【机器学习】LR和线性回归讲解,区别
前言
回归算法是一种通过最小化预测值与实际结果值之间的差距,而得到输入特征之间的最佳组合方式的一类算法。对于连续值预测有线性回归等,而对于离散值/类别预测,我们也可以把逻辑回归等也视作回归算法的一种。
线性回归与逻辑回归是机器学习中比较基础又很常用的内容。线性回归主要用来解决**连续值预测**的问题,逻辑回归用**来解决分类的问题**,输出的属于某个类别的概率,工业界经常会用逻辑回归来做排序。
1. 线性回归
1.1 线性回归问题
线性回归,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w’x+e,e为误差服从均值为0的正态分布。中学就有接触线性回归,那么线性回归应用在什么地方呢?它适用于有监督学习的预测。
一元线性回归分析:y=ax+by=ax+b,包括两个或两个以上的自变量,并且因变量和自变量是线性关系。
1.2 损失函数
损失函数:是指一种将一个事件(在一个样本空间中的一个元素)映射到一个表达与其事件相关的经济成本或机会成本的实数上的一种函数。更通俗地说,损失函数用来衡量参数选择的准确性。损失函数定义为:
J(θ0,θ1,...,θn)=12m∑i=1m(hθ(x(i))−y(i))2J(θ0,θ1,...,θn)=12m∑i=1m(hθ(x(i))−y(i))2
这个公式计算的是线性回归分析的值与实际值的距离的平均值。显然,损失函数得到的值越小,损失也就越小。
1.3 梯度下降
怎样最小化损失函数?损失函数的定义是一个凸函数,就可以使用凸优化的一些方法:
1) 梯度下降:逐步最小化损失函数的过程。如同下山的过程,找准下山方向(梯度),每次迈进一步,直至山底。如果有多个特征,对应多个参数θθ,比如0.01。下图展示了梯度下降的过程。

2) 牛顿法:速度快适用于小数据,大数据比较耗内存。
1.4 过拟合与正则化
回归与欠/过拟合:
1) 欠拟合:函数假设太简单导致无法覆盖足够的原始数据,可能造成数据预测的不准确。
2) 拟合问题:比如我们有很多的特征,假设的函数曲线对原始数据拟合的非常好,从而丧失一般性,导致对新给的待预测样本,预测效果差。下图就是一个例子,一个复杂的曲线,把所有点都拟合进去了,但是泛化能力变差了,没有得到一个规律性的函数,不能有效的预测新样本。
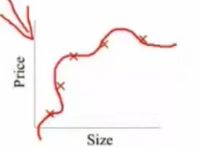
过拟合解决方法:
1) 减少特征个数:手工选择保留特征、模型选择的算法选择特征。
2) 正则化:在原来的损失函数中加入θθ
即L2正则化。留下所有的特征,但是减少参数的大小。
2. 逻辑(斯特)回归
2.1 应用分析
与线性回归不同,逻辑回归主要用于解决分类问题,那么线性回归能不能做同样的事情呢?下面举一个例子。比如恶性肿瘤和良性肿瘤的判定。假设我们通过拟合数据得到线性回归方程和一个阈值,用阈值判定是良性还是恶性:
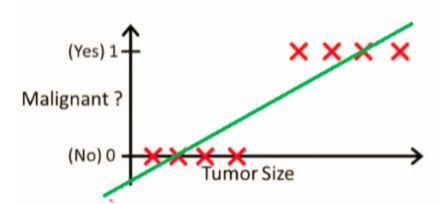
如图,size小于某值就是良性,否则恶性。但是“噪声”对线性方程的影响特别大,会大大降低分类准确性。例如再加三个样本就可以使方程变成这样:
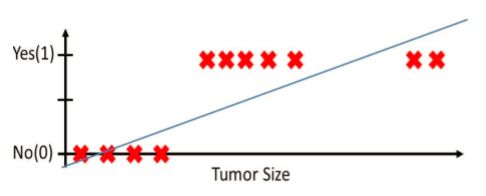
那么,逻辑斯特回归是怎么做的呢?如果不能找到一个绝对的数值判定肿瘤的性质,就用概率的方法,预测出一个概率,比如>0.5判定为恶性的。
2.2 Sigmoid函数
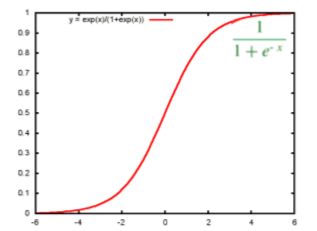
逻辑回归首先把样本映射到[0,1]之间的数值,这就归功于sigmoid函数,可以把任何连续的值映射到[0,1]之间,数越大越趋向于0,越小越趋近于1。Sigmoid函数公式如下:
g(z)=11+e−zg(z)=11+e−z
函数的图像如下图,x=0的时候y对应中心点。
判定边界:对多元线性回归方程求Sigmoid函数hθ(x)=g(θ0+θ1x1+...+θnxn)hθ(x)=g(θ0+θ1x1+...+θnxn)的直线,把样本分成两类。把(1,1)代入g函数,概率值<0.5,就判定为负样本。这条直线就是判定边界,如下图:
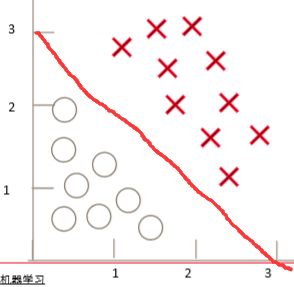
除了线性判定边界,还有较复杂的非线性判定边界。
2.3 逻辑回归的损失函数
线性回归的损失函数对逻辑回归不可用,因为逻辑回归的值是0或者1,求距离平均值会是一条不断弯曲的曲线,不是理想的凸函数。聪明的数学家找到了一个适合逻辑回归的损失定义方法:
Cost(hθ(x),y)={−log(hθ(x)),−log(1−hθ(x)),if y=1if y=0Cost(hθ(x),y)={−log(hθ(x)),if y=1−log(1−hθ(x)),if y=0
这个函数依然可以用梯度下降求解。
2.4 多分类问题
刚才讲述的都是二分类的问题,那如果是多分类的问题,又该怎么做呢?其实可以套用二分类的方法,根据特征,一层层细化类别。比如下图中有三种形状:
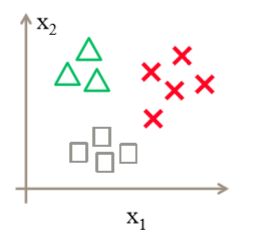
可以先用一个分类器区分“正方形”和“非正方形”,再用一个分类器对非正方形区分,得到“三角形”和“非三角形”,然后再用一个分类器区分叉。
3. 工程应用经验
逻辑斯特回归(LR)是个比较基础的算法,在它只会有很多算法SVM/GBDT/RandomForest。复杂的算法比较难以把握,工业界更偏向于用简单的算法。
3.1 LR优点与应用
LR的优点:
1) LR是以概率的形式输出结果,不只是0和1的判定;
2) LR的可解释强,可控性高;
3) 训练快,feature engineering之后效果赞;
4) 因为结果是概率,可以做ranking model;
5) 添加feature简单。
LR的应用场景很多哈:
1) CTR预估、推荐系统的learning to rank;
2) 一些电商搜索排序基线;
3) 一些电商的购物搭配推荐;
4) 新闻app排序基线。
3.2 关于样本处理
样本太大怎么处理?
1) 对特征离散化,离散化后用one-hot编码处理成0,1值,再用LR处理会较快收敛;
2) 如果一定要用连续值的话,可以做scaling;
3) 工具的话有 spark Mllib,它损失了一小部分的准确度达到速度的提升;
4) 如果没有并行化平台,想做大数据就试试采样。需要注意采样数据,最好不要随机取,可以按照日期/用户/行为,来分层抽样。
怎么使样本平衡?
1) 如果样本不均衡,样本充足的情况下可以做下采样——抽样,样本不足的情况下做上采样——对样本少的做重复;
2) 修改损失函数,给不同权重。比如负样本少,就可以给负样本大一点的权重;
3) 采样后的predict结果,用作判定请还原。
3.3 关于特征处理
1) 离散化优点:映射到高维空间,用linear的LR(快,且兼具更好的分割性);稀疏化,0,1向量内积乘法运算速度快,计算结果方 便存储,容易扩展;离散化后,给线性模型带来一定的非线性;模型稳定,收敛度高,鲁棒性好;在一定程度上降低了过拟合风险
2) 通过组合特征引入个性化因素:比如uuid+tag
3) 注意特征的频度: 区分特征重要度,可以用重要特征产出层次判定模型
3.4 算法调优
假设只看模型的话:
1) 选择合适的正则化:L2准确度高,训练时间长;L1可以做一定的特征选择,适合大量数据
2) 收敛阈值e,控制迭代轮数
3) 样本不均匀时调整loss function,给不同权重
4) Bagging或其他方式的模型融合
5) 选择最优化算法:liblinear、sag、newton-cg等
More
- 七月算法机器学习视频
- 逻辑回归初步
zhewei大佬