R语言处理数据——janitor包的介绍及使用
janitor功能介绍
janitor可以检查并清理脏数据,适用于R语言用户。主要功能如下:
1、完美格式化数据框的列名;
2、创建并格式化1-3个变量的频率表,可以看作是一个改进的table()函数;
3、提供用于清理和检查数据框的其他工具
制表和报告功能类似于SPSS和excel的常用功能。janitor是一个对标tidyverse的包。具体来讲,它与%>%这一pipeline配合的很好,并针对清理readr和readxl包中的数据进行了优化。
janitor的安装
方法一
install.packages("janitor")
方法二
install.packages("devtools")
devtools::install_github("sfirke/janitor")
janitor的使用
具体使用方法可以点击链接。以下是快速入门例子。
清理脏数据
例如下图中的数据
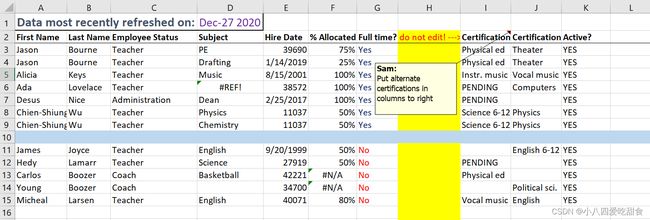
需要清理的部分主要有:
1、顶部标题;
2、列名;
3、包含excel格式但不包含数据的行和列;
4、单列中两种不同格式的日期(MM/DD/YYYY和数字)
5、“Certification”列中的值分布不一致
以下是读入R后的数据展示:
library(readxl); library(janitor); library(dplyr); library(here)
roster_raw <- read_excel(here("dirty_data.xlsx")) # available at https://github.com/sfirke/janitor
glimpse(roster_raw)
#> Rows: 14
#> Columns: 11
#> $ `Data most recently refreshed on:` "First Name", "Jason", "Jason", "Alicia", "Ada", "Desus", "Chien-…
#> $ ...2 "Last Name", "Bourne", "Bourne", "Keys", "Lovelace", "Nice", "Wu"…
#> $ ...3 "Employee Status", "Teacher", "Teacher", "Teacher", "Teacher", "A…
#> $ `Dec-27 2020` "Subject", "PE", "Drafting", "Music", NA, "Dean", "Physics", "Che…
#> $ ...5 "Hire Date", "39690", "43479", "37118", "38572", "42791", "11037"…
#> $ ...6 "% Allocated", "0.75", "0.25", "1", "1", "1", "0.5", "0.5", NA, "…
#> $ ...7 "Full time?", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", NA…
#> $ ...8 "do not edit! --->", NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
#> $ ...9 "Certification", "Physical ed", "Physical ed", "Instr. music", "P…
#> $ ...10 "Certification", "Theater", "Theater", "Vocal music", "Computers"…
#> $ ...11 "Active?", "YES", "YES", "YES", "YES", "YES", "YES", "YES", NA, "…
现在,从列名开始清理它。名字清洗有两种方式。make_clean_names()对字符向量进行操作,可在数据导入期间使用:
roster_raw_cleaner <- read_excel(here("dirty_data.xlsx"),
skip = 1,
.name_repair = make_clean_names)
glimpse(roster_raw_cleaner)
#> Rows: 13
#> Columns: 11
#> $ first_name "Jason", "Jason", "Alicia", "Ada", "Desus", "Chien-Shiung", "Chien-Shiung", NA, "J…
#> $ last_name "Bourne", "Bourne", "Keys", "Lovelace", "Nice", "Wu", "Wu", NA, "Joyce", "Lamarr",…
#> $ employee_status "Teacher", "Teacher", "Teacher", "Teacher", "Administration", "Teacher", "Teacher"…
#> $ subject "PE", "Drafting", "Music", NA, "Dean", "Physics", "Chemistry", NA, "English", "Sci…
#> $ hire_date 39690, 43479, 37118, 38572, 42791, 11037, 11037, NA, 36423, 27919, 42221, 34700, 4…
#> $ percent_allocated 0.75, 0.25, 1.00, 1.00, 1.00, 0.50, 0.50, NA, 0.50, 0.50, NA, NA, 0.80
#> $ full_time "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", NA, "No", "No", "No", "No", "No"
#> $ do_not_edit NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA
#> $ certification "Physical ed", "Physical ed", "Instr. music", "PENDING", "PENDING", "Science 6-12"…
#> $ certification_2 "Theater", "Theater", "Vocal music", "Computers", NA, "Physics", "Physics", NA, "E…
#> $ active "YES", "YES", "YES", "YES", "YES", "YES", "YES", NA, "YES", "YES", "YES", "YES", "…
clean_names()是make_clean_names()的便捷版本,可用于管道data.frame工作流。clean_names()的等效步骤如下:
roster_raw <- roster_raw %>%
row_to_names(row_number = 1) %>%
clean_names()
现在dataframe有了干净的列名。进一步整理:
roster <- roster_raw %>%
remove_empty(c("rows", "cols")) %>%
remove_constant(na.rm = TRUE, quiet = FALSE) %>% # remove the column of all "Yes" values
mutate(hire_date = convert_to_date(hire_date, # handle the mixed-format dates
character_fun = lubridate::mdy),
cert = dplyr::coalesce(certification, certification_2)) %>%
select(-certification, -certification_2) # drop unwanted columns
#> Removing 1 constant columns of 10 columns total (Removed: active).
roster
#> # A tibble: 12 × 8
#> first_name last_name employee_status subject hire_date percent_allocated full_time cert
#>
#> 1 Jason Bourne Teacher PE 2008-08-30 0.75 Yes Physical ed
#> 2 Jason Bourne Teacher Drafting 2019-01-14 0.25 Yes Physical ed
#> 3 Alicia Keys Teacher Music 2001-08-15 1 Yes Instr. music
#> 4 Ada Lovelace Teacher 2005-08-08 1 Yes PENDING
#> 5 Desus Nice Administration Dean 2017-02-25 1 Yes PENDING
#> 6 Chien-Shiung Wu Teacher Physics 1930-03-20 0.5 Yes Science 6-12
#> 7 Chien-Shiung Wu Teacher Chemistry 1930-03-20 0.5 Yes Science 6-12
#> 8 James Joyce Teacher English 1999-09-20 0.5 No English 6-12
#> 9 Hedy Lamarr Teacher Science 1976-06-08 0.5 No PENDING
#> 10 Carlos Boozer Coach Basketball 2015-08-05 No Physical ed
#> 11 Young Boozer Coach 1995-01-01 No Political sci.
#> 12 Micheal Larsen Teacher English 2009-09-15 0.8 No Vocal music
检查脏数据
寻找重复项
在数据清理期间,使用get_dupes()来识别和检查重复记录。让我们看看是否有教师被多次列出:
roster %>% get_dupes(contains("name"))
#> # A tibble: 4 × 9
#> first_name last_name dupe_count employee_status subject hire_date percent_allocated full_time cert
#>
#> 1 Chien-Shiung Wu 2 Teacher Physics 1930-03-20 0.5 Yes Science …
#> 2 Chien-Shiung Wu 2 Teacher Chemistry 1930-03-20 0.5 Yes Science …
#> 3 Jason Bourne 2 Teacher PE 2008-08-30 0.75 Yes Physical…
#> 4 Jason Bourne 2 Teacher Drafting 2019-01-14 0.25 Yes Physical…
是的,有些老师会出现两次。我们应该在计算员工人数之前解决这个问题。
制表工具
一个变量(或两个或三个变量的组合)可以用tabyl()制成表格。生成的data.frame可以用一套adorn_函数进行调整和格式化,以便在报告中快速分析和打印漂亮的结果。对于非表类型,adorn_函数也很有帮助。
tabyl()
与table()类似,但是支持管道,基于数据帧,并且功能齐全。
tabyl有两种用法:
1、在向量上,当对单个变量制表时:tabyl(roster$subject)
2、在data.frame上,指定1、2或3个要制表的变量名:roster %>% tabyl(subject,employee_status)。
这里,data.frame通过%>%管道传入;这允许在分析管道中使用tabyl
一个变量:
roster %>%
tabyl(subject)
#> subject n percent valid_percent
#> Basketball 1 0.08333333 0.1
#> Chemistry 1 0.08333333 0.1
#> Dean 1 0.08333333 0.1
#> Drafting 1 0.08333333 0.1
#> English 2 0.16666667 0.2
#> Music 1 0.08333333 0.1
#> PE 1 0.08333333 0.1
#> Physics 1 0.08333333 0.1
#> Science 1 0.08333333 0.1
#> 2 0.16666667 NA
两个变量:
roster %>%
filter(hire_date > as.Date("1950-01-01")) %>%
tabyl(employee_status, full_time)
#> employee_status No Yes
#> Administration 0 1
#> Coach 2 0
#> Teacher 3 4
三个变量:
roster %>%
tabyl(full_time, subject, employee_status, show_missing_levels = FALSE)
#> $Administration
#> full_time Dean
#> Yes 1
#>
#> $Coach
#> full_time Basketball NA_
#> No 1 1
#>
#> $Teacher
#> full_time Chemistry Drafting English Music PE Physics Science NA_
#> No 0 0 2 0 0 0 1 0
#> Yes 1 1 0 1 1 1 0 1
装饰tabyls
adorn_函数修饰这些制表调用的结果,以实现快速、基本的报告。以下是一些增强报告汇总表的功能:
roster %>%
tabyl(employee_status, full_time) %>%
adorn_totals("row") %>%
adorn_percentages("row") %>%
adorn_pct_formatting() %>%
adorn_ns() %>%
adorn_title("combined")
#> employee_status/full_time No Yes
#> Administration 0.0% (0) 100.0% (1)
#> Coach 100.0% (2) 0.0% (0)
#> Teacher 33.3% (3) 66.7% (6)
#> Total 41.7% (5) 58.3% (7)
在您的RMarkdown报告中直接将它输入到knitter::kable()中。
这些模块化装饰可以分层,以减少R在快速、信息丰富的计数方面相对于Excel和SPSS的不足。从tabyls简介中了解更多关于tabyl()和adorn _ 函数的信息。