HashMap, HashTable, ConcurrentHashMap 之间的区别
目录
- 关于线程安全
- HashTable 和 ConcurrentHashMap 的区别
-
- 1. ==加锁粒度不同==(最关键 最核心的区别!!!)
- 2. ConcurrentHashMap 利用了 CAS 机制 (无锁编程)
- 3. 优化了扩容策略
关于线程安全
我们知道 HashMap 是线程不安全的.
如果要在多线程环境下使用哈希表, 则可以使用:HashTable ConcurrentHashMap.
HashTable 是给关键方法加上锁, 给方法加锁就相当于针对 this 加锁.
HashTable 和 ConcurrentHashMap 的区别
1. 加锁粒度不同(最关键 最核心的区别!!!)
什么是锁粒度呢?
就是 synchronized 代码块所含代码的多少.(代码越多 粒度越粗, 代码越少 粒度越细)
引申: 锁粗化
写代码时, 一般情况下, 我们希望锁的粒度小一点更好.(串行执行的代码少, 并发执行的代码多)
如果某个场景要频繁加锁和解锁, 此时编译器就可能把这几个加锁解锁操作优化成一个更粗粒度的锁.(每次加锁解锁都会有开销, 特别是释放完锁后重新加锁, 这时就要重新进行锁竞争)
为什么加锁粒度不同呢?
HashTable 是针对整个哈希表加锁, 任何的增删改查操作都会触发加锁, 也就都可能触发锁竞争.
我们知道哈希表是一个数组, 每个数组元素都是一条链表, 当链表达到一定长度后, 链表就会被替换为红黑树.
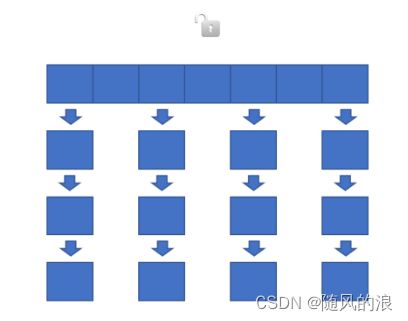
这样加锁固然能使其线程安全, 但它的效率就大大降低了.
假设一个这样的场景, 我们同时对每条链表都进行一次修改, 显然这些修改不会相互影响, 但会引发锁冲突, 导致阻塞等待, 使代码执行效率大大降低.
竟然如此, 那我们可以多加几把锁, 将每条链表都加上不同的锁, 这样对不同的链表进行操作就不会产生阻塞等待了, 大大提到代码效率. 这便是ConcurrentHashMap 的加锁方式.

它是如何实现每个链表都加上不同的锁呢?
针对每个操作, 我们都在获取到头节点后, 将链表的头节点放入 synchronized 中, 因为每个头节点都不同, 所以每把锁的锁对象都不同, 极大的降低了锁冲突.
给每个链表加锁是从 Java8 开始的, 在 Java1.7 之前 ConcurrentHashMap 是使用 “分段锁”, 什么是分段锁呢? 其实就是好几个链表共用一把锁.(“分段锁” 效率不高, 代码写起来也麻烦)
2. ConcurrentHashMap 利用了 CAS 机制 (无锁编程)
有些操作可以直接使用 CAS 完成, 比如获取/更新元素个数.
CAS 也能保证线程安全, 往往比锁更高效, 但是适用范围没有锁广泛.
3. 优化了扩容策略
对于 HashTable, 如果元素太多了, 就会涉及到扩容, 根据负载因子来决定是否扩容, 扩容就要重新申请一段内存空间, 把数组元素从旧哈希表上删除, 添加到新哈希表上.
如果哈希表上元素有很多 都上亿了, 那么搬运一次的成本将非常高, 导致 put 操作将非常卡顿.
对于 ConcurrentHashMap 它的搬运策略是 化整为零.
当 put 触发了触发扩容, 此时就会申请一块更大的内存空间, 但并不会一次就把元素搬运完, 而是搬运一部分(每次对哈希表进行操作时, 都搬运一小部分).此时就会有两个哈希表, 这时添加新元素时, 就是往新表插入;
删除, 查找, 修改元素时 就是对新旧两个表进行查找, 再进行操作.
(虽然相比 HashTable 多了浪费了一块空间, 但为了效率还是值得的)