【自监督论文阅读笔记】Integrally Pre-Trained Transformer Pyramid Networks (2022)
Abstract
在本文中,我们提出了一个基于掩码图像建模 (MIM) 的整体预训练框架。我们提倡 联合预训练 backbone 和 neck,使 MIM 和下游识别任务之间的迁移差距最小。我们做出了两项技术贡献。首先,我们通过 在预训练阶段 插入特征金字塔 来统一重建和识别颈部。其次,我们 用掩码特征建模 (MFM) 补充 掩码图像建模 (MIM),为特征金字塔提供多阶段监督。预训练模型称为 integrally pre-trained transformer pyramid networks 整体预训练transformer 金字塔网络 (iTPN),可作为视觉识别的强大基础模型。特别是,base/large-level iTPN 在 ImageNet-1K 上达到了 86.2%/87.8% 的 top-1 准确率,在使用 MaskRCNN 进行 1× 训练计划的 COCO 目标检测上达到了 53.2%/55.6% 的框 AP,以及 54.7% /57.7% mIoU 在使用 UPerHead 的 ADE20K 语义分割上——所有这些结果都创下了新记录。我们的工作激励社区致力于统一上游预训练和下游微调任务。
代码和预训练模型将在 https://github.com/sunsmarterjie/iTPN 发布。
1. Introduction
近年来,视觉识别取得了两大进展,即 作为网络主干的 vision transformer 架构 [18] 和 用于视觉预训练的掩码图像建模 (MIM) [2,25,62]。结合这两种技术 产生了一个通用的管道,在广泛的视觉识别任务中实现了最先进的技术,包括图像分类、目标检测 和 实例/语义分割。
上述流程的关键问题之一是上游预训练和下游微调之间的迁移差距。从这个角度来看,我们认为下游视觉识别,尤其是精细尺度识别(例如,检测和分割),需要层次化的视觉特征。然而,大多数 现有的预训练任务(例如 BEiT [2] 和 MAE [25])都是建立在普通的 vision transformers之上的。即使使用了分层 vision transformers(例如,在 SimMIM [62]、ConvMAE [22] 和 GreenMIM [30] 中),预训练任务只会影响骨干,但是 留下颈部(例如,特征金字塔)未被训练。这给下游微调带来了额外的风险,因为 优化从随机初始化的颈部开始,不能保证与预训练的骨干合作。
([22] Convmae: Masked convolution meets masked autoencoders)
在本文中,我们 提出了一个完整的预训练框架 来减轻风险。我们使用 HiViT [67](一种 MIM 友好的分层视觉转换器)建立基线,并为其配备特征金字塔。为了联合优化骨干(HiViT)和颈部(特征金字塔),我们做出了双重技术贡献。首先,我们通过 将特征金字塔插入预训练阶段(用于重建)并在微调阶段重用权重(用于识别)来统一上游和下游颈部。其次,为了更好地预训练特征金字塔,我们 提出了一个新的掩码特征建模 (MFM) 任务,该任务 (i) 通过 将原始图像输入移动平均主干 来计算中间目标,以及 (ii) 使用每个金字塔阶段的输出来 重建中间目标。 MFM 是 MIM 的补充,提高了重建和识别的准确性。 MFM 还可以适应从预先训练的教师(例如 CLIP [47])那里吸收知识 以获得更好的性能。
获得的模型被命名为 整体预训练金字塔 transformer 网络(iTPN)。我们在标准视觉识别基准上评估它们。如图 1 中突出显示的那样,iTPN 系列报告了最著名的下游识别准确度。在 COCO 和 ADE20K 上,iTPN 很大程度上受益于预训练的特征金字塔。例如,base/large-level iTPN 在 COCO(1× schedule,Mask R-CNN)上报告了 53.2%/55.6% box AP,在 ADE20K(UPerNet)上报告了 54.7%/57.7% mIoU,大大超越现有的所有方法。在 ImageNet-1K 上,iTPN 也显示出显着的优势,这意味着在与 neck 的联合优化过程中,backbone 本身变得更强大。例如,base/largelevel iTPN 报告了 86.2%/87.8% 的 top-1 分类准确率,比之前的最佳记录高出 0.7%/0.5%,这在如此激烈的竞争中看起来不小。在诊断实验中,我们表明 iTPN 具有 (i) MIM 预训练中 较低的重建误差 和 (ii) 下游微调中 更快的收敛速度——这证实 缩小迁移差距 对上游和下游部分都有好处。
总的来说,本文的主要贡献在于 完整的预训练框架,除了设置新的最先进的技术之外,还启发了一个重要的未来研究方向——统一上游预训练和下游微调以缩小它们之间的迁移差距。
2. Related Work
在深度学习时代[34],视觉识别算法大多建立在深度神经网络之上。在过去十年中有两个重要的网络主干,即 卷积神经网络 [28,33,48] 和 vision transformers [19,40,53,67]。本文重点介绍了 从 自然语言处理领域 移植而来的 vision transformers[52]。核心思想是通过 将每个图像块视为标记token 并 计算它们之间的自注意力 来提取视觉特征。
普通的vision transformers 以简单的形式出现[19,64,68],其中,在整个主干中,标记tokens 的数量保持恒定,并且这些标记之间的注意力完全对称。为了补偿计算机视觉中的归纳先验,社区设计了 分层 vision transformers [12,40,53,59,67],允许 标记的数量在整个主干中逐渐减少,即类似于卷积神经网络。还继承了其他设计原则,例如 将卷积引入到 transformer 架构中,以便 更好地制定邻域tokens之间的关系[12,20,36,42,53,54],混合信息之间的交互[46],使用 窗口[16 CSwin,40 Swin,67 HiViT] 或 局部[65] 自注意力 来代替全局自注意力,调整局部-全局交互的几何结构[63],分解自注意力[51] 等等。已经表明,分层vision transformers 可以 提供高质量、多级视觉特征,这些特征 容易与颈部模块 (用于特征聚集,例如特征金字塔[37]) 协作,并且有益于下游视觉识别任务。
视觉数据的持续增长需要视觉预训练,特别是 从未标记的视觉数据中 学习通用视觉表示的自监督学习。自监督学习的核心是一个前置任务,即模型追求的无监督学习目标。社区从初步的前置任务开始,例如 基于几何的任务(例如,确定图像块之间的相对位置 [15、43、56] 或 应用于图像的变换 [23])和 基于生成的任务(例如,恢复图像的删除内容 [44] 或属性 [66]),但是当迁移到下游识别任务时,这些方法的准确性不令人满意(即,显著落后于完全监督的预训练)。当引入新的前置任务时,情况发生了变化,特别是 对比学习 [5、6、9、24、24、26、61] 和 掩码图像建模 (MIM) [2、25、62],后者是另一种基于生成的学习目标。
本文重点介绍 MIM,它利用 vision transformers 的优势,将每个图像块转化为token 。因此,标记可以被任意屏蔽(从输入数据中丢弃),学习目标是在 像素级别 [25, 62]、特征级别 [2, 55] 或频率空间 [ 39]。 MIM 展示了一个名为 可扩展性 的重要属性,即 增加预训练数据量(例如,从 ImageNet-1K 到 ImageNet-22K)和/或 增加模型大小(例如,从基本级别到大型或巨大级别)可以提高下游性能 [10, 25],这与语言建模 [3, 14] 中的观察结果一致。研究人员还试图理解 MIM 的工作机制,例如 将表示学习与前置任务 [10] 分开,改变框架的输入 [21, 50] 或输出 [2, 39, 55],增加重构的难度[32,50],引入其他方式的监督 [45, 57],等等。
大多数现有的 MIM 方法都适用于普通的 vision transformers ,但 分层 vision transformers 在视觉识别方面具有更高的潜力。第一个试图弥合差距的工作是 SimMIM [62],但整体预训练开销大大增加,因为整个图像(带有dummy掩码patches)被馈送到编码器。这个问题后来通过 改革分层vision transformers [30、67] 以更好地适应 MIM 而得到缓解。本文 继承设计并更进一步,将颈部(例如,特征金字塔)集成到预训练阶段,构建整体预训练的transformers 金字塔网络。
3. The Proposed Approach
3.1. Motivation: Integral Pre-Training 整体预训练
我们首先建立一个符号系统。预训练阶段建立在数据集 ![]() 上,其中 N 是样本数。请注意,这些样本未配备标签。微调阶段涉及另一个数据集
上,其中 N 是样本数。请注意,这些样本未配备标签。微调阶段涉及另一个数据集 ![]() ,其中 M 是样本数,ymft 是 xmft 的语义标签。设目标深度神经网络由backbone、neck、head组成,分别表示为f(·;θ)、g(·;φ)、h(·;ψ),其中θ、φ、ψ为可学习参数为简单起见可以省略。 f(·)直接将x作为输入,而g(·)和h(·)作用于f(·)和g(·)的输出,即整个函数为h(g(f(x; θ ); φ); ψ)。
,其中 M 是样本数,ymft 是 xmft 的语义标签。设目标深度神经网络由backbone、neck、head组成,分别表示为f(·;θ)、g(·;φ)、h(·;ψ),其中θ、φ、ψ为可学习参数为简单起见可以省略。 f(·)直接将x作为输入,而g(·)和h(·)作用于f(·)和g(·)的输出,即整个函数为h(g(f(x; θ ); φ); ψ)。
(我们遵循传统的定义,即 颈部用于多级特征聚合(例如,特征金字塔 [37]),而 头部用于最终预测(例如,线性分类器)。)
在本文中,预训练任务是 掩码图像建模 (MIM),微调任务可以是图像分类、目标检测和实例/语义分割。现有方法假设它们共享相同的主干,但需要不同的颈部和头部。在数学上,预训练和微调目标写为:
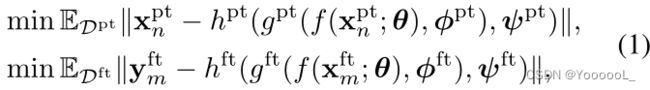
其中,φpt、φft 和 ψpt、ψft 之间不共享参数。我们认为,这样的管道会导致预训练和微调之间存在显著的迁移差距,从而带来双重缺点。首先,骨干参数 θ 并未针对用于多级特征提取进行优化。其次,微调阶段 从优化随机初始化的 φft 和 ψft 开始,这可能会减慢训练过程并导致不满意的识别结果。为了缩小差距,我们提倡 统一 gpt(·) 和 gft(·) 的整体框架,以便预训练的 φpt 很容易被重用为 φft 的初始化,因此只有 ψft 被随机初始化。
总体框架如图 2 所示。
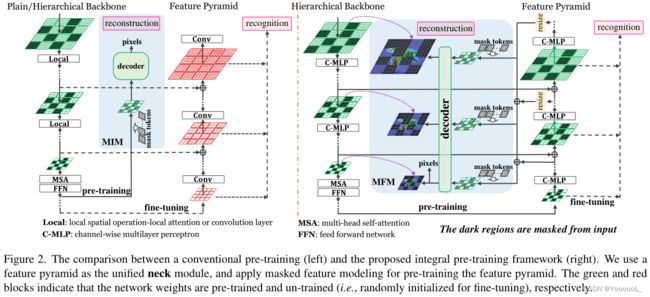
3.2.统一重建和识别
让一个分层 vision transformer 包含 S 个阶段,每个阶段都有几个 transformer 块。大多数情况下,主干(也称为编码器)逐渐 对输入信号进行下采样 并生成 S + 1 个特征图:
![]()
其中 U0 表示输入的直接嵌入,较小的上标索引表示更接近输入层的阶段。每个特征图由一组 标记tokens(特征向量)组成,即 ![]() ,其中 Ks 是第 s 个特征图中的标记数量。
,其中 Ks 是第 s 个特征图中的标记数量。
我们表明 gpt(·) 和 gft(·) 可以 共享相同的体系结构和参数,因为它们 都从 US 开始 并逐渐将其与较低级别的特征聚合。因此,我们将 颈部 写成如下:
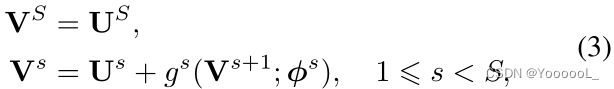
其中 gs(·) 对 Vs+1 进行上采样 以适应 Vs 的分辨率。请注意,可学习参数 φ 由分层参数集 {φs} 组成。通过 在微调中重复使用这些参数,我们大大缩小了迁移差距:在预训练和微调之间唯一保持独立的模块是头部(例如,MIM 的解码器与用于检测的 Mask R-CNN 头部) .
在进入讨论损失项的下一部分之前,我们提醒读者预训练和微调之间存在其他差异,但它们不会影响网络架构的整体设计。
• MIM 对随机掩码 M 进行采样并将其应用于 x,即 x 被替换为 ![]() 。因此,所有主干输出,U0, . . . US, 不包含 M 中带有索引的标记,V1, . . .,VS也是如此。在解码器开始时,
。因此,所有主干输出,U0, . . . US, 不包含 M 中带有索引的标记,V1, . . .,VS也是如此。在解码器开始时,![]() 通过 向掩码索引添加 dummy tokens虚拟标记来补充,然后馈入解码器以进行图像重建。
通过 向掩码索引添加 dummy tokens虚拟标记来补充,然后馈入解码器以进行图像重建。
• 下游微调程序利用解码器的特定输出来完成不同的任务。对于图像分类,使用 VS。对于检测和分割,所有的 V1,. . . VS都用。
3.3.掩码特征建模
我们首先从最小化 ![]() 的 MIM 中 继承重建损失,其中 hpt,0(·) 包含几个从
的 MIM 中 继承重建损失,其中 hpt,0(·) 包含几个从 ![]() 重建原始图像的 transformer 块。为了获得捕获多阶段特征的能力,我们在每个阶段添加一个 重建头,称为
重建原始图像的 transformer 块。为了获得捕获多阶段特征的能力,我们在每个阶段添加一个 重建头,称为 ![]() ,并优化以下多阶段损失:
,并优化以下多阶段损失:

其中 xs 是第 s 个解码器阶段的预期输出,λ = 0.3 在保留验证集中确定。由于目标是恢复掩码特征,我们将第二项命名为掩码特征建模 (MFM) 损失,以补充第一项,即掩码图像建模 (MIM) 损失。我们在图 2 中说明了 MFM。

剩下的问题是确定中间的重建目标,即 x1, . . . , xS。我们借鉴了 知识蒸馏 [29] 的想法,它利用 教师骨干![]() 来生成中间目标,即
来生成中间目标,即 ![]() 。教师模型被选择为移动平均 [49] 编码器(在这种情况下,没有引入外部知识)或 另一个预训练模型(例如,[57,58] 使用的 CLIP [47],即在图像-文本对的大型数据集上进行了预训练)。在前一种情况下,我们只将 掩码块(
。教师模型被选择为移动平均 [49] 编码器(在这种情况下,没有引入外部知识)或 另一个预训练模型(例如,[57,58] 使用的 CLIP [47],即在图像-文本对的大型数据集上进行了预训练)。在前一种情况下,我们只将 掩码块(![]() ,不是整个图像)提供给教师模型进行加速。在后一种情况下,我们按照 BEiT [2] 将整个图像提供给预训练的 CLIP 模型。
,不是整个图像)提供给教师模型进行加速。在后一种情况下,我们按照 BEiT [2] 将整个图像提供给预训练的 CLIP 模型。
作为附带评论,整体预训练和 MFM 带来的好处是独立的和互补的——我们将在消融中揭示这一点(表 6)。
3.4.技术细节
我们构建了超越 HiViT [67] 的系统,这是一种最近提出的分层 vision transformer。 HiViT 通过以下方式简化了 Swin 变换器 [40]:(i) 用 通道多层感知器 (C-MLP) 替换早期的转移窗口注意力,以及 (ii) 删除 7 × 7 阶段,以便在 14 × 14 阶段计算全局注意力。通过这些改进,当应用于 MIM 时,HiViT 允许直接从输入中丢弃掩码的标记(相比之下,以 Swin 为骨干,SimMIM [62] 要求将整个图像用作输入),节省 30%–50 % 计算成本并导致更好的性能。
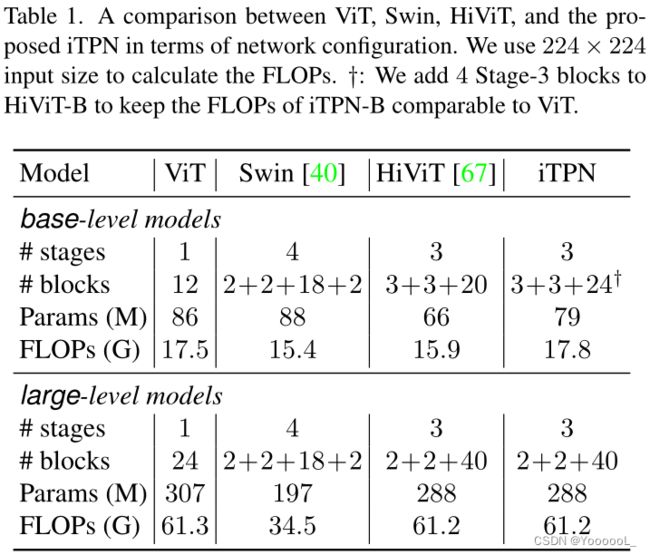
表 1 总结了 iTPN 的配置。计算复杂度与 ViT 相当。我们按照惯例在预训练期间使用 224 × 224 图像。 HiViT 产生三个阶段 (S = 3),空间分辨率分别为 56×56、28×28 和 14×14。 S个阶段的特征金字塔建立在主干之上。我们 用 C-MLP 替换特征金字塔中的所有卷积,以 避免信息从可见patches 泄漏到 不可见patches。正如我们将在消融(第 4.4 节)中看到的那样,在特征金字塔中使用 C-MLP 可以在各种视觉识别任务中获得一致的精度增益,并且这种改进是对 MFM 带来的改进的补充。
关于 MFM,我们研究了教师模型的两种选择。 (i) 第一个选项涉及计算系数为 0.996 的在线目标模型的指数移动平均线 (EMA)。我们从每个阶段的最后一层提取监督,因此对于任何 s,xs 具有与 Vs 相同的空间分辨率,因此 hs(·) 是单独作用于每个标记的线性投影。 (ii) 第二种选择直接继承一个CLIP预训练模型。请注意,CLIP 提供不生成多分辨率特征图的标准 ViT。在这种情况下,我们通过 将所有特征映射下采样到最低空间分辨率(14×14),将它们加在一起,并将总和与 CLIP 模型的最后一层输出进行比较,将 S个MFM 项统一为一个。
4. Experiments
4.1. Settings and Implementation Details
我们在 ImageNet-1K 数据集 [13] 上预训练 iTPN,这是 ImageNet 的一个子集,包含 1,000 个类别的 128 万张训练图像。在预训练阶段不使用类标签。每个训练图像都被预处理成 224×224 并分成 14×14 个patches,大小为 16×16 像素。遵循 MAE [25],从输入中屏蔽了 75% 块的随机子集,并保留了归一化像素用于重建。
我们使用 AdamW 优化器 [41],其初始学习率为 1.5 × 10−4,权重衰减为 0.05,批量大小为 4,096。学习率遵循余弦退火计划,预热阶段数设置为 40。如上所述,MFM 监督可能来自移动平均在线模型或预训练的 CLIP 模型。预训练时期的数量在前一种情况下为 400 和 1,600,在后一种情况下为 300 和 800。我们使用 64 个 NVIDIA Tesla-V100 GPU 训练所有这些模型。对于基础模型,一个像素监督的 epoch 和一个 CLIP 监督的 epoch 分别需要大约 2.7 和 4.7 分钟。对于大型模型,数字分别为 4.2 和 12.0 分钟。也就是说,iTPN-base/large 的 1600 epoch像素监督预训练大约需要 75/115 小时。我们将在附录中提供更多详细信息。
4.2.图像分类
微调
我们报告 ImageNet-1K 分类的结果。按照惯例,我们 在最后一个编码器块的顶部插入一个线性分类器,并对整个网络进行微调。基础级模型的 epoch 数为 100,大型模型为 50。我们使用 AdamW 优化器,初始学习率分别为 5 × 10−4 和 1 × 10−3 用于基础级和大型模型。权重衰减为 0.05,批量大小为 1,024。warm-up epochs 的数量为 5。对于 base-level 和 large-level 模型,layer decay 设置为 0.55 和 0.50。
结果总结在表 2 中。可以看出,iTPN 在所有轨道上都比现有方法具有更高的准确性,即使用基础或大型骨干网,有或没有外部监督(即 CLIP [47])。例如,使用基础级主干,iTPN 仅用 400 个预训练时期就达到了 85.1% 的准确率,超过了 MAE [25] 和 HiViT [67] 的 1,600 个时期。 iTPN 的准确性在 1,600 个预训练时期继续增长到 85.5%,这与从 CLIP-B [47](1,600 个时期)中提取知识的 BEiT-v2 [45] 相当,但 iTPN 报告的准确性为 86.2% CLIP 的监督(800 个纪元)。当我们使用 large-level backbone 时会出现类似的情况,由于基线较高,iTPN 的优势略小。最佳实践出现在 iTPN-L/14 模型(即,patch大小调整为 14 × 14)由 CLIP-L 教师监督时——分类准确率 88.0%,是迄今为止在公平比较下最高的。
线性探测
然后我们使用线性探测测试评估预训练模型,其中预训练的主干被冻结并且只允许对新初始化的线性分类器进行微调。因此,与微调相比,线性探测对预训练的主干提出了更高的要求。按照惯例,我们使用 LARS 优化器 [31] 训练 90 个时期的模型,批量大小为 16,384,学习率为 0.1。与微调的情况类似,iTPN 在分类精度方面优于所有基于 MIM 的方法。具体来说,具有 1,600 个预训练时期的 iTPN-B(像素)模型报告准确率为 71.6%,超过 1,600 个时期的 MAE [25] 3.8%,以及 400 个时期的 BEiT、800 个时期的 SimMIM和 1,600 次 CAE 分别增加了 22.2%、14.9% 和 1.2%。在 CLIP 监督下,具有 300 个预训练时期的 iTPN 报告准确率为 77.3%,超过具有相同设置的 MVP [57] 1.9%。
Insights见解
请注意,图像分类实验不涉及迁移预训练的颈部,即特征金字塔。也就是说,iTPN 仅通过预训练的骨干就可以实现更高的分类精度。这意味着(i)backbone 和 neck 的联合优化导致更强的 backbone,因此,(ii)衍生的 backbone 可以直接迁移到各种视觉任务,将 iTPN 扩展到更多的应用场景。
4.3.检测与分割
COCO:目标检测和实例分割
我们按照 [10] 提供的配置来评估 COCO [38] 数据集上的预训练模型。我们使用由 MMDetection [8] 实现的 Mask R-CNN [27]。我们使用权重衰减为 0.05 的 AdamW 优化器 [41]。应用标准 1×(12 个epoches)和 3× 时间表,其中初始学习率为 3 × 10-4,并且在 3/4 和 11/12 的微调时期后衰减 10 倍。逐层衰减率设置为 0.90。我们还尝试使用 3× Cascade Mask R-CNN [4] 来提高精度。我们应用多尺度训练和单尺度测试。
结果总结在表 4 中。与图像分类相比,iTPN 的优势变得更加显著,因为预训练的颈部被重复使用,因此微调阶段只需要初始化一个任务特定的头部。例如,使用像素监督的基础级主干,1× Mask R-CNN 产生 53.0% 的box AP,显著超过所有其他方法(例如,超过 MAE [25] + 4.6% 和超过 CAE [10] +3.0% ])。与没有预训练特征金字塔的 HiViT 相比,iTPN 声称在 box AP 上有 +1.7% 的增益。 1× Mask R-CNN 结果甚至与之前使用 3× Mask RCNN 或 3× Cascade Mask R-CNN 的方法相比具有竞争力。有了这些更强的heads,iTPN 报告了更强的数字,例如,使用 3× Cascade Mask R-CNN 的 box/mask AP 为 56.0%/48.5%,创下了 base-level 模型的新记录。当引入 CLIP 监督或使用大型骨干网时,优势仍然存在。稍后,我们将展示 好处确实来自预训练特征金字塔 并将其加载以进行下游微调。
4.4.分析
消融研究
在这一部分中,我们使用 400epoch 像素监督模型进行诊断。我们首先消融了整体预训练的好处。如表 5 所示,联合优化 backbone 和 neck 可以提高所有数据集(包括 ImageNet1K、COCO 和 ADE20K)的识别精度。除此之外,加载预训练的特征金字塔(颈部)进一步提高了在 COCO 和 ADE20K 上的识别精度。这证实了 iTPN 加强了骨干本身,因此它可以独立于颈部转移到下游任务。
接下来,我们研究整体预训练的技术细节,特别是在特征金字塔中使用 逐通道多层感知器 (C-MLP) 并 应用掩码特征建模 (MFM) 进行多阶段监督。如表 6 所示,C-MLP 和 MFM 都对识别精度有各自的贡献,同时,将它们结合起来会产生更好的识别性能。
可视化
在图 3 中,我们将 iTPN 和基线方法生成的注意力图可视化。 (1) 在编码器上,iTPN 显示了在 ImageNet 上检测完整目标和在 COCO 上专注于所选目标的优势。这种能力的出现是因为 iTPN 强制模型保留更丰富的视觉特征(多尺度特征图),这有助于在下游获得更好的识别结果。 (2) 在解码器上,iTPN 仍然可以实现 token 之间的语义关系,从而获得更好的重构结果(图 4)。我们将这些好处归功于聚合了多阶段视觉特征的预训练颈部。

可以使用图 4 所示的两个实验来量化 更完整的注意力所带来的好处。(1) 在左侧部分,我们观察到 iTPN 实现了更好的重建结果(即更低的重建损失值)。请注意,简单地使用分层vision transformer(具有多尺度特征图)不会改善重建,这意味着整体预训练是主要贡献者。 (2) 在右侧部分,我们展示了更好的目标描述有助于下游视觉识别任务(例如,目标检测)更快地收敛并实现更高的上限——这与 COCO 的出色准确性一致(参见第 4.3 节)。综合这些分析,我们得出结论,iTPN 成功地将上游预训练(重建)的好处转移到下游微调(识别),完成了整个链条。
5. 结论和未来的评论
在本文中,我们提出了一个用于预训练分层vision transformer的完整框架。核心贡献在于使用特征金字塔进行重建和识别的统一公式,从而最大限度地减少预训练和微调之间的迁移差距。此外,掩码特征建模(MFM)任务旨在补充掩码图像建模(MIM),以更好地优化特征金字塔。预训练的 iTPN 在一些流行的视觉识别任务中报告了卓越的识别能力。我们的工作清楚地启发了未来的方向——为上下游视觉表示学习设计一个统一的框架。