【博学谷学习记录】超强总结,用心分享 | 架构师 Linux学习总结
文章目录
- Linux简介
- Linux 文本处理(grep、sed、awk)
- 查看文件内容(less命令)
- 显示文件开头的内容(head命令)
- 显示文件结尾的内容(tail命令)
- 为什么使用管道?
- grep
- sed
Linux简介
Linux,全称GNU/Linux,是一种免费使用和自由传播的类UNIX操作系统,其内核由Linus Torvalds于1991年10月5日首次发布,它主要受到Minix和Unix思想的启发,是一个基于POSIX的多用户、多任务、支持多线程和多CPU的操作系统
Linux 一般是指 Linux 内核、 Linux 系统、 Linux 发行版。严格意义上说 Linux 是指由 Linus Torvalds 维护的并发布的内核。它的代码只包括内核而不包括其它方面的应用。内核提供系统核心服务,如进程管理,进程的调度,虚拟文件系统,内存的管理等等。
Linux 文本处理(grep、sed、awk)
连接合并文件内容(cat命令)
cat 命令可以用来显示文本文件的内容,也可以把几个文件内容附加到另一个文件中,即连接合并文件。
cat 命令的基本格式如下:
[root@localhost ~]# cat [选项] 文件名
或者
[root@localhost ~]# cat 文件1 文件2 > 文件3
注意,cat 命令用于查看文件内容时,不论文件内容有多少,都会一次性显示。如果文件非常大,那么文件开头的内容就看不到了。不过 Linux 可以使用PgUp+上箭头组合键向上翻页,但是这种翻页是有极限的,如果文件足够长,那么还是无法看全文件的内容。
【例 】将文件 file1.txt 和 file2.txt 的内容合并后输出到文件 file3.txt 中。
[root@localhost base]# ls
file1.txt file2.txt
[root@localhost base]# cat file1.txt
[root@localhost base]# cat file2.txt
[root@localhost base]# cat file1.txt file2.txt > file3.txt
[root@localhost base]# more file3.txt
[root@localhost base]# ls
file1.txt file2.txt file3.txt
分屏显示文件内容(more命令)
在讲解 cat 命令时,我们留下了一个疑问,即当使用 cat 命令查看文件内容时,如果文件过大,以至使用PgUp+上箭头组合键向上翻页也无法看全文件中的内容,该怎么办呢?这就需要使用 more 命令。
more 命令可以分页显示文本文件的内容,使用者可以逐页阅读文件中内容,此命令的基本格式如下:
[root@localhost ~]# more [选项] 文件名
选项 含义
-f 计算行数时,以实际的行数,而不是自动换行过后的行数。
-p 不以卷动的方式显示每一页,而是先清除屏幕后再显示内容。
-c 跟 -p 选项相似,不同的是先显示内容再清除其他旧资料。
-s 当遇到有连续两行以上的空白行时,就替换为一行的空白行。
-u 不显示下引号(根据环境变量 TERM 指定的终端而有所不同)。
+n 从第 n 行开始显示文件内容,n 代表数字。
-n 一次显示的行数,n 代表数字。
查看文件内容(less命令)
less 命令的作用和 more 十分类似,都用来浏览文本文件中的内容,不同之处在于,使用 more 命令浏览文件内容时,只能不断向后翻看,而使用 less 命令浏览,既可以向后翻看,也可以向前翻看。
less 命令的基本格式如下:
[root@localhost ~]# less [选项] 文件名

显示文件开头的内容(head命令)
head 命令可以显示指定文件前若干行的文件内容,其基本格式如下:
[root@localhost ~]# head [选项] 文件名
该命令常用选项以及各自的含义,如表 1 所示。
选项 含义
-n K 这里的 K 表示行数,该选项用来显示文件前 K 行的内容;如果使用 “-K” 作为参数,则表示除了文件最后 K 行外,显示剩余的全部内容。
-c K 这里的 K 表示字节数,该选项用来显示文件前 K 个字节的内容;如果使用 “-K”,则表示除了文件最后 K 字节的内容,显示剩余全部内容。
-v 显示文件名;
注意,如不设置显示的具体行数,则默认显示 10 行的文本数据。
【例 1】基本用法。
[root@localhost ~]# head anaconda-ks.cfg
head 命令默认显示文件的开头 10 行内容。如果想显示指定的行数,则只需使用 “-n” 选项即可,例如:
[root@localhost ~]# head -n 20 anaconda-ks.cfg
这是显示文件的开头 20 行内容,也可以直接写 “-行数”,例如:
[root@localhost ~]# head -20 anaconda-ks.cfg
显示文件结尾的内容(tail命令)
tail 命令和 head 命令正好相反,它用来查看文件末尾的数据,其基本格式如下:
[root@localhost ~]# tail [选项] 文件名

管道
在Linux中存在着管道,它是一个固定大小的缓冲区,该缓冲区的大小为1页,即4K字节。管道是一种使用非常频繁的通信机制,我们可以用管道符“|”来连接进程,由管道连接起来的进程可以自动运行,如同有一个数据流一样,所以管道表现为输入输出重定向的一种方法,它可以把一个命令的输出内容当作下一个命令的输入内容,两个命令之间只需要使用管道符连接即可。
将两个或者多个命令(程序或者进程)连接到一起,把一个命令的输出作为下一个命令的输入,以这种方式连接的两个或者多个命令就形成了管道(pipe)。
Linux 管道使用竖线|连接多个命令,这被shadow称为管道符。Linux 管道的具体语法格式如下:
command1 | command2
command1 | command2 [ | commandN... ]
当在两个命令之间设置管道时,管道符|左边命令的输出就变成了右边命令的输入
为什么使用管道?
我们先看下面一组命令,使用 mysqldump(一个数据库备份程序)来备份一个叫做 wiki 的数据库:
mysqldump -u root -p '123456' wiki > /tmp/wikidb.backup
gzip -9 /tmp/wikidb.backup
scp /tmp/wikidb.backup username@remote_ip:/backup/mysql/
上述这组命令主要做了如下任务:
mysqldump 命令用于将名为 wike 的数据库备份到文件 /tmp/wikidb.backup;其中-u和-p选项分别指出数据库的用户名和密码。
gzip 命令用于压缩较大的数据库文件以节省磁盘空间;其中-9表示最慢的压缩速度最好的压缩效果。
scp 命令(secure copy,安全拷贝)用于将数据库备份文件复制到 IP 地址为 remote_ip 的备份服务器的 /backup/mysql/ 目录下。其中username是登录远程服务器的用户名,命令执行后需要输入密码。
上述三个命令依次执行。然而,如果使用管道的话,你就可以将 mysqldump、gzip、ssh 命令相连接,这样就避免了创建临时文件 /tmp/wikidb.backup,而且可以同时执行这些命令并达到相同的效果。
使用管道后的命令如下所示:
mysqldump -u root -p '123456' wiki | gzip -9 | ssh username@remote_ip "cat > /backup/wikidb.gz"
这些使用了管道的命令有如下特点:
命令的语法紧凑并且使用简单。
通过使用管道,将三个命令串联到一起就完成了远程 mysql 备份的复杂任务。
从管道输出的标准错误会混合到一起。
grep
很多时候,我们并不需要列出文件的全部内容,而是从文件中找到包含指定信息的那些行,要实现这个目的,可以使用 grep 命令
grep 命令的全称:global regular expressions print
grep命令能够在一个或多个文件中,搜索某一特定的字符模式(也就是正则表达式),此模式可以是单一的字符、字符串、单词或句子。
grep 命令的基本格式如下:
[root@localhost ~]# grep [选项] 模式 文件名
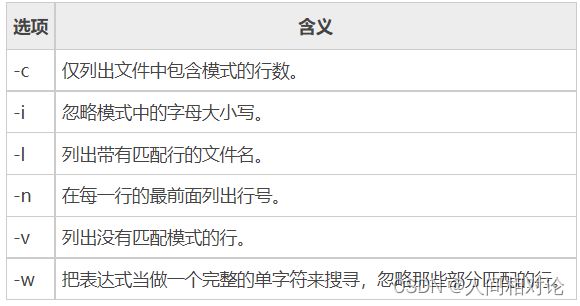
sed
Vim 采用的是交互式文本编辑模式,你可以用键盘命令来交互性地插入、删除或替换数据中的文本。但sed 命令不同,它采用的是流编辑模式,最明显的特点是,在 sed 处理数据之前,需要预先提供一组规则,sed 会按照此规则来编辑数据。
sed 会根据脚本命令来处理文本文件中的数据,这些命令要么从命令行中输入,要么存储在一个文本文件中,此命令执行数据的顺序如下:
每次仅读取一行内容;
根据提供的规则命令匹配并修改数据。注意,sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
将执行结果输出。
当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕。
sed [-hnV][-e<script>][-f<script文件>][文本文件]