正则表达式
1.体验正则表示式
let time = '2023年4月6日20:46:43';
let times = [...time].filter(item => !Number.isNaN(parseInt(item)))
console.log(times.join(''));
// 使用正则
console.log(time.match(/\d/g).join(''))2.字面量创建正则表达式
let str = 'adsfksjfkg';
let a = 'u';
// 使用字面量书写正则表达
console.log(/u/.test(str)) //false
console.log(eval(`/${a}/`).test(str))//false3.使用对象创建正则表达式
let str = 'afhajukhakg';
// let reg = new RegExp('u', 'g');
// 使用变量
let a = 'u';
let reg = new RegExp(a, 'g');
console.log(reg.test(str)) // true例子:根据用户输入的内容将匹配到的字符高亮显示
abcdefgjgkhlsdf
4.选择符的使用
let str = 'zxcvbnm'
// | (或者) 表示两边任意一个表达式符合就为真
console.log(/z|k/.test(str)) //true
let tel = '020-9999999';
// {7,8}表示限制数字的位数为7到8位
// console.log(/010\-\d{7,8}|020\-\d{7,8}/.test(tel))//true
// /010\-\d{7,8}|020\-\d{7,8}/ 这种情况发现有重复部分 使用原子组
console.log(/^(010|020)\-\d{7,8}$/.test(tel)) //true5.原子表与原子组中的选择符
// []原子表 ()原子组
let reg = /[123456]/;
let str = '2';
console.log(str.match(reg)) //并不是匹配完整的,有或的意思,只匹配其中一个
// ()原子组
let reg1 = /(123|456)/;
let str1 = '455752456123456';
console.log(str1.match(reg1)) ![]()
6.正则转义
let price = 23.34;
// .两层含义 1.除换行外任何字符 2.普通字符
console.log((/\d+\.\d/).test(price))
// let reg = new RegExp('\d+\.\d')
// 在对象创建的正则里
let reg = new RegExp('\\d+\\.\\d')
console.log(reg)
console.log(reg.test(price))
let url = 'https://www.zqw.com'
// ?代表0个或者多个
console.log(/https?:\/\/\w+\.\w+\.\w+/.test(url))7.字符的边界
let str = 'ksdf56sgaga';
// 查找字符串有一个数字即为真
// console.log(/\d/.test(str))//true
// 表示以数字开始 以数字结束
let str1 = '1'
console.log(/^\d$/.test(str1)) //true document.querySelector("[name='user']").addEventListener('keyup', function () {
// 匹配3到6位的a-z字母
let flag = this.value.match(/^[a-z]{3,6}$/)
document.querySelector('span').innerHTML = flag ? '正确' : '失败'
})8.数值与空白元字符
let str = 'sfsfsfsf 548';
//只匹配一个
console.log(str.match(/\d/)) //['5', index: 9, input: 'sfsfsfsf 548', groups: undefined]
// 收集全部数字
console.log(str.match(/\d/g)) //['5', '4', '8']
// 匹配多个
console.log(str.match(/\d+/g)) //['548']let str = `
张三:010-99999999,
李四:020-88888888`;
// 除了 -\d:, 都要
console.log(str.match(/[^-\d:,]+/g)) //(2) ['\n 张三', '\n 李四']
console.log(str.match(/[^-\d:,\s]+/g)) //(2) ['张三', '李四']
// \s 空白 \S 除了空白
console.log(/\s/.test('\n zsdf')) // true 匹配到空白
console.log(str.match(/\d{3}-\d{7,8}/g)) //(2) ['010-99999999', '020-88888888']
// \d 只有数字 \D 除了数字
let str1 = 'sfsdfsfs 2101';
console.log(str1.match(/\D+/)) //['sfsdfsfs ', index: 0, input: 'sfsdfsfs 2101', groups: undefined]9.w与W元字符
// \w 字母数字下划线
let str = 'wwesfsfsfs2010'
console.log(str.match(/\w+/)) //['wwesfsfsfs2010', index: 0, input: 'wwesfsfsfs2010', groups: undefined]
let email = '[email protected]'
console.log(email.match(/\w@\w/)) //['5@q', index: 10, input: '[email protected]', groups: undefined]
console.log(email.match(
/\w+@\w+/)) //['13658465665@qq', index: 0, input: '[email protected]', groups: undefined]
console.log(email.match(
/^\w+@\w+\.\w+$/)) //['[email protected]', index: 0, input: '[email protected]', groups: undefined]
// \W 除了字母数字下划线
console.log('qwef@'.match(/\W/)) //['@', index: 4, input: 'qwef@', groups: undefined]
// a \w 5 10
let username = prompt('情输入用户名')
console.log(/^[a-z]\w{4,9}$/.test(username))10 点元字符的使用
// . 除了换行符外的所有字符 s 单行模式
let str = `
weewsfsfsf
sdfsfsfsg
`
console.log(str.match(/.+/))//[' weewsfsfsf\n', index: 1, input: '\n weewsfsfsf\n sdfsfsfsg\n ', groups: undefined]
console.log(str.match(/.+/s)) // ['\n weewsfsfsf\n sdfsfsfsg\n ', index: 0, input: '\n weewsfsfsf\n sdfsfsfsg\n ', groups: undefined]
let tel = '010 - 99999999'
console.log(tel.match(/\d+ - \d{8}/)) // ['010 - 99999999', index: 0, input: '010 - 99999999', groups: undefined]
console.log(tel.match(/\d+\s-\s\d{8}/)) //['010 - 99999999', index: 0, input: '010 - 99999999', groups: undefined]11.匹配所有字符
// []匹配里面的内容之一
console.log(str.match(/[#$%$%$&%b]/)) //['b', index: 1, input: 'ab', groups: undefined]
console.log(str.match(/#$%$%$&%b/)) //null
let str1 = `
wesfsfs @@@
sfsfs
`
console.log(str1.match(/[\d\D]+<\/span>/))
console.log(str1.match(/[\s\S]+<\/span>/)) //['\n wesfsfs @@@\n sfsfs\n ', index: 5, input: '\n \n wesfsfs @@@\n sfsfs\n \n ', groups: undefined]
console.log(str1.match(/.+<\/span>/s)) //['\n wesfsfs @@@\n sfsfs\n ', index: 5, input: '\n \n wesfsfs @@@\n sfsfs\n \n ', groups: undefined]12 i 与 g 模式修正符
i 不区分大小写
g 匹配全部
let str = 'abaAfdfs'
console.log(str.replace(/a/gi,'@')) //@b@@fdfs13 m多行匹配修正符实例
let str = `
#1 js,200元 #
#2 php,300元 #
#3 sfkjskgj.com # 等级考试
#4 node.js,180元 #
`
let lesson = str.match(/^\s*#\d+\s+.+\s+#$/gm).map((v) => {
v = v.replace(/\s*#\d+\s*/, '').replace(/#/, '');
[name, price] = v.split(',')
return {
name,
price
}
})
console.log(JSON.stringify(lesson,null,2))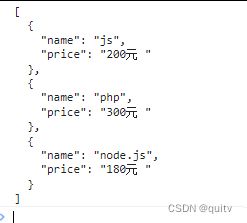
14.汉字与字符属性
let name = "songZX,你好中国,upup....加油!!!";
let str = "豆腐";
// 匹配所有字母
console.log(name.match(/[a-z]+/gi)); // ["songZX", "upup"]
// 匹配标点符号
console.log(name.match(/\p{P}/gu)); // [",", ",", ".", ".", ".", ".", "!", "!", "!"]
// 匹配汉字
let strs = str.match(/\p{sc=Han}+/gu);
console.log(strs); // ["豆腐"]
// 匹配汉字
let hanzi = name.match(/[\u4e00-\u9fa5]+/g);
console.log(hanzi); // ["你好中国", "加油"]15.lastIndex 属性的使用
let name = "songzx";
// match获取元素只能获取到第一个元素的主信息
// 加上g后主信息会丢失
console.log(name.match(/\w/));
let reg = /\w/g;
// 使用exec每检索一次,正则中的lastindex会加1
while ((res = reg.exec(name))) {
console.log(res);
// 此模式正则必须为g模式
console.log(reg.lastIndex);
}有效率的 y 模式
y 模式表示匹配到不符合的就停掉,不会继续往后匹配,必须连续的符合条件的
let name = "我的qq号是,1111111111,22224545488,6411313416544婚姻加入";
// 查到数字,逗号有或没有
// y 模式找到后就不会继续往后找
let reg = /(\d+),?/y;
reg.lastIndex = 7;
let qqList = [];
while ((res = reg.exec(name))) {
console.log(res);
qqList.push(res[1]);
}
console.log(qqList); // ["1111111111", "22224545488", "6411313416544"]原子表的基本使用
let name = "szxsfsacsdf";
// 原子表表示里面的内容时或者的关系,检测的内容在其中就可以被匹配到
let namereg = /[szx]/g;
console.log(name.match(namereg));
let time = "2020-s11-s13";
// \1 和 \2必须配合()使用,\1表示后面的内容必须和第一个小括号匹配到的内容相同
let reg = /^\d{4}([-\/])(s)\d{2}\1\2\d{2}$/;
console.log(time.match(reg));区间匹配
[a-z] 匹配 26 位小写字母
[0-9] 匹配 0-9 之间的数字,包含 0 和 9
// [a-z] 或者 [0-9] 表示区间,只能是升序书写,不能降序书写
let a = "s5df5sf5s165s6dfsdf513d2f";
// 匹配0-9的数字
let numreg = /[0-9]+/g;
console.log(a.match(numreg)); // ["5", "5", "5", "165", "6", "513", "2"]
// 匹配字母
let objreg = /[a-z]+/g;
console.log(a.match(objreg)); // ["s", "df", "sf", "s", "s", "dfsdf", "d", "f"]排除匹配
let name = "skkkzglllag";
// [^kl]表示排除字母k或者字母l
let reg = /[^kl]+/g;
console.log(name.match(reg));原子表字符不会解析
let name = "(soeng).+";
// 在原子表中的特殊字符不会被当成有特殊含义的字符,只会当做特殊字符来匹配
let reg = /[().+]/g;
console.log(name.match(reg)); // ["(", ")", ".", "+"]正则操作DOM元素
玩具
sjfkskg sfsfadsfs
sjfksfjlsfs
认识原子组
let dom = `
标题一
标题二
`;
// 一个小括号包起来的东西被称为原子组,\1表示与第一个原子组相同的内容
let reg = /<(h[1-6])>[\s\S]*<\/\1>/g;
console.log(dom.match(reg)); // ["标题一
", "标题二
"]邮箱验证使用原子组
验证邮箱表达式:/^[\da-z][\w.]+@(\w+.)+(com|cn|org)$/i
含义:以数字或者字母开头,数字字母下划线为主体,一个 @符号,后面跟上数字字母下划线和小数点,可以为多个,以 com 或 cn 或 org 结尾
原子组引用完成替换操作
let str = `
wwsfjsklajfs
学习第一
jjisjdf
`;
let reg = /<(h[1-6])>([\s\S]+)<\/\1>/gi
let res = str.replace(reg, (p0, p1, p2) => `${p2}
`);
console.log(res)嵌套分组和不记录分组
原子组里面加上?: 表示不记录该原子组,但是原子组的功能仍然生效
let url = `
http://www.baidu.com
https://taobao.cn
https://www.zhifubao.com
`;
// 原子组里面加上?:表示不记录该原子组,但是原子组的功能仍然生效
let reg = /https?:\/\/((?:\w+\.)?\w+\.(?:com|cn))/gi;
let urls = [];
while ((res = reg.exec(url))) {
// 1 表示第一个原子组
urls.push(res[1]);
}
console.log(urls); // ["www.baidu.com", "taobao.cn", "www.zhifubao.com"]
重复匹配的使用
+:一个或者多个
*:零个或者多个
?:有或者没有
{1,2}:一个到两个,最少一个,最多 2 连个,数字随便定义
重复匹配对原子组影响
let name = "sososososososos";
// 连续匹配so,使用原子组包起来是里面的内容就变成了一个整体
console.log(name.match(/(so)+/g)); // ["sososososososo"]禁止贪婪
? 禁止贪婪,会匹配最小的那个单位
let name = "soooooo";
// *:零个或多个,加上问号表示匹配0个
let reg = /so*?/g;
console.log(name.match(reg)); // ["s"]
// +:一个或多个,加上问号表示只匹配1个
reg = /so+?/g;
console.log(name.match(reg)); // ["so"]
// ?:0个或者1个,再加上问号表示只匹配0个
reg = /so??/g;
console.log(name.match(reg)); // ["s"]
// {2,5} 表示匹配2到5个,加上问号表示匹配2个
reg = /so{2,5}?/g;
console.log(name.match(reg)); // ["soo"]
使用 matchAll 完成全局匹配
matchAll 获取到的是一个迭代对象,可以被遍历到
字符串的 search 方法和 match 方法
let urls = `
http://www.baidu.com,
http://taobao.com.cn,
https://www.tmall.com/
`;
// 字符串的search方法,找到后返回字符串所在下标,否则返回-1
console.log(urls.search("baidu")); // 24
let reg = /https?:\/\/(\w+)?(\w+\.)+(com|cn)/g;
// ["http://www.baidu.com", "http://taobao.com.cn", "https://www.tmall.com"]
console.log(urls.match(reg));
$ 符在正则替换中的使用
$` : 获取替换元素左边的元素
$‘ : 获取替换元素右边的元素
$& : 获取替换元素本身
let time = "2020-05-05";
console.log(time.replace(/-/g, "/")); //2020/05/05
let tel = "(0631)-150518888";
let telreg = /\((\d{3,4})\)-(\d+)/g;
// 在replace中$1表示第一个原子组匹配到的内容
console.log(tel.replace(telreg, "$1/$2")); // 0631/150518888
// $` : 获取替换元素左边的元素
// $' : 获取替换元素右边的元素
// $& : 获取替换元素本身
let name = "123你好+++";
console.log(name.replace("你好", "$`$&$'")); // 123123你好++++++
原子组起别名
使用 ?
起原子组的别名
使用 $读取别名
百度
支付宝
后等断言
(?=xxx) 匹配右侧是 xxx 的字段
张三先生和张三女士是天造地设的一对
前等断言
(?<=href=(['"])) 前面是 href = 单引号或者双引号的字段
百度
雅虎
后不等断言
?! 表示不是以什么什么结尾
let user = `阅读量:999
新增人数:10人`;
// 匹配前面不是空格的一个或多个,后面不是数字的字段
let reg = /\S+(?!\d+)$/g;
console.log(user.match(reg).join("")); // 新增人数:10人
前不等断言
?
// ?使用断言模糊电话号
// 不使用断言
let tels = `15036999999`;
let reg = /(\d{3})(\d{4})(\d+)/g;
tels = tels.replace(reg, (v, ...args) => {
args[1] = "*".repeat(4);
return args.splice(0, 3).join("");
});
console.log(tels); // 150****9999
// 使用断言
let newtel = `15036999999`;
// 匹配前面是由3位数字组成,后面是由4位数字组成的字段
let newreg = /(?<=\d{3})\d{4}(?=\d{4})/g;
newtel = newtel.replace(newreg, (v) => {
// 将这个字段替换成4个*号
return "*".repeat(4);
});
console.log(newtel); // 150****9999