简单易上手YOLOV5-deepsort(Windows)
YOLOV5模型训练以及deepsort目标追踪的简单上手操作,并总结了常见问题
目录
文章目录
一、YOLOV5模型训练
1.下载源码文件
2.环境设置
3.准备工作
4.开始运行
二、YOLOV5-deepsort的目标识别
1.修改配置
三、常见问题与解决
四、如何修改撞线polygon(附加)
总结
一、YOLOV5模型训练
1.下载源码文件
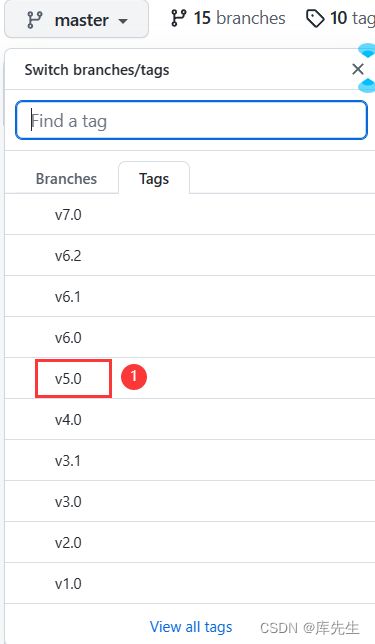
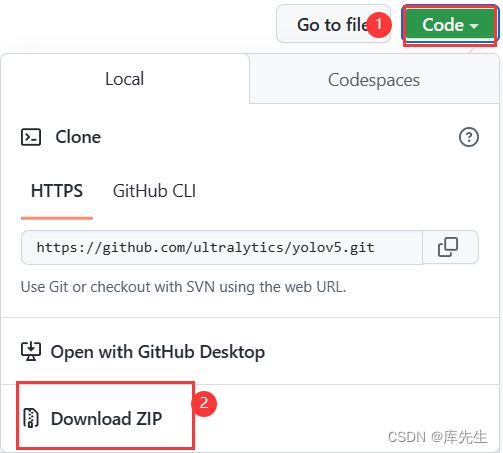
Yolov5源码文件是开源的,点开官网https://github.com/ultralytics/yolov5,选择对应的版本,我这里选择5.0版本,为了和后期的deepsort算法版本对应,点击V5.0,跳转页面后然后点击code,再点击DownloadZIP下载下来代码,解压即可。注意(下载yolov5.pt可能需要单独下载,有时候没有)。
2.环境设置
首先需要新建环境,打开cmd,输入以下代码,我用的是已经装好的torch环境,其中xxxxxx为自己建立的conda环境的名字
conda create -n xxxxxx(环境名字) python=3.8进入激活环境:
conda activate xxxxxx(环境名字)然后输入cd+文件夹命令,进入下载的yolov5目标文件夹,然后输入以下代码安装依赖包,并耐心等待。
pip install -r requirements.txt3.准备工作
建立子文件夹如下:
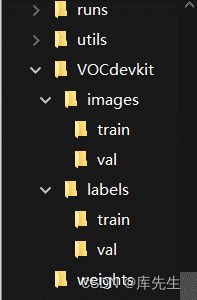
其中images放.jpg文件,label放.txt文件,其中train为训练集,用来训练,val为验证集,即验证结果是否准确。
在data文件夹下,复制voc.yaml文件,改名为egg.yaml,因为我的训练集是关于鸡蛋的,添加以下代码
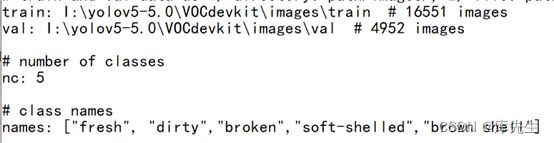
第一二行为训练集和测试集对应的文件路径,nc修改为类别数,names修改为具体哪几类。将models目录下的yolov5s.yaml复制,改名为yolov5s_egg.yaml,并将其中nc改为5,即自己的类别数这两个文件的类别数要统一。
打开train.py文件,找到第456行主函数,按照如下图对应修改,主要修改前7行即可

4.开始运行
输入以下代码开始运行,如果出现了“页面文件太小,无法完成操作”的报错,即需要在utils路径下,找到datasets.py文件,将里面的第81行里面的参数nw改为0就可以了。
python train.py跑起来就有“进度显示”,类似下图(只是演示,迭代结果不一定好哦),大家只需要耐心等待哦

二、YOLOV5-deepsort的目标识别
1.修改配置
为了实现yolov5-deepsort 的目标追踪,我们在GitHub搜索yolov5-deepsort,会发现以下内容
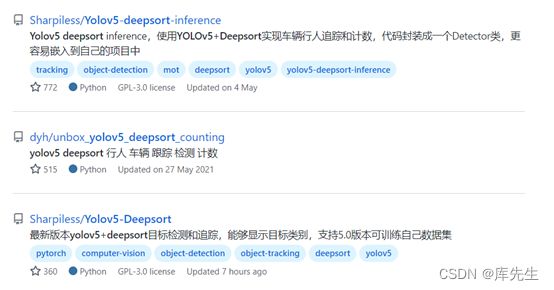
第三个为第一个的最新版本(5.0),点开第一个再跳转到最新版本(5.0)也是一样的。
将代码下载下来,看README.md,发现需要运行demo.py,在此之前
- 首先需要新建环境conda create -n deepsort(环境名字) python=3.8,我用的是已经装好的torch环境,其中deepsort为自己建立的conda环境的名字,
- 然后pip install -r requirements.txt安装所有的环境和依赖,
- 在AIDetector_pytorch.py中第18行修改自己为yolov5训练的权重文件best.pt
- 在AIDetector_pytorch.py中第19行修改为
self.device = '' if torch.cuda.is_available() else 'cpu'即CPU运行
- 在AIDetector_pytorch.py中第60行修改自己的标签名字
- 在demo,py第10行修改为自己视频路径
然后python demo.py即可
三、常见问题与解决
1.问题一:

遇到这个问题,首先可以将下面这个函数的内容完全复制修改,替换原来的tracker.py文件中这个函数的内容,然后要注意的一点是,所有的首行缩进应该保持一致,一旦有错误的话,整个逻辑将会出现错误。
def update_tracker(target_detector, image):
new_faces = []
_, bboxes = target_detector.detect(image)
bbox_xywh = []
confs = []
clss = []
outputs = [] ####################
if len(bboxes):
for x1, y1, x2, y2, cls_id, conf in bboxes:
obj = [
int((x1+x2)/2), int((y1+y2)/2),
x2-x1, y2-y1
]
bbox_xywh.append(obj)
confs.append(conf)
clss.append(cls_id)
xywhs = torch.Tensor(bbox_xywh)
confss = torch.Tensor(confs)
outputs = deepsort.update(xywhs, confss, clss, image)
bboxes2draw = []
face_bboxes = []
current_ids = []
for value in list(outputs):
x1, y1, x2, y2, cls_, track_id = value
bboxes2draw.append(
(x1, y1, x2, y2, cls_, track_id)
)
current_ids.append(track_id)
if cls_ == 'face':
if not track_id in target_detector.faceTracker:
target_detector.faceTracker[track_id] = 0
face = image[y1:y2, x1:x2]
new_faces.append((face, track_id))
face_bboxes.append(
(x1, y1, x2, y2)
)
ids2delete = []
for history_id in target_detector.faceTracker:
if not history_id in current_ids:
target_detector.faceTracker[history_id] -= 1
if target_detector.faceTracker[history_id] < -5:
ids2delete.append(history_id)
for ids in ids2delete:
target_detector.faceTracker.pop(ids)
print('-[INFO] Delete track id:', ids)
image = plot_bboxes(image, bboxes2draw)
return image, new_faces, face_bboxes
2. 问题二:
AttributeError: Can‘t get attribute ‘SPPF‘ on <module ‘models.common‘ from ‘XXX
或者model.yolo.xxxxx问题都可以这样解决
由于yolov5目前最新版本为6.2,直接从官网上下载yolov5的版本较高,但是yolov5-deepsort版本更新较慢,就会导致自己用yolov5模型训练后的模型权重文件best.pt等与此文件中的yolov5s.pt版本不匹配的问题,就会报错,所以我们需要下载对应的版本,这时我们可以参考如下链接博客。本deepsort使用的是5.0版本的权重文件。
http://t.csdn.cn/l5Q5v
3.问题三:修改测试视频文件路径
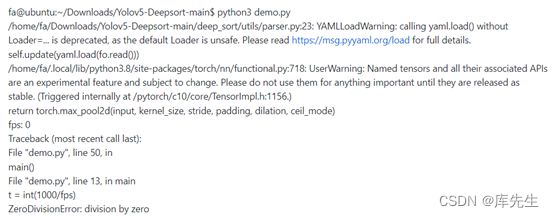
出现这种问题的原因是没有找到可以运行的测试视频文件这时我们将所需要测试的文件放到当前目录下然后修改demo.py中第十行的cap = cv2.VideoCapture('test2.mp4')视频路径即可。
4. 问题四:

提示load()函数调用的时候缺少参数
解决方法:
在deep_sort\deep_sort\utils\parser.py的第23行加上缺少的参数就好了
self.update(float(fo.read(),Loader=yaml.SafeLoader))5.问题五:修改为CPU运行

这样的问题是因为修改device时,未修改完全,在AIDetector_pytorch.py中第19行修改为
self.device = '' if torch.cuda.is_available() else 'cpu'即为cpu运行,还需要将23行half修改为float,如下:
model.float()36行同理
img = img.float() 48行同理
pred = pred.float()四、如何修改撞线polygon(附加)
Deepsort-speed代码中修改polygon
在代码中的demo.py,可以看到在开头的时候填充了polygon,然后在这个基础上分别画了蓝色polygon和黄色polygon,这两个就是撞线,以下代码即通过经过这两条线判断经过或者返回累计个数。
(1)list_pts_blue就是蓝色这个多边形的左边,可以看到有四个点坐标(x,y),这就说明这是四边形,左边点的顺序依次为左上,左下,右下,右上,即逆时针转一圈。修改位置左边或者添加坐标点的个数即可以实现多边形的切换。
(2)blue_color_plate为多边形的颜色,通过RGB值。可以修改撞线的不同的颜色。
(3)
fps = int(cap.get(5))
print('fps:', fps)
t = int(100/fps)此代码在demo.py中的第60行,fps就是按照获得的帧数,是按照get(5)的方式进行抽帧,一般都是5,t是定义的一个变量用来在代码第208行cv2.waitKey(t)中调用,实现速度的调试,想修改速度可以修改t = int(100/fps)中的100,变大速度则会变慢,变小速度则会变小,也可以不调用这个变量,直接在下面的cv2.waitKey(t)中不调用t,改为cv2.waitKey(10),或cv2.waitKey(1)都可以,保证内部值为整数即可。
总结
以上就是YOLOV5模型训练以及deep sort目标追踪的简单上手操作,并总结了一些运行过程中可能会出现的问题。