图解 K8S(01):基于 Ubuntu 20.04 部署 1.23版K8S 集群
从今天开始,我将开始连载《图解 K8S》入门系列文章。
可以点此链接订阅该系列:图解 Kubernetes
本篇是做为系列的第一篇文章,先来带大家一起搭建一个可用的 K8S 环境。
K8S 环境的搭建,是很多想学习 K8S 的人止步于在入门之外的第一道门槛,不少人在这一道关上就被直接被劝退了。
为什么呢?主要有如下三点:
- 网络问题:K8S 是 Google 开发的,官方最新镜像都在墙外,安装时下载不了镜像
- 机器问题:K8S 运行的组件非常多,对于机器本身有要求,配置不能低,如果要搭建集群,还需要多台机器,是笔不小的开销。
- 运维问题:K8S 的部署安装和维护,涉及到不少 Linux 及网络相关的内容,需要有一定的运维能力
不过在如今,其实已经出现了非常多的 K8S 部署工具,有的是图形化界面安装,也有的甚至做到了一条命令安装。
这些工具,给新手提供了一个比较友好的部署解决方案,不过很遗憾的是,我大多没有用过,因为我认为这些工具隐藏了太多原生的 K8S 部署细节,比如安装了哪些组件,是怎么安装的?组件之间的依赖关系,网络是如何走的?
而这些细节,对于我们以后进行环境的维护、问题的排查会不小的帮助。
因此,我个人从一开始就不建议新手去使用那些太高级的部署工具。。
但也不能没有部署工具,所有的组件都手动安装,我想会逼疯很多新手。
因此,我这边选用官方推荐的 kubeadm 工具进行演示,带大家一起搭建个可用的 K8S 环境。
1. 环境说明
K8S 环境,可以分为单节点和多节点集群环境两种。
单节点的话,部署非常简单,对于一般的学习概念来说,也是够用了,除了一些需要多节点支持的功能,比如 DeamonSet ,比如调度策略验证等
而线上生产的环境,都应该是分布式的集群,只是这一套环境搭建下来需要多台的机器。
你可以在自己的电脑上创建几台虚拟机,本文我以我的 mac (16 G)为例,创建两台虚拟机,实际上带三台也没有问题,如此你是 windows ,请确保你的配置。
当然也可以选择去各大云厂商那里购买机器,个人感觉应该要不少钱,愿意投资的可以上。
由于后续肯定会用得上多节点,因此本篇只讲下多节点的集群搭建方法,如果你觉得自己当前想先试试水先学习一下一些基本的内容,可以在本文的评论区留言一下,我考虑剥离出一篇个单节点的 K8S 搭建方法,方法都大同小异。
2. 集群架构
K8S 中节点节点的角色,可以分为两种:
- 一种是 控制节点,也即 Master 节点,主要运行控制平面的组件,如 kube-apiserver 等
- 一种是 计算节点,也即 Worker 节点,主要运行业务上的组件,比如 web server 等
Master 节点是整个集群的大脑,一个集群只有一个 Master 节点肯定是不行的,通常来说,要至少三个,做下高可用。
但由于我们仅仅是学习之用,没有集群稳定安全性考虑,这里就不需要浪费资源去搞高可用。
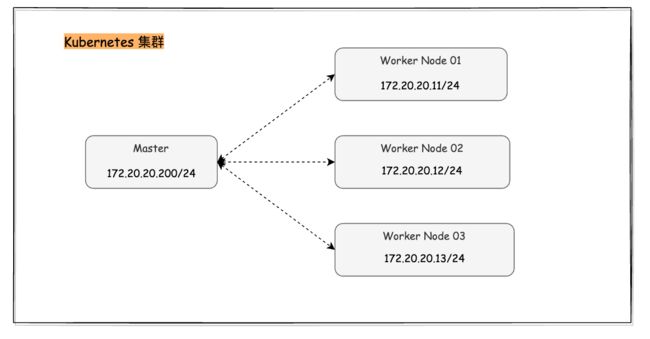
因此,我的集群是一个 Master 节点,N 个 Worker 节点(下文中仅演示一个 worker 的部署,多个 worker 类似),管理网段是 172.20.20.0/24,ip 如图所示
3. 网络环境
集群的安装需要联网下载很多的镜像,因此在开始安装之前请保证你的所有节点都可以正常联网。
对于在云厂商购买的云主机来说,都有公网 ip,这个自不用担心。
可对于在本地电脑上创建的虚拟机做为 K8S 节点的朋友,可以跟着我一起操作。
我的个人电脑是 最新款(2021)的 Macbook M1 Pro 内存仅有 16 G,现在我的电脑上已经安装好Mac 上的桌面虚拟化软件 Parallels Desktop,在 Parallels Desktop 的入口就可以下载 Ubuntu 20.04 ,请注意,这边下载的是桌面版的 Linux,本来我机器配置就不高,再使用桌面版的,实在太消耗资源了。

可以在这里下载服务器版的 Ubuntu:https://ubuntu.com/download/server/arm,会小很多,只有 1.1G。
下载完成后,可以自行安装,相信大多数人都知道如何操作,明哥这里就不会多费口舌,不懂的在留言区交流吧
等虚拟机安装完成后,别着急启动,可以先配置下网段。
如下图所示 点网络 -> 高级,再点打开 网络首选项

将桥接(Shared)的网络改为 172.20.20.0/24,也即 172.20.20.1-172.20.20.254

一旦你修改后,Paralles Desktop 就会感知,并修改本机上 bridge100 的 ip 地址为 172.20.20.0/24 里的 ip,这里分配的 ip 是 172.20.20.2,与虚拟机的网络在同一网段,如此一来,宿主机就能和虚拟机进行通信。

网络配置好后,正常启动虚拟机,可以看到虚拟机已经自动配置上 172.20.20.3 的 ip,这是怎么做到的呢?
原来在 netplan 的配置文件中 /etc/netplan/00-installer-config.yaml,配置了 enp0s5 启用 dhcp 获取 ip。

这种动态获取的 ip,会导致同一节点在不同时间、场景下获取到的 ip 可能是不一样的。
对于 K8S 集群环境来说,管理网络的 ip 应该固定的,否则会造成通信的混乱。
因此我们应该把规划好的 ip 地址写死到配置文件中,写好后,使用 netplan apply 使之生效

由于 ip 发生了变化,因此重启网络后,当前的 ssh 连接会断网,退出后,再次使用 172.20.20.200 就可以再次登陆,会发现 enp0s5 的 ip 已经按预期配置成 172.20.20.200 了。
尝试 ping 114.114.114.114 ,发现网络是不通的,这是为什么呢?
原来上面在 netplan 的配置文件中并没有指明网关地址,那网关地址是多少呢?
此时我们回想之间 bridge100 的 ip 是 172.20.20.2 ,为什么不是我们定义的 172.20.20.0/24 网段的第一个 ip 172.20.20.1 呢?
这是因为这个 ip 被 PD 拿去做网关了,因此我们只要往配置文件中加上网关再重新 netplan apply 即可

完整的配置文件如下
# /etc/netplan/00-installer-config.yaml
network:
ethernets:
enp0s5:
dhcp4: no
addresses: [172.20.20.200/24]
optional: true
gateway4: 172.20.20.1
nameservers:
addresses: [114.114.114.114]
version: 2
4. 基础环境
4.1 关闭 swapoff
在旧版的 k8s 中 kubelet 都要求关闭 swapoff ,但最新版的 kubelet 其实已经支持 swap ,因此这一步其实可以不做。
iswbm@master:~$ sudo swapoff -a
# 修改/etc/fstab,注释掉swap那行,持久化生效
iswbm@master:~$ sudo vim /etc/fstab
4.2 修改时区
修改一下时区,由原来的 UTC 变成了 CST,中间差了 8 个小时
iswbm@master:~$ date
Sat 15 Jan 2022 02:22:44 AM UTC
iswbm@master:~$ sudo timedatectl set-timezone Asia/Shanghai
iswbm@master:~$ date
Sat 15 Jan 2022 10:22:55 AM CST
修改后,如果想使得系统日志的时间戳也立即生效,由重启 rsyslog
iswbm@master:~$ sudo systemctl restart rsyslog
4.3 设置内核参数
首先确认你的系统已经加载了 br_netfilter 模块,默认是没有该模块的,需要你先安装 bridge-utils
sudo apt-get install -y bridge-utils
然后再使用 modprobe 加载一下, lsmod 就能看到 br_netfilter 模块,此时再确认一下 内核参数 net.bridge.bridge-nf-call-iptables 是否为 1。

在Ubuntu 20.04 Server上,这个值就是1。如果你的系统上不一致,使用下面的命令来修改:
cat <5. 基础软件
本小节的步骤在 master 及 worker 执行
5.1 安装 Docker
目前的 Ubuntu 已经有提供 Docker 的安装包,直接安装即可
# 安装 docker
iswbm@master:~$ sudo apt install docker.io
# 启动 docker
iswbm@master:~$ sudo systemctl start docker
# 开机自启
iswbm@master:~$ sudo systemctl enable docker
如果是旧版的 Ubuntu 还是建议按照官网(https://docs.docker.com/engine/install/ubuntu/)的操作去安装

但 ubuntu 20.04 源里提供的 Docker 版本还是比较新的,是 20.10.7,可以直接使用,我从 Docker 官网里看到的当前最新 Docker 版本是 20.10.12,只是差了几个小版本,区别不大。
iswbm@master:~$ docker --version
Docker version 20.10.7, build 20.10.7-0ubuntu5~20.04.2
5.2 安装 kubeadm kubectl
以下操作在 master和 worker 节点 上执行,由于谷歌的源和 repo 在国内的是无法访问的,因此这里需要切换为 阿里源。
按顺序执行如下几条命令
# 安装基础软件并设置源
iswbm@master:~$ sudo apt-get install -y ca-certificates curl software-properties-common apt-transport-https curl
iswbm@master:~$ curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
iswbm@master:~$ sudo tee /etc/apt/sources.list.d/kubernetes.list <6. 构建集群
6.1 部署 master
网上 90% 的文章,都是使用 kubeadm init 加各种参数实现的部署,只要一条命令即可实现,就像这样
sudo kubeadm init --pod-network-cidr 172.16.0.0/16 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--apiserver-advertise-address 172.20.20.200 \
--apiserver-bind-port 6443
但这样的部署命令,在较新版本的 k8s (maybe 1.22 +)中是会部署失败的。
原因是 kubeadm 默认会将kubelet 的 cgroupDriver 字段设置为 systemd,
如果设置为 systemd ,kubelet 会启动不了。
经过我的摸索,kubeadm init 应该使用配置文件的方式进行部署
iswbm@master:~$ sudo kubeadm init --config kubeadm-config.yaml
而如果你安装的是旧版的 k8s ,则不用使用上面的方式,直接
sudo kubeadm init --pod-network-cidr 172.16.0.0/16 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--apiserver-advertise-address 172.20.20.200 \
--apiserver-bind-port 6443 \
--token-ttl 0
关于 kubeadm 更多常用的参数及中文解释我整理如下

咱们的目的是学习,对版本没有要求,就直接上最新版,因此只能用这种方式安装
iswbm@master:~$ sudo kubeadm init --config kubeadm-config.yaml
而这个 kubeadm-config.yaml 配置文件从哪里获取呢?我准备好一个,可以直接点这里进行下载 https://wwe.lanzout.com/iITg2yt0imd
kubeadm config print init-defaults打印默认配置
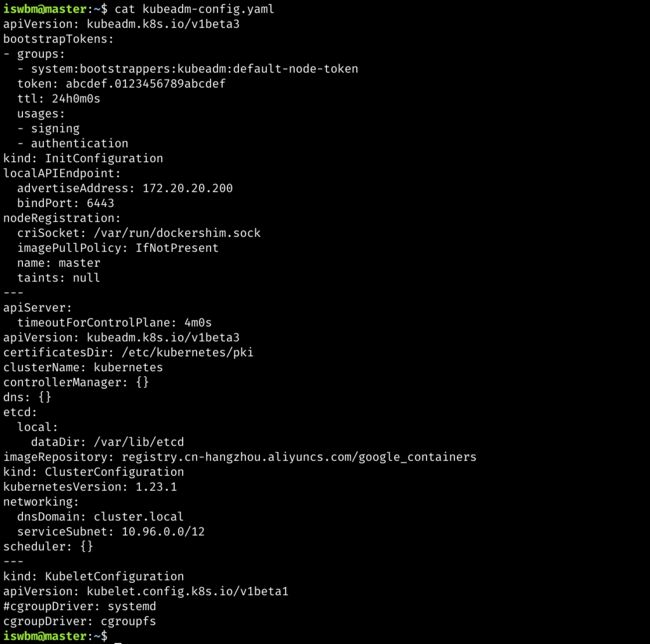
执行完成后,会提醒你做三件事

第一件事:配置环境变量
以便你能正常使用 kubectl 进行集群的操作,对于常规用户用如下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
对于 root 用户,执行如下命令
export KUBECONFIG=/etc/kubernetes/admin.conf
第二件事:将节点加入集群
后面我们要将 worker 节点加入集群,就要执行这条命令
sudo kubeadm join 172.20.20.200:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:4e4a7d0e848ae6c047d163fbe07f0e6975d71cc156d7705649241a59bbecaa04
这条命令是有有效期的,需要的时候,可以执行如下命令进行获取
kubeadm token create --print-join-command
到此,你的集群已经安装好了,可以查看一下集群的基本情况

第三件事:部署网络插件
这个我在图中没有圈出来,但它也是非常重要的,我放到 6.3 部署 calico 这节里去做。
6.2 部署 worker
相比 master ,worker 的部署就简单许多了。
只要安装好了 docker、kubelet、kubeadm 软件,就可以执行前面的 join 命令直接加入集群
sudo kubeadm join 172.20.20.200:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:4e4a7d0e848ae6c047d163fbe07f0e6975d71cc156d7705649241a59bbecaa04
完成之后,再到 master 上查看 node ,若可以看到 worker 说明成功将 worker 加入集群中

6.3 部署 Calico
上面其他我们已经部署好了 K8S 集群,但是由于还没有安装网络插件,因此整个集群实际上还是不能工作的,通过 kubectl get nodes 可以看到虽然已经有两个节点,但 Status 却都还是 NotReady 。
K8S 的网络插件有很多,常见的有 flannel、calico、cilium、kube-ovn 等等。
更多支持的 CNI 可以在官方文档上找到列表:https://kubernetes.io/docs/concepts/cluster-administration/addons/
我大概数了一下,多达 16 个网络插件,太可怕了。
K8S 拥有如此多多的 CNI 网络插件,该如何做好CNI的技术选型,一个团队需要投入大量的精力进行调研。
Flannel 是 由CoreOS开发 的,K8S 最基础的网络插件,但是功能有限,一般仅供初学者学习使用,在生产中不推荐使用。
而其他的,Calico 是比较主流的选择(实际上我们公司使用的是 kube-ovn),因此我这里选择 Calico 进行安装

安装 Calico 只需要一条命令即可。
kubectl apply -f https://docs.projectcalico.org/v3.21/manifests/calico.yaml
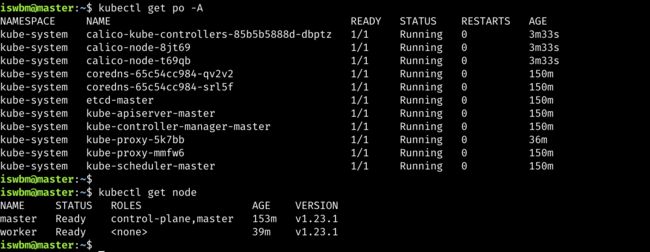
安装完成后,会创建出这几个 Pod
iswbm@master:~$ kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-85b5b5888d-dbptz 1/1 Running 0 3m33s
kube-system calico-node-8jt69 1/1 Running 0 3m33s
kube-system calico-node-t69qb 1/1 Running 0 3m33s
同时之前由于没有安装网络插件而失败的 coredns pod 也开始成功拉起了
网络 ok 后,再次确认下集群的环境
- 所有的 Pod 均已 Running
- 所有的 node 均已 Ready
7. 验收集群
关于 Pod 的概念,我将在后面慢慢介绍,现在你只要知道,Pod 是一个 K8S 最核心的资源对象,是最小的调度单位。
如果可以在 K8S 集群里,成功创建一个 Pod ,那就说明,你这个集群是健康的、可用的。
使用如下命令就可以创建一个最简单的 nginx pod
kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml
simple.pod 的 yaml 简单内容如下
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
执行后,通过 kubectl get pod 可以 观察到状态的变化

通过加 -o wide 可以查看 pod 的 ip,再使用 curl,就可以访问这个 nginx 服务

至此,我们创建了第一个 pod 的,集群搭建完成。
恭喜你,已经完成了你学习 K8S 最艰难的一步 – 环境搭建
8. 写在最后
本文虽然是在 mac 操作系统下进行演示,但机器对于搭建 K8S 集群本身并没有什么区别,最多也就虚拟机网络配置那里有所区别,但我相信这些对于正经的程序员来说,绝对不是什么难题。
本文完整复现了 K8S 集群的搭建过程,经历了 自己搭建 - > 问题排查解决 - >素材收集整理 -> 撰写文章 ,全文经过多次修缮,前前后后一共花费了 6 个多小时的时间,才形成此文,可以达到让一个没有运维能力的纯新手也能无痛学习。
一篇文章的产出,需要经过如此长的时间,更新频率自然小很多,其实我也在考虑,之后要以一种怎样的风格来完成这个系列,是类似这样的万字长文呢?还是日更级别的,每天 5 分钟学习 K8S 呢?
对于我来说,我更倾向于前者,这样才能有条件把一个知识给讲透,而且能让你感受到我写这个系列的诚意。
但从读者的角度来看,应该是后者,更新频率太低,读者的脑子会断层,一个星期前的新知识,现在可能忘得差不多了。
你是怎么想的呢?欢迎你在评论区给我建议。