图的最小生成树:Kruskal算法--并查集的经典应用,解决连通性问题
图的最小生成树:Kruskal算法–并查集的经典应用,解决连通性问题
提示:系列图的文章
提示:大厂笔试面试都可能不咋考的数据结构:图
由于图的结构比较难,出题的时候,很难把这个图的数据搞通顺,而且搞通顺了题目也需要耗费太多时间,故笔试面试都不会咋考
笔试大厂考的就是你的贪心取巧策略和编码能力,这完全不必用图来考你,其他的有大量的选择
面试大厂考你的是优化算法的能力,但是图没啥可以优化的,只要数据结构统一,它的算法是固定死的,所以不会在面试中考!
万一考,那可能都是大厂和图相关的业务太多,比如美团高德地图啥的,这种考的少。
但不管考不考,我们要有基础,要了解图的数据结构和算法。万一考了呢,准备以备不时之需。
图的数据结构比较难,算法是固定的套路
咱们需要统一一种自己熟悉的图的数据结构,方便套用算法时好写!!
下面是咱们得关于图的重要基础知识和重点应用:
(1)图数据结构,图的统一数据结构和非标准图的转化算法
(2)图的宽度优先遍历:BFS遍历
(3)图的深度优先遍历:DFS遍历
有了这些基础知识,咱就可以破解图的题目了
(4)图的拓扑排序:图的BFS的应用题
文章目录
- 图的最小生成树:Kruskal算法--并查集的经典应用,解决连通性问题
-
- @[TOC](文章目录)
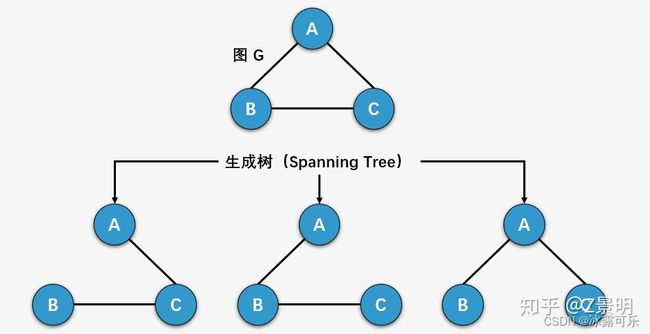
- 生成树的定义
- 本题的图结构:Graph
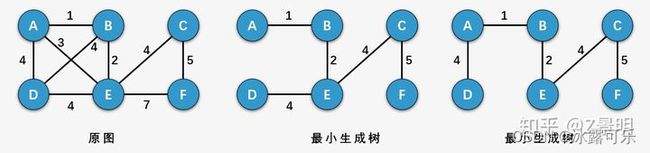
- 什么是最小生成树?
- Kruskal算法:生成最小生成树的边集合:并查集解决连通性
- 总结
文章目录
- 图的最小生成树:Kruskal算法--并查集的经典应用,解决连通性问题
-
- @[TOC](文章目录)
- 生成树的定义
- 本题的图结构:Graph
- 什么是最小生成树?
- Kruskal算法:生成最小生成树的边集合:并查集解决连通性
- 总结
生成树的定义
一个连通图的生成树是一个极小的连通子图,它包含图中全部的n个顶点,但只有构成一棵树的n-1条边。
本题的图结构:Graph
就是统一的丰富图结构表示法:
这个文章必须看透:
这个文章必须看透:
这个文章必须看透:
(1)图数据结构,图的统一数据结构和非标准图的转化算法
//这里就不得不复习一下图的结构,左神标准的结构
//边结构
public static class Edge{
public Node from;
public Node to;//源节点和目的节点
public int weight;//边的权
public Edge(int w, Node f, Node t){
weight = w;
from = f;
to = t;
}
}
//点结构
public static class Node{
public int value;//值,这种图已经有了的,并查集就不不要包装了
public int in;
public int out;
public ArrayList<Node> nexts;//直接邻居一堆动态数组节点
public ArrayList<Edge> edges;//直接邻居的边,动态数组,一堆,个图一样
public Node(int v){
value = v;
in = 0;
out = 0;
nexts = new ArrayList<>();
edges = new ArrayList<>();
}
}
//图结构
public static class Graph{
public HashMap<Integer, Node> nodes;//图的一堆节点,包出来了,并查集就不用包了
public HashSet<Edge> edges;//图的一堆边
public Graph(){
nodes = new HashMap<>();
edges = new HashSet<>();
}
}
//建图的标准函数
//这个主要是标准的左神图结构,这个玩意用来规整最明了简洁的图结构,方便实现很多图的算法
public static Graph generateGraph(int[][] matrix){
if (matrix == null || matrix.length == 0) return null;
//无非就是构造一堆图节点,将节点们的参数初始化,边,边的参数初始化
//一般图结构是二维数组:matrix,第一列是权,第二列:from节点,第三列:to节点
//int[][] matrix = {
// {1,1,2},
// {2,2,3},
// {3,1,3}
// };
Graph graph = new Graph();
for (int i = 0; i < matrix.length; i++) {
//每一行,读出来,构造节点
int weight = matrix[i][0];
int from = matrix[i][1];
int to = matrix[i][2];
//造节点,图中没有才造,否则不必---不然就要出问题,多造一些节点,导致混乱
//****************这里出过大错!!!
if (!graph.nodes.containsKey(from)) graph.nodes.put(from, new Node(from));
if (!graph.nodes.containsKey(to)) graph.nodes.put(to, new Node(to));
//获取节点
Node fromNode = graph.nodes.get(from);
Node toNode = graph.nodes.get(to);
//造边
Edge edge = new Edge(weight, fromNode, toNode);
graph.edges.add(edge);
toNode.in++;
fromNode.out++;
fromNode.nexts.add(toNode);
fromNode.edges.add(edge);
}
//每一行都建好,返回图即可
return graph;
}
//这些结构需要多写几遍,才能熟悉,记住,跟奥运健儿一样,多练习,才能稳定发挥
什么是最小生成树?
所谓一个 带权图 的最小生成树,就是原图中边的权值最小的生成树 ,
所谓最小是指边的权值之和小于或者等于其它生成树的边的权值之和。
Kruskal算法:生成最小生成树的边集合:并查集解决连通性
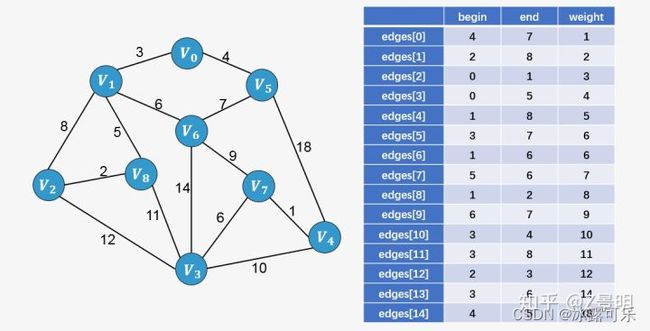
克鲁斯卡尔算法(Kruskal)是一种使用贪心方法的最小生成树算法。
该算法初始将图视为森林,图中的每一个顶点视为一棵单独的树。
一棵树只与它的邻接顶点中权值最小且不违反最小生成树属性(不构成环)的树之间建立连边。
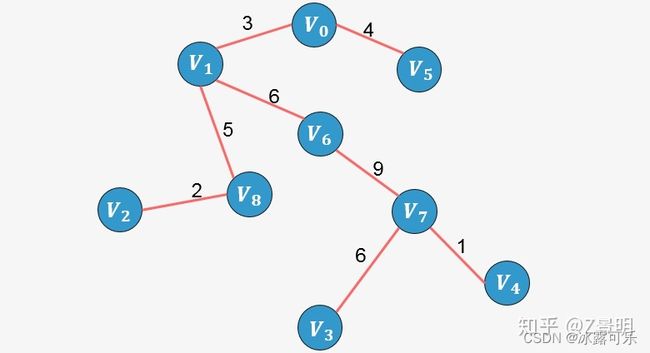
咱们的目标就是每次找最小那个权重边来合并两个节点,所在的集合【并查集干的事情】
最后将小边包含的所有节点,连通在一个集合中,这些边的集合就是咱们要的最小生成树。
Kruskal算法咋做呢?关键是并查集!
(1)将图中所有的边放入小根堆heap,这个堆heap,把边门按照权值进行升降序排列;
这需要比较器:
//注意,K算法要用小根堆,需要默认的权重按照升序排列
//比较器
public static class heapComparator implements Comparator<Edge>{
@Override
public int compare(Edge o1, Edge o2){
return o1.weight - o2.weight;
}
}
(2)把图中所有的节点,灌入并查集,并生成并查集UnionSet
关于并查集,这个文章必须看透彻,才能生成咱们得并查集:
关于并查集,这个文章必须看透彻,才能生成咱们得并查集:
关于并查集,这个文章必须看透彻,才能生成咱们得并查集:
解决连通性问题的利器:并查集
咱的并查集,不需要value和节点圈包装,因为节点已经存在了
//在写K算法前,我们还得自己定义一个合适的并查集,这样才能完成K算法的查,并操作
public static class UnionSet{
//参数,一般并查集是三张表,一张用来包int为Node
//一张用来装Node的代表Node
//一张用来并查集的Node代表的节点个数int
//但是图,本身自己就有nodes,它就是int包出来的Node,故在这我们直接操作Node即可,不再单纯操作value
//参数
public HashMap<Node, Node> parents;
public HashMap<Node, Integer> sizeMap;
//初始化
public UnionSet(){
parents = new HashMap<>();
sizeMap = new HashMap<>();
}
//建并查集,实际就是和初始化一样的函数,参数,是图中的一堆节点
//collection即集合,类型Node
public void makeUnionSet(Collection<Node> nodes){
//操作每一个节点,将其父定义为自己,size为1
for(Node node:nodes){
parents.put(node, node);//目前自己代表自己
sizeMap.put(node, 1);
}
}
//查一个节点的代表,即父findFather,同时将所有的节点挂在代表上,
public Node findFather(Node a){
if (a == null) return null;
Stack<Node> path = new Stack<>();
while (parents.get(a) != a){
//没有找到代表
path.push(a);
a = parents.get(a);
}
//直到找到了a的代表,目前是a,将沿途节点挂到a上
while (!path.isEmpty()){
parents.put(path.pop(), a);
}
return a;
}
//查俩节点是否同属一个集合,联通的?isSameSet
public boolean isSameSet(Node a, Node b){
return findFather(a) == findFather(b);
}
//将俩节点直接联通在一起,union--小挂大
public void union(Node a, Node b){
//找代表,求size,以小挂大
Node aHead = findFather(a);
Node bHead = findFather(b);
//注意,得他们的代表不同,才去挂
if (aHead != bHead){
int aSize = sizeMap.get(aHead);
int bSize = sizeMap.get(bHead);
Node big = aSize >= bSize ? aHead : bHead;
Node small = big == aHead ? bHead : aHead;
//改
parents.put(small, big);
sizeMap.put(big, aSize + bSize);//大的点更新size
sizeMap.remove(small);//小的那个点抹掉
}
//如果他们同属一个集合就不必合并了
}
}
(3)从heap中选择最小权那个边,直接弹出,即从图中所有的边中选择可以构成最小生成树的那个最小边。
检查,这个边的from节点和to节点,是否在同一个集合中?
不在?那就合并集合,并加入这个边为结果ans中
回到(3);搞定所有的边,最终就得到了结果ans。
懂了这个思想,有了统一的图结构,有了并查集,就知道K算法咋写了。
public static ArrayList<Edge> KruskalMST(Graph graph){
if (graph == null) return null;
//先将点构成并查集
UnionSet unionSet = new UnionSet();
unionSet.makeUnionSet(graph.nodes.values());//那一堆的节点,构成了并查集
//再将边放入小根堆
PriorityQueue<Edge> heap = new PriorityQueue<>(new heapComparator());
for (Edge edge:graph.edges){
heap.add(edge);
}
//按照小根堆的边,挨个查,并,最后记录结果
ArrayList<Edge> res = new ArrayList<>();
while (!heap.isEmpty()){
Edge edge = heap.poll();//弹出一根边
//看它两边的节点,是否已经联通?没有就联通一下,记录结果,要了这个边,
//如果已经联通了,就不管了
if (!unionSet.isSameSet(edge.from, edge.to)){
res.add(edge);
unionSet.union(edge.from, edge.to);
}
}
return res;
}
图的算法是真的不困难,核心思想很简单,但是图的数据结构很难
并查集不难,但是耗费时间
所以呢?
互联网大厂考你图吗?
不考的,这么多代码,没有任何人可以在笔试或者面试中写出来,时间太久了,这也不是考你撸代码的实力的好办法,更不是考你优化算法能力的最佳方案,这就不会考
因此了解一波即可!!
验证一下:
public static void test(){
//造一个图
int[][] matrix = {
{1,1,2},
{2,2,3},
{3,3,4},
{100,4,5},
{5,2,5},
{100,2,6},
{7,5,6}
};
Graph graph = generateGraph(matrix);
ArrayList<Edge> edges = KruskalMST(graph);
for (Edge edge:edges){
System.out.println(edge.weight);
}
}
public static void main(String[] args) {
test();
}
最小生成树的边:
1
2
3
5
7
总结
提示:重要经验:
1)图的算法是真的不困难,核心思想很简单,但是图的数据结构很难,在互联网大厂笔试面试中,没有任何人可以在笔试或者面试中写出来,时间太久了,这也不是考你撸代码的实力的好办法,更不是考你优化算法能力的最佳方案
2)并查集的重要性,不多说,非常非常非常重要,解决连通性的利器。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。