前所未有的 Milvus 源码架构解析

✏️ 编者按:
Deep Dive 是由 Milvus 社区发起的代码解析系列直播,针对开源数据库 Milvus 整体架构开放式解读,与社区交流与分享 Milvus 最核心的设计理念。通过本期分享,你可以了解到云原生数据库背后的设计理念,理解 Milvus 相关组件与依赖,了解 Milvus 多种应用场景。
讲师简介:
栾小凡,Zilliz 合伙人、工程总监,LF AI & Data 基金会技术咨询委员成员。他先后任职于 Oracle 美国总部、软件定义存储创业公司 Hedvig 、阿里云数据库团队,曾负责阿里云开源 HBase 和自研 NoSQL 数据库 Lindorm 的研发工作。栾小凡拥有康奈尔大学计算机工程硕士学位。
视频版讲解请戳
本期分享分为四个部分:
我们为什么需要 Milvus ?为什么它被称为下一代人工智能基础设施?
Milvus 2.0 的设计理念
Milvus 2.0 的概览与模块划分
Milvus 代码阅读注意事项
我们为什么需要 Milvus?
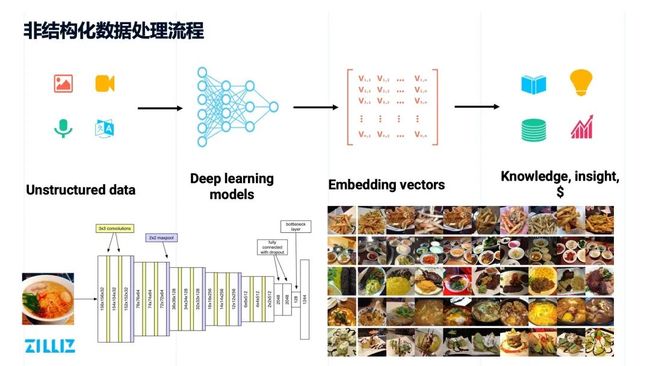
非结构化数据处理流程
Milvus 为解决非结构化数据的检索问题而生:海量的非结构化数据一般会存储在分布式文件系统或对象存储上,之后通过深度学习网络完成推理,将这些非结构数据转化成 embedding 向量,并在向量空间内完成近似性检索,从而发现数据背后的一些特征。
整个数据处理流程如下图所示。比如,有很多原始的食物图片,通过卷积神经网络做训练和推理,为每一幅照片得出一组向量,再把这些向量按照空间中的近似维度做排序,最后得到这样的结果:最上面一排是一些长得像薯条的东西,中间都是一些长得像拉面的东西,底下都是长得像寿司的东西。也就是说,图片这种非结构化数据,经过深度学习处理之后,转化成了embedding 向量,并通过在向量空间的近似度比对来表征其相似性,这在很大程度上能跟人类理解的近似度是高度一致的。
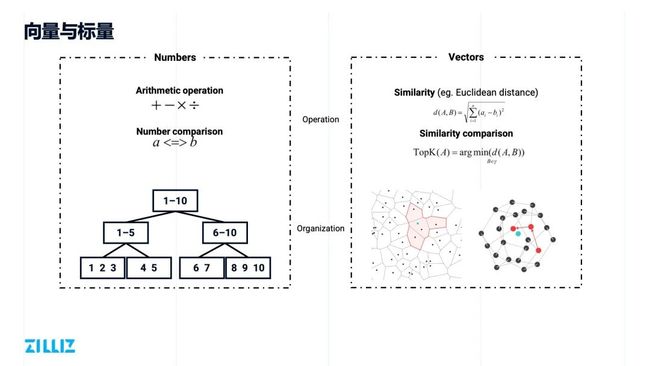
向量与标量
传统的标量数据和 Milvus 面向的向量数据之间,到底有哪些不同呢?
从基本操作上来讲,对于标量数据,针对数值类数据一般会做加减乘除的操作;对字符串类型的数据一般会做一些 term 的匹配, 或者一些类似 like 的近似匹配,抑或一些前缀匹配。
而针对向量数据而言,很少进行这种 100% 的完全匹配,更多是看近似度,也就是高维空间下的距离。较常见的距离表示有余弦距离、欧式距离等。空间中向量之间的距离,很大程度上能表示非结构化数据之间的相似度。
除了对数据的操作会有很大不同以外,数据的组织方式也会有很大不同。如,传统数据很容易比较大小,无论是数值类,还是字符串,都可以通过二叉树或者 skip list 的方式排列组合,然后做二分查找。对于向量数据来讲,则更加复杂,因为它维度较高,很难像传统的数值类数据一样通过排序的方式做加速,往往需要一些特殊的索引结构和存储方式。
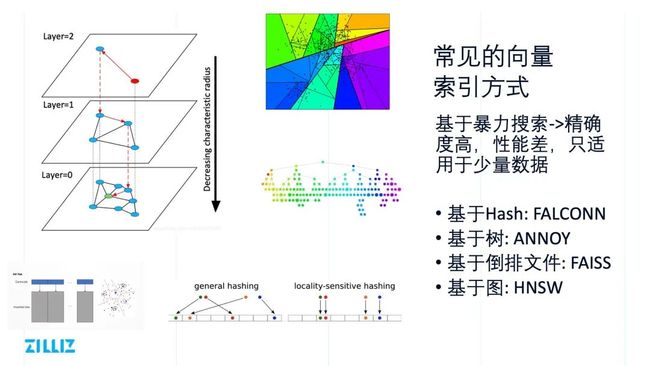
常见的向量索引方式
常见的向量的索引方式有哪些呢?
1) FLAT file,也就是大家常说的暴力搜索,这种方式是典型的牺牲性能和成本换取准确性,是唯一可以实现 100% 召回率的方式,同时可以较好地使用显卡等异构硬件加速。
2) Hash based,基于 locality sensitive hashing 将数据分到不同的哈希桶中。这种方式实现简单,性能较高,但是召回率不够理想。
3) Tree based,代表是 KDTree 或者 BallTree,通过将高维空间进行分割,并在检索时通过剪枝来减少搜索的数据量,这种方式性能不高,尤其是在维度较高时性能不理想。
4) 基于聚类的倒排,通过 k-means 算法找到数据的一组中心点,并在查询时利用查询向量和中心点距离选择部分桶进行查询。倒排这一类又拥有很多的变种,比如可以通过 PCA 将数据进行降维,进行标量量化,或者通过乘积量化 PQ 将数据降精度,这些都有助于减少系统的内存使用和单次数据计算量。
5) NSW(Navigable Small World)图是一种基于图存储的数据结构,这种索引基于一种朴素的假设,通过在构建图连接相邻的友点,然后在查询时不断寻找距离更近的节点实现局部最优。在 NSW 的基础上,HNSW(Navigable Small World)图借鉴了跳表的机制,通过层状结构构建了快速通道,提升了查询效率。
Milvus:为 AI 而生的数据库
Milvus 是专为 AI 而生的数据库,下图就是典型的 Milvus 在非结构化数据链路中的应用场景。
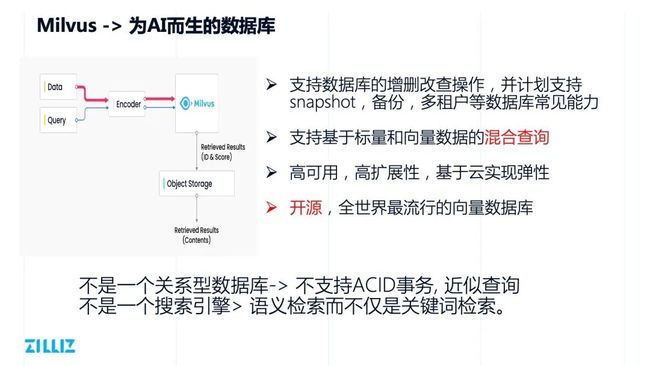
它支持的数据分为两类,一类就是需要比对的数据,另一类就是需要真正去做查询的数据。这些数据通过 Encoder 生成最终的 embedding 向量,向量通过 Milvus 做查询。所有的写入会转化成文件,并最终存储在对象存储上面。查询的过程中, search 基本上是纯内存的操作,利用一些内存的索引找到距离比较近的向量,然后再对这些向量会做一些读盘操作,拿到数据。
除了实现基本的向量搜索功能,Milvus 也是一个数据库,可以实现动态的增删改查。未来,社区也计划去做像 Snapshot、备份、多租户之类更加常见的数据库功能。
其次,相对于传统的向量检索库,Milvus 支持标量和向量数据的混合查询。传统向量搜索的 Index 通常只针对向量数据,但是我们发现很多用户希望同时使用标量和向量,给一些标量的限制条件做过滤,再在这个基础上针对向量数据做查询。
此外,借助云基础设施,Milvus 实现了高度可扩展性和健壮性,并具备很高的弹性,后面我们将具体讨论 Milvus 是如何实现这一能力的。
Milvus “不是”什么?Milvus 首先不是一个关系型数据库,不会支持特别复杂的 JOIN 之类的查询,也不会支持 ACID 的事务。Milvus 主要是做向量域的近似查询。同时,Milvus 也不是一个搜索引擎,跟传统的 Elasticsearch、Solr 之间也有很大区别。Milvus 针对的是 embedding 向量数据,而不是传统的文本格式的数据。对于文本来说,Milvus 做的是基于语义的检索,而不是基于关键词的检索。
2.0 Tradeoffs
Milvus 2.0 在 1.0 版本做了大幅的重构,为什么会有这样大的升级?社区在做 Milvus 1.0 版本的过程中,遇到了一些比较大的 Tradeoffs。
在设计一个分布式系统的过程中,一定会面临一些取舍。比较经典的数据库的取舍方法是 CAP,也就是一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。通常情况下,网络 Partation 不能解决的情况下,用户往往就只能在一致性和可用性之间 tradeoff 。比如传统的 TP 数据库往往会选择一致性,一些 AP 数据库或者 NoSQL 数据库可能会选择更高的可用性。
对于 Milvus 来讲,绝大多数用户更多偏向可用性,对数据的实时可见没有那么高的要求。在 CAP 这个理论基础上,微软提出了更新的理论“PACELC”:在网络隔离性的基础上,一致性和可用性之间存在 Tradeoff ;如果网络不发生隔离的话,就还有另一层 Tradeoff,叫做一致性和 Latency 之间的一个 Tradeoff。也就是说,如果网络都是正常的,为了维持一致性,一定要牺牲可用性。比如说跨城服务的情况下,如果要保证一致性的话,那一定需要做跨城读写。这个情况下, Latency 相对来讲一定是比较高的。本身 Milvus 就是一个更加看重 Latency 的系统,因此在大部分情况下,我们会选择去牺牲一定的 一致性,也来实现可用性和 Latency 。
除了传统的 CAP 的理论之外,还有另一个 CAP 的 Tradeoff ,就是 Cost、Accuracy 和 Performance。通常情况下,一个系统的实现成本基本上是恒定的。在这种情况下,更多程度上取决于所需查询的精度和性能。目前看下来,这两类用户各有各的选择,有些用户会倾向更精确,为此宁愿多花一点成本保证查询是精确的。因此 Milvus 也提供了很多种索引的类型,大家可以根据自己在 CAP 方面不同的取舍,选择更好的索引类型和系统参数。

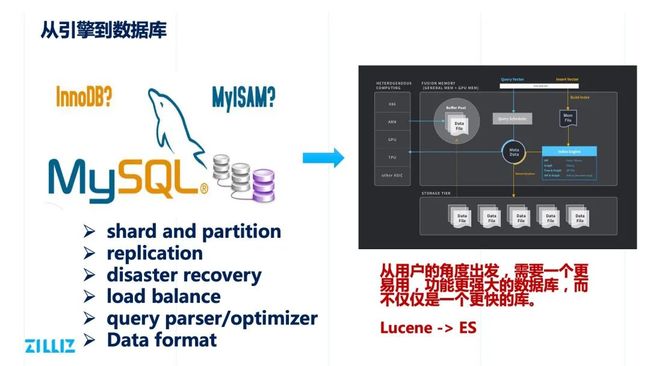
从引擎到数据库
Milvus 2.0 要解决的第二个问题,是从一个引擎变成一个强大的数据库。
大家如果了解过 InnoDB 和 MySQL 之间的关系,或者了解过 Lucene 和 ES 之间的关系的话,相信就会很清楚个中逻辑。
传统数据库主要解决功能问题,比如 Milvus 本身也会依赖 Faiss、HNSW、Annoy 之类的开源的库。这些库更关注查询的功能和性能。而 Milvus 除了要关注这些内容之外,还需要关注很多其他的东西,比如如何做数据分片,如何保证数据的高可靠性,如何保证分布式系统有节点出现异常时如何恢复,如何在一个大规模集群中实现负载均衡,如何查询语句,如何做 Parse 和 Optimize。又如,系统做持久化存储,需要考量不同的数据存储格式,而通常标准的库是不会去考虑这些的。从用户的角度出发,需要一个更加易用、功能更加强大的组件,而不仅仅是一个更快的库。
为云而生
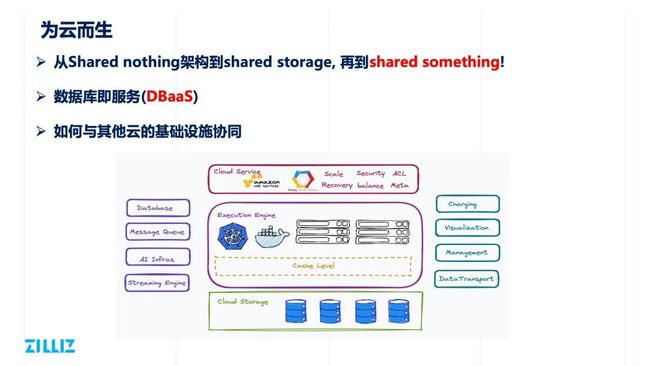
Milvus 2.0 的第三个考量是拥抱云原生。
过去十几年,传统数据库基本采用 share nothing 的架构。随着 Snowflake 的出现,很多数据库采用了 shared storage ,越来越多的数据库开始做存储计算分离。Snowflake 给予业界很大启发,利用云上的基础设施去做数据持久化,然后基于本地存储做缓存,这种模这种模式被称为 share something,获得了很多产品的共识。
另一个层面,利用 Kubernetes 管理执行引擎,利用微服务的模式分拆读、写和其他服务,也有利于各个组件分别弹性扩展。Milvus 所有的数据库执行引擎目前与 Docker 和 Kubernetes 适配,包括匹配目前主流的微服务的设计模式。
另一个很重要的趋势是 Database as a Service。在做 Database 的过程中,我们发现很多用户不仅关注数据库的功能,还越来越多地关注数据库如何做管理、计费、可视化,数据迁移。数据库不仅要提供传统的增删改查能力,还提供数据转换、迁移、多租户加密管理、计费、限流、可视化、备份快找等更加多样的服务。
第三个重要的趋势是协同一体化。Milvus 本身是一个负责系统,我们也会依赖一些开源系统作为 Milvus 的组件, 比如使用 etcd 做元信息的存储,能使用 Message Queue 作为 Milvus 的数据,或者说把我们的增量数据导出。同时也希望可以跟一些 AI 的 Infra 结合,比如与 Spark 或者 Tensorflow 建立一种上下游的依赖关系;与一些流计算引擎结合,实现流批结合的方式,希望我们的用户可以根据自己对实时性和效率的不同要求,有更多的选择。
Milvus 2.0 的设计理念
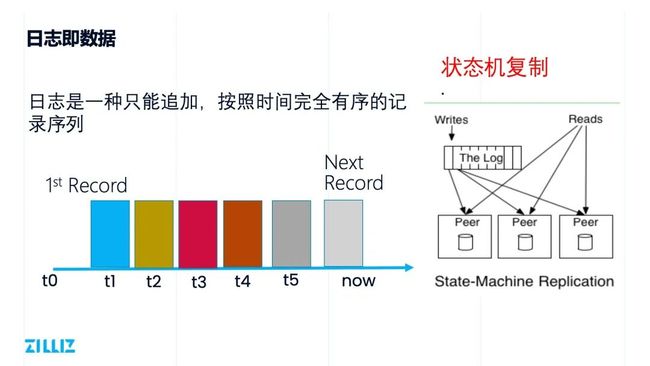
日志即数据
什么是日志呢?日志是一种只能追加、按照时间完全有序的记录序列。以下图为例,从左到右,左边的数据是老的数据,右边的数据是新数据,日志是按照时间维度排列的。在 Milvus 中,我们有一个全局的中心授时逻辑,发配全局唯一且自增的时间戳。
这个时间戳有哪些功能?时间戳对事物隔离会有很大的好处,同时,时间戳也可能会用来给数据做定序,比如说一条删除和一条写入的数据,到底哪个时间大,实际上是通过全局唯一的时间戳来定义的。
有了这个日志序列后能做什么事情?
理论上讲,如果有两个完全相同的确定性的进程,从同一个状态开始,以相同的顺序去获得相同的输入,那么两个进程最终会生成相同的输出并结束在相同的状态。所谓结果,无论是内存中的状态,还是磁盘上的状态,最终都是完全一致的。它的用途非常广泛,最广为人知的一个用途就是基于状态机的复制算法,证明了“日志即数据”是很好的工作方式。
表与日志的二象性
日志和数据之间可以相互转换的,它到底有什么作用呢?我们提出,表与日志之间存在二象性。表数据和日志数据是数据的两面,表代表的是有界数据,日志代表的是无界数据。日志可以被转换为表数据,Milvus 通过 TimeTick 分离出处理窗口,并根据处理窗口聚合日志。
日志的数据可以转换成表的数据,那么我们如何完成这个转化呢?通过日志序列,我们把数据划分成一个个窗口,根据这些窗口聚合成表的一个小文件,叫做 Log Snapshot。这些大件聚合起来叫做 Segment ,形成一个可以去单独做 Load Balance 或者扩展的单元。
日志持久化
另一个充满挑战的问题是日志持久化。分布式数据库日志的存储往往依赖一些复制算法,比如:
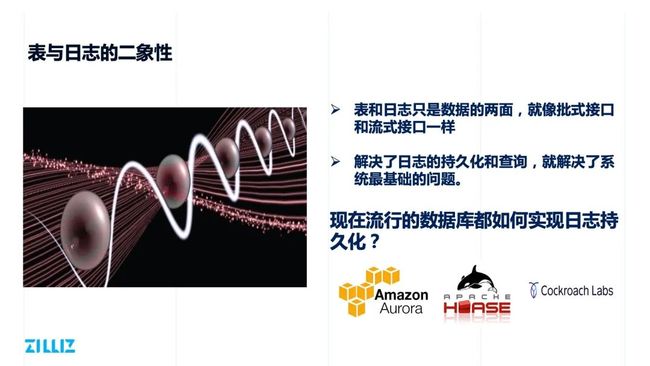
Aurora 就实现了底层的基于 Quorum 的一个持久化的日志系统。这个 Quorum 算法逻辑也比较简单,只等两个结果,读的时候也只等两个结果。只要读和写的副本数目大于总的副本数目,就一定能读到一致性的结果。
HBase 是依赖于底层的 distrubuted file system 的三副本的一个 pipeline ,Cockroach DB 、TiDB 等数据库都是依赖 Paxos 和 Raft 之类的复制算法来实现数据的一致性。
Milvus 2.0 选择了一条创新道路,依赖 Pub/sub 系统来做日志的存储和持久化。Pub/sub 系统是类似 Kafka 或者 Pulsar 的消息队列,有这么一套系统后,其他系统的角色就变成了日志的消费者。这套系统的存在将日志和服务器完全解耦,保证 Milvus 本身是没有状态的,这样可以提升故障恢复速度。
除此之外,我们依赖 Kafka 或者 Pulsar 来做数据的可靠性,保证大家的数据在使用过程中是不丢的。Pub/sub 系统的引入可以保证系统的扩展性,Milvus 也可以与更多的系统做集成。
集市架构
有了这套日志系统以后,可以大大简化系统的设计。我们在写 Milvus 代码的时候,关注点相对来讲就会少一些,保证这个系统可以快速迭代为大家提供服务。

基于这套日志系统,我们就设计了“集市架构”,核心解决的问题是如何高效地扩展一个系统。那么“集市架构”为什么叫集市呢?它是一种松散的耦合,大家都处在同一个环境中,但是每个人不太关心彼此在做什么事情。用户把原始数据通过各种类型的转换,才可以转化成 embedding 数据,也可以转化成 Semi-structured data。比如说一些 text 也可以转化成 Structured data,类似于 relational model。

通常有两种插入方式,一种是流式,一种是批式,更对应的是类似 T + 1 的写入,把它插入到不同的处理引擎里去。比如,向量检索方面,未来可能也会去引入一些第三方的 KV 系统或 text search 系统,去做数据关键词检索,所有数据都是从 pub/sub 系统发给所有订阅者。
数据写入之后,还会有一个混合查询的过程,通过 Query Processor 去完成用户的查询,最终把结果归并。基于日志系统来做似乎是一个比较好的方式,但是也有一些很大的挑战。最重要的挑战就是,如果完全基于日志系统回放数据来做查询的话,查询本身是比较慢的。按照 TimeTick 把数据分成一个个窗口,一段窗口的数据就会合并成一个快照,快照经过一段阈值之后就合并,从而构建 vector Index、提高向量搜索效率。除此之外,我们也通过批量插入的方式去满足用户对离线数据的高效处理。
在读取路径中,Milvus 是一个典型的 MPP(Massively Parallel Processing)架构。每个 Segment 搜索是并行进行的,Proxy 聚合 Top-K 结果并返回客户端。

Milvus 2.0 概览与模块划分
Milvus 单机与分布式
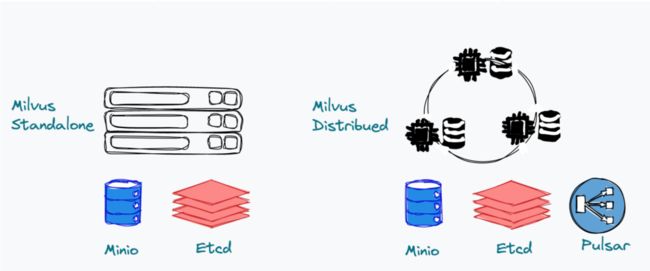
Milvus 目前来讲提供两种部署方式,一种是单机版,所有节点部署在一起,也就是说 Milvus 本身就是一个进程。目前单机版依赖 Etcd,也依赖 MinIO 。在后续版本中,去掉 MinIO 和 etcd,保证单机版足够简单,可以让大家能够把 Milvus 用起来。
另一种是分布式,这个方案相对来讲比较复杂,符合微服务化的设计。那么它依赖的除了 etcd 和 MinIO,还有就是 Pulsar。Pulsar 作为我们整个系统的 log broker 来实现以日志为主干的设计。
Milvus 的角色
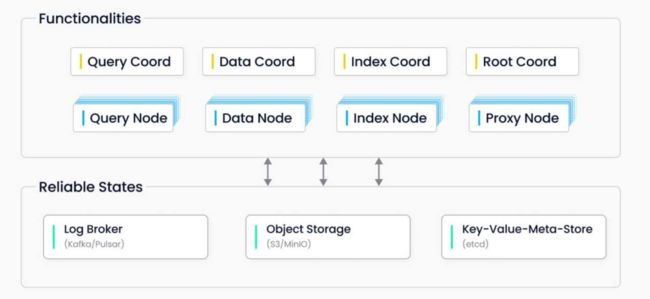
具体到所有角色来看,整个 Milvus 的分布式方案有八个角色和三个不同的依赖。
这八个角色中,上面四个的 Coordinator 部分也叫 Coordinator Service ,下方分四种 Worker Node,每个 Worker Node 类似于 Hadoop 里的 Data Node 或者 HBase 里的 Region Server。横向来看,它用于执行用户请求,区分种类是为了管控节点和下方的 Worker 节点。纵向来看,Query Coord 对应 Query Node ,Data Coord 对应 Data Node,Index Coord 对应 Index Node,Root Coord 对应 Proxy Node。
每种角色到底有什么作用呢?
从最前端讲起, Proxy 就是充当系统门面,所有的 SDK 查询都会通过一个 load balancer,发给 Pulsar Proxy 去处理连接,做一些静态检查。比如,一个请求,可能 collection 名字根本不存在,Pulsar Proxy 就会直接报错,或者当插入的数据缺少了某些列,就会由 SDK 发现。完成了预处理之后, Proxy 就会把数据投递到 Message Broker 里。
整体来讲,Proxy 会处理三类数据:写请求、读请求、控制请求,比如 DDL。Proxy 需要把数据投递到对应的 channel 里, Root Coord 类似于传统系统中的 Master,主要做一些 DDL 和 DCL 的管理,比如建 Collection、删 Collection。
除此之外,Root Coord 还承担着非常大的责任,就是为系统分配时间戳。TimeTick 的机制会保证数据根据时间戳定序。
很多朋友可能会担心,是不是会有单点的存在?对于 Milvus 而言,第一,性能瓶颈这块是比较好处理的,不太需要去做过多考虑,写入往往都是批量插入的,所以 TPS 本身没有那么高,只要满足吞吐的要求即可。第二,Milvus 在读链路的时候,对中心授权模块没有过多的依赖,因此 Root Coord 节点宕机不会对整个系统的读入有任何影响。第三,Milvus 依赖云原生的设计,Root Coord 如果宕机,可以快速被 Kubernetes 拉起来,可用性有保障。
Data 有两种角色,Data Coord 和 Data node。Data Coord 是协调者,会做一些 load balance 的分配、管理 segment、处理 Data Node 故障的恢复,比如有些 Data Node 宕机的话,是通过 Data Coord 发现和恢复的。Data Node 就做一件事情,把 log 里面的数据转化成 log snapshot,log snapshot 可以理解为 binlog,会生成一块大的 binlog,每个 binlog 通过 parquet 的格式存。Data Node 生成文件后,就会把文件传给 Index Node、生成 Sealed Segment,然后 Index Coord 会对 Sealed Segment 建索引。
有的同学会好奇,为什么建索引还要抽单独的角色去做,直接加一块做完可不可以?其实也是可以的。但是抽单独的角色去做的好处在于,第一, Index 很消耗性能,对弹性的要求更高。它不需要长时间保存的内存,如果有见缝插针的资源,Index 就可以用起来。第二, Index 本身很消耗资源,所以通常情况下用户做一些异构加速,Index Node 可以用 GPU 或专用硬件对索引做加速。Index Node 生成数据之后,就会把数据给到 Query Node 管理。所有的 Segment 都在 Query Node 上提供服务,通过 Query Node 执行查询。Query Node 有很多除了故障恢复以外的查询逻辑,同时也是整个 Milvus 里最复杂的节点。
Milvus 架构概览
整个系统的框图如下。从左侧来看,SDK 把数据发到 Load Balancer,进入 Proxy,再根据不同的查询写入 Log Broker 里来,最后由 Log Broker 通知 Data Node 新增的数据。
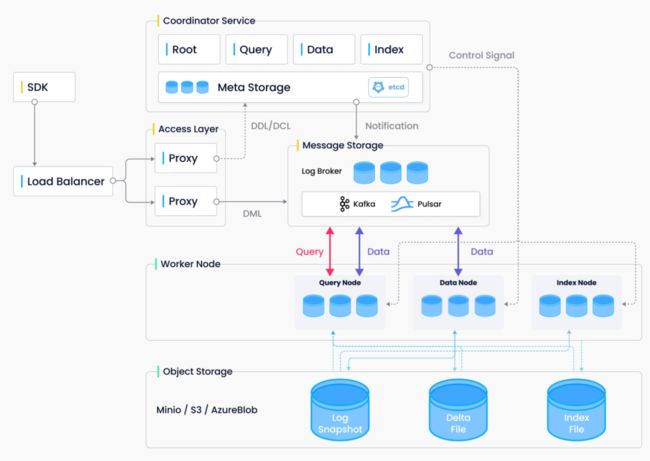
这里有个比较有意思的地方:新增数据除了要进 Data Node 之外,也会进 Query Node。有些用户对数据的实时性有比较高的要求,因此会通过 Broker 提前通知 Query Node 有新增数据,保证数据的可见周期更短。当然所有查询也会通过 Log Broker 发到 Query Node 上,Query Node 执行完以后再把结果传回到 Log Broker,通知 Proxy。
在 Query Node、Data Node 和 Index Node 之下,是基于 S3 构建的云存储。我们发现云存储本身有很高的可能性,成本也比较低,非常适合 Milvus 存储持久化的数据。
在 Coordinator Service 部分,除了刚刚说的 Root、Query、Data、Index 以外,还有 Meta Storage,目前是用 etcd 做的。一些比较小的 etcd 不太适合存在 S3 上,所以我们把这些数据存在 etcd 上,etcd 也提供了很好的事务能力,整个系统的故障恢复和服务发现也是基于 etcd 去做的。
Milvus 的数据模型
那么 Milvus 到底提供给用户什么样的数据模型或能力呢?
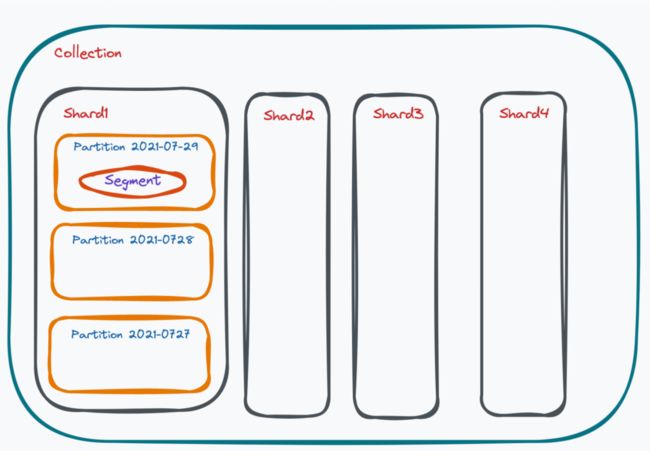
首先,我们为用户提供的最大概念叫做 Collection,即可以映射到传统数据库的一个表。每个 Collection 我们会分多个 Shard,默认情况下是两个 Shard,到底要取多少 Shard 取决于你的写入量有多大、需要把写入分到多少个节点去做处理。如果你的写入比较少,默认两个 Shard 就可以满足你的需求。
如果你的集群规模是 10 台或 100 台,我们推荐 Shard 的规模做到 Data Node 的两到三倍。每个 Shard 中间又有很多 Partition ,Partition 自带数据的属性, Shard 本身是根据主键的哈希去分的,而 Partition 往往是根据你指定的字段或 Partition 的 tag 去分的。常见的 Partition 方式有根据数据写入的日期划分、根据用户是男女去划分、根据用户的年龄去划分等。Partition 的一个很大优势是在查询过程中,如果你加上 Partition tag 的话,可以帮你过滤掉很多数据。
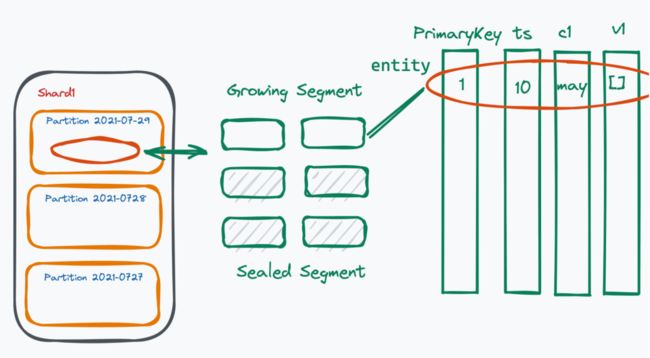
Shard 更多是帮你去扩展写的操作,而 Partition 是帮你在读操作的情况下去提升读的一个性能,每个 Shard 里的每个 partition 又会对应到很多小的 Segment 。Segment 就是我们整个系统调度的最小单元,分为 Growing Segment 和 Sealed Segment。Growing Segment 就是 Query Node 订阅,用户持续写入 Segment,等 Growing Segment 写大了以后,就不允许继续;默认上限是 512MB,写到上限以后,我们就把它 seal 掉,并对 seal 的 Segment 建一些向量索引。
在读的时候,Growing Segment 和 Sealed Segment 都是需要去被读到的,可以保证用户数据的可见实时性比较高。每个 Segment 里又分为很多 Entitity,Entity 是传统数据库里面“一行”的概念。Entity 是有 Schema 的,通常一个 Entitity 中必须有一个 Primary Key。一般来讲,我们会有一个隐式的 ts 字段,Primary Key 如果不是主动指定的话,往往可以自增。除此之外,还有一个列和 Vector,一个 Entitity 会有一个 Vector, Vector 也是整个 Milvus 系统的核心。
Milvus 数据存储模式
Milvus 在存储数据的过程中,会把数据存成什么样?
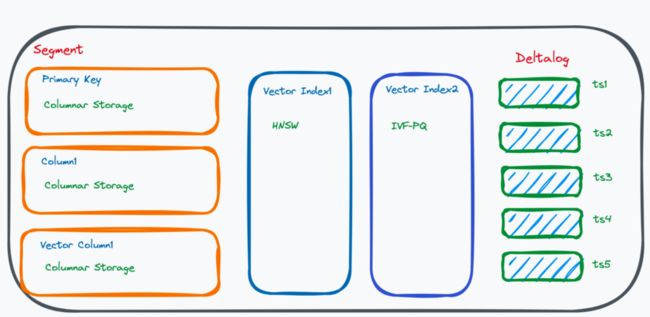
首先,存储过程是以 Segment 为单位,用的是列存的方式,每个 Primary Key 、Column、Vector 都是单独用一个文件存储。Segment seal 掉之后,我们会针对性地构建 Vector Index,整个 segment 只构建一个。
Vector Index 目前来讲只能支持建一个索引,我们很快就会支持一个表建多个索引。比如你想尝试 HNSW 和 IVF-PQ 到底哪个性能好的话,可以建多个索引。后续我们可能还会再加入一些自动调优的部分,帮用户自动选择建一些索引。
为什么要选择存储的过程中去列存呢?第一,列存的压缩率比较高,通常我们都是存一些 int 型的数据,或者存一些稠密的 float int 向量,可以通过列存去做比较好的压缩。第二,做标量过滤可能会通过回盘的方式去做读取,那么列式存储可以用来做加速。
Sealed Segment 一旦写入完成,就不能修改。实际过程中,用户会有删除或者修改数据的需求,因此我们就在 Segment 加了 Delta Log,每个 Delta Log 包含了几行删除或追加的数据。
用户做删除的时候,我们会通过路由找到对应的 Segment,在 Segment 里面生成 Delta Log。Delta Log 有点类似于传统的 LSM 树的架构,我们会先去读原始文件,然后把 Delta Log 根据时间戳慢慢打到读出来的数据上。如果 Delta Log 的 ts 大于原始数据的 ts,那么原始数据就会被删除。Delta Log 写多了或者删除多了之后,也需要做清理,不然你的读取就会变得越来越慢。因此我们基于文件格式做 compaction ,定时把 Delta Log 整合到原有的文件里面,使得在读的过程中保证不需要往回打太多的数据。
Milvus 代码阅读注意事项
准备工作
在你真正了解 Milvus 之前,你可以做如下准备工作:
第一,Milvus 本身是基于 Go 和 C++ 来写的,上层的分布式用的是 Go,下层的核心部分用的是 C++。Go 的部分帮助我们更加的云原生,以及帮助系统更好地去做拓展。C++ 的部分更多是出于性能和异构硬件的考虑。所以你需要对这两种语言都有一定的了解,我们建议初学者先从 Go 来入手。
第二,阅读 Milvus 官网上关于系统架构的设计文档(https://milvus.io/docs/architecture_overview.md)。今天讲的内容很大程度上都会在覆盖这个文档里,未来我们也会补充各种各样的设计文档到 Milvus 官网和我们的 GitHub 里面。
第三,Milvus 本身依赖 Pulsar、etcd、开源的 MinIO、S3 等。因此,在读 Milvus 代码之前,你可以先了解一下这些东西在做什么。你还可以阅读我们在 SIGMOD 2021 发表的 paper,你会对 Milvus 这个系统的初心以及它的一些用途有更深入的了解。
Milvus: A Purpose-Built Vector Data Management System, SIGMOD'21
地址:https://www.cs.purdue.edu/homes/csjgwang/pubs/SIGMOD21_Milvus.pdf
最后,你要先完成 Milvus 的 study demo,了解一下 Milvus 到底能帮你做哪些事情。在你开始去熟悉一个系统之前,先成为他的用户,简单地把这个东西玩一玩。
Demo 地址:https://milvus.io/milvus-demos
学习路径
当你做完这些事情以后,接下来的学习内容可以参考如下路径:
第一,Milvus 的一些 API 和 Python SDK 的实现
第二 ,了解系统前端的设计、proxy 的功能,以及 Milvus 的增删改查等主要操作的路径和流程
第三,数据文件的生成路径,以及存储的格式
第四,查询路径(数据查询进入到 Milvus 之后会经历哪些组件,每个组件大概实现一些什么样的功能)、故障恢复、负载均衡
最后,学习标量执行引擎,和向量执行
DeepDive 系列也将按照以上路径为大家进行讲解。
等我熟悉了 Milvus,我可以……
熟悉了代码之后你应该做什么呢?
首先,欢迎大家加入 Contributer 大家庭,希望大家可以花点时间阅读我们的文档,甚至参与修改我们的文档。文档地址:https://milvus.io/docs
当你熟悉的这个系统之后,我相信你会有很多的 idea ,也许你想了解更多的技术细节以及这个社区想要发展的方向。我们的 Tech Meeting 会定期同步到 LF AI & Data 的 Home (地址:https://wiki.lfaidata.foundation/display/MIL/Milvus+Home)。欢迎大家加入我们的讨论!
想要第一时间了解了解社区最新的功能和改进?
GitHub: https://github.com/milvus-io/milvus
欢迎在这里与我们畅聊新功能!
Slack: https://milvusio.slack.com/
当然最重要的就是为 Milvus 社区贡献代码,你贡献的代码是可以让全世界的工程师都看到都用起来,这也是大家为什么都非常愿意加入到 Milvus 社区的重要原因,用我们自己的力量去帮助更多的人去使用。当你对这个代码有很深入的理解以后,欢迎你在知乎或者在一些其他地方分享关于 Milvus 代码学习的一些心得体会,让更多的人能方便学习和使用 Milvus!

Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 数据库是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐系统、聊天机器人等方面具有广泛的应用。
![]() 阅读原文,解锁更多应用场景
阅读原文,解锁更多应用场景