Redis分布式基石——主从复制技术详述,大厂Java面试真题精选
简介
基于SpringCloud(Hoxton.SR1) + SpringBoot(2.2.4.RELEASE) 的 SaaS型微服务脚手架,具备用户管理、资源权限管理、网关统一鉴权、Xss防跨站攻击、自动代码生成、多存储系统、分布式事务、分布式定时任务等多个模块,支持多业务系统并行开发, 支持多服务并行开发,可以作为后端服务的开发脚手架。代码简洁,架构清晰,非常适合学习使用。核心技术采用Nacos、Fegin、Ribbon、Zuul、Hystrix、JWT Token、Mybatis、SpringBoot、Seata、Nacos、Sentinel、 RabbitMQ、FastDFS等主要框架和中间件。
希望能努力打造一套从 SaaS基础框架 - 分布式微服务架构 - 持续集成 - 系统监测 的解决方案。本项目旨在实现基础能力,不涉及具体业务。
2.1.2 命令传播
当同步工作完成之后,主从之间需要通过命令传播来维持数据状态的一致性。
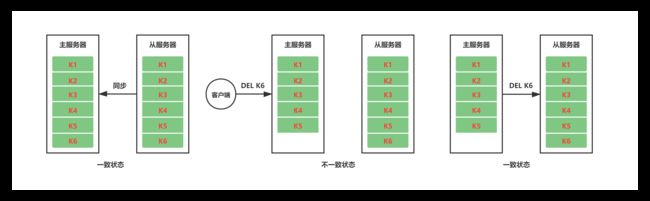
如下图,当前主从服务器之间完成同步工作之后,主服务接收客户端的DEL K6指令后删除了K6,此时从服务器仍然存在K6,主从数据状态并不一致。为了维持主从服务器状态一致,主服务器会将导致自己数据状态发生改变的命令传播到从服务器执行,当从服务器也执行了相同的命令之后,主从服务器之间的数据状态将会保持一致。
2.1.3 缺陷
从上面看不出2.8以前版本的主从复制有什么缺陷,这是因为我们还没有考虑网络波动的情况。了解分布式的兄弟们肯定听说过CAP理论,CAP理论是分布式存储系统的基石,在CAP理论中P(partition网络分区)必然存在,Redis主从复制也不例外。当主从服务器之间出现网络故障,导致一段时间内从服务器与主服务器之间无法通信,当从服务器重新连接上主服务器时,如果主服务器在这段时间内数据状态发生了改变,那么主从服务器之间将出现数据状态不一致。
在Redis 2.8以前的主从复制版本中,解决这种数据状态不一致的方式是通过重新发送sync命令来实现。虽然sync能保证主从服务器数据状态一致,但是很明显sync是一个非常消耗资源的操作。
sync命令执行,主从服务器需要占用的资源:
-
主服务器执行BGSAVE生成RDB文件,会占用大量CPU、磁盘I/O和内存资源
-
主服务器将生成的RDB文件发送给从服务器,会占用大量网络带宽,
-
从服务器接收RDB文件并载入,会导致从服务器阻塞,无法提供服务
从上面三点可以看出,sync命令不仅会导致主服务器的响应能力下降,也会导致从服务器在此期间拒绝对外提供服务。
2.2 版本2.8-4.0
2.2.1 改进点
针对2.8以前的版本,Redis在2.8之后对从服务器重连后的数据状态同步进行了改进。改进的方向是减少全量同步(full resynchronizaztion)的发生,尽可能使用增量同步(partial resynchronization)。在2.8版本之后使用psync命令代替了sync命令来执行同步操作,psync命令同时具备全量同步和增量同步的功能:
-
全量同步与上一版本(sync)一致
-
增量同步中对于断线重连后的复制,会根据情况采取不同措施;如果条件允许,仍然只发送从服务缺失的部分数据。
2.2.2 psync如何实现
Redis为了实现从服务器断线重连后的增量同步,增加了三个辅助参数:
-
复制偏移量(replication offset)
-
积压缓冲区(replication backlog)
-
服务器运行id(run id)
2.2.2.1 复制偏移量
在主服务器和从服务器内都会维护一个复制偏移量
-
主服务器向从服务发送数据,传播N个字节的数据,主服务的复制偏移量增加N
-
从服务器接收主服务器发送的数据,接收N个字节的数据,从服务器的复制偏移量增加N
正常同步的情况如下:
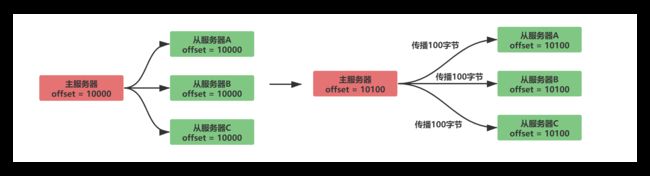
通过对比主从服务器之间的复制偏移量是否相等,能够得知主从服务器之间的数据状态是否保持一致。
假设此时A/B正常传播,C从服务器断线,那么将出现如下情况:
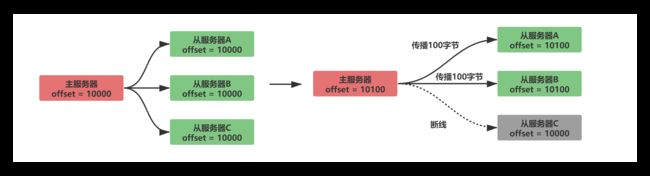
很明显有了复制偏移量之后,从服务器C断线重连后,主服务器只需要发送从服务器缺少的100字节数据即可。但是主服务器又是如何知道从服务器缺少的是那些数据呢?
2.2.2.2 复制积压缓冲区
复制积压缓冲区是一个固定长度的队列,默认为1MB大小。当主服务器数据状态发生改变,主服务器将数据同步给从服务器的同时会另存一份到复制积压缓冲区中。
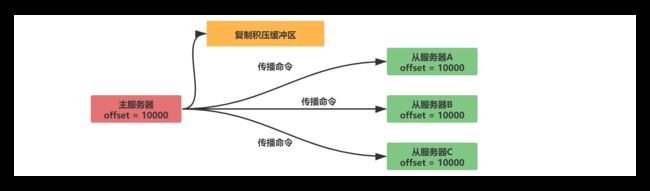
复制积压缓冲区为了能和偏移量进行匹配,它不仅存储了数据内容,还记录了每个字节对应的偏移量:

当从服务器断线重连后,从服务器通过psync命令将自己的复制偏移量(offset)发送给主服务器,主服务器便可通过这个偏移量来判断进行增量传播还是全量同步。
-
如果偏移量offset+1的数据仍然在复制积压缓冲区中,那么进行增量同步操作
-
反之进行全量同步操作,与sync一致
Redis的复制积压缓冲区的大小默认为1MB,如果需要自定义应该如何设置呢?
很明显,我们希望能尽可能的使用增量同步,但是又不希望缓冲区占用过多的内存空间。那么我们可以通过预估Redis从服务断线后重连的时间T,Redis主服务器每秒接收的写命令的内存大小M,来设置复制积压缓冲区的大小S。
S = 2 * M * T
注意这里扩大2倍是为了留有一定的余地,保证绝大部分的断线重连都能采用增量同步。
2.2.2.3 服务器运行 ID
看到这里是不是再想上面已经可以实现断线重连的增量同步了,还要运行ID干嘛?其实还有一种情况没考虑,就是当主服务器宕机后,某台从服务器被选举成为新的主服务器,这种情况我们就通过比较运行ID来区分。
-
运行ID(run id)是服务器启动时自动生成的40个随机的十六进制字符串,主服务和从服务器均会生成运行ID
-
当从服务器首次同步主服务器的数据时,主服务器会发送自己的运行ID给从服务器,从服务器会保存在RDB文件中
-
当从服务器断线重连后,从服务器会向主服务器发送之前保存的主服务器运行ID,如果服务器运行ID匹配,则证明主服务器未发生更改,可以尝试进行增量同步
-
如果服务器运行ID不匹配,则进行全量同步
2.2.3 完整的psync
完整的psync过程非常的复杂,在2.8-4.0的主从复制版本中已经做到了非常完善。psync命令发送的参数如下:
psync
当从服务器没有复制过任何主服务器(并不是主从第一次复制,因为主服务器可能会变化,而是从服务器第一次全量同步),从服务器将会发送:
psync ? -1
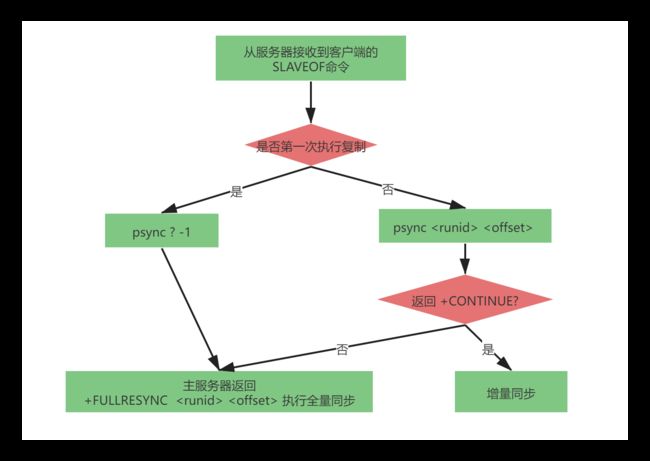
一起完整的psync流程如下图:
《一线大厂Java面试真题解析+Java核心总结学习笔记+最新全套讲解视频+实战项目源码》开源
Java优秀开源项目:
- ali1024.coding.net/public/P7/Java/git
最后
本人也收藏了一份Java面试核心知识点来应付面试,借着这次机会可以送给我的读者朋友们
目录:

Java面试核心知识点
一共有30个专题,足够读者朋友们应付面试啦,也节省朋友们去到处搜刮资料自己整理的时间!

Java面试核心知识点
已经有读者朋友靠着这一份Java面试知识点指导拿到不错的offer了

…(img-k9Z9oNiE-1649344307078)]
Java面试核心知识点
一共有30个专题,足够读者朋友们应付面试啦,也节省朋友们去到处搜刮资料自己整理的时间!
[外链图片转存中…(img-Ujw8vRXR-1649344307078)]
Java面试核心知识点
已经有读者朋友靠着这一份Java面试知识点指导拿到不错的offer了
[外链图片转存中…(img-8cDCzbJL-1649344307079)]