Git 分支操作&存储原理浅谈
相信大家对于 git 版本控制系统都不陌生,大部分同学在工作中都会使用到 git,他帮助我们管理我们的代码,让我们能够随心所欲的提交代码,进行不同的实验而不用担心将项目毁掉,同学们可以在工作中熟练的使用 git 进行代码提交,但是部分同学对于 rebase,merge 等等针对分支,合并的操作不十分自信,并且对目前腾讯视频客户端采用的主干开发模式背后的原理并不熟悉,在本文章中,我想通过介绍 git 的存储机制,来帮助大家更好的理解分支以及分支操作。
希望有相关困惑的同学能够通过本文章,从原理上对 git 的分支操作有一定的理解,在日后的工作中使用相对应的 git 命令时能更加得心应手,游刃有余,本文主要分为以下几个部分:
- Git 简单介绍
- Git 存储原理浅谈
- 分支与分支管理,以及不同的分支合并方式
- 常见问题&一些使用技巧
Git 是什么?— 分布式的版本控制系统
git 是一个分布式版本控制系统。Git 记录的是整个项目的快照,而非不同版本之间的差异,这一点上,git 和许多其他的版本控制系统不太一样,当 git 存储更新或者保存文件状态时,它基本上就会对当时项目中由 git 管理的全部文件创建一个快照并保存这个快照的索引。 为了效率,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。 Git 对待数据更像是一个快照流。

分布式的版本控制
Git 的版本控制是分布式的,这意味着当多人工作在同一个项目或者同一个分支上时,每个人的系统之都包含了这个项目或者分支的全部信息,即使此时中央 git 服务器出现不可修复的故障,仍可以基于任何一个已经检出该项目的电脑来使用本地的 git 记录来进行覆盖还原。同时 git 对于所有的数据在存储前都会计算校验合(使用一种叫做 SHA-1 的哈希计算方式),用来校验和引用,这意味着 git 可以察觉到所管理项目中任何一个文件内容或者目录内容的变动。
总是在添加数据
Git 一般只会添加数据,我们所做的任何操作(即使是回退代码),都在向 git 数据库中添加数据,这意味着 git 几乎不会执行任何可能导致文件不可恢复的操作。
鼓励分支的使用
Git 引入了分支的概念,并且允许我们频繁的添加,删除,合并以及修改分支,这极大地便利了我们在不同开发工作之间切换,同时也让项目管理者可以更好的管理有很多开发者参与以及提交贡献的项目。 Git 的这些特性迅速让他成为了主流,git 让我们可以愉快的进行多人协作开发,也允许开发人员针对项目的规模和特点,选择各种各样的开发模式。(对 git 开发模式感兴趣的同学可以阅读:https://git-scm.com/book/en/v2/Distributed-Git-Distributed-Workflows)
Git 的存储原理浅谈
要想搞明白分支的概念,以及各种分支操作到底做了什么,我们首先需要对 git 存储代码版本和信息的原理有个简单的认识。
Git 的本质是一个键值存储系统,我们可以向 git 仓库中插入任意类型的内容,他会对内容进行存储,同时基于内容计算并返回一个唯一的值(前文说到的 sha-1 哈希值)作为键,通过该键我们可以再次访问到该内容。 Git 就是基于这个存储系统存储我们的项目提交的,为了记录我们项目的提交快照,提交信息等数据,git 定义并存储了不同类型的存储对象,主要包括:
数据对象(blob):包含存储文件的内容信息的对象,一个数据对象通常包含一个文件的内容信息,但是不包含文件名。
树对象(tree):存储文件名,同时可以将多个文件组织到一起,(有点类似 unix 文件系统中的目录项。一个树对象可以包含一条或多条提交记录)通常,我们在 git commit 时会将暂存区的所有状态写为一个树对象,一个树对象包含多个树对象记录(tree entry),每条记录都代表了当前目录下的一个条目,他们有可能是一个文件,也有可能是一个子目录(指向另一个树对象的指针)他们帮助我们管理项目的目录和层级关系。
提交对象(commit):有了树对象和数据对象,我们记录下了每次提交的内容,为了记录提交之间的顺序关系,以及提交的作者信息,git 引入了提交对象的概念,一个提交对象通常会保存一个树对象,作为当前的项目快照。可能存在的父提交对象,作者信息,时间戳,以及提交的注释。
靠这三种对象,git 基本上保存了我们项目需要的所有信息。假设我们创建了一个简易的项目,我们首先在项目中创建了一个 test.txt 文件并提交给 git 来管理,之后我们修改了 test.txt 文件的内容,并创建了另一个叫做 new.txt 的文件,最后我们又新建了一个叫 bak 的目录,并将 test.txt 文件的第一个版本放在了该目录中。在以上过程中,我们创建了三次提交,git 的提交历史大概长这样:

可以看到,数据对象对象保存了文件内容信息,树对象存储了文件名和目录相关的信息,而提交对象为我们存储了提交之间的顺序,以及和每个提交相关的信息。
现在我们回到我们的主题:分支以及分支操作上。这涉及到了另外一种对象:引用对象(reference)
Git 引用
上文我简单介绍了 git 存储信息的结构,不难看出,想要检出或者重现某个 commit 对应的树对象,我们需要获得他对应提交对象的 SHA-1 code, 我们很难记住所有存储在 git 中提交对象的 SHA1-code 以及他们对应修改具体的作用,所以 git 引入了引用对象的概念来帮我们更好的管理和访问不同的提交。 **引用(reference)**允许我们给某个提交对象起一个简单的名字,这个名字可以帮助你想起这个提交对象所对应的项目状态,引用一般存储在.git/refs 目录下。你应该已经猜到了,每个引用都对应我们项目中的一个分支。现在假设我们为后两次提交分别创建了不同的引用,我们的 git 文件目录可能长这样:

引用对象的种类多种多样,包括:
- HEAD 引用:(指向当前检出的分支的头部,可能指向其他引用的指针,或者某个 git 对象),
- 标签引用(指向某个标签对应的提交对象),
- 远程引用(对远端仓库的引用,只读),
(如果你对不同的引用类型不熟悉,可以查看这里:Git--local-branching-on-the-cheap) 此处我们就不再展开。
分支与分支管理 - 分支的创建,切换
知道了 git 的存储原理和分支的本质,我们现在可以来聊聊分支以及一些分支的操作了,我们已经知道了分支本质上是指向提交对象的指针,所以在 git 中创建分支的花费极小,同时检出新分支的操作也只是将 HEAD 引用指向对应分支的引用,同时检出对应的树对象到工作目录。
我们在前文已经提到,当你在当前检出的分支上提交新的修改并提交时,git 会自动帮助你将当前分支的引用对象挪动到新的提交节点,HEAD 引用也会随之移动,但是这不会对其他分支的引用进行任何修改,我们也知道提交对象(commit)会保存自己的父提交对象信息,这使得当项目存在分叉时寻找恰当的合并基础(共同提交祖先)变得简单而高效(lowest common ancestor 问题)。
使用 merge 合并分支:
在适当的时机开发者们会将多个分支的提交合并到一个分支上,在 git 中,将两个分支合并有两种不同的方式,merge 和 rebase,我们将分别讨论这两种合并方式,以及他们到底做了什么,以便同学们在日后的工作中可以更好的选择不同的方式。
合并没有分叉的分支
如果我们的开发分支与合入到的目标分支之间没有任何分叉(例如在下面的示意图中, 我们检出了 master 分支,并且想将 hotfix 分支合并到 master 分支上,hotfix 分支所指向的提交 C4 是我们所在的分支 master 所指向的提交 C2 的直接后继),那么这时候 git 会直接将目标分支的指针向前挪动到指向开发分支的头部,这个指针移动操作被叫做 fast forward,


图:将 hotfix 分支 merge 到 master 分支,master 分支的引用对象直接向前移动到 hotfix 分支所指向的提交对象。
合并包含分叉的分支
并不是所有的分支合并都能够 fast forward,假设我们有这样一条分叉提交记录:
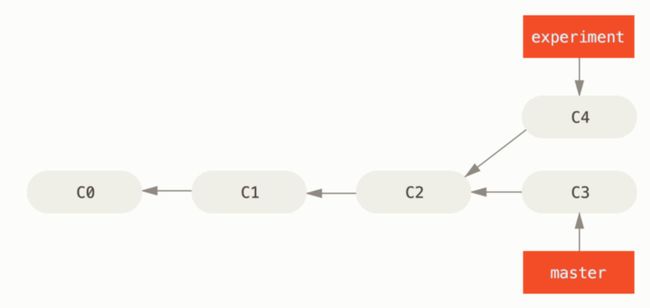
图:一个包含分叉的 git 提交记录,此时检出名为 master 的分支。
当我们想把 experiment 分支上的修改通过 merge 的方式合并到 master 分支上时,两个分支的头部提交节点都不在另一个分支的提交历史中(如上图中 c3,c4 节点的情况),git 会帮助我们创建一个新的合并提交,合并之后的提交记录长这样:

其中 c5 是 git 为了完成此次三方合并而创建出来的一个新的提交,可以发现 c5 拥有两个父提交。 当两个分支对同一文件的相同位置进行了不同修改时,git 会暂停下来并询问你想要如何处理此处冲突。

图:git 在监测到冲突后生成的冲突标记,将两部分冲突的代码放在两个代码块中,用=======号间隔开。
通常我们在进行 merge 操作时会检出两个分支中的一个,此时 git 自动产生的冲突解决标记中的 HEAD 代码块就代表了当前检出分支上的修改,而另一部分则是合入过来的分支上对该部分代码进行的修改。(HEAD 所指向的分支在 rebase 情况下会发生颠倒,如果在解决冲突时遇到需要解决不熟悉的代码冲突,一定要进行区分,否则可能导致 revert 他人代码或者旧的修改被重新提交到远端的情况,我们在后面会对解决冲突时选择哪个分支的提交进行更详细的解释) 当然你也可以在解决冲突后任意修改此次合并提交的 commit message(C5 提交的 commit message)。
Merge 操作的一个问题是使用后我们的提交记录将不再是线性的,这不仅会影响提交记录的简洁性,也会增加在遇到问题时正确回滚代码的难度(想了解回滚分支合并提交时可能产生的问题,可以阅读这个文档中的撤销合并部分:https://git-scm.com/book/zh/v2/Git-%E5%B7%A5%E5%85%B7-%E9%AB%98%E7%BA%A7%E5%90%88%E5%B9%B6 )
同时,由于在计算两个分支差异时 git 会寻找他们的公共父节点,所以如果两个分支存在分叉,git 可能会计算出错误的 diff 信息(例如在上面的例子中,C3 提交是某个从 experiment 分支 cherry-pick 过来的提交,或是某个过去提交的回滚提交),这时候如果基于错误的父节点进行了 diff 计算,会产生令开发者迷惑的 diff 记录。 那么就没有办法解决这些问题,并维持漂亮的线性提交记录了吗?有的!rebase。
使用 rebase 合并分支,rebase 到底做了什么?
Rebase 操作会修改当前分支的 git 提交历史,将它修改成像是将当前分支的提交按照顺序依次 cherry-pick 到目标分支上一样,正入他的名字“变基”一样,他让你将当前分支(experiment 分支)上所做的修改改变为基于 rebase 分支(master)的头部,而不是你当前分支修改前的头部。换句话说,他让你修改 C4 提交,使他的祖先从 C2 变到 C3. 如果我们使用 rebase 的方式合并之前提到的分叉分支,合并后的分支会长这样:
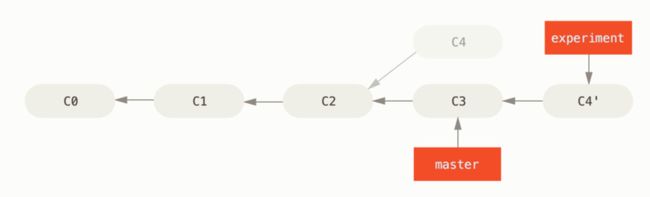
图:将 experiment 分支基于 master 分支进行变基
当我们对自己的开发分支进行变基合并后,将它 merge 到之前变基的分支变得十分轻松了,只需要 fast-forward master 的引用指针,同时也不会出现多余的合并节点。
注意在示意图中我们 rebase 后的分支为 C4’而并非 C4,这是因为他和 C4 已经是两个不同的(长得十分相似)提交对象,他们分别基于不同的父提交,如果 git 在将 C4 应用到 C3 上时出现了冲突,同样也会暂停并询问你应当如何解决这个冲突,这会使得 C4‘和 C4 的差异更大,你同时也可以在解决冲突后对 c4’的提交信息进行修改。如果你在当前分支存在多条提交记录,例如 C4 后面还跟着 C5,C6…那么在变基后他们的变基提交也会依次跟在 C4’的后面 C4’ - C5’ -C6’。
同时在 rebase 过后,我们在 experiment 分支上的提交已经被修改为基于 master 分支的头部节点,这极大的降低了 git 计算 diff 时找到错误的 base 的可能性。
很多同学不喜欢使用 rebase 的一大原因是,在 rebase 的时候,我们经常会需要解决同一个冲突很多次,当我们基于新的 master 重放原有的提交时,如果 git 不知道如何基于你刚刚解决冲突后的 C4‘应用 C5(很有可能发生,因为 C5 是基于 C4 进行的开发,现在 C4 已经被改变了),那么在应用 C5 的时候你需要再解决一次冲突(这次冲突很可能是你解决 C4 冲突时引入的)。
作者推荐的解决方式是尽量保证在 rebase 前本地只有一个 commit 记录,你可以使用 git squash 等命令将多个提交合并,也可以在本地有一次新的提交以后,后续使用 git commit —amend 的方式来对本次提交进行追加修改。除此之外,git 也提供了一个可以记住你之前解决冲突的方式,并且当相同的冲突再次出现的时候自动帮助你应用相同解法的工具 git rerere(https://git-scm.com/book/en/v2/Git-Tools-Rerere )
使用 squash&merge 进行合并
除了使用 rebase 保证项目的提交历史为线性外,我们还希望提交历史没有冗余的提交记录,同时确保提交历史中的每一笔提交都是一个可以稳定运行的版本(由流水线进行保证),这将会极大的提升项目主干的稳定性,同时让回滚操作变得更加便利。

工蜂的 git 网页端已经为我们提供了 squash and merge 的按钮选项,我们也可以在命令行使用 git merge 命令时 通过添加 git merge --squash 来通过 squash merge 的方式将 branchName 分支合入到当前检出分支中, 本质上就是将分支上的修改压缩成一个提交再合并过来。将 branch 上的所有改动保存到当前的暂存区中,如果在本地使用 git merge --squash 命令进行 merge 的话,还需要进行一次 commit 操作,将 staged change 提交,才算是完成了整个 merge 的过程,在网页端,当我们点击 squash and merge 按钮并且填写好本次提交的 commit 信息后,网页端会自动帮助我们完成上述操作,假设我们有以下的分支提交历史:
E----F feature branch
/
A----B----C----D master branch
那么当我们在 master branch 上 使用 git merge --squash 并进行 commit 后,我们将得到下面的提交历史:
E----F feature branch
/
A----B----C----D----H master branch
其中 master 分支上面的 H 提交包含了 feature 分支上面 E 和 F 两次修改的内容。
一种理解 squash merge 的方式是他只会保留文件的修改内容信息,同时丢弃掉 feature 分支上的提交信息。从上面的例子我们注意到使用 squah and merge 不会创建出 target 分支和 feature 分支的 merge 公共节点,squash merge 相当于在 target 分支上将 feature 分支上与 target 分支不同的所有修改全部保存在一个新的 commit 中并提交上去。这个新的 commit 和 feature 分支上的提交除了内容修改相同外(无冲突情况下),没有任何的联系。使用 squash merge 后并不能从任何一个分支的提交历史中辨认出两个分支存在 merge 过程。这也是一部分开发者非常反对在项目中使用 squash merge 的原因之一。大家在选择使用 squash merge 作为 merge 方式时需要谨慎,同时建议在 squash merge 后将 feature 分支删除,防止混淆。
将 rebase 和 squash and merge 搭配使用
在大型项目中,由于开发者众多,如何保证主干的稳定性成了这一类项目能够持续发展的关键。在这个背景下,配套使用 rebase 和 squash merge 的主干开发模式可以很好的保证主干上的每一笔提交都有质量把关,同时提交历史是简介的,线性的。由于 rebase 后,target 分支的头部一定在 feature 分支的提交历史记录中,所以 git 计算出来的 diff 就只包含 feature 分支上面的修改。通过 squash merge 的提交信息,可以将每一笔提交的具体改动和功能和对应的需求进行绑定,很好的解决了 squash merge 没有合并信息的问题。rebase 和 squash & merge 的配套使用,让我们既享受到了简洁,线性的提交记录,又尽可能的避免了合并的风险。
合并前的提交历史:
E----F feature branch
/
A----B----C----D master branch
feature 分支基于 master 分支 rebase 后:
B----C----D----E'----F' feature branch
/
A----B----C----D master branch
squash merge:
B----C----D----E'----F' feature branch
/
A----B----C----D----G master branch
在 G 提交的 commit 信息中包含必要的信息,用来记录此次提交的改动。
相信大家对于 merge 操作已经有了更深的了解,在以后的开发过程中对于分支的合并可以更加的得心应手。
常见问题&一些使用技巧
在 rebase 后使用 git push -f 来更新远端的跟踪分支
如果我们之前已经将我们的开发分支推送到了远端,此时本地又 rebase 了另一个分支(比如主干),这时如果我们想更新远端该分支的提交记录,就不能再使用 git push 了(有时候即使推送成功了,远端分支的提交记录也是错误的,git 有时会将 rebase 后分支上来自 rebase 分支的提交当成是新的提交,在发起 mr 时产生令人混乱的 diff 记录)
正确的做法是使用 git push -f 命令来强制更新远端分支的提交记录,很多同学对于 git push -f 的使用很忌惮,因为这会使用本地的提交完全覆盖掉远端的提交记录,其实在官方的文档中,也推荐在 rebase 过后使用 git push -f 来更新远端对应分支的记录,但是使用中一定要记住一点,不要对多人共享的分支使用 git push -f,否则会导致已经将该分支检出到本地的同学在合并以及后续开发中痛苦至极(对于这种情况的解决办法,可以参考:https://git-scm.com/book/zh/v2/Git-%E5%88%86%E6%94%AF-%E5%8F%98%E5%9F%BA 中用变基解决变基的例子)
如何将本地检出分支上的修改提交到其他的分支
有时候我们会遇到比较紧急需求或者 bugfix 的情况,在开发完过后才发现自己还在 master 分支上,忘记了切换分支(也有可能只是我)。我们无法直接将本地的 master 推送到远端,但是有一些方法可以解决这个问题:
- 切换到正确的分支 将代码 cp 过来。
- 如果还未提交,将未提交的代码 stash,切换到对应的提交分支,再使用 stash pop 方法将代码从 stash 栈中取出。
- 使用 git push HEAD: 方法将当前分支推送到远端的指定分支上(如果 HEAD 指向的远端分支已经存在,且两个分支存在提交历史冲突,需要使用-f 进行强行覆盖,需要谨慎使用)。
对本地 commit 进行修改
我们经常遇到讲代码提交成 commit 后,又发现一些需要修改的点的情况,无论是因为编译发现一些遗漏的逻辑,还是因为突然发现了某个 typo 或者多余的空行,这个时候如果修改并且从新提交一个 commit,会导致提交记录中充满了“修复 typo”, “修复另一个 typo”这样没有意义的提交,不但使得提交记录不美观,同时也导致同一个 feature 的提交记录不收敛(当然如果在合入 master 时使用 squash&merge 可以解决这个问题),如果你的上一个 commit 还没有被提交到远端,那么可以在 git add 过后,使用 git commit —amend 命令,这会将当前暂存区的提交合并到上一个 commit 中,同时允许你修改上一条 commit 的 commit message。 当然,你也可以选择让 commit message 保持原样,只要使用 git commit —amend —no-edit 就可以。
Ps:这会修改你最后一次的提交记录,如果你还没有将最后一次提交推送到远端,那么这样做是很安全的,如果你已经将修改提交到了远端,请确保没有其他人此刻与你共享该分支进行开发,因为你需要使用 git push -f 来覆盖推送修改后的最后一条 commit。这会导致其他共享该分支开发的同学 git 的冲突。
什么是 Detached Head? 我该怎么办?
前文我们提到引用的种类有很多,其中 HEAD 引用指向当前检出的项目状态的头部,HEAD 引用通常会指向当前检出分支的引用(他通常是一个指向引用的引用)当我们在当前的分支上开发并提交时,我们将当前分支的引用向前挪动到新的提交对象上,相应的 HEAD 引用也随之指向了新的提交。
但是在某些情况下,HEAD 分支可能不指向某个引用,比如我们检出了某个标签对应的树对象,或者我们检出了某个当前分支上面的提交,那么 HEAD 将不再指向任何分支的引用,而是直接指向了对应的树对象,这种情况下,我们便进入了 detached head 状态,我们可以进行任何常规的 git 操作,也可以在该状态下提交新的代码和 commit,但是当我们检出到其他分支时,如果没有为在 detached head 状态下提交的代码创建新的引用,那些提交将无法再被访问到,git 会对他们进行 gc。所以你如果需要在 detached head 模式下进行开发和提交,一定要记得在检出其他分支前为他们创建引用。(例如创建一个新的分支)
在解决冲突时遇到不了解的修改到底应该接受哪个?
很多同学在解决冲突的时候都会遇到这个问题,如果冲突代码我们比较熟悉还好,但是如果出现冲突的代码我们并不熟悉,只想要使用最新的提交的话,到底应该接受哪部分修改呢? 我们举个很常见的例子:
当你在 experiment 分支上使用 git rebase origin/master 命令将当前分支基于主干进行 rebase 时,如果出现冲突,而你想要应用 master 分支上面的最新修改,则应该选择 HEAD section 中的修改进行提交,此时的冲突 block 与分支的对应关系如下:

如果你使用 git merge origin/master 或者 git pull origin/master 命令将 master 反向合入到 experiemnt 分支,那么此时的冲突 block 会是这样:

可以看到,来自 master 分支的提交被放在了下方的区域中,如果我们想要应用来自 master 分支的修改,则应该选择非 HEAD section 中的修改进行提交,两个种不同的合并操作下,接受同一个分支的提交所进行的选择是相反的。
这看起来很反直觉,这样设计的原因在于两种合并操作站在不同的分支立场上。当你使用 rebase 操作时,由于我们是在 master 分支上重放 experiment 分支分叉上的每次提交,所以 git 是站在 master 分支的立场上,此时若发生冲突,git 会把 rebase 基于的分支(在此例子中,master 分支)上面的修改放在 HEAD section 中,而将 experiment 分支的修改放在下方。 如果是使用 merge 操作反相合并主干分支,那么 git 会站在 experiment 分支的立场上,将 master 分支的提交合入到当前分支。如果遇到冲突,自然会将 master 分支放在非 HEAD 的 section 中了。同学们在解冲突,尤其是自己不清楚的代码冲突时一定要明确二者的区别。
使用 GUI 工具(Sourcetree)来管理 git 仓库
如果你对于 git 命令行的使用并不是那么得心应手,我强烈推荐你使用 source tree 等 gui 工具来辅助你进行项目的 git 管理,sourcetree 提供了非常直观的 git 提交记录图,可以帮助你快速的查看各个文件的状态,不同分支之间的关系,同时也可以让你轻松管理本地以及远端分支,实现文件部分代码区块的回滚,合并多个本地提交,或者将本地修改分成多次提交等操作。sourceTree 允许你快速查看每次提交的修改内容,同时支持一键回滚任意行的改动,十分方便。感兴趣的同学可以去 sourcetree 的官网进行更深入的了解:https://www.sourcetreeapp.com/
图:sourceTree 展示的 git 提交历史
结语
本文章中使用到的例子以及截图大部分都来自https://git-scm.com/book/en/v2 ,git 的功能十分强大,本文章只是围绕着分支操作这个主题,简单介绍了 git 的存储原理。如果你感兴趣,可以去该网站更深入和详细的了解 git 的更多功能和特性。