Python爬虫&Excel&Tableau可视化数据分析
数据分析【1】
- 项目介绍
-
- 技术背景
- 数据说明
- 数据获取---Python爬虫
- 数据分析---Excel
-
- Excel数据分析总结
- 数据分析---Tableau
- 总结
项目介绍
本次项目是我个人学习之后的实战项目,应该会分为几个阶段对应自己学习的进度,主要是做关于数据分析的,包括数据获取、可视化分析、预测等等。本篇文章是在学习了Python、Excel、Tableau等相关技术后对淘宝软件进行爬虫华为和vivo两款手机的销售数据并进行可视化分析。
技术背景
- 数据来源:淘宝网
- 数据获取:Python爬虫及Selenium自动化测试
- 可视化分析:Excel、Tableau
数据说明
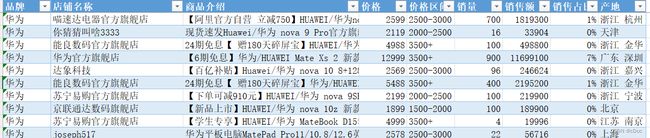
本次爬取所得的数据有些粗糙,共1800+条数据,包括了vivo和华为手机的部分销售数据,话不多说,直接上图:
数据获取—Python爬虫
本来想上网查找数据进行简单的可视化分析就行了的,但是发现没有合适,数据就是金钱啊!那就爬!由于需要爬取多条数据,人为的手动分析爬取可行性并不是很高,所以引用了Selenium自动化测试模块,需要注意的就是chromedriver的下载和路径的配置,网上很多教程,自行搜索即可。
首先来分析一下页面数据,F12打开开发者工具,就会发现所有的数据都是在一个items标签下,再往下看,就会发现所有想要的数据都会有一个标签或者父标签,当然,你选择其他标签也是可以的,根据自己的需求改就行,如下图:
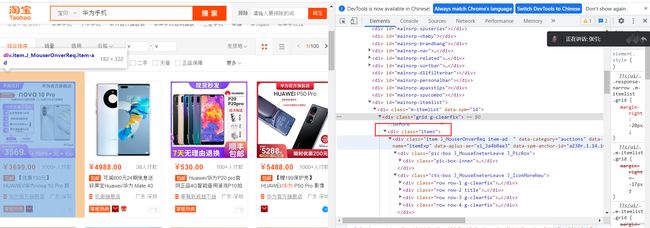
接下来,不需要重复造轮子(当然前提是你懂了)直接上代码:
# 导入模块
from selenium import webdriver
import time
import csv
import re
from selenium.webdriver.common.by import By
# 搜索商品,获取商品页码
def search_product(key_word):
key_word += "手机"
# 定位输入框
browser.find_element(By.ID, "q").send_keys(key_word)
# 定义点击按钮,并点击
browser.find_element(By.CLASS_NAME, 'btn-search').click()
# 最大化窗口:为了方便我们扫码登录淘宝
browser.maximize_window()
# 等待15秒,给足时间我们扫码登录
time.sleep(15)
# 定位这个商品“页码”,获取到“共100页“这个文本
page_info = browser.find_element(By.XPATH, '//div[@class="total"]').text
# 需要注意的是:findall()返回的是一个列表,虽然此时只有一个元素它也是一个列表。
page = re.findall("(\d+)", page_info)[0]
print(key_word + "有" + str(page) + "页信息,请问需要爬取多少页?")
page = int(input("请输入需要爬取的页面: "))
return page
# 获取商品信息数据
def get_data():
# 通过页面分析发现:所有的信息都在items节点下
items = browser.find_elements(By.XPATH, '//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for item in items:
# print(item)
# 店铺名称
shop_name = item.find_element(By.XPATH, './/div[@class="shop"]').text.strip()
# 参数信息
pro_desc = item.find_element(By.XPATH, './/div[@class="row row-2 title"]/a').text
# 价格
pro_price = item.find_element(By.XPATH, './/strong').text
# 付款人数
buy_num = item.find_element(By.XPATH, './/div[@class="deal-cnt"]').text[:-3]
# 简单的处理销售人数格式
if "+" in buy_num:
buy_num = buy_num.replace("+", "")
# 地区
location = item.find_element(By.XPATH, './/div[@class="location"]').text
# 保存到csv文件
with open('{}手机.csv'.format(key_word), mode='a', newline='', encoding='utf-8-sig') as f:
csv_writer = csv.writer(f, delimiter=',')
csv_writer.writerow([shop_name, pro_desc, pro_price, buy_num, location])
def main():
# 浏览器要获取的链接
browser.get('https://www.taobao.com/')
# 要获取的关键字
page = search_product(key_word)
print("开始爬取:")
page_num = 0
while page != page_num:
print("*" * 60)
print("正在爬取第{}页".format(page_num + 1))
# 爬取页面
browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_num * 44))
browser.implicitly_wait(15)
get_data()
page_num += 1
print(key_word + "手机数据爬取完毕!")
if __name__ == '__main__':
key_word = input("请输入你要搜索的手机品牌:(输入Q/q停止)")
while key_word != 'Q' and key_word != 'q':
browser = webdriver.Chrome()
main()
key_word = input("请输入你要搜索的手机品牌:(输入Q/q停止)")
当然,你也可以选择点击进每个手机主页,获取它更加详细的信息,包括购买时间、评论等等,但是那么多条数据,一个一个点进手机主页,想想就应该很吃电脑性能,所以……不过,这也是我下一个阶段要解决的事情,可以期待一下。
数据分析—Excel
获取数据了之后就应该是数据分析了(应该还有数据清理这些的,但是咱们这个数据比较简单,我经过简单的处理就可以直接用了),这次是先用Excel进行数据分析,其实用Excel做数据报表的可能会多一些,咱们这次就简单做一做,巩固知识。
大家做数据分析之前,要养成一个保存源数据的良好习惯。这次的Excel数据分析,我用的大多是函数编写,用数据透视表分析也可以,根据自己的需求来,学习阶段,咱们尽量用自己学习的知识来进行实践,打好基础,后续偷懒更方便。我做的功能包括一个联动筛选,会根据源数据或者你所选择的数据变化而变化,还有Sumprodunct的多条件求和、Index+Small+If+Row一对多函数查询显示多结果【这个会很影响电脑性能,后续会改进】等等。实现了就不同品牌在销量、营收额、不同产品价格区间受欢迎程度及爆款机型等各方面进行对比分析。说着比较抽象,直接上图讲解!
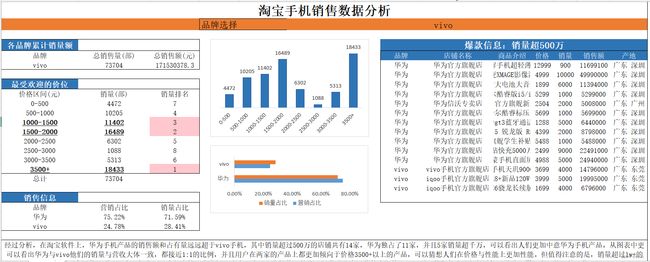
它会根据品牌的选择实现联动筛选。
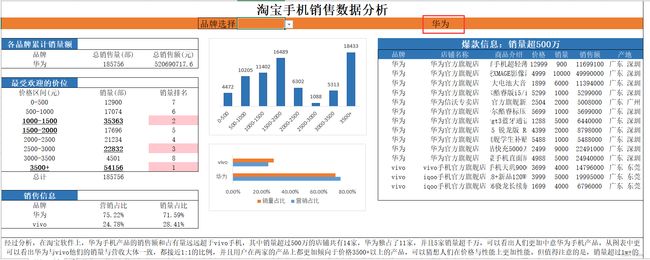
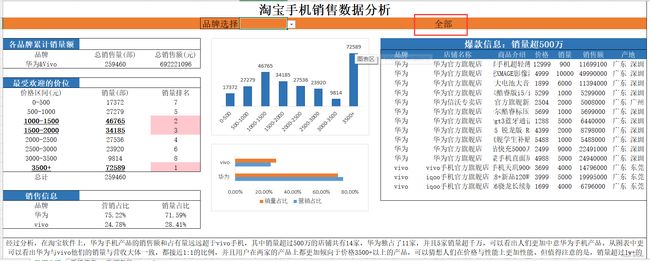
Excel的数据分析主要就是函数的嵌套使用,根据自身的需求结合不同的函数能够得到不一样的结果,最常见的有vlookup、sumproduct、sumif、index+match等,有不会的直接百度都能出来。主要是熟悉Excel各个功能的使用,对数据进行合适的可视化分析。
Excel数据分析总结
通过以上图表可以看出,在淘宝软件上,华为手机产品无论是在销售额上还是占有量上都远远超于vivo手机品牌。其中销量超过500万的店铺共有14家,华为独占了11家,并且5家销量超千万,可以看出人们更加中意华为手机产品,也可以猜想华为手机产品可能在性价比、售后服务等方面优于Vivo手机品牌。从图表中更可以看出华为与vivo他们的销量与营收大体一致,都接近1:1的比例,并且用户在两家的产品上都更加倾向于价格3500+以上的产品,但是3000-3500价位的机型销量几乎倒数,可以猜想人们在价格与性能上更加倾向性能较好的产品。但值得注意的是,销量超过1w+的机型只有一款,说明两家手机产品还有很大的进步空间,应该打造更具有性价比的产品,营造多点开花的市场格局。同时,他们都应该扬长避短,铸造出属于自己的品牌文化。
数据分析—Tableau
个人认为在可视化分析上,Tableau更优于Excel,更加简单便捷,当然两者要结合场景来使用,发挥其优势。在Tableau的数据分析中,我主要是实现了两个品牌全国不同产地的销量分布、官方店铺和第三方店铺销售额对比分析、价位销量分析、不同品牌销售额占比及各个机型价位的对比分析。有些地方会与Excel分析重复,因为我最初是按照两个软件单独实现分析来做的。
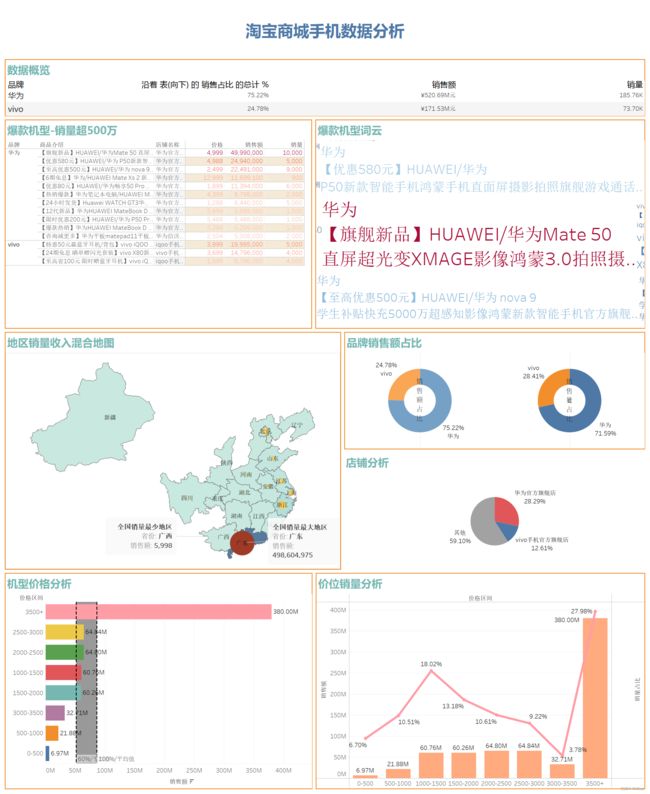
上图是Tableau数据分析的一个仪表盘,可以更直观的看出两个品牌数据分析的各个分析结果。
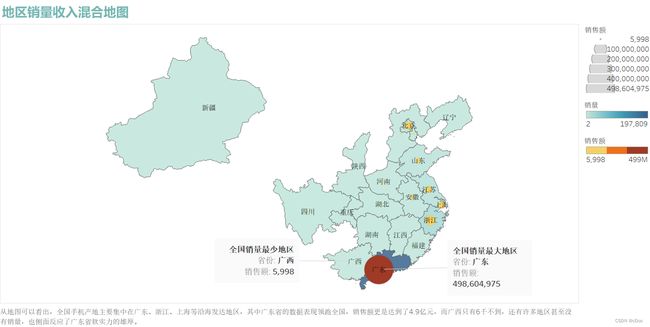
从上混合地图可以看出,全国手机产地主要集中在广东、浙江、上海等沿海发达地区,其中广东省的数据表现领跑全国,销售额更是达到了4.9亿元,而广西只有6千不到,还有许多地区甚至没有销量,也侧面反应了广东省软实力的雄厚。
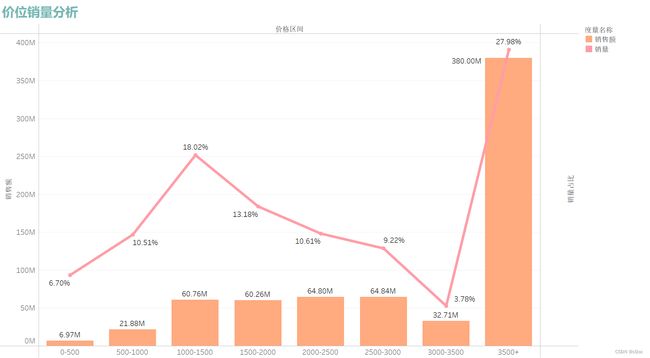
从上图可以看出用户在产品上更加倾向于价格3500+以上的产品,但是3000-3500价位的机型销量几乎倒数,可以猜想人们在价格与性能上更加倾向性能较好的产品。
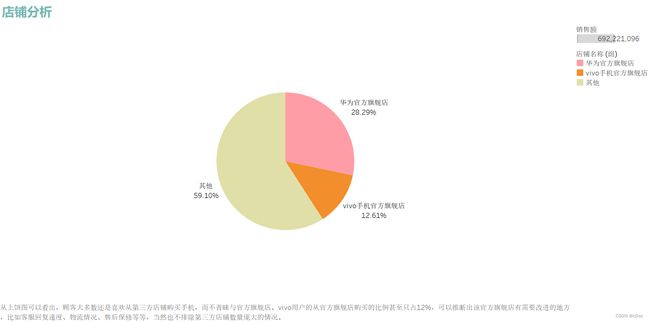
从上饼图可以看出,顾客大多数还是喜欢从第三方店铺购买手机,而不青睐与官方旗舰店。vivo用户的从官方旗舰店购买的比例甚至只占12%,可以推断出该官方旗舰店有需要改进的地方,比如客服回复速度、物流情况、售后保修等等,当然也不排除第三方店铺数量庞大的情况。

这是利用销量超500万机型做的一个爆款机型词云,可以看出最受欢迎的是华为Mate50手机。可以用Python来做这个词云会更好一些。
总结
这次的数据分析可以看出华为与vivo两款品牌在销量、爆款机型、用户不同价位的选择及不同地区销售额等方面的差距与相关信息,也表明了两家手机品牌在不同方面存在的问题,比如官方店铺占有量为啥远远少于第三方店铺、不同机型营销差距为何那么大等,他们应该打造更具有性价比的产品,营造出多点开花的市场格局。同时,铸造出属于自己的品牌文化。
最后我想说的是无论是Excel、Tableau还是Python也好,他们都只是一门工具,你熟练掌握他只是为了更好的实现业务需求,更重要的是分析数据的思维能力,这个是区分你能力的主要指标。
当然,这次数据分析还有很多值得优化的地方,后期也会不断的持续更新,欢迎关注!