详解C语言的编译与链接
文章目录
- 写在前面
- 1.程序的翻译环境和执行环境
- 2.详解编译+链接
-
- 2.1翻译环境
- 2.2编译的几个阶段
-
- 2.2.1 预编译
- 2.2.2 编译
- 2.2.3 汇编
- 2.2.4 链接
- 2.3 运行环境
- 3. 总结
写在前面
众所周知,我们写的代码是放在一个或多个xxx.c的文件,你知道从源代码到可执行文件经历了哪些过程吗?或许这个问题一直困扰着你,那就跟着我,让我们一起来探寻其中的奥秘吧!
本文用到的编译器:
1.vs2013(windows下面)
2.gcc编译器(linux下面)
1.程序的翻译环境和执行环境
在ANSI C的任何一种实现中,存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。
第2种是执行环境,它用于实际执行代码。
2.详解编译+链接
2.1翻译环境
一个程序可能会有多个xxx.c的源文件,每个源文件都会单独经过编译器的编译生成一个xxx.obj的目标文件(window系统下)。
每个目标文件由链接器(linker)捆绑在一起,链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中。形成一个单一而完整的可执行程序。
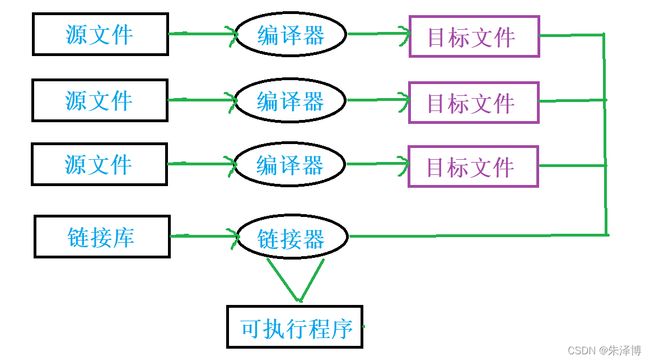
事实真的是像上面那样的吗?下面来我们通过一个例子先大致感受一下上面的过程。

2.2编译的几个阶段
一个xxx.c文件,经过编译链接以后,最终变成可执行的xxx.exe文件,经过了如下几个过程:
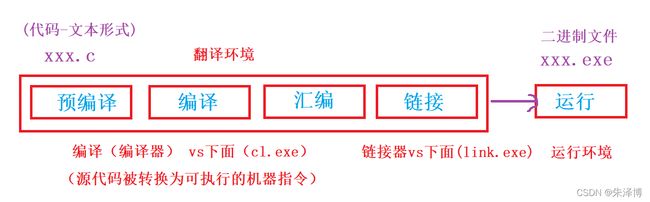
由于vs是集成开发环境,具体的细节没办法很好的观察,接下来我们用linux底下的gcc编译器,来逐一分析各个阶段的究竟做了哪些事情。
2.2.1 预编译
(1)我们在编译器里面写如下代码:
int main()
{
int a = 10;
int b = 20;
int c = a + b;
return 0;
}
紧接着执行gcc test.c -E -o test.i,这句话的意思是预编译test.c以后停下来,并将结果输出到test.i里面去。

打开test.i文件看一下:

我们在编译器再写如下代码:
#include 执行完gcc test.c -E -o test.i以后,我们再次打开test.i文件看一下:
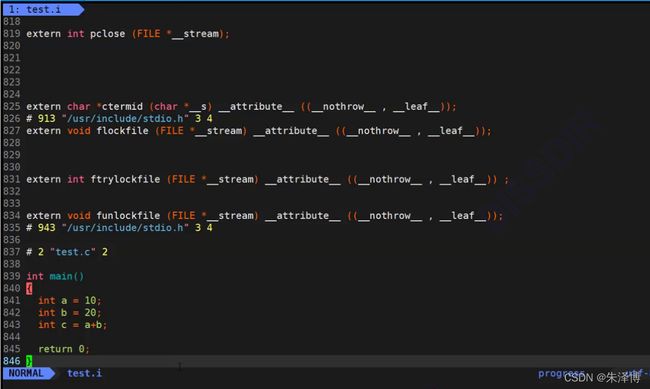
打开文件以后我们发现了,前面多了800多行代码。到这里我们应该能感受到的一件事情是,预处理阶段做的一件事情是头文件包含。
紧接着我们在做一个测试,我们自己定义一个头文件test.h,定义如下:
//test.h
int Add(int x, int y);
然后在test.c这个文件包含我们自己定义的头文件test.h,执行完gcc test.c -E -o test.i以后,我们再次打开test.i文件看一下:
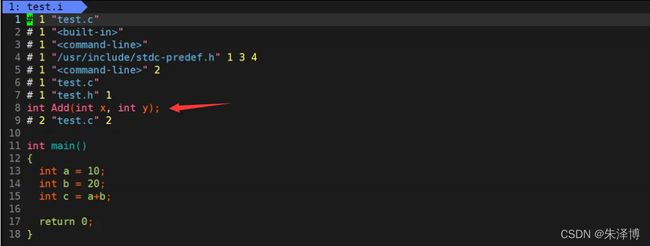
至此我们明白了,头文件的包含是在预编译阶段完成的。
(2)我们在编译器里面写如下代码:
#include "test.h"
#define MAX 100
int main()
{
int a = MAX;
int b = 20;
int c = a + b;
return 0;
}
我们执行完gcc test.c -E -o test.i以后,打开test.i文件看一下:
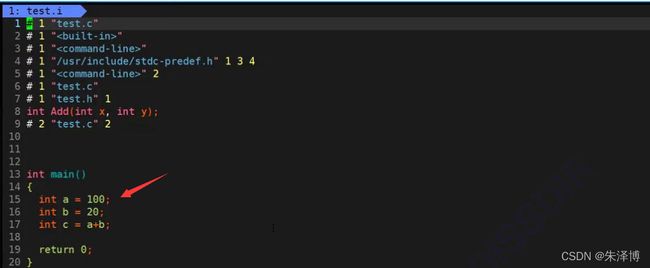
打开文件以后我们发现,#define定义的MAX,已经被替换成了100。所以#define定义符号的替换也是在预编译阶段完成的。
(3)我们在编译器里面写如下代码:
#include "test.h"
#define MAX 100
//这是一个注释
int main()
{
int a = MAX;
int b = 20;
int c = a + b;
return 0;
}
我们执行完gcc test.c -E -o test.i以后,打开test.i文件看一下:

打开文件以后我们发现,刚刚写的注释经过预编译以后就看不到了。所以在预编译阶段还做了另外一个是事情,就是删除注释。
(4)总而言之,预编译是在编译之前做的一些事情的处理,是一些文本的操作。
2.2.2 编译
我们用gcc test.i -S 编译我们的test.i文件,这句话的意思是编译完成之后就停下来,结果保存在test.s中。结果如下:
我们打开test.s文件看一下:
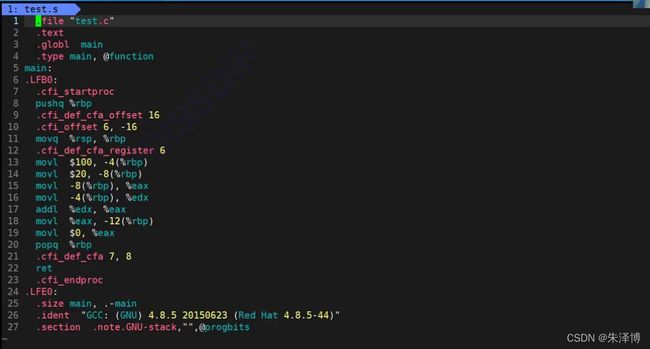
我们可以直观的感受到编译这个过程是将C语言代码转化为了汇编代码。而这个大的过程实际上做了如下几个事情:
1:语法分析
2.词法分析
3.语义分析
4.符号汇总
关于语法分析,词法分析,语义分析这些大家有兴趣了解的可以看一下《编译原理》这本书,这里面有详细的讲解,这里就不做赘述。
紧接着我们重点说一下符号汇总,因为在后面的链接里面我们会用到这个东西。首先符号汇总,汇总的都是全局的符号,局部变量的符号是汇总不到的。
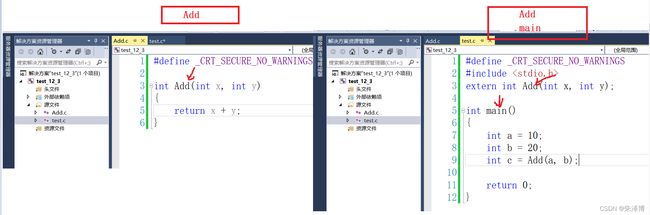
我们通过一个例子来理解一下这个符号汇总:
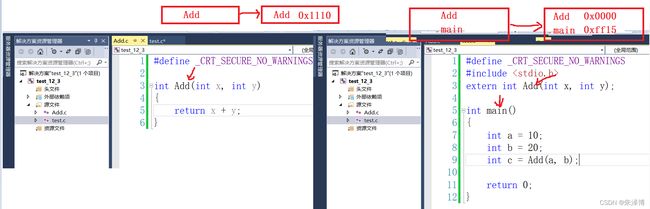
通过上面的分析我们知道,每一个xxx.c的源文件都会单独经过编译器的编译,所以Add.c被单独编译的时候会汇总到Add这一个符号,而test.c被编译的时候会汇总到Add,main这两个符号。
2.2.3 汇编
我们用gcc -c test.c 编译我们的test.c文件,这句话的意思是汇编完成之后就停下来,结果保存在test.o中。(windows底下生成的是xxx.obj目标文件,linux底下生成的是xxx.o的目标文件)结果如下:

我们打开test.o文件看一下:

由于这是二进制的文件,而我们用文本的形式来打开的,所以我们根本读不懂。因此,我们可以直观的感受到汇编这个过程是将汇编代码转化为了二进制指令(机器指令)。
此外,在汇编阶段还完成了一件事---->形成符号表。前面经过我们的分析,在编译这个阶段进行了符号汇总,而在汇编阶段则是形成了一张符号表。简单的理解一下这张表格就是:符号名+它的地址。
上面我们知道,经过汇编以后会生成xxx.o的目标文件。而在linux系统下,xxx.o的目标文件是elf格式的。它会把一个文件分成几个段,每个段代表着不同的意思。有个工具叫readelf可以看的懂它,因此我们可以用这个工具打开我们的test.o文件来观察一下。我们输入readelf test.o -a看一下它的所有段。

这里我们不过分解读它的段。
这里我们重点关注一下它最下面的符号。写如下代码:
#include "test.h"
#define MAX 100
//这是一个注释
int Add(int x, int y)
{
return x + y;
}
int g_val = 100;
int main()
{
int a = MAX;
int b = 20;
int c = Add(a, b);
return 0;
}
我们gcc -c test.c 编译我们的test.c文件,然后readelf test.o -a来打开这个文件:
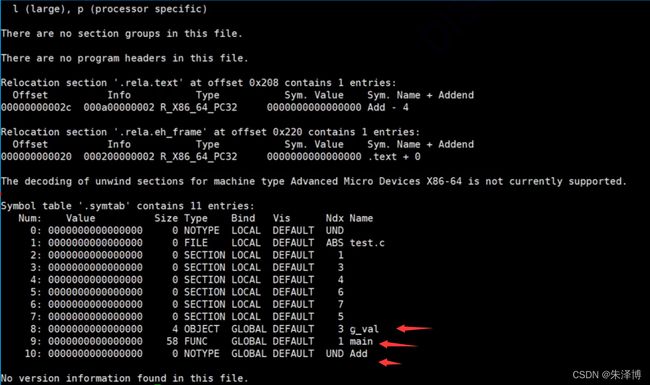
从上面的图中,我们可以看出,打箭头的三个信息,就是我们在汇总符号表的时候汇总的符号。
2.2.4 链接
通过上面的分析,我们知道,生成的目标文件通过链接器链接在一起,最终生成可执行的程序。而在linux底下生成的xxx.out的可执行程序的格式也是elf的。
所以在这个阶段把它们链接在一起,就是把它们对应的段合并起来。当然它们合并肯定是有一定规则的,最终它们会合并成一个。
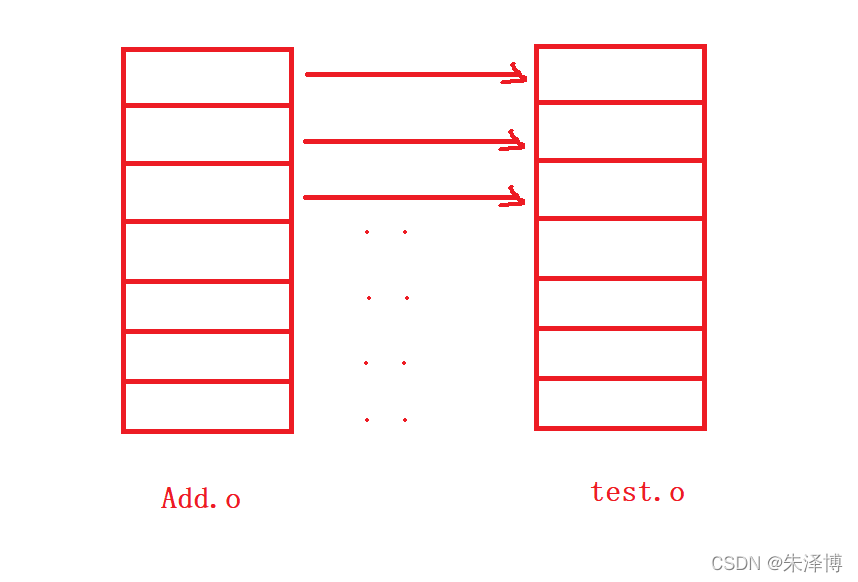
这个阶段还做了一件事情—>符号表的合并和重定位。
通过上面的分析,我们知道,每个xxx.o的文件中都有自己的符号表,在这个阶段也会把他们的符号表合并成一个。

这也是为什么在Add.c里面写的函数可以在test.c中调用的一个原因。当test.c想调用Add函数的时候,它就会去符号表里面查找Add,找到以后,然后拿到它地址进行调用。
2.3 运行环境
程序执行的过程:
- 程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
- 程序的执行便开始。接着便调用main函数。
- 开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回
地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程
一直保留他们的值。- 终止程序。正常终止main函数;也有可能是意外终止。
3. 总结
下面用一张图来总结一下各个过程做了哪些事情:
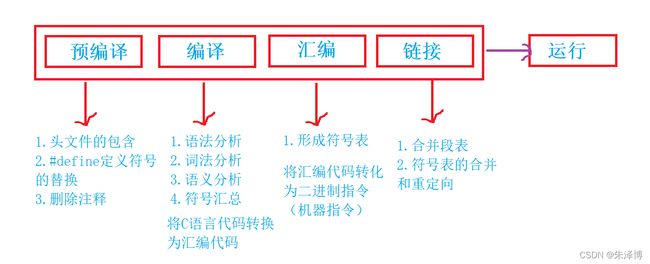
本篇到这里就结束了,如果大家还想深入的理解这个东西,这里给大家推荐一本书《程序员的自我修养》,有兴趣读者的可以读一下,如若需要电子版,评论留言或私信我,我分享给大家。
若本篇内容对您有所帮助,请三连点赞,关注,收藏支持下。
创作不易,白嫖不好,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !
