真香!基于ShardingSphere-JDBC的MySQL读写分离
前言
为了减轻每台MySQL主机的访问压力,还可以对MySQL进行读写分离,实际上,主从复制和读写分离一般就是联合使用的。
找到一份好的资料也是学习过程中,非常重要的一个点。你的检索能力越强,你就会越容易找到最合适你的资料。
我这边也整理了一些最新的面试题资料和Java架构学习资料,学习技术内容包含有:Spring,Dubbo,MyBatis, RPC,源码分析,高并发、高性能、分布式,性能优化,微服务 高级架构开发等等。。
有需要的小伙伴可以戳这里免费领取,暗号:CSDN。
这篇水文来聊一下MySQL的读写分离。借助于一些数据库中间件,实现起来贼容易,一看就会!
MySQL读写分离
MySQL读写分离基本原理是让master数据库处理写操作,slave数据库处理读操作。master将写操作的变更同步到各个slave节点。
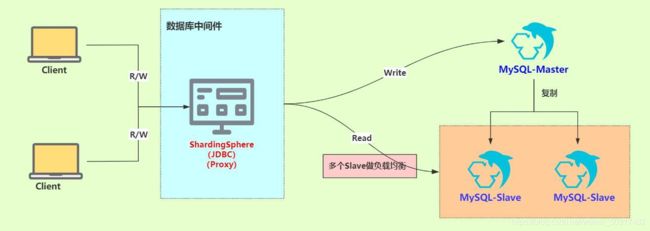
MySQL读写分离能提高系统性能:
- 物理服务器增加,机器处理能力提升。拿硬件换性能。
- slave可以配置myiasm引擎,提升查询性能以及节约系统开销。
- master直接写是并发的,slave通过主库发送来的binlog恢复数据是异步的。
- slave可以单独设置一些参数来提升其读的性能。
- 增加冗余,提高可用性。
如何实现读写分离
MySQL官方提供了MySQL Proxy,但是已经不建议使用了:

与此同时它建议我们使用MySQL Router,再但是,MySQL Router不仅功能少,而且需要在应用程序代码中指定读/写的不同端口,在实际生产环境中应该没人会这样用。
其实,当前已经有不少比较不错的MySQL中间件,像shardingsphere-jdbc,mycat,amoeba等,这些都是比较不错的选择。
这里,我们使用Apache开源项目ShardingSphere的JDBC来实现MySQL的读写分离。#
ShardingSphere-JDBC
ShardingSphere的JDBC组件,称之为Sharding-JDBC,它是一个轻量级的Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
这就意味着,在项目中我们不需要额外安装什么软件,直接引入Jar包依赖,就可以实现数据库的分库分表、读写分离等。
说的直白一点,Sharding-JDBC就是包含了分库分表读写分离功能的JDBC,因此我们可以直接把Sharding-JDBC当做普通的JDBC来使用。

Sharding-JDBC实现读写分离的核心概念
主库
- 添加、更新以及删除数据操作所使用的数据库,目前仅支持单主库。
从库
- 查询数据操作所使用的数据库,可支持多从库。
- 我们使用一主两从的MySQL数据库架构来实现主从复制和读写分离。
主从同步
- 将主库的数据异步的同步到从库的操作。由于主从同步的异步性,从库与主库的数据会短时间内不一致。
负载均衡策略
- 如果有多个从库,可以通过负载均衡策略将查询请求疏导至不同的从库。
基于Sharding-JDBC的MySQL读写分离代码实现
- 主从复制主机配置:

主从同步的数据库为shardingsphere_demo:
log-bin=master-bin
binlog-format=ROW
server-id=1
binlog-do-db=shardingsphere_demo
shardingsphere_demo库有一个表叫laogong:
create table laogong( id int,
name varchar(20),
age int
);
- 创建SpringBoot项目,引入Jar包
引入ShardingSphere的Jar包依赖:
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.1.1version>
dependency>
还用到了druid连接池,mybatis,mysql驱动,这里不展示了。
- 配置文件
配置是整个Sharding-JDBC的核心,是Sharding-JDBC中唯一与应用开发者打交道的模块。
配置模块也是Sharding-JDBC的门户,通过它可以快速清晰的理解Sharding-JDBC所提供的功能。
配置读写分离
根据前文主从复制主机的信息,配置如下:
spring:
shardingsphere:
# 数据源相关配置
datasource:
# 数据源名称
names: master,s1,s2
# MySQL master数据源
master:
# 数据库连接池
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.2.158:3306/shardingsphere_demo? serverTimezone=UTC
username: root
password: 123456
# 两个slave数据源
s1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.2.159:3306/shardingsphere_demo?serverTimezone=UTC
username: root
password: 123456
s2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.2.157:3306/shardingsphere_demo? serverTimezone=UTC
username: root
password: 123456
masterslave:
load-balance-algorithm-type: round_robin
name: ms
master-data-source-name: master
slave-data-source-names: s1,s2
# 其他属性
props:
# 开启SQL显示
sql.show: true
- 创建实体类和Mapper类
实体类的代码这里不贴了,侮辱智商
Mapper类:
@Repository
@Mapper
public interface LaogongMapper {
@Insert("insert into laogong(id, name, age) values(#{id}, #{name}, #{age})") public void addLaogong(Laogong laogong);
@Select("select * from laogong where id=#{id}")
public Laogong queryLaogong(Integer id);
}
- 测试
测试写入数据
向laogong表插入5条数据:
@Test
public void testMSInsert(){
for (int i = 1; i <= 5; i++) {
Laogong laogong = new Laogong();
laogong.setId(i);
laogong.setName("xblzer" + i);
laogong.setAge(new Random().nextInt(30));
laogongMapper.addLaogong(laogong);
}
}
运行结果:

可以看到,插入的SQL语句,全部往master主库写入数据。
- 测试读取数据
读取id=1的数据,循环读取10次,看都从哪个库读取:
@Test
public void testMSQuery(){
for (int i = 0; i < 10; i++) {
Laogong laogong = laogongMapper.queryLaogong(1);
System.out.println(laogong);
}
}
结果验证:

只从S1、S2这两个从库中读取数据。
通过以上两个读取和写入数据的测试,可以可到,通过Sharding-JDBC真的很方便就帮我们实现了读写分离!这个时候我们可以说真香了!
最后
基于Sharding-JDBC的MySQL读写分离用起来真是很方便,而且ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目了,相信ShardingSphere会很快的火起来的。
我们项目上已经用这个做MySQL分库分表读写分离了。这次这篇文章只提到了读写分离,其实Sharding-JDBC还可以实现很多功能:
- 数据分片(分库&分表)
- 读写分离
- 分布式事务
- 分布式治理
- 数据加密
- …
ShardingSphere已经形成了一个生态圈,其功能仍在不断完善。
本次导航结束,以上。