Ruby_10_JSON与XML解析


Ruby JSON
本章节我们将为大家介绍如何使用 Ruby 语言来编码和解码 JSON 对象。
环境配置
在使用 Ruby 编码或解码 JSON 数据前,我们需要先安装 Ruby JSON 模块。
在安装该模块前你需要先安装 Ruby gem,然后,我们再使用 Ruby gem 安装 JSON 模块。
但是,如果你使用的是最新版本的 Ruby,可能已经安装了 gem,如图所示:
在irb中,如果require "json"返回true,则说明已经安装json解析模块

如果,提示的是LoadError: cannot load such file,
那么就需要用ruby的包管理工具gem命令来安装Ruby JSON 模块:
$gem install json
使用 Ruby 解析 JSON
以下为JSON数据,将该数据存储在 anime.json 文件中:
{
"coder": "beyond",
"未闻花名": [
"面码",
"宿海仁太"
],
"龙与虎": [
"逢坂大河",
"高须龙儿"
],
"可塑性记忆": [
"艾拉",
"水柿司"
]
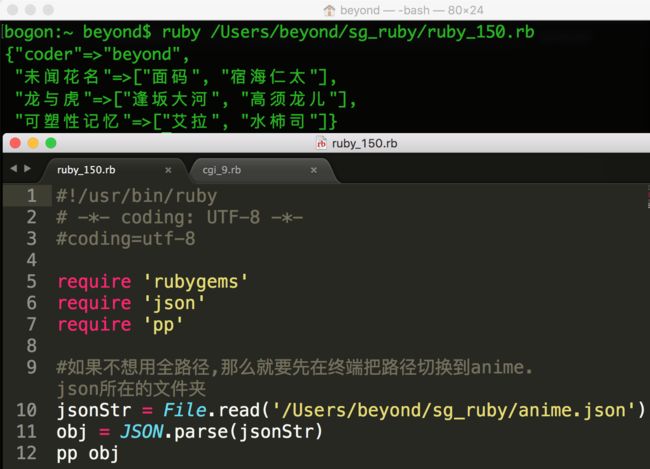
}以下的 Ruby 程序用于解析以上 JSON 文件;
#!/usr/bin/ruby
# -*- coding: UTF-8 -*-
#coding=utf-8
require 'rubygems'
require 'json'
require 'pp'
#如果不想用全路径,那么就要先在终端把路径切换到anime.json所在的文件夹
jsonStr = File.read('/Users/beyond/sg_ruby/anime.json')
obj = JSON.parse(jsonStr)
pp obj以上实例执行结果为:
Ruby XML, XSLT 和 XPath 教程
什么是 XML ?
XML 指可扩展标记语言(eXtensible Markup Language)。
可扩展标记语言,标准通用标记语言的子集,一种用于标记电子文件使其具有结构性的标记语言。
它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。
它非常适合万维网传输,提供统一的方法来 描述和交换 独立于应用程序或供应商的 结构化数据。
XML解析器结构和API
XML的解析器主要有DOM和SAX两种。
- SAX解析器是基于事件处理的,需要从头到尾把XML文档扫描一遍,在扫描的过程中,每次遇到一个语法结构时,就会调用这个特定语法结构的事件处理程序,向应用程序发送一个事件。
- DOM是文档对象模型解析,构建文档的分层语法结构,在内存中建立DOM树,DOM树的节点以对象的形式来标识,文档解析完成以后,文档的整个DOM树都会放在内存中。
Ruby 中解析及创建 XML
RUBY中对XML的文档的解析可以使用这个REXML库。
REXML库是ruby的一个XML工具包,是使用纯Ruby语言编写的,遵守XML1.0规范。
在Ruby1.8版本及其以后,RUBY标准库中将包含REXML。
REXML库的路径是: rexml/document
所有的方法和类都被封装到一个REXML模块内。
REXML解析器比其他的解析器有以下优点:
- 100% 由 Ruby 编写。
- 可适用于 SAX 和 DOM 解析器。
- 它是轻量级的,不到2000行代码。
- 很容易理解的方法和类。
- 基于 SAX2 API 和完整的 XPath 支持。
- 使用 Ruby 安装,而无需另外单独安装。

以下为实例的 XML 代码,保存为movies.xml:
逢坂大河
25集
2008年
这个是龙与虎的介绍
面码
11集
2011年
这个是那朵花的介绍
平泽唯
24集
2009年
这个是轻音少女的介绍
关于dom,sax,pull解析的几点简单对比
dom解析:
优点:简单易学,可对文档进行修改,如删除节点,增加节点等,灵活性较高,读取速度较快,
缺点:解析时,把整个xml文档全部加载到内存中,占用较多资源
使用范围:如果需要对文档进行修改,dom解析肯定是首选,
如果仅仅是读取文档中的某些内容或全部内容,而不作任何的修改,建议不要使用dom解析,而用sax解析或者pull解析.
sax解析:
优点:解析速度很快,不需要把文档读入内存,并且可以根据自身需求来获取数据,而不必解析整个文档
缺点:需要自己编写事件处理逻辑,使用麻烦,并且还不能同时访问文档中的不同部分.
使用范围:对于较大的文档有较好的解析能力,所以适用大文档的解析
pull解析:感觉像是sax的升级版,比sax好用一些
优点:不必自己写事件逻辑,并且也不需要把文档读到内存,
缺点:对文档进行修改比较困难
DOM 解析器
让我们先来解析 XML 数据,首先我们先引入 rexml/document 库,
通常我们可以将 REXML 在顶级的命名空间中引入:
#!/usr/bin/ruby
# -*- coding: UTF-8 -*-
#coding=utf-8
require 'rexml/document'
#???Excuse Me???
include REXML
xmlFilePath = "/Users/beyond/sg_ruby/movies.xml"
xmlFile = File.new(xmlFilePath)
xmlDoc = Document.new(xmlFile)
#打印Root元素
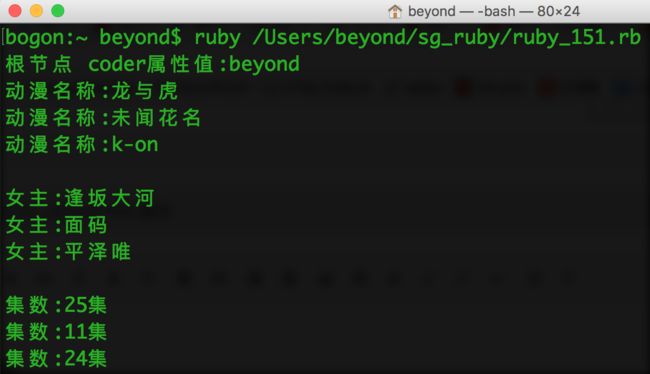
root = xmlDoc.root
puts "根节点 coder属性值:" + root.attributes["coder"]
#打印动漫名称
xmlDoc.elements.each("movielist/movie"){|m|
print "动漫名称:", m.attributes["name"],"\n"
}
puts ""
#打印动漫女角
xmlDoc.elements.each("movielist/movie/actress"){|e|
print "女主:",e.text,"\n"
}
puts ""
#打印动漫集数
xmlDoc.elements.each("movielist/movie/episodes"){|e|
print "集数:",e.text,"\n"
}以上实例输出结果为:
SAX 解析器
处理相同的数据文件:movies.xml,不建议使用SAX解析一些个小文件
以下是个最简单的实例:
#!/usr/bin/ruby
# -*- coding: UTF-8 -*-
#coding=utf-8
require 'rexml/document'
require 'rexml/streamlistener'
#???Excuse Me???
include REXML
class BeyondListener
#实现SAX解析的3个接口,(开始节点事件处理程序,结束节点事件处理程序,读到文本时的事件处理程序)
include REXML::StreamListener
# 实现接口
# 节点开始事件处理程序
def tag_start(*nodeAndAttributeArr)
#节点名称
nodeName = nodeAndAttributeArr[0]
print "开始节点名:#{nodeName}--->"
#节点的属性
attributeName = nodeAndAttributeArr[1]
if attributeName.length > 0
attributeName.each{|key,value|
puts "拥有属性名:#{key},其值为:#{value}"
}
end
end
# 实现接口
# 读到文本时的事件处理程序
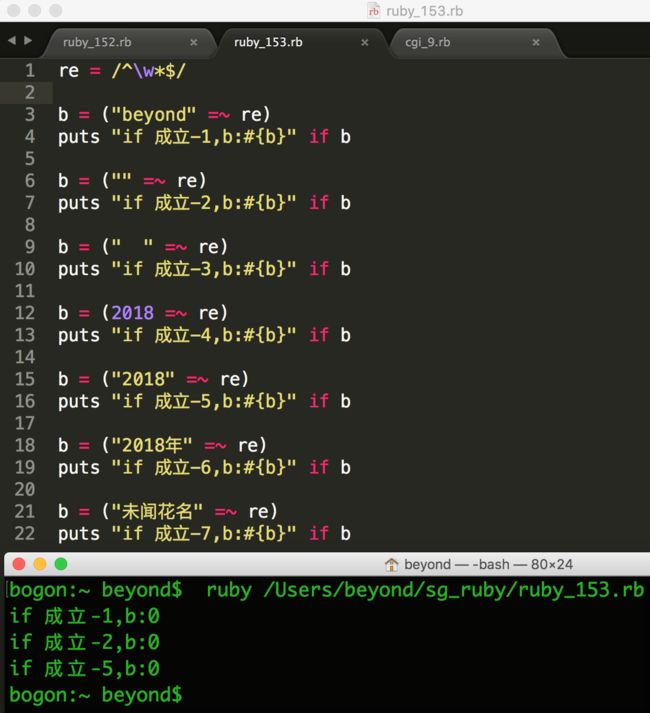
def text(data)
#这个正则是做啥的???Excuse Me???
#ruby中 \w 不能匹配汉字,只能匹配数字,字母,下划线
#当data匹配正则成功的时候(比如data是tiger),b = 0, if 0 为真,就直接返回了,没有下面的输出了
#当data匹配正则失败的时候(比如data是中文:龙与虎),b = nil(也就是空), if 空 为假,所以就会往下执行,把中文文本进行输出
b = (data =~ /^\w*$/)
return if b
# 如果文本太长,大于40的长度,就在后面用...省略
suffix = data.length > 40 ? "..." : ""
#新的data,用原来的data的前40个字符 + 后缀suffix连接起来
dataBrief = data[0..40] + suffix
#输出处理后的文本
puts "包含的文本是:#{dataBrief.inspect}"
end
def tag_end(*nodeAndAttributeArr)
#节点名称
nodeName = nodeAndAttributeArr[0]
print "结束节点名:#{nodeName}<---","\n\n"
end
end
#主线程
listener = BeyondListener.new
xmlFilePath = "/Users/beyond/sg_ruby/movies.xml"
xmlFile = File.new(xmlFilePath)
Document.parse_stream(xmlFile,listener)
先补充一下用到的Ruby里的基础知识: 0 在ruby的条件语句if里是真,只有false和nil(也就是空)为假
下面的正则匹配的是有N个 或者 没有 \w的情况,
其中\w代表的是数字或字母或下划线,但在Ruby中不包括汉字
正则匹配成功的话,b = 0, 所以if b是成立的,因为在ruby中,0也是真,只有false和nil是假
然后,再运行ruby_152.rb的SAX解析XML的代码,如下图所示,输出结果为:
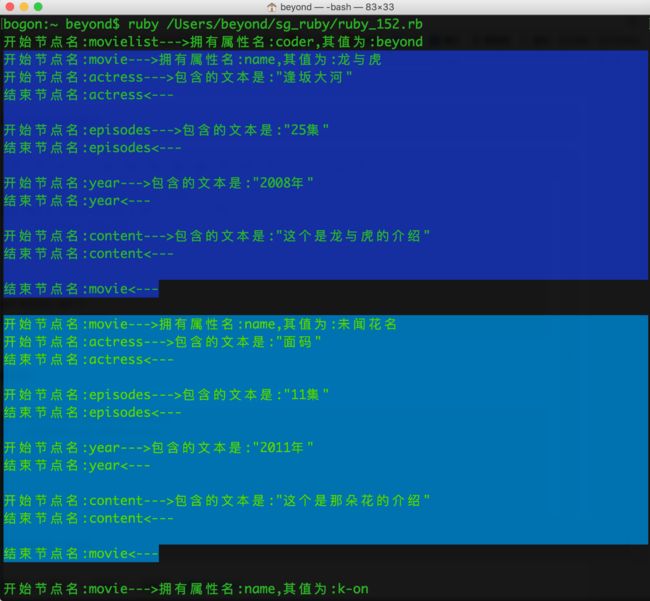
bogon:~ beyond$ ruby /Users/beyond/sg_ruby/ruby_152.rb
开始节点名:movielist--->拥有属性名:coder,其值为:beyond
开始节点名:movie--->拥有属性名:name,其值为:龙与虎
开始节点名:actress--->包含的文本是:"逢坂大河"
结束节点名:actress<---
开始节点名:episodes--->包含的文本是:"25集"
结束节点名:episodes<---
开始节点名:year--->包含的文本是:"2008年"
结束节点名:year<---
开始节点名:content--->包含的文本是:"这个是龙与虎的介绍"
结束节点名:content<---
结束节点名:movie<---
开始节点名:movie--->拥有属性名:name,其值为:未闻花名
开始节点名:actress--->包含的文本是:"面码"
结束节点名:actress<---
开始节点名:episodes--->包含的文本是:"11集"
结束节点名:episodes<---
开始节点名:year--->包含的文本是:"2011年"
结束节点名:year<---
开始节点名:content--->包含的文本是:"这个是那朵花的介绍"
结束节点名:content<---
结束节点名:movie<---
开始节点名:movie--->拥有属性名:name,其值为:k-on
开始节点名:actress--->包含的文本是:"平泽唯"
结束节点名:actress<---
开始节点名:episodes--->包含的文本是:"24集"
结束节点名:episodes<---
开始节点名:year--->包含的文本是:"2009年"
结束节点名:year<---
开始节点名:content--->包含的文本是:"这个是轻音少女的介绍"
结束节点名:content<---
结束节点名:movie<---
结束节点名:movielist<---XPath 和 Ruby
我们可以使用XPath来查看XML ,XPath 是一门在 XML 文档中查找信息的语言(查看:XPath 教程)。
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集,可扩展标记语言(eXtensible Markup Language))文档中某部分位置的语言。
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。
Ruby 通过 REXML 的 XPath 类支持 XPath,它是基于树的分析(文档对象模型):
实例代码如下:
#!/usr/bin/ruby
# -*- coding: UTF-8 -*-
#coding=utf-8
require "rexml/document"
#???Excuse Me???
include REXML
filePath = "/Users/beyond/sg_ruby/movies.xml"
xmlFile = File.new(filePath)
xmlDoc = Document.new(xmlFile)
#使用XPath光速打印第一个动漫名
movie = XPath.first(xmlDoc,"//movie")
p movie
# ...
#打印所有的动漫女主
XPath.each(xmlDoc,"//actress"){|element|
puts element.text
}
#获取所有电影的介绍,并返回数组
contentArr = XPath.match(xmlDoc,"//content").map { |element|
element.text
}
p contentArr 以上实例输出结果如下:
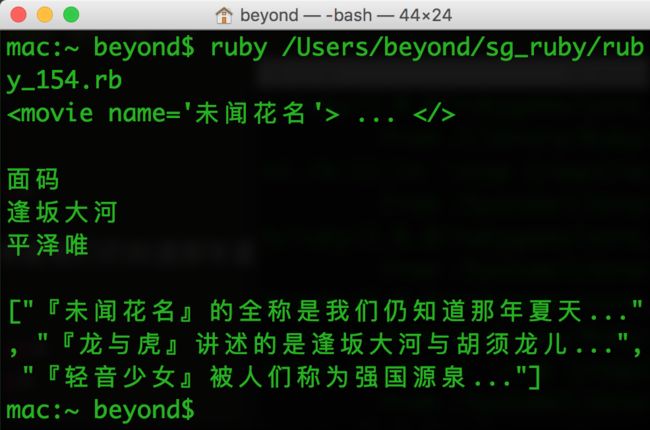
附上movies.xml如下:

XSLT 和 Ruby
Ruby 中有两个 XSLT 解析器,以下给出简要描述:
XSLT 指 XSL 转换(Transfer),说白了,就是一个转换器,能将用XSL语言描述的XML文档转换成其他文档(如XHTML等)。
XSL 指扩展样式表语言(eXtensible Stylesheet Language), 它是一个 XML 文档的样式表语言。
在此教程中,你将学习如何使用 XSLT 将 XML 文档转换为其他文档,比如 XHTML。
第1个XSTL解析器:Ruby-Sablotron
这个解析器主要是为Linux操作系统编写的,需要以下库:
- Sablot
- Iconv
- Expat
第2个XSTL解析器:XSLT4R
XSLT4R 用于简单的命令行交互,可以被第三方应用程序用来转换XML文档。XSLT4R需要XMLScan操作,包含了 XSLT4R 归档,它是一个100%的Ruby的模块。
这些模块都可以使用标准的Ruby安装方法(即Ruby install.rb)进行安装。
XSLT4R 语法格式如下:
ruby xslt.rb stylesheet.xsl document.xml [arguments]
您可以先在irb中require "xslt" 看看是否有ruby-xslt模块:

如果没有,则使用gems安装,先查找一下gems远程库有哪些xslt,如图所示:

然后使用gem install命令安装:
sudo gem install ruby-xslt

然后您就可以在应用程序中使用XSLT4R了,只需要引入XSLT及输入你所需要的参数即可完成对xml文档的转换。
实例代码如下(???Excuse Me???代码有问题,大家不用试了,!!!找不到xslt!!!):
# !!!还是找不到xslt啊!!!require "xslt" stylesheet = File.readlines("stylesheet.xsl").to_s xml_doc = File.readlines("document.xml").to_s arguments = { 'image_dir' => '/....' } sheet = XSLT::Stylesheet.new( stylesheet, arguments ) # output to StdOut sheet.apply( xml_doc ) # output to 'str' str = "" sheet.output = [ str ] sheet.apply( xml_doc )
Ruby Web Services 应用 - SOAP4R
什么是 SOAP?
简单对象访问协议(SOAP,全写为Simple Object Access Protocol)是交换数据的一种协议规范。
SOAP 是一种简单的基于 XML 的协议,它使应用程序通过 HTTP 来交换信息。
简单对象访问协议 是交换数据的一种协议规范,是一种轻量的、简单的、基于XML(标准通用标记语言下的一个子集)的协议,
它被设计成在WEB上交换 结构化的和固化 的信息。
SOAP4R 安装
SOAP4R 用于 Ruby 的 SOAP 应用。
SOAP4R 安装代码如下:
sudo gem install soap4r

注意:你的ruby环境也可能已经安装了该该组件。
Linux 环境下你也可以使用 gem 来安装该组件,命令如下:
$ gem install soap4r --include-dependencies
如果你是window环境下开发,你需要下载zip压缩文件,并通过执行 install.rb 来安装。
SOAP4R 服务
SOAP4R 支持两种不同的服务类型:
- 基于 CGI/FastCGI 服务 (SOAP::RPC::CGIStub)
- 独立服务 (SOAP::RPC:StandaloneServer)
RPC(Remote Procedure Call)即远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
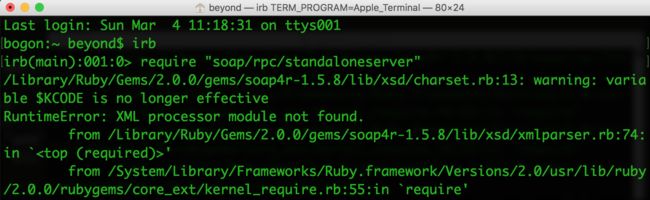
本教程将为大家介绍如何建立独立的 SOAP 服务。步骤如下:(由于出现下面的异常错误,接下来的内容被迫中止)

未完待续,下一章节,つづく