Hive SQL 2023必考常用窗口函数及面试题
一、窗口函数概述
窗口函数也称为OLAP函数,OLAP 是OnLine Analytical Processing 的简称,意思是对数据库数据进行实时分析处理。例如,市场分析、创建财务报表、创建计划等日常性商务工作。窗口函数就是为了实现OLAP 而添加的标准SQL 功能。
1. 窗口函数的分类
按照功能划分:
-
序号函数:row_number() / rank() / dense_rank()
-
分布函数:percent_rank() / cume_dist()
-
前后函数:lag() / lead()
-
头尾函数:first_val() / last_val()
-
聚合函数+窗口函数联合:
-
求和 sum() over()
-
求最大/小 max()/min() over()
-
求平均 avg() over()
-
-
其他函数:nth_value() / nfile()
如上,窗口函数的用法多种多样,不仅有专门的的窗口函数,还可以与聚合函数配合使用。
2. 窗口函数与普通聚合函数的区别:
聚合函数是将多条记录聚合为一条;窗口函数是每条记录都会执行,有几条记录执行完还是几条。
窗口函数兼具GROUP BY 子句的分组功能以及ORDER BY 子句的排序功能。但是,PARTITION BY 子句并不具备 GROUP BY 子句的汇总功能。
举例:若原表中有id一样的10行数据,使用GROUP BY,返回的结果是将多条记录聚合成一条;而使用 rank() 等窗口函数并不会减少原表中 记录的行数,结果中仍然包含 10 行数据。
窗口函数兼具分组和排序两种功能。
二、窗口函数的基本用法
如有基础数据:
drop table if exists exam_record;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1006, 9003, '2021-09-07 10:01:01', '2021-09-07 10:21:02', 84),
(1006, 9001, '2021-09-01 12:11:01', '2021-09-01 12:31:01', 89),
(1006, 9002, '2021-09-06 10:01:01', '2021-09-06 10:21:01', 81),
(1005, 9002, '2021-09-05 10:01:01', '2021-09-05 10:21:01', 81),
(1005, 9001, '2021-09-05 10:31:01', '2021-09-05 10:51:01', 81),
(1004, 9002, '2021-09-05 10:01:01', '2021-09-05 10:21:01', 71),
(1004, 9001, '2021-09-05 10:31:01', '2021-09-05 10:51:01', 91),
(1004, 9002, '2021-09-05 10:01:01', '2021-09-05 10:21:01', 80),
(1004, 9001, '2021-09-05 10:31:01', '2021-09-05 10:51:01', 80);
select uid,score from exam_record;
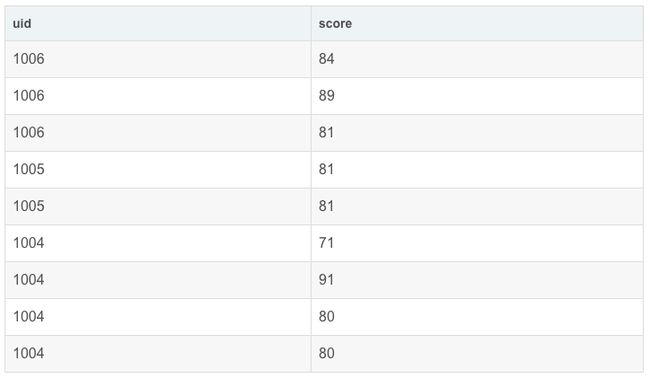
运行结果展示
1. 基本语法
<窗口函数> OVER ([PARTITION BY <列名清单>]
ORDER BY <排序列名清单>
[rows between 开始位置 and 结束位置])
其中:
<窗口函数>:指需要使用的分析函数,如row_number()、sum()等。
over() : 用来指定函数执行的窗口范围,这个数据窗口大小可能会随着行的变化而变化;
如果括号中什么都不写,则意味着窗口包含满足WHERE条件的所有行,窗口函数基于所有行进行计算。如:
select
uid,
score,
sum(score) over() as sum_score
from exam_record
结果:
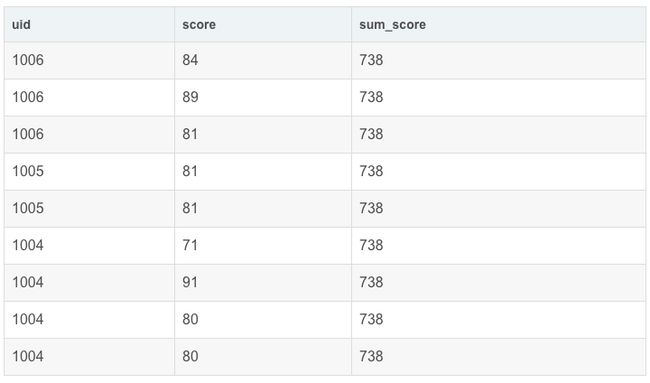
sum(score) over() as sum_score 会聚合所有的数据,将结果接到每一行的后面(窗口函数不会改变结果原表行数)。
2. 设置窗口的方法
如果不为空,则支持以下4中语法来设置窗口。
1)window_name
给窗口指定一个别名。如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读,如:
--给窗口指定别名:WINDOW my_window_name AS (PARTITION BY uid ORDER BY score)
SELECT
uid,
score,
rank() OVER my_window_name AS rk_num,
row_number() OVER my_window_name AS row_num
FROM exam_record
WINDOW my_window_name AS (PARTITION BY uid ORDER BY score)
2)partition by 子句
窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行,如:
实例1:
SELECT
uid,
score,
sum(score) OVER(PARTITION BY uid) AS sum_score
FROM exam_record
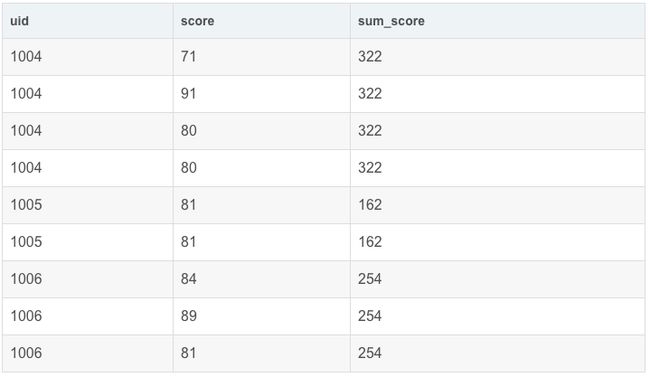
sum(score) OVER(PARTITION BY uid) AS sum_score 会按照 uid 分组,分别求和,展示在每个分组的末尾。
如果我想看某个uid有多少行记录,并标明序号该如何实现?使用序号函数row_number()请看:
SELECT
uid,
score,
row_number() OVER(PARTITION BY uid) AS row_num
FROM exam_record
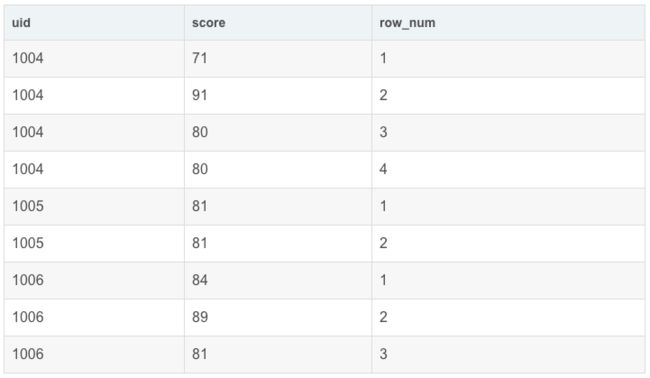
可以看到,row_number()按照uid分组并从上到下按照顺序标号。我们看到1004中的score是无序的,如果想按照score降序排名应该怎么做呢?(实际场景:成绩排名)
可以结合 order by 子句实现
3)order by子句
按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号,如:
SELECT
uid,
score,
row_number() OVER(PARTITION BY uid ORDER BY score desc) AS row_num
FROM exam_record
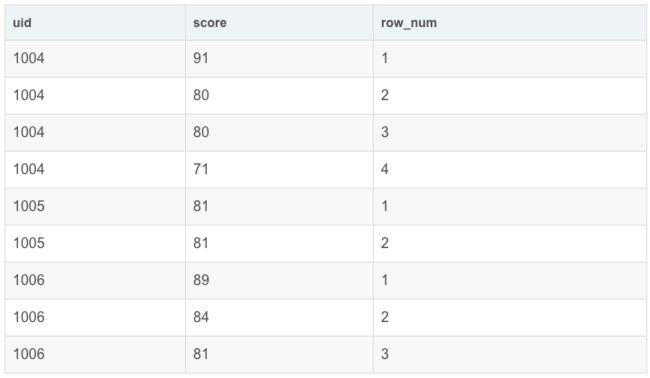
这样就实现了每个uid内的分数降序排名,order by 后面可以跟多个列名,大家可以试一试。
当order by 与聚合类函数连用时,特别需要注意理解,如下面几个例子:
先看前面的例子,单独使用 partition by uid
SELECT
uid,
score,
sum(score) OVER(PARTITION BY uid) AS sum_score
FROM exam_record
结果:
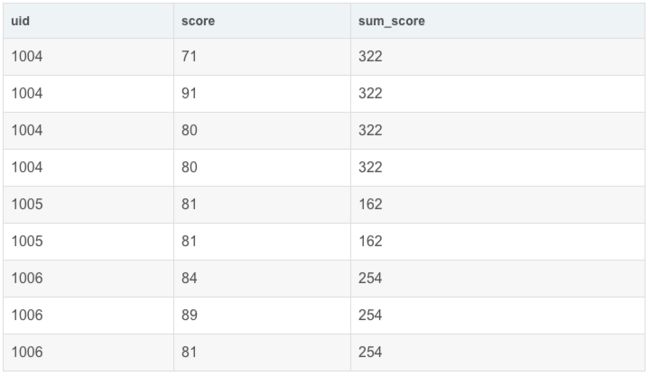
单独使用order by uid
SELECT
uid,
score,
sum(score) OVER(ORDER BY uid) AS sum_score
FROM exam_record
结果:
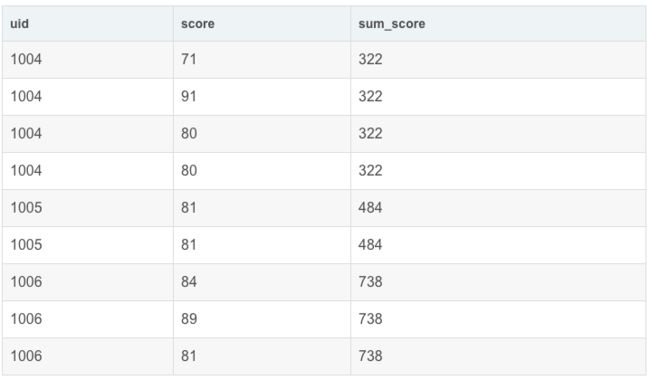
运行结果展示
注意观察uid 从1004->1005的变化,两条SQL的结果有什么不同:
-
partition by 按照uid分组,分别对score求和,”接到每一行的末尾“
-
分组内求和,分组间相互独立。
-
-
order by 按照uid排序,对”序号“相同的元素进行求和,不同”序号“的数累加求和
-
如果将”序号“认为是分组的话,个人理解这是一个分组求和并累加的过程
-
即分组内求和,分组间累加。
-
再看,order by score 的例子
SELECT
uid,
score,
sum(score) OVER(ORDER BY score) AS sum_score
FROM exam_record
结果:
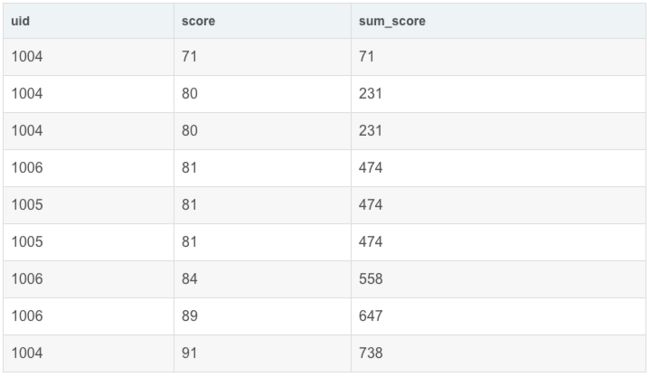
总结一下:
如果使⽤环境为hive,over()开窗函数前分排序函数和聚合函数两种。
当为排序函数,如row_number(),rank()等时,over中的order by只起到窗⼝内排序作⽤。
当为聚合函数,如max,min,count等时,over中的order by不仅起到窗⼝内排序,还起到窗⼝内从当前⾏到之前所有⾏的聚合(多了⼀个范围)。
4)rows 指定窗口大小
a. 先看个例子,按照顺序,求score的平均值:
SELECT
uid,
score,
avg(score) OVER(ORDER BY score desc) AS avg_score
FROM exam_record
注意score相同的部分:
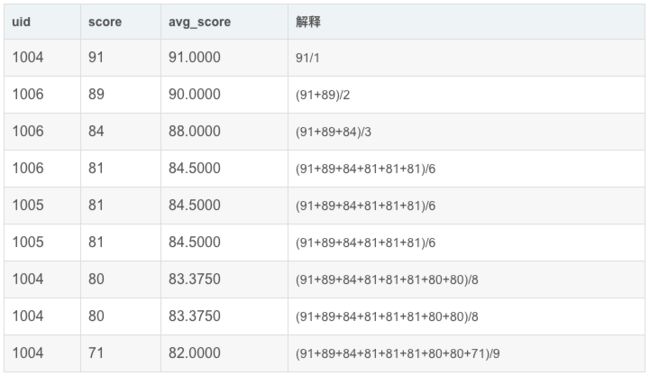
如果想要 sql 先按照 score 降序排列,每一行计算从第一行到当前行的 score 平均值,该怎么计算呢?——想办法做一个不重复的 key 。
实现:
SELECT
uid,
score,
row_score,
avg(score) OVER(ORDER BY row_score) AS avg_score
FROM (
SELECT
uid,
score,
row_number() OVER(ORDER BY score desc) AS row_score
FROM exam_record
) res

现在改下需求,希望求"我与前两名的平均值"应该怎么实现呢?
分析一下,"我与前两名"指的是当前行以及前两行总共三行数据求平均,也就是说,我们需要限定窗口的范围或者窗口大小。
b.引入窗口框架
指定窗口大小,又称为窗口框架。框架是对窗口进行进一步分区,框架有两种范围限定方式:
一种是使用 ROWS 子句,通过指定当前行之前或之后的固定数目的行来限制分区中的行数。
另一种是使用 RANGE 子句,按照排列序列的当前值,根据相同值来确定分区中的行数。
语法:
ORDER BY 字段名 RANGE|ROWS 边界规则0 | [BETWEEN 边界规则1 AND 边界规则2]
RANGE | ROWS的区别是什么?
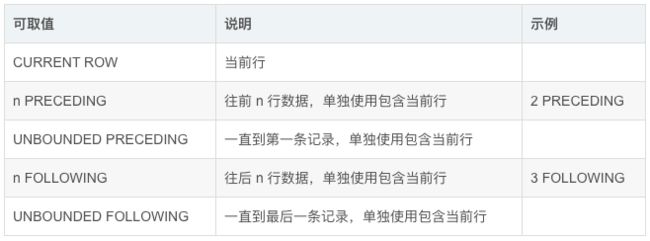
RANGE表示按照值的范围进行范围的定义,而ROWS表示按照行的范围进行范围的定义;边界规则的可取值见下表:
需要注意:
-
当使用框架时,必须要有 order by 子句,如果仅指定了order by 子句而未指定框架,那么默认框架将采用 RANGE UNBOUNDED PRECEDING AND CURRENT ROW(表示当前行以及一直到第一行的数据)。
-
如果窗口函数没有指定 order by 子句,也就不存在 ROWS/RANGE 窗口的计算。
-
PS: RANGE 只支持使用 UNBOUNDED 和 CURRENT ROW 窗口框架分隔符。
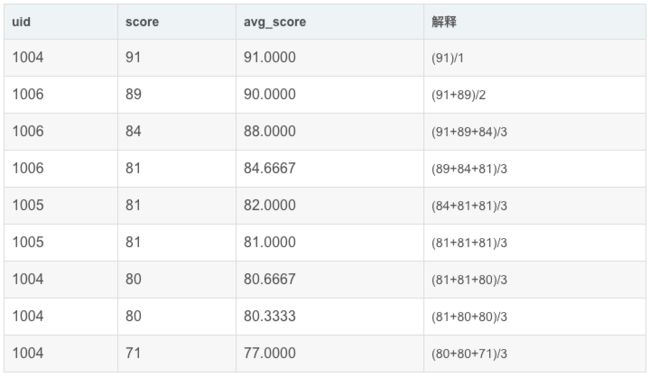
OK,回到前面的需求:求"我与前两名的平均值"。因为要"我与前两名",所以我们会用到规则 2 PRECEDING
之前2行的记录
之前1行的记录
自身(当前记录)
SELECT
uid,
score,
avg(score) OVER(ORDER BY score desc rows 2 PRECEDING) AS avg_score
FROM exam_record
如果要求当前行及前后一行呢?
之前1行的记录
自身(当前记录)
之后1行的记录
SELECT
uid,
score,
avg(score) OVER(ORDER BY score desc rows between 1 PRECEDING and 1 FOLLOWING) AS avg_score
FROM exam_record
结果略~
其他组合举例:
1.第一行到当前行
ORDER BY score desc rows UNBOUNDED PRECEDING
2.第一行到前一行(不含当前行)
ORDER BY score desc rows between UNBOUNDED PRECEDING and 1 PRECEDING
3.第一行到后一行(包含当前行)
ORDER BY score desc rows between UNBOUNDED PRECEDING and 1 FOLLOWING
4.当前行到最后一行
ORDER BY score desc rows between CURRENT ROW and UNBOUNDED FOLLOWING
注意,这种写法是错误的
ORDER BY score desc rows UNBOUNDED FOLLOWING -- 错误示范
5.前一行到最后一行(包含当前行)
ORDER BY score desc rows between 1 PRECEDING and UNBOUNDED FOLLOWING
6.后一行到最后一行(不含当前行)
ORDER BY score desc rows between 1 FOLLOWING and UNBOUNDED FOLLOWING
7.前一行到后一行(包含当前行)
ORDER BY score desc rows between 1 PRECEDING and 1 FOLLOWING
3. 开窗函数中加order by 和 不加 order by的区别
如果使⽤环境为hive,over()开窗函数前分排序函数和聚合函数两种。
当为排序函数,如row_number(),rank()等时,over中的order by只起到窗⼝内排序作⽤。
当为聚合函数,如max,min,count等时,over中的order by不仅起到窗⼝内排序,还起到窗⼝内从当前⾏到之前所有⾏的聚合(多了⼀个范围)。
如:
-- sql ①
select id, dept, salary, min(salary) over(partition by dept) min_sal from dept;
-- sql ②
select id, dept, salary, min(salary) over(partition by dept order by id) min_sal from dept;
上⾯①②中的min_salary字段的值会不⼀样,原因是②中使⽤order by后,等同于 min(salary) over(partition by dept order by userid range between unbounded preceding and current row ),当然可以在order by后使⽤框架⼦句,即rows,range等,如果没有写框架⼦句,就默认在窗⼝范围中当前⾏到之前所有⾏的数据进⾏统计。
再看个例子:
# 表数据为:exam_record(uid,exam_id,start_time,end_time,score)
# (1001, 9001, '2021-09-01 09:01:01', '2021-09-01 09:31:00', 100),
# (1001, 9001, '2021-09-02 09:01:01', '2021-09-01 09:31:00', 100),
# (1001, 9001, '2021-09-03 09:01:01', '2021-09-01 09:31:00', 100),
# (1002, 9001, '2021-09-01 09:01:01', '2021-09-01 09:31:00', 100),
# (1002, 9001, '2021-09-01 09:01:01', '2021-09-01 09:31:00', 100),
# (1002, 9001, '2021-09-02 09:01:01', '2021-09-01 09:31:00', 100);
-- 执行下面的sql
select
uid,
exam_id,
start_time,
sum(score) over(partition by uid) as one,
sum(score) over(partition by uid order by start_time) as two
from exam_record;
得到结果:
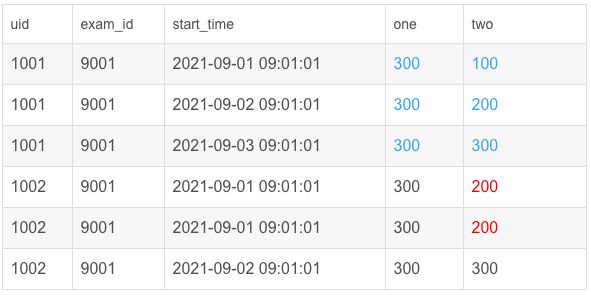
需要注意表中标注的部分。
三、窗口函数用法举例
1. 序号函数:row_number() / rank() / dense_rank()(面试重点)
三者区别:
-
RANK(): 并列排序,跳过重复序号——1、1、3
-
ROW_NUMBER(): 顺序排序——1、2、3
-
DENSE_RANK(): 并列排序,不跳过重复序号——1、1、2
--给窗口指定别名:WINDOW my_window_name AS (PARTITION BY uid ORDER BY score)
SELECT
uid,
score,
rank() OVER my_window_name AS rk_num,
row_number() OVER my_window_name AS row_num
FROM exam_record
WINDOW my_window_name AS (PARTITION BY uid ORDER BY score)
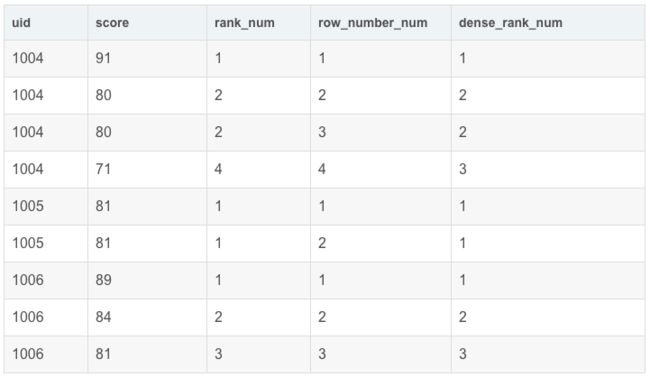
我们来探索一下,如果不使用窗口函数,如何实现分数排序呢?(使用自连接的方法)
-- 相当于 rank()
SELECT
P1.uid,
P1.score,
(SELECT
COUNT(P2.score)
FROM exam_record P2
WHERE P2.score > P1.score) + 1 AS rank_1
FROM exam_record P1
ORDER BY rank_1;
这里1234447..,如果想要7改为5呢,不跳过位次。相当于DENSE_RANK 函数。
只需要改 COUNT(P2.score) 为 COUNT(distinct P2.score) 即可。
2. 分布函数:percent_rank() / cume_dist()
1)percent_rank():
percent_rank()函数将某个数值在数据集中的排位作为数据集的百分比值返回,此处的百分比值的范围为 0 到 1。此函数可用于计算值在数据集内的相对位置。如班级成绩为例,返回的百分数30%表示某个分数排在班级总分排名的前30%。
每行按照公式(rank-1) / (rows-1)进行计算。其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。
SELECT
uid,
score,
rank() OVER my_window_name AS rank_num,
PERCENT_RANK() OVER my_window_name AS prk
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
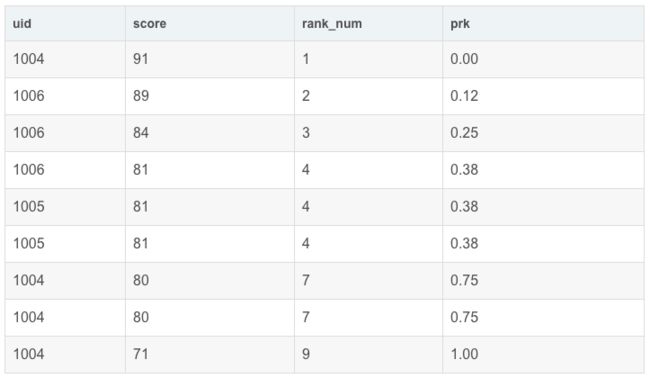
运行结果展示
2)cume_dist():
如果按升序排列,则统计:小于等于当前值的行数/总行数。
如果是降序排列,则统计:大于等于当前值的行数/总行数。
如:查询小于等于当前成绩(score)的比例。
SELECT
uid,
score,
rank() OVER my_window_name AS rank_num,
cume_dist() OVER my_window_name AS cume_dist_num
FROM exam_record
WINDOW my_window_name AS (ORDER BY score asc)

运行结果展示
3. 前后函数 lag(expr,n,defval)、lead(expr,n,defval)(面试重点)
Lag()和Lead()分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
在实际应用当中,若要用到取今天和昨天的某字段差值时,Lag()和Lead()函数的应用就显得尤为重要。当然,这种操作可以用表的自连接实现,但是LAG()和LEAD()与left join、rightjoin等自连接相比,效率更高,SQL更简洁。下面我就对这两个函数做一个简单的介绍。
函数语法如下:
lag( exp_str,offset,defval) over(partition by .. order by …)
lead(exp_str,offset,defval) over(partition by .. order by …)
其中
-
exp_str 是字段名
-
Offset 是偏移量,即是上1个或上N个的值,假设当前行在表中排在第5行,offset 为3,则表示我们所要找的数据行就是表中的第2行(即5-3=2)。
-
Defval 默认值,当两个函数取 上N 或者 下N 个值,当在表中从当前行位置向前数N行已经超出了表的范围时,lag() 函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NULL,那么在数学运算中,总要给一个默认值才不会出错。
用途:
-
返回位于当前行的前n行的expr的值:LAG(expr,n)
-
返回位于当前行的后n行的expr的值:LEAD(expr,n)
举例:查询前1名同学及后一名同学的成绩和当前同学成绩的差值(只排分数,不按uid分组)
先将前一名和后一名的分数与当前行的分数放在一起:
SELECT
uid,
score,
LAG(score,1,0) OVER my_window_name AS `前一名分数`,
LEAD(score,1,0) OVER my_window_name AS `后一名分数`
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
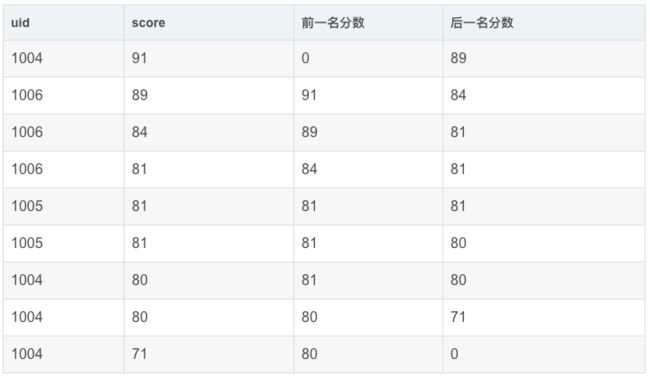
再做diff:
SELECT
uid,
score,
score - `前一名分数` AS `与前一名分差`,
score - `后一名分数` AS `与后一名分差`
FROM (
SELECT
uid,
score,
LAG(score,1,0) OVER my_window_name AS `前一名分数`,
LEAD(score,1,0) OVER my_window_name AS `后一名分数`
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
) res
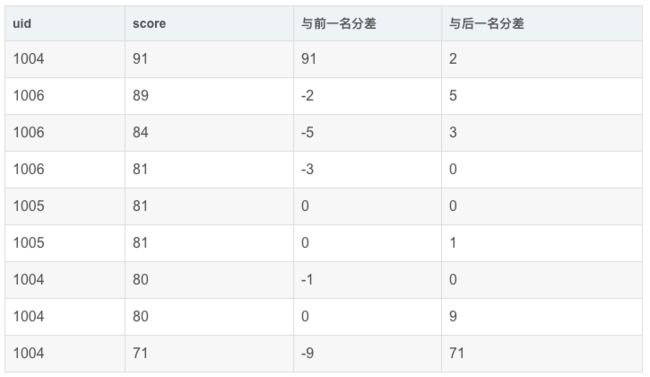
运行结果展示
4. 头尾函数:FIRST_VALUE(expr),LAST_VALUE(expr)
用途:
-
返回第一个expr的值:FIRST_VALUE(expr)
-
返回最后一个expr的值:LAST_VALUE(expr)
应用场景:截止到当前成绩,按照分数排序查询第1个和最后1个的分数
SELECT
uid,
score,
FIRST_VALUE(score) OVER my_window_name AS `第一行分数`,
LAST_VALUE(score) OVER my_window_name AS `最后一行分数`
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
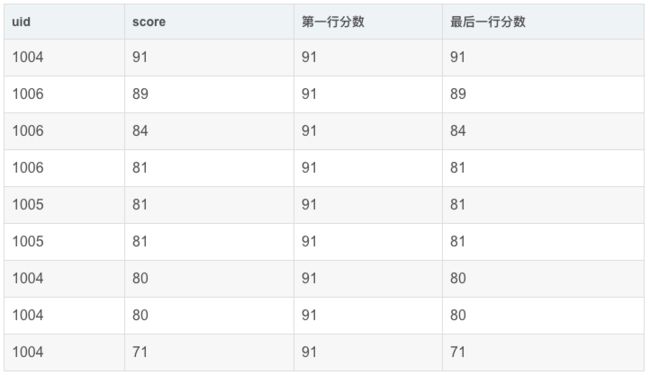
运行结果展示
5. 聚合函数+窗口函数联合使用
聚合函数也可以用于窗口函数。
原因就在于窗口函数的执行顺序(逻辑上的)是在FROM,JOIN,WHERE,GROUP BY,HAVING之后,在ORDER BY,LIMIT,SELECT DISTINCT之前。它执行时GROUP BY的聚合过程已经完成了,所以不会再产生数据聚合。
注:窗口函数是在where之后执行的,所以如果where子句需要用窗口函数作为条件,需要多一层查询,在子查询外面进行。
前面基本用法中已经有部分举例,如:
SELECT
uid,
score,
sum(score) OVER my_window_name AS sum_score,
max(score) OVER my_window_name AS max_score,
min(score) OVER my_window_name AS min_score,
avg(score) OVER my_window_name AS avg_score
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
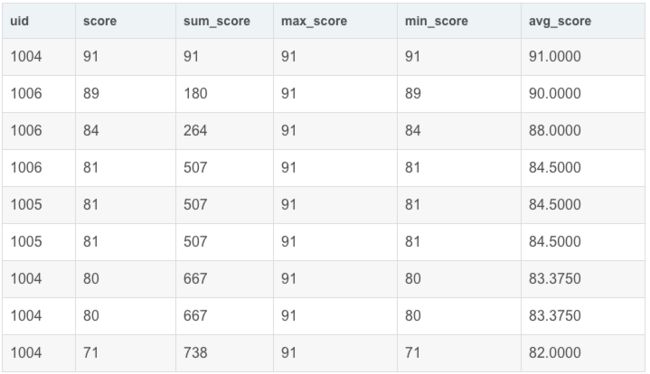
运行结果展示
mysql> SELECT
-> stu_id,
-> lesson_id,
-> score,
-> create_time,
-> FIRST_VALUE(score) OVER w AS first_score, -- 按照lesson_id分区,create_time升序,取第一个score值
-> LAST_VALUE(score) OVER w AS last_score -- 按照lesson_id分区,create_time升序,取最后一个score值
-> FROM t_score
-> WHERE lesson_id IN ('L001','L002')
-> WINDOW w AS (PARTITION BY lesson_id ORDER BY create_time)
-> ;
+--------+-----------+-------+-------------+-------------+------------+
| stu_id | lesson_id | score | create_time | first_score | last_score |
+--------+-----------+-------+-------------+-------------+------------+
| 3 | L001 | 100 | 2018-08-07 | 100 | 100 |
| 1 | L001 | 98 | 2018-08-08 | 100 | 98 |
| 2 | L001 | 84 | 2018-08-09 | 100 | 99 |
| 4 | L001 | 99 | 2018-08-09 | 100 | 99 |
| 3 | L002 | 91 | 2018-08-07 | 91 | 91 |
| 1 | L002 | 86 | 2018-08-08 | 91 | 86 |
| 2 | L002 | 90 | 2018-08-09 | 91 | 90 |
| 4 | L002 | 88 | 2018-08-10 | 91 | 88 |
+--------+-----------+-------+-------------+-------------+------------+
四、面试题
1. 用户行为分析
表1:用户行为表tracking_log,大概字段有(user_id‘用户编号’,opr_id‘操作编号’,log_time‘操作时间’)如下所示:

问题:
1)统计每天符合以下条件的用户数:A操作之后是B操作,AB操作必须相邻
分析:
(1)统计每天,所以需要按天分组统计求和
(2)A操作之后是B,且AB操作必须相邻,那就涉及一个前后问题,所以想到用窗口函数中的lag()或lead()。
-- 使用 lead() 实现
select
dt,
count(1) as res_cnt
from (
select
user_id,
date_format(log_time,"%Y%m%d") as dt,
opr_id as curr_opr, -- 当前操作
lead(opr_id,1) over(partition by user_id,date_format(log_time,"%Y%m%d") order by log_time) as next_opr -- 获取 下一个操作
from tracking_log
) res
where curr_opr = "A" and next_opr="B"
group by dt
---------------------------------
-- 使用 lag() 实现
select
dt,
count(1) as res_cnt
from (
select
user_id,
date_format(log_time,"%Y%m%d") as dt,
opr_id as curr_opr, -- 当前操作
lag(opr_id,1) over(partition by user_id,date_format(log_time,"%Y%m%d") order by log_time) as before_opr -- 获取 前一个操作
from tracking_log
) res
where before_opr = "A" and curr_opr="B"
group by dt
2)统计用户行为序列为A-B-D的用户数,其中:A-B之间可以有任何其他浏览记录(如C,E等),B-D之间除了C记录可以有任何其他浏览记录(如A,E等)
select
count(*)
from(
select
user_id,
group_concat(opr_id) ubp -- 先按照用户分组,将组内的opr_id拼接起来
from tracking_log
group by user_id
) a
where ubp like '%A%B%D%' and ubp not like '%A%B%C%D%'
2. 学生成绩分析
表:Enrollments (student_id, course_id) 是该表的主键。
1)查询每位学生获得的最高成绩和它所对应的科目,若科目成绩并列,取 course_id 最小的一门。查询结果需按 student_id 增序进行排序。
分析:因为需要最高成绩和所对应的科目,所以可采用窗口函数排序分组取第一个
select
student_id,
course_id,
grade
from (
select
student_id,
course_id,
grade,
row_number() over(partition by student_id order by grade desc,course_id asc) as rank_num
from Enrollments
) res
where rank_num = 1
order by student_id
解法2:IN 解法
取成绩在最大成绩之中的学生的最小课程号的课程
select student_id,min(course_id)
from Enrollments
where (student_id,grade) in (
-- 先取最大成绩
select student_id,max(grade)
from Enrollments
group by student_id)
group by student_id
order by student_id;
2)查询每一科目成绩最高和最低分数的学生,输出course_id,student_id,score
我们可以按科目查找成绩最高的同学和最低分的同学,然后利用union连接起来。
select
c_id,
s_id
from(
select
*,
row_number() over(partition by c_id order by s_score desc) r
from score
) a
where r = 1
union
select
c_id,
s_id
from(
select
*,
row_number() over(partition by c_id order by s_score) r
from score
) a
where r = 1;
解法2:case-when
select
c_id,
max(case when r1 = 1 then s_id else null end) '最高分学生',
max(case when r2 = 1 then s_id else null end) '最低分学生'
from(
select
*,
row_number() over(partition by c_id order by s_score desc) r1,
row_number() over(partition by c_id order by s_score) r2
from score
) a
group by c_id;