前端面试题整理
vue
vue双向绑定
数据劫持:vue.js是采用数据劫持结合发布者订阅者的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调
面试官:阐述下你对MVVM响应式原理的理解?
vue是通过数据劫持object.defineProperty()来劫持各个属性的setter getter ,在数据变动时,发送消息给依赖收集器(dep中的subs),去通知(notify)观察者,做出相应的回调函数
--no-
面试官:说说vue的生命周期?
beforeCreate
创建之前,此时还没有data和method
Created
创建完成,此时data和method可以使用
在Created之后beforeMount之前如果没有el选项的话那么此时的生命周期结束,停止编译,如果有的话则继续
beforeMount
在渲染之前
mounted
页面已经渲染完成,并且vm实例中已经添加完了$el了,以及替换掉那些Dom元素了(双括号中的变量),这个时候可以操作dom了(但是获取不了元素的高度等属性,但是如果想要获取,我们可以使用nextTick())
beforeUpdate
data改变之后,对应的组件渲染之前
updated
data改变后,对应的组件重新渲染完成
beforeDestory
在实例销毁之前,此时实例依然可以使用
destoryed
实例销毁之后。
面试官:vue中父子组件的生命周期?
父子组件的生命周期是一个嵌套的过程
渲染过程是
父beforeCreate->父Created->父beforeMount->子beforeCreate->子Created->子beforeMount->子mounted->父mounted
子组件更新过程
父beforeUpDate->子beforeUpDate->子update->父updated
父组件更新过程
父beforeUpdata->父updated
销毁过程
父beforeDestroy->子beforeDestroy->子destoryed->父destoryed
面试官:vue中的nextTick
nextTick
解释
nextTick:在下次dom更新循环结束之后执行延迟回调,在修改数据之后立即使用这个方法,获取更新之后的dom
应用
想要在vue的created生命周期中操作dom 我们可以使用Vue.nextTick()回调函数
在数据改变后要执行的操作,而这个操作需要等数据改变后而改变DOM结构的时候才进行操作,需要用到nextTick
面试官:computed和watch的区别
computed
- 计算属性,依赖其他属性,当其他属性改变的时候下一次获取computed值时也会改变,
computed的值会有缓存
watch
- 类似于数据改变后的回调
- 如果想深度监听的话,后面加一个
deep:true - 如果想监听完立马运行的话,后面加一个
immediate:true
面试官:Vue优化方式
v-if和v-show
使用Object.freeze()方式冻结data中的属性,从而阻止数据劫持
组件销毁的时候会断开所有与实例联系,但是除了addEventListener,所以当一个组件销毁的时候需要手动去removeEventListener
图片懒加载
路由懒加载
为减少重新渲染和创建dom节点的时间,采用虚拟dom
面试官:Vue-router的模式
hash模式
监听hashchange事件实现前端路由,利用url中的hash来模拟一个hash,以保证url改变的时候,页面不会重新加载
history模式
利用pushstate和replacestate来将url替换但不刷新,但是有一个致命点就是,一旦刷新的话,就会可能404,因为没有当前的真正路径,要想解决这一问题需要后端配合,将不存在的路径重定向到入口文件。
面试官:MVC和MVVM的区别
---no--
面试官:说说数组的常用方法
常用的
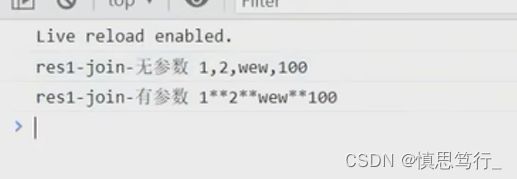
1.join array.join("符号") 把数组转为字符串,不改变原来的数组

2.split string.split("符号") 以字符串为标准进行分割字符串,返回数组
3.push array.push(参数) 把参数加到数组的尾部,改变原数组,此方法返回最新的数组长度为字符串
4.pop 删除尾部的
5.shift 将参数加到数组的头部
6.unShift 删除数组头部 第一参数
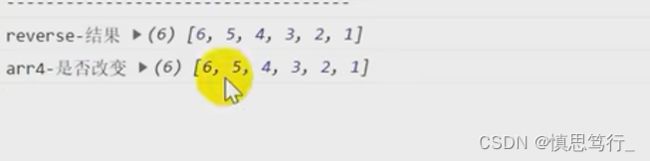
7.reverse 反转数组,更改原来数组

8.srot 排序
9.concat 合并
10.splice 截取/删除 3个参数非必填
array.splice("开始截取的数组下标",“截取的长度”,“填充替换的数组”)
更改原数组,返回删除的数据数组
11.slice 截取/删除数组,不更改原来的数组
array.slice("开始截取的数组下标","结束截取的数组下标,并且不包含",)
遍历数组的方法
1.forEarch 对数组每一项进行操作 没有返回值
2.map 为数组里面每一项进行操作,并返回一个新数组
3.filter 循环过滤数组,返回一个新数组
4.find 查找符合条件的返回,只会返回符合条件的第一个元素
5.findIndex 查找符合条件的返回,只会返回符合条件的第一个下标
6.some 遍历 有真则真 只会返回true不会返回false
7.every 遍历 有假则假 只会返回false不会返回true
8.reduce 遍历累加
let arr1 =[1,2,3,4,5,6]
let res111=arr1.reduce((p,n)=>p+n)
console.log("reduce累加",res111) //21
面试官:说说深拷贝和浅拷贝
浅拷贝:复杂数据类型的传址 (指的是两个变量,指向一个地址)
深拷贝:完全赋值一份数据一致的非同一个地址的数据(指的是两个变量,指向两个地址)
深拷贝
1.JSON.parse(JSON.stringfy(obj)) //先把对象转换为字符串 字符串在转化为对象 完成新对象拷贝
(缺点:underfined和函数无法赋值,这是一个缺陷)
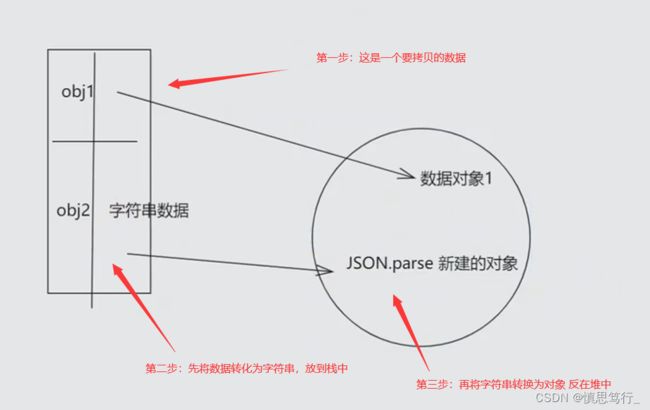
最标准的常用的深拷贝方法是递归进行拷贝!!!!!
面试官:说下this指向 及改变this的方法
首先 this指向window window==this
我想这个里面我有必要说下箭头函数里面的this指向,箭头函数的this指向的是当前上下文的环境,并不可以改变this的指向
重点:普通函数的this是执行的时候绑定,箭头函数是申明的时候绑定的this
改变this指向的三个方法apply call bind
apply 改变this指向并且立即执行函数,参数逗号分隔
obj3.oson1.oson2.fun2.apply({a:123},["A",'B'])
call 改变this指向并且立即执行函数,参数以数组的形
obj3.oson1.oson2.fun2.call({a:456},"C",'D')
bind 改变this指向并且立即执行函数,参数逗号分隔
语法和call是一样的
面试官:聊下构造函数和new操作符
构造函数(普通函数,约定构造函数的函数名首字母大写)
1.创建一个对象 指向构造函数的this
2.this的 _proto_ 指向构造函数的prototype
面试官:异步解决方案
callback 回调函数

promise (promise是es6新增的构造函数 pending=>转换成两个状态resolve/reject)

promise.all 这个印象深刻 (当项目中有多个异步要处理的时候,就会使用到)


async/await

面试官:聊下原型链
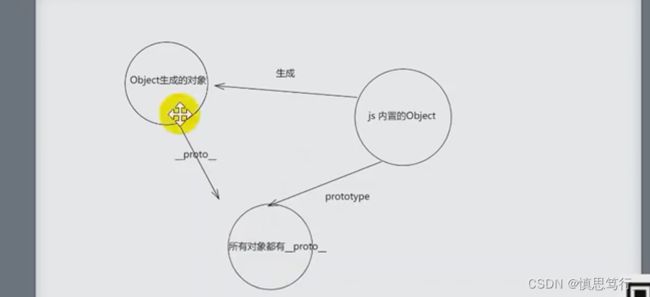
prototype (这个属性只有函数对象才有的 (构造)函数原型对象)
__proto__所有对象都有此属性,总是指向对应的构造函数的原型对象
constructor:__proto__ 下面的constructor指向构造函数自己 (主要指向对象的原型是否是某个对象)
对象访问属性的时候 在自身属性查找 找不到了再去__proto__上查找!!!
面试官:聊聊闭包
应用场景:闭包就是函数里面套函数,并把内部的函数return出来,内部函数可以访问外部变量,并且一级一级的向上去找
(内部函数可以访问父函数的变量的最终结果)
作用:封装变量,收敛权限
优点:防止变量污染
内存:当一个变量在作用域内部不会被使用,会被存储释放
闭包的缺点就是引用的变量不会被回收,有可能造成内存泄漏(缺点)

面试官:聊聊 MVC和MVVM
SPA简述:
SPA整个项目只有一个html文件,但是页面的内容可以随着router路由的切换而变换
优点:
1.用户体验及交互比较的流畅
2.提取组件开发,易于后期的维护
3.减轻了服务器的压力
缺点:
1.不利于SEO优化(搜索引擎优化) 搜索引擎爬虫 不会爬取js 这个对关键词搜索是不利的
2.第一次进入比较的慢(已有按需加载策略)
mvc: model 数据层 也就是data view试图 也就是用户界面 controller 控制器
流程:
用户点击view视图 -----发生行为-----> controller 控制器------通知数据更改----->Model数据层改变-----再传给view视图

mvvm:model 数据层 也就是data view视图层 也就是用户界面 viewModel 双向绑定
用户行为更改数据,数据可以主动触发视图更新
双向绑定是通过viewModel进行更新的

面试官:聊聊 vue的生命周期
vue2的生命周期
8个生命周期 create mounted updated destoryed
beforeCreate (beforeCreate挂载了vue实例的方法,但是data没有挂载)
created (created挂载了data)
beforemounte(‘data没有渲染到页面’)
mounted(data渲染到了页面)
beforeUpdate(数据更改导致dom更改之前)
updated(数据更改导致dom更改之后)
beforeDestoryed(销毁之前)
destoryed(销毁之后)
vue3的生命周期
vue3删除了beforeCreate 和 created
面试官:computed 和watch的区别
comouted:计算属性,计算出一个结果,函数值改变了就会重新计算
watch:监听某个数据,被监听的数据更改,则watch执行
面试官:router routes route三者的区别
router:路由对象
routes:路由配置项
route:当前路由信息
面试官:v-if和v-show的区别
v-if可以配合v-else一起使用 就是单纯的逻辑判断 v-show它主要操作的是 是否给当下html的style添加display:none 他是对css进行操作 消耗比v-if小
面试官:来聊聊父传子 子传父
先说下父传子吧,再子组件中设置一个props:[] 然后再父组件中 子标签上设置:data=data1
然后是子传父,再子组件中使用$emit(abc,this.data)发射一个数据出来 然后再父组件中使用@abc
面试官:来聊聊兄弟传值
我会在main.js总线文件里面,设置一个vue.prototype.$bus=new vue
然后在 兄弟A中 设置$emit("方法名","相关数据") 发射一个数据出来
再然后 兄弟B中 mounted里面设置this.$bus.$on("方法名"(value)=>{})
面试官:来聊聊nextTick()
vue的渲染是异步的渲染,所以vue就提供了一个nextTick()来解决这个异步渲染之后再执行
面试官:来聊聊插槽的使用
vue的插槽分为普通插槽和具名插槽和作用域插槽
我先说下普通的插槽:
普通插槽 slot ,这个是要配合父子组件使用的。在子组件中设置一个slot标签 就可以在父组件中子组件里面添加自己想要的东西了
具名插槽:是在普通插槽的基础上,在子组件中给插槽添加上名字,然后在父组件中给相关标签设置上对应名称。以对应相关插槽
作用域插槽:在开发中,我们在使用插槽的时候会遇到一个问题,就是父组件想要使用子组件中的数据的时候。使用不起来。这时候我们就可以在父中标签上添加slot-scope的属性 这样就可以直接拿到子组件中的数据了
面试官:keep-alive是什么?
在我们日常开发 的时候 假设我们写tab选项卡
比如tab1 tab2 tab3 ,在tab切换的时候你要让他保持点击之前点击或者输入的某个结果
就得使用keep-alive
当不使用keep-alive的时候,在tab进行切换的时候,会被自动销毁。keep-alive 也就是避免了自动销毁这个操作
vue系统自带的一个组件,功能:是来缓存组件的
面试官:ref是什么?
ref是帮助js来获取html相关的dom的 就像我们之前纯js操作dom的时候 document.querySelector(".class") 操作dom是一个道理
面试官:mixin是什么?
mixin 就是公共的方法
之前开发中也有使用到,我会设置一个mixin.js
然后在js文件中写入相关的方法

再然后直接在相关页面中调用
import mixin from "./mixin"
然后在export default里面家伙是那个mixins:[mixin] 然后直接调用相关方法就可以了

面试官:聊一下vue的侦听器的实现?
是使用了js中的 object.defineProperty()进行一个数据劫持 然后再通过观察者模式
let obj = {}
let val =20
Object.defineProperty(obj ,"age"{
get(){
console.log("age属性被修改了${val}")
return val
}
set(newVal){
console.log("age属性被修改了${newVal}")
val=newVal
}
})
JS数据类型
面试官:js中什么是基础数据类型?什么是引用数据类型?以及各种数据类型如何存储?♥♥♥♥♥
答:
基础数据类型有:
- String(字符串)
- Number(数字)
- Boolean(布尔)
- Null(空)
- Undefined
- Symbol(Es6新增数据类型)
- bigInt
引用数据类型有:
- Object(对象)
- Array(数组)
- RegExp(正则表达式)
- Function(函数)
- Data(Data对象 引用本地时间,等....)
基础数据类型中的数据存储在栈中,引用数据类型的数据存储在堆中,
栈中存储数据的引用地址,每个引用地址都对应的堆中的数据。
顺带提一句:栈内存是自动分配内存的,而堆内存是动态分配内存的,不会自动释放。所以每次使用内存的时候都要把它设置为null,从而减少无用内存的消耗。
类型转换
面试官:在js中为什么0.1+0.2>0.3?♥♥♥♥♥
答:
因为在js中,浮点数是使用64位固定长度来表示的,其中1位表示符号位,11位表示指数位。剩下52位尾数位由于只有52位表示位数位。
而0.1转为二进制是一个无限循环数0.0001100110011001100......(1100循环)
由于只能存储52位尾数位,所以会出现精度缺失,把它存到内存中再取出来转换成十进制就不是原来的0.1了,就变成了0.100000000000000005551115123126,而为什么0.2+0.1是因为
// 0.1 和 0.2 都转化成二进制后再进行运算
0.00011001100110011001100110011001100110011001100110011010 +
0.0011001100110011001100110011001100110011001100110011010 =
0.0100110011001100110011001100110011001100110011001100111// 转成十进制正好是 0.30000000000000004
面试官:那为什么0.2+0.3=0.5呢?♥♥♥♥♥
// 0.2 和 0.3 都转化为二进制后再进行计算
0.001100110011001100110011001100110011001100110011001101 +
0.0100110011001100110011001100110011001100110011001101 =
0.10000000000000000000000000000000000000000000000000001 //尾数为大于52位// 而实际取值只取52位尾数位,就变成了
0.1000000000000000000000000000000000000000000000000000 //0.5
答:
0.2和0.3分别转化位二进制进行计算的时候:在内存中,他们的位数位都是等于52位的,而他们相加必定大于52位。而他们相加有恰巧前52位数字都为0,截取之后恰好是0.1000000000000000000000000000000000000000000000000000也就是0.5
面试官:那既然0.1不是0.1了,为什么console.log(0.1)的时候还是0.1呢?♥♥♥
答:
在console.log的时候会二进制转换为十进制,十进制再转化为字符串的形式,在转化过程中发生了近似值,所以打印出来是一个近似值的字符串。
面试官:判断数据类型有几种方法?♥♥♥♥♥
答:
- typeof(缺点:typeof null 的值为object,开发过程中就无法判断数据类型是null还是object了)
- instanceof(缺点:只能判断对象是否存在于目标对象的原型链上)
- constructor
- object.prototype.toString.call() (一种最好的基本数据类型的检测方法,他可以区分
null 、 string 、boolean 、 number 、 undefined 、 array 、 function 、 object 、 date 、 math 数据类型 缺点:他不能细分为谁谁的实例)
// -----------------------------------------typeof
typeof undefined // 'undefined'
typeof '10' // 'String'
typeof 10 // 'Number'
typeof false // 'Boolean'
typeof Symbol() // 'Symbol'
typeof Function // ‘function'
typeof null // ‘Object’
typeof [] // 'Object'
typeof {} // 'Object'
// -----------------------------------------instanceof
function Foo() { }
var f1 = new Foo();
var d = new Number(1)
console.log(f1 instanceof Foo);// true
console.log(d instanceof Number); //true
console.log(123 instanceof Number); //false -->不能判断字面量的基本数据类型
// -----------------------------------------constructor
var d = new Number(1)
var e = 1
function fn() {
console.log("ming");
}
var date = new Date();
var arr = [1, 2, 3];
var reg = /[hbc]at/gi;console.log(e.constructor);//ƒ Number() { [native code] }
console.log(e.constructor.name);//Number
console.log(fn.constructor.name) // Function
console.log(date.constructor.name)// Date
console.log(arr.constructor.name) // Array
console.log(reg.constructor.name) // RegExp
//-----------------------------------------Object.prototype.toString.call()
console.log(Object.prototype.toString.call(undefined)); // "[object Undefined]"
console.log(Object.prototype.toString.call(null)); // "[object Null]"
console.log(Object.prototype.toString.call(123)); // "[object Number]"
console.log(Object.prototype.toString.call("abc")); // "[object String]"
console.log(Object.prototype.toString.call(true)); // "[object Boolean]"
function fn() {
console.log("ming");
}
var date = new Date();
var arr = [1, 2, 3];
var reg = /[hbc]at/gi;
console.log(Object.prototype.toString.call(fn));// "[object Function]"
console.log(Object.prototype.toString.call(date));// "[object Date]"
console.log(Object.prototype.toString.call(arr)); // "[object Array]"
console.log(Object.prototype.toString.call(reg));// "[object RegExp]"
instanceof原理♥♥♥♥♥
- instanceof原理实际上就是查找目标对象的原型链
function myInstance(L, R) {//L代表instanceof左边,R代表右边
var RP = R.prototype
var LP = L.__proto__
while (true) {
if(LP == null) {
return false
}
if(LP == RP) {
return true
}
LP = LP.__proto__
}
}
console.log(myInstance({},Object));
面试官:为什么typeof null是Object ♥♥♥♥
答:
在js中,不同的对象都是使用二进制来进行存储的,如果二进制前三位都是0的话,系统会判断为object类型,而null的二进制都是0,自然也就被判断为object了
这个bug是初版本js遗留下来的,扩展下其他五种标识位:
000对象1整型010双精度类型100字符串110布尔类型
面试官:==和===有什么区别♥♥♥♥♥
答:
===是严格意义上的相等,会比较两个数据类型和值的大小
- 数据类型不同返回false
- 数据类型相同,但是值不同的时候返回false
==是非严格意义上的相等
- 两个数据类型相同的时候,比较大小
- 两方数据类型不同的时候,根据下方表格,再进一步进行比较。
- Null == Undefined ->true
- String == Number ->先将String转为Number,在比较大小
- Boolean == Number ->现将Boolean转为Number,在进行比较
- Object == String,Number,Symbol -> Object 转化为原始类型
面试官:手写call,apply,bind ♥♥♥♥♥
答:---
面试官:字面量创建对象和new创建对象有什么区别,new内部都实现了什么,手写一个new♥♥♥♥♥
//字面量创建对象
let obj ={
age:24,
name:"季哈哈"
jobNo:"001"
}
//new创建对象
let obj =new Object()
obj.name='季哈哈'字面量:
- 字面量创建对象更加的简单,易读
- 不需要作用域解析,速度更快
new内部
- 创建一个新对象
- 使用新对象的_proto_指向原函数的prototype
- 改变this指向(指向新obj)并执行该函数,执行结果保存起来作为result
- 判断执行函数的结果是不是null或者underfined,如果是则返回之前的新对象,如果不是则返回result
手写new
// 手写一个new
function myNew(fn, ...args) {
// 创建一个空对象
let obj = {}
// 使空对象的隐式原型指向原函数的显式原型
obj.__proto__ = fn.prototype
// this指向obj
let result = fn.apply(obj, args)
// 返回
return result instanceof Object ? result : obj
}
面试官:字面量new出来的对象和Object.create(null)创建出来的对象有什么区别♥♥♥
答:
- 字面量和new创建出来的对象会继承Object的方法和属性,他们的隐式原型会指向object的显示原型
- 而object.create(null)创建出来的对象原型为null,作为原型链的顶端,自然也不会继承object的方法和属性
面试官:什么是作用域,什么是作用域链
答:
作用域是一个查找机制,在当前作用域下用到某个变量或者函数,有私有的有公共的,没有私有的会往更上一级作用域中查找,直到找到全局作用域为止,找到相关变量会返回出来找不到可能报错
- 规定变量和函数的可使用范围称作作用域
- 每个函数都是作用域链的一部分,查找变量或者函数时,需要从局部作用域到全局作用域依次查找,这些作用域的集合称为作用域链。
面试官:什么是执行栈,什么是执行上下文
答:
执行上下文分为:
- 全局执行上下文
浏览器中全局对象就是window对象,我们正常使用的this指向就是指向的这个全局对象。执行 js的时候就压入栈底,关闭浏览器的时候才会弹出来
- 函数执行上下文
1.每次函数调用时,都会新创建一个函数执行上下文
2.执行上下文分为创建阶段和执行阶段
创建阶段:函数环境会创建变量对象:arguments对象(并赋值)、函数声明(并赋值)、 变量声明(不赋值),函数表达式声明(不赋值);会确定this指向;会确定作用域
执行阶段:变量赋值、函数表达式赋值,使变量对象变成动态对象 (动态网页)
- eval执行上下文
执行栈:
- 首先栈特点:先进后出
- 当进入一个执行环境,就会创建出它的执行上下文,然后进行压栈,当程序完成的时候,他的执行上下问就会被销毁,进行弹栈
- 栈底永远是全局环境的执行上下文,栈顶永远是正在执行函数的执行上下文
- 只有浏览器关闭的时候,全局执行上下文才会弹出
闭包
面试官:什么是闭包?闭包的作用?闭包的应用?
答:
函数执行,形成私有的执行上下文,使内部私有变量不受外部干扰,起到保护和保存的作用
-------no---------
原型和原型链
什么是原型?什么是原型链?如何理解
答:
原型分为隐式原型和显式原型
function Fn(){}
//显式原型--->空的Object对象
console.log(Fn.prototype);
//隐式原型--->
var fn = new Fn();//this.__proto__ = Fn.prototype
console.log(fn.__proto__);
//对象的隐式原型的值为其对应构造函数的显式原型的值。
console.log(Fn.prototype===fn.__proto__);//true
//给原型函数添加方法
Fn.prototype.test = function(){
alert("!");
}
fn.test();原型:原型分为隐式原型和显式原型,每个对象都是一个隐式原型,它会指向自己的构造函数的显式原型
原型链:多个_proto_组合城的集合成为原型链
- 所有实例的_proto_指向他们构造函数的prototype
- 所有的prototype都是对象,自然它的_proto_指向的是object()的prototype
- 所有的构造函数的隐式原型指向的都是Function()的显示原型
- Object的隐式原型是null
继承
面试官:说一说js中常用的继承方式有哪些?以及各种继承方式的有点和缺点
答:
原型继承,组合继承,寄生组合继承,ES6的extend
---------------------no-------------------------------
内存泄漏、垃圾回收机制
面试官:什么是内存泄漏?
答:
内存泄漏是指不再用的内存没有被即使释放出来,导致该段内存无法被使用就是内存泄漏
面试官:为什么会导致内存泄漏?
答:
内存泄漏指我们无法通过js访问某个对象,而垃圾回收机制却认为该对象还在被引用,因此垃圾回收不会释放该对象,导致该块内存永远无法得到释放,积少成多,系统会越来越卡以至于崩溃
面试官:垃圾回收机制有哪些策略?
答:
- 标记清除法
(垃圾回收机制获取根并标记他们,然后访问并标记所有来自它们的引用,然后在访问这些对象并标记它们的引用…如此递进结束后若发现有没有标记的(不可达的)进行删除,进入执行环境的不能进行删除)
- 引用计数法
(
当声明一个变量并给该变量赋值一个引用类型的值时候,该值的计数+1,当该值赋值给另一个变量的时候,该计数+1,当该值被其他值取代的时候,该计数-1,当计数变为0的时候,说明无法访问该值了,垃圾回收机制清除该对象
缺点: 当两个对象循环引用的时候,引用计数无计可施。如果循环引用多次执行的话,会造成崩溃等问题。所以后来被标记清除法取代。
)
单线程,同步异步
面试官:为什么js是单线程?
答:
因为js中有大量的dom操作,假设是多线程的话,一个线程在删除 一个线程在增加,会导致浏览器不知道应该听谁使唤
面试官:如何实现异步编程?
答:
回调函数(回调函数指的是一个函数可以作为参数,传到另一个函数中使用,并被调用)
变量提升
面试官:变量和函数是怎么进行提升的?优先级是怎么样的
答:
- 对所有函数声明进行提升(除了函数表达式和箭头函数),引用类型的赋值
开辟堆空间
存储内容
将地址赋给变量
- 对变量进行提升,只声明,不赋值,值为underfined
面试官:var let const 有什么区别
答:
- Var
var声明可以进行变量提升,let和const不会
var可以重复声明
var在非函数作用域中定义是挂在window上的
- let
let声明的变量只在局部起作用
let防止变量污染
不可在声明
- const
具有let所有的特征
不可被改变
如果使用const声明对象的话,是可以修改对象中的值的
面试官:箭头函数和普通函数的区别?箭头函数可以当作构造函数new吗?
- 箭头函数是普通函数的简写,但是它不具备很多普通函数的特性
- 第一点,this指向问题,箭头函数的this指向它定义时所在的对象,而不是调用时所在的对象
- 不会进行函数提升
- 没有arguments对象,不能使用arguments,如果获取参数的话可以使用rest运算符
- 没有yield属性,不能作为生成器Generator使用
- 不能new
没有自己的this,不能调用call和apply
没有prototype,new关键字内部需要把新对象的_proto_指向函数的prototype
面试官:说说你对代理的理解
- 代理有几种定义方式
字面量定义,对象里的get和set
类定义,class中的get和set
Proxy对象,里面传两个对象,第一个对象是目标对象target,第二个对象是专门放get和set的 handler对象。Proxy和上面两个的区别在Proxy专门对对象的属性进行get和set
- 代理的实际应用有
vue的双向绑定vue2用的是object.defineProperty,vue3用的是proxy
校验值
计算机属性值(get的时候加以修饰)
面试官:为什么使用模块化?都有哪几种方式可以实现模块化,各有什么特点?
- 为什么要使用模块化
防止命名冲突
更好的分离,按需加载
更好的复用性
更高的维护性
面试官:exports和module.exports有什么区别?
- 导出方式不一样
exports.xxx='xxx'
module.export={}
- exports是module.exports的引用,两个指向的是用一个地址,而require能看到的只有module.exports
面试官:js模块包装格式有哪些?
--no-
面试官:ES6和common.js的区别?
--no-
跨域
面试官:跨域的方式都有哪些?他们的特点是什么?
JSONP
JSONP通过同源策略涉及不到的’漏洞‘,也就是像img中的src,link标签的href,script的src都没有被同能源策略限制到
JSONP只能get请求
源码:
function addScriptTag(src) {
var script = document.createElement("script")
script.setAttribute('type','text/javascript')
script.src = src
document.appendChild(script)
}
// 回调函数
function endFn(res) {
console.log(res.message);
}// 前后端商量好,后端如果传数据的话,返回`endFn({message:'hello'})`
document.domain
只能跨一级域名相同的域(www.qq.com和www.id.qq.com,二者都有qq.com)
使用方法
>表示输入 <表示输出 以下是在www.id.qq.com网站下执行的操作
> var w = window.open("https://www.qq.com")
< undefined
> w.document
✖ VM3061:1 Uncaught DOMException: Blocked a frame with origin "https://id.qq.com" from accessing a cross-origin frame.
at:1:3
> document.domain
< "id.qq.com"
> document.domain = 'qq.com'
< "qq.com"
> w.document
< #document
location.hash+iframe
因为hash传值只能单向传输,所以可以通过一个中间网页,a若想和b进行通信,可以通过一个与a同源的c作为中间网页,a传给b,b传给c,c再传回a
具体做法:在a中放一个回调函数,方便c回调。放一个iframe标签,随后传值
在b中监听哈希值改变,一旦改变,把a要接收的值传给c
在c中监听哈希值改变,一旦改变,调用a中的回调函数
window.name+iframe
利用window.name不会改变(而且很大)来获取数据
a要获取b的数据,b中把数据转为json格式放到window.name中
postMessage
a窗口向b窗口发送数据,先把data转为json格式,在发送。提前设置好message监听
b窗口进行message监听,监听到了以同样的方式返回数据
a窗口监听到 message,在进行一系列的操作
CORS
通过自定义请求头来让服务器和浏览器进行沟通
有简单的请求和非常简单的请求
满足以下条件就是简单请求
请求方式是HEAD,POST,GET
请求头只有Accept,AcceptLanguage,ContentType,ContentLanguage,Last-Event-Id
简单请求,浏览器自动添加一个Origin字段
同时后端需要设置的请求头
Access-Control-Allow-Origin --必须
Access-Control-Expose-Headers
XMLHttpRequest只能拿到六个字段,要想拿到其他的需要在这里指定
Access-Control-Allow-Credentials --是否可传cookie
要是想传cookie,前端需要设置xhr.withCredentials = true,后端设置Access-Control- Allow-Credentials
非简单请求,浏览器判断是否为简单请求,如果是非简单请求,则 浏览器先发送一个header头为option的请求进行预检
预检请求格式(请求行 的请求方法为OPTIONS(专门用来询问的))
Origin
Access-Control-Request-Method
Access-Control-Request-Header
浏览器检查了Origin、Access-Control-Allow-Method和Access-Control-Request-Header之后确认允许就可以做出回应了
通过预检后,浏览器接下来的每次请求就类似于简单请求了
nginx代理跨域
nginx模拟一个虚拟服务器,因为服务器于服务器之间是不存在跨域的
发送数据时,客户端->nginx->服务端
返回数据时,服务端->nginx->客户端
网络原理
面试官:讲一讲三次握手四次挥手,为什么是三次握手而不是两次握手
客户端和服务端之间通过三次握手建立连接,四次挥手释放连接
三次握手:客户端先向服务端发起一个SYN包,进入SYN_SENT状态,服务端收到SYN后,给客户端返回一个ACK+SYN包,表示已收到SYN,并进入SYN_RECEIVE状态,最后客户端再向服务端发送一个ACK包表示确认,双方进入establish状态。
---no---
面试官:HTTP的结构
请求行 请求头 空行 请求体
请求行包括http版本号 url 请求方式
响应行包括版本号,状态码,原因
面试官:HTTP头都有哪些字段
请求头
cache-control是否使用缓存
connection:keep-alive与服务器的连接状态
Host主机域
返回头
cache-control
etag唯一标识,缓存用的
last-modified最后修改时间
面试官:说说你知道的状态码
2开头的表示成功
一般见到的就是200
3开头的表示重定向
301永久重定向
302临时重定向
304表示可以缓存中取数据(协商缓存)
4开头的表示客户端错误
403表示跨域问题
404请求字段不存在
5开头的表示服务端错误
500
网络OSI七层模型都有哪些?TCP是哪一层的?
七层模型
应用层
表示层
会话层
传输层
网络层
数据链路层
物理层
TCP属于传输层
面试官:http1.0和http1.1,还有http2有什么区别?
http0.9只能进行get请求
http1.0添加了 post,head,option,put,delete等
http1.1增加了长连接keep-alive 增加了host域,而且节约带宽
http2多路复用 头部压缩 服务器推送
面试官:https和http有什么区别,https的实现原理?
http无状态无连接,而且明文传输不安全
https传输内容加密,身份验证,保证数据完整性
https实现原理
首先客户端向服务端发起一个随机值,以及一个加密算法
服务端收到后返回一个协商好的加密算法,以及另一个随机值
服务端在发送一个公钥CA
客户端收到以后先验证CA是否有效,如果无效则报错弹窗,有过有效则进行下一步操作
客户端使用之前的两个随机值和一个预主密钥组成一个会话密钥,在通过服务端传来的公钥加密把会话密钥发送给服务端
服务端收到后使用私钥解密,得到两个随机值和预主密钥,然后组装成会话密钥
客户端在向服务端发起一条信息,这条信息使用会话秘钥加密,用来验证服务端时候能收到加密的信息
服务端收到信息后返回一个会话秘钥加密的信息
都收到以后SSL层连接建立成功
面试官:localStorage,SessionStorage,cookie,session之间有什么区别
localStorage
生命周期:关闭浏览器之后数据一直保存 ,除非手动清除,否则一直存在
作用域:相同浏览器的不同标签,在同源的情况下可以共享localStorage
SessionStorage
生命周期:关闭浏览器或者标签之后消失
作用域:只在当前标签有用,当前标签的iframe中且同源可以共享
Cookie
是保存在客户端的,一般由后端设置值,可以设置过期时间
存储大小只有4k
一般用来保存用户的信息的
在http下的cookie都是明文传输的,不安全
cookie属性有
http-only不能被客户端更改访问,防止xss攻击(保证cookie安全性的操作)
Secure:只允许在https下传输
Max-age:cookie生成后失效的秒数
expire:cookie的最长有效时间,若不设置则cookie生命周期与会话期相同
session
session是保存在服务端的
session的运行依赖sessionId,而sessionId又保存在cookie中,所以如果禁用的cookie,session也是不能用的,不过硬要用也可以,可以把sessionId保存在URL中
session一般用来跟踪用户的状态
session 的安全性更高,保存在服务端,不过一般为使服务端性能更加,会考虑部分信息保存在cookie中
面试官:localStorage存满了怎么办?
划分域名,各域名下的存储空间由各业务组统一规划使用
跨页面传数据:考虑单页面应用。采用url传输数据
最后兜底方案:清掉别人的存储
面试官:怎么使用cookie保存用户信息?
document.cookie("name=数据;expire=时间")
面试官:怎么删除cookie?
目前没有提供删除操作,但是可以把它max-age设置为0,也就立马失效了,也就是删除了。
面试官:get和post的区别
幂等/不幂等(可缓存/不可缓存)
get请求是幂等的,所以get数据是可以缓存的
而post请求是不幂等的,查询对数据是有副作用的,是不可缓存的
传参
get传参在url中
准确说get传参可以放在body中,只不过不推荐使用
post传参,参数是在请求体中
准确的说post传参是可以放到url中的,只不过不推荐使用
安全性
get较不安全
post较为安全
准确的说两者都是不安全的,都是明文传输的。在路过公网的时候都会被访问到,不管是url还是header还是body,都会被访问到,要想做到安全,就需要使用https
参数长度
get参数的长度有限,是较小的
准确来说get使用url传参的时候是很小的
post传参长度是不受限制的
发送数据
post传参的时候是发送两个请求包。一个是请求头一个是请求体,请求头发送后服务器进行验证,要是验证通过的话,就会给客户端发送一个100-continue的状态码,然后就会发送请求体
字符编码
get在url上传输的时候只允许ASCII编码
面试官:讲讲http缓存
缓存分为强缓存和协商缓存
强缓存
在浏览器加载资源时,先看看cachel-control里的max-age,判断数据有没有过期,如果没有的直接使用该缓存,有些用户可能在没有过期的时候就点击刷新按钮,这个时候浏览器就会回去请求客户端,要想避免这样做。可以在cachel-control里面加一个immutable
public
允许客户端和虚拟服务器缓存该资源,cache-control中的一个属性
private
只允许客户端缓存该资源
no-cache
不允许强缓存,可以协商缓存
no-store
不允许缓存
协商缓存
浏览器加载资源的时候,没有命中强缓存,这时候就会请求服务器,去请求服务器的时候回带两个参数,一个是If-None-Match,也就是响应头中的etag属性,每一个文件对应一个etag;另一个参数是If-Modified-Since,也就是响应头中的Last-Modified属性,带这两个参数去检验缓存是否过期,如果没有过期,则服务器会给浏览器返回一个304状态码,表示缓存没有过期,可以使用旧缓存
etag的作用
有时候编辑了文件,但是没有修改,但是last-modified属性的时间就会改变,导致服务器会重新发送资源。但是etag的出现完美的避免了这个问题,他是文件的唯一的标识
缓存位置:
内存缓存Memory-Cache
离线缓存Service-Worker
磁盘缓存Disk-Cache
推送缓存Push-Cache
杂项
面试官:事件冒泡和事件捕捉有什么区别?
事件冒泡
在addEventListener中的第三属性设置为false(默认)
从下至上(儿子至祖宗)执行
事件捕捉
在addEventListener中的第三属性设置为true
从上至下(祖宗到儿子)执行
面试官:什么是防抖?什么是节流?
防抖
就是设置在几秒钟内,不可以频繁的触发。则重新计时
应用场景:手机号或者电子邮件输入验证码 ,搜索的时候只显示1s输入后的结果。
节流
n秒内值触发一次,如果n秒内重新触发,只有一次生效
应用场景:电子游戏 领取红包 这些场景用户都会多次点击 其实他们只点了一次
面试官:js常见的设计模式?
单例模式、工厂模式、构造函数模式、发布订阅者模式、迭代器模式、代理模式
面试官:js性能优化方式?
垃圾回收
闭包中的对象清除
防抖节流
分批加载
事件委托
少用with
requestAnimationFrame的使用
script标签中的defer和async
CDN