kafka入门篇
目录
-
- 1、kafka基本介绍
-
- 1.1、kafka发展历史
- 1.2、编程语言
- 1.3、kafka应用场景
-
- 1.3.1、message queue 消息传递
- 1.3.2、流式应用程序(数据集成+流计算)
- 2、kafka安装和服务端操作
-
- 2.1、kafka的安装
- 2.2、kafka和zookeeper
- 2.3、kafka脚本介绍
- 2.4、kafka界面管理工具
- 3、kafka架构
-
- 3.1、Broker
- 3.2、Message
- 3.3、Producer
- 3.4、Consumer
- 3.5、Topic
- 3.6、Partition
- 3.7、Replica
- 3.8、Segment
- 3.9、Consumer Group
- 3.10、Consumer Offset
- 3.11、架构图解读
- 4、kafka与java开发
-
- 4.1、java API
-
- 4.1.1、引入依赖
- 4.1.2、生产者
- 4.1.3、消费者
- 4.2、Springboot集成Kafka
-
- 4.2.1、引入依赖
- 4.2.2、配置
- 4.2.3、生产者
- 4.2.4、消费者
- 4.3、Kafka携手canal实现数据同步
- 5、kafka幂等消息
-
- 5.1、定义及使用
- 5.2、原理分析
- 6、Producer事务
-
- 6.1、事务介绍和使用
-
- 事务使用java API
- 事务在SpringBoot中使用
- 6.2、Producer事务原理分析
- 7、Kafka的主要特性
- 8、Kafka和RabbitMQ对比
-
- 优先选择RabbitMQ的情况
- 优先选择Kafka的情况:
1、kafka基本介绍
官网文档 中文文档 github地址
1.1、kafka发展历史
Apache Kafka最初由LinkedIn开发,并在2011年初开源。
在2012年10月23日由Apache Incubator(Apache Incubator(阿帕奇孵化器)是旨在成为完全成熟的Apache软件基金会项目的开源项目的通道)孵化出站,成为了Apache软件基金会的项目。
2014年11月, Jun Rao、Jay Kreps、 Neha Narkhede等几个曾在领英为Kafka工作的工程师,创建了名为Confluent的新公司,并着眼于Kafka。
根据2014年Quora(美版知乎)的帖子,Jay Kreps似乎已经将它以作家Franz Kafka(是奥匈帝国一位使用德语的小说家和短篇犹太人故事家,被评论家们认为是20世纪作家中最具影响力的一位)命名。Kreps选择将该系统以一个作家命名是因为,它是“asystem optimized for writing”(一个用于优化写作的系统),而且他很喜欢Kafka的作品。
1.2、编程语言
kafka是由Scala写成,Scala 运行在Java虚拟机上,并兼容现有的Java程序,因此部署kakfa的时候,需要先部署jdk环境。kafka客
户端在主流的编程语言里面都有对应的支持。
1.3、kafka应用场景
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于消息队列(message queue))
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
1.3.1、message queue 消息传递
消息传递就是发送数据,作为TCPHTTP或者RPC的替代方案,可以实现异步、解耦、削峰(RabbitMQ和RocketMQ能做的事情,
它也能做)。因为kafka的吞吐量更高,在大规模消息系统中更有优势。
案例
-
Website Activity Tracking 网站活动跟踪:把用户活动发布到数据管道中,可以用来做监控、实时处理、报表等等,比如社交网站的行为跟踪,购物网站的行为跟踪,这样可以实现更加精准的内容推荐。举例:外卖、物流、电力系统的实时信息。
-
Log Aggregation日志聚合:又比如用kafka来实现日志聚合。这样就不用把日志记录到本地磁盘或者数据库,实现分布式的日志聚合。
-
Metrics应用指标监控:还可以用来记录运营监控数据。举例,对于贷款公司,需要监控贷款的业务数据:今天放出去多少笔贷款,放出去的总金额,用户的年龄分布、地区分布、性别分布等等。或者对于运维数据的监控,CPU、内存、磁盘、网络连接的使用情况,可以实现告警。
1.3.2、流式应用程序(数据集成+流计算)
数据集成:指的是把 Kafka 的数据导入Hadoop、HBase等离线数据仓库,实现数据分析。
流计算:什么是流(Stream) ?它不是静态的数据,而是没有边界的、源源不断的产生的数据,就像水流一样。流计算指的
就是Stream对做实时的计算。Kafka在0.10版本后,内置了流处理框架API———Kafka Streams。
所以,它跟 RabbitMQ的定位差别还是比较大的,不仅仅是一个简单的消息中间件,而且是一个流处理平台。在kafka里面,消息被称为日志。日志就是消息的数据文件。
2、kafka安装和服务端操作
2.1、kafka的安装
注意: kafka_2.12-2.8.0.tgz这个名字里面的版本号,前面(2.12)是scala的版本号,后面(2.8.0)才是 kafka的版本号。
- 单机版安装
- 集群安装(单机)
2.2、kafka和zookeeper
在安装kafka 的时候我们知道,必须要依赖zookeeper的服务,在生产环境通常是ZK的集群,而且kafka还自带了一个zookeeper服务。
zookeeper做了什么事情呢?
利用zookeeper的有序节点、临时节点和监听机制,帮助kafka做了这些事情
- 配置中心(管理Broker、Topic、Partition、Consumer的信息,包括元数据的变动)
- 负载均衡
- 命名服务
- 分布式通知
- 集群管理和选举
- 分布式锁
2.3、kafka脚本介绍
客户端的脚本是用Java编写的,本质上都是执行Java方法(kafka-run-class.sh),做了进一步的封装,需要的参数更
少。
| 脚本 | 作用 |
|---|---|
| kafka-server-start.sh kafka-server-stop.sh |
Kafka启动停止 |
| kafka-topics.sh | 查看创建删除 topic |
| kafka-console-consumer.sh | 消费者操作,例如监听topic |
| kafka-consumer-groups.sh | 消费者组操作 |
| kafka-console-producer.sh | 生产者操作,例如发送消息 |
| zookeeper-server-start.sh | zK操作:启动停止连接ZK |
| kafka-reassign-partitions.sh | 分区重新分配 |
| kafka-consumer-perf-test.sh | 性能测试 |
2.4、kafka界面管理工具
kafka没有自带管理界面,但是基于admin的接口可以开发。目前比较流行的管理界面主要是
-
kafka-manager
-
kafka-eagle
注意最新版本的cmak对Java版本要求比较高,最低需要JDK11。
kafka-eagle对内存要求比较高,在虚拟机中部署需要修改JVM参数才能启动。
3、kafka架构
3.1、Broker
一台 Kafka 机器就是一个 Broker。一个集群由多个 Broker 组成。一个 Broker 可以容纳多个 Topic。
3.2、Message
客户端之间传输的数据叫做消息,或者叫做记录(Record名词['reko:d ]) 。在客户端的代码中,Record可以是一个KV键值对。
生产者对应的封装类是ProducerRecord,消费者对应的封装类是ConsumerRecord。消息在传输的过程中需要序列化,所以代码
里面要指定序列化工具。消息在服务端的存储格式(RecordBatch和Record) :
http://kafka.apache.org/documentation/#messageformat
3.3、Producer
发送消息的一方叫做生产者,接收消息的一方叫做消费者。为了提升消息发送速率,生产者不是逐条发送消息给Broker,而是批量
发送的。多少条发送一次由一个参数决定。
prop.put("batch.size",16384);
3.4、Consumer
一般来说消费者获取消息有两种模式,一种是pull模式,一种是push模式。
Pull模式就是消费放在Broker,消费者自己决定什么时候去获取。Push模式是消息放在Consumer,只要有消息到达Broker,都直接推给消费者。
RabbitMQ Consumer 既支持push又支持pull,一般用的是push。Kafka只有pull模式。
kafka为什么是消费者使用pull来消费数据?
官网已经说得很明白了:
http://kafka.apache.org/documentation/#design_pull
在push模式下,如果消息产生速度远远大于消费者消费消息的速率,那消费者就会不堪重负(你已经吃不下了,但是还要不
断地往你嘴里塞),直到挂掉。而且消费者可以自己控制一次到底获取多少条消息,通过
max.poll.record来控制。
3.5、Topic
可以理解为一个队列,Topic 将消息分类,生产者和消费者面向的是同一个 Topic。生产者和Topic、Topic和消费者的关系都是
多对多。一个生产者可以发送消息到多个Topic,一个消费者也可以从多个Topic获取消息(但是不建议这么做)。
注意,生产者发送消息时,如果Topic不存在,会自动创建。由一个参数auto.create.topics.enable=true来控制,默认为
true。如果要彻底删掉一个Topic,这个参数必须改成false,否则只要有代码使用这个Topic,它就会自动创建。
http://kafka.apache.org/documentation/#auto.create.topics.enable
3.6、Partition
Partition是分区的意思。为了实现扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker (即服务器)上,一个
Topic 可以分为多个 Partition,每个 Partition 是一个有序的队列。分区在创建topic的时候指定,每个topic至少有一个分区。
创建Topic命令
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
partitions是指定分区数目,如果不指定,默认分区数是1个。可以通过参数num.partitons=1修改。
replication-factor是副本数量。
partition思想上有点类似于分库分表,实现的也是横向扩展和负载的目的。
举个例子,Topic有3个分区,生产者依次发送9条消息,对消息进行编号。
第一个分区存147,第二个分区存258,第三个分区存369,这个就实现了负载。
每个partition都有一个物理目录。在配置的数据目录下(日志就是数据)︰/tmp/kafka-logs/
跟RabbitMQ不一样的地方是,Partition里面的消息被读取之后不会被删除,所以同一批消息在一个Partition里面顺序、追加写入
的。这个也是kafka吞吐量大的一个很重要的原因。分区数量怎么选择呢?是不是分区数越多越好?不一定。不同的机器网络环境,
这个答案不尽相同,最好是通过性能测试的脚本验证。
如何确定分区数量?
参考博客:
https://os.51cto.com/art/202008/622946.htm
https://www.cnblogs.com/xiaodf/p/6023531.html
3.7、Replica
Replica是副本的意思。Replica是作为Partition的副本,也就备份,防止网络或者硬件发生故障导致的数据丢失问题。每个
partition可以有若干个副本(Replica),副本必须在不同的 Broker上面。一般我们说的副本包括其中的主节点。
由replication-factor指定一个Topic的副本数。
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test3p3r
默认副本数量由服务端参数offsets.topic.replication.factor控制。
举例:部署了3个Broker,该topic有3个分区,每个分区一共3个副本。如下图
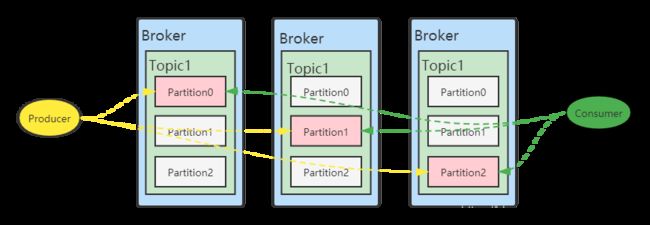
注意:这些存放相同数据的partition副本有leader(图中红色)和follower(图中绿色)的概念。
leader在哪台机器是不一定的,选举出来的。生产者发消息、消费者读消息都是针对leader(为什么不让客户端读
follower呢?)。follower的数据是从leader同步过来的。
3.8、Segment
kafka的数据是放在后缀.log 的文件里面的。如果一个partition只有一个log文件,消息不断地追加,这个 log文件
也会变得越来越大,这个时候要检索数据效率就很低了。所以干脆把 partition再做一个切分,切分出来的单位就
叫做段(segment)。实际上kafka的存储文件是划分成段来存储的。
默认存储路径:/tmp/kafka-logs/
每个segment都有至少有1个数据文件和2个索引文件,这3个文件是成套出现的。( partition 一个目录,一个
segement一套文件)

segment默认大小是1073741824 bytes (1G),由参数log.segment.bytes控制。
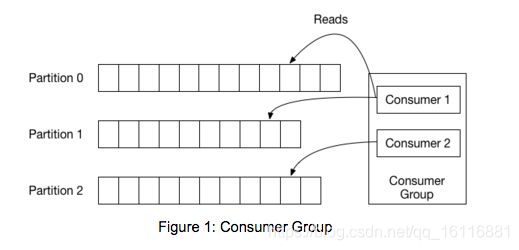
3.9、Consumer Group
多个Consumer消费一个Topic提高了消费消息的吞吐量。
Consumer Group是消费者组的意思,多个Consumer通过设置相同的group id来组成一个Consumer Group。同一个Consumer Group的Consumer消费同一个Topic是互斥的,而且一个partition只能由组内的一个Consumer来消费。
如果想要同时消费同一个partition的消息,那么需要其他的组来消费。

3.10、Consumer Offset
Offset(偏移量):是用来记录Consumer消费message位置的编码。如果消费者挂掉,再次连接上来,就通过
Offset知道之前消费到哪里了。这也保证了同一个partition消息的有序性。
offset记录着下一条将要发送给consumer的消息的序号。
这个消费者跟partition之间的偏移量没有保存在ZK,而是直接保存在服务端。
3.11、架构图解读
首先,我们有3台Broker。
有两个Topic: Topic0和Topic1。
Topic0有2个分区: partition0和partition1,每个分区一共3个副本。Topic1只有1个分区: partition0,每个分区一
共3个副本。
图中红色字体的副本代表是leader,黑色字体的副本代表是follower。绿色的线代表是数据同步。
蓝色的线是写消息,橙色的线是读消息,都是针对leader节点。
有两个消费者组,
第一个消费者组只有一个消费者,它消费了topic0的两个分区。
第二个消费者组,既消费topic0,又消费 topic1。其中有一个消费者,消费 topic0的partition0,还消费topic1的
partition0。有一个消费者,消费 partition0的partition1。有一个消费者,没有partition可以消费。
4、kafka与java开发
4.1、java API
根据官网,Kafka主要有5种API:
| 类别 | 作用 |
|---|---|
| Producer API | 用于应用将数据发送到Kafka的topic |
| Consumer API | 用于应用从Kafka的topic中读取数据流 |
| Admin APl | 允许管理和检测Topic、broker 以及其他 Kafka 实例,与Kafka自带的脚本命令作用类似 |
| Streams API | 用于从来源topic转化到目的topic转换数据流,作用跟Spark . Storm、Flink一样(应用) |
| Connect APl | 用于持续地从一些源系统输入数据到Kafka,或者从Kafka推送数据到一些系统,比如数据库或者Hadoop 等等(存储) |
4.1.1、引入依赖
注意,客户端的版本跟服务端的版本要匹配。如果客户端版本太高,服务端版本太旧,有可能无法连接。
<dependency>
<groupId>groupld>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.6.0version>
dependency>
4.1.2、生产者
public class SimpleProducer {
public static void main(String[] args) {
Properties pros=new Properties();
pros.put("bootstrap.servers","192.168.0.101:9092,192.168.0.102:9092,192.168.0.103:9092");
pros.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
pros.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
// 0 发出去就确认 | 1 leader 落盘就确认| all(-1) 所有Follower同步完才确认
pros.put("acks","1");
// 异常自动重试次数
pros.put("retries",3);
// 多少条数据发送一次,默认16K
pros.put("batch.size",16384);
// 批量发送的等待时间
pros.put("linger.ms",5);
// 客户端缓冲区大小,默认32M,满了也会触发消息发送
pros.put("buffer.memory",33554432);
// 获取元数据时生产者的阻塞时间,超时后抛出异常
pros.put("max.block.ms",3000);
// 创建Sender线程
Producer<String,String> producer = new KafkaProducer<String,String>(pros);
for (int i =0 ;i<10;i++) {
producer.send(new ProducerRecord<String,String>("mytopic",Integer.toString(i),Integer.toString(i)));
System.out.println("发送:"+i);
}
// producer.send(new ProducerRecord("mytopic","1","1"));
//producer.send(new ProducerRecord("mytopic","2","2"));
producer.close();
}
}
4.1.3、消费者
public class SimpleConsumer {
public static void main(String[] args) {
Properties props= new Properties();
props.put("bootstrap.servers","192.168.0.101:9092,192.168.0.102:9092,192.168.0.103:9092");
props.put("group.id","gp-test-group");
// 是否自动提交偏移量,只有commit之后才更新消费组的 offset
props.put("enable.auto.commit","true");
// 消费者自动提交的间隔
props.put("auto.commit.interval.ms","1000");
// 从最早的数据开始消费 earliest | latest | none
props.put("auto.offset.reset","earliest");
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer=new KafkaConsumer<String, String>(props);
// 订阅topic
consumer.subscribe(Arrays.asList("mytopic"));
try {
while (true){
ConsumerRecords<String,String> records=consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String,String> record:records){
System.out.printf("offset = %d ,key =%s, value= %s, partition= %s%n" ,record.offset(),record.key(),record.value(),record.partition());
}
}
}finally {
consumer.close();
}
}
}
4.2、Springboot集成Kafka
版本对应关系:
https://spring.io/projects/spring-kafka
4.2.1、引入依赖
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
4.2.2、配置
application.properties
#spring.kafka.bootstrap-servers=192.168.0.101:9092,192.168.0.102:9092,192.168.0.103:9092
# producer
spring.kafka.producer.retries=1
spring.kafka.producer.batch-size=16384
spring.kafka.producer.buffer-memory=33554432
spring.kafka.producer.acks=all
spring.kafka.producer.properties.linger.ms=5
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# consumer
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=1000
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
4.2.3、生产者
注入模板方法KafkaTemplate发送消息。
注意send方法有很多重载。异步回调ListenableFuture。
@Component
public class KafkaProducer {
@Autowired
private KafkaTemplate<String,Object> kafkaTemplate;
public String send(@RequestParam String msg){
kafkaTemplate.send("springboottopic", msg);
return "ok";
}
}
4.2.4、消费者
使用注解@KafkaListener 监听Topic。
@Component
public class ConsumerListener {
@KafkaListener(topics = "springboottopic",groupId = "springboottopic-group")
public void onMessage(String msg){
System.out.println("----收到消息:"+msg+"----");
}
}
4.3、Kafka携手canal实现数据同步
https://www.cnblogs.com/throwable/p/12483983.html
5、kafka幂等消息
5.1、定义及使用
消息幂等性:是指Producer发送到Broker的消息是去重的,Broker会对重复的消息进行判断过滤。
可以通过Producer的API来配置
props.put("enable.idempotence",true);
5.2、原理分析
kafka幂等消息是如何实现的呢?
大家应该接触过幂等接口,如果保证一个接口的幂等性,简单的做法就每次请求都带上一个唯一标识。kafka的思想也是类型,为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。
- PID,每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的。
- Sequence Numbler,(对于每个PID,该Producer发送数据的每个
由此通过PID和Sequence Number就可以保证消息的幂等性。
消息重复判断逻辑?
- 如果新消息的sequence number正好是broker端维护的
- 如果新消息的sequence number比broker端维护的sequence number要小,说明时重复消息,broker可以将其直接丢弃
- 如果新消息的sequence number比broker端维护的sequence number要大过1,说明中间存在了丢数据的情况,那么会响应该情况,对应的Producer会抛出OutOfOrderSequenceException。
**注意:**通过PID和sequence number来实现的消息幂等性,只能保证消息在一个Partition不会出现重复消息。
6、Producer事务
6.1、事务介绍和使用
生产者事务是Kafka 2017年0.11.0.0引入的新特性,通过事务,Kafka可以保证跨生产者会话的消息幂等发送。
Producer事务,保证了Producer发送多条消息,要么都成功要都失败。(这里消息可能发送到多个Partition或者多个Topic)
事务使用java API
props.put("enable.idempotence",true);
// 事务ID,唯一
props.put("transactional.id", UUID.randomUUID().toString());
Producer<String,String> producer = new KafkaProducer<String,String>(props);
// 初始化事务
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(new ProducerRecord<String,String>("transaction-test","1","1"));
producer.send(new ProducerRecord<String,String>("transaction-test","2","2"));
// Integer i = 1/0;
producer.send(new ProducerRecord<String,String>("transaction-test","3","3"));
// 提交事务
producer.commitTransaction();
} catch (KafkaException e) {
// 中止事务
producer.abortTransaction();
}
producer.close();
}
事务在SpringBoot中使用
具体使用方法参考博客:https://www.hangge.com/blog/cache/detail_2950.html
方式一:可以通过executeInTransaction来做
kafkaTemplate.executeInTransaction(operations -> {
operations.send("topic1","test executeInTransaction");
throw new RuntimeException("fail");
});
方式二:使用 @Transactional 注解方式
6.2、Producer事务原理分析
- 因为生产者的消息可能会跨分区,所以这里的事务是属于分布式事务。分布式事务的实现方式有很多,kafka选择了最常见的两阶段提交(2PC)。如果大家都可以commit,那么就 commit,否则abort。
- 既然是2PC,必须要有一个协调者的角色,叫做Transaction Coordinator。
- 事务管理必须要有事务日志,来记录事务的状态,以便Coordinator在意外挂掉之后继续处理原来的事务。跟消费者offset的存储一样,kafka使用一个特殊的topic_transaction_state来记录事务状态。
- 如果生产者挂了,事务要在重启后可以继续处理,接着之前未处理完的事务,或者在其他机器上处理,必须要有一个唯一的ID,这个就是transaction.id,这里我们使用UUID。配置了transaction.id,则此时 enable.idempotence 会被设置为true(事务实现的前提是幂等性)。事务ID相同的生产者,可以接着处理原来的事务。

步骤描述:
A:生产者通过initTransactions API向Coordinator注册事务ID。
B: Coordinator记录事务日志。
C:生产者把消息写入目标分区。
D:分区和Coordinator的交互。当事务完成以后,消息的状态应该是已提交,这样消费者才可以消费到。
7、Kafka的主要特性
市面上有这么多MQ的产品,kafka 跟他们有什么区别呢?我们说一个产品的诞生背景决定了它的特性,特性决定使用场景。
因为kafka是用来解决数据流的传输的问题的,所以它有这些特性:
- 高吞吐、低延迟: kakfa最大的特点就是收发消息非常快,kafka每秒可以处理几十万条消息,它的最低延迟只有几毫秒;
- 高伸缩性:如果可以通过增加分区partition来实现扩容。不同的分区可以在不同的Broker中。通过ZK来管理Broker实现扩展,ZK管理Consumer可以实现负载;
- 持久性、可靠性:Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失;
- 容错性:允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作;
- 高并发:支持数千个客户端同时读写。
8、Kafka和RabbitMQ对比
Kafka和RabbitMQ的主要区别:
| Kafka | RabbitMQ | |
|---|---|---|
| 产品侧重 | 流式消息处理、消息引擎 | 消息代理 |
| 性能 | kafka有更高的吞吐量,只有pull模式 | RabbitMQ主要是push |
| 消息顺序 | 分区里面的消息是有序的,同一个consumer group里面的一个消 费者只能消费一个partition |
能保证消息的顺序性 |
| 消息的路由和分发 | 不支持 | RabbitMQ支持 |
| 延迟消息、死信队列 | 不支持 | RabbitMQ支持 |
| 消息的留存 | 消费完之后消息会留存,可以设置retention,清理消息。 | 消费完就会删除 |
优先选择RabbitMQ的情况
- 高级灵活的路由规则
- 消息时序控制(控制消息过期或者消息延迟)
- 高级的容错处理能力,在消费者更有可能处理消息不成功的情景中(瞬时或者持久)
- 更简单的消费者实现
优先选择Kafka的情况:
- 严格的消息顺序
- 延长消息留存时间,包括过去消息重放的可能
- 传统解决方案无法满足的高伸缩能力。