学习备忘录--语义分割比赛
hairlessman的学习备忘录(1)–图像语义分割比赛
寒假期间太无聊了,本着闲着也是闲着的态度,参加了天池的一个语义分割相关的比赛,初赛A榜当时在4000多个队里排120多名,再努努力本应该可以进复赛。
但是开学之后有别的学习任务,并且买基金赔的稍微有点多,舍不得再租服务器了,只好作罢。
反正能学一点是一点,写个文章做一下备忘。也希望相关领域的专业人士可以多教教我,毕竟是刚刚入门,论文是自己找的,pytorch是现学的,很多东西都不太会。
1.赛题
本赛题基于不同地形地貌的高分辨率遥感影像资料,希望参赛者能够利用遥感影像智能解译技术识别提取土地覆盖和利用类型,实现生态资产盘点、土地利用动态监测、水环境监测与评估、耕地数量与监测等应用。结合现有的地物分类实际需求,参照地理国情监测、“三调”等既有地物分类标准,设计陆域土地覆盖与利用类目体系,包括:林地、草地、耕地、水域、道路、城镇建设用地、农村建设用地,工业用地、构筑物、裸地。
训练数据是256*256的四通道遥感图像,标注数据是单通道的灰度图像,对标注数据进行可视化后如下图:
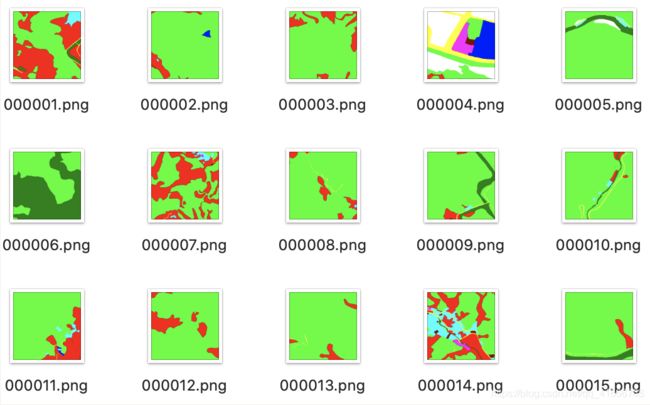
每种颜色都代表不同的类别。
2.模型选择
在图像语义分割的任务中,最常用的模型就是deeplab以及Unet。
deeplab采用了空洞卷积金字塔技术,具体结构如下图:

而Unet的结构如下:
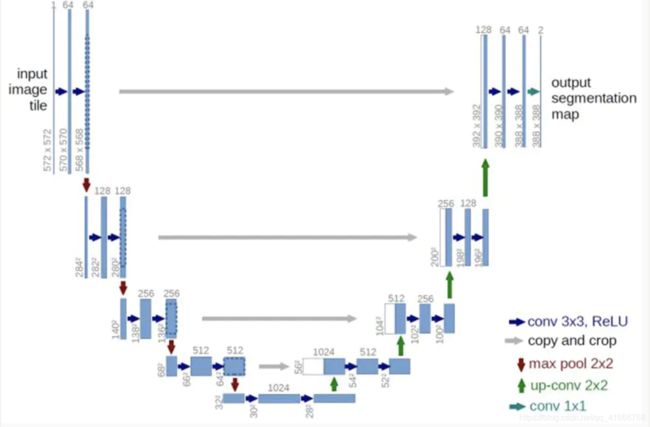
想更进一步了解还是得去看论文,不过从经验来说,deeplab的分割效果更好,边缘更加光滑,但是相应的其训练的速度也比较慢,所以在算力资源有限的情况下,选择Unet还是操作性更高一点。
3.数据增强
(1)随机翻转、线性拉伸
这两种都是比较常规的增强方式,具体实现如下:
# 截断线性拉伸,用于调整图像亮度
def truncated_linear_stretch(image, truncated_value, max_out = 255, min_out = 0):
#对单一通道进行处理
def gray_process(gray):
#np.percentile:计算一个多维数组的任意百分比分位数
truncated_down = np.percentile(gray, truncated_value)
truncated_up = np.percentile(gray, 100 - truncated_value)
#进行灰度变换
gray = (gray - truncated_down) / (truncated_up - truncated_down) * (max_out - min_out) + min_out
#截取数组中[min_out,max_out] 之间的部分
gray = np.clip(gray, min_out, max_out)
gray = np.uint8(gray)
return gray
image_stretch = []
#对每一个通道进行拉伸
for i in range(image.shape[2]):
gray = gray_process(image[:,:,i])
image_stretch.append(gray)
image_stretch = np.array(image_stretch)
image_stretch = image_stretch.swapaxes(1, 0).swapaxes(1, 2)
return image_stretch
# 随机数据增强
# image 图像
# label 标签
def DataAugmentation(image, label):
hor = random.choice(['yes', 'no'])
if(hor == 'yes'):
# 图像水平翻转
image = np.flip(image, axis = 1)
label = np.flip(label, axis = 1)
ver = random.choice(['yes', 'no'])
if(ver == 'yes'):
# 图像垂直翻转
image = np.flip(image, axis = 0)
label = np.flip(label, axis = 0)
stretch = random.choice(['yes', 'no'])
if(stretch == 'yes'):
# 50%线性拉伸
image = truncated_linear_stretch(image, 0.5)
return image, label
(2)添加NDVI(归一化植被指数)
这次比赛所给的图像是四通道的遥感影像,除了传统的RGB三个通道之外,还有nir通道,也就是近红外光谱值。
但是论坛上的很多人在处理数据时直接把nir通道去掉,用他们以前处理普通RGB图像的框架来处理遥感图像,个人认为这样对数据的利用不是很充分。
于是我在网上搜索了一些遥感图像处理的相关内容,发现了有一个叫做归一化植被指数(NDVI)的指标,该指标是指遥感影像中,近红外波段的反射值与红光波段的反射值之差比上两者之和,即(NIR-R)/(NIR+R)。
NDVI的范围在[-1,1]之间,负值表示地面覆盖为云、水、雪等,对可见光高反射;0表示有岩石或裸土等,NIR和R近似相等;正值,表示有植被覆盖,且随覆盖度增大而增大。在训练数据集中,有一部分图像是在冬季拍摄的,植被表面有雨雪覆盖,而NDVI刚好对土壤背景比较敏感,个人猜想增加这个参数可以使模型泛化能力更好。
于是我反其道而行之,没有去掉nir通道,而是添加了NDVI通道,将四通道图像拓展为五个通道。
具体代码如下:
def imgread(fileName, addNDVI):
#使用gdal读取图像
dataset = gdal.Open(fileName)
width = dataset.RasterXSize
height = dataset.RasterYSize
data = dataset.ReadAsArray(0, 0, width, height)
if(len(data.shape) == 3):
if(addNDVI):
#读取nir以及r通道,并计算NDVI
nir, r = data[3], data[0]
ndvi = (nir - r) / (nir + r + 0.00001) * 1.0
# 和其他波段保持统一,归一到0-255,后面的totensor会/255统一归一化
ndvi = (ndvi - (-1)) / (1 - (-1)) * 255
#将ndvi作为第五个通道加入到图像中
data_add_ndvi = np.zeros((5, 256, 256), np.uint8)
data_add_ndvi[0:4] = data
data_add_ndvi[4] = np.uint8(ndvi)
data = data_add_ndvi
# (C,H,W)->(H,W,C)
data = data.swapaxes(1, 0).swapaxes(1, 2)
return data
(3)RICAP(random image crop and patch)
这种方式简言之就是就是截取不同图像的不同部分,再把他们拼接起来。如下图,就是选了四张图像进行RICAP的结果:

可以看到该图片有着明显的拼接痕迹,但是实验结果证明,在DCNN网络中,这样的数据增强方式具有很好的效果。尽管这过程很简单,但是RICAP大幅度增加了图像的多样性,并防止了深度CNN具有许多参数的过拟合。具体实现如下:
if(RICAP):
#random image crop and patch
#图像的长和宽
I_x,I_y = image.size()[2:]
#随机取图的长和宽
w = int(np.round(I_x * np.random.beta(ricap_beta, ricap_beta)))
h = int(np.round(I_y * np.random.beta(ricap_beta, ricap_beta)))
#存起来方便拼接
w_ = [w, I_x - w, w, I_x - w]
h_ = [h, h, I_y - h, I_y - h]
#存储剪切后的图像
cropped_images = {}
#c里存target,W里存切出来的图的占比
c_ = {}
W_ = {}
for k in range(4):
idx = torch.randperm(image.size(0))#image.size(0)=16
x_k = np.random.randint(0, I_x - w_[k] + 1)
y_k = np.random.randint(0, I_y - h_[k] + 1)
cropped_images[k] = image[idx][:, :, x_k:x_k + w_[k], y_k:y_k + h_[k]]
c_[k] = target[idx].cuda()
W_[k] = w_[k] * h_[k] / (I_x * I_y)
#把图像拼接起来
patched_images = torch.cat(
(torch.cat((cropped_images[0], cropped_images[1]), 2),
torch.cat((cropped_images[2], cropped_images[3]), 2)),
3)
patched_images = patched_images.cuda()
4.训练的trick
(1)余弦退火调整学习率
上学期学了《最优化算法》这门课程,初步了解了一下退火算法。简而言之,余弦退火就是让学习率做类似于cos函数的变化。计算方法如下:

随着epoch的增加,learning rate 先急速下降,再陡然提升,然后不断重复这个过程。其目的是为了是模型有能力跳出局部最优解,继续搜索全局最优解。学习率的变化如下图:
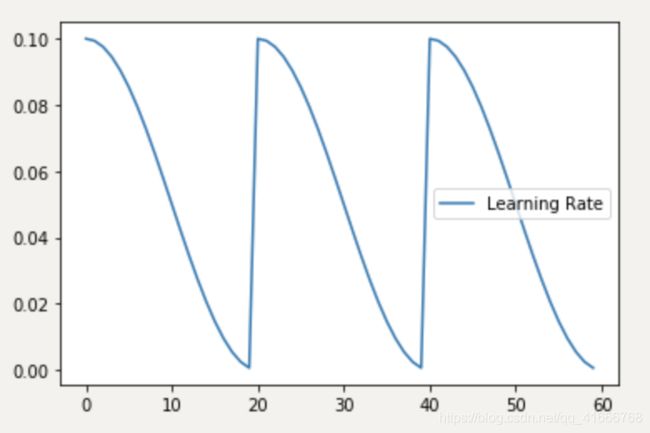
pytorch中的torch.optim.lr_scheduler.CosineAnnealingWarmRestarts类给出了实现,可以直接用。
(2)随机加权平均(STOCHASTIC WEIGHT AVERAGING)
集成的方式通常可以获得更好的泛化效果,传统的集成方法是集成几种不同的模型,再用相同的输入进行预测,然后使用某种平均方法来确定集成模型的最终预测。但是这样的话就需要去训练多个模型 ,在时间以及算力上都是一个不小的消耗。
为了避免训练多个模型带来的时间消耗,同时又想达到模型集成的效果,康奈尔大学的Pavel Izmailov团队在18年的一项工作中提出了STOCHASTIC WEIGHT AVERAGING(简称SWA)。
简单来说,就是对训练过程中的多个checkpoints进行平均,以提升模型的泛化性能。
一般情况下,我们会选择训练的最后一个epoch,或者是在验证集上表现最好的那一个epoch的模型参数,作为最终的模型参数,但SWA一般在最后采用较高的固定学习速率或者周期式学习速率额外训练一段时间,取多个checkpoints的平均值作为最终的模型。
具体做法是:前75%的时间使用标准的衰减学习速率策略训练,然后剩余25%设置一个合理的固定学习速率进行训练,或者在每个epoch采用周期式的学习速率策略来训练。最后平均第二阶段每个epoch的weights。
而关于SWA为什么有效,论文也给出了简单的解释,如下图:

由于模型的参数属于高维空间,使用SGD训练的模型往往都会收敛到全局最优解的边界,如图一所示,对他们进行平均是可以更加接近最优解的。图二以及图三说的是训练误差和测试误差往往不对齐,那么平均的话其实是可以提升泛化性能的。
pytorch中的AverageModel类已经实现了SWA,注释中也给出了使用示例,用起来很方便:
loader, optimizer, model, loss_fn = ...
swa_model = torch.optim.swa_utils.AveragedModel(model)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,
T_max=300)
swa_start = 160
swa_scheduler = SWALR(optimizer, swa_lr=0.05)
for i in range(300):
for input, target in loader:
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
if i > swa_start:
swa_model.update_parameters(model)
swa_scheduler.step()
else:
scheduler.step()
# Update bn statistics for the swa_model at the end
torch.optim.swa_utils.update_bn(loader, swa_model)
(3)交叉熵以及DiceLoss的混合损失函数
多类别的语义分割任务一般使用交叉熵,也就是CrossEntropy作为损失函数,但是该损失函数在类别不平衡的情况下表现并不是太好。而此次比赛的训练数据就是类别非常不均衡(如图),因此需要选择合适的损失函数。
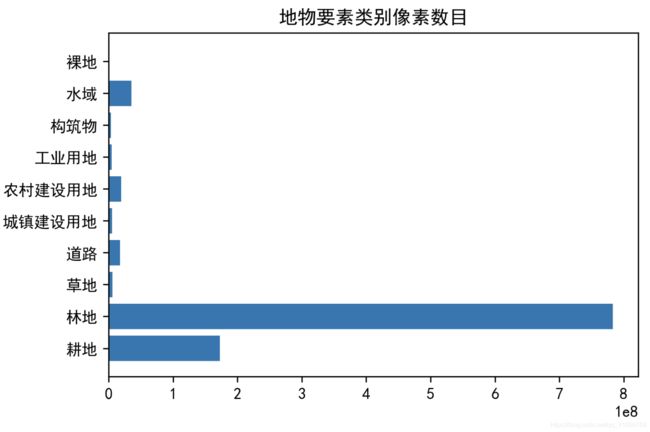
DiceLoss是解决类别不平衡的方式之一。
Dice系数是分割效果的一个评判指标,其公式相当于预测结果区域和ground truth区域的交并比,所以它是把一个类别的所有像素作为一个整体去计算Loss的。因为Dice Loss直接把分割效果评估指标作为Loss去监督网络,不绕弯子,而且计算交并比时还忽略了大量背景像素,解决了正负样本不均衡的问题,所以收敛速度很快。Diceloss在一定程度上可以缓解类别不平衡,但是训练容易不稳定。
在训练中,采用软交叉熵函数和diceloss的联合函数作为实验的损失函数:
DiceLoss_fn=DiceLoss(mode='multiclass')
# 软交叉熵,即使用了标签平滑的交叉熵,会增加泛化性
SoftCrossEntropy_fn=SoftCrossEntropyLoss(smooth_factor=0.1)
loss_fn = L.JointLoss(first=DiceLoss_fn, second=SoftCrossEntropy_fn,
first_weight=0.5, second_weight=0.5).cuda()
5.TTA
测试时对原图像、水平翻转图像、垂直翻转图像的预测结果进行平均,得到TTA结果。可以得到泛化性更好的结果。一定程度上缓解过拟合。
#TTA(测试时增强)
for image,image_path in test_loader:
with torch.no_grad():
image = image.cuda()
#(batchsize,10,256,256)
#直接预测
predict_1 = model(image)
# 水平翻转预测,再翻转回来
predict_2 = model(torch.flip(image,[-1]))
predict_2 = torch.flip(predict_2,[-1])
# 垂直翻转预测,再翻转回来
predict_3 = model(torch.flip(image,[-2]))
predict_3 = torch.flip(predict_3,[-2])
# 水平垂直翻转预测,再翻转回来
predict_4 = model(torch.flip(image,[-1,-2]))
predict_4 = torch.flip(predict_4,[-1,-2])
#将上述预测结果相加
predict_list = (predict_1 + predict_2 + predict_3 + predict_4).cpu().data.numpy()
for i in range(predict_list.shape[0]):
pred = predict_list[i]
#pred.shape = (10,256,256),取最大概率的类别
pred = np.argmax(pred, axis = 0) + 1
pred = np.uint8(pred)
save_path = os.path.join(output_dir, image_path[i][-10:].replace('.tif', '.png'))
print(save_path)
cv2.imwrite(save_path, pred)
6.参考资料
【1】Averaging Weights Leads to Wider Optima and Better Generalization
【2】DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs
【3】Rethinking Atrous Convolution for Semantic Image Segmentation
【4】Data Augmentation using Random Image Cropping and Patching for Deep CNNs
【5】Averaging Weights Leads to Wider Optima and Better Generalization
【6】Fully Convolutional Networks for Semantic Segmentation