比特鹏哥数据的存储深度剖析(上半部分)
本章重点
数据类型详细介绍。
整形在内存中的存储:原码、反码、补码。
大小端字节序介绍及判断。
浮点型在内存中的存储解析。
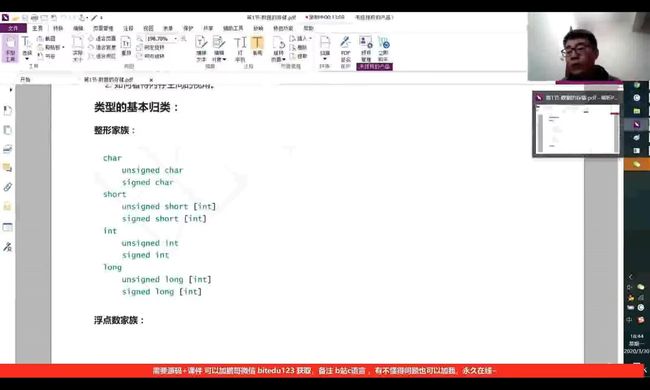
c语言类型
内置类型
char
short
int
long
float
double
2.自定义类型(构造类型)
数据类型的意义:
使用这个类型开辟内存空间的大小(大小决定了使用范围)
如何看待内存空间的视角
例:
int与float同样向内存空间申请了四个字节,那么他们在内存中的结果是否相同呢?我们以10为例:
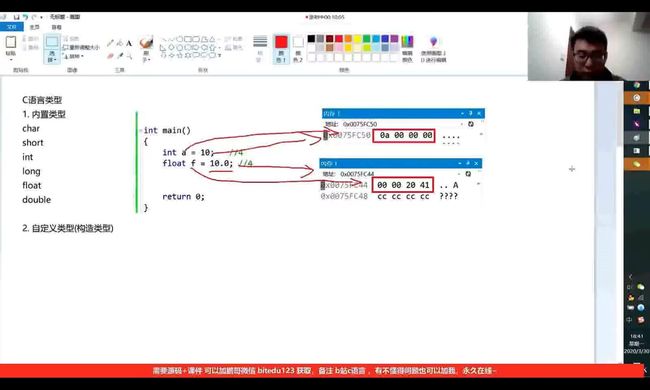
如图,
int a = 10;的内存空间为 0a 00 00 00
float f = 10; 的内存空间为 00 00 20 41
很显然,两者的区别很大,所以类型决定了看待空间的视角。
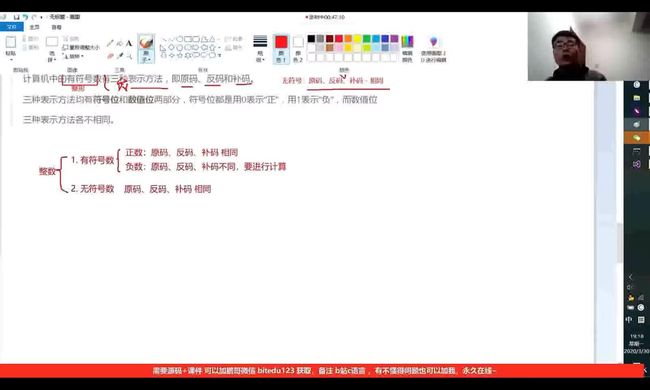
类型的基本归类:
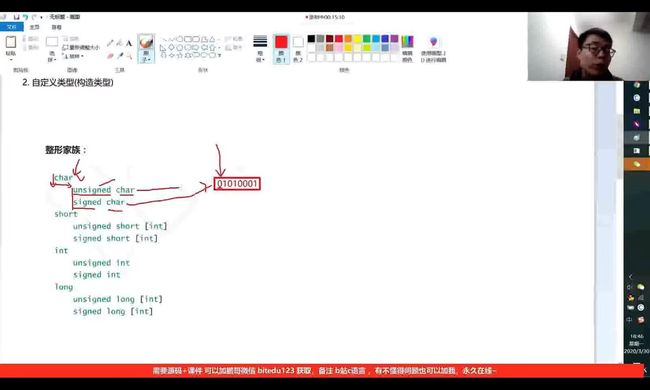
整形家族中,都分为有符号数和无符号数。1.其中,以char类型为例,若为signed char,即有符号数,那么其最高位表示符号,0表示正数,1表示负数,以01010010为例,其结果为84,若第一位的0改成1,则为-84。由此可知道,无符号的char比有符号的char表示的范围更大。
【int】表示可省略,加不加都可以。

数组类型中,以int arr[10] = 0;为例,int [10]为数组的类型,同理char[5]也为数组的类型,且二者为不同类型。
*指针类型的大小都为4个或8个字节。
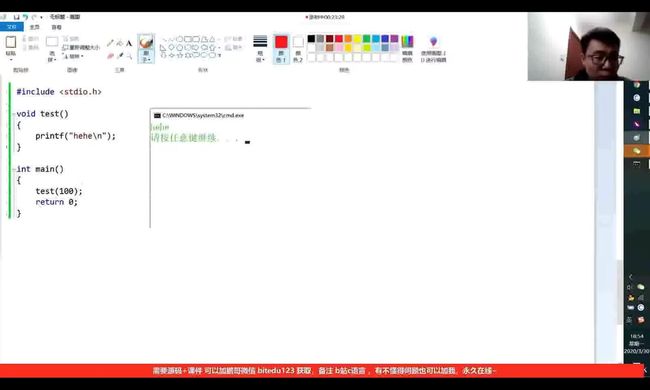
当函数不需要返回值时,我们用void声明,但图中,test()中有参数100,而程序却可以正常运行。这其实是c语言本身的问题,要想彻底解决,则在void test()中加入一个void即可,如图:

此时若test()中仍然有参数,则系统会自动报警告。
整形在内存中的存储:
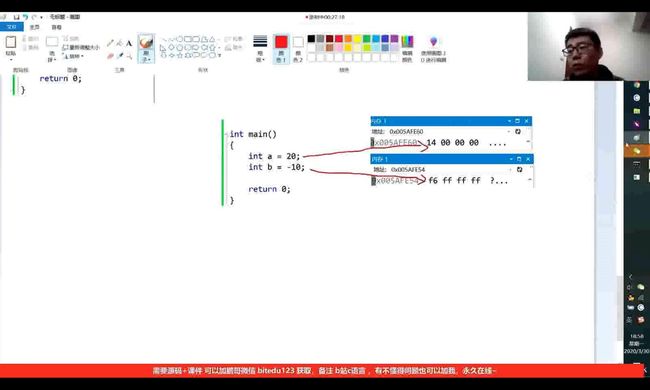
为什么同样是int型,而a与b在内存中的存储却不一样呢?为了研究这个问题,我们得先知道原码、反码、补码是什么:

符号位不变,其他位按位取反 +1
原码--------------------------------------------->反码------------------------------------------->补码
计算机中以补码形式存储,原码形式输出。
无符号数原码反码补码三码合一。
有符号数中的正数也是三码合一,负数原码、反码、补码才不同。
以下为例子中的原码,反码,补码:

在计算机中,四个二进制比特位可转化为一个16进制,补码在内存中以16进制方式存储:
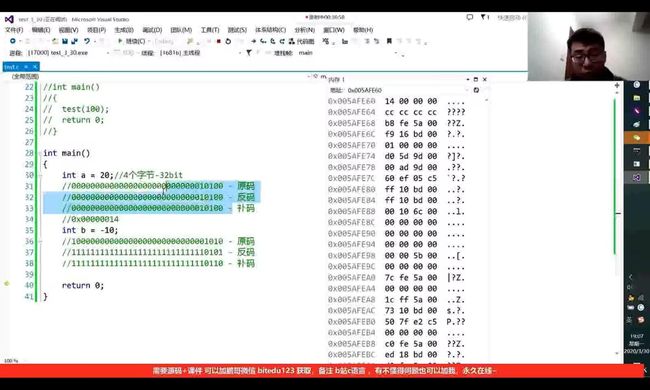
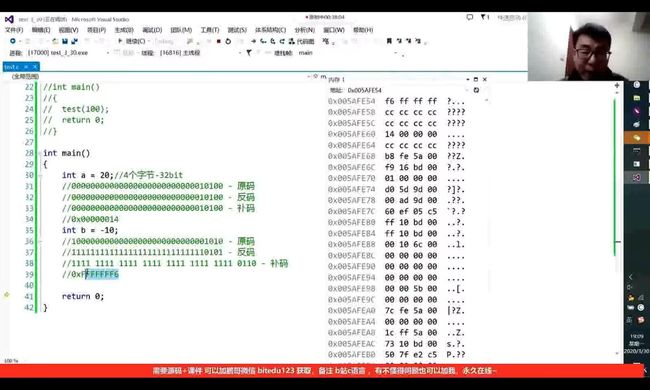
上下两图分别为a和b的补码转化为16进制在内存中的存储。
补码的出现使得计算机中加法和减法可以统一处理,比如要计算1 - 1的值,计算机会自动转化为 我 1 + (-1)进行计算,那么我们使用原码计算会有什么结果呢?让我们一起看看:
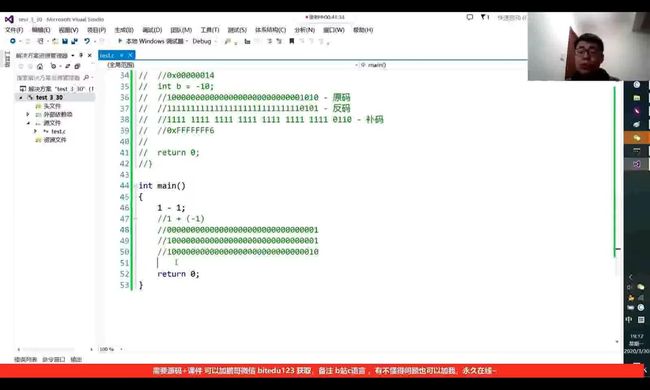
如图,原码相加最后等于-2,我们都知道,1 - 1等于0,并不等于-2,那么我们便知道了用原码计算并不太合适,让我们看看用补码的计算:

这是-1的补码。

这是1的补码和-1的补码相加,由图我们可得,结果为0。所以,很显然,计算机使用补码进行计算是正确的。
梳理:
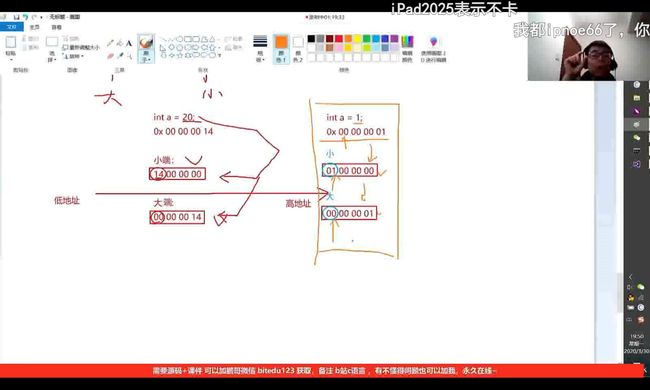
解决了上述问题,我们又会发现一个问题,为什么int a = 20;的16进制为0x00000014,而在内存中却是倒过来写的呢?

这个问题我们就得提到大小端的概念了。

大端存储:低位放在高地址,高位放在低地址。
小端存储:低位放在低地址,高位放在高地址。
以0x11223344为例
若为大端存储:44为低位,应该放在高地址处。则存储形式为11 22 33 44
若为小端存储:44为低位,应该放在低地址处。则存储形式为44 33 22 11
特别注意,大小端是对字节进行顺序排列,为不是比特位。两个16进制数为一个字节,如11 22 33 44
例题:请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。(百度笔试题)
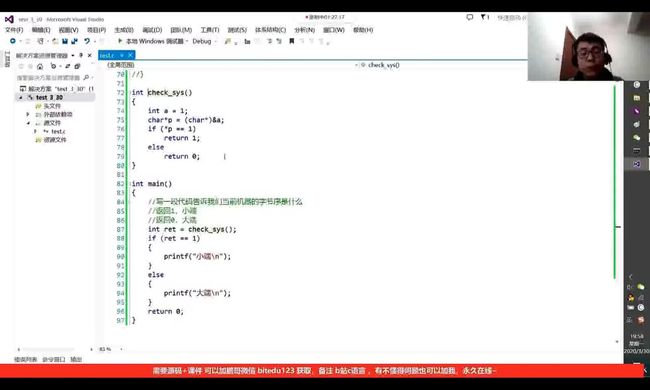
思路:要想判断当前机器的字节序,以数字1为例,它的16进制表现形式为0x00000001,所以只需要取出它的第一个地址,判断是否为0或1,则可以判断当前机器的字节序,如图:
既然需要取出地址,那么我们就要用到指针,由前面指针的知识我们可知,想取出一个字节的内容,得用char*指针,如图:

注意这里int 与char*并不兼容,所以需要将&a强制类型转换。
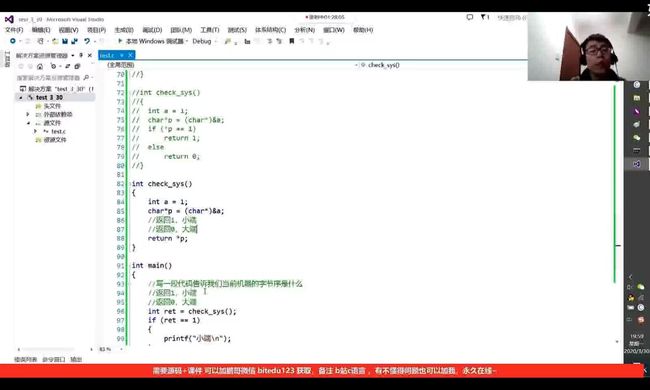
这种写法并不太好,太低级,因此我们需要将其封装成函数的形式:
这段代码还可以优化,既然返回值都是1或者0,那么不如返回*p,*p也是1或者0,代码如下:
指针类型的意义:
指针类型决定了指针解引用操作能访问几个字节。:char*p,*p访问了一个字节。int*访问4个字节。
指针类型决定了指针+1,-1,加的或者减的是几个字节:char*p;p+1,跳过一个字节。int*为4个字节
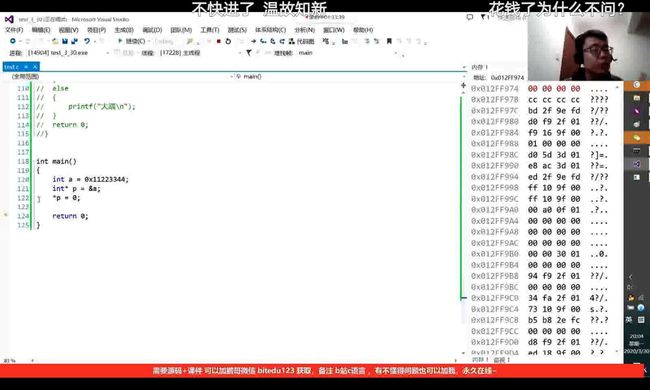

如图分别为int*hechar*类型下*p可访问的存储空间,将*p赋值为0,int * 类型可改变四个字节,如图。而char*只可改变一个字节:如图。
例题:
1.知识点:有符号数,无符号数,整型提升
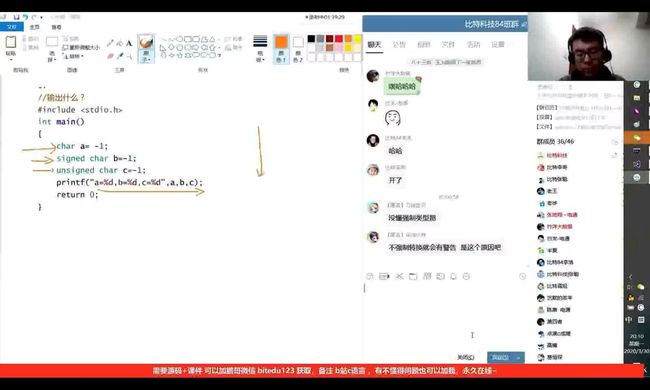
让我们一起来看看这段代码,如图,a,b,c都为char类型,所以在内存中为他们开辟了8个bit的空间。所以,对于a来说:
原码:10000001
反码:11111110
补码:11111111
很多小伙伴可能以为到这a就结束了,但如果我们仔细的观察就可以发现,printf中要求打印的是%d的整形,所以在这里我们就要提到整型提升的概念。
整型提升:

当表达式的长度小于四个字节时,就会发生整型提升。
对于有符号数来说,若被截断的最高位为1,则全补1.若为0,则全补0;
对于无符号数来说,直接全部补0;
所以,对于本题的a来说,它是有符号数,被截断时最高位是1,所以全补1.
整形提升后的a的补码:11111111111111111111111111111111
因为输出值为原码,所以a的反码为:11111111111111111111111111111110
a的原码为:10000000000000000000000000000001 = -1.
所以a的值为-1.
b和a一样,都是有符号数,所以也为-1.
对于c来说,它是无符号数,最高位直接补0;且原码反码补码相同。
c的补码:11111111(这是-1的补码,虽然c是无符号数,但是-1的补码是定的,只不过整形提升的方式不一样)
整型提升后:00000000000000000000000011111111
因为原码反码补码相同,所以这即使补码也是原码。输出值为255
例2:
%u是打印十进制的无符号数字(默认需要打印的字符改为无符号整形)
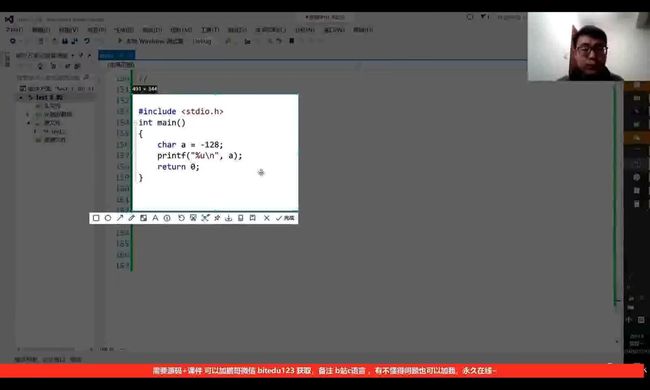
无论什么样的题,我们都要先静下心来写出内容的补码:
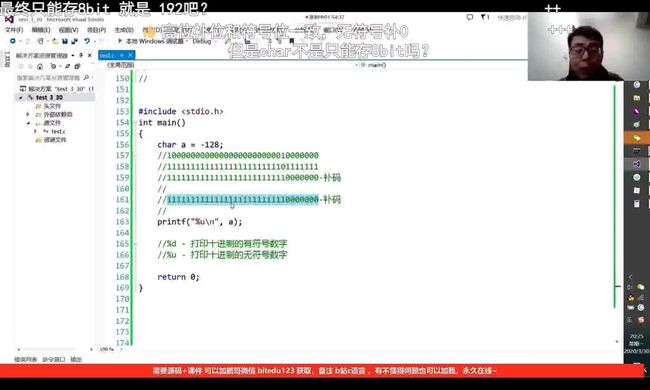
本题写出了-128的补码,按照规则是因该写出原码后再输出。但本题是以%u的形式输出,也就是十进制无符号数。既然a被看作是无符号十进制数,那么其原码反码补码也就相同。所以按照这串二进制数打印出的结果便是最终结果。
例3:
char类型可表示的范围:
有符号数:-128-127
无符号数:0-255
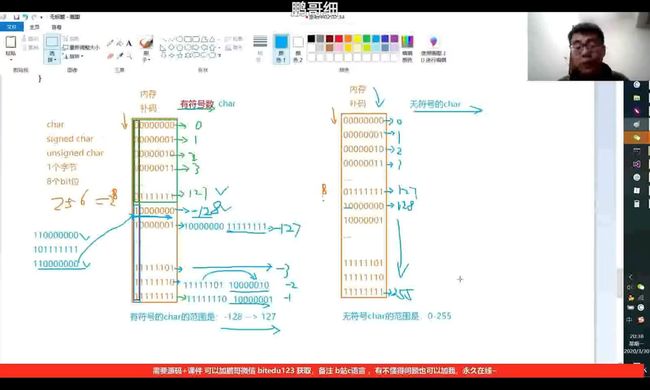
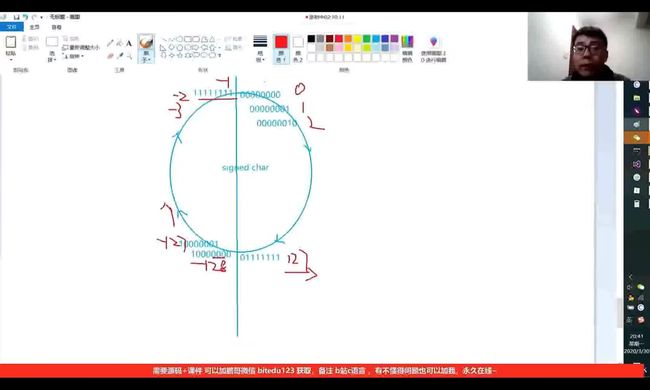
以上便是char的表示范围。
例4:
有符号char存储最大为127,无符号为-128,当有符号char存储128时,即127+1,按照上图,则为-128.
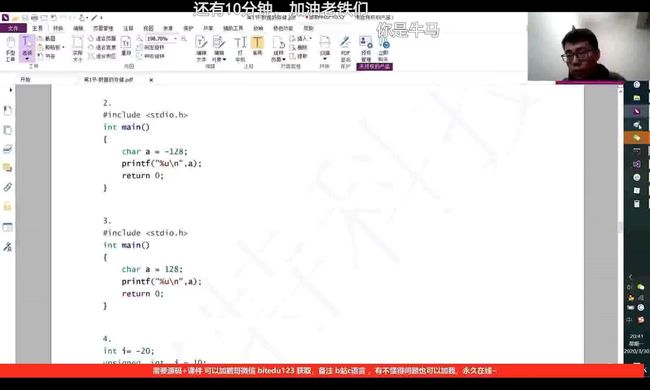
2、3两题并无区别。输出结果都相同。