Clickhouse工作原理
文章目录
-
- Clickhouse为什么做查询分析那么快?
- 1. 数据分区(MergeTree)
-
- 1.1 命名规则 & 合并规则
-
- 触发合并的时机
- 1.2 各文件含义
- 1.3 文件目录时序图
- 2. 列式存储
- 3. 一级索引(主键索引,稀疏索引)
- 4. 二级索引(跳数索引)
- 5. 数据压缩
- 6. 数据标记
Clickhouse为什么做查询分析那么快?
因为clickhouse使用了下列方案:
- clickhouse 数据分区
- clickhouse 列式存储
- clickhouse 一级索引(主键索引)
- clickhouse 二级索引(跳数索引)
- clickhouse 数据压缩
- clickhouse 数据标记
结合两个需求场景来理解
- 数据插入
- 数据查询
1. 数据分区(MergeTree)
关于表分区目录结构: MergeTree表的分区目录物理结构:
假设有一个分区表:该表有a, b, date, name四个字段,其中date是分区字段(按月份)
那么对于分区有两个问题:
- 分区文件夹的命名规则是什么?合并规则是什么?
- 分区文件夹中的文件列表,各是什么作用,什么含义?
1.1 命名规则 & 合并规则
ParitionID_MinBlockNum_MaxBlockNum_level,示例202103_1_1_0
ParitionID: 分区字段的值
MinBlockNum: 最小快序号
MaxBlockNum: 最大块序号
Level: 参与合并的次数
BlockNum是表内全局累加,每次创建一个新的分区目录,就会累加1。
文件目录的变化过程
-- 假设有两条语句
A: insert into table values ('2021-06', 'a'), ('2021-07', 'b');
B: insert into table values ('2021-06', 'c'), ('2021-07', 'd');
语句执行完成后,就会创建如下文件夹
# 结果体现了blockNum的表内全局累加
A语句 创建文件夹:2021-06_1_1_0, 2021-07_2_2_0
B语句 创建文件夹:2021-06_3_3_0, 2021-07_4_4_0
这里就会有疑问,我两条语句向同一个分区写入数据,创建两个目录岂不是增加了没必要目录数量?且增加了很多小文件?
这其实也是为什么说clickhouse不适合单条或少量数据高频写入了,因为clickhouse是通过分区文件合并来整合目录的!当要整合的目录过多,会极大消耗系统的IO资源。
# 文件目录合并结果
2021-06_1_1_0 + 2021-06_3_3_0 = 2021-06_1_3_1
2021-07_2_2_0 + 2021-07_4_4_0 = 2021-07_2_4_1
这里再重温一下文件夹命名规则:
ParitionID_MinBlockNum_MaxBlockNum_level
通过结果可以很直观的看出,同一个分区多目录合并时,会取最小的blockNum 与 最大的blockNum作为批次号,同时会取 max(level) + 1的方式记录合并次数
触发合并的时机
待补充。。。。。。。
1.2 各文件含义
# 文件目录
## 以下是数据列存储的文件,其中bin是数据内容,mrk是标记文件,结合索引标记数据位置
a.bin
a.mrk2
b.bin
b.mrk2
date.bin
date.mrk2
name.bin
name.mrk2
## 以下是系统数据文件
checksums.txt # 校验文件完整性,二进制存储(primary.idx, count.txt)size大小及size哈希值
columns.txt # 列信息
primary.idx # 一级索引,主键索引
minmax_date.idx # 二级索引,分区字段索引
default_compression_codec.txt # 压缩编码
count.txt # 当前分区的数据量
1.3 文件目录时序图

2. 列式存储
所有的OLAP技术,基本都是使用的列式存储。其有以下优点:
- 分析场景中往往需要读大量行但是少量列。 在行存储模式中,所有的列数据都存储在一个block中,不参与计算的列在IO的时候也需要读取,造成没必要的IO浪费。而列式存储,则只需要读取参与计算的列即可,极大的减少了IO消耗,加快了查询效率
- 同一列数据中的数据类型相同,这有利于提高压缩比,节省大量存储空间
- 而压缩比高,则意味着数据体积小,对应的其IO读取耗时更短
- 自由压缩算法选择,不同的列可以根据数据类型,来使用不同的压缩算法
- 高压缩比,同时也会减少内存消耗,同样的内存可以缓存更多的数据
注意: 列式存储,一般不用于数据删除场景,这是列式存储并不擅长做的事情

3. 一级索引(主键索引,稀疏索引)
在clickhouse中,主键索引默认8192条数据作为一条索引
关于一级索引:MergeTree的主键使用Primary Key定义,待主键定义之后,MergeTree会根据index_granularity间隔(默认8192条),为数据表生成一级索引并保存至primary.idx文件

4. 二级索引(跳数索引)
clickhouse中二级索引是在一级索引的基础上建立的,有一个重要的参数:granularity = 3
这个参数的意思是:在3段一级索引上创建二级索引
二级索引支持的类型
- minmax: 以
index_granularity为单位,存储指定表达式计算后的min、max值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO - set(max_rows): 以
index_granularity为单位,存储指定表达式的disinct value集合,用于快速判断等值查询是否命中该块,减少IO - ngrambf_v1(n, size_of_bloom_fiter_in_bytes, number_of_hash_functions, random_seed):将string进行ngram分词后,构建bloom filter,能够优化 等值、like、in 等查询条件
- tokenbf_v1(size_of_bloom_fiter_in_bytes, number_of_hash_functions, random_seed):与ngrambf_v1类似,区别是不使用ngram进行分词,而是通过标点符号进行词语分割
- bloom_filter([false_positive]):对指定列构建bloom filter,用于加速 等值、like、in 等查询条件执行
5. 数据压缩
关于数据压缩:Clickhouse的数据存储文件 column.bin中存储的是一列数据,由于一列是相同的数据类型,所以方便高效压缩,在进行压缩的时候,请注意:一个压缩数据块由头信息和压缩数据两部分组成,头信息固定使用9位字节表示,具体由1个UInt8(1字节)整型和2个UInt32(4字节)整型组成,分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小。每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在64KB ~ 1MB,其上下限分别由 min_compress-block_size(默认65535=64KB)与max_compress_block_size(默认1MB)参数指定。
原理说法:每8192条记录,其实就是一条一级索引,一个索引区间压缩成一个数据块
具体压缩规则:
1、单个批次数据 size < 64KB:如果单个批次数据小于64KB,则继续获取下一批数据后,直至累计到size >= 64KB时,生成下一个压缩数据块。如果平均每条记录小于8byte,多个数据批次压缩成一个数据块
2、单个批次数据 64KB <= size <= 1MB:如果单个批次数据大小在64KB与1MB之间,则直接生成下一个压缩数据块
3、> 单个批次数据 size > 1MB:如果单个批次数据直接超过1MB,则首先按照1MB大小截断并生成下一个压缩数据块。剩余数据继续依照上述规则执行。此时,会出现一个批次数据生成多个压缩数据块的情况。如果平均每条记录的大小超过128byte,则会把当前这一个批次的数据压缩成多个数据块
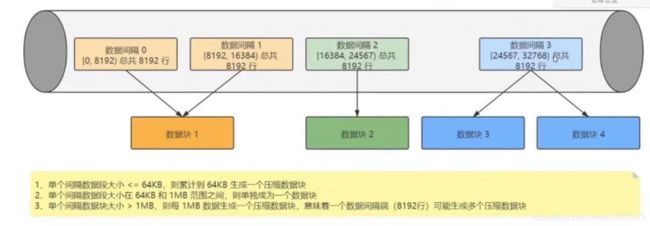
总结:在一个xxx.bin字段存储文件中,并不是一个压缩快对应到一条一级索引,而是每8192条数据,构建一条一级索引
总结:一个column.bin其实是由一个个的压缩数据块组成的,每个渊薮快的大小在64KB ~ 1M之间
column.bin 数据文件的组成

6. 数据标记
关于数据标记,数据标记文件也与
xxx.bin文件一一对应,是一级索引与数据块之间关系的数据
每一个列字段xxx.coumn都对应有一个xxx.mrk文件标记
特别说明:本文内容来自于
奈学教育课件