Densely Connected Pyramid Dehazing Network
Abstract
提出了一种新的端到端的单幅图像去雾方法,称为稠密连接金字塔去雾网络(DCPDN),该方法可以联合学习透射图、大气光照和去雾。通过将大气散射模型直接嵌入到网络中,实现了端到端的学习,从而保证了所提方法严格遵循物理驱动的散射模型进行去雾。受密集网络能够最大化不同层次沿着信息流的启发,提出了一种新的边缘保持密集连接编解码器结构,并采用多级金字塔池模块来估计传输图。利用新引入的保边损失函数对网络进行优化。为了进一步融合估计的透射图与去雾结果之间的互结构信息,提出了一种基于生成对抗网络框架的联合鉴别器,用于判断对应的去雾图像与估计的透射图的真伪。进行消融研究以证明在估计的透射图和去雾结果下评价的每个模块的有效性。大量实验表明,该方法与现有方法相比有显著的改进。代码和数据集可从以下网址获取:https://github.com/hezhangsprinter/DCPDN
1. Introduction
在严重的雾霾条件下,大气中的漂浮颗粒物,如黄昏和烟雾,极大地吸收和散射光,导致图像质量下降。这些退化又可能影响许多计算机视觉系统的性能,例如分类和检测。为了克服由雾引起的退化,文献[33、5、42、3、13、21、27、51、24、58、8、10、9、34]中已经提出了基于图像和视频的雾去除算法。
由于雾的存在而导致的图像劣化(大气散射模型)在数学上被公式化为
![]()
其中I是观察到的雾图像,J是真实场景辐射率,A是全局大气光,指示环境光的强度,t是透射图,z是像素位置。透射贴图是与距离相关的因素,它会影响到达相机传感器的光线比例。当大气光A均匀时,透射图可以表示为![]() ,其中β表示大气的衰减系数,d是场景深度。在单幅图像去雾中,给定I,目标是估计J。
,其中β表示大气的衰减系数,d是场景深度。在单幅图像去雾中,给定I,目标是估计J。
可从公式中观察到。1在去雾过程中存在两个重要方面:(1)准确估计透射图;(2)准确估计大气光。除了几项侧重于估计大气光的工作[4,40]外,大多数其他算法更侧重于准确估计透射图,并且它们在估计大气光时利用经验法则[13,29,33,41]。这主要是由于通常相信透射图的良好估计将导致更好的去雾。这些方法可大致分为两大类:基于先验的方法和基于学习的方法。基于先验的方法通常利用不同的先验来表征传输图,例如暗通道先验[13],对比度颜色线[10]和Haze-line先验[3],而基于学习的方法,例如基于卷积神经网络(CNN)的方法,试图直接从训练数据中学习传输图[42,33,5,51,24]。一旦估计了透射图和大气光,就可以如下恢复去雾图像
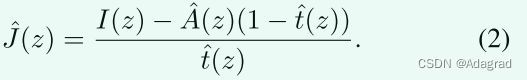
虽然基于学习的方法已经取得了巨大的进步,但是一些因素阻碍了这些方法的性能,并且结果远非最优。这主要是因为:1.透射图估计的不准确性转化为低质量的去雾结果。2.现有的方法没有利用端到端的学习,并且不能捕捉透射图、大气光和去雾图像之间的内在关系。不相交的优化可能会妨碍整体去雾性能。最近,在[24]中提出了一种联合优化整个除雾网络的方法。这是通过利用线性变换将透射图和大气光嵌入到一个变量中,然后学习轻量级CNN来恢复干净的图像来实现的。
在本文中,我们采取了一种不同的方法来解决图像去雾的端到端学习。特别地,我们提出了一种新的图像去雾架构,称为密集连接金字塔去雾网络(DCPDN),其可以被联合优化以通过遵循图像退化模型方程同时估计透射图、大气光以及图像去雾。1(见图2)。换句话说,端到端学习是通过嵌入等式1通过深度学习框架提供的数学运算模块直接进入网络。然而,训练这样一个复杂的网络(具有三个不同的任务)是非常具有挑战性的。为了简化训练过程并加速网络收敛,我们利用了一种分阶段学习技术,首先逐步优化网络的每个部分,然后联合优化整个网络。为了确保估计的透射图在去雾时保持锐利的边缘并避免光晕伪影,基于梯度算子和CNN结构的前几层可以充当边缘提取器的观察,提出了一种新的边缘保持损失函数。此外,提出了一种具有多级池模块的密集连接的编码器-解码器网络,以利用来自不同级别的特征来估计传输图。为了利用透射图和去雾图像之间的结构关系,提出了一种基于联合鉴别器的生成对抗网络(GAN)。联合鉴别器鉴别一对估计的透射图和去雾图像是真实的还是假对。为了保证大气光也可以在整个结构内被优化,采用U网[35]来估计均匀大气光图。图1中所示的是使用所提出的方法的样本去雾图像。
本文主要贡献如下:
·提出了一种新型的端到端联合优化去雾网络。这可以通过嵌入公式1通过数学运算模块直接导入优化框架。因此,它允许网络联合地估计透射图、大气光和去雾图像。整个网络通过分阶段学习方法进行训练。
·提出了一种保持边缘的金字塔密集连接编解码器网络,用于精确估计传输图。进一步,利用新提出的边缘保持损失函数对该算法进行了优化。
·由于估计的透射图和去雾图像的结构高度相关,我们利用GAN框架内的联合鉴别器来确定成对样本(即透射图和去雾图像)是否来自数据分布。
·在两个合成数据集和一个真实世界图像数据集上进行了广泛的实验。此外,还与几种最新技术水平的方法进行了比较。此外,进行了消融研究,以证明所提出的网络中的不同模块所获得的改进。
2. Related Work
Single Image Dehazing.
单幅图像去雾是一个高度不适定的问题。各种基于先验和基于学习的手工方法已经被开发出来以解决这个问题。
基于先验的手工制作:Fattal [9]提出了一种基于物理的方法,通过估计场景的反照率。由于在有雾条件下拍摄的图像总是缺乏颜色对比度,Tan [41]等人提出了一种基于块的对比度最大化方法。在[22]中,Kratz和Nishino提出了一个因子MRF模型来估计反照率和深度场。受晴朗天气下户外物体至少有一个颜色通道明显较暗这一观察结果的启发,He等人在[13]中提出了暗信道模型来估计透射图。最近,Fattal [10]提出了一种色线方法,该方法基于小图像块通常在RGB颜色空间中呈现一维分布的观察结果。类似地,Berman等人[3]提出了在表征干净图像之前的非局部补丁。
学习型:与使用不同先验来估计传输图的上述方法中的一些不同,Cai等人[5]引入了端到端CNN网络,用于利用新颖的BReLU单元来估计传输。最近,Ren等人[33]提出了一种多尺度深度神经网络来估计透射图。这些方法的局限性之一是它们通过仅考虑它们的CNN框架中的传输图来限制它们的能力。针对这一问题,李.等人[24]提出了一种一体化去雾网络,其中利用线性变换将透射图和大气光编码为一个变量。最近,针对去雾问题的合成和真实世界雾图像的几个基准数据集被引入到社区[53,25]。
Generative Adversarial Networks (GANs).
GAN的概念首先由Goodfellow等人在[12]中提出,以通过经由博弈论极小极大优化框架有效地学习训练图像的分布来合成真实感图像。GAN在合成真实图像方面的成功使得研究人员开始探索各种低级视觉应用的对抗性损失,例如文本到图像合成[32,52,55,6]、图像到图像转换[18,28,46,45,50]、超分辨率[23]、人体姿势估计[31]和其他应用[56,59,38,44]。受这些方法在生成具有精细细节的高质量图像方面的成功启发,我们提出了一种基于联合鉴别器的GAN来细化估计的透射图和去雾图像。
3. Proposed Method
所提出的DCPDN网络架构如图2所示,其由以下四个模块组成:1)金字塔密集连接的透射图估计网络,2)大气光估计网络,3)通过等式2和4)联合鉴别器。在下文中,我们将详细解释这些模块。
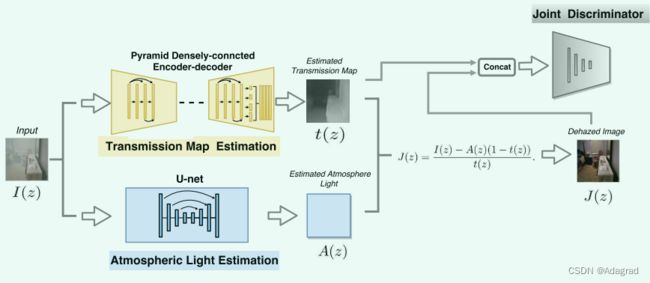
图2:本文提出的DCPDN图像去雾方法的概述。DCPDN由四个模块组成:金字塔密集连接传输地图估计网。2. 大气光估计网。3.通过Eq2去雾。4. 联合鉴别器。我们首先使用提出的金字塔密集连接的传输估计网估计传输图,然后使用u -网结构预测大气光。最后,利用估计的透射图和大气光,我们通过公式2估计去雾图像。
Pyramid Densely Connected Transmission Map Estimation Network.
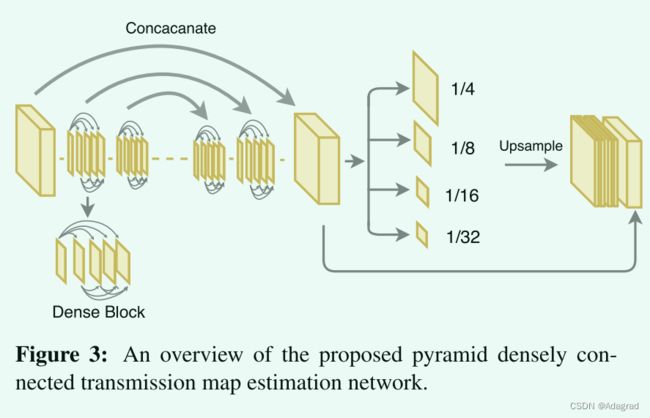
受使用多级特征来估计传输图的先前方法[33,5,42,1,24]的启发,我们提出了利用来自CNN的多个层的特征的密集连接的编码器-解码器结构,其中密集块被用作基本结构。使用密集块的原因在于它可以最大化沿着这些特征的信息流,并通过连接所有层来保证更好的收敛。此外,采用多级金字塔池化模块,通过将“全局”结构信息考虑到优化中来细化学习的特征[57]。为了利用密集网[15]的预定义权重,我们采用来自预训练密集网121的第一Conv层和前三个密集块以及它们对应的下采样操作转换块作为我们的编码器结构。编码部分末端的特征尺寸是输入尺寸的1/32。为了将传输图重建为原始分辨率,我们将五个密集块与细化的上采样过渡块[19,60,54]堆叠作为解码模块。此外,采用具有对应于相同维度的特征的级联。
即使所提出的稠密连接编码器-解码器结构结合了网络内部的不同特征,但单纯的稠密连接结构仍然缺乏不同尺度对象的“全局”结构信息。一个可能的原因是来自不同尺度的特征没有被用于直接估计最终的透射图。为了有效地解决这一问题,采用了多级金字塔池块,以确保不同尺度的特征都嵌入到最终结果中。这是受到在分类和分割任务中使用全局上下文信息的启发[57,48,14]。不是采用非常大的池大小来捕获不同对象之间的更多全局上下文信息[57],而是需要更多的“局部”信息来表征每个对象的“全局”结构。因此,采用池化大小为1/32、1/16、1/8和1/4的四级池化操作。然后,所有四级特征被上采样到原始特征大小,并在最终估计之前与原始特征级联回。图3给出了所提出的金字塔密集连接的传输图估计网络的概观。
Atmospheric Light Estimation Network.
遵循图像退化模型方程:1,我们假设大气光照图A是均匀的[13,5]。类似于先前的工作,预测的大气光A对于给定图像是均匀的。换言之,预测的A是2D图,其中每个像素A(z)具有相同的值(例如,A(z)= c,c为常数)。结果,真实背景A具有与输入图像相同的特征大小,并且A中的像素被填充以相同的值。为了估计大气光,我们采用8块U网[35]结构,其中编码器由四个Conv-BN-Relu块组成,解码器由对称的Dconv-BN-Relu块1组成。
Dehazing via Eq. 2.
为了桥接透射图、大气光和去雾图像之间的关系,并且为了确保整个网络结构对于所有三个任务被联合优化,我们将(2)直接嵌入到整体优化框架中。整个DCPDN结构的概述如图1所示。
3.1. Joint Discriminator Learning
令Gt和Gd分别表示生成透射图和去雾结果的网络。为了细化输出并确保估计的透射图Gt(I)和去雾图像Gd(I)分别与它们对应的地面真值t和J不可区分,我们使用具有新颖的联合鉴别器的GAN [12]。
从(1)以及图4可以观察到,估计的透射图![]() 和去雾图像
和去雾图像![]() 之间的结构信息高度相关。因此,为了利用这两个模态之间的结构信息的依赖性,我们引入联合鉴别器来学习联合分布,以判定对应对(透射图、去雾图像)是真实的还是虚假的。通过利用联合分布优化,可以更好地利用它们之间的结构相关性。与以前的工作类似,对于给定的图像,预测的空气光A是均匀的。换言之,预测的空气光A是2D图,其中每个像素A(z)具有相同的值(例如,A(z)= c,c为常数)。我们提出以下基于联合鉴别器的优化
之间的结构信息高度相关。因此,为了利用这两个模态之间的结构信息的依赖性,我们引入联合鉴别器来学习联合分布,以判定对应对(透射图、去雾图像)是真实的还是虚假的。通过利用联合分布优化,可以更好地利用它们之间的结构相关性。与以前的工作类似,对于给定的图像,预测的空气光A是均匀的。换言之,预测的空气光A是2D图,其中每个像素A(z)具有相同的值(例如,A(z)= c,c为常数)。我们提出以下基于联合鉴别器的优化
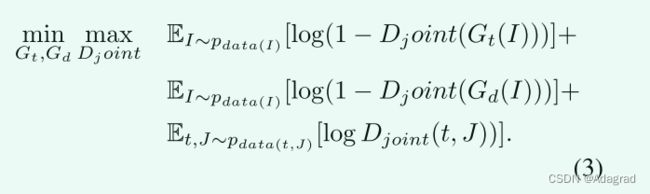
在实际应用中,我们将去雾后的图像与估计的透射图连接成一对样本,然后将其馈送到鉴别器。
3.2. Edge-preserving Loss
通常认为,欧几里德损失(L2损失)倾向于雾最终结果。因此,仅L2损失的透射图的不准确估计可能导致细节损失,从而导致去雾图像中的晕圈伪影[16]。为了有效地解决这一问题,提出了一种新的边缘保持损失,其由以下两个观察所激发。1)边缘对应于图像强度中的不连续性,因此其可以由图像梯度表征。2)已知可以在CNN结构的浅(前几个)层中捕获诸如边缘和轮廓的低级特征[47]。换句话说,前几层用作深度网络中的边缘检测器。例如,如果将透射图输入预定义的VGG-16 [37]模型,然后可视化层relu 1 2输出的某些特征,则可以清楚地观察到边缘信息保留在相应的特征图中(见图5)。

基于这些观察并且受到深度估计中使用的梯度损失[43,26]以及在低级视觉任务中使用感知损失[20,49]的启发,我们提出了由三个不同部分组成的新的边缘保留损失函数:L2误差、双向梯度误差和特征边缘误差,定义如下


3.3. Overall Loss Function
所提出的DCPDN架构使用以下四个损失函数来训练

3.4. Stage-wise Learning
在实验中,我们发现直接用复损耗Eq. 7从头开始训练整个网络是困难的,并且网络收敛速度很慢。一个可能的原因可能是由于不同任务引起的梯度扩散。例如,来自去雾图像丢失的梯度可能最初“分散”来自透射图丢失的梯度,导致较慢的收敛。为了解决这个问题并加快训练速度,引入了一种阶段式学习策略,该策略已用于不同的应用,如多模型识别[7]和特征学习[2]。因此,训练数据中的信息逐渐呈现给网络。换句话说,不同的任务是逐步学习的。首先,我们通过不同时更新其他任务来分别优化每个任务。在每个任务的“初始化”之后,我们通过联合优化所有三个任务来微调整个网络。
4. Experimental Results
在本节中,我们通过在两个合成数据集和一个真实世界数据集上进行各种实验来证明所提出的方法的有效性。将所有结果与五种最先进的方法进行比较:He等人(CVPR'09)[13],Zhu等人(TIP'15)[58],Ren等人[33](ECCV'16),Berman等人[3,4](CVPR'16和ICCP'17)和Li等人[24](ICCV'17)。此外,我们还进行了消融研究,以证明我们网络中每个模块的有效性。
4.1. Datasets
类似于现有的基于深度学习的去雾方法[33,5,24,51],我们基于(1)合成训练样本{Hazy /Clean /Transmission Map /Atmosphere Light}。合成过程中,随机抽取4种大气光照条件A ∈ [0.5,1]和散射系数β ∈ [0.4,1.6],生成相应的雾天图像、透射图和大气光照图。从NYU-depth 2数据集[30]中选择1000张图像的随机集以生成训练集。因此,总共有4000个训练图像,表示为TrainA。同样,获得了由400(100×4)张图像组成的测试数据集TestA,这些图像也来自NYU-depth 2。我们确保没有测试图像在训练集中。为了证明我们的网络对其他数据集的泛化能力,我们从Middlebury立体数据库(40)[36]和Sun 3D数据集(160)[39]合成了200个{Hazy /Clean /Transmission Map /Atmosphere Light}图像作为TestB集。
4.2. Training Details

4.3. Ablation Study
为了证明在所提出的网络中引入的每个模块所获得的改进,我们进行了涉及以下五个实验的消融研究:1)密集连接的编解码器结构(DED),2)具有多级金字塔池的密集连接的编码器解码器结构(DED-MLP),3)具有使用L2损失和梯度损失的多级金字塔池的密集连接的编码器解码器结构(DED-MLPGRA),4)具有使用边缘保留损失的多级金字塔池的密集连接编码器解码器结构(DED-MLP-EP),5)所提出的DCPDN,其由具有使用边缘保留损失和联合鉴别器的多级金字塔池的密集连接的编码器解码器结构(DCPDN)组成。
对合成的TestA和TestB数据集进行评价。表1中列出了在各种配置的估计透射图和去雾图像上平均的SSIM结果。目视比较见图6。从图6中,我们得出以下观察结果:1)与(a)和(b)相比,所提出的多级池化模块能够更好地保持具有相对较大规模的对象的“全局”结构。2)与(b)、(c)和(d)相比,边缘保留损失的使用能够更好地细化估计的透射图中的边缘。3)最终的联合鉴别器可以通过确保在结果中捕获精细的结构细节(诸如(e)中的第二行中所示的表格上的小对象的细节)来进一步增强估计的透射图。在测试A和测试B上评价的定量性能也证明了每个模块的有效性。

4.4. Comparison with state-of-the-art Methods
为了证明所提出的方法实现的改进,将其与最近的最先进的方法[13,58,33,3,4,24]进行比较。在合成和真实的数据集上。
Evaluation on synthetic dataset:
在两个合成数据集TestA和TestB上对所提出的网络进行了评估。由于数据集是合成的,因此可获得地面实况图像和透射图,使我们能够定性和定量地评估性能。图7显示了所提出的方法和五种最新的最先进的方法在测试数据集的两个样本图像上的样本结果。可以观察到,即使先前的方法能够从输入图像中去除雾,但是它们倾向于对图像去雾过度或去雾不足,使得结果较暗或在结果中留下一些雾。相比之下,从我们的结果中可以观察到,它们保留了更清晰的轮廓,颜色失真更少,并且在视觉上更接近地面实况。表2和表3和表4中列出了在试验A和试验B上评价的定量结果,也证明了拟定方法的有效性。
Evaluation on a real dataset:
为了验证所提方法的泛化能力,我们在几幅由之前方法提供的真实世界雾霾图像和从互联网上下载的其他具有挑战性的雾霾图像上对所提方法进行了评估。
图8显示了从之前的方法[33,5,10]中获得的四个样本图像的结果。如图8所示,He等人的方法。[13]和Ren等人的方法。[33](在第四行观察到)倾向于在结果中留下雾,Zhu等人的方法。[58]和Li等人。[24](在第二行显示)倾向于使一些区域变暗(注意背景墙)。Berman等人[3,4]的方法和我们的方法具有最具竞争力的视觉结果。然而,通过仔细观察,我们发现Berman等人[3,4]产生了不真实的颜色偏移,例如第四行中的建筑物颜色。相比之下,我们的方法能够生成真实感的颜色,同时更好地消除雾。这可以通过比较第一行和第二行看出。
我们还对从互联网上下载的几幅雾图像进行了评估。除雾结果如图9所示。从这些结果可以看出,He等人[13]和Berman等人[3,4]的输出遭受颜色失真,如第二和第三行所示。相比之下,我们的方法能够实现更好的去雾,具有视觉上吸引人的结果。
5. Conclusion
提出了一种新的基于深度学习的端到端去雾方法,能够联合优化透射图、大气光照和去雾图像。这是通过将大气图像退化模型直接嵌入到总体优化框架中来实现的。为了有效地估计传输图,提出了一种新的具有多级池模块的密集连接编解码器结构,并通过一种新的边缘保持损失对该网络进行了优化。此外,为了细化细节和利用去雾图像与估计的透射图之间的相互结构相关性,在该方法中引入了一个基于联合鉴别器的GAN框架。通过实验验证了该方法的有效性。
代码
from __future__ import division
import numpy as np
import sys
sys.path.append("./mingqingscript")
import scipy.io as sio
import scipy.ndimage.interpolation
# import scipy.signal
import os
import math
import random
import pdb
import random
import numpy as np
import pickle
import random
import sys
import shutil
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import matplotlib.patches as patches
# torch condiguration
import argparse
from math import log10
# import scipy.io as sio
import numpy as np
import random
from random import uniform
import h5py
import time
import PIL
from PIL import Image
import h5py
import numpy as np
import matplotlib.pyplot as plt
# plt.axis([0, 10, 0, 1])
plt.ion()
# for i in range(10):
# y = np.random.random()
# plt.scatter(i, y)
# plt.pause(0.05)
#
# while True:
# plt.pause(0.05)
def array2PIL(arr, size):
mode = 'RGBA'
arr = arr.reshape(arr.shape[0] * arr.shape[1], arr.shape[2])
if len(arr[0]) == 3:
arr = np.c_[arr, 255 * numpy.ones((len(arr), 1), numpy.uint8)]
return Image.frombuffer(mode, size, arr.tostring(), 'raw', mode, 0, 1)
index = 1
nyu_depth = h5py.File('nyu_depth_v2_labeled.mat', 'r')
directory='facades/train'
if not os.path.exists(directory):
os.makedirs(directory)
image = nyu_depth['images']
depth = nyu_depth['depths']
img_size = 224
# per=np.random.permutation(1400)
# np.save('rand_per.py',per)
# pdb.set_trace()
total_num = 0
plt.ion()
for index in range(1000):
index = index
gt_image = (image[index, :, :, :]).astype(float)
gt_image = np.swapaxes(gt_image, 0, 2)
gt_image = scipy.misc.imresize(gt_image, [img_size, img_size]).astype(float)
gt_image = gt_image / 255
gt_depth = depth[index, :, :]
maxhazy = gt_depth.max()
minhazy = gt_depth.min()
gt_depth = (gt_depth) / (maxhazy)
gt_depth = np.swapaxes(gt_depth, 0, 1)
scale1 = (gt_depth.shape[0]) / img_size
scale2 = (gt_depth.shape[1]) / img_size
gt_depth = scipy.ndimage.zoom(gt_depth, (1 / scale1, 1 / scale2), order=1)
if gt_depth.shape != (img_size, img_size):
continue
for j in range(8):
beta = uniform(0.5, 2)
tx1 = np.exp(-beta * gt_depth)
a = 1 - 0.5 * uniform(0, 1)
m = gt_image.shape[0]
n = gt_image.shape[1]
rep_atmosphere = np.tile(np.reshape(A, [1, 1, 3]), [m, n, 1])
tx1 = np.reshape(tx1, [m, n, 1])
max_transmission = np.tile(tx1, [1, 1, 3])
haze_image = gt_image * max_transmission + rep_atmosphere * (1 - max_transmission)
total_num = total_num + 1
scipy.misc.imsave('a0.9beta1.29.jpg', haze_image)
scipy.misc.imsave('gt.jpg', gt_image)
h5f=h5py.File('./facades/train/'+str(total_num)+'.h5','w')
h5f.create_dataset('haze',data=haze_image)
h5f.create_dataset('trans',data=max_transmission)
h5f.create_dataset('atom',data=rep_atmosphere)
h5f.create_dataset('gt',data=gt_image)import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.nn.functional as F
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
from collections import OrderedDict
import torchvision.models as models
from torch.autograd import Variable
def conv_block(in_dim,out_dim):
return nn.Sequential(nn.Conv2d(in_dim,in_dim,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(in_dim,in_dim,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(in_dim,out_dim,kernel_size=1,stride=1,padding=0),
nn.AvgPool2d(kernel_size=2,stride=2))
def deconv_block(in_dim,out_dim):
return nn.Sequential(nn.Conv2d(in_dim,out_dim,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(out_dim,out_dim,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.UpsamplingNearest2d(scale_factor=2))
def blockUNet1(in_c, out_c, name, transposed=False, bn=False, relu=True, dropout=False):
block = nn.Sequential()
if relu:
block.add_module('%s.relu' % name, nn.ReLU(inplace=True))
else:
block.add_module('%s.leakyrelu' % name, nn.LeakyReLU(0.2, inplace=True))
if not transposed:
block.add_module('%s.conv' % name, nn.Conv2d(in_c, out_c, 3, 1, 1, bias=False))
else:
block.add_module('%s.tconv' % name, nn.ConvTranspose2d(in_c, out_c, 3, 1, 1, bias=False))
if bn:
block.add_module('%s.bn' % name, nn.BatchNorm2d(out_c))
if dropout:
block.add_module('%s.dropout' % name, nn.Dropout2d(0.5, inplace=True))
return block
def blockUNet(in_c, out_c, name, transposed=False, bn=False, relu=True, dropout=False):
block = nn.Sequential()
if relu:
block.add_module('%s.relu' % name, nn.ReLU(inplace=True))
else:
block.add_module('%s.leakyrelu' % name, nn.LeakyReLU(0.2, inplace=True))
if not transposed:
block.add_module('%s.conv' % name, nn.Conv2d(in_c, out_c, 4, 2, 1, bias=False))
else:
block.add_module('%s.tconv' % name, nn.ConvTranspose2d(in_c, out_c, 4, 2, 1, bias=False))
if bn:
block.add_module('%s.bn' % name, nn.BatchNorm2d(out_c))
if dropout:
block.add_module('%s.dropout' % name, nn.Dropout2d(0.5, inplace=True))
return block
class D1(nn.Module):
def __init__(self, nc, ndf, hidden_size):
super(D1, self).__init__()
# 256
self.conv1 = nn.Sequential(nn.Conv2d(nc,ndf,kernel_size=3,stride=1,padding=1),
nn.ELU(True))
# 256
self.conv2 = conv_block(ndf,ndf)
# 128
self.conv3 = conv_block(ndf, ndf*2)
# 64
self.conv4 = conv_block(ndf*2, ndf*3)
# 32
self.encode = nn.Conv2d(ndf*3, hidden_size, kernel_size=1,stride=1,padding=0)
self.decode = nn.Conv2d(hidden_size, ndf, kernel_size=1,stride=1,padding=0)
# 32
self.deconv4 = deconv_block(ndf, ndf)
# 64
self.deconv3 = deconv_block(ndf, ndf)
# 128
self.deconv2 = deconv_block(ndf, ndf)
# 256
self.deconv1 = nn.Sequential(nn.Conv2d(ndf,ndf,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(ndf,ndf,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(ndf, nc, kernel_size=3, stride=1, padding=1),
nn.Tanh())
"""
self.deconv1 = nn.Sequential(nn.Conv2d(ndf,nc,kernel_size=3,stride=1,padding=1),
nn.Tanh())
"""
def forward(self,x):
out1 = self.conv1(x)
out2 = self.conv2(out1)
out3 = self.conv3(out2)
out4 = self.conv4(out3)
out5 = self.encode(out4)
dout5= self.decode(out5)
dout4= self.deconv4(dout5)
dout3= self.deconv3(dout4)
dout2= self.deconv2(dout3)
dout1= self.deconv1(dout2)
return dout1
class D(nn.Module):
def __init__(self, nc, nf):
super(D, self).__init__()
main = nn.Sequential()
# 256
layer_idx = 1
name = 'layer%d' % layer_idx
main.add_module('%s.conv' % name, nn.Conv2d(nc, nf, 4, 2, 1, bias=False))
# 128
layer_idx += 1
name = 'layer%d' % layer_idx
main.add_module(name, blockUNet(nf, nf*2, name, transposed=False, bn=True, relu=False, dropout=False))
# 64
layer_idx += 1
name = 'layer%d' % layer_idx
nf = nf * 2
main.add_module(name, blockUNet(nf, nf*2, name, transposed=False, bn=True, relu=False, dropout=False))
# 32
layer_idx += 1
name = 'layer%d' % layer_idx
nf = nf * 2
main.add_module('%s.leakyrelu' % name, nn.LeakyReLU(0.2, inplace=True))
main.add_module('%s.conv' % name, nn.Conv2d(nf, nf*2, 4, 1, 1, bias=False))
main.add_module('%s.bn' % name, nn.BatchNorm2d(nf*2))
# 31
layer_idx += 1
name = 'layer%d' % layer_idx
nf = nf * 2
main.add_module('%s.leakyrelu' % name, nn.LeakyReLU(0.2, inplace=True))
main.add_module('%s.conv' % name, nn.Conv2d(nf, 1, 4, 1, 1, bias=False))
main.add_module('%s.sigmoid' % name , nn.Sigmoid())
# 30 (sizePatchGAN=30)
self.main = main
def forward(self, x):
output = self.main(x)
return output
class D_tran(nn.Module):
def __init__(self, nc, nf):
super(D_tran, self).__init__()
main = nn.Sequential()
# 256
layer_idx = 1
name = 'layer%d' % layer_idx
main.add_module('%s.conv' % name, nn.Conv2d(nc, nf, 4, 2, 1, bias=False))
# 128
layer_idx += 1
name = 'layer%d' % layer_idx
main.add_module(name, blockUNet(nf, nf*2, name, transposed=False, bn=True, relu=False, dropout=False))
# 64
layer_idx += 1
name = 'layer%d' % layer_idx
nf = nf * 2
main.add_module(name, blockUNet(nf, nf*2, name, transposed=False, bn=True, relu=False, dropout=False))
# 32
layer_idx += 1
name = 'layer%d' % layer_idx
nf = nf * 2
main.add_module('%s.leakyrelu' % name, nn.LeakyReLU(0.2, inplace=True))
main.add_module('%s.conv' % name, nn.Conv2d(nf, nf*2, 4, 1, 1, bias=False))
main.add_module('%s.bn' % name, nn.BatchNorm2d(nf*2))
# 31
layer_idx += 1
name = 'layer%d' % layer_idx
nf = nf * 2
main.add_module('%s.leakyrelu' % name, nn.LeakyReLU(0.2, inplace=True))
main.add_module('%s.conv' % name, nn.Conv2d(nf, 1, 4, 1, 1, bias=False))
main.add_module('%s.sigmoid' % name , nn.Sigmoid())
# 30 (sizePatchGAN=30)
self.main = main
def forward(self, x):
output = self.main(x)
return output
class G(nn.Module):
def __init__(self, input_nc, output_nc, nf):
super(G, self).__init__()
# input is 256 x 256
layer_idx = 1
name = 'layer%d' % layer_idx
layer1 = nn.Sequential()
layer1.add_module(name, nn.Conv2d(input_nc, nf, 4, 2, 1, bias=False))
# input is 128 x 128
layer_idx += 1
name = 'layer%d' % layer_idx
layer2 = blockUNet(nf, nf*2, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 64 x 64
layer_idx += 1
name = 'layer%d' % layer_idx
layer3 = blockUNet(nf*2, nf*4, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 32
layer_idx += 1
name = 'layer%d' % layer_idx
layer4 = blockUNet(nf*4, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 16
layer_idx += 1
name = 'layer%d' % layer_idx
layer5 = blockUNet(nf*8, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 8
layer_idx += 1
name = 'layer%d' % layer_idx
layer6 = blockUNet(nf*8, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 4
layer_idx += 1
name = 'layer%d' % layer_idx
layer7 = blockUNet(nf*8, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 2 x 2
layer_idx += 1
name = 'layer%d' % layer_idx
layer8 = blockUNet(nf*8, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
## NOTE: decoder
# input is 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8
dlayer8 = blockUNet(d_inc, nf*8, name, transposed=True, bn=False, relu=True, dropout=True)
# input is 2
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8*2
dlayer7 = blockUNet(d_inc, nf*8, name, transposed=True, bn=True, relu=True, dropout=True)
# input is 4
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8*2
dlayer6 = blockUNet(d_inc, nf*8, name, transposed=True, bn=True, relu=True, dropout=True)
# input is 8
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8*2
dlayer5 = blockUNet(d_inc, nf*8, name, transposed=True, bn=True, relu=True, dropout=False)
# input is 16
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8*2
dlayer4 = blockUNet(d_inc, nf*4, name, transposed=True, bn=True, relu=True, dropout=False)
# input is 32
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*4*2
dlayer3 = blockUNet(d_inc, nf*2, name, transposed=True, bn=True, relu=True, dropout=False)
# input is 64
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*2*2
dlayer2 = blockUNet(d_inc, nf, name, transposed=True, bn=True, relu=True, dropout=False)
# input is 128
layer_idx -= 1
name = 'dlayer%d' % layer_idx
dlayer1 = nn.Sequential()
d_inc = nf*2
dlayer1.add_module('%s.relu' % name, nn.ReLU(inplace=True))
dlayer1.add_module('%s.tconv' % name, nn.ConvTranspose2d(d_inc, 20, 4, 2, 1, bias=False))
dlayerfinal = nn.Sequential()
dlayerfinal.add_module('%s.conv' % name, nn.Conv2d(24, output_nc, 3, 1, 1, bias=False))
dlayerfinal.add_module('%s.tanh' % name, nn.Tanh())
self.conv1010 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1020 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1030 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1040 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.refine3= nn.Conv2d(20+4, 3, kernel_size=3,stride=1,padding=1)
self.upsample = F.upsample_nearest
self.layer1 = layer1
self.layer2 = layer2
self.layer3 = layer3
self.layer4 = layer4
self.layer5 = layer5
self.layer6 = layer6
self.layer7 = layer7
self.layer8 = layer8
self.dlayer8 = dlayer8
self.dlayer7 = dlayer7
self.dlayer6 = dlayer6
self.dlayer5 = dlayer5
self.dlayer4 = dlayer4
self.dlayer3 = dlayer3
self.dlayer2 = dlayer2
self.dlayer1 = dlayer1
self.dlayerfinal = dlayerfinal
self.relu=nn.LeakyReLU(0.2, inplace=True)
def forward(self, x):
out1 = self.layer1(x)
out2 = self.layer2(out1)
out3 = self.layer3(out2)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
out6 = self.layer6(out5)
out7 = self.layer7(out6)
out8 = self.layer8(out7)
dout8 = self.dlayer8(out8)
dout8_out7 = torch.cat([dout8, out7], 1)
dout7 = self.dlayer7(dout8_out7)
dout7_out6 = torch.cat([dout7, out6], 1)
dout6 = self.dlayer6(dout7_out6)
dout6_out5 = torch.cat([dout6, out5], 1)
dout5 = self.dlayer5(dout6_out5)
dout5_out4 = torch.cat([dout5, out4], 1)
dout4 = self.dlayer4(dout5_out4)
dout4_out3 = torch.cat([dout4, out3], 1)
dout3 = self.dlayer3(dout4_out3)
dout3_out2 = torch.cat([dout3, out2], 1)
dout2 = self.dlayer2(dout3_out2)
dout2_out1 = torch.cat([dout2, out1], 1)
dout1 = self.dlayer1(dout2_out1)
shape_out = dout1.data.size()
# print(shape_out)
shape_out = shape_out[2:4]
x101 = F.avg_pool2d(dout1, 16)
x102 = F.avg_pool2d(dout1, 8)
x103 = F.avg_pool2d(dout1, 4)
x104 = F.avg_pool2d(dout1, 2)
x1010 = self.upsample(self.relu(self.conv1010(x101)),size=shape_out)
x1020 = self.upsample(self.relu(self.conv1020(x102)),size=shape_out)
x1030 = self.upsample(self.relu(self.conv1030(x103)),size=shape_out)
x1040 = self.upsample(self.relu(self.conv1040(x104)),size=shape_out)
dehaze = torch.cat((x1010, x1020, x1030, x1040, dout1), 1)
dout1 = self.dlayerfinal(dehaze)
return dout1
class G2(nn.Module):
def __init__(self, input_nc, output_nc, nf):
super(G2, self).__init__()
# input is 256 x 256
layer_idx = 1
name = 'layer%d' % layer_idx
layer1 = nn.Sequential()
layer1.add_module(name, nn.Conv2d(input_nc, nf, 4, 2, 1, bias=False))
# input is 128 x 128
layer_idx += 1
name = 'layer%d' % layer_idx
layer2 = blockUNet(nf, nf*2, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 64 x 64
layer_idx += 1
name = 'layer%d' % layer_idx
layer3 = blockUNet(nf*2, nf*4, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 32
layer_idx += 1
name = 'layer%d' % layer_idx
layer4 = blockUNet(nf*4, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 16
layer_idx += 1
name = 'layer%d' % layer_idx
layer5 = blockUNet(nf*8, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 8
layer_idx += 1
name = 'layer%d' % layer_idx
layer6 = blockUNet(nf*8, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 4
layer_idx += 1
name = 'layer%d' % layer_idx
layer7 = blockUNet(nf*8, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
# input is 2 x 2
layer_idx += 1
name = 'layer%d' % layer_idx
layer8 = blockUNet(nf*8, nf*8, name, transposed=False, bn=True, relu=False, dropout=False)
## NOTE: decoder
# input is 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8
dlayer8 = blockUNet(d_inc, nf*8, name, transposed=True, bn=False, relu=True, dropout=True)
#import pdb; pdb.set_trace()
# input is 2
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8*2
dlayer7 = blockUNet(d_inc, nf*8, name, transposed=True, bn=True, relu=True, dropout=True)
# input is 4
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8*2
dlayer6 = blockUNet(d_inc, nf*8, name, transposed=True, bn=True, relu=True, dropout=True)
# input is 8
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8*2
dlayer5 = blockUNet(d_inc, nf*8, name, transposed=True, bn=True, relu=True, dropout=False)
# input is 16
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*8*2
dlayer4 = blockUNet(d_inc, nf*4, name, transposed=True, bn=True, relu=True, dropout=False)
# input is 32
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*4*2
dlayer3 = blockUNet(d_inc, nf*2, name, transposed=True, bn=True, relu=True, dropout=False)
# input is 64
layer_idx -= 1
name = 'dlayer%d' % layer_idx
d_inc = nf*2*2
dlayer2 = blockUNet(d_inc, nf, name, transposed=True, bn=True, relu=True, dropout=False)
# input is 128
layer_idx -= 1
name = 'dlayer%d' % layer_idx
dlayer1 = nn.Sequential()
d_inc = nf*2
dlayer1.add_module('%s.relu' % name, nn.ReLU(inplace=True))
dlayer1.add_module('%s.tconv' % name, nn.ConvTranspose2d(d_inc, output_nc, 4, 2, 1, bias=False))
dlayer1.add_module('%s.tanh' % name, nn.LeakyReLU(0.2, inplace=True))
self.layer1 = layer1
self.layer2 = layer2
self.layer3 = layer3
self.layer4 = layer4
self.layer5 = layer5
self.layer6 = layer6
self.layer7 = layer7
self.layer8 = layer8
self.dlayer8 = dlayer8
self.dlayer7 = dlayer7
self.dlayer6 = dlayer6
self.dlayer5 = dlayer5
self.dlayer4 = dlayer4
self.dlayer3 = dlayer3
self.dlayer2 = dlayer2
self.dlayer1 = dlayer1
def forward(self, x):
out1 = self.layer1(x)
out2 = self.layer2(out1)
out3 = self.layer3(out2)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
out6 = self.layer6(out5)
out7 = self.layer7(out6)
out8 = self.layer8(out7)
dout8 = self.dlayer8(out8)
dout8_out7 = torch.cat([dout8, out7], 1)
dout7 = self.dlayer7(dout8_out7)
dout7_out6 = torch.cat([dout7, out6], 1)
dout6 = self.dlayer6(dout7_out6)
dout6_out5 = torch.cat([dout6, out5], 1)
dout5 = self.dlayer5(dout6_out5)
dout5_out4 = torch.cat([dout5, out4], 1)
dout4 = self.dlayer4(dout5_out4)
dout4_out3 = torch.cat([dout4, out3], 1)
dout3 = self.dlayer3(dout4_out3)
dout3_out2 = torch.cat([dout3, out2], 1)
dout2 = self.dlayer2(dout3_out2)
dout2_out1 = torch.cat([dout2, out1], 1)
dout1 = self.dlayer1(dout2_out1)
return dout1
class BottleneckBlock(nn.Module):
def __init__(self, in_planes, out_planes, dropRate=0.0):
super(BottleneckBlock, self).__init__()
inter_planes = out_planes * 4
self.bn1 = nn.BatchNorm2d(in_planes)
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_planes, inter_planes, kernel_size=1, stride=1,
padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(inter_planes)
self.conv2 = nn.Conv2d(inter_planes, out_planes, kernel_size=3, stride=1,
padding=1, bias=False)
self.droprate = dropRate
def forward(self, x):
out = self.conv1(self.relu(self.bn1(x)))
if self.droprate > 0:
out = F.dropout(out, p=self.droprate, inplace=False, training=self.training)
out = self.conv2(self.relu(self.bn2(out)))
if self.droprate > 0:
out = F.dropout(out, p=self.droprate, inplace=False, training=self.training)
return torch.cat([x, out], 1)
class TransitionBlock(nn.Module):
def __init__(self, in_planes, out_planes, dropRate=0.0):
super(TransitionBlock, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.ConvTranspose2d(in_planes, out_planes, kernel_size=1, stride=1,
padding=0, bias=False)
self.droprate = dropRate
def forward(self, x):
out = self.conv1(self.relu(self.bn1(x)))
if self.droprate > 0:
out = F.dropout(out, p=self.droprate, inplace=False, training=self.training)
return F.upsample_nearest(out, scale_factor=2)
class Dense(nn.Module):
def __init__(self):
super(Dense, self).__init__()
############# 256-256 ##############
haze_class = models.densenet121(pretrained=True)
self.conv0=haze_class.features.conv0
self.norm0=haze_class.features.norm0
self.relu0=haze_class.features.relu0
self.pool0=haze_class.features.pool0
############# Block1-down 64-64 ##############
self.dense_block1=haze_class.features.denseblock1
self.trans_block1=haze_class.features.transition1
############# Block2-down 32-32 ##############
self.dense_block2=haze_class.features.denseblock2
self.trans_block2=haze_class.features.transition2
############# Block3-down 16-16 ##############
self.dense_block3=haze_class.features.denseblock3
self.trans_block3=haze_class.features.transition3
############# Block4-up 8-8 ##############
self.dense_block4=BottleneckBlock(512,256)
self.trans_block4=TransitionBlock(768,128)
############# Block5-up 16-16 ##############
self.dense_block5=BottleneckBlock(384,256)
self.trans_block5=TransitionBlock(640,128)
############# Block6-up 32-32 ##############
self.dense_block6=BottleneckBlock(256,128)
self.trans_block6=TransitionBlock(384,64)
############# Block7-up 64-64 ##############
self.dense_block7=BottleneckBlock(64,64)
self.trans_block7=TransitionBlock(128,32)
## 128 X 128
############# Block8-up c ##############
self.dense_block8=BottleneckBlock(32,32)
self.trans_block8=TransitionBlock(64,16)
self.conv_refin=nn.Conv2d(19,20,3,1,1)
self.tanh=nn.Tanh()
self.conv1010 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1020 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1030 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1040 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.refine3= nn.Conv2d(20+4, 3, kernel_size=3,stride=1,padding=1)
# self.refine3= nn.Conv2d(20+4, 3, kernel_size=7,stride=1,padding=3)
self.upsample = F.upsample_nearest
self.relu=nn.LeakyReLU(0.2, inplace=True)
def forward(self, x):
## 256x256
x0=self.pool0(self.relu0(self.norm0(self.conv0(x))))
## 64 X 64
x1=self.dense_block1(x0)
# print x1.size()
x1=self.trans_block1(x1)
### 32x32
x2=self.trans_block2(self.dense_block2(x1))
# print x2.size()
### 16 X 16
x3=self.trans_block3(self.dense_block3(x2))
# x3=Variable(x3.data,requires_grad=True)
## 8 X 8
x4=self.trans_block4(self.dense_block4(x3))
x42=torch.cat([x4,x2],1)
## 16 X 16
x5=self.trans_block5(self.dense_block5(x42))
x52=torch.cat([x5,x1],1)
## 32 X 32
x6=self.trans_block6(self.dense_block6(x52))
## 64 X 64
x7=self.trans_block7(self.dense_block7(x6))
## 128 X 128
x8=self.trans_block8(self.dense_block8(x7))
# print x8.size()
# print x.size()
x8=torch.cat([x8,x],1)
# print x8.size()
x9=self.relu(self.conv_refin(x8))
shape_out = x9.data.size()
# print(shape_out)
shape_out = shape_out[2:4]
x101 = F.avg_pool2d(x9, 32)
x102 = F.avg_pool2d(x9, 16)
x103 = F.avg_pool2d(x9, 8)
x104 = F.avg_pool2d(x9, 4)
x1010 = self.upsample(self.relu(self.conv1010(x101)), size=shape_out)
x1020 = self.upsample(self.relu(self.conv1020(x102)), size=shape_out)
x1030 = self.upsample(self.relu(self.conv1030(x103)), size=shape_out)
x1040 = self.upsample(self.relu(self.conv1040(x104)), size=shape_out)
dehaze = torch.cat((x1010, x1020, x1030, x1040, x9), 1)
dehaze = self.tanh(self.refine3(dehaze))
return dehaze
class dehaze(nn.Module):
def __init__(self, input_nc, output_nc, nf):
super(dehaze, self).__init__()
self.tran_est=G(input_nc=3,output_nc=3, nf=64)
self.atp_est=G2(input_nc=3,output_nc=3, nf=8)
self.tran_dense=Dense()
self.relu=nn.LeakyReLU(0.2, inplace=True)
# self.relu5=nn.ReLU6()
self.tanh=nn.Tanh()
self.refine1= nn.Conv2d(6, 20, kernel_size=3,stride=1,padding=1)
self.refine2= nn.Conv2d(20, 20, kernel_size=3,stride=1,padding=1)
self.threshold=nn.Threshold(0.1, 0.1)
self.conv1010 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1020 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1030 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.conv1040 = nn.Conv2d(20, 1, kernel_size=1,stride=1,padding=0) # 1mm
self.refine3= nn.Conv2d(20+4, 3, kernel_size=3,stride=1,padding=1)
self.upsample = F.upsample_nearest
self.batch1= nn.BatchNorm2d(20)
# self.batch2 = nn.InstanceNorm2d(100, affine=True)
def forward(self, x):
tran=self.tran_dense(x)
atp= self.atp_est(x)
# x = Variable(x.data, requires_grad=True)
# zz= torch.abs(self.threshold(tran))
zz= torch.abs((tran))+(10**-10)
shape_out1 = atp.data.size()
# print(shape_out)
# shape_out = shape_out[0:5]
# atp_mean=torch.mean(atp)
# threshold = nn.Threshold(10, 0.95)
shape_out = shape_out1[2:4]
atp = F.avg_pool2d(atp, shape_out1[2])
atp = self.upsample(self.relu(atp),size=shape_out)
# print atp.data
# atp = threshold(atp)
dehaze= (x-atp)/zz+ atp
dehaze2=dehaze
dehaze=torch.cat([dehaze,x],1)
# dehaze=dehaze/(tran+(10**-10))
# dehaze=self.relu(self.batch1(self.refine1(dehaze)))
# dehaze=self.relu(self.batch1(self.refine2(dehaze)))
dehaze=self.relu((self.refine1(dehaze)))
dehaze=self.relu((self.refine2(dehaze)))
shape_out = dehaze.data.size()
# print(shape_out)
shape_out = shape_out[2:4]
x101 = F.avg_pool2d(dehaze, 32)
x1010 = F.avg_pool2d(dehaze, 32)
x102 = F.avg_pool2d(dehaze, 16)
x1020 = F.avg_pool2d(dehaze, 16)
x103 = F.avg_pool2d(dehaze, 8)
x104 = F.avg_pool2d(dehaze, 4)
x1010 = self.upsample(self.relu(self.conv1010(x101)),size=shape_out)
x1020 = self.upsample(self.relu(self.conv1020(x102)),size=shape_out)
x1030 = self.upsample(self.relu(self.conv1030(x103)),size=shape_out)
x1040 = self.upsample(self.relu(self.conv1040(x104)),size=shape_out)
dehaze = torch.cat((x1010, x1020, x1030, x1040, dehaze), 1)
dehaze= self.tanh(self.refine3(dehaze))
return dehaze, tran, atp, dehaze2