一. 原理
tcmalloc就是一个内存分配器,管理堆内存,主要影响malloc和free,用于降低频繁分配、释放内存造成的性能损耗,并且有效地控制内存碎片。glibc中的内存分配器是ptmalloc2,tcmalloc号称要比它快。一次malloc和free操作,ptmalloc需要300ns,而tcmalloc只要50ns。同时tcmalloc也优化了小对象的存储,需要更少的空间。tcmalloc特别对多线程做了优化,对于小对象的分配基本上是不存在锁竞争,而大对象使用了细粒度、高效的自旋锁(spinlock)。分配给线程的本地缓存,在长时间空闲的情况下会被回收,供其他线程使用,这样提高了在多线程情况下的内存利用率,不会浪费内存,而这一点ptmalloc2是做不到的。
tcmalloc区别的对待大、小对象。它为每个线程分配了一个线程局部的cache,线程需要的小对象都是在其cache中分配的,由于是thread local的,所以基本上是无锁操作(在cache不够,需要增加内存时,会加锁)。同时,tcmalloc维护了进程级别的cache,所有的大对象都在这个cache中分配,由于多个线程的大对象的分配都从这个cache进行,所以必须加锁访问。在实际的程序中,小对象分配的频率要远远高于大对象,通过这种方式(小对象无锁分配,大对象加锁分配)可以提升整体性能。
线程级别cache和进程级别cache实际上就是一个多级的空闲块列表(Free List)。一个Free List以大小为k bytes倍数的空闲块进行分配,包含n个链表,每个链表存放大小为nk bytes的空闲块。在tcmalloc中,<=32KB的对象被称作是小对象,>32KB的是大对象。在小对象中,<=1024bytes的对象以8n bytes分配,1025<size<=32KB的对象以128n bytes大小分配,比如:要分配20bytes则返回的空闲块大小是24bytes的,这样在<=1024的情况下最多浪费7bytes,>1025则浪费127bytes。而大对象是以页大小4KB进行对齐的,最多会浪费4KB - 1 bytes。下图就是一个基本的free list的示意图:
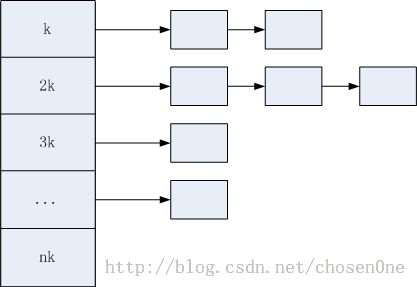
实际上,一个free list(我称之为空闲块列表)就是一个数组索引多个链表,每个链表存放相同大小的块。可以根据要分配的内存大小size算出合适的块在free list中的下标,然后找到对应的空闲块链表。
tcmalloc的数据结构组织如下:
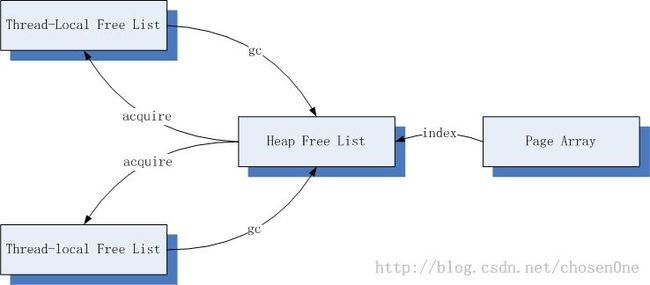
Thread-local free list:线程本地的空闲块cache,用于分配小对象。
Heap free list:中心free list,全局唯一,用于按页对齐分配大对象或者是将连续的多个页(被称作span)分割成多个小对象的空闲块分配给thread-local free list。
Page array:用于描述当前tcmalloc持有的内存状态,完成的是从page number到span的映射。
下面看一下小对象的分配:
(1)根据分配的size计算出对应的空闲块大小,从而确定对应空闲块链表,然后从thread local的free list进行分配。
(2)如果的空闲块链表非空,直接将头结点对应的空闲块返回并从空闲块链表中将其删除。
(3)如果空闲块链表是空的,需要从heap free list获取一个span。如果heap free list非空,则将span切分成多个相同大小的空闲块插入空闲块链表中,然后返回头结点。
(4)如果heap free list是空的,则调用sbrk或者mmap进行内存的分配一系列连续的内存页,作为span,然后切分成多个相同大小的空闲块插入空闲块链表,然后返回头结点。
大对象的分配就要简单多了,直接从heap free list分配4nKB大小的空闲块即可,如果heap free list不存在该大小的空闲块,通过系统调用分配连续的内存页。
tcmalloc还会对thread local cache进行垃圾收集,从而避免内存浪费。
二. 安装和使用
tcmalloc属于gperftools,安装比较简单,需要注意一下,在64bit系统上需要先安装libunwind(http://download.savannah.gnu.org/releases/libunwind/libunwind-0.99-beta.tar.gz,只能是这个版本),这个库为基于64位CPU和操作系统的程序提供了基本的堆栈辗转开解功能,其中包括用于输出堆栈跟踪的API、用于以编程方式辗转开解堆栈的API以及支持C++异常处理机制的API,32bit系统不需安装。在安装过程中,可能出现下列错误:
- gcc -DHAVE_CONFIG_H -I. -I../include -I../include -I../include/tdep-x86_64 -I. -D_GNU_SOURCE -DNDEBUG -g -O2 -fexceptions -Wall -Wsign-compare -MT setjmp/longjmp.lo -MD -MP -MF setjmp/.deps/longjmp.Tpo -c setjmp/longjmp.c -fPIC -DPIC -o setjmp/.libs/longjmp.o
- /usr/include/x86_64-linux-gnu/bits/setjmp2.h:26:13: error: 'longjmp' aliased to undefined symbol '_longjmp
是因为缺少编译选项U_FORTIFY_SOURCE,解决方法有两种:
1,尚未调用configure进行配置,则执行CPPFLAGS=-U_FORTIFY_SOURCE ./configure ... 会自动将编译选项添加到Makefile中。
2,已经配置过,直接修改Makefile,查找CPPFLAGS然后添加上-U_FORTIFY_SOURCE。
然后就是安装gperftools,这个正常安装即可,默认安装到/usr/local/lib下,完成后调用lddconfig添加到动态链接库缓存,然后就可以使用了。
使用方法,很简单,在编译时加上tcmalloc动态链接库即可
源码不需任何修改,tcmalloc会自动替换掉glibc默认的malloc和free,简简单单的一条命令就可以提升不少性能,very good。
最近开发一个私人程序时碰到了严重的内存问题,具体表现为:进程占用的内存会随着访问高峰不断上升,直到发生OOM被kill为止。我们使用valgrind等工具进行检查发现程序并无内存泄露,经过仔细调查我们发现时glibc的内存管理机制导致的,下次将发文对此深入解释,本文只列出核心的几个要素:
1. glibc在多线程内存分配的场景下为了减少lock contention,会new出很多arena出来,每个线程都有自己默认的arena,但是内存申请时如果默认arena被占用,则round-robin到下一个arena。
2. 每个arena的空间不可直接共享和互相借用,除非通过主arena释放给操作系统然后被各个辅助arena重新申请。
3. glibc归还内存给OS有一个很苛刻的条件就是top chunk必须是free的,否则,即使应用程序已经释放了大片内存,glibc也不会将这些内存归还给OS。
在我们的场景中常常是thread A alloc一片空间,最后由thread B free,所以这就造成各个arena之间及其不平衡,加上苛刻的内存归还条件,在整个程序运行过程中,占用内存几乎从未下降过,区别仅仅是缓慢上涨和快速上涨。
由此我们实验了tcmalloc,具体介绍见:http://google-perftools.googlecode.com/svn/trunk/doc/tcmalloc.html
安装过程见其中的INSTALL文件,下面简略说一下:
1. install libunwind : git clone git://git.sv.gnu.org/libunwind.git
2. download : http://google-perftools.googlecode.com/files/google-perftools-1.7.tar.gz
3. ./configure --enable-frame_pointers && make && sudo make install
4. sudo ldconfig
5. g++ .... -ltcmalloc (link static lib)
tcmalloc每个线程默认最大缓存16M空间,所以当线程多的时候其占用的空间还是非常可观的,在common.h中有几个参数是控制缓存空间的,可以做合理的修改(只可个人做实验,注意法律问题):
1. 降低每个线程的缓存空间,可以修改common.h中的kMaxThreadCacheSize,比如2M
2. 降低所有线程的缓存空间的总大小,可以修改common.h中的kDefaultOverallThreadCacheSize,比如20M
3. 尽快将free的空间还给central list,可以将kMaxOverages改小一点,比如1
还可以定期让tcmalloc归还空间给OS,
#include "google/malloc_extension.h"
MallocExtension::instance()->ReleaseFreeMemory();
|
实验结果证明,tcmalloc分配速度的确快,而且程序不再像以前那样内存只增不减。
上面Sanjay的文章已经对tcmalloc做了个大概的介绍,我看了一下tcmalloc的核心code,下面将其分配和释放的过程简单介绍一下:
线程申请资源:
1. 首先根据申请空间的大小从当前线程的可用内存块里面找(每个进程维护一组链表,每个链表代表一定大小的可用空间)
2. 如果step 1没有找到,则到central list里面查找(central list跟线程各自维护的list结构很像,为不同的size各自维护一组可用空间列表)
3. 如果step 2 central list也没有找到,则计算分配size个字节需要分配多少page(变量:class_to_pages)
4. 根据pagemap查找page对应的可用的span列表,如果找到了,则直接返回span,central list会将该span切割成合适的大小放入对应的列表中,然后交给thread cache
5. 如果step 4没有找到可用的span,则向OS直接申请,然后步骤同step 4。
注意的是tcmalloc向系统申请空间有三种方式:sbrk,mmap,/dev/mem文件,默认是三种都try的,一种不行换另外一种。
线程释放资源:
1. 释放某个object
2. 找到该object所在的span
3. 如果该span中所有object都被释放,则释放该span到对应的可用列表,在释放的过程中,尝试将该span跟左右spans merge成更大的span
4. 如果当前thread cache的free 空间大于指定预置,归还部分空间给central list
5. central list也会试图通过释放可用span列表的最后几个span来将不用的空间归还给OS
tcmalloc向OS申请/释放资源是以span为单位的。
tcmalloc里面不少实现值得称道,比如pagesize到void*的mapping方式,添加/移除链表元素的时候利用结构体内存布局直接赋值,span/page/item的内存层次结构等,值得一看。