Python基础--数据类型
数据类型
将一组具有相同性质的数据的集合统称为一种数据类型,在Pyhton中定义了很多种数据类型,每种数据类型以一个类(class)来定义,在类中定义每种数据类型的属性和方法。
我们可以使用内置函数type()来返回一个变量的数据类型,或者使用内置函数isinstance()来判断变量的数据类型,如下图

那这里为什么bool类型的变量,用isinstance()函数判断为int类型呢?我们按住ctrl键,点击int跳转到数据类型定义模块文件中,搜索bool类,可以看到bool类继承了int类,也就是说bool类是int类的子类,所以bool类型的数据也是int类型

数据操作
几乎所有数据类型的对象都能进行真值测试,布尔运算和比较运算,这几个操作最终返回的都是布尔值,也就是返回真True或者假False
真值测试(逻辑值测试)
任何对象都可以进行真值测试,一个对象在默认情况下被视为真值,除非当该对象被调用时其所属类定义了 __bool__方法且返回 False 或是定义了 __len__方法且返回零才会被视为假值。会被视为假值的内置对象如下:
- 被定义为假值的常量:None和False
- 任何数值类型的0:0、0.0、0j、Decimal(0)、Fraction(0, 1)
- 空的序列和多项集:‘’、[]、()、{}、set()、range(0)
假设我们自定义了一个类,这个类的实例对象可以进行真值测试,那什么情况下这个对象进行真值测试会返回False呢?
第一种情况是在这个类中定义了__bool__方法且该方法return False,那么真值测试会返回False;
第二种情况是在这个类中定义了__len__方法且该方法return 0,那么真值测试会返回False。
如果一个类中即定义了__bool__方法,又定义了__len__方法,那么会先查看__bool__方法的返回值,如果返回值为False,那么直接是False,如果返回值是True,那么接着看__len__方法的返回值,返回值为0,那么就是False,返回值是非0,那么就是True
除上面两种情况之外,任何对象进行真值测试都默认返回True
布尔运算(and、or、not)
任何对象在进行真值测试之后,都能作为布尔运算的操作数,布尔运算的运算规则如下:
- x and y:当x为假时,直接返回False;当x为真时,再对y求值,如果y为假则返回False,y为真则返回True
- x or y:当x为真时,直接返回true;当x为假时,再对y求值,如果y为假则返回False,y为真则返回True
- not x:当x为真时,返回False;当x为假时,返回True
比较运算
在Python中有八种比较运算符,他们的优先级相等(比布尔运算符的优先级高)。比较运算可以任意串联,比如:x is和is not属于身份运算符,跟其他运算符不同的是,其他运算符比较的是对象的值,而身份运算符比较的是对象的内存地址。身份运算符两边都应该是一个对象的标识符,而不应该是一个具体的对象 在Python 3中定义了以下八种标准的数据类型: 不可变和可变指的是这种数据类型的变量值是否能被改变 其余数据类型还有: 其中字符串、元组、字节串、列表又被称为序列类型,这些数据类型都有的共同特征是都存在索引,都可以做切片操作,以及其他序列类型操作等 其中字符串、字节串、元组、列表、字典、集合又被称为迭代器类型,这些数据类型都能通过调用iter()函数返回一个迭代器,并通过迭代器调用next()函数进行迭代操作 其中字典又被称为映射类型,是Python中唯一一种标准的映射类型 Python 3的数字类型包括: 函数定义:class int(x,base=10) 使用int()函数转换时要注意以下几点: 由于bool类属于int类的子类,所以bool值也相当于一个整数 按位运算只对整数有意义,将两个整数先转换为二进制数,然后依次按位运算,得到的结果再转换为整数输出,包含的位运算有: 在计算机中,一个数字或者一个字符占一个字节(byte),一个字节(byte)等于8比特(bit)也就是8位,每一位用一个二进制数(0或者1)来表示,所以1在计算机中被存储为00000001(最高位代表符号位,0代表正号,1代表负号) 通过规律我们可以发现 函数定义:class float(x) 使用float()函数转换时要注意以下几点: 复数是由一个实数和一个虚数组合构成的数,表示为x+yj或x+yJ,其中: 函数定义:class complex(real[,imag]) 使用complex()函数转换时要注意以下几点: 所有的数字类型(除复数之外)都支持下列运算: math是Python内置的数学类函数库,这个库只适用于整数和浮点数,不适用于复数。math模块在使用之前必须先import导入,下图可以看到math模块包含了很多属性,下面我们来逐一介绍 math里的常量表示的是数学常数,比如数学里面的π,所有常量如下 布尔类型是与逻辑相关一种数据类型,只有两个值:True(真)与False(假) 函数定义class bool(x): 如果x经过真值测试为false,则bool(x)返回False,否则返回True 序列类型包括 在Python中只要类的定义中实现了__getitem__和 __len__方法,那么这个类的对象就会被认为是序列类型 几乎所有的序列类型都可以进行以下操作 对s进行s * n操作相当于将s里面的元素 * n之后返回一个新的序列,得到的新序列跟s不是同一个地址,但是新的序列里面n个相同的元素的地址是相同的,所以如果你对这n个元素中的其中一个元素进行操作,那么这个操作将作用于n个元素,看下面的例子 所有序列都可以进行切片操作,其实就是根据元素的下标取出在某个范围的元素,记作:s[i:j:k] 我们在切片的时候可以按照这个顺序来:首先看k的正负,判断i和j的位置,如果k为正数,那么i不在j的左边直接返回空,否则从i开始取到j-1;如果k为负数,那么i在j的左边直接返回空,否则从i开始取到j-1 序列的切片操作实际上是调用__getitem__函数 不可变序列类型普遍实现而可变序列类型未实现的唯一操作就是对hash()内置函数的支持,所以不可变序列类型的对象都是可哈希对象,他们都可以用来作为字典dict的键,以及存储在 set 和 frozenset 实例中。而可变序列类型的对象无法作为字典dict的键,或存储在set和frozenset中,否则会引发TypeErroe异常。当然仅当不可变序列类型里面的元素都是可哈希的,这个序列才是可哈希的,比如如果元组里面存在可变元素,那么这个元组就不是可哈希的 hashable可哈希:一个对象的哈希值在其生命周期内绝不改变,就被称为可哈希,那么该对象的类中一定定义了__hash__()方法,且存在__eq__()方法使得他们能和其他对象进行比较 实例: 在Python中,可以使用引号( ’ )、双引号( " )、三引号( ‘’’ 或 “”" ) 来定义字符串,引号的开始与结束必须是相同类型的 三者都可以用来定义字符串,但为了省去转义的麻烦,当定义带有单引号的字符串时,使用双引号来定义就不需要进行转义,同理在定义带有双引号的字符串时,使用单引号来定义就不需要进行转义。而使用三引号定义的字符串,输出会严格按照定义时的格式输出,比如定义换行的字符串,使用单引号或者双引号定义时每行的末尾都需要加一个反斜杠,而使用三引号定义就不需要 函数定义:class str(object,encoding=‘utf-8’, errors=‘strict’) 常用字符串方法详解 该方法可以将字符串、元组、列表、字典、集合里面的元素重新组合成一个新的字符串,组合规则如下: 该方法可以将字符串转化为元组,始终返回三元元组,拆分规则如下: 该方法可以将字符串转化为列表,拆分规则如下: 行边界符如下 该方法用于移除字符串中前导和末尾的chars,移除规则如下: 元组里面的元素可以是任何标准数据类型的对象 函数定义:class tuple(iterable) 函数定义:class list(iterable) 列表对象的所有方法如下 该方法用于在列表末尾追加一个元素,参数不能为空,x可以是任何数据类型 该方法用于在列表末尾追加一个可迭代对象,将可迭代对象中的每一项作为一个元素追加到列表中,当参数为字典时追加的是他的key 该方法用于在列表的指定位置i插入元素x,i代表插入元素的索引,x可以是任何数据类型 该方法用于从列表中删除第一个值为x的元素,元素未找到就抛出异常ValueError 该方法用于从列表中删除指定位置的元素,并返回该元素。i代表需要删除的元素的下标,这个下标必须存在,如果不存在抛出异常IndexError;i可以不写,当参数为空时默认删除最后一个元素 该方法用于清空列表元素 该方法用于返回列表中第一个值为x的索引,找不到就抛出异常ValueError。可选参数start和end用于限定查找范围,两个参数的值都代表的下标 该方法用于返回列表中元素x出现的次数,同样的会把True看作1,False看作0 该方法详看下面排序介绍 该方法用于反转列表元素,顺序颠倒 该方法用于返回列表的浅拷贝,拷贝跟赋值很像,但也有区别。如果是赋值,那么两个变量指向的是同一个对象,相当于两个变量指向的是同一个地址空间,而拷贝有时候并不是这样。浅拷贝的规则如下: 还可以使用copy模块来进行浅拷贝和深拷贝,使用之前需要import copy,浅拷贝方法是copy.copy(x),深拷贝方法是copy.deepcopy(x) 深拷贝规则对于不是复合类型的变量来说跟浅拷贝一样,类型不可变,拷贝之后地址相同,类型可变拷贝之后地址不相同。而对于复合类型来说深拷贝和浅拷贝有所不同,浅拷贝是内层元素地址均不变,外层可变地址就不同,不可变地址就相同,但深拷贝是根据内层元素类型来决定外层拷贝后地址是否相同的。具体就是:如果内层包含可变类型,那么不管外层是什么类型,深拷贝之后得到的变量地址和原变量不相同,里面的元素是可变类型的地址就不相同,是不可变类型的地址就相同;如果内层不包含可变类型,那么再看外层,如果外层是不可变类型那么深拷贝之后得到的变量地址和原变量相同,如果外层是可变类型,那么深拷贝之后得到的变量地址和原变量不相同,里面的元素因为都是不可变类型的,所以深拷贝之后地址都相同 del语句可以按索引删除列表中的值,也可以命名空间中直接删除列表变量 方法定义:list.sort(*, key=None, reverse=False) 函数定义:sorted(iterable, /, *, key=None, reverse=False) list.sort() 和 sorted() 都有一个 key 形参用来指定在进行比较前要在每个列表元素上调用的函数(或其他可调用对象),下面我们来指定关键函数进行排序 利用集合元素的不重复性,可以使用set()将列表转换为一个集合,然后再将集合使用list()转换为列表,达到去重的目的 但利用set()去重之后原列表的顺序就改变了,如果想要保持原列表的顺序那么可以结合sorted()方法一起使用 利用字典键key的不重复性将列表中的项作为字典的键创建一个字典,然后再使用list()将字典转换为列表,达到去重的目的,这种方式还可以保留列表的原序 range 类型表示不可变的数字序列,通常用于在 for 循环中指定循环的次数 类型定义:class range(start, stop[, step]) 目前只有一种标准的映射类型,那就是字典。字典的键可以是任何可哈希对象,但键具有唯一性,所以当数字类型作为键时,如果两个数在字面上相等,比如1和1.0,那么当将这两个数都作为键时,字典中只会创建一个映射,而这两个数都可以被用来索引同一个条目 函数定义:class dict(**kwargs)或class dict(mapping,**kwargs)或class dict(iterable,**kwargs) 返回字典d中的项数 返回字典d中以key为键的键值,如果key不存在将引发KeyError异常 将字典d中以key为键的项的键值设为value,如果key存在那么相当于修改键值,如果key不存在那么相当于添加新的项 将字典d中以key为键的项移除,如果d[key]不存在将引发KeyError异常 如果键key在字典d中,那么返回True,否则返回False 如果键key不在字典d中,那么返回True,否则返回False 返回以字典d中的键为元素的迭代器 清空字典d 返回字典d的浅拷贝 使用该方法来创建一个新字典,新字典的键来自可迭代对象,所以可迭代对象参数中不能有不可哈希的项,否则将引发TypeError异常,可以指定每个键的默认键值,如果不指定那么默认为None 从字典d中获取键为key的键值,如果key不在d中就返回default,default默认为None 返回字典d的每一项(键:键值)组成的一个新视图,可以用来循环遍历字典 返回字典d的每个键组成的一个新视图,可以用来循环遍历字典的键 返回字典d的每个键值组成的一个新视图,可以用来循环遍历字典的键值 移除字典d中键为key的项,并返回key的键值,如果key不存在则不会执行移除动作,直接返回default,如果default没有定义那么将引发KeyError异常 移除字典d的最后一项,并返回最后的一项(键:键值),如果字典为空将引发KeyError异常 返回一个逆序获取字典d中的键的迭代器,这个迭代器既然是逆序取字典的键,那么就可以用该迭代器生成一个元组或列表 如果字典d中存在key,那么返回key的键值,否则将key加入字典d中,key的键值就是default,并返回default,如果default未指定,那么默认为None 使用来自other的键值对更新字典d,如果键存在了就覆盖,该方法会返回None。参数为空时什么都不做,仍然返回None;参数为字典对象时,将该字典对象的键值对追加到字典d的末尾;参数可以是任何空的可迭代对象,什么都不做,仍然返回None;参数还可以是关键字参数;参数还可以是元组或列表或集合,但要求这些参数对象中只能包含键值对,也就是这些参数对象中的每一项只能是只包含两个对象的元组或列表,且第一个对象只能是可哈希的,会将每一项的第一个对象作为字典d的键,第二个元素作为字典d的键值追加到字典d中,看下面的实例更清晰 合并两个字典并返回一个新的字典,d和other都必须是字典,如果两者中存在相同的键,那么以other的值作为键值 用other的键值对更新d,相当于d.update(other) 字典只能进行等于(==)或不等于(!=)比较,无法进行(‘>’,‘<’,‘>=’,‘<=’)比较,否则会引发TypeError异常。字典进行相等比较时,只有两个字典里面的键值对完全相同才会相等 集合元素具有两个特性:唯一性和无序性 函数定义:class set([iterable])或class frozenset([iterable]) 返回集合s的元素数量 如果x在集合s中存在,那么返回True,否则返回False 如果x不在集合s中,那么返回True,否则返回False 如果集合s中没有与集合other共有的元素,那么返回True,否则返回false,也就是用来判断两个集合是否有交集,有返回False,没有返回True 用于判断集合s是否是集合other的子集,如果是返回True,否则返回False。相关运算有s < other和s <= other 对于集合A和集合B,如果集合A中的所有元素在集合B中都有,那么集合A就是集合B的子集,集合B称为集合A的超集或父集;如果集合A不等于集合B,那么又称集合A是集合B的真子集 用于判断集合s是否是集合other的父集,也就是判断集合other是否是集合s的子集。相关运算有s > other和s >= other 返回集合s以及other指定的集合中的所有元素组成的一个新集合。计算集合的并集,相关运算有set | other |… 返回集合s以及other指定的集合中的公有元素组成的一个新集合。计算集合的交集,相关运算有set & other & … 返回集合s中有的,但other指定集合中没有的元素组成的一个新集合。计算集合的差集,相关运算有set - other - … 返回集合s中有的但集合other中没有的,或集合other中有的但集合s中没有的元素组成的一个新集合。计算集合的补集,相关运算有set ^ other 返回集合s的浅拷贝 上面几个函数的other参数不要求一定是集合,也可以是可迭代对象 由于set实例可变而frozenset实例不可变,所以下面是set对象独有的方法 更新集合s,添加来自 others 中的所有元素,该方法返回None,相当于s |= other |= …运算 更新集合s,只保留在所有other中也存在的元素,该方法返回None,相当于s &= other &=…运算 更新集合s,移除也存在于所有other中的元素,该方法返回None,相当于s -= other -=…运算 更新集合s,只保留存在于集合的一方而非共同存在的元素,该方法返回None,相当于s ^= other 将元素elem添加到集合s中,该方法返回None 移除集合s中的elem元素,如果elem不存在集合s中将引发KeyError异常 如果元素elem存在集合s中就将它移除,否则什么也不做,该方法返回None 从集合中移除任意一个元素,并返回该元素的值。如果集合为空将引发keyError异常 清空集合s中的元素,该方法返回None 求两个集合的并集、交集、差集、补集,set对象和frozenset对象运算的结果会是一个frozenset对象 参考资源:
运算符
含义
备注
<
严格小于
x
<=
小于或等于
x<=y,比较x和y的值,如果x<=y则返回True,否则返回False
>
严格大于
同上
>=
大于或等于
同上
==
等于
同上,但注意除了不同类型的两个数字对象之外,其他不同类型的两个对象不能进行相等比较
!=
不等于
同上
is
对象标识
判断两个标识符是不是引用同一对象,x is y相当于id(x) == id(y)
is not
否定的对象标识
判断两个标识符是不是引用不同对象,x is y相当于id(x) != id(y)


标准数据类型
Numbers(数字)
有符号整型int
#定义单个变量
a = 11
#连续定义多个变量
a = b = c = 22
#交互式赋值定义变量
a,b,c = 1,2,3
print(a,b,c) #1 2 3
print(type(a)) #
int()是Python的内置函数,用于生成一个整数0,或将一个字符串或数字转换为整型
#使用int()生成整型变量
a = int()
print(a,type(a)) #0 #将bool类型转换为整型
f1 = int(False)
print(f1,type(f1)) #0
bb = int('-111',0)
print(bb,type(bb)) #-111
aa = int('15',8)
print(aa,type(aa)) #13 整数的按位运算
x = 1 #001
y = 3 #011
z = x & y
print(z,type(z)) #1
按位取反运算得到的是一个补码,一个正数的原码、反码和补码是相等的,而一个负数的补码等于符号位不变,反码+1,反码又等于符号位不变,原码取反
所以当我们对一个数进行逐位取反时,一个正数会变成负数,一个负数会变成正数,那么取反之后的数该怎么计算呢?比如上面的对3逐位取反,首先3的二进制数是00000011,逐位取反得到11111100,得到的这个数是个补码,由于补码等于符号位不变,反码+1,那么这个数的反码等于1111100-1=1111011,那么这个数的原码等于0000100,加上符号位就是-4
浮点型float
#定义浮点型变量
a = 1.23
a = b = c = 2.1314
a,b = 11.0000,22.0
print(a,type(a)) #11.0
float()是Python的内置函数,用于生成一个浮点数0.0,或将一个字符串或数字转换为浮点型
#使用float生成浮点型变量
a = float()
print(a,type(a)) #0.0 #将bool类型转换为浮点型
f1 = float(False)
print(f1,type(f1)) #0.0
两个浮点数相加减的结果可能会有误差ff = 1.28+1.0
print(ff,type(ff)) #2.2800000000000002 复数complex
#定义复数变量
a = 1.5+3.4j
print(a,type(a)) #(1.5+3.4j)
complex()是Python的内置函数,用于生成一个0.0+0.0j的复数,或将一个字符串或数字转换为复数
#使用complex()生成一个复数
a = complex()
print(a,type(a)) #0j 数字类型的算法
数字运算
运算
含义
备注
x + y
求x加y
x - y
求x减y
x * y
求x乘以y
x / y
求x除以y
x // y
求x整除y
整除法:将商取整,如果商是个正小数那么直接取整数部分,如果商是个负小数,取-(整数部分+1)
x % y
求x/y的余数
求余法:x和y的余数总是等于x-y*(x//y)
-x
求(-1)*x
+x
x本身
x ** y
求x的y次幂
等同于内置函数power(x,y),规定power(0,0)=1或0**0 = 1
内置函数abs(x)
返回一个数的绝对值
如果参数为复数则返回它的模
内置函数divmod(x,y)
返回(x//y,x%y)
返回的是一个元组类型的对象
内置函数pow(x,y,mod=None)
返回x的y次幂
如果指定mod,那么返回(x^y)%mod
内置函数round(x,n=None)
返回浮点数x四舍五入的值
如果指定n,那么返回x舍入到小数点后n位的值
x = 12.3
y = 5
print(abs(x)) #12.3
print(divmod(x,y),type(divmod(x,y))) #(2.0, 2.3000000000000007) 数学函数math

math常量
常量
描述
备注
math.pi
表示圆周率π
math.pi = 3.141592653589793
math.e
表示自然底数e
math.e = 2.718281828459045
math.tau
表示圆的周长与半径之比T=2π
math.tau = 6.283185307179586
math.inf
表示正无穷大的浮点数,-math.inf表示负无穷大浮点数
math.inf = inf,type(math.inf) =
math.nan
表示浮点数nan,仅代表一个“非数字的”浮点值
math.nan = nan,type(math.nan)=float
数论与表示函数
函数
描述
备注
math.ceil(x)
返回大于或等于x的最小整数
正小数,小数点后面只要有大于0的数,那么就向上取整(负小数直接取整)
math.floor(x)
返回小于或等于x的最大整数
负小数,小数点后面只要有大于0的数,那么就向下取整(正小数直接取整)
math.comb(n,k)
返回从n项中取k项的可能组合数
n,k必须是正整数,如果k>n那么返回0,如果k=0那么返回1
math.perm(n,k)
返回不重复且有顺序的从n项中取k项的可能组合数
同math.comb(n,k)
math.copysign(x,y)
返回一个新的浮点数x,这个x的正负取决于y
y=-0时取+,y=-0.0时取-
math.fabs(x)
返回x的绝对值
总是返回一个浮点数
math.fmod(x,y)
返回x%y,总是返回一个浮点数
一般整数首选x%y运算符,浮点数首选math.fmod(x,y)
math.frexp(x)
以(m,e)的形式返回x的指数和尾数,总是返回一个元组对象
x=m*2**e(0.5<=m<1),如果x为0则返回(0.0,0)
math.ldexp(m,e)
返回m*2**e的值,总是返回浮点数
相当于math.frexp(x)的反函数
math.fsum(iterable)
返回一个可迭代对象的元素总和,跟sum()相比他总是返回一个精确的浮点数
要求可迭代对象里面的元素必须是整数或浮点数
math.gcd(*int)
返回给定整数的最大公约数,总是返回正整数
可以有0个或多个整数参数,参数为空时返回0
math.lcm(*int)
返回给定整数的最小公倍数,总是返回正整数
可以有0个或多个整数参数,参数为空时返回1
math.isclose(x,y)
判断x和y是否接近,是返回True,否返回False
math.isfinite(x)
如果x既不是无穷大也不是nan,那么返回True,否则返回False
math.isinf(x)
如果x是无穷大,那么返回True,否则返回False
math.isnan(x)
如果x是nan,那么返回True,否则返回False
math.isqrt(x)
返回x的整数平方根
x必须是非负整数,平方根向下取整
math.modf(x)
返回元组(f,i),f属于x的小数部分,i属于x的整数部分
f不一定准确,f和i都是浮点数
math.prod(iterable,start=1)
返回可迭代对象所有元素的乘积,乘积的默认初始值为1
math.trunc(x)
返回去除x小数部分的整数
import math
a = math.fsum([1.0,1.2,2,3])
print(a,type(a)) #7.2 Boolean(布尔)
#定义bool变量
a = False
b = True
a = b = c = True
a,b = True,False
print(a,type(a)) #True
bool()是Python的内置函数,用于生成一个值为False的布尔变量,或将给定参数转换为布尔类型
#bool()转换
a1 = bool()
print(a1,type(a1)) #False
由于bool类继承int类,所以bool类型值可以相加减,相加减的时候true就代表1,false就代表0,相加的结果将是个int类型#布尔值相加减
a = bool('00')
b = True
print(a,type(a)) #True 序列类型
通用序列操作
运算
描述
备注
x in s
如果x在序列s中就返回True,否则返回False
x not in s
如果x不在序列s中就返回True,否则返回False
s + t
s拼接t
要求s和t必须是同类型的,否则无法相拼接;range对象无法做拼接
s * n或n * s
相当于s与自身进行n次拼接
n小于等于0时,会得到一个跟s同类型的空序列
s[i]
s中下标为i的项,下标从0开始
s[i:j]
返回下标从i到j的切片
s[i:j:k]
返回下标从i到j,步长为k的切片
len(s)
返回s的长度
调用__len__函数
min(s)
返回s中的最小项
max(s)
返回s中的最大项
s.index(x[, i[, j]])
返回x在s中第一次出现的索引
[i,j]表示查找范围,i代表的下标值一定要在j的左边
s.count(x)
返回x在s中出现的次数
s * n
a = 'avdhwj'
a1 = a*3
print(a1) #avdhwjavdhwjavdhwj
print(a is a1) #False
b = (11,22)
b1 = b*3
print(b1) #(11, 22, 11, 22, 11, 22)
print(b is b1) #False
c = [1]
c1 = c*3
print(c) #[1, 1, 1]
print(c is c1) #False
print(id(c[0]),id(c1[1]),id(c1[2])) #140725936583464 140725936583464 140725936583464
#里面的元素引用的是同一个对象
lists = [[],[1]]
l = lists * 3
print(lists) #[[], [1]]
print(l) #[[], [1], [], [1], [], [1]]
l[0].append('a')
l[1].clear()
print(lists) #[['a'], []]
print(l) #[['a'], [], ['a'], [], ['a'], []]
切片
#切片
s = 'adfvgbrhnewadfgbfh'
n = len(s)
print(n) #18
#k>=1
print(s[1:20:3]) #dghwff
#-10和8刚好都是n,所以i不在j的左边,直接返回空
print(s[-10:8:]) #''
#-10是n,10是w,那么取到10的前一位
print(s[-10:10:]) #ne
#k<=-1
#默认i=len(s)=18
print(s[::-5]) #hdhf
#i不在j的右边直接返回空
print(s[1:10:-1]) #''
#-1是h,-11是r,h在r的右边,取到r的前一个
print(s[-1:-11:-3]) #hgan
#
s = 'adfvgbrhnewadfgbfh'
n = len(s)
print(n) #18
#i默认为0
print(s[:5]) #adfvg
print(s[0:5]) #adfvg
#j默认为len(s)
print(s[10:]) #wadfgbfh
print(s[10:18]) #wadfgbfh
#i默认为len(s)
print(s[:7:-1]) #hfbgfdawen
print(s[17:7:-1]) #hfbgfdawen
#j为空,默认取完,跟j为0结果不一样
print(s[5::-1]) #bgvfda
print(s[5:0:-1]) #bgvfd
不可变序列类型通用操作
对象的可哈希性使得该对象能够作为字典键或集合成员使用,因为这些数据结构要在内部使用哈希值可变序列类型通用操作
运算
描述
备注
s[i]=x
将可变序列s中下标为i的项修改为x
s[i:j]=t
将可变序列s从i到j的切片替换为可迭代对象t
del s[i:j]
将可变序列s从i到j的切片删除
s[i:j:k]=t
将s[i:j:k]的元素替换为可迭代对象t的元素
与s[i:j]不同的是,这里是将切片得到的元素替换为t中的元素,所以s[i:j:k]的元素个数要和t元素个数一致,否则会引发ValueError
del s[i:j:k]
从可变序列s中移除s[i:j:k]元素
s.append(x)
将x追加到可变序列s末尾
s.clear()
从可变序列s中移除所有项
s.copy()
创建s的浅拷贝
s.extend(t)
将可迭代对象t中的元素追加到可变序列s末尾
s.insert(i,x)
在可变序列s的索引i处插入x
s.pop(i)
移除下标为i的项,并返回该项的值
s.remove(x)
删除可变序列s中第一个值为x的项
找不到x就引发ValueError
s.reverse()
就地将序列中的元素翻转
s = [1,'2',(3,),range(10,2)]
print(s) #[1, '2', (3,), range(10,2)]
s[3] = 33
print(s) #[1, '2', (3,), 33]
s[2:] = '12345'
print(s) #[1, '2', '1', '2', '3', '4', '5']
del s[:2]
print(s) #['1', '2', '3', '4', '5']
s[:9:-1] = ''
print(s) #['1', '2', '3', '4', '5']
String(字符串)
#定义字符串
a = '这是' \
'一个"字符串"' #换行使用\来连接,\后面不能有空格
b = "I'm " \
"coco"
c = """第一行
第二行
第三行
"""
print(a,type(a)) #这是一个"字符串"
str()是Python的内置函数,用于生成一个空字符串或者返回一个对象的字符串版本

字符串方法
方法
描述
备注
str.capitalize()
返回原字符串的副本,其首字母大写,其他字母小写
如果第一个字符不是字母那么不会有大写字母
str.title()
返回原字符串的标题版本,其中每个单词的首字母为大写,其他字母为小写
str.casefold()
返回原字符串的副本,其所有字母全部变为小写
str.lower()
返回原字符串的副本,其所有区分大小写的字符转变为小写
str.upper()
返回原字符串的副本,其所有区分大小写的字符转变为大写
str.swapcase()
返回原字符串的副本,其所有大写字符变为小写,小写字符变为大写
str.center(width)
返回长度为width的字符串,原字符串居中
如果width<=len(str)那么返回原字符串
str.ljust(width)
返回长度为width的字符串,原字符串靠左对齐
同center()
str.rjust(width)
返回长度为width的字符串,原字符串靠右对齐
同center()
str.zfill(width)
返回长度为width的字符串,长度不够width的在前面补0,如果带有正负号那么在正负号后面补0
str.count(sub[,start[,end])
返回子字符串在[start,end]范围内出现的次数
start默认为0,end默认为len(str)-1,两个数可以是任意整数
str.encode(encoding=“utf-8”, errors=“strict”)
返回字符串编码后的字节串
默认使用utf-8编码
str.startswith(prefix[, start[, end])
判断字符串是否以prefix开头,是返回True,不是返回False
prefix可以是字符串(空字符串)或元组(元素只能是字符串类型),必须以该字符串开头,或者必须以元组中某一元素开头才会返回True
str.endswith(suffix[, start[, end])
判断字符串是否以suffix结尾,是返回True,不是返回False
同startswith()
str.find(sub[,start[,end])
返回子字符串在切片内被找到的最小索引
如果未找到就返回-1
str.index(sub[,start[,end])
同find(),但该方法找不到会抛出异常ValueError
str.rfind(sub[, start[, end]])
返回子字符串在切片内被找到的最大索引
如果未找到返回-1
str.rindex(sub[, start[, end]])
同rfind(),但该方法未找到抛出异常ValueError
str.join(iterable)
返回一个由可迭代对象中的字符串拼接而成的字符串,str为分隔符
可迭代对象中只允许有字符串类型的对象,否则引发TypeError异常
str.partition(sep)
在sep首次出现的位置拆分字符串,返回一个三元组(分隔符之前的部分,分隔符,分隔符之后的部分)
str.rpartition(sep)
在sep最后一次出现的位置拆分字符串,返回一个三元组(分隔符之前的部分,分隔符,分隔符之后的部分)
str.replace(old, new[, count])
在字符串中将old替换为new
count表示替换多少次,默认是全部替换
str.split(sep=None, maxsplit=-1)
返回一个由字符串内单词组成的列表,使用 sep 作为分隔字符串。 如果给出了 maxsplit,则最多进行 maxsplit 次拆分
如果存在连续个sep,那么这些sep之间默认被分隔成空字符串;如果参数为空那么分隔符默认为空格
str.rsplit(sep=None,maxsplit=-1))
同split(),但该方法是从右到左
str.splitlines(keepends=False)
返回由原字符串中各行组成的列表,在行边界的位置拆分
str.strip(chars)
将原字符串前导和末尾的chars字符移除后返回
str.lstrip(chars)
将原字符串前导的chars字符移除后返回
str.rstrip(chars)
将原字符串末尾的chars字符移除后返回
str.isalnum()
如果字符串中的所有字符都是字母或数字,且字符串长度大于等于1,那么返回True,否则返回false
str.isalpha()
如果字符串中的所有字符都是字母,且字符串长度大于等于1,那么就返回True,否则返回False
str.isascii()
如果字符串为空或字符串中所有字符全是ASCII,那么就返回True,否则返回False
str.isdecimal()
如果字符串中的所有字符都是十进制字符,且字符串长度大于等于1,那么返回True,否则返回False
str.isdigit()
如果字符串中的所有字符都是数字,且字符串长度大于等于1,那么返回True,否则返回False
str.isidentifier()
判断str是否是一个有效的标识符,是则返回True,不是返回False
str.islower()
如果字符串中包含字母,且字母都为小写,那么返回True,否则返回False
str.isnumeric()
如果字符串中所有字符均为数值,那么返回True,否则返回False
str.isprintable()
如果字符串中所有字符均为可打印字符或字符串为空,那么返回True,否则返回False
str.isspace()
如果字符串中只有空白字符且至少包含一个字符,那么返回True,否则返回False
str.istitle()
如果字符串中包含字母,且首字母大写,且连续,那么返回True,否则返回false
str.isupper()
如果字符串中包含字母,且字母全为大写,那么返回True,否则返回False
str.join(iterable)
#join()方法
a = 'sdgh,erbjpn vqhif'
b = ('1','2','3','a','b','c')
c = ['1','2','3','a','b','c']
d = {'1':1,'2':2,'3':3}
s = {'a','b','c','d'}
print(','.join(a)) #s,d,g,h,,,e,r,b,j,p,n, ,v,q,h,i,f
print(''.join(b)) #123abc
print(','.join(c)) #1,2,3,a,b,c
print(','.join(d)) #1,2,3
print(','.join(s)) #a,b,c,d
str.partition(sep)
#partition()方法
a = 'sdghi,erbjpn vqhif'
print(a.partition('123')) #('sdghi,erbjpn vqhif', '', '')
print(a.partition('hi')) #('sdg', 'hi', ',erbjpn vqhif')
str.split(sep=None, maxsplit=-1)
#字符串方法
a = ' 1323D VDWSdsvAsdvsaa a135fw '
print(a.split()) #['1323D', 'VDWSdsvAsdvsaa', 'a135fw']
#分隔符左右没字符的当作空字符来处理
print(a.split(' '*2)) #['', '1323D', '', '', '', '', 'VDWSdsvAsdvsaa', 'a135fw', '']
print(a.split('a')) #[' 1323D VDWSdsvAsdvs', '', ' ', '135fw ']
print(a.split('3',2)) #[' 1', '2', 'D VDWSdsvAsdvsaa a135fw ']
print(a.split('')) #ValueError: empty separator
#str为空字符串
a = ''
print(a.split('1')) #['']
print(a.split()) #[]
#split()和rsplit()的区别
print(a.split('3',2)) #[' 1', '2', 'D VDWSdsvAsdvsaa a135fw ']
print(a.rsplit('3',2)) #[' 132', 'D VDWSdsvAsdvsaa a1', '5fw ']
str.splitlines(keepends=False)
表示符
描述
\n
换行符
\r
回车符
\r\n
回车加换行
\v或\x0b
行制表符
\f或\x0c
换表单
\x1c
文件分隔符
\x1d
组分隔符
\x1e
记录分隔符
\x85
下一行
\u2028
行分隔符
\u2029
段分隔符
print('esgrh\nsd'.splitlines()) #['esgrh', 'sd']
print('esgrh\n'.splitlines()) #['esgrh']
print('\n'.splitlines()) #['']
print(''.splitlines()) #[]
print(' ew'.splitlines()) #[' ew']
str.strip(chars)
#字符串方法
a = ' swesfrs'
print(a.strip()) #swesfrs
print(a.strip('')) # swesfrs
#chars包含了末端字符'esfrs'
print(a.strip('fevfas234r')) # sw
#chars包含了'swesfrs',只要能在首端或末端将全部字符移除,那么另一个方向的空格符也会一同被移除
print(a.strip('wfevfas234r')) #空字符串
字符串格式化输出
在字符串前面加’f’或’F’前缀,那么就可以在字符串中使用{}表达式代表替换字段name = 1.3141596
a = 12
b = 34
#两个花括号会被当作一个来对待
print(f"this is {{}},{{{a = }}},{b = }") #this is {},{a = 12},b = 34
# 替换字段后面加:,冒号后的第一位数代表该值的宽度
# 如果该值是个浮点数,那么宽度后面加小数点,小数点后面的数代表保留几位数(会进行四舍五入)
# 如果小数点后面的数带一个f后缀,那就代表保留几位小数(会进行四舍五入)
print(f'this is name={name:10.4f}') #this is name= 1.3142
# {}表达式输出计算结果
print(f'this is a+b={a+b}') #this is a+b=46
today = datetime(year=2023, month=3, day=5)
#输出时间
print(today)
print(f'{today=:%B %d %Y}')
默认是以右对齐的方式输出,%-表示以左对齐的方式输出,%0表示输出宽度不够时用0填补,%+表示显示正数的正号,占位符如下
name = 'Python'
c = 1.3141596
a = -12
b = 34
print('my name is %s' % name)
print('(%d+%d)=%d' % (a,b,a+b))
print('this is %.4f' % c)
print('%c' % name[0])
print('%u' % a)
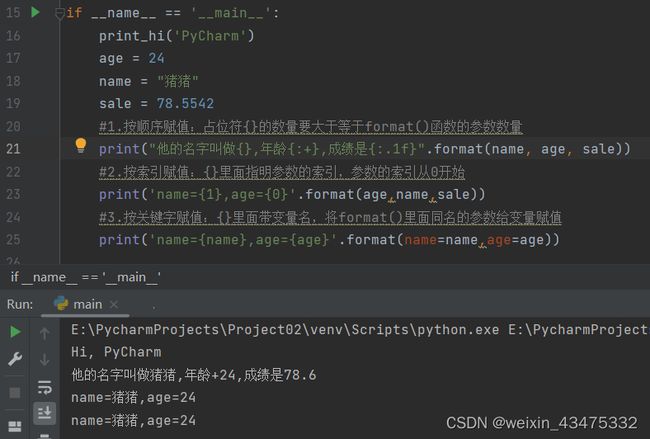
Tuple(元组)
**当圆括号里面只有一个对象时,就表示该对象本身,而不是一个元组,如果想定义只包含一个元素的元组,那么元素后面必须有一个逗号#定义元组
a = ()
print(a,type(a)) #()
tuple()是Python的内置函数,用于生成一个空元组,或将可迭代对象转换成元组
a = tuple()
print(a,type(a)) #() List(列表)
#定义列表
a = []
print(a,type(a)) #[]
list()是Python的内置函数,用来生成一个空列表,或将可迭代对象转化为列表类型
a = list()
print(a,type(a)) #[] 列表方法
list.append(x)
#列表方法list.append()
a = []
a.append(1)
a.append(False)
a.append('')
a.append(())
a.append([])
a.append({})
a.append({1})
print(a) #[1, False, '', (), [], {}, {1}]
list.extend(iterable)
#列表方法list.aextend()
a = []
a.extend('123')
a.extend(('123','123',(11,22)))
a.extend(['1','2','12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
print(a) #['1', '2', '3', '123', '123', (11, 22), '1', '2', '12', 1, 2, 3, 'c', (12, 23), 'a', 'b']
list.insert(i,x)
#列表方法list.insert()
a = []
a.extend('123')
a.extend(('123','123',(11,22)))
a.extend(['1','2','12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
a.insert(0,True)
a.insert(-10,-1)
print(a) #[True, '1', '2', '3', '123', '123', (11, 22), -1, '1', '2', '12', 1, 2, 3, 'c', (12, 23), 'b', 'a']
list.remove(x)
#列表方法list.remove()
a = []
a.extend('123')
a.extend(('123','123',(11,22)))
a.extend(['1',0,'12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
a.insert(0,True)
a.insert(-10,-1)
a.insert(len(a)+5,0)
print(a) #[True, '1', '2', '3', '123', '123', (11, 22), -1, '1', 0, '12', 1, 2, 3, 'a', (12, 23), 'c', 'b', 0]
a.remove('123')
a.remove(False)
print(a) #[True, '1', '2', '3', '123', (11, 22), -1, '1', '12', 1, 2, 3, 'a', (12, 23), 'c', 'b', 0]
list.pop([i])
#列表方法list.pop()
a = []
a.extend('123')
a.extend(('123','123',(11,22)))
a.extend(['1','2','12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
a.insert(0,True)
a.insert(-10,-1)
a.insert(len(a)+5,-5)
a.remove('123')
print(a.pop()) #-5
print(a.pop(-10)) #1
print(a) #[True, '1', '2', '3', '123', (11, 22), -1, '2', '12', 1, 2, 3, 'c', 'a', (12, 23), 'b']
list.clear()
#列表方法list.clear()
a = []
a.extend('123')
a.extend(('123','123',(11,22)))
a.extend(['1','2','12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
a.insert(0,True)
a.insert(-10,-1)
a.insert(len(a)+5,-5)
a.remove('123')
print(a.pop()) #-5
print(a.pop(-10)) #1
a.clear()
print(a) #[]
list.index(x[, start[, end]])
#列表方法list.index()
a = []
a.extend('123')
a.extend(('123','123',(11,22)))
a.extend(['1',0,'12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
a.insert(0,True)
a.insert(-10,-1)
a.insert(len(a)+5,0)
print(a.index(1)) #0
print(a.index(False)) #9
print(a.index('1',5,-5)) #8
print(a) #[True, '1', '2', '3', '123', '123', (11, 22), -1, '1', 0, '12', 1, 2, 3, 'c', (12, 23), 'b', 'a', 0]
list.count(x)
#列表方法list.count()
a = []
a.extend('123')
a.extend(('123','123',()))
a.extend(['1',0,'12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
a.insert(0,True)
a.insert(-10,-1)
a.insert(len(a)+5,0)
print(a.count(1))
print(a.count(False))
print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0]
list.sort()
list.reverse()
#列表方法list.reverse()
a = []
a.extend('123')
a.extend(('123','123',()))
a.extend(['1',0,'12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
a.insert(0,True)
a.insert(-10,-1)
a.insert(len(a)+5,0)
print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0]
a.reverse()
print(a) #[0, 'c', 'b', 'a', (12, 23), 3, 2, 1, '12', 0, '1', -1, (), '123', '123', '3', '2', '1', True]
list.copy()
#list.copy()
a = [1,'2',(3,4),[5,6],{7:7},{8}]
b = a.copy()
print(b)
print(id(a)) #2783887325120
print(id(b)) #2783891229632
print(a[0] is b[0]) #True
print(a[1] is b[1]) #True
print(a[2] is b[2]) #True
print(a[3] is b[3]) #True
print(a[4] is b[4]) #True
print(a[5] is b[5]) #True
import copy
a = (1,'2',(3,4),[5,6],{7:7},{8})
b = copy.deepcopy(a)
print(b)
print(id(a)) #2452158272832
print(id(b)) #2452158276576
print(a[0] is b[0]) #True
print(a[1] is b[1]) #True
print(a[2] is b[2]) #True
print(a[3] is b[3]) #False
print(a[4] is b[4]) #False
print(a[5] is b[5]) #False
import copy
a = (1,'2',(3,4))
b = copy.deepcopy(a)
print(b)
print(id(a)) #1635445769408
print(id(b)) #1635445769408
print(a[0] is b[0]) #True
print(a[1] is b[1]) #True
print(a[2] is b[2]) #True
del语句
#del语句
a = []
a.extend('123')
a.extend(('123','123',()))
a.extend(['1',0,'12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
a.insert(0,True)
a.insert(-10,-1)
a.insert(len(a)+5,0)
print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0]
del a[0]
del a[0:5]
print(a) #[(), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0]
del a
print(a) #NameError: name 'a' is not defined
列表排序
简单排序
list.sort()方法是列表的内置方法,用于直接修改列表进行排序,由于是在各项间进行比较来排序的,所以如果比较操作失败,整个排序失败,就会导致这个列表处在被部分修改的状态
#list.sort()排序
a = [4,6,8,3,0,5,1]
a.sort()
print(a) #[0, 1, 3, 4, 5, 6, 8]
a.sort(reverse=True)
print(a) #[8, 6, 5, 4, 3, 1, 0]
b = ['a','s','D','f','g','h']
#sort()默认是比较ASCII码大小来排序的
b.sort()
print(b) #['D', 'a', 'f', 'g', 'h', 's']
#str.lower用于在比较前将每一项全部转换为小写
b.sort(key=str.lower)
print(b) #['a', 'D', 'f', 'g', 'h', 's']
sorted()是Python的内置函数,用于给可迭代对象进行排序并返回一个已排序列表,所以他所服务的对象不仅仅是列表,而且他和list.sort()最大的区别在于他不会去直接修改原对象,而是对原对象排序后返回一个新的已排序列表
#sorted()排序
#将字符串排序
a = 'asdfgnbvc'
print(sorted(a))
#将元组排序
b = ('ad','wgvd','dQ','SA')
print(sorted(b))
#将列表排序
c = [3,45,67,32,76]
print(sorted(c))
#将字典排序,只对key排序输出
d = {'1':1,'9':2,'3':0}
print(sorted(d))
#对集合排序
e = {11,4,9,3,-1}
print(sorted(e))
高级排序
#使用str.lower函数
a = "This is a test string from Andrew".split()
a.sort(key=str.lower) #['a', 'Andrew', 'from', 'is', 'string', 'test', 'This']
print(a)
b = sorted("This is a test string from Andrew".split(),key=str.lower)
print(b)
#使用lambda函数
ss = [('shanghai',80),('guangzhou',90),('hangzhou',70)]
ssa = sorted(ss,key=lambda x:x[1])
print(ssa) #[('hangzhou', 70), ('shanghai', 80), ('guangzhou', 90)]
ss.sort(key=lambda x:x[0])
print(ss) #[('guangzhou', 90), ('hangzhou', 70), ('shanghai', 80)]
列表去重
set()去重
#set()去重
a = []
a.extend('123')
a.extend(('123','123',()))
a.extend(['1',0,'12'])
a.extend({1:[1],2:[2],3:[3]})
a.extend({'a','b','c',(12,23)})
a.insert(0,True)
a.insert(-10,-1)
a.insert(len(a)+5,0)
print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0]
a = list(set(a))
print(a) #[0, True, '123', 2, '2', '1', '3', 3, (12, 23), 'a', '12', 'b', (), 'c', -1]
print(a) #[True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0]
b = list(set(a))
print(b) #[0, True, '123', 2, '2', '1', '3', 3, (12, 23), 'a', '12', 'b', (), 'c', -1]
b.sort(key=a.index)
print(b) #[True, '1', '2', '3', '123', (), -1, 0, '12', 2, 3, 'b', (12, 23), 'c', 'a']
#使用sorted()更便捷,一行代码搞定
a = sorted(list(set(a)),key=a.index)
print(a) #[True, '1', '2', '3', '123', (), -1, 0, '12', 2, 3, 'b', 'c', (12, 23), 'a']
dict.fromkeys()去重
#dict.fromkeys()去重
a = [True, '1', '2', '3', '123', '123', (), -1, '1', 0, '12', 1, 2, 3, (12, 23), 'a', 'c', 'b', 0]
b = list(dict.fromkeys(a))
print(b) #[True, '1', '2', '3', '123', (), -1, 0, '12', 2, 3, (12, 23), 'a', 'c', 'b']
range对象
a = str(range(5,2))
print(a) #range(5, 2)
t = tuple(range(10))
print(t) #(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
s = list(range(1,20,3))
print(s) #[1, 4, 7, 10, 13, 16, 19]
s1 = list(range(0))
print(s1) #[]
s2 = list(range(10,20,-2))
print(s2) #[]
d = set(range(10,2,-1))
print(d) #{3, 4, 5, 6, 7, 8, 9, 10}
映射类型
Dict(字典)
#定义字典
a = 1
b = '12'
c = (23,'3')
#由于1和1.0在字面上相等,所以只会创建一个映射,键值取后写的那个
d = {a:10,b:2,c:3,1.0:4}
print(d) #{1: 4, '12': 2, (23, '3'): 3}
#任何值为1的键都可以用来索引同一条目
print(d[1],d[1.0],d[True]) #4 4 4
d1 = {}
print(d1) #{}
#使用字典推导式
d2 = {x:x for x in range(4)}
print(d2) #{0: 0, 1: 1, 2: 2, 3: 3}
dict()是Python内置的字典构造器,用于生成一个空字典或将其他类型转换为字典
#dict()
d1 = {1:'a',2:'b','3':'c'}
d2 = dict(d1)
print(d2) #{1: 'a', 2: 'b', '3': 'c'}
print(d2 is d1) #False
d2 = dict(((1,2),))
print(d2) #{1: 2}
d3 = dict([(1,['a']),[2,'b'],('one','abc')],one=123)
print(d3) #{1: ['a'], 2: 'b', 'one': 123}
d4 = dict(one='aa',two='bb',three='cc')
print(d4) #{'one': 'aa', 'two': 'bb', 'three': 'cc'}
d5 = dict(zip('iloveyou',(0,1,3,[5])))
print(d5) #{'i': 0, 'l': 1, 'o': 3, 'v': [5]}
字典方法
len(d)
d[key]
d[key]=value
del d[key]
if key in d
if key not in d
iter(d)
d.clear()
d.copy()
dict.fromkeys(iterable[,value])
d.get(key[,default])
d.items()
d.keys()
d.values()
d.pop(key[,default])
d.popitem()
reversed(d)
a = [11,22,33]
b = dict.fromkeys(a,'ab')
print(b) #{11: 'ab', 22: 'ab', 33: 'ab'}
print(list(reversed(b))) #[33, 22, 11]
d.setdefault(key[,default])
d.update([other])
d5 = dict(zip('iloveyou',(0,1,3,[5])))
print(d5) #{'i': 0, 'l': 1, 'o': 3, 'v': [5]}
#参数为字典
other = {'i':333,'sb':'sbsbsb'}
print(d5.update(other)) #None
print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb'}
#参数为空
other = ''
print(d5.update(other)) #None
print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb'}
#参数为元组
other = ((21,22),['fd','gf'],['kkk',[1,2,3]])
print(d5.update(other)) #None
print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb', 21: 22, 'fd': 'gf', 'kkk': [1, 2, 3]}
#参数为列表
other = [(21,20),['fd','df'],['kkk',[1,2,3]]]
print(d5.update(other)) #None
print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb', 21: 20, 'fd': 'df', 'kkk': [1, 2, 3]}
#参数为集合,集合里面不能出现任何不可哈希对象
other = {(21,(25,False)),(9,0)}
print(d5.update(other)) #None
print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb', 21: (25, False), 'fd': 'df', 'kkk': [1, 2, 3], 9: 0}
#参数为关键字参数
other = {'i':333,'sb':'sbsbsb'}
d5.update(one='one',two='two')
print(d5) #{'i': 0, 'l': 1, 'o': 3, 'v': [5], 'one': 'one', 'two': 'two'}
d | other
d5 = dict(zip('iloveyou',(0,1,3,[5])))
print(d5) #{'i': 0, 'l': 1, 'o': 3, 'v': [5]}
#d | other
other = {'i':333,'sb':'sbsbsb'}
print(other | d5) #{'i': 0, 'sb': 'sbsbsb', 'l': 1, 'o': 3, 'v': [5]}
d |= other
字典的比较运算
d5 = dict(zip('iloveyou',(0,1,3,[5])))
print(d5) #{'i': 0, 'l': 1, 'o': 3, 'v': [5]}
other = {'i':333,'sb':'sbsbsb'}
d6 = d5 | other
d5 |=other
#字典比较
if d5 == d6:
print(d5) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb'}
print(d6) #{'i': 333, 'l': 1, 'o': 3, 'v': [5], 'sb': 'sbsbsb'}
集合
#集合定义,集合中只能包含可哈希对象
a = {1,2,3,4}
print(a,type(a)) #{1, 2, 3, 4}
set()函数和frozenset()函数都是集合的构造器,区别在于frozense()创建的是一个不可变的集合,是可哈希的,而set()函数创建的是可变的集合,不可哈希,所以frozense()创建的集合可以当作字典的键或者集合元素
#set()和frozenset()
a = frozenset()
b = set()
print(hash(a)) #133146708735736
print(hash(b)) #TypeError: unhashable type: 'set'
#参数为空
a = frozenset()
b = set()
print(a,b) #frozenset() set()
#参数是字符串
a = frozenset('abc')
b = set('12345')
print(a,b) #frozenset({'a', 'c', 'b'}) {'3', '1', '2', '5', '4'}
#参数是元组,元组里面不能包含不可哈希对象
a = frozenset((1,2,'a','b'))
b = set(('a1','a2','a3'))
print(a,b) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'}
#参数是列表,列表里面不能包含不可哈希对象
a = frozenset([1,2,'a','b'])
b = set(['a1','a2','a3'])
print(a,b) #frozenset({1, 2, 'a', 'b'}) {'a2', 'a3', 'a1'}
#参数是字典,取字典的key
a = frozenset({1:1,2:'a',3:3})
b = set({1:1,2:'a',3:3})
print(a,b) #frozenset({1, 2, 3}) {1, 2, 3}
#参数是frozenset对象
b = set(a)
print(b) #{1, 2, 'a', 'b'}
集合方法
len(s)
if x in s
if x not in s
s.isdisjoint(other)
s.issubset(other)
s.issuperset(other)
s.union(*others)
s.intersection(*others)
s.difference(*others)
s.symmetric_difference(other)
s.copy()
set方法
s.update(*others)
s.intersection_update(*others)
s.difference_update(*others)
s.symmetric_difference_update(other)
s.add(elem)
s.remove(elem)
s.discard(elem)
s.pop()
s.clear()
集合运算
并集set_a | set_b
a = frozenset((1,2,'a','b'))
b = set((1,'a1','a2','a3'))
c = set('1njq')
print(a,b,c) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'} {'q', 'n', '1', 'j'}
print(a | b) #frozenset({'a2', 1, 2, 'a', 'a1', 'b', 'a3'})
print(b | c) #{1, 'q', '1', 'a2', 'j', 'n', 'a1', 'a3'}
交集set_a & set_b
a = frozenset((1,2,'a','b'))
b = set((1,'a1','a2','a3'))
c = set('1njq')
print(a,b,c) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'} {'q', 'n', '1', 'j'}
print(a & b) #frozenset({1})
print(b & c) #set()
差集set_a - set_b
a = frozenset((1,2,'a','b'))
b = set((1,'a1','a2','a3'))
c = set('1njq')
print(a,b,c) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'} {'q', 'n', '1', 'j'}
print(a - b) #frozenset({2, 'a', 'b'})
print(b - c) #{'a1', 'a2', 'a3', 1}
补集set_a ^ set_b
a = frozenset((1,2,'a','b'))
b = set((1,'a1','a2','a3'))
c = set('1njq')
print(a,b,c) #frozenset({'b', 1, 2, 'a'}) {'a3', 'a1', 'a2'} {'q', 'n', '1', 'j'}
print(a ^ b) #frozenset({2, 'a1', 'a3', 'a2', 'b', 'a'})
print(b ^ c) #{'q', 1, 'a1', 'n', 'a3', 'a2', 'j', '1'}
https://docs.python.org/zh-cn/3.9/library/stdtypes.html#