保证高效写入查询的情况下,如何实现 CPU 资源和磁盘 IO 的最低开销?
从《写入性能:TDengine 最高达到 InfluxDB 的 10.3 倍,TimeScaleDB 的 6.74 倍》、《查询性能:TDengine 最高达到了 InfluxDB 的 37 倍、 TimescaleDB 的 28.6 倍》两篇文章中,我们发现,TDengine 不仅在写入和查询性能上超越了 InfluxDB 和 TimescaleDB,在数据处理过程的资源消耗也比两大时序数据库要更低。本篇文章将会从 TDengine( Time Series Database ) 的产品设计角度出发,为感兴趣的小伙伴分析一下 TDengine 性能强消耗低的原因。
为什么 TDengine 的“写入强,开销低”?
“客户端上 TDengine 对 CPU 的需求大于 TimescaleDB 和 InfluxDB, 而 InfluxDB 的写入压力基本上完全集中在服务端,这种模式很容易导致服务端成为瓶颈。TDengine 在客户端的开销最大,峰值瞬间达到了 56%,然后快速回落。综合服务器与客户端的资源开销来看,TDengine 写入持续时间更短,在系统整体 CPU 开销上 TDengine 仍然具有相当大的优势。”
在 TSBS 测试报告全部的 cpu-only 五个场景中,TDengine 写入性能均优于 TimescaleDB 和 InfluxDB。相对于 TimescaleDB,TDengine 写入速度最领先的场景是其 6.7 倍(场景二),最少也是 1.5 倍(场景五),而且对于场景四,如果将每个采集点的记录条数由 18 条增加到 576 条,TDengine 写入速度是 TimescaleDB 的 13.2 倍。相对于 InfluxDB,TDengine 写入速度最领先的场景是其 10.6 倍(场景五),最少也是 3.0 倍(场景一)。此外,在保证高效写入的情况下,TDengine 在写入过程中消耗的 CPU 资源和磁盘 IO 开销也是最少的。
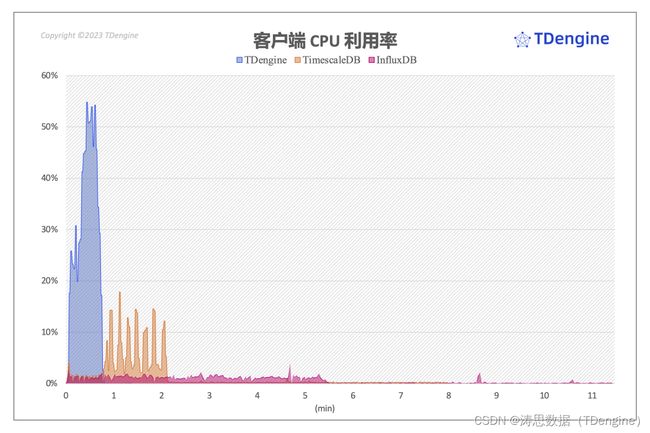 写入过程中客户端 CPU 开销
写入过程中客户端 CPU 开销
通过上图可以看到,从客户端负载来说,三个系统中 InfluxDB 计算资源占用最低,对客户端压力最小,但这并不能说明 InfluxDB 是三个数据库当中 CPU 开销最低的,因为其写入压力基本完全集中在了服务端,而这种模式也为 InfluxDB 埋下了一个隐患,如果写入的数据规模过大,写入线程会长时间地大量消耗服务器的计算和磁盘IO资源。
与 InfluxDB 相反,TDengine 在客户端的开销最大,峰值直接冲到了 56%,其在客户端的开销比 TimescaleDB 都多了 1 倍,但在用时上,却比 InfluxDB 和 TimescaleDB 都小。也因此,从系统整体的 CPU 开销来看,TDengine 的优势仍旧非常显著。
基于产品特点,我们可以从两个方面分析这种“高写入,低开销”的特点。首先,为充分利用数据的时序性等特点,TDengine 采取了“一个数据采集点一张表”的策略,要求对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表),用来存储这个数据采集点所采集的时序数据。这种设计对于提升写入性能来说主要表现在两个方面:
- 由于不同数据采集点产生数据的过程完全独立,每个数据采集点的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
- 对于一个数据采集点而言,其产生的数据是按照时间排序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
其次,因为 TDengine 的 SQL 解析是在客户端完成的,这样一来,其在整个写入过程中,主要的负载都集中在客户端,服务器端承担的压力就会变得非常小。我们之所以将写入的负载转移到客户端,其原因是客户应用端的伸缩和扩展操作非常地便捷容易,可操作性更强——在保障服务器有剩余能力的情况下,如果写入性能不够,只要增加写入进程或写入客户端即可解决此问题,不再需要增加服务器的设备了。
试想一下,如果不需要变更服务器数量,那也就不会涉及到集群的伸缩操作、资源负载均衡等复杂逻辑,整体的写入成本自然就会显著降低。
除了客户端 CPU 开销外,三个系统对比,TDengine 对服务器的 CPU 需求也是最小的,峰值仅使用了 17% 左右的服务器 CPU 资源。在磁盘写入能力的消耗上,InfluxDB 长时间消耗完全部的磁盘写入能力,TimescaleDB 写入过程对于写入的消耗相对 InfluxDB 来说要更具优势,但是仍然远超 TDengine 对磁盘写入能力的需求。
如何用最小的计算开销实现最高的查询性能?
“从整体 CPU 开销上来看,TDengine 不仅完成全部查询的时间低于 TimescaleDB 和 InfluxDB,在整体上CPU计算资源的消耗也远小于 TimescaleDB 和 InfluxDB。在整个查询过程中,TDengine 内存也始终维持在一个相对平稳的状态。”
基于 TSBS 测试报告我们可以总结出,查询方面,在场景一(只包含 4 天的数据)与场景二的 15 个不同类型的查询中,TDengine 的查询平均响应时间全面优于 InfluxDB 和 TimescaleDB,而且在复杂查询上优势更为明显,同时具有最小的计算资源开销。相比 InfluxDB,场景一中 TDengine 查询性能是其 1.9 ~ 37.0 倍,场景二中 TDengine 查询性能是其 1.8 ~ 34.2 倍;相比 TimescaleDB,场景一中 TDengine 查询性能是其 1.1 ~ 28.6 倍,场景二中 TDengine 查询性能是其 1.2 ~ 24.6 倍。
 查询过程中服务器 CPU 开销
查询过程中服务器 CPU 开销
在资源开销上,TDengine 在查询过程中整体 CPU 占用约 80%,是三个系统中最高的,TimescaleDB 在查询过程中瞬时 CPU 占用次之,InfluxDB 的稳定 CPU 占用最小(但是有较多的瞬时冲高)。从整体 CPU 开销上来看,虽然 InfluxDB 瞬时 CPU 开销大部分是最低的,但是其完成查询持续时间最长,所以整体 CPU 资源消耗最多。由于 TDengine 完成全部查询的时间仅为 TimescaleDB 或 InfluxDB 的 1/20,虽然 CPU 稳定值是 TimescaleDB 与 InfluxDB 的 2 倍多,但整体的 CPU 计算时间消耗只有其 1/10 。
用最小的计算开销实现最高的查询性能,TDengine 是如何做到的呢?首先,TDengine 对每个数据采集点单独建表,但在实际应用中经常需要对不同的采集点数据进行聚合。为高效的进行聚合操作,TDengine 引入超级表(STable)的概念。超级表用来代表一特定类型的数据采集点,它是包含多张表的表集合,集合里每张表的模式(schema)完全一致,但每张表都带有自己的静态标签,标签可以有多个,可以随时增加、删除和修改。应用可通过指定标签的过滤条件,对一个 STable 下的全部或部分表进行聚合或统计操作,这样就大大简化了应用的开发。其具体流程如下图所示:
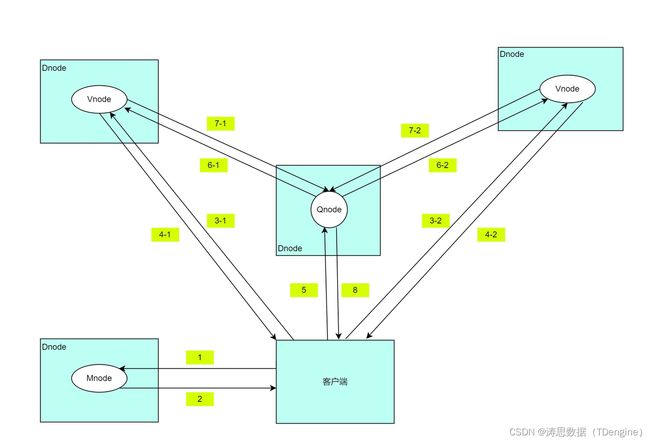
由于 TDengine 在 vnode 内将标签数据与时序数据分离存储,通过在内存里过滤标签数据,就可以先找到需要参与聚合操作的表的集合,这样需要扫描的数据集就会变得大幅减少,聚合计算速度自然就会获得显著提升。同时,由于数据分布在多个 vnode/dnode,聚合计算操作在多个 vnode 里并发进行,这又进一步提升了聚合的速度。
其次,在单表查询上,当我们要对全部数据集进行查询时,就需要将查询请求广播到所有的节点。试想一下,当我们在业务场景中需要对某个设备进行查询,这时如果可以不使用标签过滤,直接查询对应的设备,查询效率是不是变得更高了,TDengine 便是如此。在本次测试报告中就有几个这样的场景,TDengine 都表现出了很好的查询性能。
此外,为有效提升查询处理的性能,针对物联网数据不可更改的特点,TDengine 会在数据块头部记录该数据块中存储数据的统计信息:包括最大值、最小值、和,我们称之为预计算单元。如果查询处理涉及整个数据块的全部数据,就可以直接使用预计算结果,完全不需要读取数据块的内容。由于预计算数据量远小于磁盘上存储的数据块数据的大小,对于磁盘 I/O 为瓶颈的查询处理,使用预计算结果可以极大地减小读取 I/O 压力,加速查询处理的流程。预计算机制与 PostgreSQL 的索引 BRIN(block range index)有异曲同工之妙。
用极致压缩比实现存储成本的最大程度降低
“磁盘空间占用方面,TimescaleDB 在所有五个场景下的数据规模均显著大于 InfluxDB 和 TDengine,并且这种差距随着数据规模增加快速变大。TimescaleDB 在场景四和场景五中占用磁盘空间是 TDengine 的 25.6 倍和 26.9 倍。在前面三个场景中,InfluxDB 落盘后数据文件规模与 TDengine 非常接近,但是在大数据规模的场景四和场景五中,InfluxDB 落盘后文件占用的磁盘空间是 TDengine 的 4.2 倍和 4.5 倍。”
当数据写入磁盘时,TDengine 会根据系统配置参数 comp 决定是否压缩数据。TDengine 共提供了三种压缩选项:无压缩、一阶段压缩和两阶段压缩,分别对应 comp 值为 0、1 和 2 的情况。一阶段压缩根据数据的类型进行了相应的压缩,压缩算法包括 delta-delta 编码、simple 8B 方法、zig-zag 编码、LZ4 等算法。二阶段压缩在一阶段压缩的基础上又用通用压缩算法进行了压缩,压缩率更高。
同时,TDengine 采用的是标签分离存储机制,即标签与数据是分开进行存储的,这样就带来了两个方面的好处:
- 在存储操作上占用更小的磁盘空间,表级别的标签基本上没有冗余。
- 标签集中存储更有利于标签过滤操作中 IO 访问的局部性,标签过滤完成得更快,查询性能也会变得更好。
此外,对于 TDengine 来说,每个数据块内部采用的就是列式存储模式,而且打造了“一个数据采集点一张表”的创新设计,一个数据采集点采集量的变化肯定比多个采集点的采集量变化更慢,压缩率自然也会变得更高。综合上述的几点设计,TDengine 在进行数据处理时提供了很好的压缩比,帮用户节约了存储空间和存储资源,极大程度上减少了存储成本浪费。
写在最后
在产品开发之初,TDengine 就明确了设计方向,即针对时序数据的特点对写入、存储、查询等流程进行设计和优化,在经过几个版本的不断迭代加强后,其存储量大、存储运维成本低、读写性能卓越、压缩率高等特点越发显著。这些优势也体现在企业的具体实践上,以西门子的数字化解决方案改造项目 https://www.taosdata.com/user-cases/12851.html为例,TDengine 帮助其 SIMICAS® OEM 2.0 版本移除了 Flink、Kafka 以及 Redis,大大简化了系统架构,节约了运维成本;而在零跑科技的 C11 新车型项目https://www.taosdata.com/user-cases/3132.html中,TDengine 高压缩算法助力其压缩性能提升了10-20 倍,降低存储压力的同时也解决了数据存储成本高的问题。
https://www.taosdata.com/user-cases/12851.html为例,TDengine 帮助其 SIMICAS® OEM 2.0 版本移除了 Flink、Kafka 以及 Redis,大大简化了系统架构,节约了运维成本;而在零跑科技的 C11 新车型项目https://www.taosdata.com/user-cases/3132.html中,TDengine 高压缩算法助力其压缩性能提升了10-20 倍,降低存储压力的同时也解决了数据存储成本高的问题。
如果你也面临着性能和成本难以两全的数据处理难题,亟需升级数据架构,欢迎添加小T vx:tdengine1,加入 TDengine 用户交流群,和更多志同道合的开发者一起攻克难关。