2020年因果推断综述《A Survey on Causal Inference》
最近阅读了TKDD2020年的《A Survey on Causal Inference》,传送门,自己对文章按照顺序做了整理,同时对优秀的内容进行融合,如有不当之处,请多多指教。
文章对因果推理方法进行了全面的回顾,根据传统因果框架所做的三个假设,将这些方法分为两类,对于每个类别,都讨论和比较了传统的统计方法和最近的机器学习方法。
1. 背景介绍
相关性: 当两个变量呈现增加或减少的趋势,它们就是相关的。
因果关系: 部分原因造成了结果,而结果部分地依赖于原因。
例如:冰激凌销量与溺水死亡率
观察到随着冰淇淋销量增加,溺水死亡率急剧上升的现象。简单的相关性认为,吃冰淇淋会导致溺水;吃冰淇淋和游泳背后共同因素是季节。在炎热的夏季,冰淇淋的销售速度远高于寒冷的月份,而且在炎热的夏季,人们更有可能进行游泳活动,这就是因果关系。
因此,搞清因果推理背后的原因是有价值的,而最有效的方法则是进行随机对照实验,实验组和对照组的差异即因果因素分析。
存在问题:
- 在现实中,随机对照试验总是代价昂贵的,受试者样本不足,不能代表实验/干预最终目标的现实世界人群。
- 另一个问题是,随机对照试验只关注样本的平均值,并没有解释机制或适用于个别受试者。
- 此外,大多数随机对照试验还需要考虑伦理问题,这在很大程度上限制了其应用。
因此,现实中只能拿到非随机对照实验的数据,也称观察数据。比如在医院里面就记录了每个人病人就医时的情况(特征)、医生开的药(treatment)、病人用药后的效果(outcome),这些就是观察数据。无论是随机对照实验的数据(RCT)还是观察数据,在因果推断领域都是这样的三元组,
为了准确预估因果效应,解决观察数据的问题,人们提出了各种框架,比较有名的是:potential outcome framework(POF)、structural causal model(SCM)。
- POF:倾向于预估反事实的效果(即potential outcome)
- SCM:引入了因果图和结构方程,因果图构建因果结构,结构方程则衡量因果效益的大小
本文介绍潜在结果框架的基本概念及其三个关键假设,以确定因果效应。然后,详细讨论了基于这三个假设的七种因果推理方法,包括重新加权方法、分层方法、基于匹配的方法、基于树的方法、基于表示的方法、基于多任务学习的方法和基于元学习的方法。还描述了放宽三个假设的因果效应估计方法,以满足不同情况下的需求。
2. 基本概念
因果推断的任务核心目标就是找到影响结果产出的核心因素。比如一种病有A、B 两种药可以治疗,医生给一个病人吃A药,成功率为70%,如果吃B药,成功率为90%。成功率及其变化就是因果推断希望能够从数据中学习到的。
2.1 基础定义
- unit: 因果推断里最小的物理单元,具有原子性的。单位可以是一个实体,一个公司,一个病人,一个人,或者一个物体或人的集合。
- treatment: 对一个unit施加的动作。比如潘金莲给大郎喂药,喂药就是treatment。一般用W表示,比如W=1表示吃药(施加treatment),W=0表示不吃药(没有施加treatment)。
- outcome: 某个unit在某个treatment下的表现,比如吃药之后好了还是没好。一般用Y表示,Y(W=1)表示这个人在吃药后的表现,如果Y=1表示病好了,则Y(W=1)=1的含义是这个人吃药之后病好了。同理,Y(W=1)=0表示这个人吃药之后病没有好。
- observed outcome: unit在实际的treatment下的表现,这个人实际是吃了这个药的,一般用 Y F = Y ( W = w ) Y^F=Y(W=w) YF=Y(W=w)表示。
- potential outcome: unit在潜在的treatment下的表现,比如这个人没有吃药,但是如果吃药了,其表现就是potential outcome,其实就是如果怎么做就会怎么样的结果。
- Counterfactual outcome: 是除单位实际采取的治疗之外的治疗的潜在结果。由于一个单位只能接受一种治疗,因此只能观察到一种潜在结果,其余未观察到的潜在结果就是反事实结果。一般用 Y C F = Y ( W = w ′ ) Y^{CF}=Y(W=w') YCF=Y(W=w′)表示。
- Pre-treatment Variables: 实施treatment前变量是一种不受treatment影响的变量,也被称为背景变量,它们可以是患者的人口统计数据、病史等。
- Post-treatment Variables: 实施treatment后变量是受治疗影响的变量。治疗后变量的一个例子是中间结果,例如前面提到的药物例子中服用药物后的实验室测试。
- treatment effect: 施加了treatment后的增量效果(or 增益),比如吃药之后相比于没有吃药,其治愈率提升了多少,其存在如下3个维度:
- Average Treatment Effect (ATE) : A T E = E [ Y ( W = 1 ) ] − E [ T ( W = 0 ) ] ATE = E[Y(W=1)] - E[T(W=0)] ATE=E[Y(W=1)]−E[T(W=0)],所有人的平均treatment effect。
- Conditional Average Treatment Effect (CATE): C A T E = E [ Y ( W = 1 ) ∣ X = x ] − E [ Y ( W = 0 ) ∣ X = x ] CATE = E[Y(W = 1)|X = x] − E[Y(W = 0)|X = x] CATE=E[Y(W=1)∣X=x]−E[Y(W=0)∣X=x],在特征 X = x X=x X=x的子人群里面treatment effect。
- Individual Treatment Effect (ITE): I T E i = Y i ( W = 1 ) − Y i ( W = 0 ) ITE_i = Y_i (W = 1) − Y_i (W = 0) ITEi=Yi(W=1)−Yi(W=0),某个unit(个体维度)的treatment effect。
2.2 三大假设
- Stable Unit Treatment Value Assumption (SUTVA): 任何单位的潜在结果(potential outcome)不会随着分配给其他单位的治疗而变化,并且,对于每个单位,每个治疗水平没有不同的形式或版本。这一假设强调两点:
- 第一是各单元的独立性,即各单元之间不存在相互作用。
- 第二是每种治疗是单一版本。如不同剂量的A药在SUTVA假设下是不同的治疗方法。
- Ignorability(可忽略性): 考虑到背景变量X,治疗分配W与潜在结果无关。可忽略性假设表明了三方面:
- 第一,如果两个患者具有相同的背景变量X,无论治疗分配如何,他们的潜在结果都应该是相同的。
- 第二,如果两个患者具有相同的背景变量值,无论他们的潜在结果值如何,他们的治疗分配机制应该是相同的。
- 第三,不存在某个在X之外的隐变量,同时影响outcome和treatment,使得treatment和outcome相关,因此这个假设又称unconfoundedness assumption。
- Positivity(正向性): 对于X的任何值,治疗分配都不是确定的概率。每个人都有概率被施加任何treatment,并且人群中存在所有的treatment。
2.3 Confounders and General Solutions(混淆因子和通用解决方案)
- Confounders(混淆因子): 是对实验结果有干扰的变量。如医药分析案例的年龄就是混淆因子。
- Selection bias(选择偏差): 正如ATE的定义, A T E = E [ Y ( W = 1 ) ] − E [ T ( W = 0 ) ] ATE = E[Y(W=1)] - E[T(W=0)] ATE=E[Y(W=1)]−E[T(W=0)],在机器学习领域,为了能够得到这个值,简单粗暴地用2个模型预估 E [ Y ( W = 1 ) ] E[Y(W=1)] E[Y(W=1)]和 E [ T ( W = 0 ) ] E[T(W=0)] E[T(W=0)],然后做差值即可得到ATE,但是由于混淆变量(Confounders)的存在,导致ATE的计算会存在很大的偏差,这种偏差就称为选择偏差。
我们再看一个辛普森悖论问题,比如,现在有两种药A和B,我们希望看看每种药的效果,如果直接看总的治愈率,A是83%,B是78%,A药的效果比B好。但是如果根据用户的年龄划分,年轻病人中:A的治愈率是87%,B是92%;年老病人中A的治愈率是69%,B是73%。这么看,B药的效果反而比A好。这个问题又被成为辛普森悖论。
出现悖论的原因是年轻的病人其症状更轻微,因此医生倾向于开A种药,年老的病人则开B种药,由于年轻病人的抵抗力一般较好,治愈率都比较高,所有总体看,会得出A药的效果比B药的效果好的错误结论。在这里,年龄这个变量就是一个Confounder。
避免Confounders导致的Selection bias通常有2种方法:
- match: 施加了不同treatment的人,需要需要经过匹配之后再做比较,比如选择的都是年轻人,这样就是模拟控制变量的做法。一般方法有sample re-weighting, matching, tree-based methods, confounder balancing, balanced representation learning methods, multi-task based methods。
- Meta-learning: 先基于观察数据训练模型,得到有偏的结果,后续对结果进行纠正。
3. 基于3大假设的常用方法
一般主要分为以下几类方法:
- re-weighting methods;
- stratification methods;
- matchingmethods;
- tree-based methods;
- representation based methods;
- multi-task methods;
- meta-learning methods.
3.1 Re-weighting Methods

由于混杂因子的存在,实验和对照组的协变量分布不同,将会导致选择偏差问题,而样本加权是克服选择偏差的有效方法,为数据每个单位分配适当的权重,可以创建一个治疗组和对照组分布相似的伪总体。
倾向分数(propensity score): 是平衡分数的一种特殊情况。 e ( x ) = P r ( W = 1 ∣ X = x ) e(x) = Pr (W = 1|X = x) e(x)=Pr(W=1∣X=x)
在倾向分数的基础上,提出了基于倾向评分的样本重加权。Inverse propensity weighting(IPW) 称为处理加权的逆概率,为每个样本分配一个权重 r : r: r: r = W e ( x ) + 1 − W 1 − e ( x ) r = \frac{W}{e(x)}+ \frac{1-W}{1-e(x)} r=e(x)W+1−e(x)1−W。
W W W为Treatment, e ( x ) e(x) e(x)定义如上。
IPW 中的DR estimator方法将倾向评分权重与结果回归结合起来,因此即使倾向评分或结果回归中的一个不正确(但不是两个都不正确),具有鲁棒性。
CBPS 直接从估计的参数倾向性得分构建协变量平衡得分,增加了对倾向性得分模型错定的鲁棒性。
Data-Driven Variable Decomposition(D2VD) 算法提出了区分混杂因素和调整变量,同时剔除不相关变量的方法。
实践中对观测变量之间相互作用的先验知识很少,数据通常是高维的和有噪声的。为了解决这个问题,Confounder Balancing, DCB算法用于选择和区分混杂因素以平衡分布。总的来说,DCB通过重新加权样本和混杂因素来平衡分布。
3.2 Stratification Methods
同一亚组中的单位可以被视为来自随机对照试验数据的样本。基于每个亚组的同质性,可以通过随机对照试验(rct)数据开发的方法计算每个亚组(即CATE)内的治疗效果。或者换种说法,即通过将treatment组和control组划分成为同质的子人群,消除confounder,从而消除选择偏差。简单来说就是将观察数据构建成控制变量的随机实验的数据,从而可以得到类似于AB实验的置信的数据。
比如根据倾向性得分划分多个子人群,使得子人群是同质的,从而求得子人群的ATE。缺点是treatment组和control组在倾向性得分的重叠度不一定高,导致子人群样本量少,偏差大。ATE的计算过程如下:
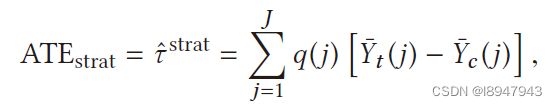
其中 Y ^ t ( j ) \hat{Y}_t (j) Y^t(j)和 Y ^ c ( j ) \hat{Y}_c (j) Y^c(j)分别是第j个子块中处理结果和控制结果的平均值。 q ( j ) q(j) q(j)是第j个方块中单位的比例,分层有效地减小了ATE估计的偏差。分层方法的关键是如何创建块和如何组合创建的块。等频率方法是创建块的常用策略。等频率方法按出现概率(如倾向得分)分割块,使协变量在每个子组中具有相同的出现概率(即倾向得分)。
3.3 Matching Methods
基于匹配的方法提供了一种估计反事实的方法,同时减少了混杂因素带来的估计偏差。可以理解为因为每个人要么在treatment组(w=1),要么在control组(w=0)。对于在treatment组的人(原始人群),需要在control组中找到相似特征的相似人群,用相似人群的outcome来近似原始人群在control组中的outcome。一般来说,通过匹配估计的第i个单元的潜在结果为:

其中 Y ^ i ( 0 ) \hat{Y}_i(0) Y^i(0)和 Y ^ i ( 1 ) \hat{Y}_i(1) Y^i(1)是实验和对照估计结果,J(i)表示相反实验组中单元i匹配的邻居。
基于匹配的方法核心思想是经过变换后的倾向性评价距离,从而减少偏差,现有方法集中于Hilbert-Schmidt Independence Criterion based nearest neighbor matching (HSIC-NNM)和Randomized Nearest Neighbor Matching(RNNM)、nearest-neighbor matching (NNM)、Johnson–Lindenstrauss (JL),即通过线性或者非线性方法投影特征,进而计算距离减少偏差。常见的方法总结如图:

3.4 Tree-based Methods
基于决策树学习是一种预测建模方法。决策树是一种用于分类和回归的非参数监督学习方法。目标是创建一个模型,通过学习从数据推断出的简单决策规则来预测目标变量的值。目标变量是离散的树模型称为分类树,其预测误差是根据错误分类代价测量的。在这些树结构中,叶子表示类标签,分支表示指向这些类标签的特征的连接。目标变量是连续的决策树被称为回归树,其预测误差由观测值和预测值之间的差的平方来测量。Classification And Regression Tree(CART)分析是一个总称,用于指代上述两个过程。CART模型对数据空间进行了分区,并为每个分区空间拟合了一个简单的预测模型,因此每个分区都可以图形化地表示为一棵决策树。
树模型在分裂过程中,每个节点的特征都是一样的,因此在做matching上有天然的优势,可以得到偏差较小的CATE的值,不过现有的树模型无法完成因果推断的任务,还需要修改树的分裂标准和输出值计算,通常输出值就是CATE。
Bayesian Additive Regression Trees(BART)有几个优势。它很容易实现,只需要插入结果、治疗分配和混杂协变量,无需关于这些变量如何参数相关的信息,以便在拟合模型时需要更少的猜测,此外,它可以处理大量的预测因子,产生一致的不确定性区间,并处理连续的处理变量和缺失数据。基于树的框架也可以扩展到一维或多维的处理。每个维度可以是离散的或连续的。树状结构用于指定用户特征和相应处理之间的关系。这个基于树的框架对于建模错误规范非常健壮,并且高度灵活,只需进行最少的手工调优。
3.5 Representation Learning Methods
表示学习通常是通过转换原始协变量或从协变量空间中提取特征来学习输入数据的表示。特别关注深度学习,多个非线性变换的组合可以产生更抽象,最终更有用的表示。深度表示学习模型能够自动搜索相关的特征并将它们组合在一起,从而实现更有效和更准确的反事实估计,而传统机器学习方法需要用户准确地识别特征。到目前为止,基于深度表征学习的方法已经取得了重大进展,以克服观测数据因果效应估计的挑战。我们将基于深度表示学习的方法分为基于领域适应的方法、基于匹配的方法和基于持续学习的方法。
基于表征的域适配(Domain Adaptation Based on Representation Learning): 提取有效的特征表示是领域自适应的关键。在接下来的讨论中,差异距离在解决因果推理中的域适应问题中起着重要的作用。学习特征表示有三大目标:
(1)基于事实表示法的低误差预测;
(2)考虑相关事实结果,对反事实结果进行低误差预测;
(3)处理实验组与对照组的分布距离
基于表征的匹配方法(Matching Based on Representation Learning): 更容易解释,因为任何样本的反事实结果都直接被设定为接受相反处理的组中与其最近的邻居的事实结果。
基于表征的持续学习方法(Continual Learning Based on Representation Learning): 现有的表示学习方法只关注特定来源和平稳的观测数据。这样的学习策略假设所有的观察数据在训练阶段已经可用,并且只有一个来源。这一假设在实践中是站不住脚的。
3.6 Multi-task Learning Methods
因果推断可以被定义为一个多任务学习问题,其中实验组和对照组有一组共享层,实验组和对照组分别有一组特定层。通过倾向分数的关联程度的dropout概率,对网络结构进行优化。多任务模型可以扩展到多个实验组中,而每个实验组的可以对参数连续性进行处理,如dose response network (DRNet)对实验的剂量进行区间化处理进行实验。
3.7 Meta-Learning Methods
因果推断里有2个关键的任务:
(1)控制混杂因素,即消除混杂因素与结果之间的伪相关性;
(2)给出了CATE估计的精确表达式。
一般来说,基于元学习的算法基于两步骤完成上述任务:
(1)估计条件平均结果 E [ Y ∣ X = X ] E[Y |X = X] E[Y∣X=X],这一步学习到的预测模型为基础学习器。
(2)推导基于步进结果差异的CATE估计器,现有的元学习方法有 T − l e a r n e r 、 S − l e a r n e r 、 X − l e a r n e r 、 U − l e a r n e r T-learner、S-learner、X-learner、U-learner T−learner、S−learner、X−learner、U−learner和 R − l e a r n e r R-learner R−learner。
T − l e a r n e r T-learner T−learner和 S − l e a r n e r S-learner S−learner高度依赖训练基模型的性能。当两组的单元数量极度不平衡(即一组的单元数量远远大于另一组)时,在小组上训练的基础模型的性能会很差。为了克服这一问题,提出了 X − l e a r n e r X-learner X−learner,它采用对照组的信息,对处理组给出更好的估计,反之亦然。
4. 三种假设的放宽情形
-
Relaxing Stable Unit Treatment Value Assumption(SUTVA):这个假设主要集中在两个方面
(1)单元是独立和同分布的(i.i.d); 如和图相关的社交网络问题,信号处理(signal processing),时间序列问题(time series problem)。
(2)只存在一种程度的treatment。如treatment是连续值,比如药品的剂量,可以将连续值转化为离散值。 -
Relaxing Unconfoundedness Assumption:现有的工作绝大多数依赖于无混淆性假设,即所有混淆因素都可以测量。然而,这种假设在实践中可能是站不住脚的。
-
Relaxing Positivity Assumption:正向性假设也称为协变量重叠或共同支持,是观察性研究中确定treatment效果的必要假设。然而,很少有文献讨论在高维数据集中满足这一假设。也就是说,这个假设保证了在任何的X下,所有treatment的数据都存在,但是在高维的X下,样本是很少的,不一定存在所有treatment的样本。
5. 实践应用
5.1 常用数据集
IHDP、Jobs、Twins、ACIC datasets、IBM等其他数据集,感兴趣的请参考原论文。
5.2 常见代码库
- Dowhy,Python,https://github.com/py-why/dowhy
- Causal ML,Python,https://github.com/uber/causalml
- EconML,Python,https://github.com/microsoft/EconML#blogs-and-publications
- causalToolbox,R,https://github.com/soerenkuenzel/causalToolbox
- dragonnet,Python,https://github.com/claudiashi57/dragonnet
- DRNets,Python,https://github.com/d909b/drnet
6. 常见的应用方向
- Decision evaluation:决策相关
- Counterfactual estimation:反事实预估
- Dealing with selection bias:消除选择偏差
6.1 广告系统
如果可以正确地预估广告营销活动的收益,那么就可以给决策提供准确的数据支持,并且可以判断进行哪些广告营销活动可以带来最大的收益,如果和优化理论相结合,就可以求解在有约束条件下最大化收益的广告策略。由于随机对照实验成本较高,因此利用观察数据衡量广告收益就是一个比较重要的方向。
6.2 推荐系统
推荐和treatment effect的预估密切相关,因为给用户推荐一个item,可以认为是施加一个treatment。并且在推荐领域,选择偏差更加严重,因为用户更倾向于点击自己喜欢的item,因此推荐系统会给用户推荐他们感兴趣的item,这就导致观察数据有很大的偏差。
6.3 医药方面
当每个病人在每种药的疗效都能够准确的预估之后,医生也更有针对性的提供药方。
6.4 强化学习方面
在强化学习领域的因果推断,可以看做是一个多臂老虎机问题,treatment就是action,outcome就是reward,X特征就是上下文的特征,exploration and exploitation就类似于随机实验数据和观察数据。
6.5 自然语言处理方面
去混淆词汇特征学习旨在学习对一组目标变量具有预测性但与一组混淆变量不相关的词汇特征。它对语言分析和下游任务的解释具有重要意义。
6.6 计算机视觉方面
现有的大多数工作依赖于相关性,而不是因果相关的证据,数据中的虚假相关性导致模型对问题的语言变化非常脆弱。为此,在提出了一种数据增强策略,使模型对伪相关具有更强的鲁棒性。
6.7 其他应用
教育: 通过比较不同教学方法对学生群体的影响,可以确定更好的教学方法。此外,ITE评估可以通过评估每个学生在不同教学方法下的结果来增强个性化学习。例如,ITE评估是用来回答这样的问题:“当这个学生不能解决问题时,这个学生是从视频提示中受益更多,还是从文本提示中受益更多?”,这样智能导师系统就可以决定哪个提示更适合特定的学生。
政策决策: 在政治领域,因果推理可以提供决策支持。例如,针对工作数据集开发了各种方法,旨在回答“谁将从补贴工作培训中受益最大?”因果推断还有助于政治决策,例如是否应该将一项政策推广到较大的人口规模。
改进机器学习方法: 其实说白了就是增强了模型的可解释性。也可以扩展以提高机器学习方法的稳定性,提高模型在未知领域的泛化能力。
7. 未来方向
- 增加或放宽因果模型中的假设
- 在不同的因果模型之间建立正式的联系
- 因果推理的机器学习”和“机器学习的因果推理
- 让机器学习具备因果推理能力
- 动态环境中的因果推理
参考文献:
- https://zhuanlan.zhihu.com/p/576878672(这篇文章给我了很多启发,老哥还是很棒的)
- https://zhuanlan.zhihu.com/p/554682071
- https://blog.csdn.net/baidu_39413110/article/details/111411360
- https://www.cnblogs.com/caoyusang/p/13518354.html
- https://blog.csdn.net/qq_40707758/article/details/123348551