【论文笔记】From the Detection of Toxic Spans in Online Discuss to the Analysis of Toxic-to-Civil Transfer
From the Detection of Toxic Spans in Online Discussions to the Analysis of Toxic-to-Civil Transfer
文章目录
- From the Detection of Toxic Spans in Online Discussions to the Analysis of Toxic-to-Civil Transfer
-
- Abstract
- 1. Introduction
- 2. Related Work
- 3. The new TOXICSPANS dataset
- 4. Evaluation framework for toxic spans
- 5. Methods for toxic spans detection
-
- 5.1 Simplistic baselines
- 5.2 Supervised sequence labelling
- 5.3 Weakly supervised learning
- 6. Experimental results for toxic spans
- 7. Toxic spans in toxic-to-civil transfer
-
- 7.1 System-detoxified posts
- 7.2 Explicit Toxicity Removal Accuracy
- 7.3 Human-detoxified posts
- 7.4 Toxicity scores of posts with and without explicit toxicity
- 8. Discuss
- 9. Conclusions and future work
- 个人思考
会议:ACL2022
任务:言论毒性片段检测/言论去毒/文本风格迁移
原文:链接
源码:链接
Abstract
文本毒性片段检测任务旨在检测出文本中存在的具体攻击性表达片段。(该任务源自SemEval2021 Task5)本文开发并公开了一个数据集用于此任务:TOXICSPANS。
通过一系列实验研究发现,序列标注方法在该任务上取得了最佳性能。并且,在训练好的预测帖子是否有毒的二分类器上添加通用的依据抽取(rationale extraction)机制也有显著效果(这些rationales意味着从输入文本中提取简短且具有决定性的文字片段)。
最后,本文使用TOXICSPANS及在其上面训练的模型进一步分析最佳性能的言论去毒模型(Toxic-to-Civil)以及人类在言论去毒任务中的表现。
1. Introduction
在社交媒体上和在线论坛上,有毒内容可以被定义为令人想离开讨论的粗鲁的、不尊重的或不合理的帖子。现有的毒性检测模型和数据集大多关注于对整个帖子进行有毒/无毒的二分类,而非识别文本中特定的致毒片段。该任务可以帮助人工言论评审员避免处理过长的文本,以及找到言论致毒原因。因此,在文本中定位致毒片段是实现内容半自动修正、构建健康在线讨论社区的一个重要步骤。
针对这个新任务,本文发布了第一个标注有毒性片段的英文帖子毒性数据集TOXICSPANS。本文论述了它的创建过程以及提出了一套言论毒性片段检测与评测框架。本文考虑了几个方法:i.序列标注方法;ii.按照依据抽取机制的方法,依靠基于注意力的二元毒性分类器来预测帖子的毒性,然后在推理时调用它的注意力以获取致毒片段。后一种方法的应用范围更广,因为现有的毒性数据集大多仅标注了是否有毒性。序列标注方法展现出更好的性能,但是,尽管是在无致毒片段标注的数据上训练的,后者的二分类模型也展现出了惊人的效果。
本文还研究了在几个数据集上训练的监督和自监督的言论去毒模型的特性,包括最近发布的去毒平行数据集ParaDetox(ACL2022)和最新的TOXICSPANS数据集。在TOXICSPANS上,本文提出了一种方法来评估显式毒性(explicit toxicity)的消除,然后使用这个方法来比较言论去毒模型的行为和性能。最后,通过应用言论致毒片段检测模型,本文评估了人工外包去毒工作的效果。
2. Related Work
文本毒性片段检测任务可以视为一个针对毒性帖子的属性或证据抽取任务。识别片段,最近在鼓吹性和仇恨性言论检测任务中也被提到。但是,即使标注类型(片段)是相似的,鼓吹性言论检测与该任务大不相同。而仇恨性言论则是毒性言论中特定的一种,该言论的检测任务可以使用更加通用的毒性检测器,反之则不是。这就可以解释后续的实验结果中为什么基于仇恨言论数据集HateXplain(AAAI2021)的模型匹配baseline在毒性言论检测上的效果仅略好于在TOXICSPANS上的随机baseline。(见后续的实验部分)
将有毒的言论改写成文明的言论可以被视为一个文本风格迁移任务。本文展示了如何把毒性片段检测用于言论去毒任务的评估,这是首次将这两个任务联系在一个的工作。
3. The new TOXICSPANS dataset
本文使用了一个公开的公众评论(Civil Comments)数据集,CC,该数据集包含对整个帖子的毒性标注。根据该数据集对毒性的定义,本文使用“toxic”作为一个总括术语,涵盖辱骂性语言现象,例如侮辱、仇恨言论、身份攻击或亵渎。我们要求标注者找出那些“粗鲁的、不尊重的,或者不合理地使人想要离开对话”的片段。除了标注毒性,本文还要求他们标注出毒性片段的子类型,在“侮辱”、“威胁”、“人身攻击”、“亵渎”、“其他”之间选择。这个措施一方面提升他们的工作参与感,一方面有助于他们进一步调整他们对于毒性的概念,增加标注者之间达成一致的概率。数据集中包含了文本的毒性子类型,但是由于实验需要,本文在实验中将所有子类型归为单一的毒性类,没有进一步地研究它们。
标注 最初的Civil Coments数据集有1.2M个帖子,本文保留被至少一半的标注者标注为毒性的帖子,这样剩余约30K个毒性帖子。随机选择了11K个帖子作为子集进行毒性片段标注。使用众包标注平台Appen,每个帖子雇佣三个标注者进行标注。标注者需对每个帖子标记出对应的毒性字符序列(片段)。对于每条帖子,数据集包含了所有三个标注员的标注片段。如果标注者确认一个帖子无毒或整段文本都具有毒性,则选择相应的勾选框,而不必标注任何片段。如果被选中,在数据集中将会显示。
然而,无法对任意一个帖子都进行毒性片段标注。例如,在一些帖子中,传达的信息可能具有内在的毒性(例如,一个讽刺性的帖子,间接地声称特定血统的人低人一等)。因此,很难将这些帖子的致毒原因归于特定的片段。这种情况下可能标记为无毒性片段。另一种情况是,很容易识别帖子中的致毒片段,一个帖子可能有多处,但是这些片段只覆盖帖子的很小一部分。
一致性(Agreement) 本文随机挑选了数据集中的87个帖子来评估标注者的一致性。在该研究内容下每个帖子由5个标注者进行标注。针对每对(两个)标注者,我们计算了每个帖子平均的Cohen’s kappa系数,使用字符偏移作为被分类为有毒和无毒的实例,然后取所有帖子的平均。虽然我们的数据集只包含至少一半原始标注者认为有毒的帖子,在 87 个帖子中,只有 31 个帖子被我们的所有五位标注者认为有毒,而51 个帖子被大多数标注者认为有毒;这是众所周知的毒性检测主观性的体现。这31,51和87个帖子的平均kappa系数是0.65,0.55,0.48。表明当标注者对帖子的毒性的认识一致时,对于毒性片段的认识也具有合理的一致性。注意,有毒片段通常很短。这会导致类别不平衡(大多数字符偏移量被标记为无毒),偶然增加一致性(在无毒偏移量上),并导致低 kappa 分数(kappa 调整机会一致性)。这种适度的标注者间的一致性背后的另一个原因是决定帖子是否有毒的固有主观性。本文计算的kappa分数事实上比以往的毒性检测工作略高,从这个意义上说,本文标注者之间的一致性可以被视为一个提升。
Cohen’s kappa系数一致性评价参考1参考2参考3
Ground truth 获取流程:对于每个帖子t,
i.首先将每个标注者标注的每个文本片段映射到该片段在整个帖子文本中的字符级偏移量;
ii.对帖子t的每个字符偏移量分配一个毒性分数,该分数的计算方式为将该字符偏移量标注为毒性的标注者的比例;
iii.仅保留毒性分数高于0.5的字符偏移量,换句话说,至少有一半的标注者将其包含在标记的毒性片段中。

数据集
在数据集中匿名保留所有标注者的结果,以避免忽视少数人的意见。
| 字段名 | probability | position | text | type | support | text_of_post | position_probability |
|---|---|---|---|---|---|---|---|
| 含义 | 全部标注的毒性片段的字符偏移区间(左闭右开)及其毒性分数 | 最终符合要求的毒性片段字符偏移集 | 全部标注的毒性片段文本及其毒性分数 | 全部标注的毒性子类型及其毒性分数 | 标注人数 | 帖子文本内容 | 全部标注的每个字符的偏移量及其毒性分数 |
| 示例 | {(42, 51): 1.0, (17, 20): 0.6666666666666666, (12, 15): 0.3333333333333333} | [17, 18, 19, 42, 43, 44, 45, 46, 47, 48, 49, 50] | {‘stupidity’: 1.0, ‘Die’: 0.6666666666666666, ‘gun’: 0.3333333333333333} | {‘insult’: 1.0, ‘identity based attack’: 0.3333333333333333, ‘other toxicity’: 0.3333333333333333} | 3 | Live by the gun. Die by the gun. Same for stupidity. Gonna love the boring retirement life of 6 walls staring at you, schmuck. | {42: 1.0, 43: 1.0, 44: 1.0, 45: 1.0, 46: 1.0, 47: 1.0, 48: 1.0, 49: 1.0, 50: 1.0, 17: 0.6666666666666666, 18: 0.6666666666666666, 19: 0.6666666666666666, 12: 0.3333333333333333, 13: 0.3333333333333333, 14: 0.3333333333333333} |
探索性分析 数据集中仍有34个帖子的ground truth覆盖了整个帖子,然而,这其中有14个是只有单个词的帖子,并且其他帖子都非常短。并且,有5K个帖子的ground truth是空的,这是groundtruth的获取方法所致。这也表明并不可能将所有的帖子的毒性归因于特定毒性片段。在几乎所有的帖子中,ground truth的覆盖范围低于帖子长度的一半。并且在绝大多数帖子中低于20%。本文定义稠密毒性片段(dense toxic span)为最大连续毒性字符序列。存在一些帖子有多个稠密毒性片段,但是大多数只有一个。

4. Evaluation framework for toxic spans
使用F1-score进行评估。给定一个帖子 t t t, S A i t S_{A_i}^t SAit即模型 A i A_i Ai识别出的毒性片段字符偏移量集。 G G G指Ground truth。且,对于 S G t S_{G}^t SGt是空的情况,即无标注毒性片段的帖子,如果 S A i t S_{A_i}^t SAit也是空,则置F1-score=1;反之若 S A i t S_{A_i}^t SAit不为空,则置其为0。


5. Methods for toxic spans detection
5.1 Simplistic baselines
TRAIN-MATCH:基于查找的模型,把在训练数据中有毒片段内遇到的所有单词分类为有毒。
HATE-MATCH:基于查找的模型,但是训练数据集换成Hatexplain仇恨言论检测数据集(Hatexplain: A benchmark dataset for explainable hate speech detection,AAAI2021)。
RAND-SEQ:将单词随机分类为有毒或无毒。
5.2 Supervised sequence labelling
对于监督学习模型,将毒性片段检测视为序列标注任务,下列方法需要手工地进行训练数据的毒性片段标注。
CNN-SEQ:Spacy的预训练好的CNN,主要用于标注、解析、实体识别任务。在dense toxic span上进行微调,将其视为实体。
BILSTM-SEQ:双向的LSTM。
BERT-SEQ:在毒性片段上微调BERT。
SPAN-BERT-SEQ:在毒性片段上微调SPAN-BERT。
5.3 Weakly supervised learning
对于弱监督学习模型,下列方法只需要对训练数据的帖子的整体毒性进行标注。
训练了一个二分类器来预测每个帖子的毒性标签,并在推理中使用注意力作为一个依据抽取机制来获取毒性片段。在这一方法上使用了两个分类器进行实验:
BILSTM+ARE:BILSTM+Attention,训练时视为一个回归任务,使用概率标签。
BERT+ARE:BERT加上一个dense层,[CLS]的输出表征经过一个sigmod。
为了获取毒性片段,本文分别使用了 BILSTM 的注意力分数和BERT最后一层头部的注意力分数在头部上的平均值。在这两种情况下,本文通过使用应用于注意力分数的概率阈值(根据验证集调整)获得帖子每个单词的二元分类(有毒、无毒)序列。
6. Experimental results for toxic spans
使用五折蒙特卡洛交叉验证(五次随机划分成训练、验证、测试集),对每一折,训练、验证、测试集的比例为8:1:1。
基于依据抽取(ARE)的方法依赖于底层的帖子毒性二分类器,训练时仅使用帖子毒性标签,而不使用毒性片段标注,并且,从Civil Comments数据集中随机选择同等数量的无毒帖子(不包含在TOXICSPAN数据集中的)。在评估该二分类器的性能时,使用一个新的同等平衡的测试集:由从Civil Comments中随机抽样的3K个新的帖子数据组成。
实验结果表明,基于查找的方法表现得都比随机baseline好,但是均不如序列标注模型,这表明单词的毒性是上下文相关的,并不能被基于语料库的上下文无关方法很好地捕获。毒性言论检测相较于仇恨性言论检测是一个范围更广的任务;虽然在帖子毒性二分类上BERT(ROC AUC 96.1%)比BILSTM(ROC AUC 90.9%)性能更好,但是BERT+ARE却表现得比BILSTM+ARE差。此外,BILSTM+ARE的性能接近于BILSTM-SEQ,即使后者是直接在标注好的毒性片段上进行训练的。
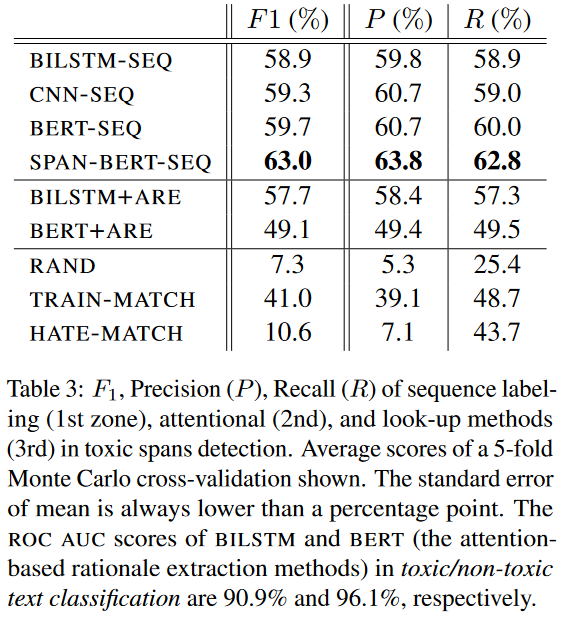
原则上讲,如果底层的二元分类器能够在一个更大的数据集上训练,那么,基于依据抽取机制的毒性片段检测模型(BILSTM+ARE、BERT+ARE)性能应该更好。于是,本文对交叉验证的每折增加80K个有毒和无毒的帖子(从Civil Comments数据集中选择,不包含在TOXICSPANS中的数据)。实验结果显示,对于BILSTM,其F1-socre从90.9%提升到94.2%,而BILSTM+ARE的F1-score从57.7%提升到58.8%。


7. Toxic spans in toxic-to-civil transfer
言论去毒任务,旨在将有毒的文本改述成无毒的文本,并保留源文本的语义信息。这部分内容通过将毒性片段数据集和基于SPAN-BERT-SEQ的毒性片段检测模型联系起来,展示它们如何在言论去毒任务中发挥作用。
7.1 System-detoxified posts
- 模型
CAE-T5:自监督的条件自编码器(Conditional Auto-Encoder),在预处理CC数据集后的非平行数据集上微调。
SED-T5:监督的编码器-解码器框架(Supervised Encoder-Decoder),在一个较小的平行数据集ParaDetox上进行微调。
- 指标
Accuracy(ACC):文本的毒性到文明风格的迁移成功率。计算为改述后的帖子文明版本被BERT毒性分类器判定为无毒的帖子的比例。这里使用一个基于BERT的毒性分类器。(Civil Rephrases Of Toxic Texts With Self-Supervised Transformers,EACL2021)
Perplexity(PPL):衡量生成文本的流畅程度,使用GPT-2计算。
Similarity(SIM):通过计算原始毒性文本和复述后的文明版本(self-SIM)或参考的文明复述版本(ref-SIM,对于平行语料库才有)之间的向量表征的余弦相似度,来衡量风格迁移生成的文本的内容留存度。文本的向量表征由通用的句子把编码器产生。
Geometric Mean (GM) of ACC, 1/PPL, SIM:ACC、1/PPL、SIM的几何平均值(几何平均数是n个变量值连乘积的n次方根)。
- 结果
CAE-T5的GM值更高(PPL更低,ACC更高),总体性能更好。然而,SED-T5的内容保留度更好,即在相似度指标SIM上更高,因为它在平行数据集上进行训练。相反地,CAE-T5使用一种循环一致性损失在非平行数据集上训练,这会导致生成原始帖子中不存在的幻觉内容,这类幻觉内容倾向于通过生成一些流畅的“文明复述语句”来帮助CAE-T5取得更好的PPL指标,但是却不保留帖子的原始语义。此外,尽管所有三个数据集的总体趋势相似(SED-T5 更好地保留内容,CAE-T5 在困惑度和 GM 方面更好),但三个数据集之间也存在一些差异。例如,CAE-T5 在非平行数据集和TOXICSPANS上的准确度(解毒后)上比 SED-T5 好得很多,但两个模型在平行数据集上的准确度相同;并且模型的分数在三个数据集中的表现差异较大。

通过研究从毒性到文明的文本迁移模型如何应对显式的毒性(explicit toxicity),即可以明确指出作为文本毒性来源的片段,可以进一步分析和研究文本去毒模型。而另一面则是未来研究的方向,即研究如何将未被模型或人工显式标注毒性的毒性文本片段迁移、改述成文明风格的无毒文本。(无毒性片段标注的文本如何解毒)
7.2 Explicit Toxicity Removal Accuracy
表 6 的准确度 (ACC) 分数衡量了迁移模型(CAE-T5、SED-T5)改写为(基于 BERT)毒性分类器认为无毒的形式的有毒帖子的百分比。然而,对于无法指定特定致毒片段的言论,是否能够将其改写成无毒的复述,这对于大多数模型来说几乎是不可能完成的任务(甚至对于人类而言)。将这类帖子解毒的唯一方法可能是将原始帖子改得面目全非,这或许会趋使模型在生成复述时产生上节所讨论的幻觉,即复述文本与原始文本的语义相似度很低。
因此,关注包含明确致毒片段的帖子是有意义的。使用这些致毒片段,定义三个新的准确率指标:
ACC2:和ACC一样,但是在计算时,分母忽略无任何毒性片段的帖子。
ACC3:和ACC一样,但是只考虑有毒性片段的帖子,但计算这些帖子中所有有毒片段被模型改述(甚至部分)的比例。
ACC4:对ACC3的进一步约束,要求改写后的帖子被基于BERT的毒性分类器判定为无毒。
表6中,实验结果显示,两个模型在非平行数据集P上的ACC2指标大大提高,说明原来的ACC考虑了很多包含了无明确致毒片段的帖子,限制了这个指标的得分。相反地,在平行数据集P和TOXICSPANS上,模型的ACC2相对于ACC的提升几乎可以忽略不计,因为这两个数据集相对于NP数据集的无致毒片段文本数据更少。此外,所有的实验结果上ACC4总是低于ACC3,这说明模型常常成功检测出毒性片段然后尝试改写它,但是改写后的文本仍然存在毒性。
7.3 Human-detoxified posts
本实验研究人类改述具有已知致毒片段的帖子的程度。使用平行数据集P,该数据集包含了人类改写的帖子去毒复述。因为P数据集不包含致毒片段标注,本文使用SPAN-BERT-SEQ来为源帖识别致毒片段,并保留具有至少一个毒性片段的1354对毒性帖子-无毒复述样本对。在这1354个有毒帖子中,除了6个之外,其余的复述中人类标注的无毒复述均改述了帖子中的致毒片段。在那6个帖子中,主要是通过人工改变了上下文来缓解毒性,而保留了原先的致毒片段。例如“he’s not that stupid” 变成“he’s not stupid”。这种情况从上下文中删除“that”可以减少帖子的冒犯性。总的来说,本实验得出的结论是,人类确实在他们收到的有毒帖子中改写了几乎所有具有明确的毒性案例(片段)。
本实验也使用SPAN-BERT-SEQ在P平行数据集的标注(即无毒复述)数据上进行测试,以检查帖子的无毒复述是否还存在明确的毒性,或复述是否引入新的毒性。实验结果表明有93个帖子的无毒复述仍存在致毒片段。原因主要有两类。i.帖子确实被改写了,但是新的复述语句并不被模型认为是完全文明的;ii.模型假阳。
7.4 Toxicity scores of posts with and without explicit toxicity
本研究使用基于BERT的文本毒性分类器来对P数据集的2778个帖子进行分类。首先将它们分成两个子集:被SPAN-BERT-SEQ检测出有明确致毒片段的1354个帖子和其余存在隐式毒性的帖子。相比后者,BERT毒性分类器在前者上的平均得分更高。二者的差异约为14%(0.94和0.80)。通过从两个子集中重新采样1000个子集(每个子集50个帖子),本文证实了这是一个统计学上的显著性差异(P=0.001),即说明二者来自具有明确差异性的两个不同的总体。
8. Discuss
因为标注致毒片段的成本太高了,因此探索通过在更大数据集上训练的毒性分类器上添加基本的依据抽取机制显得很有意义。
实验结果表明,BILSTM+ARE性能接近于BILSTM-SEQ,因此将来重要的研究工作应当聚焦于无标注的致毒片段识别。这在文本毒性资源有限的情况下可能特别有用。可以简单地在毒性检测模型末端添加一个致毒片段检测组件用于毒性检测,并且只有在检测到毒性时才会调用新组件,而现有模型的其余部分保持不变。因为大部分现实世界的帖子是无毒的,因此这种方法只会增加相对少数的被归类为有毒的帖子的计算负载。仅使用有毒数据做毒性片段检测是一种简化的方法, 未来的工作可以向数据集中添加无毒帖子,然后要求模型先检测出有毒帖子,再提取有毒帖子中的致毒片段。
由于数据集仅包含有毒帖子,因此规模较小,通过增加无毒言论可以扩大规模。
如第 7 节所示,TOXICSPANS 数据集和有毒片段检测器还可以帮助研究和评估在将有毒帖子改写为无毒时显式毒性的去除程度。在这种情况下,有毒片段可用于通过展示有毒片段、它们的上下文及其无毒改述来更好地了解文本的有毒到文明的风格迁移模型的运作方式。
9. Conclusions and future work
本文研究了言论致毒片段检测任务,本文构建并发布了一个数据集TOXICSPANS用于此任务,并提出了基线以及模型。实验结果表明,采用序列标注方法,使用SPAN-BERT在数据集上进行微调取得了最佳性能,此外,BILSTM毒性二分类器加上一个基于注意力机制的属性抽取方法在无致毒片段标注的数据集上表现出的性能也很好,性能接近于监督学习的BILSTM序列标注器。这一结果将促进我们的下一步研究工作聚焦于半监督、无监督的致毒片段识别。在最后部分进行了文本去毒模型的实验研究,通过帮助评估模型和人类如何处理显式的毒性,展示了有毒片段如何帮助处理这个任务。未来的计划在多语言和上下文相关的有毒帖子中研究有毒片段检测。
个人思考
本文主要研究了言论致毒片段检测、言论去毒两大任务。本文的实验丰富且细致,启发了几个未来的研究方向:
- 对于无致毒片段标注的致毒言论片段识别,能否进一步从依据抽取机制中得到启发?(半监督、无监督)
- 对于言论去毒模型,除了显式毒性片段去除以外,针对存在隐式毒性(如反讽等无明确毒性词汇的情况)的言论如何改写?这种情况改述后的文本往往已经面目全非。该任务可视为文本生成任务,能否利用生成任务的特性,在去除言论的隐式毒性的同时,最大程度保留源文本的语义?
- 对于TOXICSPANS数据集中言论毒性子类型、言论毒性分数的使用是否能够促进毒性片段的识别和毒性的去除?