不吹牛,吃下我这篇,Spring面试这关算是过了(近2w字,源码级)
你好,我是yes。
这次是 Spring 面试题的总结,有些答案我写的都是源码级别的,吃下这篇,Spring 面试绝对稳了。
好了,话不多说,发车!
说下你理解的 Spring
可以从两个层面来理解 Spring。
第一个层面指的是 Spring Framework,是一个开源的应用框架,提供 IOC 和 AOP 降低了应用开发的复杂度。
第二个层面指的是 Spring 全家桶,Spring 发展到今天可以说几乎是统领了 Java,有关 Java 应用开发所需的全部功能, Spring 都提供了解决方案,包括对批处理的支持、对 web 的支持、对微服务的支持等。
这种题大致说一下就行了,不需要太多细节,面试官会接着追问的。
看过源码吗?说下 Spring 由哪些重要的模块组成?
Spring 最主要的核心就是 IOC 容器,这个容器根据我们的配置文件创建了各种 Bean 且编织它们之间的依赖关系,管理这些 Bean 的生命周期。
所以最核心的代码模块是:
- spring-core:核心类库,包括资源访问等一些工具类,别的模块都会依赖此模块
- spring-beans:对 Bean 的支持,包括控制反转和依赖注入,核心工厂 BeanFacotry 就在这个模块。
- spring-context:Spring 的上下文,支持数据验证、国际化、事件传播等支持,ApplicationContext 就在这里,可以理解为运行时的 Spring 容器。
基于上面的这些核心模块,Spring 也提供了很多重要的支持:
- spring-aop:AOP 的支持
- spring-jdbc:jdbc 的支持
- spring-orm: orm 的支持
- spring-webmvc: mvc 的支持
- 等等
什么是 IOC?
IOC,即 Inversion of Control,控制反转。
首先要明确 IOC 是一种思想,而不是一个具体的技术,其次 IOC 这个思想也不是 Spring 创造的。
然后我们要理解到底控制的是什么,其实就是控制对象的创建,IOC 容器根据配置文件来创建对象,在对象的生命周期内,在不同时期根据不同配置进行对象的创建和改造。
那什么被反转了?其实就是关于创建对象且注入依赖对象的这个动作,本来这个动作是由我们程序员在代码里面指定的,例如对象 A 依赖对象 B,在创建对象 A 代码里,我们需要写好如何创建对象 B,这样才能构造出一个完整的 A。
而反转之后,这个动作就由 IOC 容器触发,IOC 容器在创建对象 A 的时候,发现依赖对象 B ,根据配置文件,它会创建 B,并将对象 B 注入 A 中。
这里要注意,注入的不一定非得是一个对象,也可以注入配置文件里面的一个值给对象 A 等等。
至此,你应该明确了,控制和反转。
IOC 有什么好处?
对象的创建都由 IOC 容器来控制之后,对象之间就不会有很明确的依赖关系,使得非常容易设计出松耦合的程序。
例如,对象 A 需要依赖一个实现 B,但是对象都由 IOC 控制之后,我们不需要明确地在对象 A 的代码里写死依赖的实现 B,只需要写明依赖一个接口,这样我们的代码就能顺序的编写下去。
然后,我们可以在配置文件里定义 A 依赖的具体的实现 B,根据配置文件,在创建 A 的时候,IOC 容器就知晓 A 依赖的 B,这时候注入这个依赖即可。
如果之后你有新的实现需要替换,那 A 的代码不需要任何改动,你只需要将配置文件 A 依赖 B 改成 B1,这样重启之后,IOC 容器会为 A 注入 B1。
这样就使得类 A 和类 B 解耦了, very nice!
并且也因为创建对象由 IOC 全权把控,那么我们就能很方便的让 IOC 基于扩展点来“加工”对象,例如我们要代理一个对象,IOC 在对象创建完毕,直接判断下这个对象是否需要代理,如果要代理,则直接包装返回代理对象。
这等于我们只要告诉 IOC 我们要什么,IOC 就能基于我们提供的配置文件,创建符合我们需求的对象。
正是这个控制反转的思想,解放了我们的双手。
什么是 DI
DI,Dependency Injection,依赖注入。
普遍的答案是 DI 是 IOC 的一种实现。
其实它跟 IOC 的概念一致,只是从不同角度来描述罢了。
Martin Fowler 提出了 DI 的概念,它觉得用 DI 来形容更加具体。
大致理解为容器在运行的时候,可以找到被依赖的对象,然后将其注入,通过这样的方式,使得各对象之间的关系可由运行期决定,而不用在编码时候明确。
什么是 Bean
可以认为,由 Spring 创建的、用于依赖注入的对象,就是 Bean。
例如调用 getBean 能返回的玩意,就是 Bean。
BeanFactory 什么用
BeanFactory 其实就是 IOC 的底层容器。
我们都说 Spring 是 IOC 容器,说的再直白点,其实就是 Bean 的工厂,它帮我们生产 Bean,如果我们需要 Bean 就从工厂拿到 bean,所以再来理解下 BeanFactory 这个名字,就知晓它就是 Spring 的核心。
例如我们调用 getBean ,这就是 BeanFactory 定义的方法,通过它得到 Bean。
不过一般我们所述的 BeanFactory 指的是它实现类,例如 DefaultListableBeanFactory。
BeanFactory 本身只是一个接口。
FactoryBean 又是啥
从命名角度来看,我们可以得知它就是一个 Bean,而不是一个工厂。
那为什么名字如此奇怪,它其实是一个接口,并且有以下几个方法
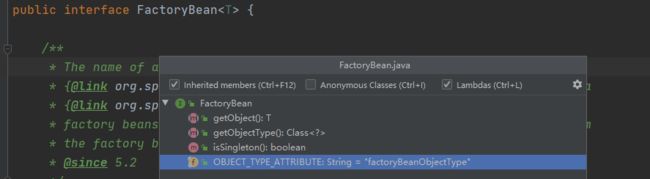
如果一个对象实现了这接口,那它就成为一种特殊的 Bean,注册到 IOC 容器之后,如果调用 getBean 获取得到的其实是 FactoryBean#getObject() 方法返回的结果。
为什么要这样做?
假设你依赖一个第三方的类 A,而我们又不能修改第三方的类,并且这个对象创建比较复杂,那么你就可以创建一个 bean 来封装它:
public class AFactoryBean implements FactoryBean<A> {
public A getObject() throws Exception {
A a = new A();
a.setXXX
....
...
return A
}
....省略一些实现
}
这样,我们 getBean(“A”) 会得到 AFactoryBean#getObject 的结果,如果单纯只想要 AFactoryBean, 那么加个 “&” 即可,即 getBean("&A")
ObjectFactory 又是啥
从命名角度来看,它是一个工厂。
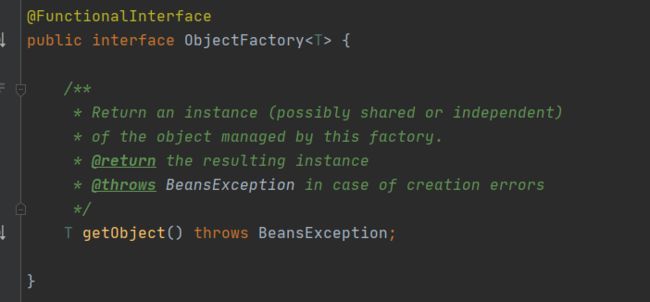
好吧,摊牌了,没啥特殊含义,就是一个工厂。
Spring 的循环依赖(后面会细说)里就用到它了,三级缓存的 map 里面存储的就是 ObjectFactory,用于延迟代理对象的创建。
其实就是封装对象的创建过程,像三级缓存里的 ObjectFactory 逻辑就是判断这个 Bean 是否有代理,如果有则返回代理对象,没有则返回原来传入的对象。
ApplicationContext 呢
ApplicationContext 对我们来说应该很熟悉,我们基本上都是基于 ApplicationContext 操作的。
它也继承了 BeanFactory 的实现类,也属于一个 BeanFactory ,但是它内部还包装了一个 BeanFactory 的实现,这属于组合。
简单理解就是我 ApplicationContext 虽然是个 BeanFactory ,但是关于 Bean 的操作我还是委托内部组合的 BeanFactory 。
即,关于 Spring Beans 的一些操作都是委托内部的 BeanFactory 来操作的。
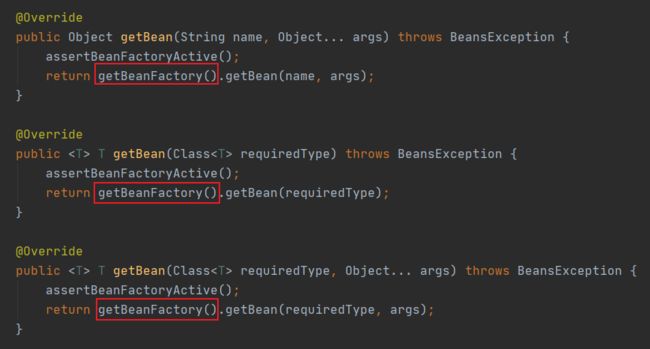
所以它有 BeanFactory 的所有功能。看到这肯定有同学发出疑问,那这玩意又啥用?
别急嘛,因为它还扩展了很多其他功能:
- AOP
- 国际化
- 资源管理
- 事件
- 注解
- 等等
因此,我们开发直接用的肯定是 ApplicationContext 而不是 BeanFactory。
Bean 一共有几种作用域
从官网,我们很容易可以得知,最新版本一共有六种作用域:

- singleton:默认是单例,含义不用解释了吧,一个 IOC 容器内部仅此一个
- prototype:原型,多实例
- request:每个请求都会新建一个属于自己的 Bean 实例,这种作用域仅存在 Spring Web 应用中
- session:一个 http session 中有一个 bean 的实例,这种作用域仅存在 Spring Web 应用中
- application:整个 ServletContext 生命周期里,只有一个 bean,这种作用域仅存在 Spring Web 应用中
- websocket:一个 WebSocket 生命周期内一个 bean 实例,这种作用域仅存在 Spring Web 应用中
别背网上那些多年前的答案了,以上才是最新的~
Spring 一共有几种注入方式
- 构造器注入,Spring 倡导构造函数注入,因为构造器注入返回给客户端使用的时候一定是完整的。
- setter 注入,可选的注入方式,好处是在有变更的情况下,可以重新注入。
- 字段注入,就是平日我们用 @Autowired 标记字段
- 方法注入,就是平日我们用 @Autowired 标记方法
- 接口回调注入,就是实现 Spring 定义的一些内建接口,例如 BeanFactoryAware,会进行 BeanFactory 的注入
其实官网上关于注入就写了构造器和setter :
像字段注入其实官方是不推荐的使用的,因为依赖注解,然后没有控制注入顺序且无法注入静态字段。
emmmm…怎么说呢,个人字段注入用的最多,你们呢,哈哈哈。
说下 AOP
AOP,Aspect Oriented Programming,面向切面编程。
将一些通用的逻辑集中实现,然后通过 AOP 进行逻辑的切入,减少了零散的碎片化代码,提高了系统的可维护性。
具体是含义可以理解为:通过代理的方式,在调用想要的对象方法时候,进行拦截处理,执行切入的逻辑,然后再调用真正的方法实现。
例如,你实现了一个 A 对象,里面有 addUser 方法,此时你需要记录该方法的调用次数。
那么你就可以搞个代理对象,这个代理对象也提供了 addUser 方法,最终你调用的是代理对象的 addUser ,在这个代理对象内部填充记录调用次数的逻辑,最终的效果就类似下面代码:
class A代理 {
A a;// 被代理的 A
void addUser(User user) {
count();// 计数
a.addUser(user);
}
}
最终使用的是:
A代理.addUser(user);
这就叫做面向切面编程,当然具体的代理的代码不是像上面这样写死的,而是动态切入。
实现上代理大体上可以分为:动态代理和静态代理。
- 动态代理,即在运行时将切面的逻辑进去,按照上面的逻辑就是你实现 A 类,然后定义要代理的切入点和切面的实现,程序会自动在运行时生成类似上面的代理类。
- 静态代理,在编译时或者类加载时进行切面的织入,典型的 AspectJ 就是静态代理。
Spring AOP默认用的是什么动态代理,两者的区别
Spring AOP 的动态代理实现分别是:JDK 动态代理与 CGLIB。
默认的实现是 JDK 动态代理。
ok,这个问题没毛病(对实际应用来说其实不太准确),然后面试官接着问那你平时有调试过吗,确定你得到的代理对象是 JDK 动态代理实现的?
然后你信誓旦旦的说,对,我们都实现接口的,所以是 JDK 动态代理。
然而你简历上写着项目使用的框架是 SpringBoot,我问你 SpringBoot 是什么版本,你说2.x。
然后我就可以推断,你没看过,你大概率仅仅只是网上看了相关的面试题。
要注意上面说的默认实现是 Spring Framework (最新版我没去验证),而 SpringBoot 2.x 版本已经默认改成了 CGLIB。
而我们现在公司大部分使用的都是 SpringBoot 2.x 版本,所以你要说默认 JDK 动态代理也没错,但是不符合你平日使用的情况,对吧?
如果你调试过,或者看过调用栈,你肯定能发现默认用的是 CGLIB(当然你要是没用 SpringBoot 当我没说哈):
![]()
市面上大部分面试题答案写的就是 JDK 动态代理,是没错,Spring 官网都这样写的,但是咱们现在不都是用 SpringBoot 了嘛,所以其实不符合我们当下使用的情况。
所以面试时候不要只说 Spring AOP 默认用的是 JDK 动态代理,把 SpringBoot 也提一嘴,这不就是让面试官刮目一看嘛(不过指不定面试官也不知道~)
如果要修改 SpringBoot 使用 JDK 动态代理,那么设置 spring.aop.proxy-target-class=false
如果你提了这个,那面试官肯定会追问:
那为什么要改成默认用 CGLIB?
嘿嘿,答案我也为你准备好了,我们来看看:

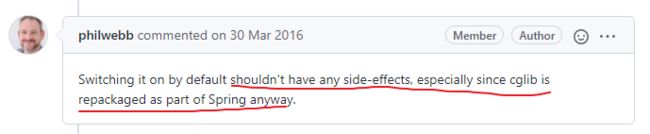
大佬说 JDK 动态代理要求接口,所以没有接口的话会有报错,很令人讨厌,并且让 CGLIB 作为默认也没什么副作用,特别是 CGLIB 已经被重新打包为 Spring 的一部分了,所以就默认 CGLIB 。
好吧,其实也没有什么很特殊的含义,就是效果没差多少,还少报错,方便咯。
详细issue 链接:https://github.com/spring-projects/spring-boot/issues/5423
JDK 动态代理
JDK 动态代理是基于接口的,也就是被代理的类一定要实现了某个接口,否则无法被代理。
主要实现原理就是:
- 首先通过实现一个 InvocationHandler 接口得到一个切面类。
- 然后利用 Proxy 糅合目标类的类加载器、接口和切面类得到一个代理类。
- 代理类的逻辑就是执行切入逻辑,把所有接口方法的调用转发到 InvocationHandler 的 invoke() 方法上,然后根据反射调用目标类的方法。
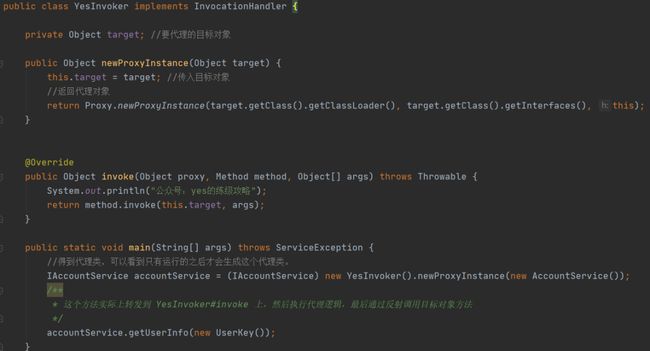
我们再深入一点点了解下原理实现。
如果你反编译的话,你能看到生成的代理类是会先在静态块中通过反射把所有方法都拿到存在静态变量中,(我盲写了一下)大致长这样:

上面就是把 getUserInfo 方法缓存了,然后在调用代理类的 getUserInfo 的时候,会调用你之前实现的 InvocationHandler 里面的 invoke,这样就执行到切入的逻辑了,且最终执行了被代理类的 getUserInfo 方法。
就是中间商拦了一道咯,道理就是这个道理。
CGLIB
如果被代理的类没有实现接口,那么就用 CGLIB 来完成动态代理。
CGLIB 是基于ASM 字节码生成工具,它是通过继承的方式来实现代理类,所以要注意 final 方法,这种方法无法被继承。
简单理解下,就是生成代理类的子类,如何生成呢?
通过字节码技术动态拼接成一个子类,在其中织入切面的逻辑。
使用例子:
Enhancer en = new Enhancer();
//2.设置父类,也就是代理目标类,上面提到了它是通过生成子类的方式
en.setSuperclass(target.getClass());
//3.设置回调函数,这个this其实就是代理逻辑实现类,也就是切面,可以理解为JDK 动态代理的handler
en.setCallback(this);
//4.创建代理对象,也就是目标类的子类了。
return en.create();
JDK 动态代理和 CGLIB 两者经常还可能被面试官问性能对比,所以咱们也列一下(以下内容取自:haiq的博客):
- jdk6 下,在运行次数较少的情况下,jdk动态代理与 cglib 差距不明显,甚至更快一些;而当调用次数增加之后, cglib 表现稍微更快一些
- jdk7 下,情况发生了逆转!在运行次数较少(1,000,000)的情况下,jdk动态代理比 cglib 快了差不多30%;而当调用次数增加之后(50,000,000), 动态代理比 cglib 快了接近1倍
- jdk8 表现和 jdk7 基本一致
我没试过,有兴趣的同学可以自己实验一下。
能说说拦截链的实现吗?
我们都知道 Spring AOP 提供了多种拦截点,便捷我们对 AOP 的使用,比如 @Before、@After、@AfterReturning、@AfterThrowing 等等。
方便我们在目标方法执行前、后、抛错等地方进行一些逻辑的切入。
那 Spring 具体是如何链起这些调用顺序的呢?
这就是拦截链干的事。
实际上这些注解都对应着不同的 interceptor 实现,然后 Spring 会利用一个集合把所有类型的 interceptor 组合起来,我在代码里用了 @Before、@After、@AfterReturning、@AfterThrowing这几个注解。
于是拦截链集合里就有了这些 interceptor(多了一个 expose…等下解释),这是由 Spring 扫描到注解自动加进来的:
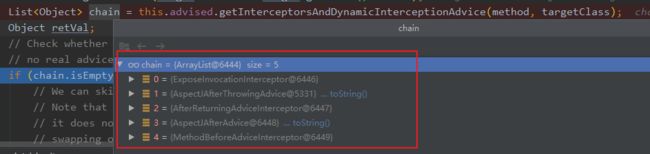
然后通过一个对象 CglibMethodInvocation 将这个集合封装起来,紧接着调用这个对象的 proceed 方法,可看到这个集合 chain 被传入了。

我们来看下 CglibMethodInvocation#proceed 方法逻辑。
要注意,这里就开始递归套娃了,核心调用逻辑就在这里:
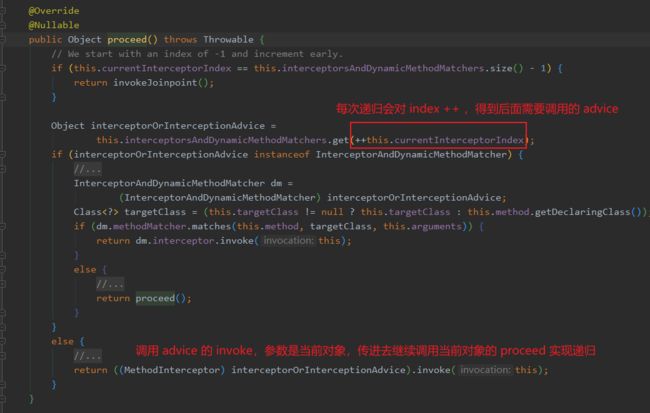
可以看到有个 currentInterceptorIndex 变量,通过递归,每次新增这索引值,来得到下一个 interceptor ,并且每次都传入当前对象并调用 interceptor#invoke ,这样就实现了拦截链的调用,所以这是个递归。
对于 interceptor 肯定有很多同学好奇内部的实现,我们拿集合里面的 MethodBeforeAdviceInterceptor 来举例看下,这个是目标方法执行的前置拦截,我们看下它的实现,有更直观的认识:

invoke 的实现是先执行切入的前置逻辑,然后再继续调用 CglibMethodInvocation#proceed(也就是mi.proceed),进行下一个 interceptor 的调用。可以看到还是挺简单的。
总结下:
Spring 根据 @Before、@After、@AfterReturning、@AfterThrowing 这些注解,往集合里面加入对应的 Spring 提供的 MethodInterceptor 实现,比如上面的 MethodBeforeAdviceInterceptor ,如果你没用 @Before,集合里就没有 MethodBeforeAdviceInterceptor 。
然后通过一个对象 CglibMethodInvocation 将这个集合封装起来,紧接着调用这个对象的 proceed 方法,具体是利用 currentInterceptorIndex 下标,利用递归顺序地执行集合里面的 MethodInterceptor ,这样就完成了拦截链的调用。
我截个调用链的堆栈截图,可以很直观地看到调用的顺序(从下往上看):
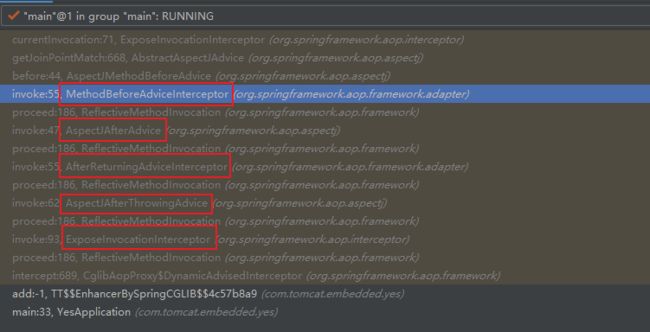
是吧,是按照顺序一个一个往后执行,然后再一个一个返回,就是递归呗。
然后我再解释下上面的 chain 集合我们看到第一个索引位置的 ExposeInvocationInterceptor 。
这个 Interceptor 作为第一个被调用,实际上就是将创建的 CglibMethodInvocation 这个对象存入 threadlocal 中,方便后面 Interceptor 调用的时候能得到这个对象,进行一些调用。

从名字就能看出 expose:暴露。
ok,更多细节还是得自己看源码的,应付面试了解到这个程度差不多的,上面几个关键点一抛,这个题绝对稳了!
Spring AOP 和 AspectJ 有什么区别
从上面的题目我们已经知道,两者分别是动态代理和静态代理的区别。
Spring AOP 是动态代理,AspectJ 是静态代理。
从一个是运行时织入,一个在编译时织入,我们稍微一想到就能知道,编译时就准备完毕,那么在调用时候没有额外的织入开销,性能更好些。
且 AspectJ 提供完整的 AOP 解决方案,像 Spring AOP 只支持方法级别的织入,而 AspectJ 支持字段、方法、构造函数等等,所以它更加强大,当然也更加复杂。
什么是循环依赖(常问)
很简单,看下方的代码就知晓了
@Service
public class A {
@Autowired
private B b;
}
@Service
public class B {
@Autowired
private A a;
}
//或者自己依赖自己
@Service
public class A {
@Autowired
private A a;
}
上面这两种方式都是循环依赖,应该很好理解,当然也可以是三个 Bean 甚至更多 Bean 相互依赖,原理都是一样的,今天我们主要分析两个 Bean 的依赖。

这种循环依赖可能会产生问题,例如 A 要依赖 B,发现 B 还没创建,于是开始创建 B ,创建的过程发现 B 要依赖 A, 而 A 还没创建好呀,因为它要等 B 创建好,就这样它们俩就搁这卡 bug 了。
Spring 如何解决循环依赖
上面这种循环依赖在实际场景中是会出现的,所以 Spring 需要解决这个问题,那如何解决呢?
关键就是提前暴露未完全创建完毕的 Bean。
在 Spring 中,只有同时满足以下两点才能解决循环依赖的问题:
- 依赖的 Bean 必须都是单例
- 依赖注入的方式,必须不全是构造器注入,且 beanName 字母序在前的不能是构造器注入
为什么必须都是单例
如果从源码来看的话,循环依赖的 Bean 是原型模式,会直接抛错:

所以 Spring 只支持单例的循环依赖,但是为什么呢?
按照理解,如果两个 Bean 都是原型模式的话,那么创建 A1 需要创建一个 B1,创建 B1 的时候要创建一个 A2,创建 A2 又要创建一个 B2,创建 B2 又要创建一个 A3,创建 A3 又要创建一个 B3…
就又卡 BUG 了,是吧,因为原型模式都需要创建新的对象,不能跟用以前的对象。
如果是单例的话,创建 A 需要创建 B,而创建的 B 需要的是之前的个 A, 不然就不叫单例了,对吧?
也是基于这点, Spring 就能操作操作了。
具体做法就是:先创建 A,此时的 A 是不完整的(没有注入 B),用个 map 保存这个不完整的 A,再创建 B ,B 需要 A,所以从那个 map 得到“不完整”的 A,此时的 B 就完整了,然后 A 就可以注入 B,然后 A 就完整了,B 也完整了,且它们是相互依赖的。
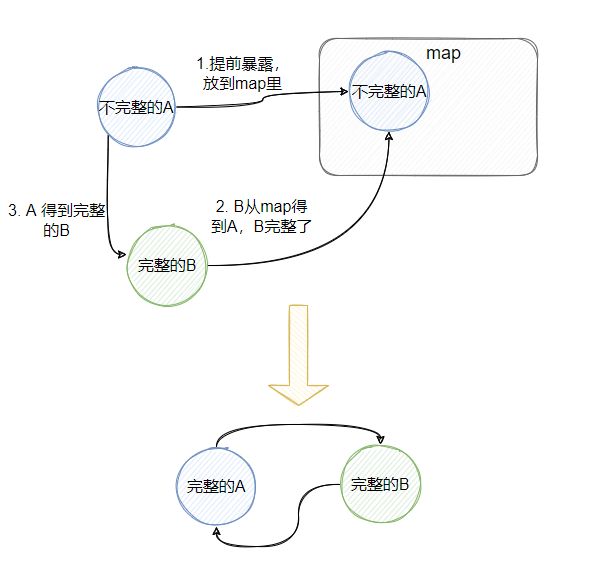
读起来好像有点绕,但是逻辑其实很清晰。
为什么不能全是构造器注入
在 Spring 中创建 Bean 分三步:
- 实例化,createBeanInstance,就是 new 了个对象
- 属性注入,populateBean, 就是 set 一些属性值
- 初始化,initializeBean,执行一些 aware 接口中的方法,initMethod,AOP代理等
明确了上面这三点,再结合我上面说的“不完整的”,我们来理一下:
如果全是构造器注入,比如A(B b),那表明在 new 的时候,就需要得到 B,此时需要 new B ,但是 B 也是要在构造的时候注入 A ,即B(A a),这时候 B 需要在一个 map 中找到不完整的 A ,发现找不到。
为什么找不到?因为 A 还没 new 完呢,所以找到不完整的 A,因此如果全是构造器注入的话,那么 Spring 无法处理循环依赖。
一个set注入,一个构造器注入一定能成功?
假设我们 A 是通过 set 注入 B,B 通过构造函数注入 A,此时是成功的。
我们来分析下:实例化 A 之后,此时可以在 map 中存入 A,开始为 A 进行属性注入,发现需要 B,此时 new B,发现构造器需要 A,此时从 map 中得到 A ,B 构造完毕,B 进行属性注入,初始化,然后 A 注入 B 完成属性注入,然后初始化 A。
整个过程很顺利,没毛病。
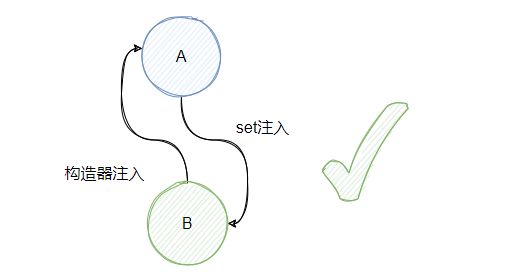
假设 A 是通过构造器注入 B,B 通过 set 注入 A,此时是失败的。
我们来分析下:实例化 A,发现构造函数需要 B, 此时去实例化 B,然后进行 B 的属性注入,从 map 里面找不到 A,因为 A 还没 new 成功,所以 B 也卡住了,然后就 gg。

看到这里,仔细思考的小伙伴可能会说,可以先实例化 B 啊,往 map 里面塞入不完整的 B,这样就能成功实例化 A 了啊。
确实,思路没错但是 Spring 容器(在同个包下,没有特殊 DependsOn等)是按照字母序创建 Bean 的,A 的创建永远排在 B 前面,
小贴士:排序跟包名也是有关系的,简单来说就是包名+类型,按字母序排
现在我们总结一下:
- 如果循环依赖都是构造器注入,则失败
- 如果循环依赖不完全是构造器注入,则可能成功,可能失败,具体跟包名+BeanName的字母序有关系。
Spring 解决循环依赖全流程
经过上面的铺垫,我想你对 Spring 如何解决循环依赖应该已经有点感觉了,接下来我们就来看看它到底是如何实现的。
明确了 Spring 创建 Bean 的三步骤之后,我们再来看看它为单例搞的三个 map:
- 一级缓存,singletonObjects,存储所有已创建完毕的单例 Bean (完整的 Bean)
- 二级缓存,earlySingletonObjects,存储所有仅完成实例化,但还未进行属性注入和初始化的 Bean
- 三级缓存,singletonFactories,存储能建立这个 Bean 的一个工厂,通过工厂能获取这个 Bean,延迟化 Bean 的生成,工厂生成的 Bean 会塞入二级缓存
这三个 map 是如何配合的呢?
- 首先,获取单例 Bean 的时候会通过 BeanName 先去 singletonObjects(一级缓存) 查找完整的 Bean,如果找到则直接返回,否则进行步骤 2。
- 看对应的 Bean 是否在创建中,如果不在直接返回找不到,如果是,则会去 earlySingletonObjects (二级缓存)查找 Bean,如果找到则返回,否则进行步骤 3
- 去 singletonFactories (三级缓存)通过 BeanName 查找到对应的工厂,如果存着工厂则通过工厂创建 Bean ,并且放置到 earlySingletonObjects 中。
- 如果三个缓存都没找到,则返回 null。
从上面的步骤我们可以得知,如果查询发现 Bean 还未创建,到第二步就直接返回 null,不会继续查二级和三级缓存。
返回 null 之后,说明这个 Bean 还未创建,这个时候会标记这个 Bean 正在创建中,然后再调用 createBean 来创建 Bean,而实际创建是调用方法 doCreateBean。
doCreateBean 这个方法就会执行上面我们说的三步骤:
- 实例化
- 属性注入
- 初始化
在实例化 Bean 之后,会往 singletonFactories 塞入一个工厂,而调用这个工厂的 getObject 方法,就能得到这个 Bean。
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
要注意,此时 Spring 是不知道会不会有循环依赖发生的,但是它不管,反正往 singletonFactories 塞这个工厂,这里就是提前暴露。
然后就开始执行属性注入,这个时候 A 发现需要注入 B,所以去 getBean(B),此时又会走一遍上面描述的逻辑,到了 B 的属性注入这一步。
此时 B 调用 getBean(A),这时候一级缓存里面找不到,但是发现 A 正在创建中的,于是去二级缓存找,发现没找到,于是去三级缓存找,然后找到了。
并且通过上面提前在三级缓存里暴露的工厂得到 A,然后将这个工厂从三级缓存里删除,并将 A 加入到二级缓存中。
然后结果就是 B 属性注入成功。
紧接着 B 调用 initializeBean 初始化,最终返回,此时 B 已经被加到了一级缓存里 。
这时候就回到了 A 的属性注入,此时注入了 B,接着执行初始化,最后 A 也会被加到一级缓存里,且从二级缓存中删除 A。
Spring 解决依赖循环就是按照上面所述的逻辑来实现的。
重点就是在对象实例化之后,都会在三级缓存里加入一个工厂,提前对外暴露还未完整的 Bean,这样如果被循环依赖了,对方就可以利用这个工厂得到一个不完整的 Bean,破坏了循环的条件。
为什么循环依赖需要三级缓存,二级不够吗?
上面都说了那么多了,那我们思考下,解决循环依赖需要三级缓存吗?
很明显,如果仅仅只是为了破解循环依赖,二级缓存够了,压根就不必要三级。
你思考一下,在实例化 Bean A 之后,我在二级 map 里面塞入这个 A,然后继续属性注入,发现 A 依赖 B 所以要创建 Bean B,这时候 B 就能从二级 map 得到 A ,完成 B 的建立之后, A 自然而然能完成。
所以为什么要搞个三级缓存,且里面存的是创建 Bean 的工厂呢?
我们来看下调用工厂的 getObject 到底会做什么,实际会调用下面这个方法:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
重点就在中间的判断,如果 false,返回就是参数传进来的 bean,没任何变化。
如果是 true 说明有 InstantiationAwareBeanPostProcessors ,且循环的 smartInstantiationAware 类型,如有这个 BeanPostProcessor 说明 Bean 需要被 aop 代理。
我们都知道如果有代理的话,那么我们想要直接拿到的是代理对象,也就是说如果 A 需要被代理,那么 B 依赖的 A 是已经被代理的 A,所以我们不能返回 A 给 B,而是返回代理的 A 给 B。
这个工厂的作用就是判断这个对象是否需要代理,如果否则直接返回,如果是则返回代理对象。
看到这明白的小伙伴肯定会问,那跟三级缓存有什么关系,我可以在要放到二级缓存的时候判断这个 Bean 是否需要代理,如果要直接放代理的对象不就完事儿了。
是的,这个思路看起来没任何问题,问题就出在时机,这跟 Bean 的生命周期有关系。
正常代理对象的生成是基于后置处理器,是在被代理的对象初始化后期调用生成的,所以如果你提早代理了其实是违背了 Bean 定义的生命周期。
所以 Spring 先在一个三级缓存放置一个工厂,如果产生循环依赖,那么就调用这个工厂提早得到代理对象,如果没产生依赖,这个工厂根本不会被调用,所以 Bean 的生命周期就是对的。
至此,我想你应该明白为什么会有三级缓存了。
也明白,其实破坏循环依赖,其实只有二级缓存就够了,但是碍于生命周期的问题,提前暴露工厂延迟代理对象的生成。
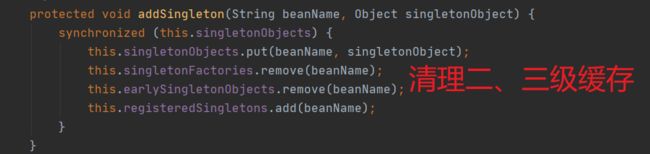
对了,不用担心三级缓存因为没有循环依赖,数据堆积的问题,最终单例 Bean 创建完毕都会加入一级缓存,此时会清理下面的二、三级缓存。
说下 Spring Bean 的生命周期
在说具体的生命周期前,我们需要先知晓之所以 Bean 容易被添加一些属性,或者能在运行时被改造就是因为在生成 Bean 的时候,Spring对外暴露出很多扩展点。
基于这些点我们可以设置一些逻辑,Spring 会在 Bean 创建的某些阶段根据这些扩展点,基于此进行 Bean 的改造。
有了上面的认识,我们再来看 Spring Bean 的生命周期,我用一幅图先总结一下:

大致了解生命周期之后,我们再来看详细的操作,可以看到有好多扩展点可以搞事情:

注意细节,这幅图的颜色和上面那副有对应关系的。
我再用文字描述一下:
- 实例化Bean
- 根据属性,注入需要的 Bean
- 如果 Bean 实现了 BeanNameAware 等 aware 接口,则执行 aware 注入
- 如果有 BeanPostProcessor,则执行
BeanPostProcessor#postProcessBeforeInitialization方法 - 如果 Bean 是 InitializingBean,则执行 afterPropertiesSet 方法
- 如果有 initMethod ,则执行
- 如果有 BeanPostProcessor,执行
BeanPostProcessor#postProcessAfterInitialization方法 - 使用 Bean
- 如果 Bean 是 DisposableBean,则执行 destroy 方法
- 如果有 destroy 方法,则执行
说下对 Spring MVC 的理解?
Spring MVC 是基于 Servlet API 构建的,可以说核心就是 DispatcherServlet,即一个前端控制器。
还有几个重要的组件:处理器映射、控制器、视图解析器等。
由这几个组件让我们与 Servlet 解耦,不需要写一个个 Servlet ,基于 Spring 的管理就可以很好的实现 web 应用,简单,方便。
然后关于 MVC 的解释,我就不提了,什么 Model,View,Controller 啥的。
Spring MVC 具体的工作原理?
当一个请求过来的时候,由 DispatcherServlet 接待,它会根据处理器映射(HandlerMapping)找到对应的 HandlerExecutionChain(这里面包含了很多定义的 HandlerInterceptor,拦截器)。
然后通过 HandlerAdapter 适配器的适配(适配器模式了解一下)后,执行 handler,即通过 controller 的调用,返回 ModelAndView。
然后 DispatcherServlet 解析得到 ViewName,将其传给 ViewResoler 视图解析器,解析后获得 View 视图。
然后 DispatcherServlet 将 model 数据填充到 view ,得到最终的 Responose 返回给用户。
我们常用的视图有 jsp、freemaker、velocity 等。
SpringMVC 父子容器是什么知道吗
官网上有幅图可以了解下:
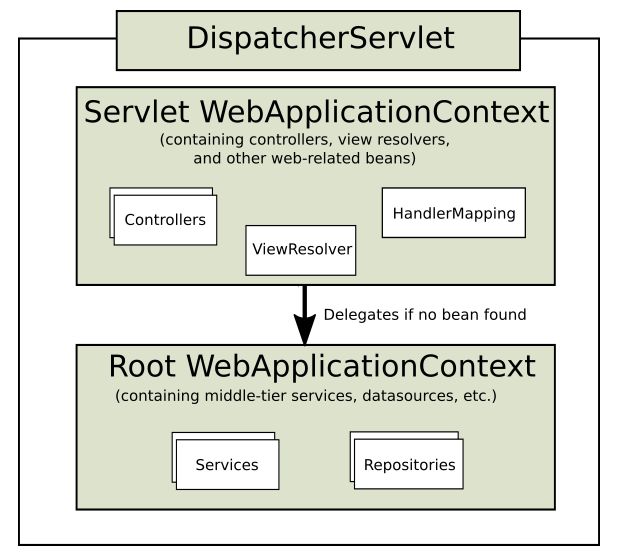
可以看到,services 和 repositories 是属于父容器的,而 Controllers 等是属于子容器的。
那为什么会有父子之分?
其实 Spring 容器在启动的时候,不会有 SpringMVC 这个概念,只会扫描文件然后创建一个 context ,此时就是父容器。
然后发现是 web 服务需要生成 DispatcherServlet ,此时就会调用 DispatcherServlet#init,这个方法里面最会生成一个新的 context,并把之前的 context 置为自己的 Parent。
这样就有了父子之分,这样指责就更加清晰,子容器就负责 web 部分,父容器则是通用的一些 bean。
也正是有了父子之分,如果有些人没把 controller 扫包的配置写在 spring-servlet.xml ,而写到了 service.xml 里,那就会把 controller 添加到父容器里,这样子容器里面就找不到了,请求就 404 了。
当然,如果你把 services 和 repositories 添加到子容器是没影响的,不过没必要,分层还是比较好的方式。
对了,子容器可以用父容器的 Bean,父容器不能用子容器的 Bean。
你了解的 Spring 都用到哪些设计模式
工厂模式,从名字就看出来了 BeanFacotry。
模板方法,什么 JdbcTemplate、RestTemplate 。
代理模式,AOP 整的都是代理。
单例,这都不需要说了。
责任链模式,比如拦截器
观察者模式,Spring里的监听器
适配器模式…SpringMVC 提到的 handlerApdaper
太多啦…
Spring 事务有几个隔离级别
从源码定义我们可以看到,一共有 5 种隔离级别,而 DEFAULT 就是使用数据库定义的隔离级别。
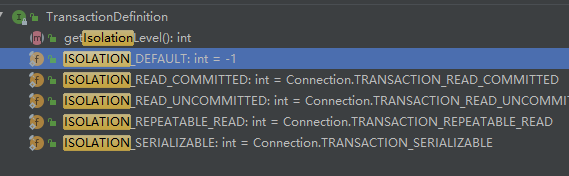
其他几种分别是:读未提交、读已提交、可重复读、序列化。
具体几个隔离级别的概念我就不介绍了,应该都很清楚。
不清楚的看我这篇 MySQL 的文章:mysql总结。
文章的后半段有写。
Spring 有哪几种事务传播行为?
从源码来看,一共有 7 种事务传播行为:
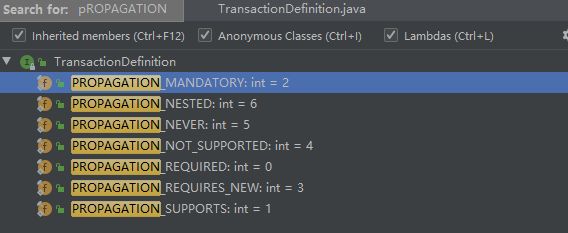
- PROPAGATION_REQUIRED(默认)
如果当前存在事务,则用当前事务,如果没有事务则新起一个事务 - PROPAGATION_SUPPORTS
支持当前事务,如果不存在,则以非事务方式执行 - PROPAGATION_MANDATORY
支持当前事务,如果不存在,则抛出异常 - PROPAGATION_REQUIRES_NEW
创建一个新事务,如果存在当前事务,则挂起当前事务 - PROPAGATION_NOT_SUPPORTED
不支持当前事务,始终以非事务方式执行 - PROPAGATION_NEVER
不支持当前事务,如果当前存在事务,则抛出异常 - PROPAGATION_NESTED
如果当前事务存在,则在嵌套事务中执行,内层事务依赖外层事务,如果外层失败,则会回滚内层,内层失败不影响外层。
Spring 事务传播行为有什么用?
这题是群里有位小伙伴遇到的面试题。
其实答案就几个字:控制事务的边界。
最后
好了,有关 Spring 的面试题暂时就写到这啦差不多啦。
如果你面试中遇到一些不好回答的面试题,可以评论或者直接联系我哈,我会整理出来滴。
欢迎点击下方名片关注我,解锁更多面试文章,每周至少一篇原创更新,主攻面试方向滴~