YOLO涨点Trick | 超越CIOU/SIOU,Wise-IOU让Yolov7再涨1.5个点!
作者 | 小书童 编辑 | 集智书童
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
后台回复【2D检测综述】获取鱼眼检测、实时检测、通用2D检测等近5年内所有综述!

边界框回归(BBR)的损失函数对于目标检测至关重要。它的良好定义将为模型带来显著的性能改进。大多数现有的工作假设训练数据中的样本是高质量的,并侧重于增强BBR损失的拟合能力。如果盲目地加强低质量样本的BBR,这将危及本地化性能。
Focal EIoU v1被提出来解决这个问题,但由于其静态聚焦机制(FM),非单调FM的潜力没有被充分利用。基于这一思想,作者提出了一种基于IoU的损失,该损失具有动态非单调FM,名为Wise IoU(WIoU)。当WIoU应用于最先进的实时检测器YOLOv7时,MS-COCO数据集上的AP75从53.03%提高到54.50%。
1、简介
YOLO系列的实时检测器已经得到大多数研究人员的认可,并自其问世以来应用于许多场景。例如YOLOv1,它构建了一个由BBR损失、分类损失和目标损失加权的损失函数。直到现在,这种构造仍然是目标检测任务最有效的损失函数范式,其中BBR损失直接决定了模型的定位性能。为了进一步提高模型的本地化性能,设计良好的BBR损失至关重要。
1.1、损失
对于 anchor box ,其中的值对应于边界框的中心坐标和宽高。类似地,描述目标框的特性。
YOLOv1和YOLOv2在BBR损失的定义上非常相似。其中YOLOv2将BBR损失定义为:

但是,这种形式的损失函数并不能屏蔽边界框大小的干扰,使得YOLOv2对小目标的定位性能较差。虽然YOLOv3构建了,试图减少模型对大目标的关注,但这种BBR损失给模型带来的定位性能仍然非常有限。
1.2、IOU
在目标检测任务中,使用IoU来测量anchor box与目标box之间的重叠程度。它以比例的形式有效地屏蔽了边界框大小的干扰,使该模型在使用(Eq2)作为BBR损失时,能够很好地平衡对大物体和小物体的学习。
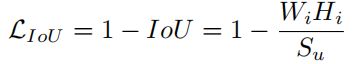
然而,有另一个致命缺陷,可在方程3中观察到当边界框之间没有重叠时(),的反向投影梯度消失。因此,在训练期间无法更新重叠区域(图1)的宽度。
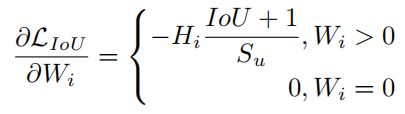
现有的工作GIOU、DIOU、Focal EIOU、CIOU以及SIOU中考虑了许多与边界框相关的几何因子,并构造了惩罚项来解决这个问题。现有的BBR损失遵循以下范例:
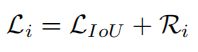
1.3、Focusing机制

图2显示了训练数据中一些低质量的例子。当一个性能良好的模型为低质量的例子生产高质量的anchor box时,它将产生大的。如果单调FM分配这些anchor box较大的梯度增益,模型的学习将受到损害。
在Focal EIOU中,FifanZhang等人提出了使用非单调调频的Focal EIOU v1。Focal-EIoU v1的FM 是静态的,它指定了anchor box的边界值,使等于边界值的anchor box具有最高的梯度增益。Focal-EIoU v1没有注意到anchor box的质量评价反映在相互比较中没有充分利用非单调调频的潜力。
最终通过估计anchor box的离群值来定义一个动态FM β为β。本文的FM通过分配小质量的梯度增益,使BBR能够专注于普通质量的anchor box。同时,该机制将较小的梯度增益分配给β较大的低质量anchor box,有效地削弱了低质量示例对BBR的危害。
作者将这样的FM与基于IoU的损失结合起来,并称之为Wise-IoU(WIoU)。为了评估提出的方法,作者将WIoU纳入到了最先进的实时检测器YOLOv7中。
主要贡献总结如下:
-
提出了BBR的基于注意力的损失WIoU v1,它在仿真实验中实现了比最先进的SIoU更低的回归误差。
-
设计了具有单调FM的WIoU v2和具有动态非单调FM的WIoU v3。利用动态非单调FM的明智的梯度增益分配策略,WIoU v3获得了优越的性能。
-
对低质量的样本的影响进行了一系列详细的研究,证明了动态非单调调频的有效性和效率。
2、相关工作
2.1、回归损失函数
为了补偿l2-范数损失的尺度敏感性,YOLOv1通过对边界框的大小进行平方根变换来削弱大边界框的影响。YOLOv3提议构建一个惩罚项来降低大目标框的竞争力。然而,l2-范数损失忽略了边界框属性之间的相关性,使得这种类型的BBR损失的效果较差。
为了解决IoU损失的梯度消失问题,GIoU使用了由最小的封闭框构造的惩罚项。DIoU使用由距离度量构造的惩罚项,而CIoU是通过添加基于DIoU的高宽比度量得到的。而SIoU构建了具有角度惩罚、距离惩罚和形状惩罚的IOU损失,具有更快的收敛速度和更好的性能。
2.2、带有FM的损失函数
交叉熵损失在二值分类任务中被广泛地应用。然而,这个损失函数的一个显著特性是,即使是简单的样本也会产生很大的损失值,与困难的样本竞争。林等人提出了单调FM的focal loss,有效地降低了简单样本的竞争力。
在Focal-EIoU中,Zifan等人提出了非单调调频的 Focal-EIoU v1和单调调频的 Focal-EIoU v1。在实验中,单调调频比非单调调频是一个更好的选择。
Focal-EIoU v1的FM是静态的,它规定了anchor box的质量划分标准。当anchor box的IoU损失等于界值时,得到了anchor box的最高梯度增益。由于没有注意到anchor box的质量评价反映在相互比较中,因此它没有充分利用非单调调频的潜力。
3、本文方法
3.1 模拟实验
为了初步比较BBR的各损失函数,使用了DIOU中提出的模拟实验进行评价。以7个宽高比(即1:4、1:3、1:2、1:1、2:1、3:1、4:1)生成目标框(面积1/32)。在以半径为r的(0.5,0.5)为中心的圆形区域中,均匀产生 Anchor。同时,为每个Anchor放置49个7个比例(即1/32、1/24、3/64、1/16、1/12、3/32、1/8)和7个长宽比(即1:4、1:3、1:2、1:1、2:1、3:1、4:1)的anchor box。每个anchor box需要映射到每个目标框上,有个回归样本。为了比较不同时期的收敛速度,建立了以下实验环境:

-
r = 0.5,anchor box分布在目标框覆盖区域内外(图4a),对应于BBR中的所有情况。
-
r = 0.1,anchor box在目标框的覆盖范围内生成(图4b),对应于BBR中的主要情况。
作者还将损失值定义为整体回归情况,并使用梯度下降算法对其进行优化,学习率为0.01。
3.2 梯度消失问题的求解
1、DIoU
郑辉等将定义为两个边界框中心点之间的归一化距离:
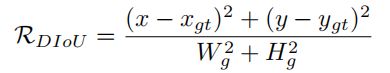
这个项不仅解决了的梯度消失问题,而且还可以作为一个几何因子。允许DIoU在面对具有相同的anchor box时做出更直观的选择。

同时,为最小的封闭盒的大小提供了一个负的梯度,这将使和增加,阻碍anchor box与目标框之间的重叠。然而,不可否认的是,距离度量确实是一个非常有效的解决方案,并成为SIOU的必要度量。在此基础上,张一凡等人增加了对距离度量的惩罚,并提出了EIoU:
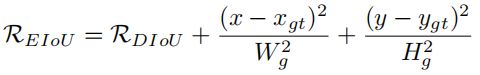
2、CIoU

在的基础上,郑辉等增加了高宽比的考虑,并提出了:

其中,描述了长宽比的一致性:
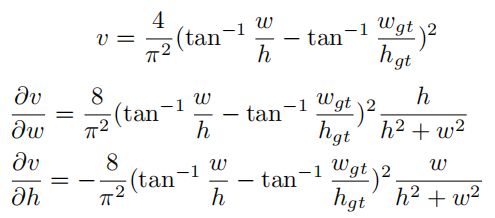
Yifan Zhang等人认为,DIoU的不合理之处在于,这意味着不能为anchor box的宽度w和高度h提供相同符号的梯度。在之前对DIoU的分析中,可以看出将产生负的梯度(方程式6)。当该负梯度恰好抵消了在anchor box上生成的梯度时,anchor box将不会被优化。CIoU对纵横比的考虑将打破这一僵局(图3b)。
3、SIoU
Zhora证明了中心对准anchor box具有更快的收敛速度,并根据角度成本、距离成本和形状成本构造了SIoU。
角度成本描述了中心点连接(图1)与x-y轴之间的最小角度:
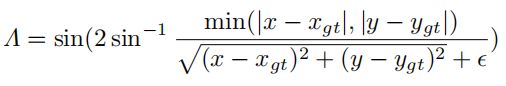
当中心点在x轴或y轴上对齐时,Λ = 0。当中心点连接到x轴45°时,Λ = 1。这一惩罚可以引导anchor box移动到目标框的最近的轴上,减少了BBR的总自由度数。
距离惩罚描述了中心点之间的距离,其惩罚代价与角度代价呈正相关。距离成本的定义为:
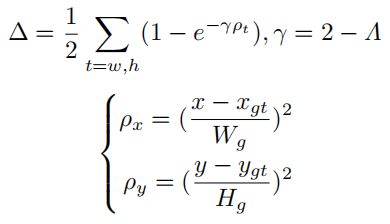
形状成本描述了边界框之间的大小差异。当边界框的大小不一致时,请使用Ω ≠ 0,并将其定义为:
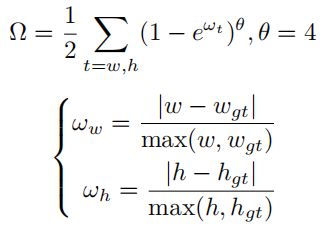
与相似,它们都包括距离成本和形状成本:
由于对距离度量的惩罚随着形状成本的增加而增加,因此由SIoU训练的模型具有更快的收敛速度和更低的回归误差。
3.3、本文方法

由于训练数据不可避免地包含低质量示例,几何因素(如距离和纵横比)将加重对低质量示例的惩罚,从而降低模型的泛化性能。当anchor box与目标盒很好地重合时,一个好的损失函数应该会削弱几何因素的惩罚,而较少的训练干预将使模型获得更好的泛化能力。基于此,我们构建了距离注意力(方程17),并获得了具有两层注意力机制的WIoU v1:
-
,这将显著放大普通质量anchor box的LIoU。
-
,这将显著降低高质量anchor box的,并在anchor box与目标框重合时,重点关注中心点之间的距离。
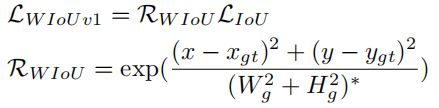
其中,、是最小封闭框的大小(图1)。为了防止产生阻碍收敛的梯度,和从计算图中分离出来(上标*表示此操作)。因为它有效地消除了阻碍收敛的因素,所以没有引入新的度量,例如纵横比。
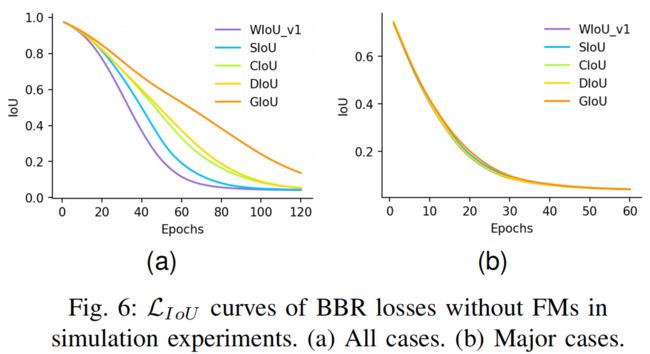
通过III-A中提到的模拟实验,比较了没有FMs的BBR损失的性能。从图6的结果中有以下观察结果:
-
在现有工作中提到的一系列BBR损失中,SIoU的收敛速度最快。
-
对于BBR中的主要情况,所有的BBR损失都具有极相似的收敛速率。由此可见,收敛速度的差异主要来自于非重叠的边界框。本文提出的基于注意力的WIoU v1在这方面的效果最好。
1、Learning from focal loss
focal loss为交叉熵设计了单调FM,这有效地减少了简单示例对损失值的贡献。因此,该模型可以专注于困难样本并获得分类性能改进。类似地,作者构造了的单调聚focusing系数。
由于focusing系数的增加,WIoU v2反向传播的梯度也发生了变化:

注意,梯度增益为。在模型的训练过程中,梯度增益随着的减小而减小,导致训练后期的收敛速度缓慢。因此,引入的平均值作为归一化因子:

其中是动量m的运行平均值。动态更新归一化因子将梯度增益保持在较高水平,这解决了训练后期收敛缓慢的问题。
2、Dynamic non-monotonic FM
anchor box的异常程度由与的比率表示:
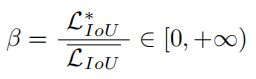
较小的异常度意味着anchor box质量较高。为其分配了一个小的梯度增益,以便将BBR聚焦在普通质量的anchor box上。此外,将小的梯度增益分配给具有大离群度的anchor box将有效地防止来自低质量样本的大的有害梯度。使用β构建非单调Focusing系数,并将其应用于WIoU v1:
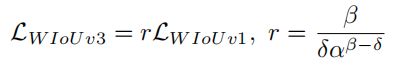
其中,当β=δ时,δ使r=1。如图8所示,当anchor box的离群度满足β=C(C为常数)时,anchor box将获得最高的梯度增益。由于是动态的,anchor box的质量分界标准也是动态的,这使得WIoU v3能够在每一刻都制定最符合当前情况的梯度增益分配策略。
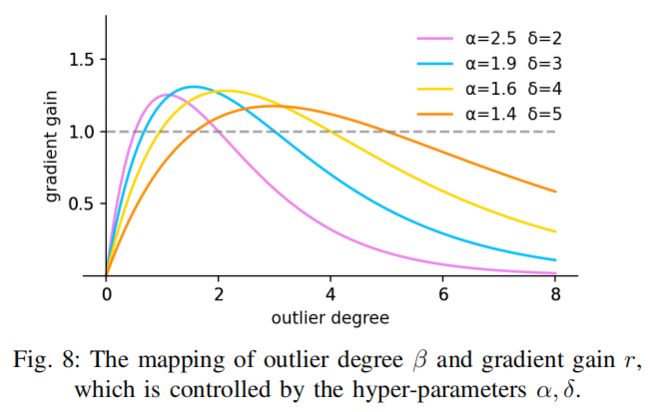
为了防止在训练的早期阶段留下低质量的anchor box,初始化=1,使=1的anchor box享有最高的梯度增益。为了在训练的早期阶段保持这种策略,有必要设置一个小的动量m,以延迟接近真实值的时间。对于数据批数为n的训练,我们建议将动量设置为:
该设置使训练t个阶段后的。
在训练的中后期,WIoU v3为低质量anchor box分配较小的梯度增益,以减少有害梯度。同时,它还专注于普通质量的anchor box,以提高模型的本地化性能。
4、实验
4.1、消融实验
将FMs应用于BBR损失,以研究FMs对附加损失的影响。这些BBR损失的版本2使用了γ = 0.5的设置,以与Focal-EIoU的单调FM对齐。
通过比较BBR损失的版本2和原始版本(表I),可以知道单调的FM对SIoU和EIoU的性能都有负面影响。由于这两种方法对距离度规的惩罚作用更强,因此在单调调频的作用下合成了更大的有害梯度。CIoU和WIoU v1对距离度量的惩罚较小,这使得它们有效地削弱了单调FM对有害梯度的放大。
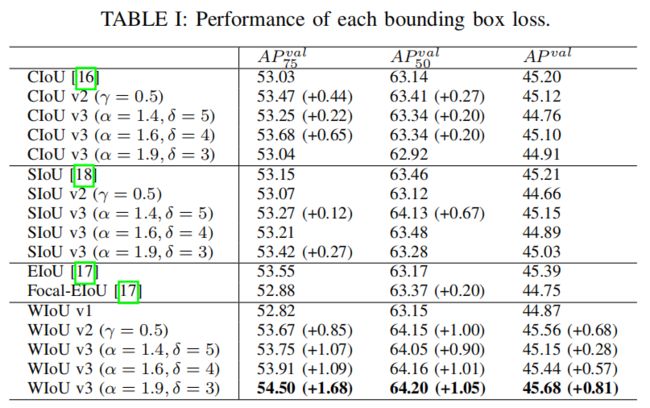
通过比较BBR损耗的版本3和原始版本(表I),可以知道非单调FM可以有效地提高BBR损失的性能。对于每个BBR损失,都有一组唯一的参数,可以最大化这种性能增益。
此外,还比较了anchor box的回归结果(图5)。具有单调FM的WIoU v2受到低质量样本的影响,导致预测结果较差,WIoU v3受益于动态非单调FM,它有效地屏蔽了低质量样本的影响,并实现了理想的预测。
4.2、消融实验分析
在表一中,BBR损失的原始版本的性能排名为:EIoU > SIoU > CIoU > WIoU v1。这样的命令也符合对距离度量的惩罚的强度。然而,当应用FMs时,BBR损失的性能增益的顺序则相反。在进行的实验中,由WIoU v3训练的模型取得了最好的性能。
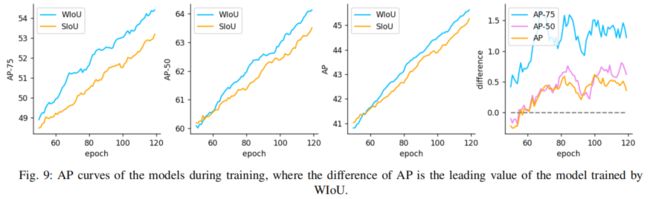
在训练过程中监测YOLOv7精度的变化(图9)。由于动态非单调调频,提出的WIoU v3在训练过程中有效地屏蔽了许多负面影响,因此模型的精度可以更快地提高。

将WIoU v3与最先进的BBR损失进行了比较,并获得了精度差异较大的几个类别(表II)。受益于识别低质量样本的能力,WIoU v3训练的模型大大提高了某些类别的精度。同时,该模型对飞机和长椅的精度也有所下降。

作者注意到,一些飞机的标签存在争议(图7),而一些被选择的飞机缺乏突出的特征,如机身。这些例子和低质量的样本一样难以学习,而这部分困难的样本被WIoU v3的FM抛弃了。此外,在板凳的标签上有大量的错误,也有大量的板凳没有被标注。这对于能够很好地推广和检测到更多长凳的模型来说是不公平的。
在有限的参数下学习适当的知识是实时探测器成功的关键。WIoU v3通过权衡对低质量样本和高质量样本的学习情况,提高了模型的整体性能。
5、参考
[1].Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism.