代码转换到汇编代码再转换到机器码的过程中,其实是能够知道前后数据的依赖关系的。因此,超长指令字设计采取了让编译器把没有依赖关系的代码位置进行交换,再把多条连续的指令打包成一个指令包的方案。
CPU 在运行的时候,不再是取一条指令,而是取出一个指令包。然后,译码解析整个指令包,解析出多条指令直接并行运行。使用超长指令字架构的 CPU,同样是采用流水线架构的。也就是说,一组(Group)指令,仍然要经历多个时钟周期。同样的,下一组指令并不是等上一组指令执行完成之后再执行,而是在上一组指令的指令译码阶段,就开始取指令了。
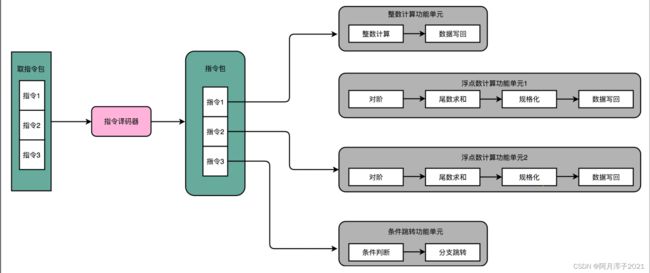
流水线停顿这件事情在超长指令字里面,很多时候也是由编译器来做的。除了停下整个处理器流水线,超长指令字的 CPU 不能在某个时钟周期停顿。编译器需要在适当的位置插入 NOP 操作,直接在编译出来的机器码里面,就把流水线停顿这个事情在软件层面就安排妥当。
VLIW 在技术层面非常具有颠覆性,不仅仅只是一个硬件层面的改造,而且利用了软件层面的编译器,来组合解决提升 CPU 指令吞吐率的问题。然而,最终 VLIW 却没有得到市场和业界的认可。
VLIW 架构决定了,如果CPU需要提升并行度,就需要增加一个指令包里包含的指令数量,比方说从 3 个变成 6 个。一旦这么做了,虽然同样 VLIW 架构,同样指令集的CPU,程序也需要重新编译。因为原来编译器判断的依赖关系是在 3 个指令以及由 3 个指令组成的指令包之间,现在要变成 6 个指令和 6 个指令组成的指令包。编译器需要重新编译,交换指令顺序以及 NOP 操作,才能满足条件。甚至,需要重新来写编译器,才能让程序在新的 CPU 上跑起来,很难实现兼容。
二、如何加速矩阵乘法
(一)超线程
无论是多个 CPU 核心运行不同的程序,还是在单个 CPU 核心里面切换运行不同线程的任务,在同一时间点上,一个物理的 CPU 核心只会运行一个线程的指令,所以其实我们并没有真正地做到指令的并行运行。
超线程的 CPU,是把一个物理层面的 CPU 核心,“伪装”成两个逻辑层面的 CPU 核心。这个 CPU,会在硬件层面增加很多电路,使得一个 CPU 核心内部可以维护两个不同线程指令的状态信息。
比如,在一个物理 CPU 核心内部,会有双份的 PC 寄存器、指令寄存器乃至条件码寄存器。这样,这个 CPU 核心就可以维护两条并行的指令的状态。在外面看起来,似乎有两个逻辑层面的 CPU 在同时运行。所以,超线程技术一般也被叫作同时多线程(Simultaneous Multi-Threading,简称 SMT)技术。
不过,在 CPU 的其他功能组件上,无论是指令译码器还是 ALU,一个 CPU 核心仍然只有一份。因为超线程并不是真的去同时运行两个指令,那就变成物理多核了。超线程的目的,是在一个线程 A 的指令,在流水线里停顿的时候,让另外一个线程去执行指令。因为这个时候,CPU 的译码器和 ALU 就空出来了,那么另外一个线程 B,就可以拿来干自己需要的事情。这个线程 B 可没有对于线程 A 里面指令的关联和依赖。
超线程只在特定的应用场景下效果比较好。一般是在那些各个线程“等待”时间比较长的应用场景下。比如,需要应对很多请求的数据库应用,就很适合使用超线程。各个指令都要等待访问内存数据,但是并不需要做太多计算。
(二)SIMD--单指令多数据流
使用循环一步一步计算的算法,一般被称为 SISD,也就是单指令单数据(Single Instruction Single Data)处理方式。多核 CPU 同时处理多个指令的方式可以叫作 MIMD,也就是多指令多数据(Multiple Instruction Multiple Data)。
SIMD,中文叫作单指令多数据流(Single Instruction Multiple Data)。是一种“指令级并行”的加速方案,或者我们可以说,它是一种“数据并行”的加速方案。在处理向量计算时,同一向量不同维度之间的计算是相互独立的。而的 CPU 里的寄存器,又能放得下多条数据,因此可以一次性取出多条数据,交给 CPU 并行计算。(SIMD 在获取数据和执行指令的时候,都做到了并行)
对于那些在计算层面存在大量“数据并行”(Data Parallelism)的计算中,使用 SIMD 是一个很划算的办法。大量的“数据并行”,其实通常就是实践当中的向量运算或者矩阵运算。在实际的程序开发过程中,过去通常是在进行图片、视频、音频的处理。最近几年则通常是在进行各种机器学习算法的计算。
基于 SIMD 的向量计算指令,正是在 Intel 发布 Pentium 处理器的时候,被引入的指令集。当时的指令集叫作 MMX,也就是 Matrix Math eXtensions 的缩写,中文名字就是矩阵数学扩展。
正是 SIMD 技术的出现,使得Pentium 时代的个人 PC,开始有了多媒体运算的能力。可以说,Intel 的 MMX、SSE 指令集,和微软的 Windows 95 这样的图形界面操作系统,推动了 PC 快速进入家庭的历史进程。
【SIMD在程序中的应用:C# 使用SIMD系列方法加速批量运算 - 知乎】
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间