Kotlin基础学习笔记之第五章——lambda编程
lamda表达式,或者简称lamda,本质上就是可以传递给其他函数的 一小段代码。有了lamda,可以轻松地把通用的代码结构抽取成库函数,kotlin标准库就大量地使用了他们。最常见的一种lamda用途就是和集合一起工作。
1、lamda表达式和成员引用
函数式编程:把函数当做值来对待。可以直接传递函数,而不需要先声明一个类再传递这个类的实例。使用lamda表达式之后,代码会更加简洁。都不需要声明函数了:相反,可以高效地直接传递代码块作为函数参数。 
可以看到,实现的功能是一样的,但是使用lamda更简洁。
lamda和集合
假设现在有一个人的列表,需要找到列表中年龄最大的那个人。
maxBy函数可以在任何集合上调用,且只需要一个实参:一个函数,指定比较哪个值来找到最大元素。花括号中的代码{it.age}就是实现了这个逻辑的lamda。它接收一个集合中的元素作为实参(使用it引用它)并且返回用来比较的值。
如果lamda刚好是函数或者属性的委托,可以用成员引用替换:
people.maxBy(Person::age)来看看kotlin库函数maxBy的源码实现
/**
* Returns the first element yielding the largest value of the given function or `null` if there are no elements.
*
* @sample samples.collections.Collections.Aggregates.maxBy
*/
public inline fun > Iterable.maxBy(selector: (T) -> R): T? {
val iterator = iterator()
if (!iterator.hasNext()) return null
var maxElem = iterator.next()
if (!iterator.hasNext()) return maxElem
var maxValue = selector(maxElem)
do {
val e = iterator.next()
val v = selector(e)
if (maxValue < v) {
maxElem = e
maxValue = v
}
} while (iterator.hasNext())
return maxElem
} 可以看到只要是Iterable
lamda表达式的语法
一个lamda把一小段行为进行编码,你能把它当做值到处传递。它可以被独立地声明并存储到一个变量中。但更常见的还是直接声明它并传递给函数。

kotlin的lamda表达式始终用花括号包围。注意实参并没有用括号括起来,箭头把实参列表和lamda的函数体隔开。
people.max {it.age}如果不用任何简明语法来重写上面代码,将会是
people.maxBy({p: Person -> p.age})这代码一目了然:花括号中的代码片段是lamda表达式,把它作为实参传给函数。这个lamda接收一个类型为Person的参数并返回它的年龄。
kotlin有这样一种语法规定:如果lamda表达式是函数调用的最后一个参数,它可以放到括号的外边。
people.maxBy() {p: Person -> p.age}当lamda是函数唯一的实参时,还可以去掉调用代码中的空括号对:
people.maxBy {p: Person -> p.age}如果你想传递两个或者更多的lamda,不能把超过一个的lamda放到外面。

还可以继续简化:移除参数的类型:
 和局部变量一样,如果lamda参数的类型可以被推导出来,你就不需要显式地指定它。以这里的maxBy为例,其参数类型始终和集合的元素类型相同。编译器知道你是对一个Person对象的集合调用 maxBy 函数,所以它能推断 lambda参数也会是Person类型。
和局部变量一样,如果lamda参数的类型可以被推导出来,你就不需要显式地指定它。以这里的maxBy为例,其参数类型始终和集合的元素类型相同。编译器知道你是对一个Person对象的集合调用 maxBy 函数,所以它能推断 lambda参数也会是Person类型。
也存在编译器不能推断出lambda参数类型的情况,但这里暂不讨论。可以遵循这样一条简单的原则:先不声明类型,等编译器报错后再制定他们。
可以指定部分实参的类型,而剩下的实参只用名称。如果编译器不能推导出其中一种类型,又或者是显式的类型可以提升可读性,这种做法或许更方便。
上面的代码还能进一步简化:使用默认参数名称it代替命名参数。如果当前上下文期望的是只有一个参数的lambda且这个参数的类型是可以推导出来,就会生成这个名称。

如果使用变量存储lambda,那么就没有可以推断出参数类型的上下文,所以你必须显示地指定参数类型:
![]()
lambda并没有限制函数体的规模,它可以包含更多的语句。lambda函数体最后一条语句就是lambda的结果:

在作用域中访问变量
当在函数内声明一个匿名内部类的时候,能够在这个匿名内部类内部引用这个函数的参数和局部变量。使用lambda也可以做同样的事情。如果在函数内部使用lambda,也可以访问这个函数的参数,还有在lambda之前定义的局部变量。
用标准库函数forEach来展示这种行为。它是最基本的集合操作函数之一:它所做的全部事情就是在集合中的每一个元素上都调用给定的lambda。forEach函数比普通的for循环更简洁一点,但它并没有更多的其他优势。
/**
* Performs the given [action] on each element.
*/
@kotlin.internal.HidesMembers
public inline fun Iterable.forEach(action: (T) -> Unit): Unit {
for (element in this) action(element)
} 
kotlin和java的一个显著区别是:kotlin中不会仅限于访问final变量,在lambda内部也可以修改这些变量。
从lambda内部访问外部变量,我们称这些变量被lambda捕捉。
注意,默认情况下,局部变量的生命周期被限制在声明这个变量的函数中。但是如果它被lambda捕捉了,使用这个变量的代码可以被存储并稍后再执行。其背后的原理是:当你捕捉final变量时,它的值和使用这个值的lambda代码一起存储。而对非final变量来说,它的值被封装在一个特殊的包装器中,这样你就可以改变这个值,而对这个包装器的引用会和lambda代码一起存储。

这里还有一个重要的注意事项,如果lambda被用作事件处理器或用在其他异步执行的情况,对局部变量的修改只会在lambda执行的时候发生。

成员引用
如果你想要当做参数传递的代码已经被定义成了函数,该怎么办? 当然可以传递一个调用这个函数的lambda。但是这样做有点多余。
kotlin和java8一样,如果把函数转换成一个值,你就可以传递它。使用::运算符来转换:
val getAge = Person::age这种表达式被称为成员引用,它提供了简明语法,来创建一个调用单个方法或者访问单个属性的函数值。 双冒号把类名称与你想要引用的成员(一个方法或者一个属性)名称隔开。

它等同于
val getAge = {person: Person -> person.age}注意,不管你引用的是函数还是属性,都不要再成员引用的名称后面加括号。
成员引用和调用该函数的lambda具有一样的类型,所以可以互换使用:
people.maxBy(Person::age)还可以引用顶层函数(不是类的成员):

这种情况下,你省略了类名称,直接以::开头。成员引用::sault被当做实参传递给库函数run,它会调用相应的函数。
如果lambda要委托给一个接收多个参数的函数,提供成员引用代替它将会非常方便:
 可以用构造方法引用存储或者延期执行创建类实例的动作。构造方法引用的形式是在双冒号后指定类名称。(为什么要这么做,直接通过类名创建实例不就可以了吗?)
可以用构造方法引用存储或者延期执行创建类实例的动作。构造方法引用的形式是在双冒号后指定类名称。(为什么要这么做,直接通过类名创建实例不就可以了吗?)

注意,还可以用同样的方式引用扩展函数:
fun Person.isAdult() = age >= 21
val predicate = Person::isAdult尽管isAdult不是Person类的成员,还是可以通过引用访问它,这和访问实例的成员没什么两样:person.isAdult()。

二、集合的函数式API
1、基础:filter和map
filter和map函数形成了集合操作的基础,很多集合操作都是借助于他们来表达的。

filter函数可以从集合中移除你不想要的元素,但是它并不会改变这些元素。
来看看filter的源码实现:
/**
* Returns a list containing only elements matching the given [predicate].
*
* @sample samples.collections.Collections.Filtering.filter
*/
public inline fun Iterable.filter(predicate: (T) -> Boolean): List {
return filterTo(ArrayList(), predicate)
}
/**
* Appends all elements matching the given [predicate] to the given [destination].
*/
public inline fun > Iterable.filterTo(destination: C, predicate: (T) -> Boolean): C {
for (element in this) if (predicate(element)) destination.add(element)
return destination
} 如果变换元素需要使用map。map函数对集合中的每一个元素应用给定的函数并把结果手机到一个新集合。
如果你想打印的只是一个姓名列表,而不是人的完整信息,可以使用map来变换列表:

来看看map的源码:
/**
* Returns a list containing the results of applying the given [transform] function
* to each element in the original collection.
*
* @sample samples.collections.Collections.Transformations.map
*/
public inline fun Iterable.map(transform: (T) -> R): List {
return mapTo(ArrayList(collectionSizeOrDefault(10)), transform)
}
/**
* Applies the given [transform] function to each element of the original collection
* and appends the results to the given [destination].
*/
public inline fun > Iterable.mapTo(destination: C, transform: (T) -> R): C {
for (item in this)
destination.add(transform(item))
return destination
} 除了对List列表进行操作,还可以对Map应用过滤和变换函数:
2、all、any、count和find:对集合应用判断式
另一种常见的任务是检查集合中的所有元素是否符合某个条件(或者它的变种,是否存在符合的元素)。kotlin中,它们是通过all和any函数来表达的。
如果你对所有元素都满足判断式感兴趣,应该使用all函数。

如果你需要检查集合中是否至少存在一个匹配的元素,那就使用any:
![]()
注意,!all(不是所有)加上某个条件,可以用any加上这个条件的取反来替换,反之亦然。 
如果你想知道有多少元素满足判断式,使用count:

要找到一个满足判断式的元素,使用find函数:

3、groupBy:把列表转换成分组的map
假设你需要把所有元素按照不同的特征划分成不同的分组。例如,把人按年龄进行分组,相同年龄的人放在一组。把这个特征直接当做参数传递十分方便。

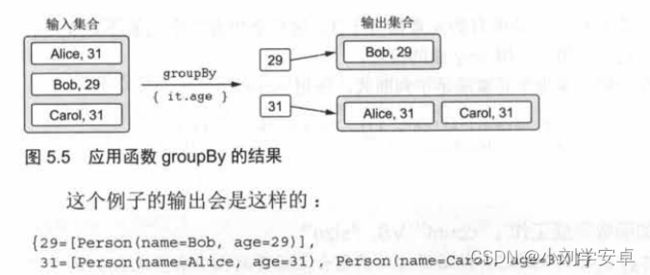 每一个分组都是存放在一个列表中,结果的类型就是Map
每一个分组都是存放在一个列表中,结果的类型就是Map
 来看看groupBy的源码:
来看看groupBy的源码:
/**
* Groups elements of the original collection by the key returned by the given [keySelector] function
* applied to each element and returns a map where each group key is associated with a list of corresponding elements.
*
* The returned map preserves the entry iteration order of the keys produced from the original collection.
*
* @sample samples.collections.Collections.Transformations.groupBy
*/
public inline fun Iterable.groupBy(keySelector: (T) -> K): Map> {
return groupByTo(LinkedHashMap>(), keySelector)
}
/**
* Groups elements of the original collection by the key returned by the given [keySelector] function
* applied to each element and puts to the [destination] map each group key associated with a list of corresponding elements.
*
* @return The [destination] map.
*
* @sample samples.collections.Collections.Transformations.groupBy
*/
public inline fun >> Iterable.groupByTo(destination: M, keySelector: (T) -> K): M {
for (element in this) {
val key = keySelector(element)
val list = destination.getOrPut(key) { ArrayList() }
list.add(element)
}
return destination
} 3、惰性集合操作:序列
上面的链式集合函数,比如map和filter,这些函数会及早地创建中间集合,也就是说每一步的中间结果都被存储在一个临时列表。序列给了你执行这些操作的另一种选择,可以避免创建这些临时中间对象。
people.map(Person::name).filter { it.startWith("A")}filter和map都会返回一个列表。这意味着上面的链式调用会创建两个表:一个保存filter函数的结果,另一个保存map函数的结果。如果源列表只有两个元素,这不会有什么问题,但是如果有一百万个元素,链式调用就会变得十分低效。
为了提高效率,可以把操作变成使用序列,而不是直接使用集合:
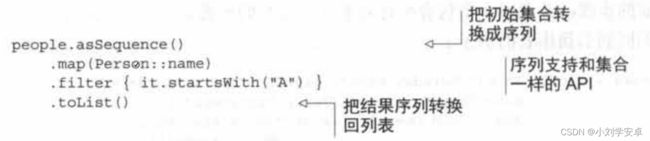
使用序列后没有创建任何用于存储元素的中间集合,所以元素数量巨大的情况下性能将显著提升。
kotlin惰性集合操作的入口就是Sequence接口。这个接口表示的就是一个可以逐个列举元素的元素的序列。Sequence只提供了一个方法,iterator,用来从序列中获取值。
Sequence接口的强大之处在于其操作的实现方式。序列中的元素求值是惰性的。因此,可以使用序列更高效地对集合元素执行链式操作,而不需要创建额外的集合来保存过程中产生的中中间结果。
可以调用扩展函数asSequence把任意集合转换成序列,调用toList来做反向的转换。
为什么需要把序列转换回集合?用序列代替集合不是更方便吗?特别是它们还有这么多优点。答案是:有时候是这样,如果你只需要迭代序列中的元素,可以直接使用序列。如果你要用其他的api方法,比如用下标访问元素,那么需要把序列转换成列表。
来看看序列是如何做到惰性求值的。下面是其源码,从源码中我们能窥见一二:
/**
* Creates a [Sequence] instance that wraps the original collection returning its elements when being iterated.
*
* @sample samples.collections.Sequences.Building.sequenceFromCollection
*/
public fun Iterable.asSequence(): Sequence {
return Sequence { this.iterator() }
} 可以看到,Iteratable的实现类(列表是其实现类之一)的asSequence方法利用Iteratable的迭代器iterator创建一个序列对象Seqence。
/**
* Returns a sequence containing only elements matching the given [predicate].
*
* The operation is _intermediate_ and _stateless_.
*
* @sample samples.collections.Collections.Filtering.filter
*/
public fun Sequence.filter(predicate: (T) -> Boolean): Sequence {
return FilteringSequence(this, true, predicate)
}
/**
* A sequence that returns the values from the underlying [sequence] that either match or do not match
* the specified [predicate].
*
* @param sendWhen If `true`, values for which the predicate returns `true` are returned. Otherwise,
* values for which the predicate returns `false` are returned
*/
internal class FilteringSequence(
private val sequence: Sequence,
private val sendWhen: Boolean = true,
private val predicate: (T) -> Boolean
) : Sequence {
override fun iterator(): Iterator = object : Iterator {
val iterator = sequence.iterator()
var nextState: Int = -1 // -1 for unknown, 0 for done, 1 for continue
var nextItem: T? = null
private fun calcNext() {
while (iterator.hasNext()) {
val item = iterator.next()
if (predicate(item) == sendWhen) {
nextItem = item
nextState = 1
return
}
}
nextState = 0
}
override fun next(): T {
if (nextState == -1)
calcNext()
if (nextState == 0)
throw NoSuchElementException()
val result = nextItem
nextItem = null
nextState = -1
@Suppress("UNCHECKED_CAST")
return result as T
}
override fun hasNext(): Boolean {
if (nextState == -1)
calcNext()
return nextState == 1
}
}
} filter方法利用Sequence自身对象封装成了FilteringSequence。FilteringSequence是Sequence的实现类,它只是实现了iterator()方法。在iterator()方法中利用lambda表达式对元素类型进行转换。iterator()方法返回一个迭代器对象,实现了next,hasNext方法用于在迭代过程中获取循环值。可以看到,filter函数返回的是一个Sequence对象,其内部封装了一个迭代器可以在循环中遍历值。
看懂了filter,map函数的原理也是一样的了:
/**
* Returns a sequence containing the results of applying the given [transform] function
* to each element in the original sequence.
*
* The operation is _intermediate_ and _stateless_.
*
* @sample samples.collections.Collections.Transformations.map
*/
public fun Sequence.map(transform: (T) -> R): Sequence {
return TransformingSequence(this, transform)
}
/**
* A sequence which returns the results of applying the given [transformer] function to the values
* in the underlying [sequence].
*/
internal class TransformingSequence
constructor(private val sequence: Sequence, private val transformer: (T) -> R) : Sequence {
override fun iterator(): Iterator = object : Iterator {
val iterator = sequence.iterator()
override fun next(): R {
return transformer(iterator.next())
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
internal fun flatten(iterator: (R) -> Iterator): Sequence {
return FlatteningSequence(sequence, transformer, iterator)
}
} map函数也是返回一个Sequence的子类TransformingSequence。其内部的iterator()放回一个迭代器对象用来遍历并转换元素。
可以看到,filter和map函数都没有进行任何实质性的操作,而是封装了不同类型的对象。
1、执行序列操作:中间和末端操作
序列操作可以分为两类:中间的和末端的。一次中间操作返回的是另一个序列,这个新序列知道如何变换原始序列中的元素。而一次末端操作返回的是一个结果,这个结果可能是集合、元素、数字,或者其他从初始集合的变换序列中获取的任意对象。

中间操作始终是惰性的。 对序列来说,所有操作时按顺序应用在每一个元素上:处理完第一个元素(先映射再过来),然后完成第二个元素的处理,以此类推。
对序列来说,所有操作时按顺序应用在每一个元素上:处理完第一个元素(先映射再过来),然后完成第二个元素的处理,以此类推。
listOf(1, 2, 3, 4).asSequence().map {it * it}.find {it > 3}如果同样的操作被应用在集合上而不是序列上,那么map的结果首先被求出来,即变换初始集合中的所有元素。第二步,中间集合中满足判断式的一个元素会被找出来。
而对于序列来说,惰性方法以为着你可以跳过处理部分元素。
使用集合是及早求值,使用序列是惰性求值。

可以看到,惰性操作大大提高了效率。
注意:在集合上执行操作的顺序也会影响性能。

 如果map在前,每个元素都被变换。而如果filter在前,不合适的元素会被尽早地被过来掉且不会发生变换。
如果map在前,每个元素都被变换。而如果filter在前,不合适的元素会被尽早地被过来掉且不会发生变换。
最后来看看序列的toList()末端操作是如何返回结果的。
/**
* Returns a [List] containing all elements.
*
* The operation is _terminal_.
*/
public fun Sequence.toList(): List {
return this.toMutableList().optimizeReadOnlyList()
} /**
* Returns a [MutableList] filled with all elements of this sequence.
*
* The operation is _terminal_.
*/
public fun Sequence.toMutableList(): MutableList {
return toCollection(ArrayList())
} /**
* Appends all elements to the given [destination] collection.
*
* The operation is _terminal_.
*/
public fun > Sequence.toCollection(destination: C): C {
for (item in this) {
destination.add(item)
}
return destination
} 到这里终于知道是如何返回结果了。toCollection函数中传入了一个新创建的空列表用来保存结果。在toCollection函数体中使用for循环对序列进行遍历。序列会调用自己的迭代器遍历到每一个元素。注意,序列在调用自己的迭代器获取当前值的时候,知道如何从最初的集合中元素如何经过一些列中间操作,最后计算出最终结果。
2、创建序列
前面的例子都是使用同一个方法创建序列:在集合上调用asSequence()。另一种可能性是使用generateSequence函数。给定序列中的前一个元素,这个函数会计算出下一个元素。

注意,这个例子中的naturalNumbers和numbersTo100都是有延期操作的序列。这些序列中的实际数字直到你调用了末端操作(这里是sum)的时候才会求值。
另一种常见的用例是父序列。如果元素的父元素和它的类型相同(比如人类和java文件),你可能会对它所有祖先组成的序列的特质感兴趣。下面的例子可以查询文件是否存放在隐藏目录中。通过创建一个其父目录的序列并检查每个目录的属性来实现。
最后,还是要来看看generateSequence源码是如何基于初始值创建序列的。
/**
* Returns a sequence defined by the starting value [seed] and the function [nextFunction],
* which is invoked to calculate the next value based on the previous one on each iteration.
*
* The sequence produces values until it encounters first `null` value.
* If [seed] is `null`, an empty sequence is produced.
*
* The sequence can be iterated multiple times, each time starting with [seed].
*
* @see kotlin.sequences.sequence
*
* @sample samples.collections.Sequences.Building.generateSequenceWithSeed
*/
@kotlin.internal.LowPriorityInOverloadResolution
public fun generateSequence(seed: T?, nextFunction: (T) -> T?): Sequence =
if (seed == null)
EmptySequence
else
GeneratorSequence({ seed }, nextFunction) private class GeneratorSequence(private val getInitialValue: () -> T?, private val getNextValue: (T) -> T?) : Sequence {
override fun iterator(): Iterator = object : Iterator {
var nextItem: T? = null
var nextState: Int = -2 // -2 for initial unknown, -1 for next unknown, 0 for done, 1 for continue
private fun calcNext() {
nextItem = if (nextState == -2) getInitialValue() else getNextValue(nextItem!!)
nextState = if (nextItem == null) 0 else 1
}
override fun next(): T {
if (nextState < 0)
calcNext()
if (nextState == 0)
throw NoSuchElementException()
val result = nextItem as T
// Do not clean nextItem (to avoid keeping reference on yielded instance) -- need to keep state for getNextValue
nextState = -1
return result
}
override fun hasNext(): Boolean {
if (nextState < 0)
calcNext()
return nextState == 1
}
}
} 重点在第二段代码中的iterator()函数中迭代获取下一个元素的计算方式上,可以看到calNext函数会调用nextItem = getNextValue(nextItem!!)来获取下一个值(这里可以看到,获取下一个元素值是基于上一个元素值计算的),其中getNextValue函数就是最开始传入到generateSequence的lambda表达式用来计算下一个元素。
4、使用java函数式接口

接口中只有一个方法,这种接口被称为函数式接口,或者SAM接口,SAM代表单抽象方法(simple abstract method)。kotlin允许你在调用接受函数式接口作为参数的方法时使用lambda,来保证你的kotlin代码即整洁又符合习惯。

把lambda当作参数传递给java方法
可以把lambda传给任何期望函数式接口的方法。
注意:当我们说“一个Runnable的实例”时,指的是“一个实现了Runnable接口的匿名类的实例”。编译器会帮你创建它,并使用lambda作为单抽象方法——这个例子是run方法——的方法体。
通过显式地创建一个实现Runnable的匿名对象也能达到同样的效果:

但是这里有一点不一样。当你显式地声明对象时,每次调用都会创建一个新的实例。使用lambda的情况不同:如果lambda没有访问任何来自定义它的函数的变量,相应的匿名类实例可以在多次调用之间重用:
如果lambda从包围它的作用域中捕捉了变量,每次调用就不再可能重用同一个实例了。这种情况下,每次调用时编译器都要创建一个新对象,其中存储着被捕捉的变量的值。

请注意这里讨论的为lambda创建一个匿名类,以及该类的实例的方式只对期望函数式接口的java方法有效,但是对集合使用kotlin扩展方法的方式并不适用。如果你把lambda传给标记成inline的kotlin函数,是不会创建任何匿名类的。而大多数的库函数都标记成了inline。详见8.2节。(这里我有个疑问:集合中的扩展方法的确都标记成了inline,但是序列中并没有,那序列为什么不需要标记为inline呢?)
如你所见,大多数情况下,从lambda到函数式接口实例的转换都是自动发生的,不需要你做什么。但是也存在需要显式地执行转换的情况。
SAM构造方法:显式地把lambda转换成函数式接口
SAM构造方法是编译器生成的函数,让你执行从lambda到函数式接口实例的显式转换。可以在编译器不会自动应用转换的上下文中使用它。例如,如果有一个方法返回的是一个函数式接口的实例,不能之间返回一个lambda,要用SAM构造方法把它包装起来。
 SAM构造方法的名称和底层函数式接口的名称一样。SAM构造方法只接收一个参数——一个被用作函数式接口单抽象方法体的lambda——并返回实现了这个接口的类的一个实例。
SAM构造方法的名称和底层函数式接口的名称一样。SAM构造方法只接收一个参数——一个被用作函数式接口单抽象方法体的lambda——并返回实现了这个接口的类的一个实例。
除了返回值外,SAM构造方法还可以用在需要把从lambda生成的函数式接口实例存储在一个变量中的情况。假如你要在多个按钮上重用一个监听器。

还有,尽管方法中调用的SAM转换一般都自动发生,但是当把lambda作为实参传给一个重载方法时,也有编译器不能选择正确的重载方法。这时候,时候显式的SAM构造方法时解决编译器错误的好方法。
5、带接收者的lambda:with和apply
1、with函数
很多语言都有这样的语句,可以用它对同一个对象执行多次操作,而不需要反复把对象的名称写出来。kotlin中也不例外,但它提供的是一个叫with的库函数,而不是某种特殊的语言结构。
 with结构看起来像一个特殊的语法结构,但它实际上是一个接收两个参数的函数:这个例子中两个参数分别是stringBuilder和一个lambda。
with结构看起来像一个特殊的语法结构,但它实际上是一个接收两个参数的函数:这个例子中两个参数分别是stringBuilder和一个lambda。
with函数把它的第一个参数转换成作为第二个参数传给它的lambda的接收者。可以显式地通过this引用来访问这个接收者。或者,按照惯例,可以省略this引用,不用任何限定符直接访问这个值的方法和属性。
 现在这个函数只返回一个表达式,所以使用表达式函数体语法重写了它。
现在这个函数只返回一个表达式,所以使用表达式函数体语法重写了它。
with返回的值是执行lambda代码的结果,该结果就是lambda中的最后一个表达式(的值)。但有时候你想返回的是接收者对象,而不是执行lambda的结果。这是apply库函数就派上用场了。
到这里,一定很好奇with函数内部是如何实现的,下面看看它的源码来一探究竟。
/**
* Calls the specified function [block] with the given [receiver] as its receiver and returns its result.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#with).
*/
@kotlin.internal.InlineOnly
public inline fun with(receiver: T, block: T.() -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return receiver.block()
} 注意看上面的代码,block: T.() -> R需要好好理解一下。首先() -> R代表的是一个lambda函数。T.() -> R代表这个lambda函数是T类型的扩展函数。这意味着传给with的实参lambda将会是T类型的扩展函数。既然lambda是T类型的扩展函数,所以可以直接使用T的实例,即with的第一个参数来调用第二个参数,即lambda。并且lambda作为类型T的扩展函数,所有其函数体内可以直接调用类型T的方法及属性。
2、apply函数
apply函数几乎和with函数一模一样,唯一的区别是apply始终会返回作为实参传递给它的对象(换句话说,接收者对象)。
 apply被声明成一个扩展函数。它的接收者变成了作为实参的lambda的接收者。
apply被声明成一个扩展函数。它的接收者变成了作为实参的lambda的接收者。
很多情况下apply都很有效,其中一种是在创建一个对象实例并需要正确的方式初始化它的一些属性的时候。在java中,这通常是通过另外一个单独的Builder对象来完成的;而在kotlin中,可以在任意对象上使用apply,完全不需要任何来自定义该对象的库的特别支持。

apply函数允许你使用紧凑的表达式函数体风格。with和apply函数时最基本和最通用的使用带接收者的lambda的例子。
最后还是按照惯例来看看apply函数的实现源码:
/**
* Calls the specified function [block] with `this` value as its receiver and returns `this` value.
*
* For detailed usage information see the documentation for [scope functions](https://kotlinlang.org/docs/reference/scope-functions.html#apply).
*/
@kotlin.internal.InlineOnly
public inline fun T.apply(block: T.() -> Unit): T {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
block()
return this
} 如果你对with函数的实现源码都吃透了,那么apply函数就很好理解了。