k8s,helm命令详解
基础运维手册
1、kubernetes运维手册
1.1 整体介绍
1.2 架构描述
1.3 交互逻辑
1.4 kubernetes常用操作
一、查看帮助和集群基础信息
二、获取资源情况
三、资源扩缩容
四、更新资源
五、删除资源
六、对节点的操作
七、与运行中的 Pod 交互
1.5 kubernetes使用问题排查
1.6 kubernetes环境故障排查
2、helm运维手册
2.1 整体介绍
2.2 架构描述
2.3 交互逻辑
2.4 helm常用操作
一、查看Charts
二、从charts部署release
三、查看release
四、release升级和回滚
五、删除release
六、仓库常用命令
2.5 helm故障排查
3、prometheus监控
4、ceph
1、kubernetes运维手册
1.1 整体介绍
Kubernetes是谷歌开源的容器集群管理系统,是Google多年大规模容器管理技术Borg的开源版本,主要功能包括:
• 基于容器的应用部署、维护和滚动升级
• 负载均衡和服务发现
• 跨机器和跨地区的集群调度
• 自动伸缩
• 无状态服务和有状态服务
• 广泛的 Volume 支持
• 插件机制保证扩展性
Kubernetes发展非常迅速,已经成为容器编排领域的领导者
1.2 架构描述
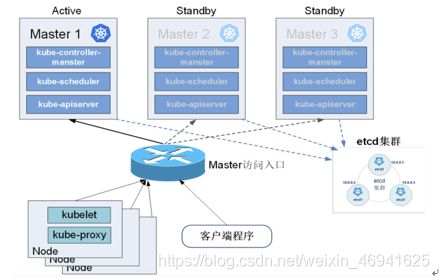
• kube-apiserver:提供资源操作的唯一入口,读写etcd数据库,提供认证、授权、访问控制、API注册和发现等机制
• kube-controller-manager:维护集群状态,比如故障检测、自动扩展、滚动更新等
• kube-scheduler:收集节点负载,按照预定的策略将Pod调度到相应的节点上
• kubelet:负责节点的容器、镜像、卷等的管理,维护容器的生命周期。提供插件机制,支持Volume和Network扩展
• kube-proxy:负责Service的实现,实现内部从Pod到Service 和外部从NodePort到Service的访问
• kubectl:客户端cli工具
1.3 交互逻辑
如架构图所示,pod创建的过程如下:
1. 客户端提交创建请求,通过API Server的Restful API,或者用kubectl命令行工具。支持的数据类型包括JSON和YAML。
2. API Server处理用户请求,存储Pod数据到etcd。
3. kube-scheduler通过API Server查看未绑定的Pod。尝试为Pod分配主机。
4. kube-scheduler通过预选算法过滤掉不符合要求的主机。比如Pod指定了所需要的资源量,那么可用资源比Pod需要的资源量少的主机会被过滤掉,端口被占用的也被过滤掉;
5. kube-scheduler通过优选算法给主机打分,对预选筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把一个deployment类型的pod分布到不同的主机上,使得资源均衡;或者将两个亲和的服务分配到同一个主机上。
6. 选择主机:选择打分最高的主机,进行binding(调用apiserver将pod和node绑定)操作,结果存储到etcd中。
7. kubelet监听Api Server,根据调度结果执行Pod创建操作:绑定成功后,scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器。
8. kubelet调用CNI(Docker 运行或通过 rkt)运行 Pod 的容器。并周期性的对容器生命周期进行探测。(健康检查readness-隔离、liveness-重启)
1.4 kubernetes常用操作
一、查看帮助和集群基础信息
kubectl --help ## 查看帮助
kubectl --version ## 查看k8s版本
kubectl cluster-info ## 查看k8s集群信息,master和服务地址
kubectl cluster-info dump ## 将当前集群状态输出到 stdout
kubectl cluster-info dump --output-directory=/path/to/cluster-state ## 将当前集群状态输出到 /path/to/cluster-state
二、获取资源情况
get命令用于获取集群的一个或一些resource信息。 使用–help查看详细信息。resource包括集群节点、运行的pod、Deployment、service等。
kubectl get nodes ## 查看所有的nodes
kubectl get pods ## 查看default的namespace下所有的pods
kubectl get pods -o wide ## 查看default的namespace下所有的pods,包含pod所在的节点等信息
kubectl get pods --all-namespaces ## 查看所有namespaces下的所有pods
kubectl get deployment my-dep ## 列出指定 deployment
kubectl get pods pod-redis -o yaml ## 以yaml文件形式显示一个pod的详细信息
根据重启次数排序列出pod
kubectl get pods --sort-by='.status.containerStatuses[0].restartCount'
获取所有具有app=cassandra的pod中的version标签
kubectl get pods --selector=app=cassandra rc -o jsonpath='{.items[*].metadata.labels.version}'
使用describe获取resource的详细输出,describe类似于get,同样用于获取resource的相关信息。不同的是,get获得的是更详细的resource个性的详细信息,describe获得的是resource集群相关的信息。describe命令同get类似,但是describe不支持-o选项,对于同一类型resource,describe输出的信息格式,内容域相同。
注:如果发现是查询某个resource的信息,使用get命令能够获取更加详尽的信息。但是如果想要查询某个resource的状态,如某个pod并不是在running状态,这时需要获取更详尽的状态信息时,就应该使用describe命令。
kubectl describe nodes my-node ## 获取节点my-node的详细信息
kubectl describe pods my-pod ## 获取容器my-pod的详细信息
kubectl describe deployments my-dp ## 获取deployment对象my-dp的详细信息
三、资源扩缩容
scale用于程序在负载加重或缩小时副本进行扩容或缩小,如前面创建的nginx有两个副本,可以轻松的使用scale命令对副本数进行扩展或缩小。
##扩展副本数到4:
kubectl scale deployment my-dp --replicas=4
##重新缩减副本数到2:
kubectl scale deployment my-dp --replicas=2
四、更新资源
apply命令可以通过编排文件来部署、更新资源,kubernetes会在引用更新前将当前配置文件中的配置同已经应用的配置做比较,并只更新更改的部分,而不会主动更改任何用户未指定的部分。apply直接在原有resource的基础上进行更新。同时kubectl apply还会resource中添加一条注释,标记当前的apply。类似于git操作。
kubectl apply -f my-deployment.yaml ## 通过新my-deployment.yaml文件创建或者更新deployment资源
还可以直接对已经部署的资源进行编辑,edit提供了另一种更新resource源的操作,在编辑器中编辑任何 API 资源
kubectl edit svc docker-registry ## 编辑名为 docker-registry 的 service
滚动更新rolling-update,rolling-update是一个非常重要的命令,对于已经部署并且正在运行的业务,rolling-update提供了不中断业务的更新方式。rolling-update每次起一个新的pod,等新pod完全起来后删除一个旧的pod,然后再起一个新的pod替换旧的pod,直到替换掉所有的pod。
rolling-update需要确保新的版本有不同的name,Version和label,否则会报错 。
根据rc-nginx.yaml中变更的地方更新rc-nginx-2
kubectl rolling-update rc-nginx-2 -f rc-nginx.yaml
如果在升级过程中,发现有问题还可以中途停止update,并回滚到前面版本
kubectl rolling-update rc-nginx-2 —rollback
rolling-update还有很多其他选项提供丰富的功能,--update-period指定间隔周期,--image=image:v2更新镜像,使用时可以使用-h查看help信息。
五、删除资源
kubectl delete -f ./pod.json # 删除 pod.json 文件中定义的类型和名称的 pod
kubectl delete pod,service baz foo # 删除名为“baz”的 pod 和名为“foo”的 service
kubectl delete pods,services -l name=myLabel # 删除具有 name=myLabel 标签的 pod 和 serivce
六、对节点的操作
通过label命令为kubernetes集群的resource打标签,如前面实例中提到的为rc打标签对rc分组。还可以对nodes打标签,这样在编排容器时,可以为容器指定nodeSelector将容器调度到指定lable的机器上,如如果集群中有IO密集型,计算密集型的机器分组,可以将不同的机器打上不同标签,然后将不同特征的容器调度到不同分组上。
kubectl label node node1 type=compute ## 给节点my-node添加标签type=compute
cordon, drain, uncordon
三个命令配合使用可以实现节点的维护。可以保证维护节点时,平滑的将被维护节点上的业务迁移到其他节点上,保证业务不受影响。如下图所示是一个整个的节点维护的流程(为了方便demo增加了一些查看节点信息的操作):
1)首先查看当前集群所有节点状态,可以看到共四个节点都处于ready状态;
2)查看当前nginx两个副本分别运行在d-node1和k-node2两个节点上;
3)使用cordon命令将d-node1标记为不可调度;
4)再使用kubectl get nodes查看节点状态,发现d-node1虽然还处于Ready状态,但是同时还被禁能了调度,这意味着新的pod将不会被调度到d-node1上。
5)再查看nginx状态,没有任何变化,两个副本仍运行在d-node1和k-node2上;
6)执行drain命令,将运行在d-node1上运行的pod平滑的赶到其他节点上;
7)再查看nginx的状态发现,d-node1上的副本已经被迁移到k-node1上;这时候就可以对d-node1进行一些节点维护的操作,如升级内核,升级Docker等;
8)节点维护完后,使用uncordon命令解锁d-node1,使其重新变得可调度;
9)检查节点状态,发现d-node1重新变回Ready状态。
kubectl cordon my-node ## 标记 my-node 不可调度
kubectl drain my-node ## 清空 my-node 以待维护
kubectl uncordon my-node ## 标记 my-node 可调度
kubectl top node my-node ## 显示 my-node 的指标度量
如果该键和影响的污点(taint)已存在,则使用指定的值替换
kubectl taint nodes foo dedicated=special-user:NoSchedule
七、与运行中的 Pod 交互
logs命令用于显示pod运行中,容器内程序输出到标准输出的内容。跟docker的logs命令类似。如果要获得tail -f 的方式,也可以使用-f选项。
kubectl logs my-pod ## dump 输出 pod 的日志(stdout)
kubectl logs my-pod -c my-container ## dump 输出 pod 中容器的日志(stdout,pod 中有多个容器的情况下使用)
kubectl logs -f my-pod ## 流式输出 pod 的日志(stdout)
kubectl logs -f my-pod -c my-container ## 流式输出 pod 中容器的日志(stdout,pod 中有多个容器的情况下使用)
exec命令用来进入到容器
kubectl exec my-pod -it bash ## 在已存在的容器中执行命令(只有一个容器的情况下)
kubectl exec my-pod -c my-container -it bash ## 在已存在的容器中执行命令(pod 中有多个容器的情况下)
1.5 kubernetes使用问题排查
查看某个资源的定义和用法
kubectl explain
查看对象资源调度、挂卷是否有问题
根据对象是deployment/statefulset/daemonset来修改这里相应字段
kubectl describe deployment/statefulset/daemonset my-resource
查看Pod的状态
kubectl get pods
kubectl describe pods my-pod
监控Pod状态的变化
kubectl get pod -w
可以看到一个 namespace 中所有的 pod 的 phase 变化,请参考 Pod 的生命周期。
查看 Pod 的日志,-f 参数可以 follow 日志输出
kubectl logs my-pod
kubectl logs my-pod -c my-container
kubectl logs -f my-pod
kubectl logs -f my-pod -c my-container
交互式 debug
kubectl exec my-pod -it /bin/bash
kubectl top pod POD_NAME --containers
1.6 kubernetes环境故障排查
1、查看核心组件运行状态
kubectl get pods -n kube-system -o wide
如果发现有核心组件不正常,查看不正常组件日志
kubectl describe pod {不正常组件的pod名称} -n kube-system
kubectl logs {不正常组件的pod名称} -n kube-system
然后登录该不正常pod所在节点,查看messages日志
vim /var/log/messages
2、查看节点运行状态
kubectl get nodes
如果发现有节点不正常,登录该节点,查看相关日志信息:
systemctl status kubelet
systemctl status docker
以及查看messages日志
vim /var/log/messages
节点不正常多跟资源使用有关,也可以结合常用资源使用命令来查看
top ## 观察负载、僵尸进程等情况
free -m
df -h
2、helm运维手册
2.1 整体介绍
一个 Chart 是一个 Helm 包。它包含在 Kubernetes 集群内部运行应用程序,工具或服务所需的所有资源定义。它就类似于一个 Apt dpkg 或一个 Yum RPM 文件的 Kubernetes 环境里面的等价物。
一个 Repository 是 Charts 收集和共享的地方。它就像 Perl 的 CPAN archive 或 Fedora 软件包 repoFedora Package Database。
一个 Release 是处于 Kubernetes 集群中运行的 Chart 的一个实例。一个 chart 通常可以多次安装到同一个群集中。每次安装时,都会创建一个新 release 。比如像一个 MySQL chart。如果希望在群集中运行两个数据库,则可以安装该 chart 两次。每个都有自己的 release,每个 release 都有自己的 release name。
所以,Helm将charts安装到Kubernetes中,每个安装创建一个新release。要找到新的chart,可以搜索Helm charts存储库repositories
2.2 架构描述
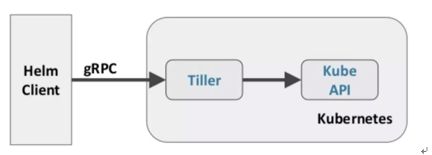
Helm Client 是最终用户的命令行客户端。客户端负责以下部分:
• 本地 chart 开发
• 管理存储库
• 与 Tiller 服务交互
• 发送要安装的 chart
• 查询有关发布的信息
• 请求升级或卸载现有 release
Tiller Server 是一个集群内服务,与 Helm 客户端进行交互,并与 Kubernetes API 服务进行交互。服务负责以下内容:
• 监听来自 Helm 客户端的传入请求
• 结合 chart 和配置来构建发布
• 将 chart 安装到 Kubernetes 中,然后跟踪后续 release
• 通过与 Kubernetes 交互来升级和卸载 chart
2.3 交互逻辑
1、用户通过helm客户端提交chart
2、tiller收到请求,将chart翻译成k8s对象,给apiserver发送请求
3、apiserver收到请求,和etcd通信,将相应资源对象存储到etcd里
2.4 helm常用操作
一、查看Charts
可以通过运行 helm search 查看有哪些 charts 可用
helm search
如果没有使用过滤条件,helm search显示所有可用的charts。可以通过使用过滤条件进行搜索来缩小搜索的结果范围:
helm search mariadb
查看chart详细信息
helm inspect stable/mariadb ## 查看stable库里mariadb的详细信息
二、从charts部署release
要安装新的软件包,请使用该 helm install 命令。最简单的方法,它只需要一个参数:chart 的名称。
helm install stable/mariadb
在安装过程中,helm 客户端将打印有关创建哪些资源的有用信息,release 的状态以及是否可以或应该采取其他的配置步骤。
Helm 不会一直等到所有资源都运行才退出。许多 charts 需要大小超过 600M 的 Docker 镜像,因此可能需要很长时间才能安装到群集中。
要跟踪 release 状态或重新读取配置信息,可以使用 helm status:
helm status happy-panda
三、查看release
通过list和get命令可以查看release列表和详情信息
helm list
helm get
四、release升级和回滚
使用helm upgrade和helm rollback命令用来升级版本和失败时恢复
当新版本的 chart 发布时,或者当你想要更改 release 配置时,可以使用 helm upgrade 命令。
升级需要已有的 release 并根据提供的信息进行升级。由于 k8s chart 可能很大而且很复杂,因此 Helm 会尝试执行最小侵入式升级。它只会更新自上次发布以来发生更改的内容。
helm upgrade -f panda.yaml happy-panda stable/mariadb
我们可以使用 helm get values 看看新设置是否生效。
helm get values happy-panda
如果在发布过程中某些事情没有按计划进行,那么使用回滚到以前的版本很容易 helm rollback [RELEASE] [REVISION]。
helm rollback happy-panda 1
上述回滚我们的 “happy-panda” 到它的第一个 release 版本。release 版本是增量修订。每次安装,升级或回滚时,修订版本号都会增加 1. 第一个修订版本号始终为 1. 我们可以使用 helm history [RELEASE] 查看特定版本的修订版号。
安装 / 升级 / 回滚的有用选项:
这不是 cli 参数的完整列表。要查看所有参数的说明,请运行 helm --help
--timeout:等待 Kubernetes 命令完成的超时时间值(秒),默认值为 300(5 分钟)
--wait:等待所有 Pod 都处于就绪状态,PVC 绑定完,将 release 标记为成功之前,Deployments 有最小(Desired-maxUnavailable)Pod 处于就绪状态,并且服务具有 IP 地址(如果是 LoadBalancer,则为 Ingress )。它会等待 --timeout 的值。如果达到超时,release 将被标记为 FAILED。注意:在部署 replicas 设置为 1 maxUnavailable 且未设置为 0,作为滚动更新策略的一部分的情况下, --wait 它将返回就绪状态,因为它已满足就绪状态下的最小 Pod。
--no-hooks:这会跳过命令的运行钩子
--recreate-pods(仅适用于 upgrade 和 rollback):此参数将导致重新创建所有 pod(属于 deployment 的 pod 除外)
五、删除release
在需要从群集中卸载或删除 release 时,请使用以下 helm delete 命令
helm delete happy-panda
这将从集群中删除该 release。可以使用以下 helm list 命令查看是否已经删除
尽快如此,Helm 总是保留记录发生了什么。需要查看已删除的版本?helm list --deleted 可显示这些内容,并 helm list --all 显示了所有 release(已删除和当前部署的,以及失败的版本)
由于 Helm 保留已删除 release 的记录,因此不能重新使用 release 名称。(如果 确实 需要重新使用此 release 名称,则可以使用此 --replace 参数,但它只会重用现有 release 并替换其资源。)
请注意,因为 release 以这种方式保存,所以可以回滚已删除的资源并重新激活它。
如果需要彻底删除release,则使用
helm delete happy-panda --purge
六、仓库常用命令
可以使用 helm repo list 以下命令查看配置了哪些 repo
helm repo list
新的 repo 可以通过 helm repo add 添加
helm repo add dev https://example.com/dev-charts
由于 chart repo 经常更改,因此可以随时通过运行如下命令确保Helm客户端处于最新状态
helm repo update
2.5 helm故障排查
主要排查tiller服务是否正常
kubectl get po -n kube-system|grep tiller
3、prometheus监控
主要是通过grafana来展示的,具体参照Grafana使用说明
4、ceph
可参照https://lihaijing.gitbooks.io/ceph-handbook/content/