FuseDream论文阅读笔记 文本生成图像 text2image
论文地址
论文代码
背景:
使用CLIP和GAN来完成T2I任务,一种常规的做法就是最大化输入文本与生成图像在CLIP空间上的得分,论文中把这个分数叫做![]() ,也就是最大化这两者的余弦相似度(这是CLIP的原理),可以用如下公式表达。
,也就是最大化这两者的余弦相似度(这是CLIP的原理),可以用如下公式表达。

 表示GAN的输入,一般就是高斯分布中随机采样的噪声,但是在这,作者使用的是BigGAN,他在论文中也说了,BigGAN的生成器的输入就是随机噪声和图像类别,还说了这个BigGAN是在ImageNet上训练的,包含了1000个类别。
表示GAN的输入,一般就是高斯分布中随机采样的噪声,但是在这,作者使用的是BigGAN,他在论文中也说了,BigGAN的生成器的输入就是随机噪声和图像类别,还说了这个BigGAN是在ImageNet上训练的,包含了1000个类别。 就是文本描述。
就是文本描述。
如果单纯最大化这个![]() 分数就会有两个矛盾的问题
分数就会有两个矛盾的问题
1:CLIP得分容易被攻击,即图像中的一些小邻域范围内易产生高得分的CLIP分数,比如下面这些红色圈圈的图像,可能图像与描述之间的CLIP分数很高,但显然这些图像并不是我们想要的,甚至和输入语义是相违背的。

2:最大化![]() 分数确实可以生成与原始图像相似且
分数确实可以生成与原始图像相似且![]() 分数高的图像。
分数高的图像。
论文工作:
分析现有的CLIP+GAN模型的问题瓶颈,提出3个改进点:
1. Robust Score:原始CLIP得分并不能作为GAN空间中优化的良好目标函数,因为它往往会产生语义无关的图像,从而“对抗性地”最大化CLIP得分。提出AugCLIP评分。
2. 改进优化策略:在GAN空间中最大化CLIP得分产生高度非凸的多模态优化问题,使用一种新的初始化和过度参数化策略来解决这个问题。
3. 组合生成Composed Generation:生成效果容易受预训练的GAN影响,难以生成训练集之外的图像。提出合成生成技术,将两幅图像协调调优,以便可以无缝合成在一起。做法是将合成生成公式转化为一个新的双层优化问题,该问题最大化AugCLIP得分,将感知一致性得分作为次要目标,使用动态屏障梯度下降算法解决。
各个工作具体介绍:
1. AugCLIP:
公式如下

I'是I的随机扰动,I来自于候选数据增强的分布,作者们使用了DiffAugment中提到的随机着色、随机平移、随机裁剪、随机调整大小的方式。
AugCLIP对于对抗性攻击更为稳健,因为必须同时攻击大多数随机增强图像上的CLIP分数,才能攻击成功,这要比单纯攻击一张图像要困难的多。
AugCLIP的消融实验如下:
两个实验都是基于一张初始图像狗,来生成一只猫。
上面一排是用![]() 的,会发现即使后来的
的,会发现即使后来的![]() 分数越来越高,但生成的图像还是狗的样子。
分数越来越高,但生成的图像还是狗的样子。
下面的AugCLIP分数,分数高生成的图像也更符合。

2. 优化
作者提出一种初始化和超参数化策略来改进优化
传统方法是从单个噪声开始初始化的。作者提出从初始化M个噪声副本中开始采样,选择其中前k大AugCLIP分数的噪声,使用他们作为后续优化对的初始基向量。
重新定义这个噪声,我的理解是优化学习这k个噪声的权重,因为重新定义的噪声是前k大个噪声的组合,下面的公式就是优化学习w
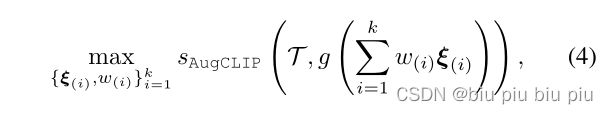
{ ![]() }从k个选定的AugCLIP分数最大的噪声中进行初始化,
}从k个选定的AugCLIP分数最大的噪声中进行初始化,![]() 从1/k开始初始化。作者设置了M为10000和相对较小的k(≤15)。
从1/k开始初始化。作者设置了M为10000和相对较小的k(≤15)。
组合权重{![]() }的更新对应于基向量(那k个噪声向量)的线性跨度中的快速和全局移动,使得更容易逃离局部最优。
}的更新对应于基向量(那k个噪声向量)的线性跨度中的快速和全局移动,使得更容易逃离局部最优。
在实验中,作者使用BigGAN,噪声从N(0,1)采样,类别特征从ImageNet的1000个类别中随机选择。
3. 组合生成
通过合成由GAN生成的两幅图像来扩展图像空间并减少数据偏差,以获得高度灵活性。
这部分暂时没看懂。之后再补充。
模型效果
1. 定量分析
与其他模型对比,GAN-IC到DF-GAN是有图像文本对训练的,DALL-E到BigSleep是无语言训练。
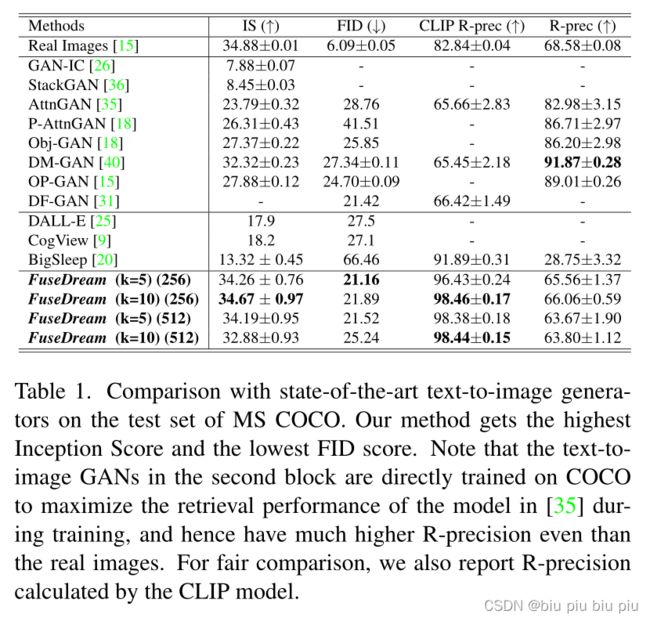
FuseDream中的BigGAN是在ImageNet上训练的,尽管评估是在COCO上进行的,效果依然很好
2. 定性分析
对比模型在COCO数据集的效果

不同艺术风格的图像,如下图第一行,将Style改变为不同的描述
不同纹理、背景的图像,如下图第二行,第二行最后一个例子为各国的美食
不合事实的图像,如下图第三行还有开头的蓝狗

在实验过程中,没有改变BigGAN的参数
总结
作者在conclusion中提到,FuseDream是training-free和zero-shot的,且易于定制,对于计算资源有限或有特殊需求的用户来说很容易访问。